Hadoop HDFS DataNode 目录结构
DataNode 目录结构
和namenode不同的是,datanode的存储目录是初始阶段自动创建的,不需要额外格式化。
1、 在/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current这个目录下查看版本号
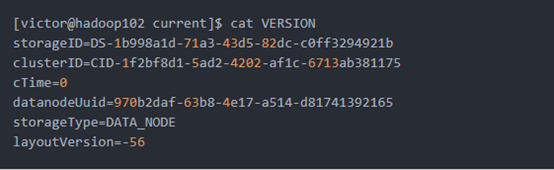
[victor@hadoop102 current]$ cat VERSION
storageID=DS-1b998a1d-71a3-43d5-82dc-c0ff3294921b
clusterID=CID-1f2bf8d1-5ad2-4202-af1c-6713ab381175
cTime=0
datanodeUuid=970b2daf-63b8-4e17-a514-d81741392165
storageType=DATA_NODE
layoutVersion=-56
2、具体解释
(1)storageID:存储id号
(2)clusterID集群id,全局唯一
(3)cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(4)datanodeUuid:datanode的唯一识别码
(5)storageType:存储类型
(6)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
3、在/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-97847618-192.168.10.102-1493726072779/current这个目录下查看该数据块的版本号
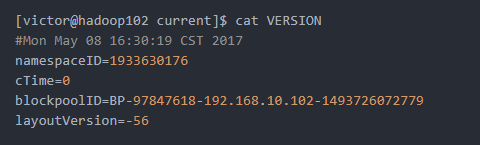
[victor@hadoop102 current]$ cat VERSION
#Mon May 08 16:30:19 CST 2017
namespaceID=1933630176
cTime=0
blockpoolID=BP-97847618-192.168.10.102-1493726072779
layoutVersion=-56
4、具体解释
(1)namespaceID:是datanode首次访问namenode的时候从namenode处获取的storageID对每个datanode来说是唯一的(但对于单个datanode中所有存储目录来说则是相同的),namenode可用这个属性来区分不同datanode。
(2)cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(3)blockpoolID:一个block pool id标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。
(4)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
Hadoop HDFS DataNode 目录结构的更多相关文章
- Hadoop HDFS元数据目录分析
元数据目录分析 在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘: $HADOOP_HOME/bin/hdfs namenode -format 格式化完成之后 ...
- Hadoop HDFS本地存储目录结构解析
转自:https://blog.csdn.net/superman_xxx/article/details/51689398 HDFS metadata以树状结构存储整个HDFS上的文件和目录,以及相 ...
- Hadoop阅读笔记(五)——重返Hadoop目录结构
常言道:男人是视觉动物.我觉得不完全对,我的理解是范围再扩大点,不管男人女人都是视觉动物.某些场合(比如面试.初次见面等),别人没有那么多的闲暇时间听你诉说过往以塑立一个关于你的完整模型.所以,第一眼 ...
- hadoop安装包的目录结构
初次接触Hadoop,了解了Hadoop安装包的目录结构,和大家分享下: bin:Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理 ...
- hadoop fs -put上传文件失败,WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: master:8020
hadoop fs -put上传文件失败 报错信息:(test文件夹是已经成功建好的) [root@master ~]# hadoop fs -put test1.txt /test // :: WA ...
- ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Incompatible namespaceIDs
用三台centos操作系统的机器搭建了一个hadoop的分布式集群.启动服务后失败,查看datanode的日志,提示错误:ERROR org.apache.hadoop.hdfs.server.dat ...
- hadoop的目录结构介绍
hadoop的目录结构介绍 解压缩hadoop 利用tar –zxvf把hadoop的jar包放到指定的目录下. tar -zxvf /home/software/aa.tar.gz -C /home ...
- hadoop目录结构
Hadoop目录结构 重要目录结构: bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本 etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件 lib目录:存放H ...
- Hadoop1.x目录结构及Eclipse导入Hadoop源码项目
这是解压hadoop后,hadoop-1.2.1目录 各目录结构及说明: Eclipse导入Hadoop源码项目: 注意:如果没有ant的包可以去网上下,不是hadoop里面的. 然后如果通过以上还报 ...
随机推荐
- python 一行代码字符串转字典方法
b = 'bid=Qzw9cKnyESM; ll="108288"; __yadk_uid=4YChvgeANLBEh4iV00n1tc0HQ8zpmSl1; __utmc=301 ...
- python 三方库
---------------- 这又是一个 Awesome XXX 系列的资源整理,由 vinta 发起和维护.内容包括:Web框架.网络爬虫.网络内容提取.模板引擎.数据库.数据可视化.图片处理. ...
- Python 依赖关系
class Person: def play(self, tools): # 通过参数的传递把另外一个类的对象传递进来 tools.run() print("很开心, 我能玩儿游戏了&quo ...
- 【Python】etree方法生成,解析xml
#练习:另一种遍历xml文件的方式etree,xpathimport systry: import xml.etree.cElementTree as ET #前面带c的都是比较快的,效率高且不占内存 ...
- webgl,threejs教程、笔记
发现一个不错的博客,学学. webgl和threejs教程
- PHPweb应用攻击总结(转)
XSS跨站脚本 概念:恶意攻击者往Web页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web里面的html代码会被执行,从而达到恶意用户的特殊目的. 危害: 盗取用户COOKIE信息. 跳转 ...
- Python之路,第十七篇:Python入门与基础17
python3 面向对象编程 面向对象编程 什么是对象? 一切皆对象: 面向对象是思想: 描述思想的语言有:C++/Java/Python/Swift/C# 两个概念: 类 class 对象 ob ...
- linux命令行总结给自己看的版本
复制 cp -r /src /dst 查看硬盘容量 df -h 重命名: mv /原来的 /现在的
- whmcs语言汉化路径
前台语言访问文件夹/lang,后台语言文件放入/admin/lang
- python猜数字(多种实现方法)
设定一个理想数字比如:66,让用户输入数字,如果比66⼤,则显示猜测的结果⼤了:如果比66⼩,则显示猜测的结果小了;只有等于66,显示猜测结果 第一种方式(最简单的方式实现) n = 66 # 理想数 ...