生存分析与R--转载
生存分析与R
生存分析是将事件的结果和出现这一结果所经历的时间结合起来分析的一类统计分析方法。不仅考虑事件是否出现,而且还考虑事件出现的时间长短,因此这类方法也被称为事件时间分析(time-to-event analysis)。生存分析是医学领域中一个重要的内容,在肿瘤等疾病的研究中运用十分广泛。
1.生存分析中的重要概念
生存分析的数据资料与其它一般的数据资料有一些不同的特征:
1. 其同时考虑生存时间和生存结局
2. 通常存在删失(censored)数据
3. 生存时间通常不服从生态分布。
1.1 生存时间
生存时间(survival time)指的是从开始事件到终点事件所经历的事件跨度。例如,急性白血病患者从发病到死亡所经历的事件跨度,冠心病患者两次发作之间的时间间隔等。
注意:在进行实验设计时,需要对起始事件、终点事件、时间单位进行明确的定义。
1.2 删失
生存结局(status)一般分为「死亡」和删失两类。「死亡」指的是我们感兴趣的终点事件(如白血病患者死亡、冠心病患者第二次发病)。除此之外的结局或生存结局则归类为删失(censoring),也称为截尾或终检。
删失的一般原因有:
1. 研究截至日期时,感兴趣终点事件仍未出现
2. 失访,不知道感兴趣终点事件何时发生或是否会发生
3. 因各种原因中途退出
4. 死于其它「事件」,如交通意外或其他疾病
2 生存分析的统计学方法与R的实现
生存分析拥有着与其它分析不同的统计学方法。
1. 描述统计:常采用Kaplan-Meier法进行分析,并绘制生存曲线;对于频数表资料,则可以采用寿命表进行分析(属于非参数统计方法)
2. 比较分析:我们经常需要对不同组别的生存率进行比较分析,比如比较使用或不用某种药物的HIV阳性患者的生存率是否不同。经常采用的log-rank检验以及Breslow检验。检验的零假设为:两组或多组总体生存时间分布相同。
3. 影响因素分析:我们可以建立生存模型来探讨哪些因素影响生存时间。常用的方法有两类,一类为半参数法:Cox比例风险模型;还有一类为参数法,主要有logistic分布法、Gompertz分布法等回归模型。
2.1 用R绘制生存曲线
在R中进行生存分析常用的包有survival包以及survminer包。
- survival 包提供了生存函数的建立,Cox模型的建立,以及比较分析。这个包也提供了基于基础绘图系统的生存曲线绘制。
- * survminer包*提供了基于ggplot2系统的可视化,具有更加美观的图形,以及定制方式。
2.1.1 数据集(data set)
我们在这里使用的数据集是survival包中含有的肺癌数据集:lung。前6条数据如下:
> library(survival)
## 前6条数据
> head(lung)
inst time status age sex ph.ecog ph.karno pat.karno meal.cal wt.loss
1 3 306 2 74 1 1 90 100 1175 NA
2 3 455 2 68 1 0 90 90 1225 15
3 3 1010 1 56 1 0 90 90 NA 15
4 5 210 2 57 1 1 90 60 1150 11
5 1 883 2 60 1 0 100 90 NA 0
6 12 1022 1 74 1 1 50 80 513 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
解释:
- inst: Institution code
- time: Survival time in days
- status: censoring status 1=censored, 2=dead
- age: Age in years
- sex: Male=1 Female=2
- ph.ecog: ECOG performance score (0=good 5=dead)
- ph.karno: Karnofsky performance score (bad=0-good=100) rated by physician Karnofsky
- pat.karno: performance score as rated by patient
- meal.cal: Calories consumed at meals
- wt.loss: Weight loss in last six months
2.1.2 生存曲线的拟合
survival包中的Sruv 函数可以创建一个生存对象。
>fit.surv <-Surv(lung$time,lung$status)
> head(fit.surv)
[1] 306 455 1010+ 210 883 1022+- 1
- 2
- 3
该函数根据是否为删失,将时间进行分类。右侧带有「+」号,代表为删失数据。
这时,我们可以使用survival包中的survfit函数用Kaplan-Meier法进行生存曲线的拟合。
> km<-survfit(fit.surv~1,data = lung)- 1
同时,我们也可以将其根据年龄(age)分为两组进行拟合:
>km_2<- survfit(fit.surv~sex,data=lung)- 1
2.1.3 生存曲线可视化的方法:
可视化方法有两种,一种是基于基础绘图系统的plot,还有一种是基于ggplot2绘图系统的ggsurvplot。
我们可以使用基于基础绘图系统的plot函数将其可视化:
plot (km)- 1
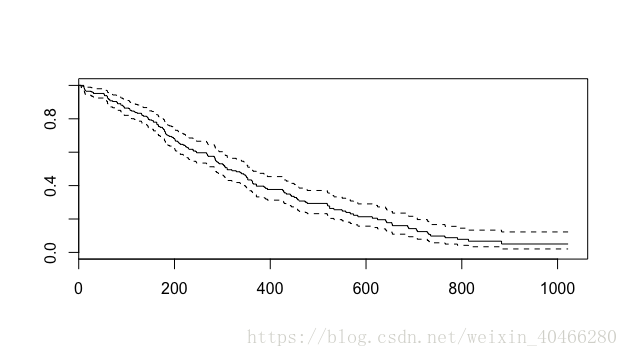
分组的生存曲线:
plot (km_2)- 1
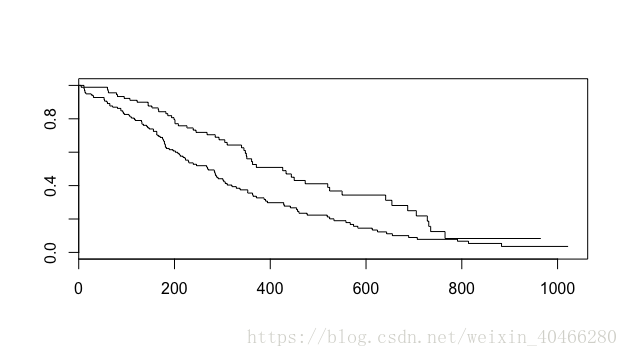
这种基于基础绘图系统的可视化方法较为简陋,可以修改的也参数也较少。目前在R语言中,可视化功能极其强大的是ggplot2系统。survminer包提供了基于ggplot2系统的可视化函数:ggsurvplot
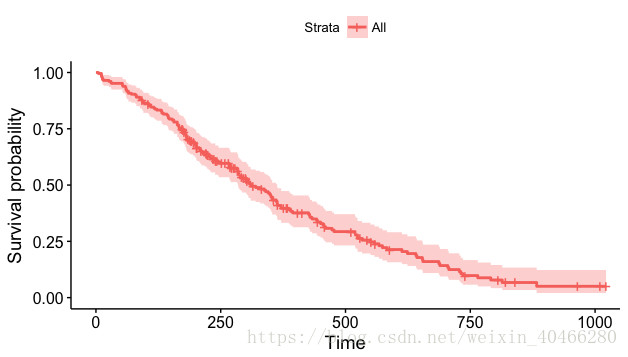
library(survminer)
ggsurvplot (km)- 1
- 2
ggsurvplot (km_2)- 1
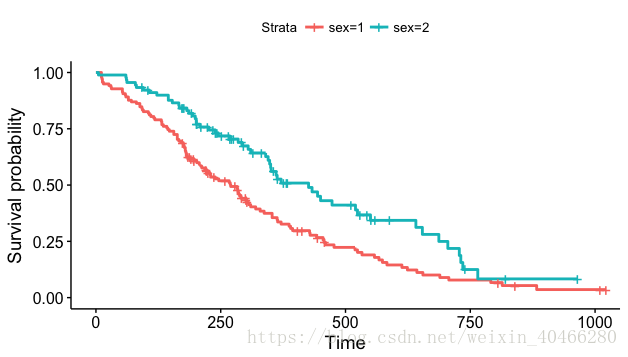
对比可以看出,survminer包绘制的生存曲线更加美观。同样,我们还可以对图形进行颜色的改变,图形大小的改变,增加图标以及图例位置的更换等:
ggsurvplot(km_2,
legend = "bottom", #将图例移动到下方
legend.title = "Sex",#改变图例名称
legend.labs = c("Male", "Female"),
linetype = "strata"# 改变线条类型
)- 1
- 2
- 3
- 4
- 5
- 6
修改后的图形:
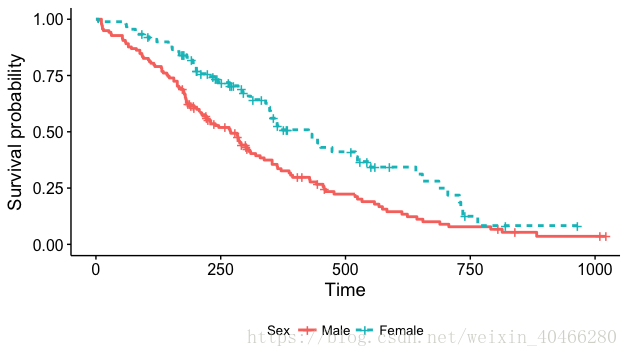
3.比较分析
一般情况下,我们都需要比较分析两组的生存时间分布是否不同。在survival包中,有一个survdiff的函数可以进行long-rank检验
> survdiff(fit.surv~sex,data = lung,
rho = 0 # rho = 0 表示使用long-rank检验或者Mantel-Haenszel 检验)
Call:
survdiff(formula = fit.surv ~ sex, data = lung, rho = 0)
N Observed Expected (O-E)^2/E (O-E)^2/V
sex=1 138 112 91.6 4.55 10.3
sex=2 90 53 73.4 5.68 10.3
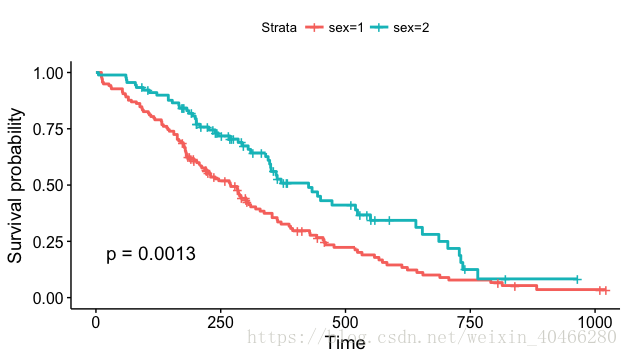
Chisq= 10.3 on 1 degrees of freedom, p= 0.00131
> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
此外,可以使用survminer包中的ggsurvplot函数中的pval=TRUE参数,在生存曲线中添加P值:
ggsurvplot(km_2, main = "Survival curve",
pval=TRUE #添加P值
)- 1
- 2
- 3
4.Cox 回归模型
4.1 Cox 模型的建立
我们还是利用第二部分所用的肺癌数据集(lung)进行Cox回归模型的建立,这一次,我们感兴趣的点主要是年龄、体重减轻以及性别是否会影响肺癌的生存时间:
> library(survival)
> res.cox<-coxph(Surv(time,status)~age+ph.ecog+wt.loss,data = lung)
> res.cox
Call:
coxph(formula = Surv(time, status) ~ age + ph.ecog + wt.loss,
data = lung)
coef exp(coef) se(coef) z p
age 0.01347 1.01356 0.00974 1.38 0.16659
ph.ecog 0.47222 1.60356 0.12771 3.70 0.00022
wt.loss -0.00717 0.99285 0.00663 -1.08 0.27921
Likelihood ratio test=19 on 3 df, p=0.000269
n= 213, number of events= 151
(15 observations deleted due to missingness)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在这个模型中我们可以看到ECOG评分的P值\<0.01,认为在这个模型中能够显著影响肺癌的生存分析,OR=1.6。
4.2 模型诊断——PH检验
在构建Cox模型之后,我们需要对这个模型进行PH检验。如果无法通过PH检验,我们需要对上述的Cox模型进行修改。
在survival包中,函数cox.zph可进行PH检验:
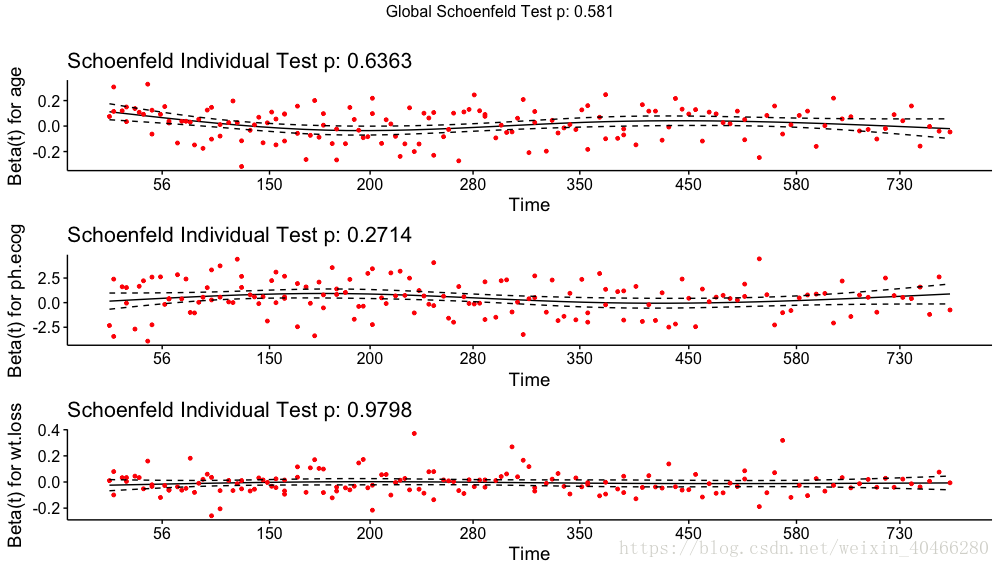
cox.zph(res.cox)
rho chisq p
age -0.03663 0.22364 0.636
ph.ecog -0.08018 1.20971 0.271
wt.loss -0.00191 0.00064 0.980
GLOBAL NA 1.95904 0.581
> - 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到P 值都>0.01,说明该模型能够通过PH检验。
使用survminer包中的ggcoxzph函数还可以将其进行可视化:
> temp<-cox.zph(res.cox)
> ggcoxzph(temp)- 1
- 2
如果无法通过PH检验,可以进行分层或使用其他的检验方法,如参数检验等。
生存分析与R--转载的更多相关文章
- 生存分析与R
生存分析与R 2018年05月19日 19:55:06 走在码农路上的医学狗 阅读数:4399更多 个人分类: R语言 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blo ...
- survival analysis 生存分析与R 语言示例 入门篇
原创博客,未经允许,不得转载. 生存分析,survival analysis,顾名思义是用来研究个体的存活概率与时间的关系.例如研究病人感染了病毒后,多长时间会死亡:工作的机器多长时间会发生崩溃等. ...
- R|生存分析 - KM曲线 ,值得拥有姓名和颜值
本文首发于“生信补给站”:https://mp.weixin.qq.com/s/lpkWwrLNtkLH8QA75X5STw 生存分析作为分析疾病/癌症预后的出镜频率超高的分析手段,而其结果展示的KM ...
- R语言学习 - 非参数法生存分析--转载
生存分析指根据试验或调查得到的数据对生物或人的生存时间进行分析和推断,研究生存时间和结局与众多影响因素间关系及其程度大小的方法,也称生存率分析或存活率分析.常用于肿瘤等疾病的标志物筛选.疗效及预后的考 ...
- R数据分析:生存分析与有竞争事件的生存分析的做法和解释
今天被粉丝发的文章给难住了,又偷偷去学习了一下竞争风险模型,想起之前写的关于竞争风险模型的做法,真的都是皮毛哟,大家见笑了.想着就顺便把所有的生存分析的知识和R语言的做法和论文报告方法都给大家梳理一遍 ...
- WOE:信用评分卡模型中的变量离散化方法(生存分析)
WOE:信用评分卡模型中的变量离散化方法 2016-03-21 生存分析 在做回归模型时,因临床需要常常需要对连续性的变量离散化,诸如年龄,分为老.中.青三组,一般的做法是ROC或者X-tile等等. ...
- Cox回归模型【生存分析】
参考:<复杂数据统计方法--基于R的应用> 吴喜之 在生存分析中,研究的主要对象是寿命超过某一时间的概率.还可以描述其他一些事情发生的概率,例如产品的失效.出狱犯人第一次犯罪.失业人员第一 ...
- Spark2 生存分析Survival regression
在spark.ml中,实现了加速失效时间(AFT)模型,这是一个用于检查数据的参数生存回归模型. 它描述了生存时间对数的模型,因此它通常被称为生存分析的对数线性模型. 不同于为相同目的设计的比例风险模 ...
- Forest plot(森林图) | Cox生存分析可视化
本文首发于“生信补给站”微信公众号,https://mp.weixin.qq.com/s/2W1W-8JKTM4S4nml3VF51w 更多关于R语言,ggplot2绘图,生信分析的内容,敬请关注小号 ...
随机推荐
- vue生命周期图示中英文版Vue实例生命周期钩子
vue生命周期图示中英文版Vue实例生命周期钩子知乎上近日有人发起了一个 “react 是不是比 vue 牛皮,为什么?” 的问题,Vue.js 作者尤雨溪12月4日正面回应了该问题.以下是尤雨溪回复 ...
- createDocumentFragment()用法总结
1.createDocumentFragment()方法,是用来创建一个虚拟的节点对象,或者说,是用来创建文档碎片节点.它可以包含各种类型的节点,在创建之初是空的. 2.DocumentFragmen ...
- springboot 接收post和get请求
接收post请求: @RequestMapping(value = "/api/v1/create_info", method = RequestMethod.POST) publ ...
- avr定时器做的正弦波
2010-04-19 16:53:00 实物照片如下 RC电路的电阻为1K与10K时的波形分别如下 仿真图片如下: 程序如下: #include <iom16v.h> #include & ...
- JavaUtil 处理Base64的图片上传
UploadImageBase64.java package com.lee.util; import java.io.File; import java.io.FileOutputStream; i ...
- jt项目菜单页面实现
jt项目菜单页面实现 一. 业务描述: 1) 数据呈现时使用bootstrap中的treeGrid插件(基于jquery实现). bootstrap特点:简洁.直观.强悍.移动设备优先的前端开发框架, ...
- Linux下的Jmeter运行测试
本文主要介绍Jmeter脚本如何在Linux通过no GUI的方式运行.总共分三部分: 1.Linux下JDK的安装及环境变量的配置 2.Linux下Jmeter的安装及环境变量的配置 3.运行结果的 ...
- A-作业01
#1 简单作业 1. 系统的日志文件/var/log/secure /var/log/messages /var/log/cron会自动的进行轮询,系统是通过什么实现的? 2. 写出下面特殊符号在定时 ...
- 如何搭建一个 MySQL 分布式集群
1.准备集群搭建环境 使用6台虚拟机来搭建 MySQL分布式集群 ,相应的实验环境与对应的MySQL节点之间的对应关系如下图所示: 管理节点(MGM):这类节点的作用是管理MySQLCluster内的 ...
- springboot 项目pom.xml文件基本配置
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven ...