Scrapy学习篇(三)之创建项目和Scrapy的安装
安装Scrapy
了解了Scrapy的框架和部分命令行之后,创建项目,开始使用之前,当然是安装Scrapy框架了。
关于Scrapy框架的安装,请参考:https://cuiqingcai.com/5421.html
创建项目
创建项目是爬取内容的第一步,之前已经讲过,Scrapy通过scrapy startproject <project_name>命令来在当前目录下创建一个新的项目。
下面我们创建一个爬取网址(http://quotes.toscrape.com/)的名言,作者和tags为例讲解。
scrapy startproject quotes #项目名称
scrapy genspider quotes quotes.com # quotes为爬虫名称,quotes.com为允许爬取的域名限制
其中quotes是你的项目的名字,可以自己定义。
其目录结构如下
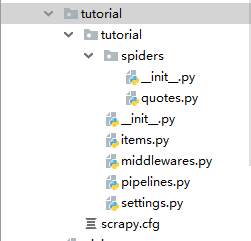
下面简单的讲解一下各目录/文件的作用:
- scrapy.cfg
项目的配置文件,带有这个文件的那个目录作为scrapy项目的根目录 - items.py
定义你所要抓取的字段 - pipelines.py
管道文件,当spider抓取到内容(item)以后,会被送到这里,这些信息(item)在这里会被清洗,去重,保存到文件或者数据库。 - middlewares.py
中间件,主要是对功能的拓展,你可以添加一些自定义的功能,比如添加随机user-agent, 添加proxy,cookies;当需要使用selenium时,也是在这里设置。 - settings.py
设置文件,用来设置爬虫的默认信息,相关功能开启与否,比如是否遵循robots协议,设置默认的headers,设置文件的路径,中间件的执行顺序等等。 - spiders/
在这个文件夹下面,编写你自定义的spider。
编写爬虫
编写spider文件
在项目中的spiders文件夹下面创建一个文件,命名为quotes.py我们将在这个文件里面编写我们的爬虫。先上代码再解释。
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes = BeautifulSoup(response.text,'lxml')
for quote in quotes.find_all(name = 'div',class_='quote'):
item = QuoteItem() #使用items中定义的数据结构
for s in quote.find_all(name = 'span',class_='text'):
item['text'] = s.text
for s in quote.find_all(name= 'small',class_='author'):
item['author'] = s.text
for s in quote.find_all(name='div', class_='tags'):
item['tags'] = s.text.replace('\n','').strip().replace(' ','')
yield item
nexts = quotes.find_all(name='li', class_='next') #获取下一页的地址
for next in nexts:
n = next.find(name='a')
url = 'http://quotes.toscrape.com/' + n['href']
yield scrapy.Request(url = url,callback = self.parse)
- 导入scrapy模块
- 定义一个spider类,继承自scrapy.Spider父类。
下面是三个重要的内容
- name: 用于区别Spider。 该名字必须是唯一的,不可以为不同的Spider设定相同的名字。这一点很重要。
- start_urls: 包含了Spider在启动时进行爬取的url列表。第一个被获取到的页面将是其中之一。即这是爬虫链接的起点,爬虫项目启动,便开始从这个链接爬取,后续的URL则从初始的URL获取到的数据中提取。
- parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
修改settings.py文件
将settings.py文件里面的下列内容修改如下,其余的内容不动。
ROBOTSTXT_OBEY = False #不遵循robots协议 #去掉下面的这个注释,以设置请求头信息,伪造浏览器headers,并手动添加一个user-agent,也可以在下载器中间件中设置更灵活的user-agent获取方法
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
#user-agent新添加
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
编写Pipeline
我们将在pipeline文件中处理在spider中获取到的item,将其存储到mongodb数据库中。
class MongoPipeline(object):
def __init__(self,mongo_url,mongo_db):
self.mongo_url = mongo_url
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_url=crawler.settings.get('MONGO_URL'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
def process_item(self,item, spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
运行我们的爬虫项目
至此,项目必要的信息已经全部完成了,下面就是运行我们的爬虫项目
进入带有scrapy.cfg文件的那个目录,前面已经说过,这是项目的根目录,执行下面的命令scrapy crawl quotes
查看mongodb数据库,数据应该已经获取下来了。
Scrapy学习篇(三)之创建项目和Scrapy的安装的更多相关文章
- Scrapy学习篇(七)之Item Pipeline
在之前的Scrapy学习篇(四)之数据的存储的章节中,我们其实已经使用了Item Pipeline,那一章节主要的目的是形成一个笼统的认识,知道scrapy能干些什么,但是,为了形成一个更加全面的体系 ...
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- Scrapy学习篇(三)之创建项目
创建项目 创建项目是爬取内容的第一步,之前已经讲过,Scrapy通过scrapy startproject <project_name>命令来在当前目录下创建一个新的项目. 下面我们创建一 ...
- Scrapy教程——搭建环境、创建项目、爬取内容、保存文件
1.创建项目 在开始爬取之前,您必须创建一个新的Scrapy项目.进入您打算存储代码的目录中,运行新建命令. 例如,我需要在D:\00Coding\Python\scrapy目录下存放该项目,打开命令 ...
- Scrapy学习篇(九)之文件与图片下载
Media Pipeline Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines . 这些pipeline有些共同的方 ...
- Scrapy学习篇(八)之settings
Scrapy设定(settings)提供了定制Scrapy组件的方法.你可以控制包括核心(core),插件(extension),pipeline及spider组件.设定为代码提供了提取以key-va ...
- Scrapy学习篇(五)之Spiders
Spiders Spider类定义了如何爬取某个网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item).简而言之,Spider就是你定义爬取的动作及分析某个网 ...
- Scrapy学习篇(二)之常用命令行工具
简介 Scrapy是通过Scrapy命令行工具进行控制的,包括创建新的项目,爬虫的启动,相关的设置,Scrapy提供了两种内置的命令,分别是全局命令和项目命令,顾名思义,全局命令就是在任意位置都可以执 ...
- scrapy学习笔记(三):使用item与pipeline保存数据
scrapy下使用item才是正经方法.在item中定义需要保存的内容,然后在pipeline处理item,爬虫流程就成了这样: 抓取 --> 按item规则收集需要数据 -->使用pip ...
随机推荐
- 命令提示符操作及Java的特点
day1_3 命令提示符的操作 GUI 图形化方式(可视化) CLI 命令行方式 (编程方式) dir 列出当前目录下文件及文件夹 md 创建文件夹 rd 删除文件夹(只能删除空文件夹) cd 进入指 ...
- java中类与方法叙述正确的是
这道题的4个选项全是错的. A.一个文件中,可以有多个public class public class Main { public class Inner{ } } 即,外部类为public,还 ...
- nginx 优化(突破十万并发)
一般来说nginx配置文件中对优化比较有作用的为以下几项: worker_processes 8; nginx进程数,建议按照cpu数目来指定,一般为它的倍数. worker_cpu_affinity ...
- oracle重做日志文件硬盘坏掉解决方法
rman target/ list backup; list backup summary; 删除数据库数据文件夹下的log日志,例如/u01/app/oracle/oradata/ORCL下的所有后 ...
- CSVN部署安装,实现web管理svn
系统环境:centos7最小化安装 下载这个文件并解压 https://pan.baidu.com/s/1miwdBc8 tar zxvf jdk-8u91-linux-x64.gz mv jdk1. ...
- MySQL--时间戳与时区问题
对于使用 timestamp 的场景,MySQL 在访问 timestamp 字段时会做时区转换,当 time_zone 设置为 system 时,MySQL 访问每一行的 timestamp 字段时 ...
- zeebe 为微服务架构的工作流引擎
zeebe 是灵活.轻量的基于微服务架构的工作流引擎 包含以下特性: 可视化的额工作流 审计日志以及历史 水平缩放 持久化&&容错 消息驱动 操作容易 语言无关 工作流基于标准bpmn ...
- node nightmare 网页自动化测试 sample
安装nightmare 编写1.js 运行 node 1.js var Nightmare = require('nightmare');var nightmare = Nightmare({ sho ...
- ASP.NET AJAX入门系列(1):概述
经常关注我的Blog的朋友可能注意到了,在我Blog的左边系列文章中,已经移除了对Atlas学习手记系列文章的推荐,因为随着ASP.NET AJAX 1.0 Beta版的发布,它们已经不再适用,为了不 ...
- Centos6.7 运行 eclipse出错解决办法
今天在centos下运行eclipse c++出现来点问题.主要原因是jdk点安装以及环境变量始终不对. 尝试在/etc/profile中手动配置,也没有成功. 做了如下步骤成功解决. 1.查看jdk ...