ID3决策树
决策树
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺少不敏感,可以处理不相关特征数据
- 缺点:过拟合
决策树的构造
熵:混乱程度,信息的期望值
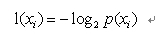
其中p(xi)是选择分类的概率
熵就是计算所有类别所有可能值包含的信息期望值,公式如下:
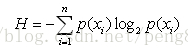
构造基本思路
信息增益 = 初始香农熵-新计算得到的香农熵(混乱程度下降的多少)
创建根节点(数据)
分裂:选择合适的特征进行分裂,采取的办法是遍历每个特征,然后计算并累加每个特征值的香农熵,与其他特征所计算出来的香农熵对比,选取信息增益最大的那个作为最大信息增益的特征节点进行分裂,分裂时,该特征有几个特征值,就会分裂成多少个树干,之后重复迭代分裂直至不能再分裂为止
好了!懂这些就可以直接上代码了!
from math import log
import operator def calcShannonEnt(dataSet):
"计算熵,熵代表不确定度,混乱程度" numEntries = len(dataSet) #训练样本总数
labelCounts = {} for featVec in dataSet:
currentLabel = featVec[-1] #取标签 if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #计算对应标签的数量 shannonEnt = 0.0 #初始化熵 for key in labelCounts:
"遍历每个标签字典,标签字典中包含每个标签的数量" prob = float(labelCounts[key]) / numEntries #计算选择该分类的概率概率
shannonEnt -= prob * log(prob,2)
return shannonEnt def createDataSet():
dataSet = [
[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no'], ]
labels = ['no surfacing','flippers']
return dataSet,labels myDat , labels = createDataSet()
ret = calcShannonEnt(myDat)
print(ret) def splitDataSet(dataSet,axis,value):
retDataSet = [] for featVec in dataSet:
if featVec[axis] == value:
"把选定特征为特定值的数据集分离出来"
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:]) #把一个列表压缩进一个列表去而不是单纯append
retDataSet.append(reducedFeatVec)
return retDataSet def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0 #信息增益
bestFeature = -1
for i in range(numFeatures):
"遍历特征,选择最大信息增益的特征"
featList = [example[i] for example in dataSet] #按特征提取数据,用于分割数据
uniqueVals = set(featList) #去重 newEntropy = 0.0 for value in uniqueVals:
"遍历每个不同的特征值,将遍历的每个特征值为节点进行分割,计算熵,累加,选择最大信息增益的特征"
subDataSet = splitDataSet(dataSet,i,value)#分割数据集,将第几个特征为哪个特征值的数据分离出来 prob = len(subDataSet) / float(len(dataSet)) #计算这个特征为这个特征值的发生概率
newEntropy += prob * calcShannonEnt(subDataSet) infoGain = baseEntropy - newEntropy #信息增益:熵值的减少 if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature def majorityCnt(classList):
"最大投票器,用于数据集只有一个特征的时候"
classcount = {} for vote in classList:
if vote not in classcount.keys(): classcount[vote] =0
classcount += 1
sorteClassCount = sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
#由大到小 字典的值排序 return sorteClassCount[0][0] def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet] #取标签 if classList.count(classList[0]) == len(classList):
"类别相同停止继续划分"
return classList[0] if len(dataSet[0]) == 1:
"停止划分,因为没有特征"
return majorityCnt(classList) bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat] mytree = {bestFeatLabel:{}} del(labels[bestFeat]) #该特征也被已划分节点,删除特征 featValues = [example[bestFeat] for example in dataSet] #提取对于该节点信息增益最大的特征的所有特征值
uniqueVals = set(featValues) #去重 for value in uniqueVals:
"为该节点下最大信息增益的特征的不重合特征值进行再次创建决策树"
subLabels = labels[:] mytree[bestFeatLabel][value] = createTree(splitDataSet(
dataSet,bestFeat,value
),subLabels)
return mytree def classify(inputTree,featLabels,testVec):
"训练完毕,用于预测"
firstStr = inputTree.keys()[0] #取第一个节点
secondDict = inputTree[firstStr] featIndex = featLabels.index(firstStr) #查看这个特征的索引(查这是第几个特征)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else:
classLabel = secondDict[key]
return classLabel def storeTree(inputTree,filename):
"保存训练完毕的决策树模型"
import pickle
fw = open(filename,'w')
pickle.dump(inputTree,fw)
fw.close() def grabTree(filename):
"加载以保存的决策树模型" import pickle
fr = open(filename)
return pickle.load(filename,fr)
'''
绘制决策树
'''
import matplotlib.pyplot as plt decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-") def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree)[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs += 1
return numLeafs def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree)[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args) def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30) def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
depth = getTreeDepth(myTree)
firstStr = list(myTree)[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key], cntrPt, str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#if you do get a dictonary you know it's a tree, and the first element will be another dict def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
#createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), '')
plt.show() #def createPlot():
# fig = plt.figure(1, facecolor='white')
# fig.clf()
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
# plotNode('a decision node', (0.5, 0.1), (0.1, 0.5), decisionNode)
# plotNode('a leaf node', (0.8, 0.1), (0.3, 0.8), leafNode)
# plt.show() def retrieveTree(i):
listOfTrees = [{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
]
return listOfTrees[i]
thisTree = retrieveTree(1)
createPlot(thisTree)
ID3决策树的更多相关文章
- ID3决策树预测的java实现
刚才写了ID3决策树的建立,这个是通过决策树来进行预测.这里主要用到的就是XML的遍历解析,比较简单. 关于xml的解析,参考了: http://blog.csdn.net/soszou/articl ...
- Python3实现机器学习经典算法(三)ID3决策树
一.ID3决策树概述 ID3决策树是另一种非常重要的用来处理分类问题的结构,它形似一个嵌套N层的IF…ELSE结构,但是它的判断标准不再是一个关系表达式,而是对应的模块的信息增益.它通过信息增益的大小 ...
- ID3决策树的Java实现
package DecisionTree; import java.io.*; import java.util.*; public class ID3 { //节点类 public class DT ...
- python ID3决策树实现
环境:ubuntu 16.04 python 3.6 数据来源:UCI wine_data(比较经典的酒数据) 决策树要点: 1. 如何确定分裂点(CART ID3 C4.5算法有着对应的分裂计算方式 ...
- ID3决策树---Java
1)熵与信息增益: 2)以下是实现代码: //import java.awt.color.ICC_ColorSpace; import java.io.*; import java.util.Arra ...
- java编写ID3决策树
说明:每个样本都会装入Data样本对象,决策树生成算法接收的是一个Array<Data>样本列表,所以构建测试数据时也要符合格式,最后生成的决策树是树的根节点,通过里面提供的showTre ...
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 决策树ID3算法[分类算法]
ID3分类算法的编码实现 <?php /* *决策树ID3算法(分类算法的实现) */ /* *求信息增益Grain(S1,S2) */ //-------------------------- ...
- 机器学习之决策树(ID3 、C4.5算法)
声明:本篇博文是学习<机器学习实战>一书的方式路程,系原创,若转载请标明来源. 1 决策树的基础概念 决策树分为分类树和回归树两种,分类树对离散变量做决策树 ,回归树对连续变量做决策树.决 ...
随机推荐
- IE报错:[vuex] vuex requires a Promise polyfill in this browser.
使用的是vue2.0版本 IE报错提醒: 导致原因:使用了 ES6 中用来传递异步消息的的Promise,而IE的浏览器不支持 解决办法: 1.安装babel-polyfill模块,babel-plo ...
- 7-通用GPIO
7-通用GPIO 1.I/O 端口控制寄存器 每个 GPIO 有 4 个 32 位存储器映射的控制寄存器(GPIOx_MODER.GPIOx_OTYPER.GPIOx_OSPEEDR.GPIOx_PU ...
- what's the 套期保值
出自 MBA智库百科(https://wiki.mbalib.com/) 什么是套期保值 套期保值是指把期货市场当作转移价格风险的场所,利用期货合约作为将来在现货市场上买卖商品的临时替代物,对其现在买 ...
- 显示日期的指令: date
1.显示日期的指令: date (1)参数: (2)实例
- idea-常用插件-nginx
1.mac上nginx安装 brew search nginx brew install nginx 当然也可以编译安装 安装完以后,可以在终端输出的信息里看到一些配置路径: /usr/local/e ...
- 【4】axios 获取数据
API:https://www.kancloud.cn/yunye/axios/234845 基于axios进行二次封装 安装axios npm install axios --save 安装成功 [ ...
- C 语言循环结构
25.有如下程序 main() { int i,sum; for(i=1;i<=3;sum++) sum+=i; printf("%d\n",sum); } 该程序的执行 ...
- 如何在Android的ListView中构建CheckBox和RadioButton列表(支持单选和多选的投票项目示例)
引言 我们在android的APP开发中有时候会碰到提供一个选项列表供用户选择的需求,如在投票类型的项目中,我们提供一些主题给用户选择,每个主题有若干选项,用户对这些主题的选项进行选择,然后提交. 本 ...
- 基于jquery ajax的多文件上传进度条
效果图 前端代码,基于jquery <!DOCTYPE html> <html> <head> <title>主页</title> < ...
- python timeit
//有时候,我们想知道一个函数的计算耗时,那么,你可以用timeit //test.py 1 import timeit 2 3 def func(): 4 s = 0 5 ...