SILC超像素分割算法详解(附Python代码)
SILC算法详解
一、原理介绍
SLIC算法是simple linear iterative cluster的简称,该算法用来生成超像素(superpixel)
算法步骤:
- 已知一副图像大小M*N,可以从RGB空间转换为LAB空间,LAB颜色空间表现的颜色更全面
- 假如预定义参数K,K为预生成的超像素数量,即预计将M*N大小的图像(像素数目即为M*N)分隔为K个超像素块,每个超像素块范围大小包含[(M*N)/K]个像素
- 假设每个超像素区域长和宽都均匀分布的话,那么每个超像素块的长和宽均可定义为S,S=sqrt(M*N/K)
- 遍历操作,将每个像素块的中心点的坐标(x,y)及其lab的值保存起来,加入到事先定义好的集合中
- 每个像素块的中心点默认是(S/2,S/2)进行获取的,有可能落在噪音点或者像素边缘(所谓像素边缘,即指像素突变处,比如从黑色过渡到白色的交界处),这里,利用差分方式进行梯度计算,调整中心点:
算法中,使用中心点的8领域像素点,计算获得最小梯度值的像素点,并将其作为新的中心点,差分计算梯度的公式:
Gradient(x,y)=dx(i,j) + dy(i,j);
dx(i,j) = I(i+1,j) - I(i,j);
dy(i,j) = I(i,j+1) - I(i,j);
遍历现中心点的8领域像素点,将其中计算得到最小Gradient值的像素点作为新的中心点
- 调整完中心点后即需要进行像素点的聚类操作
通过聚类的方式迭代计算新的聚类中心;
首先,需要借助K-means聚类算法,将像素点进行归类,通过变换的欧氏聚距离公式进行,公式如下(同时参考像素值和坐标值提取相似度):
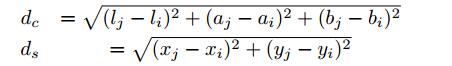
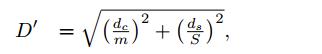
通过两个参数m和S来协调两种距离的比例分配。参数S即是上面第③步计算得出的每个像素块的长度值,而参数M为LAB空间的距离可能最大值,其可取的范围建议为[1,40]
为了节省时间,只遍历每个超像素块中心点周边的2S*2S区域内的像素点,计算该区域内每个像素点距离哪一个超像素块的中心点最近,并将其划分到其中;完成一次迭代后,重新计算每个超像素块的中心点坐标,并重新进行迭代(注:衡量效率和效果后一般选择迭代10次)
二、代码实现
import math
from skimage import io, color
import numpy as np class Cluster(object): cluster_index = 1 def __init__(self, row, col, l=0, a=0, b=0):
self.update(row, col, l, a, b)
self.pixels = []
self.no = self.cluster_index
Cluster.cluster_index += 1 def update(self, row, col, l, a, b):
self.row = row
self.col = col
self.l = l
self.a = a
self.b = b class SLICProcessor(object):
@staticmethod
def open_image(path):
rgb = io.imread(path)
lab_arr = color.rgb2lab(rgb)
return lab_arr @staticmethod
def save_lab_image(path, lab_arr):
rgb_arr = color.lab2rgb(lab_arr)
io.imsave(path, rgb_arr) def make_cluster(self, row, col):
row=int(row)
col=int(col)
return Cluster(row, col,
self.data[row][col][0],
self.data[row][col][1],
self.data[row][col][2]) def __init__(self, filename, K, M):
self.K = K
self.M = M self.data = self.open_image(filename)
self.rows = self.data.shape[0]
self.cols = self.data.shape[1]
self.N = self.rows * self.cols
self.S = int(math.sqrt(self.N / self.K)) self.clusters = []
self.label = {}
self.dis = np.full((self.rows, self.cols), np.inf) def init_clusters(self):
row = self.S / 2
col = self.S / 2
while row < self.rows:
while col < self.cols:
self.clusters.append(self.make_cluster(row, col))
col+= self.S
col = self.S / 2
row += self.S def get_gradient(self, row, col):
if col + 1 >= self.cols:
col = self.cols - 2
if row + 1 >= self.rows:
row = self.rows - 2 gradient = (self.data[row + 1][col][0] +self.data[row][col+1][0]-2*self.data[row][col][0])+ \
(self.data[row + 1][col][1] +self.data[row][col+1][1]-2*self.data[row][col][1]) + \
(self.data[row + 1][col][2] +self.data[row][col+1][2]-2*self.data[row][col][2]) return gradient def move_clusters(self):
for cluster in self.clusters:
cluster_gradient = self.get_gradient(cluster.row, cluster.col)
for dh in range(-1, 2):
for dw in range(-1, 2):
_row = cluster.row + dh
_col = cluster.col + dw
new_gradient = self.get_gradient(_row, _col)
if new_gradient < cluster_gradient:
cluster.update(_row, _col, self.data[_row][_col][0], self.data[_row][_col][1], self.data[_row][_col][2])
cluster_gradient = new_gradient def assignment(self):
for cluster in self.clusters:
for h in range(cluster.row - 2 * self.S, cluster.row + 2 * self.S):
if h < 0 or h >= self.rows: continue
for w in range(cluster.col - 2 * self.S, cluster.col + 2 * self.S):
if w < 0 or w >= self.cols: continue
L, A, B = self.data[h][w]
Dc = math.sqrt(
math.pow(L - cluster.l, 2) +
math.pow(A - cluster.a, 2) +
math.pow(B - cluster.b, 2))
Ds = math.sqrt(
math.pow(h - cluster.row, 2) +
math.pow(w - cluster.col, 2))
D = math.sqrt(math.pow(Dc / self.M, 2) + math.pow(Ds / self.S, 2))
if D < self.dis[h][w]:
if (h, w) not in self.label:
self.label[(h, w)] = cluster
cluster.pixels.append((h, w))
else:
self.label[(h, w)].pixels.remove((h, w))
self.label[(h, w)] = cluster
cluster.pixels.append((h, w))
self.dis[h][w] = D def update_cluster(self):
for cluster in self.clusters:
sum_h = sum_w = number = 0
for p in cluster.pixels:
sum_h += p[0]
sum_w += p[1]
number += 1
_h =int( sum_h / number)
_w =int( sum_w / number)
cluster.update(_h, _w, self.data[_h][_w][0], self.data[_h][_w][1], self.data[_h][_w][2]) def save_current_image(self, name):
image_arr = np.copy(self.data)
for cluster in self.clusters:
for p in cluster.pixels:
image_arr[p[0]][p[1]][0] = cluster.l
image_arr[p[0]][p[1]][1] = cluster.a
image_arr[p[0]][p[1]][2] = cluster.b
image_arr[cluster.row][cluster.col][0] = 0
image_arr[cluster.row][cluster.col][1] = 0
image_arr[cluster.row][cluster.col][2] = 0
self.save_lab_image(name, image_arr) def iterates(self):
self.init_clusters()
self.move_clusters()
#考虑到效率和效果,折中选择迭代10次
for i in range(10):
self.assignment()
self.update_cluster()
self.save_current_image("output.jpg") if __name__ == '__main__':
p = SLICProcessor('beauty.jpg', 200, 40)
p.iterates()
三、运行效果截图
(原图)
(效果图)


代码参考了https://github.com/laixintao/slic-python-implementation,且做了改进
作为一枚技术小白,写这篇笔记的时候参考了很多博客论文,在这里表示感谢,转载请注明出处......
SILC超像素分割算法详解(附Python代码)的更多相关文章
- OpenCV3三种超像素分割算法源码以及效果
OpenCV3中超像素分割算法SEEDS,SLIC, LSC算法在Contrib包里,需要使用Cmake编译使用.为了方便起见,我将三种算法的源码文件从contrib包里拎了出来,可以直接使用,顺便比 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- 对数损失函数logloss详解和python代码
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
- 洛谷P3366【模板】最小生成树-克鲁斯卡尔Kruskal算法详解附赠习题
链接 题目描述 如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出orz 输入输出格式 输入格式: 第一行包含两个整数N.M,表示该图共有N个结点和M条无向边.(N<=5000,M&l ...
- sip鉴权认证算法详解及python加密
1. 认证和加密 认证(Authorization)的作用在于表明自己是谁,即向别人证明自己是谁.而相关的概念是MD5,用于认证安全.注意MD5仅仅是个hash函数而已,并不是用于加密.因为ha ...
- AdaBoost算法详解与python实现
1. 概述 1.1 集成学习 目前存在各种各样的机器学习算法,例如SVM.决策树.感知机等等.但是实际应用中,或者说在打比赛时,成绩较好的队伍几乎都用了集成学习(ensemble learning)的 ...
- 排序算法详解(java代码实现)
排序算法大致分为内部排序和外部排序两种 内部排序:待排序的记录全部放到内存中进行排序,时间复杂度也就等于比较的次数 外部排序:数据量很大,内存无法容纳,需要对外存进行访问再排序,把若干段数据一次读 ...
- 斐波那契堆(Fibonacci heap)原理详解(附java代码实现)
前言 斐波那契堆(Fibonacci heap)是计算机科学中最小堆有序树的集合.它和二项式堆有类似的性质,但比二项式堆有更好的均摊时间.堆的名字来源于斐波那契数,它常用于分析运行时间. 堆结构介绍 ...
- 超像素经典算法SLIC的代码的深度优化和分析。
现在这个社会发展的太快,到处都充斥着各种各样的资源,各种开源的平台,如github,codeproject,pudn等等,加上一些大型的官方的开源软件,基本上能找到各个类型的代码.很多初创业的老板可能 ...
随机推荐
- HSQL可视化工具
本地使用HSQL数据库进行开发,多是集成在开发工具的内部,比如studio,往往看不到HSQL数据库,那么如何查看HSQL数据库呢? 可以使用hsql自带的可视化工具,运行hsqldb-*.jar 包 ...
- MT【1】终点在球面上的向量
解答: 评:最小值在Q为球心时取到,体现数学对称性的美!
- innerHTML、outerHTML、innerText、outerText的区别及兼容性问题
今天看了很多文章关于innerHTML.outerHTML.innerText.outerText的区别,都是很模糊的一个介绍,所以自己总结下这些区别以及一些重点内容.很多文章在描述这些区别的时候,都 ...
- Leetcode 326.3的幂 By Python
给定一个整数,写一个函数来判断它是否是 3 的幂次方. 示例 1: 输入: 27 输出: true 示例 2: 输入: 0 输出: false 示例 3: 输入: 9 输出: true 示例 4: 输 ...
- OneProxy 管理
-----client-----------haproxy---------mysql1----------mysql2------192.168.1.250 192.168.1.1 192.168. ...
- nowcoder172A 中位数 (二分答案)
二分一下答案,假设是x. 我们把大于x的看成1,小于x的看成-1,等于x的看成0 那某个区间的和如果是正的,就说明这个区间中位数大于x:如果是0,就等于x:如果是负的,就小于x: 这样的话,做一个前缀 ...
- [FJOI2017]矩阵填数——容斥
参考:题解 P3813 [[FJOI2017]矩阵填数] 题目大意: 给定一个 h∗w 的矩阵,矩阵的行编号从上到下依次为 1...h ,列编号从左到右依次 1...w . 在这个矩阵中你需要在每个格 ...
- 关于:HTTP Header -> Content-Type: text/plain Cache-Control: no-cache IE浏览器弹出错误下载对话
下午遇到一个很奇怪的现象,一个网址: http://192.168.1.3/login?action=a&fr=b.com 注意网址后面的参数形式,action参数在前,最后一个参数值的尾部含 ...
- 关于使用vw单位适配H5项目(二)
一些比较小的H5页面,我觉得全没有必要一定要使用框架的,比如vue和react之类的,我觉得原生的js,html5也可以写好移动端. 最近刚好要赶10多个h5页面,适配移动端的,各种手机型号都要适配, ...
- vs2013配置opencv2.4.13
此方法配置简单,方便易行,解压opencv2.4.13后得到opencv文件夹,进行如下步骤: 1.添加环境变量 用户变量,新建,变量名opencv,值D:\opencv\build 系统变量,Pat ...