spark 关联source
IDEA就自动把jar包中的字节码反编译为Java源码,并且,我们可以直接下个断点调试程序,但是对于Scala,IDEA的反编译效果并不是很好,如下图所示:
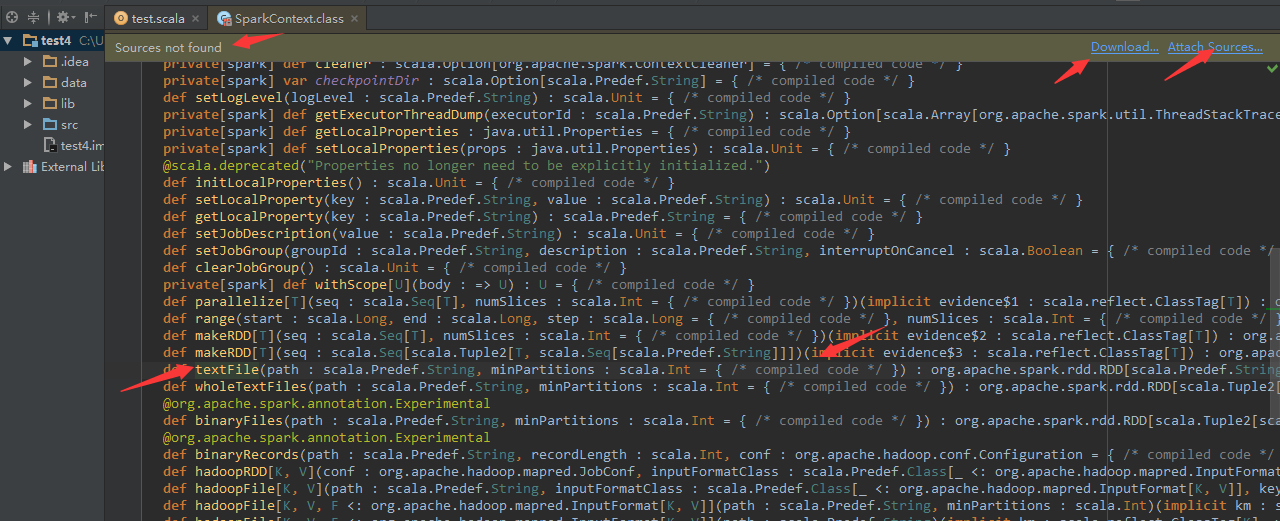
2)提示“Source not found”,我们在看textFile()方法,只可以看到方法的参数列表,方法体的内容却看不到,只能看到“compiled code”也就是“编译后的代码”。解决方法如下:
a.下载 源码 eg: https://archive.apache.org/dist/spark/spark-2.0.2/
b.然后点击右上角的“Attach Source”,添加源码,如下所示:
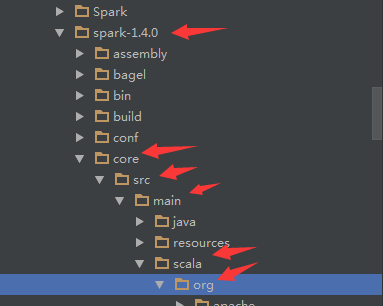
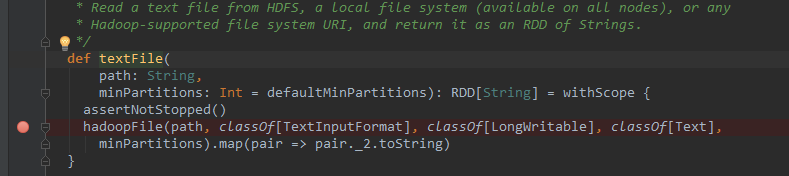
添加路径是“spark1.4.0/core/src/main/scala/org”,然后点击OK确定。“Attching”完成之后,我们就可以看到textFile()的方法体了,并且可以像之前调试hadoop一样,在这个方法下断点,运行程序的时候,会在这里命中断点,如下所示(这里只是加了个断点,没有调试):
spark 关联source的更多相关文章
- ubuntu 12.04 下 eclipse关联 source code
一.JDK source code 命令行中: sudo apt-get install openjdk-7-source 下好的jdk源码在 Linux 在目录 usr/lib/jvm/openjd ...
- Spark Streaming、Kafka结合Spark JDBC External DataSouces处理案例
场景:使用Spark Streaming接收Kafka发送过来的数据与关系型数据库中的表进行相关的查询操作: Kafka发送过来的数据格式为:id.name.cityId,分隔符为tab zhangs ...
- Spark Streaming、HDFS结合Spark JDBC External DataSouces处理案例
场景:使用Spark Streaming接收HDFS上的文件数据与关系型数据库中的表进行相关的查询操作: 使用技术:Spark Streaming + Spark JDBC External Data ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- Spark SQL编程指南(Python)
前言 Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询.它的核心是一个特殊类型的Spark RDD:SchemaRDD. SchemaRDD类似于传统关 ...
- Spark SQL编程指南(Python)【转】
转自:http://www.cnblogs.com/yurunmiao/p/4685310.html 前言 Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询 ...
- 搭建Spark的单机版集群
一.创建用户 # useradd spark # passwd spark 二.下载软件 JDK,Scala,SBT,Maven 版本信息如下: JDK jdk-7u79-linux-x64.gz S ...
- spark on yarn 提交任务出错
Application ID is application_1481285758114_422243, trackingURL: http://***:4040Exception in thread ...
- Spark On Yarn中spark.yarn.jar属性的使用
今天在测试spark-sql运行在yarn上的过程中,无意间从日志中发现了一个问题: spark-sql --master yarn // :: INFO Client: Requesting a n ...
随机推荐
- day11:装饰器
1,引子,计算函数的运行时间: import time def func(): time.sleep(0.01) # 为了计算运行时间差的时候有值 print("func") de ...
- An optimizer that trains as fast as Adam and as good as SGD. https://www.luolc.com/publications/ad…
设立3个指针pa.pb和pc,其中pa和pb分别指向La表和Lb表中当前待比较插入的结点,而pc指向Lc表中当前最后一个结点:若pa->data<=pb->data,则将pa所指结点 ...
- ORA-01950: no privileges on tablespace XXX
原因是该表空间没有为用户提供配额空间 alter user WANGGUAN quota unlimited on TS_ACCT_DAT_01; 在表空间中为该用户设置磁盘配额即可
- elastic客户端TransportClient的使用
关于TransportClient,elastic计划在Elasticsearch 7.0中弃用TransportClient,并在8.0中完全删除它.后面,应该使用Java高级REST客户端,它执行 ...
- TZOJ:最大连续子序列
描述 给定K个整数的序列{ N1, N2, ..., NK },其任意连续子序列可表示为{ Ni, Ni+1, ..., Nj },其中 1 <= i <= j <= K.最大连续子 ...
- Python 标准输出 sys.stdout 重定向(转)
add by zhj: 其实很少使用sys.stdout,之前django的manage.py命令的源码中使用了sys.stdout和sys.stderr,所以专门查了一下 这两个命令与print的区 ...
- TensorFlow安装之后导入报错:libcudnn.so.6:cannot open sharedobject file: No such file or directory
转载自:http://blog.csdn.net/silent56_th/article/details/77587792 系统环境:Ubuntu16.04 + GTX1060 目的:配置一下pyth ...
- 8.0-uC/OS-III单任务应用
1.单任务应用 app.c文件: (1).APP_CFG.H 是用于配置的头文件.例如, APP_CFG.H 中包含的#define常量确定了任务优先级,堆栈大小,以及其他特性. BSP.H 是 BS ...
- 第八节:分支开发之合并到master
流程:在客户端创建分支,修改代码,并push,然后在页面处理即可.(区别在于一个在客户端,一个在页面) 实际的开放中要记得打tag,不然到时候出问题了以后不知道从哪里开始.
- laravel项目thinksns+安装pc前端页面
前面我们说了laravel项目ThinkSNS+安装,现在要安装给用户看的页面,方便他们进行一些操作,比如发表文字/提问之类,这个已经模块化了,用composer就可以完成.命令行代码如下(之前是co ...