【转载】Hadoop mapreduce 实现原理
1. 如何用通俗的方法解释MapReduce
MapReduce是Google开源的三大技术之一,是对海量数据进行“分而治之”计算框架。为了简单的理解并讲述给客户理解。我们举下面的例子来说明.
首先,面对一堆杂乱的东西,有若干个汉堡、若干个冰淇淋、若干个可乐。如果级别都是上万数量的情况下,有没有方法把他们较快的分析出来?

第一步,调度员简单的将这一堆东西分解成若干堆。

第二步,调度员为每堆物品分配一个分拣员,注意只分拣不计数,分拣员对应MAPReduce中的Map角色。分拣员干的事情,就是将物品按类别分拣,比如分拣后的每一堆的状态应该是如下图所示。分拣员所做的也分成简单,从自己面前这一堆物品中拿一个,看是面包的话,就扔面包那。是可乐就扔可乐那。

第三步,调度员为每类物品分配一个计数员(Reducer),把所有该类型的物品都发给他计数。比如所有的面包类别都分给第一个计数员来负责计数。计数员统计出每个类别的数目,再告诉调度员。

总结:Mapper用来分类,Reduce则用来对同类型的东西做进一步处理。对于互联网的应用场景,比如分析一个网页中出现的词汇最多的单词是什么。Mapper用来将网页中的文字段落分解成一个个单词。相同的单词会被送给同一个Reducer。Reducer会计算出该单词出现了多少次。最后按照各单词出现的次数得出结论。
2. 一个文本文件的处理过程
1)对应这样一个源文本文件

2)首先由调度员通过job.setInputFormatClass(TextInputFormat.class),知道应该转换成偏移量加文本方式的键-值对;再根据当前机器个数,文件大小确定应该分解成几个待处理的片段,比如说分解成两个片段,对应两个Map程序。

3)第一个Map程序每次被调用,接受到的入参(key,value)是

Map程序的输出是
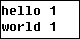
4)第二个Map程序接受的输入将是

第二个Map的输出将是

5)Map程序的输出,会被重新组合,同一个Key的内容,会被分配到同一个Reduce上。
比如上面三个单词,会被分到三个Reducer上
6)第一个Reducer接收到,如下图,注意是两个1,来自两个Map的结果

第一个Reducer的输出会是如下图,意味着hello这个单词出现了两次

7)第二个Reducer接收到

第二个Reducer输出会是

8)第三个Reducer接收到

第三个Reducer输出是

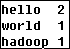
9)最后将三个Reducer进行合并,得到的结果就是
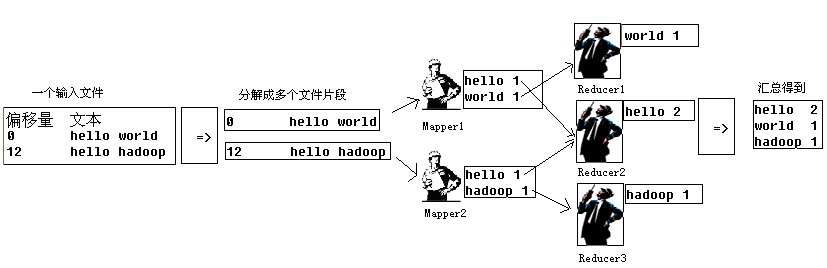
10)汇总流程描述如图所示
转载自
Hadoop的MapReduce实现原理解释
如侵删
【转载】Hadoop mapreduce 实现原理的更多相关文章
- [转载] Hadoop MapReduce
转载自http://blog.csdn.net/yfkiss/article/details/6387613和http://blog.csdn.net/yfkiss/article/details/6 ...
- Hadoop MapReduce工作原理
在学习Hadoop,慢慢的从使用到原理,逐层的深入吧 第一部分:MapReduce工作原理 MapReduce 角色 •Client :作业提交发起者. •JobTracker: 初始化作业,分配 ...
- 一图看懂hadoop MapReduce工作原理
MapReduce执行流程及单词统计WordCount示例
- [转载] MapReduce工作原理讲解
转载自http://www.aboutyun.com/thread-6723-1-1.html 有时候我们在用,但是却不知道为什么.就像苹果砸到我们头上,这或许已经是很自然的事情了,但是牛顿却发现了地 ...
- Hadoop化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- 一起学Hadoop——MapReduce原理
一致性Hash算法. Hash算法是为了保证数据均匀的分布,例如有3个桶,分别是0号桶,1号桶和2号桶:现在有12个球,怎么样才能让12个球平均分布到3个桶中呢?使用Hash算法的做法是,将1 ...
随机推荐
- AGC 016 F - Games on DAG(状压dp)
题意 给你一个有 \(n\) 个点 \(m\) 条边 DAG 图,点的标号和拓扑序一致. 现在有两个人进行博弈,有两个棋子分别在 \(1, 2\) 号点上,需要不断移动到它指向的点上. 如果当前两个点 ...
- 教你如何开启/关闭ubuntu防火墙
目录 [隐藏] 1 安装方法 2 使用方法 3 推荐设置 4 详细使用说明 安装方法 sudo apt-get install ufw 当然,这是有图形界面的(比较简陋),在新立得里搜索gufw试 ...
- MHN蜜罐系统建设
0x00 MHN蜜罐介绍 MHN(Modern Honey Network):开源蜜罐,简化蜜罐的部署,同时便于收集和统计蜜罐的数据.用ThreatStream来部署,数据存储在MOngoDB中,安 ...
- 【洛谷P4113】采花 HH的项链+
题目大意:静态统计序列区间中出现次数大于等于 2 的颜色数. 题解:类似于HH的项链,只需将 i 和 pre[i] 的关系对应到 pre[i] 和 pre[pre[i]] 的关系即可. 代码如下 #i ...
- .net Forms身份验证不能用在应用的分布式部署中吗?
参照网上的一些方法,使用Forms身份验证对应用进行分布式部署,发现没有成功. 应用部署的两台内网服务器:192.168.1.19,192.168.1.87,使用Nginx做负载分配,配置完全相同:每 ...
- JAVA中String.format()的使用
String类的format()方法用于创建格式化的字符串以及连接多个字符串对象.format()方法有两种重载形式:1.format(String format, Object... args) 新 ...
- 右值引用&&
以下内容参考https://blog.csdn.net/china_jeffery/article/details/78520237 右值引用若不作为函数参数使用,基本等于滥用 右值引用 (Rvalu ...
- Spark进阶之路-Standalone模式搭建
Spark进阶之路-Standalone模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark的集群的准备环境 1>.master节点信息(s101) 2&g ...
- 系统自带的日志管理工具-rsyslogd
系统自带的日志管理工具-rsyslogd 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.日志管理简介 1.什么是日志 系统日志是记录系统中硬件.软件和系统问题的信息,同时还可以 ...
- Kafka记录-Kafka简介与单机部署测试
1.Kafka简介 kafka-分布式发布-订阅消息系统,开发语言-Scala,协议-仿AMQP,不支持事务,支持集群,支持负载均衡,支持zk动态扩容 2.Kafka的架构组件 1.话题(Topic) ...