Python爬虫基础之认识爬虫
一、前言
爬虫Spider什么的,老早就听别人说过,感觉挺高大上的东西,爬网页,爬链接~~~dos黑屏的数据刷刷刷不断地往上冒,看着就爽,漂亮的校花照片,音乐网站的歌曲,笑话、段子应有尽有,全部都过来~~~
前段时间在学习Python打基础,一周时间过去了,是时候要开始写点东西了,Python爬虫刚好可验证下这段时间的学习成果,写写博文记录下自己学习爬虫的经过和遇到的坑,希望对同样是小白的园友有帮助!!!
我用的Python 3.5版本,2.7版本用的人也挺多的。
那么,接下来,我们要搞清楚几个问题:爬虫是什么东西?爬虫可以用来做什么?开发爬虫前需要掌握什么?
二、爬虫是什么东西
百度百科这么定义爬虫:

这里有几个关键词"规则","自动","万维网","程序"或者"脚本",理解了这几个关键词估计对爬虫就有个大体上的认识了。
接下来,会对这几个关键词就行解释.
三、爬虫从哪里爬取数据
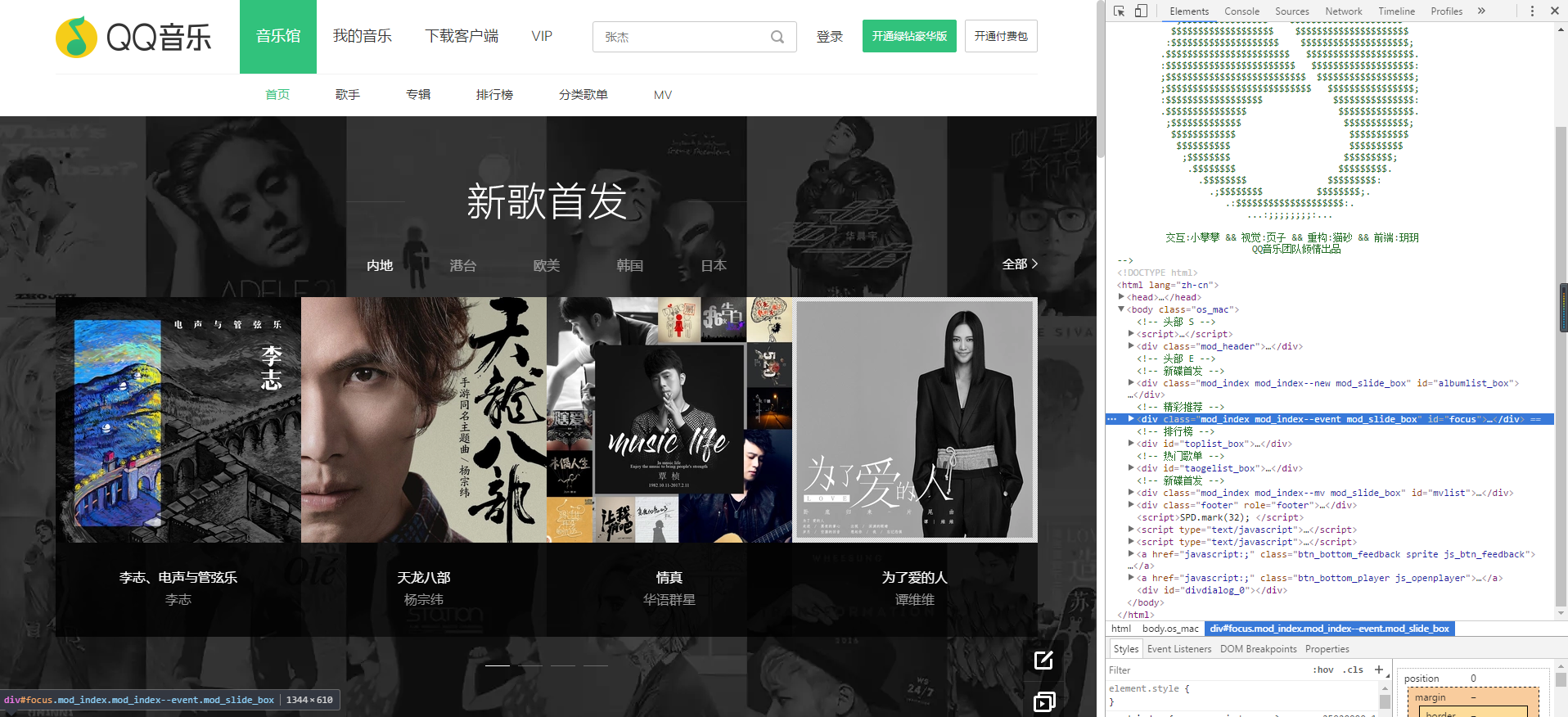
浏览器输入QQ音乐首页的网址:https://y.qq.com/,展现在我们面前的是浏览器解析器后的样子,敲击F12后,我们可以看到网页的源码,都是由一些html标签(标签我们这里用"节点"表示吧)构成。
所有网页的源码结构主要长的是这个样子:
<html>
<head>
<title>title name</title>
</head>
<body>
page content
</body>
</html>
关键词"万维网"?最简单的理解,万维网就是千千万万台电脑相互连接形成的像蜘蛛网一样的东西,我们的爬虫就是在这张网上干活,从网页上爬取信息。
关键词"规则"?这就是爬虫需要遵守的规则,<html>节点是<head>和<body>的父节点,<head>和<body>是子节点, 父节点包含子节点,子节点相邻的节点是兄弟节点,<title>是<html>的子孙节点,
这就构成了HTML DOM(文档对象模型),简单地说,爬虫就是爬取这些节点的内容,例如图片,文本等。。
关键词"自动"和"程序"或者"脚本"?可以理解成非人工的方式,也就是编写代码的方式,通过程序或者一段脚本(我们这里用Python脚本),自动按着我们预设的意愿工作,爬取我们认为有价值的信息,满足我们对信息的需求。
四、我的爬虫知识储备
HTML + CSS + Javascript
掌握一些HTML静态网页的知识,CSS样式,ID,标签,类选择器,还有Javascript如何定位和操作页面上的元素,w3school的教程,有教程和实例,还可以用来调试代码脚本,新手入门和知识查阅十分方便。网页解析方面,后面我们会用到正则表达式、BeautifulSoup和Lxml三种方式。
HTTP协议
具备一些网络方面的知识,了解浏览器和服务器之间的交互,如何发送http请求和处理请求结果。网页请求和下载网页,后面我们会用到Python的库urllib
Python
我们的脚本语言,这个自然不用说,必须掌握,入门推荐 runoob.com,Python基础 和 Python 3
掌握了以上知识,我们就可以开始实战了!!!
Python爬虫基础之认识爬虫的更多相关文章
- python爬虫基础16-cookie在爬虫中的应用
Cookie的Python爬虫应用 Cookie是什么 Cookie,有时也用其复数形式 Cookies,英文是饼干的意思.指某些网站为了辨别用户身份.进行 session 跟踪而储存在用户本地终端上 ...
- Python开发基础-Day15正则表达式爬虫应用,configparser模块和subprocess模块
正则表达式爬虫应用(校花网) import requests import re import json #定义函数返回网页的字符串信息 def getPage_str(url): page_stri ...
- python基础整理6——爬虫基础知识点
爬虫基础 什么是爬虫: 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁. ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- Python爬虫入门:爬虫基础了解
有粉丝私信我想让我出更基础一些的,我就把之前平台的copy下来了,可以粗略看一下,之后都会慢慢出. 1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫 ...
- python 3.x 爬虫基础---Urllib详解
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 前言 爬虫也了解了一段时间了希望在半个月的时间内 ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
随机推荐
- iOS开发基础-九宫格坐标(6)
继续对iOS开发基础-九宫格坐标(5)中的代码进行优化. 优化思路:把字典转模型部分的数据处理操作也拿到模型类中去实现,即将 ViewController 类实现中 apps 方法搬到 WJQAppI ...
- iOS开发基础-图片切换(3)之属性列表
延续:iOS开发基础-图片切换(2),对(2)里面的代码用属性列表plist进行改善. 新建 Property List 命名为 Data 获得一个后缀为 .plist 的文件. 按如图修改刚创建的文 ...
- spring @CrossOrigin解决跨域问题
阅读目录: 一.跨域(CORS)支持: 二.使用方法: 1.controller配置CORS 2.全局CORS配置 3.XML命名空间 4.How does it work? 5.基于过滤器的CORS ...
- ABP大型项目实战(2) - 调试与排错 - 日志 - 查看审计日志
这是<ABP大型项目实战>系列文章的一篇. 项目发布到生产环境后难免会有错误. 那么如何进行调试和排错呢? 我看到俱乐部里有人是直接登陆生产服务器把数据库下载到开发机器进行调试排错 ...
- Merge Sort(Java)
public static void main(String[] args) { Scanner input = new Scanner(System.in); int n = input.nextI ...
- Messenger更改系统语言以后无法登陆,提示“初始设置被修改”
在安装messenger机器上使用SQL management studio打开数据库,链接YCD的数据库,找到dbo.Dic_Defaults的表,编辑打开以后找到“CultureInfo”两项,删 ...
- 【ubuntu】Ubuntu 修改 Apache2 运行用户/用户组及修改方法
我们在安装apache后,有时在上传文件的时候,提示没有权限或者是不可写,我们都会去查文件夹的权限.通过ls -l /var/www/html/website可以很直观的看出我们文件和文件夹的权限,d ...
- CSS3文字、背景与列表
一.文本相关属性 1.字体 (1)字体设置 在HTML中,字体通过<font face="字体名称">来设置.在CSS中字体通过font-family属性来控制,里面可 ...
- Python pip Unable--
It is possible that pip does not get installed by default. One potential fix is: python -m ensurepip ...
- ML.NET is an open source and cross-platform machine learning framework
https://www.microsoft.com/net/learn/apps/machine-learning-and-ai/ml-dotnet Machine Learning made for ...