Lucene 05 - 使用Lucene的Java API实现分页查询
1 Lucene的分页查询
搜索内容过多时, 需要考虑分页显示, 像这样:

说明: Lucene的分页查询是在内存中实现的.
2 代码示例
/**
* 检索索引(实现分页)
* @throws Exception
*/
@Test
public void searchIndexByPage() throws Exception {
// 1. 创建分析器对象(Analyzer), 用于分词
// Analyzer analyzer = new StandardAnalyzer();
// 使用ik中文分词器
Analyzer analyzer = new IKAnalyzer();
// 2. 创建查询对象(Query)
// bookName:lucene
// 2.1 创建查询解析器对象
// 参数一: 指定一个默认的搜索域
// 参数二: 分析器
QueryParser queryParser = new QueryParser("bookName", analyzer);
// 2.2 使用查询解析器对象, 实例化Query对象
// 参数: 查询表达式
Query query = queryParser.parse("bookName:lucene");
// 3. 创建索引库目录位置对象(Directory), 指定索引库的位置
Directory directory = FSDirectory.open(new File("/Users/healchow/Documents/index"));
// 4. 创建索引读取对象(IndexReader), 用于读取索引
IndexReader reader = DirectoryReader.open(directory);
// 5. 创建索引搜索对象(IndexSearcher), 用于执行搜索
IndexSearcher searcher = new IndexSearcher(reader);
// 6. 使用IndexSearcher对象, 执行搜索, 返回搜索结果集TopDocs
// search方法: 执行搜索
// 参数一: 查询对象
// 参数二: n - 指定返回排序以后的搜索结果的前n个
TopDocs topDocs = searcher.search(query, 10);
// 7. 处理结果集
// 7.1 打印实际查询到的结果数量
System.out.println("实际查询的结果数量: "+topDocs.totalHits);
// 7.2获取搜索的结果数组
// ScoreDoc中: 有我们需要的文档的id, 有我们需要的文档的评分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
// 增加分页实现 ========= start
// 当前页
int page = 2;
// 每页的大小
int pageSize = 2;
// 计算记录起始数
int start = (page - 1) * pageSize;
// 计算记录终止数 -- 得到数据索引与实际结果数量中的最小值, 防止数组越界
// 数据索引: start + pageSize
// 实际的结果数量: scoreDocs.length
int end = Math.min(start + pageSize, scoreDocs.length);
// 增加分页实现 ========= end
for(int i = start; i < end; i++){
System.out.println("= = = = = = = = = = = = = = = = = = =");
// 获取文档Id和评分
int docId = scoreDocs[i].doc;
float score =scoreDocs[i].score;
System.out.println("文档Id: " + docId + " , 文档评分: " + score);
// 根据文档Id, 查询文档数据 -- 相当于关系数据库中根据主键Id查询
Document doc = searcher.doc(docId);
System.out.println("图书Id: " + doc.get("bookId"));
System.out.println("图书名称: " + doc.get("bookName"));
System.out.println("图书价格: " + doc.get("bookPrice"));
System.out.println("图书图片: " + doc.get("bookPic"));
System.out.println("图书描述: " + doc.get("bookDesc"));
}
// 8. 释放资源
reader.close();
}
3 分页查询结果
这里查询到的结果共有3条, 所以第2页只有一条结果:
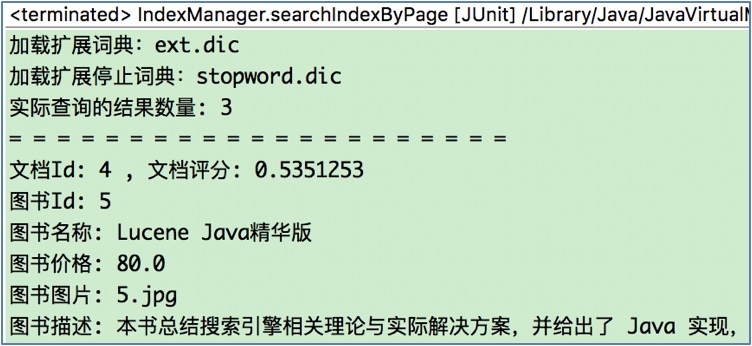
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Lucene 05 - 使用Lucene的Java API实现分页查询的更多相关文章
- HDFS 05 - HDFS 常用的 Java API 操作
目录 0 - 配置 Hadoop 环境(Windows系统) 1 - 导入 Maven 依赖 2 - 常用类介绍 3 - 常见 API 操作 3.1 获取文件系统(重要) 3.2 创建目录.写入文件 ...
- ElasticSearch AggregationBuilders java api常用聚会查询
以球员信息为例,player索引的player type包含5个字段,姓名,年龄,薪水,球队,场上位置.index的mapping为: "mappings": { "pl ...
- 【java】在分页查询结果中对最后的结果集List进行操作add()或remove()操作,报错:java.lang.UnsupportedOperationException
场景: 在分页查询结果中对最后的结果集List进行操作add()或remove()操作,报错:java.lang.UnsupportedOperationException 错误: java.lang ...
- Java GUI+mysql+分页查询
1.要求 : 创建一个学生信息管理数据库 2.实现分页查询 代码如下: a)学生实体类: /** * @author: Annie * @date:2016年6月23日 * @description: ...
- Java基础94 分页查询(以MySQL数据库为例)
1.概述 分页查询,也可叫做分批查询,基于数据库的分页语句(不同数据库是不同的). 本文使用的事MySql数据库. 假设:每页显示10条数据. Select * from c ...
- java开发之分页查询
工具类 package com.luer.comm.utils; import java.util.List; public class PageBean<T> { //已知数据 priv ...
- Elasticsearch Java API—多条件查询(must)
多条件设置 //多条件设置 MatchPhraseQueryBuilder mpq1 = QueryBuilders .matchPhraseQuery("pointid",&qu ...
- [ElasticSearch]Java API 之 词条查询(Term Level Query)
1. 词条查询(Term Query) 词条查询是ElasticSearch的一个简单查询.它仅匹配在给定字段中含有该词条的文档,而且是确切的.未经分析的词条.term 查询 会查找我们设定的准确值 ...
- Dynamics CRM2016 Web Api之分页查询
在dynamics crm web api还没出现前,我们是通过fetchxml来实现的,当然这种方式依旧可行,那既然web api来了我们就拥抱新的方式. web api中我们通过指定查询的条数来实 ...
随机推荐
- [sublime] 利用sublime搭建C/C++编译器
gcc/g++配置 先去下载TDM-GCC安装包,这里附下载地址(可能会有弹出界面,不用管他). 现在c盘中建立文件夹 g++,然后以管理员运行,点击Create傻瓜式安装, 这里要改一下安装路径,保 ...
- Java 博客导航
Java 博客导航 一.基础知识 Java 基础知识 Java 常用知识点 Java 多线程 Java 正则使用 Java IO Java 集合
- 源自于NEO的KeyValue 数据库面世啦
虽然想把标题取得大一点,但终究不是什么太大不了的工作,还是安分守己的开始介绍吧. 项目组成 这个项目叫做LightDB 由三个部分构成 Lightdb.lib 是对rocksdb做了一层封装, ...
- go语言数据库操作,xorm框架
待续............................................... 连接数据库 db, err := xorm.NewEngine("mysql", ...
- BZOJ 3864
dp of dp 我就是来贴个代码 #include<bits/stdc++.h> using namespace std; #define rep(i,a,b) for(int i=(a ...
- Largest Rectangle in a Histogram [POJ2559] [单调栈]
题意一个围挡由n个宽度为1的长方形挡板下端对齐后得到,每个长方形挡板的高度为hi.我们把其抽象成一个图形,问这个图形中包含的面积最大的长方形是多大? 输入多行数据,每行第一个为n,后面n个数,代表hi ...
- JUC
1.Java JUC简介 在Java5.0提供了java.util.concurrent(简称JUC)包,在此包中增加了在并发编程中很常用的实用工具类,用于定义类似于线程的自定义子系统,包括线程池.异 ...
- async与defer
<script>元素的几种常见属性: async 异步加载,立即下载,不应妨碍页面其他操作,标记为 async 的异步脚本并不保证按照指定的先后顺序执行,因此异步脚本不应该在加载期间修改 ...
- 2.Git配置和关联GitHub
1.配置本地信息, 右键Git Bush Here git config –global user.name '账号名' ##回车 git config –global user.email 邮箱 # ...
- Spring源码学习-容器BeanFactory(三) BeanDefinition的创建-解析Spring的默认标签
写在前面 上文Spring源码学习-容器BeanFactory(二) BeanDefinition的创建-解析前BeanDefinition的前置操作中Spring对XML解析后创建了对应的Docum ...