django - 总结
0、html-socket
import socket def handle_request(client):
request_data = client.recv(1024)
print("request_data: ", request_data)
client.send("HTTP/1.1 200 OK\r\nstatus: 200\r\nContent-Type:text/html\r\n\r\n".encode("utf8"))
client.send("<h1>Hello, luffycity!</h1><img src=''>".encode("utf8")) def main():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(('localhost', 8812))
sock.listen(5)
while True:
print("the server is waiting for client-connection....")
connection, address = sock.accept()
handle_request(connection)
connection.close() if __name__ == '__main__':
main()
常用命令
pip3 install django==2.0. 下载django
django-admin.py startproject name 创建项目名字
python manage.py startapp name 创建应用名字
python manage.py runserver 启动项目
1、wsgiref
from wsgiref.simple_server import make_server
def application(environ, start_response):
# 按着http协议解析数据:environ
# 按者http协议组装数据:start_response
start_response('200 OK', [('Content-Type', 'text/html'), ("Charset", "utf8")])
# 当前请求路径
path = environ.get("PATH_INFO")
if path == "/favicon.ico":
with open("favicon.ico", "rb") as f:
data = f.read()
return [data] # 封装socket() 更加方便我们获取path,environ包含请求信息的字典
httpd = make_server('', 9988, application)
# 开始监听HTTP请求:
httpd.serve_forever()
2、别名
STATIC_URL = '/static/' # 代指下面的绝对路径
STATICFILE_DIRS = [
os.path.join(BASE_DIR, "statics"),
]
3、 有名分组
path("^articles/(?P<year>[0-9]{4})", handler) #handler(request, year)
4、 路由分发
from django.urls import include
path("^blog", include("app01.urls"))
3 request.path # /blog/articles/2018
4 request.get_full_path # /blog/articles/2018?a=2
5、 反向解析
path("^blog/(\d*)", views.login, name="Log")
action = "{% url 'Log' 56 %}" # html使用后端的别名
from django.urls import reverse
url = reverse("Log", args=(4029,))
# 全局找完,找局部
# 通过别名在urlpatterns获取匹配的url,
# 4029替换正则表达式,---># blog/56
6、 名称空间
多个应用下的url别名重复 include() 放一个元组 路径,名称空间
# 后者会覆盖前者
url(r'^app01/', include(("app01.urls","app01"))),
url(r'^app02/', include(("app02.urls","app02"))), app01.urls:
urlpatterns = [
url(r'^index/', views.index,name="index"),
] app02.urls:
urlpatterns = [
url(r'^index/', views.index,name="index"),
] 16 reverse("app01:index")
{% url "app01:index" 123 435%}
7、path param类型转换
# 自定义方法:
class MonConvert:
regex = '[0-9]{2}' #
def to_python(self, value): # value 是由regex匹配到的字符串,返回具体的变量值,让django传递到视图函数中
return int(value)
def to_url(self, value): #和to_python相反,value是一个具体的Python变量值,返回其字符串,通常用于url反向引用。
# 反向解析
return "%04d"value
# 注册转换器
from django.urls import register_converter register_converter(MonConvert, "my_convert")
path("^blog/<my_convert:year>", views.handler)
内置转化器
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符
8、 模板语法 {{}} {% %} ------->html替换
渲染变量: {{ }} locals()
过滤器
{{ value | filter_name:参数 }}
default:"Nothing" # 若果变量为空或者空,使用默认值
length # 字符串列表长度
filesizeformat # 文件大小
date:"Y-m-d" # datetime.datetime.now()
slice:"2:-1"
truncatechars:20 # 截断字符
truncatewords:6 # 截断单词
upper # 大写
lower # 小写
add:10 # 加10
safe # 渲染标签
标签: {% %} 逻辑控制
--------------------------------------------
{% for i in [] reversed %} # 反向循环
{%forloop.counter0%} # 序号从0开始
......
{% empty %} # 如果为空,显示下边
......
{% endfor%}
--------------------------------------------
{% if param %}
......
{% elif param %}
......
{% endif %}
--------------------------------------------
{% with param=*******************%}
#{% with ******************* as param%}
{{ param }}
{%endwith%}
--------------------------------------------
{% url "别名" %} 在form表单提交数据地址使用
--------------------------------------------
{% cerf_token %} # CSRF 跨站请求伪造
# 当form表单包含再提交数据时,跳过CSRF检测
render会包含一个隐藏的input标签,有身份证号
--------------------------------------------
++++++++++++++++++++++++++++++++
自定义过滤器|标签
1、在settings中的INSTALLED_APP配置当前app,不然找不到自定义的过滤器
2、在app中创建templatetags文件(只能是这个名字)
3、创建****.py文件
from django import template
from django.utils.safestring import mark_safe
register = template.Library() #register的名字是固定的,不可改变
@register.filter 过滤器
def multi(x,y):
return x*y
@register.simple_tag 标签
def multitag(x,y,z):
return x*y*z
@register.simple_tag 标签
def my_input(id,arg):
result = "<input type='text' id='%s' class='%s' />" %(id,arg,)
return mark_safe(result)
4、在使用自定义simple_tag和filter的html中导入之前创建的****.py文件
{% load **** %}
5、如何调用
{{ i|my_filter:10 }} # 过滤器最多俩参数
{% if i|my_filter:10 >100 %} # 用于流程控制判断
{% my_tag 7 8 %} # 标签参数不限,没有返回值
++++++++++++++++++++++++++++++++
继承标签
{% include "****.html" %} # 导入***html
# 继承base.html放在首行 {% block custom_ %} 。。。 {% endblock %}
{% extends "base.html" %}
1、重写custom_盒子
{% block custom_ %}
。。。
{% endblock %}
2、重写custom_盒子,且保留原有内容
{% block custom_ %}
{{ block.super }}
。。。
{% endblock custom_ %} # custom_增加可读性,可不加
9、orm
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'orm', #你的数据库名称
'USER': 'root', #你的数据库用户名
'PASSWORD': '', #你的数据库密码
'HOST': '', #你的数据库主机,留空默认为localhost
'PORT': '', #你的数据库端口
}
}
项目下__init__
import pymysql
pymysql.install_as_MySQLdb()
显示sql语句
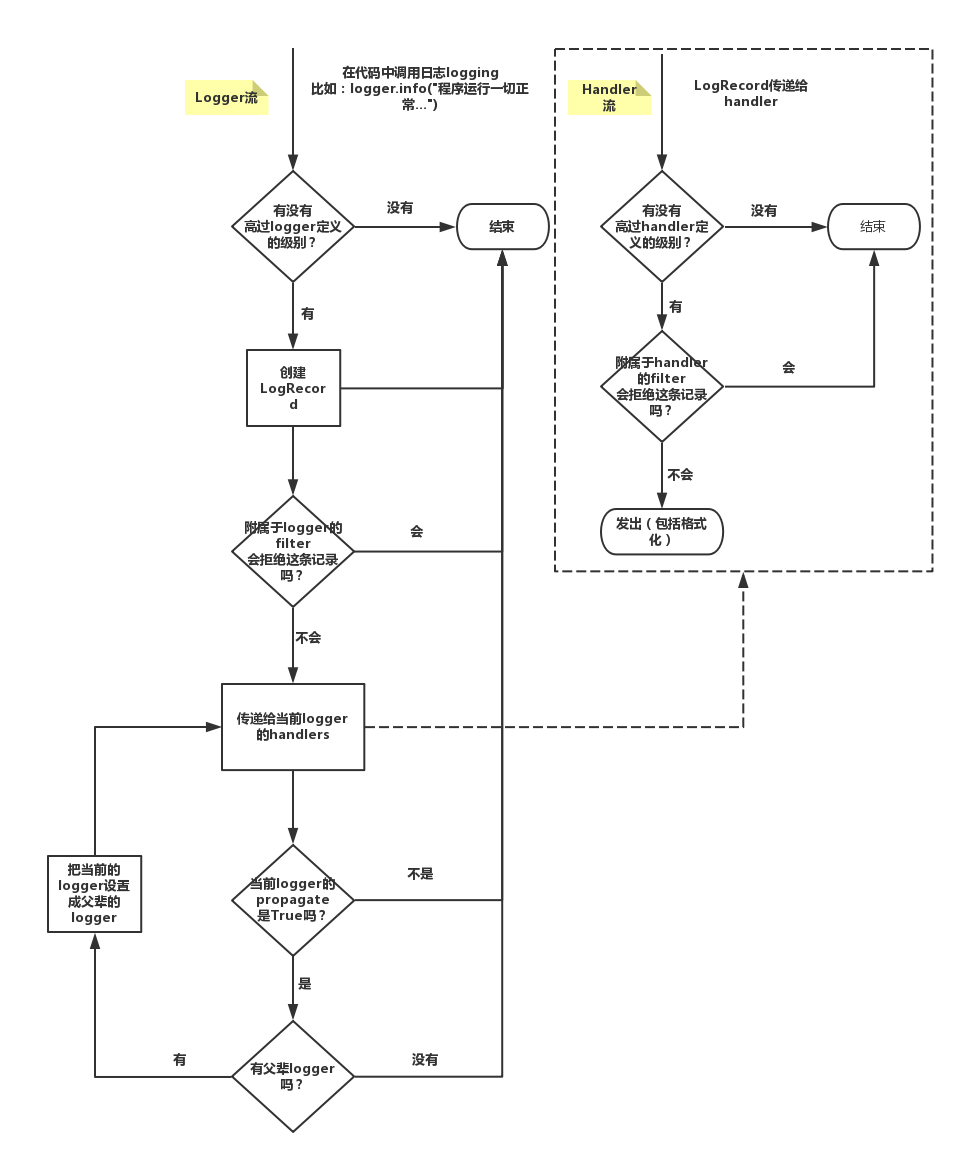
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
# django 的日志配置项
BASE_LOG_DIR = os.path.join(BASE_DIR,'log')
LOGGING = {
'version': 1, # 保留字
'disable_existing_loggers': False, # 禁用已经存在的 logger 实例
'formatters': {
# 详细的日志格式
'standard': {
'format': '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'
'[%(levelname)s][%(message)s]'
},
# 简单的日志格式
'simple': {
'format': '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
},
# 定义一个特殊的日志格式
'collect': {
'format': '%(message)s'
}
},
# 过滤器
'filters': {
# DEBUG = True 的情况 才过滤
'require_debug_true': {
'()': 'django.utils.log.RequireDebugTrue',
},
},
# 处理器
'handlers': {
# 在终端打印
'console': {
'level': 'DEBUG',
'filters': ['require_debug_true'], # 只有在Django debug为True时才在屏幕打印日志
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
# 默认
'default': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_info.log"), # 日志文件
'maxBytes': 1024 * 1024 * 50, # 日志大小 50M 一般配500M
'backupCount': 3, # 最多备份3个
'formatter': 'standard',
'encoding': 'utf-8',
},
# 专门用来记 错误日志
'error': {
'level': 'ERROR',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_err.log"), # 日志文件
'maxBytes': 1024 * 1024 * 50, # 日志大小 50M
'backupCount': 5,
'formatter': 'standard',
'encoding': 'utf-8',
},
# 专门 定义一个 收集特定信息的日志
'collect': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_collect.log"),
'maxBytes': 1024 * 1024 * 50, # 日志大小 50M
'backupCount': 5,
'formatter': 'collect',
'encoding': "utf-8"
}
},
'loggers': {
# 默认的logger应用如下配置
'': {
'handlers': ['default', 'console', 'error'], # 上线之后可以把'console'移除
'level': 'DEBUG',
'propagate': True, # 向不向更高级别的logger传递
},
# 名为 'collect'的logger还单独处理
'collect': {
'handlers': ['console', 'collect'],
'level': 'INFO',
}
},
}
LOGGING完整版
from django.shortcuts import render,HttpResponse # Create your views here. import logging
# 生成一个以当前文件名为名字的logger实例
logger = logging.getLogger(__name__)
collect_logger = logging.getLogger('collect') # 生成一个名为collect的实例 def index(requset):
logger.debug('一个debug萌萌的请求...')
logger.info('一个info萌萌的请求...')
'''
这是视图函数index的doc信息
:param requset:
:return:
'''
print('@'*120)
print('这是app01里面的index函数')
# print(requset.s9) # raise ValueError('hehe,抛异常') # return HttpResponse('OK') rep = HttpResponse('OK')
collect_logger.info('这是collect_logger日志')
collect_logger.info('hello:collect') # def render():
# return HttpResponse('不常用')
#
# rep.render = render
return rep views
view.py
INSTALLED_APPS 要有对应的应用名
创建脚本:python manage.py makemigrations
同步数据库: python manage.py migrate
APPEND_SLASH=True 是否会自动重定向(默认)
在Python脚本中调用Django环境 import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "项目名.settings")
import django
django.setup() # 引用Django内部的变量
注意:python解释器>3.4 运行django2.0
报错 django.core.exceptions.ImproperlyConfigured: mysqlclient 1.3.3 or newer is required; you have 0.7.11.None
-->如果使用更高版本的解释器的话
C:\Programs\Python\Python36-32\Lib\site-packages\Django-2.0-py3.6.egg\django\db\backends\mysql 注释掉
if version < (1, 3, 3):
raise ImproperlyConfigured("mysqlclient 1.3.3 or newer is required;
you have %s" % Database.__version__)
10、单表查询
批量插入数据
Booklist=[]
for i in range(100):
Booklist.append(Book(title="book"+str(i),price=30+i*i))
Book.objects.bulk_create(Booklist)
------------------增加记录-------------------
1 # 添加表记录 方式1
2 book_obj = Book(id=1, title="Py", price=100, pub_date="2012-12-12", publish="人民")
3 book_obj.save()
4 # 添加表记录 方式2
5 book_obj=Book.objects.create(title="Py", price=100, pub_date="2012-12-12", publish="人民")
-------------------查找记录-------------------
Book.objects.all() # QuerySet [obj1,obj2,obj3,...]
Book.objects.all().last() # obj | all()[-1]
Book.objects.all().first() # obj | all()[0]
Book.objects.filter(id=1, title="py") # QuerySet [obj1,...]
Book.objects.get(id=2) # get 只能得到唯一的记录
Book.objects.exclude(**kwargs) # 所有条件不匹配的对象
Book.objects.order_by() # 默认按id升序, order_by("-id")
Book.objects.all().reverse() # 反向排序
Book.objects.all().count() # QuerySet 对象的数量
Book.objects.filter().exists() # QuerySet是否包含数据
Book.objects.filter().values() # [{},{},{}]
Book.objects.filter().values_list() # [(),(),()]
Book.objects.filter().values().distinct() # [{},{},{}]
-----------------模糊查询------------------------
Book.objects.filter(price__gt=100)
Book.objects.filter(price__lt=100)
Book.objects.filter(price__range=[100, 200])
Book.objects.filter(price__in=[100, 200, 300])
Book.objects.filter(title__contains="python")
Book.objects.filter(title__icontains="python") # 忽略大小写
Book.objects.filter(title__startswith="py")
Book.objects.filter(pub_date__year=2012)
Book.objects.filter(pub_date__month=8)
Book.objects.filter(pub_date__day=23)
Book.objects.filter(pub_date__week_day=5)
--------------------删除记录------------------
Book.objects.filter().delete() # QuerySet model对象 都可以用
--------------------修改记录------------------
Book.objects.filter(title__startswith="py").update(price=120)
---------------------------------------------
11、一对一
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
# 一对一
authordetail = models.OneToOneField(to="AuthorDetail", to_field="nid", on_delete=models.CASCADE)
def __str__(self):
return self.name
# 作者详情表
class AuthorDetail(models.Model):
nid = models.AutoField(primary_key=True)
birthday = models.DateField()
telephone = models.BigIntegerField()
addr = models.CharField(max_length=64)
12、一对多
class Book(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField(max_length=32)
publishDate = models.DateField()
price = models.DecimalField(max_digits=5, decimal_places=2)
# 一对多关系
publish = models.ForeignKey(to="Publish", to_field="nid", on_delete=models.CASCADE, )# 级联删除
'''
publish_id INT ,
FOREIGN KEY (publish_id) REFERENCES publish(id) '''
往Auther插数据
book_obj=Book.objects.create(title="红楼梦",price=100,publishDate="2012-12-12",publish_id=1)
或者
book_obj=Book.objects.create(title="三国演绎",price=100,publishDate="2012-12-12",publish=pub_obj)
# 实际是publish===>publish_id 1=pub_obj.nid 替换
不管以哪种方式添加数据book_obj.publish都是相对应的那个书对象
13、多对多
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
# 一对一
authordetail = models.OneToOneField(to="AuthorDetail", to_field="nid",
on_delete=models.CASCADE)
def __str__(self):
return self.name class Book(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField(max_length=32)
publishDate = models.DateField()
price = models.DecimalField(max_digits=5, decimal_places=2)
# 多对多
authors = models.ManyToManyField(to="Author")
'''
CREATE TABLE book_authors(
id INT PRIMARY KEY auto_increment ,
book_id INT ,
author_id INT ,
FOREIGN KEY (book_id) REFERENCES book(id),
FOREIGN KEY (author_id) REFERENCES author(id)
)
'''
def __str__(self):
return self.title
1:第三张表添加数据
book_obj=Book.objects.create(title="瓶梅",price=100,publishDate="2012-12-12",publish_id=1)
book_obj.authors.add(1, 2, 3) # 添加了 (6,1)(6,2)(6,3)3条记录
book_obj.authors # book_obj对应的所有author对象集合 QuerySet
book_obj.authors.set([]) #
2:第三张表解除数据
book_obj.authors.remove(1, 2, 3) # 删除了 (6,1)(6,2)(6,3)3条记录 *【】
book_obj.authors.clear() # 删除了所有记录
-----跨表查询-------
1 基于对象查询 ------------->子查询
一对多
# 正向查询 ---靠字段
----------------查找”瓶梅“对应的出版社------------------------------
Book (publish) ------------->Publish
book_obj = Book.objects.filter(title="瓶梅").first()
print(book_obj.publish.name)
# 反向查询 ---靠表名小写_set
----------------查找人民出版社出版的瓶梅对应的书-----------------------
publish_obj = Publish.objects.filter(name="人民出版社").first()
book_list = publish_obj.Book_set.filter(title="瓶梅").values("title")
多对多
# 正向查询 ---靠字段
# 反向查询 ---靠表名小写_set 查询结果都是QuerySet
通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name
的值来覆写 FOO_set 的名称。
tags = models.ManyToManyField( # 手动创建第三张表
to="Tag",
through='Article2Tag',
through_fields=('article', 'tag'),
)
class Article2Tag(models.Model):
nid = models.AutoField(primary_key=True)
article = models.ForeignKey(verbose_name='文章', to="Article", to_field='nid', on_delete=models.CASCADE)
tag = models.ForeignKey(verbose_name='标签', to="Tag", to_field='nid', on_delete=models.CASCADE) class Meta:
unique_together = [
('article', 'tag'),
] def __str__(self):
v = self.article.title + "---" + self.tag.title
return v
一对一
# 正向查询 ---靠字段
# 反向查询 ---靠表名小写 查询结果都是一个model对象 ->一对一的关系嘛
例:翻译成sql语句
select publish_id from Book where title="平媒"
select name from Publish where id=1
2 基于双下划线查询 ------------->join查询
filter ---对应where values ---对应字段
# 正向查询 ---靠字段
ret = Author.objects.filter(name="alex").values("authordetail__telephone")
# 反向查询 ---靠表名小写来告诉ORM引擎join那张表
ret = AuthorDetail.objects.filter(author__name="alex").values("telephone")
练习:
手机号以110开头的作者出版过的所有书籍名称以及出版社名称
#方式一
# 需求: 通过Book表join AuthorDetail表,Book与AuthorDetail无关联,所以必须连续跨表
ret = Book.objects.filter(authors__authordetail__telephone__startswith="").values("title","publish__name")
# 方式二
ret = Author.objects.filter(authordetail__telephone__startswith="").values("book__title",)
3 聚合和分组查询
# 聚合函数 aggregate
from django.db.models import Max, Min, Avg, Count
ret= Book.objects.all().aggregate(自定义键值=Avg("price"),max_price=Max("price")) # 分组查询 annotate
#----------单表查询-----------
# 单表模型.objects.values("group by的字段").annotate(avg_salary=Avg("salary"))
# 结果:<QuerySet [{"avg_salary":***,"group by的字段":****}]>
# 注意:在单表分组下,按着主键进行group by 是没有任何意义的。
#-----------多表查询-----------
# 查询每一个出版社的名称以及出版的书籍个数
# 方式一
ret = Publish.objects.values("name").annotate(Count("book__title"))
# 方式二
ret = Publish.objects.values("nid").annotate(c=Count("book__title")).values("name","c")
# 查询每一个作者的名字以及出版过的书籍的最高价格
ret = Author.objects.values("nid").annotate(max_price=Max("book__price")).values("name","max_price")
# "每一个"表模型.objects.values("nid").annotate(聚合函数(关联表统计字段)).values(任意表里的字段)
# 统计不止一个作者的图书
ret = Book.objects.values("pk").annotate(c=Count("authors__name")).filter(c__gt=1).values("title", "c")
4 F与Q查询
from django.db.models import F,Q
# F 当涉及字段值时
Book.objects.filter(comment_num__gt=F("read_num"))
Book.objects.all().update(price=F("price")+10)
# Q 更复杂的查询
Book.objects.filter(Q(title="红楼梦")|Q(price=100)) # 或
Book.objects.filter(Q(title="红楼梦")&Q(price=100)) # 且
用来解决OR查询操作的
.filter(Q(id=) | Q(id=))
.filter(Q(id=) & Q(id=)) class Q(tree.Node):
# Connection types
AND = 'AND'
OR = 'OR'
default = AND def __init__(self, *args, **kwargs):
super(Q, self).__init__(children=list(args) + kwargs.items()) def _combine(self, other, conn):
if not isinstance(other, Q):
raise TypeError(other)
obj = type(self)()
obj.add(self, conn)
obj.add(other, conn)
return obj def __or__(self, other):
return self._combine(other, self.OR) def __and__(self, other):
return self._combine(other, self.AND) def __invert__(self):
obj = type(self)()
obj.add(self, self.AND)
obj.negate()
return obj 传Q对象,构造搜索条件
首先还是需要导入模块: from django.db.models import Q
传入条件进行查询:
q1 = Q()
q1.connector = 'OR'
q1.children.append(('id', ))
q1.children.append(('id', ))
q1.children.append(('id', )) models.Tb1.objects.filter(q1)
合并条件进行查询:
con = Q() q1 = Q()
q1.connector = 'OR'
q1.children.append(('id', ))
q1.children.append(('id', )) q2 = Q()
q2.connector = 'OR'
q2.children.append(('status', '在线')) con.add(q1, 'AND')
con.add(q2, 'AND') models.Tb1.objects.filter(con)
14、ORM事务 ()原子
try:
from django.db import transaction
with transaction.atomic():
new_publisher = models.Publisher.objects.create(name="新华出版社CCC")
new_book = models.Book.objects.create(titl="新华字典CCC", price=3.5, publisher=new_publisher)
except Exception as e:
print(str(e))
15、request属性
request.GET
一个类似于字典的对象,包含 HTTP GET 的所有参数。 request.POST
一个类似于字典的对象,包含表单数据。
如果使用 POST 上传文件的话,文件信息将包含在 FILES 属性中。
注意:键值对的值是多个的时候,比如checkbox类型的input标签,select标签,
需要用:request.POST.getlist("hobby") Request.FILES
一个类似于字典的对象,包含所有的上传文件信息。
FILES 中的每个键为<input type="file" name="" /> 中的name,值则为对应的数据。
注意,FILES 只有在请求的方法为POST 且提交的<form> 带有enctype="multipart/form-data" 情况下
才会包含数据。否则,FILES 将为一个空的类似于字典的对象。
request.body
一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用. request.path
一个字符串,表示请求的路径组件(不含域名) request.method
一个字符串,表示请求使用的HTTP 方法。
Request.encoding 一个字符串,表示提交的数据的编码方式(如果为None则表示使用 DEFAULT_CHARSET 的设置,默认'utf-8')
这个属性是可写的,你可以修改它来修改访问表单数据使用的编码。
接下来对属性的任何访问(例如从 GET 或 POST 中读取数据)将使用新的 encoding 值。
如果你知道表单数据的编码不是 DEFAULT_CHARSET ,则使用它。 Request.META 一个标准的Python 字典包含所有的HTTP 首部具体的头部信息取决于客户端和服务器,下面是一些示例 CONTENT_LENGTH —— 请求的正文的长度(是一个字符串)。
CONTENT_TYPE —— 请求的正文的MIME 类型。
HTTP_ACCEPT —— 响应可接收的Content-Type。
HTTP_ACCEPT_ENCODING —— 响应可接收的编码。
HTTP_ACCEPT_LANGUAGE —— 响应可接收的语言。
HTTP_HOST —— 客服端发送的HTTP Host 头部。
HTTP_REFERER —— Referring 页面。
HTTP_USER_AGENT —— 客户端的user-agent 字符串。
QUERY_STRING —— 单个字符串形式的查询字符串(未解析过的形式)。
REMOTE_ADDR —— 客户端的IP 地址。
REMOTE_HOST —— 客户端的主机名。
REMOTE_USER —— 服务器认证后的用户。
REQUEST_METHOD —— 一个字符串,例如"GET" 或"POST"。
SERVER_NAME —— 服务器的主机名。
SERVER_PORT —— 服务器的端口(是一个字符串)。
从上面可以看到,除 CONTENT_LENGTH 和CONTENT_TYPE之外,请求中任何HTTP首部转换为 META 的键时,
都会将所有字母大写并将连接符替换为下划线最后加上 HTTP_ 前缀。
所以,一个叫做 X-Bender 的头部将转换成 META 中的 HTTP_X_BENDER 键。
request.user.is_authenticated
15、字段类型
# models.AutoField(primary_key=True)
# models.IntegerField()
# models.DecimalField(max_digits=5, decimal_places=2) # 000.00~999.99
# models.FloatField(max_digits=5,decimal_places=2) #000.00~999.99
# models.CharField(max_length=30)
# models.BooleanField() # True/False
# models.NullBooleanField() # Yes/No/Unknown
# models.TextField() # 大容量文本字段
# models.EmailField()
# models.DateField(verbose_name="描述", auto_now=True)
# models.DateTimeField()
auto_now_add # 创建这条数据时自动添加当前时间
auto_now # 每次更新的时候都自动更新时间
# models.CharField(max_length=32, default=None)
# models.IPAddressField() # IP地址
# models.ImageField(upload_to="",default=None,ehight_filed=100,width_filed=100) # 按照100*100像素保存
# models.FileField(upload_to="本地文件的路径")
# FileField 或 ImageField 使用步骤,因为效率问题,不能直接存到数据库
"""
1、在setting中配置MEDIA_ROOT路径,以便在此处保存上传文件
2、确保定义了upload_to选项,
"""
models.URLField(verify_exists=True) # 默认为True,存入时会预先检查是否存在(404)用text标签 # media配置
MEDIA_URL='media/'# 前端访问
MEDIA_ROOT= os.path.join(BASE_DIR,'media') from django.views.static import serve
re_path('media/(?P<path>.*),server,{'document_root':settings.MEDIA_ROOT })
16、字段参数
(1)null 如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False. (1)blank 如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。 (2)default 字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。 (3)primary_key 如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,
Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,
否则没必要设置任何一个字段的primary_key=True。 (4)unique 如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的 (5)choices
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,
默认的表单将是一个选择框而不是标准的文本框,<br>而且这个选择框的选项就是choices 中的选项。
17、文件上传
请求头ContentType指的是请求体的编码类型
1 application/x-www-form-urlencoded
最常见的get提交数据方式,Form表单默认,通过enctype设置
2 multipart/form-data
支持上传文件,浏览器 原生支持以上两种,
3 application/json
ajax的上传方式
var formdata=new FormData();
formdata.append("user",$("#user").val());
formdata.append("avatar_img",$("#avatar")[0].files[0]);
$.ajax({
url:"",
type:"post",
data:formdata,
processData: false , // 告诉jquery不要去处理发送的数据
contentType: false, // 告诉jquery不要去设置Content-Type请求头
success:function(data){
# var data=JSON.parse(data) # 反序列化
# var data=JSON.toString() # 序列化
console.log(data)
}
if request.method == "POST":
print("body", request.body) # 请求报文中的请求体
print("POST", request.POST)
# if contentType==urlencoded ,request.POST才有数据
print(request.FILES)
file_obj = request.FILES.get("avatar")
with open(file_obj.name, "wb") as f:
for line in file_obj:
f.write(line)
return HttpResponse("OK")
// 给每个input框绑定获取焦点之后清除之前错误提示的事件
$("input.form-control").on("focus", function () {
$(this).parent().removeClass("has-error").find(".help-block").text("");
}); // 点击图片刷新验证码
$("#id_valid_code+img").on("click", function () {
this.src += "?";
}); // 头像预览功能,当avatar input框的值发生变化时出发事件
$("#avatar").change(function () {
// 从本地读取文件
var filePath = $(this)[0].files[0];
var fileReader = new FileReader();
fileReader.readAsDataURL(filePath); // 读是需要时间的
fileReader.onload = function () {
$(".label-img").attr("src", fileReader.result);
};
18、CBV\FBV
urlpatterns = [
path('book_list/', views.HomeView.as_view(), name='book_list'),
]
from django.conf import settings
from django.shortcuts import redirect
from django.utils.decorators import method_decorator
from django.views import View
from django.views.decorators.csrf import csrf_exempt def check_login():
pass @method_decorator(check_login, "get")
class HomeView(View):
# csrf_protect,为当前函数强制设置防跨站请求伪造功能,即便settings中没有设置全局中间件。
# csrf_exempt,取消当前函数防跨站请求伪造功能,即便settings中设置了全局中间件。
@method_decorator(csrf_exempt) # csrf相关装饰器只能装饰在dispatch上
@method_decorator(check_login)
def dispatch(self, request, *args, **kwargs):
return super(HomeView, self).dispatch(request, *args, **kwargs) @staticmethod
def get(request):
return redirect("/index/") @staticmethod
def post(request):
print("Home View POST method...")
return redirect("/index/")
django提供了以下几个view View:基础的view,实现了方法的分发,但没有实现具体的get\post TemplateView:继承自View,可以直接用来返回指定的模板。实现了get方法,乐意传递变量到模板中进行数据展示 ;可以同过集成此类,重写get_content_data,传递数据
url("",TemplateView.as_view(template_name="about.html")) DetailView:继承自View,实现了get方法,并且可以绑定一个模板,进行数据展示
class PostDetailView(CommonViewMixin, DetailView):
model = None # 指定当前View要使用Model,默认为空
queryset = Post.objects.filter(status=Post.STATUS_NORMAL) # 和Model二选一,优先级更高,默认为空
template_name = 'blog/detail.html' # 模板的名字
context_object_name = 'post'
pk_url_kwarg = 'post_id' # url参数的key def get_queryset(self):
self.context_object_name
"""用来获取queryset,涉及到model以及queryset两个字段"""
return super(PostDetailView, self).get_queryset() def get_context_data(self, **kwargs):
"""
获取所有渲染到模板中的所有上下文
返回一个字典,{k:v}
"""
return super(PostDetailView, self).get_context_data(**kwargs) def get_object(self, queryset=None):
"""根据URL参数,从queryset上获取对应的实例"""
return super(PostDetailView, self).get_object(queryset)
ListView:继承自View,实现了get方法,可以同过绑定模板来批量获取数据
19、序列化
内置方法
def books_json(request):
book_list = models.Book.objects.all()[0:10]
from django.core import serializers
ret = serializers.serialize("json", book_list)
return HttpResponse(ret)
datetime对象,而json.dumps是无法处理这样在类型
class JsonCustomEncoder(json.JSONEncoder):
"""
自定义一个支持序列化时间格式的类
""" def default(self, o):
if isinstance(o, datetime):
return o.strftime("%Y-%m-%d %H:%M:%S")
elif isinstance(o, date):
return o.strftime("%Y-%m-%d")
else:
return json.JSONEncoder.default(self, o) def books_json(request):
book_list = models.Book.objects.all().values_list("title", "publish_date")
ret = json.dumps(list(book_list), cls=JsonCustomEncoder)
return HttpResponse(ret)
在Python脚本中调用Django环境
import os if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings")
import django
django.setup() from app01 import models books = models.Book.objects.all()
print(books)
10、时区问题
TIME_ZONE = 'Asia/Shanghai'
USE_TZ = False
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
from urllib import parse
v = parse.urlencode({'k1': 1, "k2": 2, "k3": 3})
print(v) # k3=3&k1=1&k2=2
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
10、单表查询
from django.shortcuts import render
from django.utils.safestring import mark_safe def test(request):
a = mark_safe('<a href="http://www.cnblogs.com/0bug/">屠龙宝刀,点击就送</a>')
return render(request, 'test.html', {'a': a})
django - 总结的更多相关文章
- 异步任务队列Celery在Django中的使用
前段时间在Django Web平台开发中,碰到一些请求执行的任务时间较长(几分钟),为了加快用户的响应时间,因此决定采用异步任务的方式在后台执行这些任务.在同事的指引下接触了Celery这个异步任务队 ...
- 《Django By Example》第四章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:祝大家新年快乐,这次带来<D ...
- django server之间通过remote user 相互调用
首先,场景是这样的:存在两个django web应用,并且两个应用存在一定的联系.某些情况下彼此需要获取对方的数据. 但是我们的应用肯经都会有对应的鉴权机制.不会让人家随随便便就访问的对吧.好比上车要 ...
- Mysql事务探索及其在Django中的实践(二)
继上一篇<Mysql事务探索及其在Django中的实践(一)>交代完问题的背景和Mysql事务基础后,这一篇主要想介绍一下事务在Django中的使用以及实际应用给我们带来的效率提升. 首先 ...
- Mysql事务探索及其在Django中的实践(一)
前言 很早就有想开始写博客的想法,一方面是对自己近期所学知识的一些总结.沉淀,方便以后对过去的知识进行梳理.追溯,一方面也希望能通过博客来认识更多相同技术圈的朋友.所幸近期通过了博客园的申请,那么今天 ...
- 《Django By Example》第三章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:第三章滚烫出炉,大家请不要吐槽文中 ...
- 《Django By Example》第二章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:翻译完第一章后,发现翻译第二章的速 ...
- 《Django By Example》第一章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:本人目前在杭州某家互联网公司工作, ...
- Django
一.Django 简介 Django 是一个由 Python 写成的开放源代码的 Web 应用框架.它最初是被开发来用于管理劳伦斯出版集团旗下的一些以新闻内容为主的网站的,即是 CMS(内容管理系统) ...
- Django admin定制化,User字段扩展[原创]
前言 参考上篇博文,我们利用了OneToOneField的方式使用了django自带的user,http://www.cnblogs.com/caseast/p/5909248.html , 但这么用 ...
随机推荐
- Saltstack_使用指南03_配置管理
1. 主机规划 注意事项 修改了master或者minion的配置文件,那么必须重启对应的服务. 2. 了解YAML 具体地址 https://docs.saltstack.com/en/latest ...
- Scheme来实现八皇后问题(1)
版权申明:本文为博主窗户(Colin Cai)原创,欢迎转帖.如要转贴,必须注明原文网址 http://www.cnblogs.com/Colin-Cai/p/9768105.html 作者:窗户 Q ...
- 一次CMS GC问题排查过程(理解原理+读懂GC日志)
这个是之前处理过的一个线上问题,处理过程断断续续,经历了两周多的时间,中间各种尝试,总结如下.这篇文章分三部分: 1.问题的场景和处理过程:2.GC的一些理论东西:3.看懂GC的日志 先说一下问题吧 ...
- UVA10054-The Necklace(无向图欧拉回路——套圈算法)
Problem UVA10054-The Necklace Time Limit: 3000 mSec Problem Description Input The input contains T t ...
- 【题解】洛谷P3660 [USACO17FEB]Why Did the Cow Cross the Road III
题目地址 又是一道奶牛题 从左到右扫描,树状数组维护[左端点出现而右端点未出现]的数字的个数.记录每个数字第一次出现的位置. 若是第二次出现,那么删除第一次的影响. #include <cstd ...
- Analyzing 'enq: HW - contention' Wait Event (Doc ID 740075.1)
Analyzing 'enq: HW - contention' Wait Event (Doc ID 740075.1) In this Document Symptoms Cause ...
- SkylineGlobe TerraExplorer for Web 7.1.0版本 接口示例
在SkylineGlobe TerraExplorer for Web 7.1.0版本(俗称H5免插件版本)中,如何使用SGWorld接口的三维视域分析方法呢? 请参考下面的示例: 通过下面的代码大家 ...
- PyInstaller Extractor安装和使用方法
PyInstaller Extractor是可以提取出PyInstaller所创建的windows可执行文件的资源内容. 关于PyInstaller的介绍:PyInstaller安装使用方法 使用Py ...
- cookie跨域共享
domain和path属性,domain就是当前域,默认为请求的地址,如网址为www.jb51.net/test/test.aspx,那么domain默认为www.jb51.net,path默认就是当 ...
- 相片后期处理,PS调出温暖的逆光美女
原图: 效果图: 后面就是开PS导图: 说明下,因为拍的时候大概知道自己的方法会让照片变暖,现场光线又很暖,所以色温要调低一些,这边是4100,其他不用变,直接转JPG调色了 1:第一步是加第一个曲线 ...