ElasticSearch 启动时加载 Analyzer 源码分析
ElasticSearch 启动时加载 Analyzer 源码分析
本文介绍 ElasticSearch启动时如何创建、加载Analyzer,主要的参考资料是Lucene中关于Analyzer官方文档介绍、ElasticSearch6.3.2源码中相关类:AnalysisModule、AnalysisPlugin、AnalyzerProvider、各种Tokenizer类和它们对应的TokenizerFactory。另外还参考了一个具体的基于ElasticSearch采用HanLP进行中文分词的插件:elasticsearch-analysis-hanlp
这篇文章的主要目的是搞懂:AnalysisModule、AnalysisPlugin、AnalyzerProvider、某个具体的Tokenizer,比如HanLPStandardAnalyzer、和TokenizerFactory 之间的关系。这里面肯定是用过了某个(某些)设置模式的。搞懂了这个自己也能照葫芦画瓢,开发自定义的Plugin了。
分词插件
1 Tokenizer
对比HanLP中文分词器和ElasticSearch中内置的标准分词器(StandardTokenizer),发现elasticsearch-analysis-hanlp的实现方法和ElasticSearch中实现的标准分词插件二者几乎是一个套路。
HanLP提供了各种各样的中文分词方式,比如:标准分词、索引分词、NLP分词……因此,HanLPTokenizerFactory implements TokenizerFactory,实现了create()方法,负责创建各类分词器。

这种写法和ElasticSearch源码里面的StandardTokenizerFactory写法如出一辙。
2 Analyzer
把Analyzer想象成一部生产Token的机器,输入Text,输出Token。
An Analyzer builds TokenStreams, which analyze text. It thus represents a policy for extracting index terms from text.
这部机器可以以不同的方式生产Token。比如:对于英文,一般以文本中的空格作为分隔符,输入Text,输出Token。
对于中文,中文文本没有空格了,因此需要借助一些中文分词算法,输入Text,输出Token。
对于HTML这样的文本,那就需要根据HTML标签作为分隔符,输入Text,输出Token。
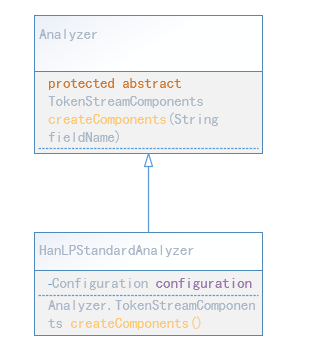
TokenStreamComponents内部类封装了生产Token的方式,看源码注释**This class encapsulates the outer components of a token stream.It provides access to the source Tokenizer and .... **。主要是封装了Tokenizer
/**
* This class encapsulates the outer components of a token stream. It provides
* access to the source ({@link Tokenizer}) and the outer end (sink), an
* instance of {@link TokenFilter} which also serves as the
* {@link TokenStream} returned by
* {@link Analyzer#tokenStream(String, Reader)}.
*/
public static class TokenStreamComponents {
/**
* Original source of the tokens.
*/
protected final Tokenizer source;
/**
* Sink tokenstream, such as the outer tokenfilter decorating
* the chain. This can be the source if there are no filters.
*/
protected final TokenStream sink;
若要自定义Analyzer,只需继承Analyzer类,重写createComponents()方法,提供一个Tokenizer就可以了。比如:HanLPStandardAnalyzer重写的方法如下:
@Override
protected Analyzer.TokenStreamComponents createComponents(String fieldName) {
// AccessController.doPrivileged((PrivilegedAction) () -> HanLP.Config.Normalization = true);
Tokenizer tokenizer = new HanLPTokenizer(HanLP.newSegment(), configuration);
return new Analyzer.TokenStreamComponents(tokenizer);
}
另外,也可参考ElasticSearch中提供的StandardAnalyzer.java,它实现了ElasticSearch查询分析过程中的标准分词,它继承了StopwordAnalyzerBase.java,这样可以在生产Token的时候,过滤掉 stop words。
3 AnalyzerProvider
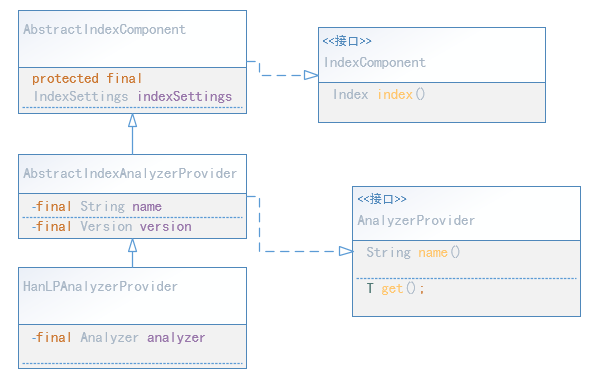
AnalyzerProvider封装了Analyzer,它的构造方法实例化一个Analyzer,并为Analyzer 提供了一些名称、版本相关的信息:
public class HanLPAnalyzerProvider extends AbstractIndexAnalyzerProvider<Analyzer> {
private final Analyzer analyzer;
AbstractIndexAnalyzerProvider 里面有 name 和 Version信息(Constructs a new analyzer component, with the index name and its settings and the analyzer name.)
public abstract class AbstractIndexAnalyzerProvider<T extends Analyzer> extends AbstractIndexComponent implements AnalyzerProvider<T> {
private final String name;
protected final Version version;
4 AnalysisPlugin
AnalysisHanLPPlugin负责注册各种各样的分词器。在定义索引的时候需要指定某个字段的Analyzer名称,比如下面 name 字段中的文本在都使用名称为hanlp_standard分词器分词后,写入ElasticSearch索引。
"name": {
"type": "text",
"analyzer": "hanlp_standard",
"fields": {
"raw": {
"type": "keyword"
}
}
},

AnalysisPlugin主要是下面三个方法,用来获取:CharFilter、TokenFilter、Tokenizer。关于这三个的区别可参考下节:索引分析过程。
/**
* Override to add additional {@link CharFilter}s. See {@link #requriesAnalysisSettings(AnalysisProvider)}
* how to on get the configuration from the index.
*/
default Map<String, AnalysisProvider<CharFilterFactory>> getCharFilters() {
return emptyMap();
}
/**
* Override to add additional {@link TokenFilter}s. See {@link #requriesAnalysisSettings(AnalysisProvider)}
* how to on get the configuration from the index.
*/
default Map<String, AnalysisProvider<TokenFilterFactory>> getTokenFilters() {
return emptyMap();
}
/**
* Override to add additional {@link Tokenizer}s. See {@link #requriesAnalysisSettings(AnalysisProvider)}
* how to on get the configuration from the index.
*/
default Map<String, AnalysisProvider<TokenizerFactory>> getTokenizers() {
return emptyMap();
}
ElasticSearch如何加载Analyzer插件
这里主要参考ElasticSearch启动过程中相关源代码。在创建PluginService过程中初始化各种Analyzer, Node.java
//加载 modules 和 plugins 目录下的内容
this.pluginsService = new PluginsService(tmpSettings, environment.configFile(), environment.modulesFile(), environment.pluginsFile(), classpathPlugins);
貌似是通过创建的ClassLoader,不管是module还是plugin都视为bundle,以SPI方式接入底层Lucene,PluginService.java
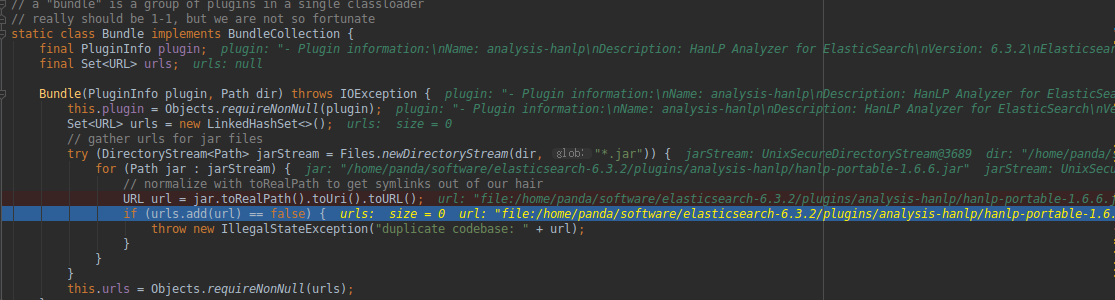
// load modules
if (modulesDirectory != null) {
Set<Bundle> modules = getModuleBundles(modulesDirectory);
for (Bundle bundle : modules) {
modulesList.add(bundle.plugin);
}
seenBundles.addAll(modules);
}
// now, find all the ones that are in plugins/
if (pluginsDirectory != null) {
List<BundleCollection> plugins = findBundles(pluginsDirectory, "plugin");
for (final BundleCollection plugin : plugins) {
final Collection<Bundle> bundles = plugin.bundles();
for (final Bundle bundle : bundles) {
pluginsList.add(bundle.plugin);
}
seenBundles.addAll(bundles);
pluginsNames.add(plugin.name());
}
加载 module/plugin jar文件:
try (DirectoryStream<Path> jarStream = Files.newDirectoryStream(dir, "*.jar")) {
for (Path jar : jarStream) {
// normalize with toRealPath to get symlinks out of our hair
URL url = jar.toRealPath().toUri().toURL();
if (urls.add(url) == false) {
throw new IllegalStateException("duplicate codebase: " + url);
}
}
}
//...
// create a child to load the plugin in this bundle
ClassLoader parentLoader = PluginLoaderIndirection.createLoader(getClass().getClassLoader(), extendedLoaders);
ClassLoader loader = URLClassLoader.newInstance(bundle.urls.toArray(new URL[0]), parentLoader);

当PluginService载入了所有的plugin后,过滤出与Analysis相关的Plugin,创建AnalysisModule
//从plugin service 中过滤出 与Analysis相关的plugin
AnalysisModule analysisModule = new AnalysisModule(this.environment, pluginsService.filterPlugins(AnalysisPlugin.class));
注册各种分词器、filters、analyzer的名称:(这样在创建索引的时候,为某个索引字段指定分词器,就是用的这里的注册了的名称)
NamedRegistry<AnalysisProvider<CharFilterFactory>> charFilters = setupCharFilters(plugins);
NamedRegistry<AnalysisProvider<TokenFilterFactory>> tokenFilters = setupTokenFilters(plugins, hunspellService);
NamedRegistry<AnalysisProvider<TokenizerFactory>> tokenizers = setupTokenizers(plugins);
NamedRegistry<AnalysisProvider<AnalyzerProvider<?>>> analyzers = setupAnalyzers(plugins);
//....
private NamedRegistry<AnalysisProvider<AnalyzerProvider<?>>> setupAnalyzers(List<AnalysisPlugin> plugins) {
NamedRegistry<AnalysisProvider<AnalyzerProvider<?>>> analyzers = new NamedRegistry<>("analyzer");
analyzers.register("default", StandardAnalyzerProvider::new);
analyzers.register("standard", StandardAnalyzerProvider::new);
//....
public StandardAnalyzerProvider(IndexSettings indexSettings, Environment env, String name, Settings settings) {
//....
standardAnalyzer = new StandardAnalyzer(stopWords);
standardAnalyzer.setVersion(version);
}
引用一段《An Introduction to Information Retrieval》中关于 token、type、term、dictionary概念的解释:(这里的type和ElasticSearch索引中的type是不一样的,ElasticSearch索引中的type以后版本将不支持了)
A token is an instance of a sequence of characters in some particular document that are grouped together as a useful semantic unit for processing. A type is the class of all tokens containing the same character sequence. A term is a (perhaps normalized) type that is included in the IR system's dictionary.
For example, if the document to be indexed is to
sleep perchance to dream, then there are 5 tokens, but only 4 types (since there are 2 instances of to). However, if to is omitted from the index (as a stop word) then there will be only 3 terms: sleep, perchance, and dream.
索引分析过程

个人觉得Tokenization和Analysis过程有交叉的地方。Lucene中定义的Analysis是指:将字符串转化成Tokens的过程,Analysis主要有四个方面:
The analysis package provides the mechanism to convert Strings and Readers into tokens that can be indexed by Lucene. There are four main classes in the package from which all analysis processes are derived. These are:
- Analyzer
- CharFilter
- Tokenizer
- TokenFilter
这四个的区别如下:(以中文处理举例)
比如一句中文:“这是一篇关于ElasticSearch Analyzer的文章”,CharFilter过滤其中的某个字。Tokenizer是将这句话进行中文分词:这是、一篇、关于、ElasticSearch、Analyzer、的、文章;分词得到的结果就是一个个的Token。TokenFilter则是过滤某些Token。
The Analyzer is a factory for analysis chains. Analyzers don't process text, Analyzers construct CharFilters, Tokenizers, and/or TokenFilters that process text. An Analyzer has two tasks: to produce TokenStreams that accept a reader and produces tokens, and to wrap or otherwise pre-process Reader objects.
具体可参考:Lucene7.6.0。在Lucene中,Analyzer不处理文本,它只是构建CharFilters、Tokenizer、TokenFilters, 然后让它们来处理文本。
参考资料
ElasticSearch6.3.2源码
HanLP进行中文分词的插件:elasticsearch-analysis-hanlp
原文:https://www.cnblogs.com/hapjin/p/10151887.html
ElasticSearch 启动时加载 Analyzer 源码分析的更多相关文章
- 微服务架构 | *2.3 Spring Cloud 启动及加载配置文件源码分析(以 Nacos 为例)
目录 前言 1. Spring Cloud 什么时候加载配置文件 2. 准备 Environment 配置环境 2.1 配置 Environment 环境 SpringApplication.prep ...
- Springboot学习04-默认错误页面加载机制源码分析
Springboot学习04-默认错误页面加载机制源码分析 前沿 希望通过本文的学习,对错误页面的加载机制有这更神的理解 正文 1-Springboot错误页面展示 2-Springboot默认错误处 ...
- Springboot 加载配置文件源码分析
Springboot 加载配置文件源码分析 本文的分析是基于springboot 2.2.0.RELEASE. 本篇文章的相关源码位置:https://github.com/wbo112/blogde ...
- Spring Cloud Nacos实现动态配置加载的源码分析
理解了上述Environment的基本原理后,如何从远程服务器上加载配置到Spring的Environment中. NacosPropertySourceLocator 顺着前面的分析思路,我们很自然 ...
- jQuery实现DOM加载方法源码分析
传统的判断dom加载的方法 使用 dom0级 onload事件来进行触发所有浏览器都支持在最初是很流行的写法 我们都熟悉这种写法: window.onload=function(){ ... } 但 ...
- springboot Properties加载顺序源码分析
关于properties: 在spring框架中properties为Environment对象重要组成部分, springboot有如下几种种方式注入(优先级从高到低): 1.命令行 java -j ...
- Spring boot加载REACTIVE源码分析
一,加载REACTIVE相关自动配置 spring boot通过判断含org.springframework.web.reactive.DispatcherHandler字节文件就确定程序类型是REA ...
- spring启动component-scan类扫描加载过程---源码分析
http://blog.csdn.net/xieyuooo/article/details/9089441#comments
- Servlet在启动时加载的tomcat源码(原创)
tomcat 8.0.36 知识点: 通过配置loadOnStartup可以设置Servlet是否在Tomcat启动时加载,以及按值大小进行有序加载,其最小有效值为0,最大有效值为Integer.MA ...
随机推荐
- HTML,CSS---问题记录
1,,登录框input和标签垂直方向对不齐,咋解决? 给input框外套一层span标签,给span标签设置宽高,让它和左边或右边的标签对齐. 不要直接给input设置宽高,这样是对不齐的 2,套没有 ...
- C# 里面swith的或者
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threa ...
- Java并发-AQS及各种Lock锁的原理
原文 : https://blog.csdn.net/zhangdong2012/article/details/79983404
- adb常用命令(golang版)及输入中文
package main import ( "crypto/md5" "fmt" "image/png" "io/ioutil&q ...
- AI SegNet
SegNet,是一种基于编码器-解码器架构的深度全卷积神经网络,用于图像语义分割. 参考链接: https://ieeexplore.ieee.org/document/7803544
- Sklearn中的回归和分类算法
一.sklearn中自带的回归算法 1. 算法 来自:https://my.oschina.net/kilosnow/blog/1619605 另外,skilearn中自带保存模型的方法,可以把训练完 ...
- vs2017创建.net core 应用程序,发布到Linux
1.打开vs2017,创建.net core 应用程序 压缩上传到linux
- jdk的安装及环境变量的配置
一.JDK的下载 1.首先打开JDK的官网(点击打开链接),找到JAVA SE 7u71/72中的JDK,选择Download 2.然后如下图,选择Accept License Agreement,则 ...
- MyBatis 学习总结 01 快速入门
本文测试源码下载地址: http://onl5wa4sd.bkt.clouddn.com/MyBatis0918.rar 一.Mybatis介绍 MyBatis是一个支持普通SQL查询,存储过程和高级 ...
- Java面试准备之JVM
介绍JVM中7个区域,然后把每个区域可能造成内存的溢出的情况说明 程序计数器:看做当前线程所执行的字节码行号指示器.是线程私有的内存,且唯一一块不报OutOfMemoryError异常. Java虚拟 ...