urllib库的应用及简单爬虫的编写
1、urllib库基础
1.1爬虫的异常处理
常见状态码及含义
301 Moved Permanently:重定向到新的URL,永久性
302 Found:重定向到临时的URL,非永久性
304 Not Modified:请求的资源未更新
400 Bad Request:非法请求
401 Unauthorized:请求未经授权
403 Forbidden:禁止访问
404 Not Found:没有找到对应页面
500 Internal Server Error:服务器内部出现错误
501 Not Implemented:服务器不支持实现请求所需要的功能
URLError与HTTPError都是异常处理的类,HTTPError是URLError的子类,HTTPError有异常状态码与异常原因,URLError没有异常状态码。不能用URLError直接代替HTTPError,如果要代替,必须要判断是否有状态码属性。
URLError:
1、连不上服务器
2、远程的URL不存在
3、本地没有网络
4、触发了HTTPError(因为HTTPError是它的子类)

1.2爬虫的浏览器伪装技术
想要伪装成浏览器,必须为爬虫添加报头信息。打开浏览器进入网页,F12中network中找到user-agent及其后面的内容,然后创建opener对象,把opener添加为全局(urllib.request.install_opener(opener))。

1.3设置代理服务器

2、爬虫实战
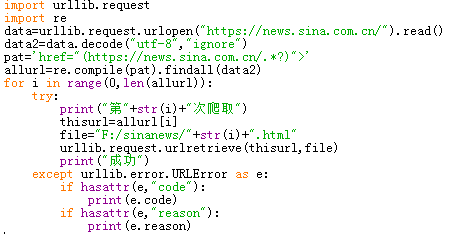
2.1将新浪新闻首页的所有新闻都爬到本地
进入新浪新闻首页,查看网页源代码,根据每个新闻链接的相似度,构造求新闻链接的正则表达式,接着再将网页全部写入到本地。
2.2爬取CSDN博客(http://blog.csdn.net/)首页显示的所有文章,每个文章内容单独生成一个本地网页存到本地中。
利用浏览器伪装技术,先爬首页,通过正则表达式筛选出所有文章的url,然后通过循环把这些url下载到本地。

3、爬取网站图片
3.1爬取淘宝网任意搜索目录下高清图
本次爬取淘宝的搜索关键词为“短裙”,在淘宝搜索短裙进入搜索结果页面。对该页面网址及下几页网址进行分析,找出url构造规律。对源代码中进行分析,注意找到图片的url,此时要特别注意图片必须要高清而不是略缩图,这同样需要注意图片地址。利用正则表达式对提取到的信息进行筛选,最后将得到的图片编号存储到本地。

由于是爬取多页的信息,如果对循环不太熟悉的话,可以先爬取一页的图片,然后找出循环的规律在对规定的页数进行循环爬取图片。
3.2对千图网任一类图片进行爬取
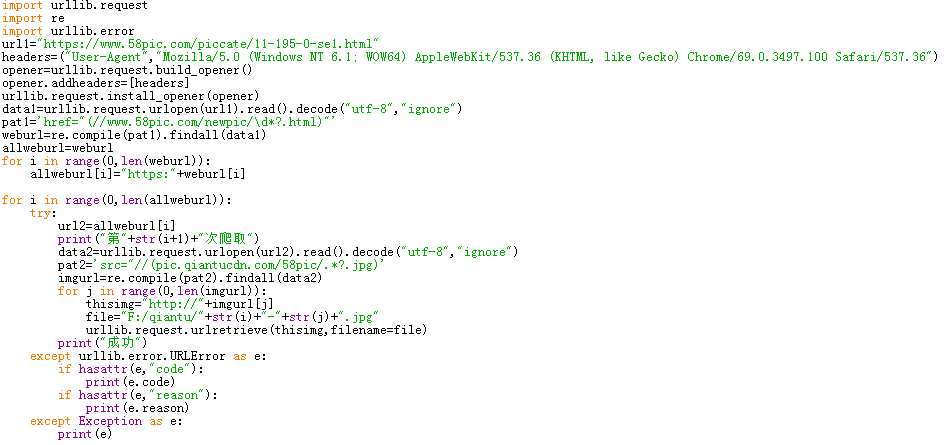
一定要进行异常处理,不然程序很容易崩。尽量每次爬取后都输出一些文字提示,以此来了解进度。
urllib库的应用及简单爬虫的编写的更多相关文章
- 对于python爬虫urllib库的一些理解(抽空更新)
urllib库是Python中一个最基本的网络请求库.可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据. urlopen函数: 在Python3的urllib库中,所有和网 ...
- 爬虫之urllib库
一.urllib库简介 简介 Urllib是Python内置的HTTP请求库.其主要作用就是可以通过代码模拟浏览器发送请求.它包含四个模块: urllib.request :请求模块 urllib.e ...
- python爬虫 urllib库基本使用
以下内容均为python3.6.*代码 学习爬虫,首先有学会使用urllib库,这个库可以方便的使我们解析网页的内容,本篇讲一下它的基本用法 解析网页 #导入urllib from urllib im ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- Python爬虫学习笔记-1.Urllib库
urllib 是python内置的基本库,提供了一系列用于操作URL的功能,我们可以通过它来做一个简单的爬虫. 0X01 基本使用 简单的爬取一个页面: import urllib2 request ...
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- 六 web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode("utf-8")将字节转化成字符串 ...
- 网络爬虫必备知识之urllib库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结合爬虫示例分别对urllib库的使用方法进行 ...
- 爬虫入门之urllib库详解(二)
爬虫入门之urllib库详解(二) 1 urllib模块 urllib模块是一个运用于URL的包 urllib.request用于访问和读取URLS urllib.error包括了所有urllib.r ...
随机推荐
- [mysql]错误解决之"Failed to start MySQL Server"
最近又开始倒腾mysql了,遇到了一个以前没有见过的问题. 问题如下: 百度了好久,发现写的文章都千篇一律,解决办法也都几乎是一样的,然而在我这里一点儿用都没有. 所以FQ看了看外面的世界,终于找到了 ...
- Centos7中一键安装zabbix
作者:邓聪聪 #!/bin/shlog=/root/install.logexec 2>>$log #关闭SELINUX,防火墙 systemctl stop firewalld.serv ...
- mysql 迁移
背景 这次做oracle数据迁移,也想总结像mysql的数据迁移方式.简单列下吧,因为具体方式网上很多. 方式 可以通过修改mysql.ini的数据文件目录位置方法实现拷贝迁移,此种方式简单 通过备份 ...
- vue-cli3.0 项目如何使用sass
执行: npm install node-sass --save-dev npm install sass-loader --save-dev 自动安装sass,vue-cli3.0 不需要在 web ...
- innodb表碎片处理
本次测试环境是 mysql 5.7.23,表空间为每个表单独表空间 mysql> sHOW VARIABLES LIKE 'innodb_file_per_tabl%'; +---------- ...
- ssh反向代理
文章链接:https://www.cnblogs.com/kwongtai/p/6903420.html 前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后 ...
- Java实现大数加法运算的几种方法
大数加法 思路一:定义String变量str1和str2分别存储输入的两个大数,定义num1[]和num2[]两个int型数组,将两个字符串分别逐个字符逆序存入数组,定义sum[]数组存放求和结果,使 ...
- Java_运算符
目录 一.算术运算符 二.关系运算符 三.位运算符 四.赋值运算符 五.条件运算符 六.instanceof 运算符 七.逻辑运算符 一.算术运算符 加 减 乘 除 取余 自增 自减(+ - * / ...
- 如何把PDF文件拆分为多个文件
一个PDF文件有很多个PDF页面组成,有时候我们只需要单个页面的时候应该怎么做呢,这个时候就需要拆分PDF文件了,那么如何把 PDF文件拆分为多个文件呢,应该有很多的小伙伴都想知道吧,那就让我们一起来 ...
- 数位dp-入门模板题 hdu2089
#include<bits/stdc++.h> using namespace std; ][],n,m; void init(){//dp[i][j]:i位的数,最高位是j dp[][] ...