C++17剖析:string_view的实现,以及性能
主要内容
C++17标准发布,string_view是标准新增的内容。这篇文章主要分析string_view的适用范围、注意事项,并分析string_view带来的性能提升,最后从gcc 8.2的libstdc++库源码级别分析性能提升的原因。
背景知识:静态字符串的处理
所谓静态字符串,就是编译时已经固定的字符串,他们存储在二进制文件的静态存储区,而且程序只能读取,不能改动。
一个例子:
//指针指向静态字符串
const char* str_ptr = "this is a static string";
//字符串数组
char str_array[] = "this is a static string";
//std::string
std::string str = "this is a static string";
//std::string_view
std::string_view sv = "this is a static string";
反汇编:
g++ -O0 -o static_str static_str.cc -std=c++17 -g && objdump -S -t -D static_str > static_str.s
汇编代码如下:
int main()
{
4013b8: 55 push %rbp
4013b9: 48 89 e5 mov %rsp,%rbp
4013bc: 53 push %rbx
4013bd: 48 83 ec 68 sub $0x68,%rsp
//指针指向静态字符串
const char* str_ptr = "this is a static string!";
##直接设置字符串指针
4013c1: 48 c7 45 e8 30 1e 40 movq $0x401e30,-0x18(%rbp)
4013c8: 00
//字符串数组
char str_array[] = "this is a static string!";
##这里使用一个很取巧的办法,不使用循环,而是使用多个mov语句把字符串设置到堆栈
4013c9: 48 b8 74 68 69 73 20 mov $0x2073692073696874,%rax
4013d0: 69 73 20
4013d3: 48 ba 61 20 73 74 61 mov $0x6369746174732061,%rdx
4013da: 74 69 63
4013dd: 48 89 45 c0 mov %rax,-0x40(%rbp)
4013e1: 48 89 55 c8 mov %rdx,-0x38(%rbp)
4013e5: 48 b8 20 73 74 72 69 mov $0x21676e6972747320,%rax
4013ec: 6e 67 21
4013ef: 48 89 45 d0 mov %rax,-0x30(%rbp)
4013f3: c6 45 d8 00 movb $0x0,-0x28(%rbp)
//std::string
std::string str = "this is a static string!";
#esi保存了字符串开始地址$0x401e30,调用std::string的构造函数
4013f7: 48 8d 45 e7 lea -0x19(%rbp),%rax
4013fb: 48 89 c7 mov %rax,%rdi
4013fe: e8 15 fe ff ff callq 401218 <_ZNSaIcEC1Ev@plt>
401403: 48 8d 55 e7 lea -0x19(%rbp),%rdx
401407: 48 8d 45 a0 lea -0x60(%rbp),%rax
40140b: be 30 1e 40 00 mov $0x401e30,%esi
401410: 48 89 c7 mov %rax,%rdi
401413: e8 fe 01 00 00 callq 401616 <_ZNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEC1IS3_EEPKcRKS3_>
401418: 48 8d 45 e7 lea -0x19(%rbp),%rax
40141c: 48 89 c7 mov %rax,%rdi
40141f: e8 c4 fd ff ff callq 4011e8 <_ZNSaIcED1Ev@plt>
//std::string_view
std::string_view sv = "this is a static string!";
#直接设置字符串的长度0x18,也就是24Bytes,还有字符串的起始指针$0x401e30,没有堆内存分配
401424: 48 c7 45 90 18 00 00 movq $0x18,-0x70(%rbp)
40142b: 00
40142c: 48 c7 45 98 30 1e 40 movq $0x401e30,-0x68(%rbp)
401433: 00
return 0;
401434: bb 00 00 00 00 mov $0x0,%ebx
//字符串数组
## 对象析构:字符串数组分配在栈上,无需析构
char str_array[] = "this is a static string!";
//std::string
## 对象析构:调用析构函数
std::string str = "this is a static string!";
401439: 48 8d 45 a0 lea -0x60(%rbp),%rax
40143d: 48 89 c7 mov %rax,%rdi
401440: e8 a9 01 00 00 callq 4015ee <_ZNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEED1Ev>
401445: 89 d8 mov %ebx,%eax
401447: eb 1a jmp 401463 <main+0xab>
401449: 48 89 c3 mov %rax,%rbx
40144c: 48 8d 45 e7 lea -0x19(%rbp),%rax
401450: 48 89 c7 mov %rax,%rdi
401453: e8 90 fd ff ff callq 4011e8 <_ZNSaIcED1Ev@plt>
401458: 48 89 d8 mov %rbx,%rax
40145b: 48 89 c7 mov %rax,%rdi
40145e: e8 e5 fd ff ff callq 401248 <_Unwind_Resume@plt>
//std::string_view
## 对象析构:std::string_view分配在栈上,无需析构
std::string_view sv = "this is a static string!";
return 0;
}
- 静态字符串:会把指针指向静态存储区,字符串只读。如果尝试修改,会导致段错误(segment fault)。
- 字符串数组:在栈上分配一块空间,长度等于字符串的长度+1(因为还需要包括末尾的'\0'字符),然后把字符串拷贝到缓冲区。上述代码,我之前一直以为会使用循环(类似memmove),但是一直找不到循环的语句,却找到一堆莫名其妙的数字($0x2073692073696874,$0x6369746174732061)仔细观察发现,原来编译器把一个长字符串分开为几个64bit的长整数,逐次mov到栈缓冲区中, 那几个长长的整数其实是: 0x2073692073696874=[ si siht],$0x6369746174732061=[citats a],0x21676e6972747320=[!gnirts],刚好就是字符串的反序,编译器是用这种方式来提高运行效率的。我觉得其实末尾的0是可以和字符串一起写在同一个mov指令中的,这样执行的指令就可以少一个了,不知道为什么不这样做。
- std::string:只在寄存器设置了字符串的起始指针,调用了
basic_string( const CharT* s,const Allocator& alloc = Allocator() )构造函数,中间涉及各种检测和字符串拷贝,后面会在另一篇讲述std::string原理的文章中详细分析,总之动态内存分配与字符串拷贝是肯定会发生的事情。值得一提的是,如果在构造函数里面至少会有如下操作:确定字符串长度(如strlen,遍历一遍字符串),按字符串长度(或者预留更多的长度)新建一块内存空间,拷贝字符串到新建的内存空间(第二次遍历字符串)。 - std::string_view:上面的汇编代码很简单,只是单纯设置静态字符串的起始指针和长度,没有其他调用,连内存分配都是栈上的!跟std::string相比,在创建std::string_view对象的时候,没有任何动态内存分配,没有对字符串多余的遍历。一直以来,对于C字符串而言,如果需要获取它的长度,至少需要strlen之类的函数。但是我们似乎忽略了一点,那就是,如果是静态字符串,编译器其实是知道它的长度的,也就是,静态字符串的长度可以在编译期间确定,那就可以减少了很多问题。
- 题外话:编译期确定字符串长度、对象大小,这种并不是什么奇技淫巧,因为早在
operator new运算符重载的时候,就有一个size_t参数,这个就是编译器传入的对象大小,而std::string_view,则是在编译期间传入字符串的指针和长度,构建对象。但是,std::string和std::string_view这两个类同时提供了只带字符串指针和同时带字符串指针和字符串长度两个版本的构造函数,默认的情况下,std::string str = "this is a static string!"会调用basic_string( const CharT* s,const Allocator& alloc = Allocator() )构造,但是std::string_view sv = "this is a static string!"会调用带长度的basic_string_view(const _CharT* __str, size_type __len) noexcept版本,这一点我一直没弄明白(TODO)。但是,标准库提供了一个方法,可以让编译器选择带长度的std::string构造函数,下一小节讲述。
std::string_view的实现(GCC 8.2)
std::string_view类的成员变量只包含两个:字符串指针和字符串长度。字符串指针可能是某个连续字符串的其中一段的指针,而字符串长度也不一定是整个字符串长度,也有可能是某个字符串的一部分长度。std::string_view所实现的接口中,完全包含了std::string的所有只读的接口,所以在很多场合可以轻易使用std::string_view代替std::string。一个通常的用法是,生成一个std::string后,如果后续的操作不再对其进行修改,那么可以考虑把std::string转换成为std::string_view,后续操作全部使用std::string_view来进行,这样字符串的传递变得轻量级。虽然在很多实现上,std::string都使用引用计数进行COW方式管理,但是引用计数也会涉及锁和原子计数器,而std::string_view的拷贝只是单纯拷贝两个数值类型变量(字符串指针及其长度),效率上前者是远远无法相比的。std::string_view高效的地方在于,它不管理内存,只保存指针和长度,所以对于只读字符串而言,查找和拷贝是相当简单的。下面主要以笔记的形式,了解std::string_view的实现。
只读操作:没有std::string的c_str()函数。因为std::string_view管理的字符串可能只是一串长字符串中的一段,而c_str()函数的语义在于返回一个C风格的字符串,这会引起二义性,可能这就是设计者不提供这个接口的原因。但是与std::string一样提供了data()接口。对于std::string而言,data()与c_str()接口是一样的。std::string_view提供的data()接口只返回它所保存的数据指针,语义上是正确的。在使用std::string_view的data()接口的时候,需要注意长度限制,例如
cout<<sv.data();与cout<<sv;的输出结果很可能是不一样的,前者会多输出一部分字符。std::string_view的前身,google的abseil::string_view的文档中有如下描述(https://abseil.io/tips/1):

std::string_view与std::string的生成:C++17新增了
operator""sv(const char* __str, size_t __len)和operator""s(const char* __str, size_t __len)操作符重载,因此,生成字符串的方法可以使用这两个操作符。令人惊奇的是,使用这种方法,生成std::string调用的是basic_string_view(const _CharT* __str, size_type __len) noexcept版本的构造函数,这就意味着免去了构造时再一次获取字符串长度的开销(实际上是编译器在帮忙)
//std::string
std::string str = "this is a static string!"s;
//std::string_view
std::string_view sv = "this is a static string!"sv;
反汇编如下(其实读者可以使用gdb调试,查看实际调用的构造函数):
//std::string
std::string str = "this is a static string!"s;
## esi存放字符串起始地址,edx存放字符串长度,0x18就是字符串长度24字节
4014b7: 48 8d 45 a0 lea -0x60(%rbp),%rax
4014bb: ba 18 00 00 00 mov $0x18,%edx
4014c0: be 50 1e 40 00 mov $0x401e50,%esi
4014c5: 48 89 c7 mov %rax,%rdi
4014c8: e8 da 00 00 00 callq 4015a7 <_ZNSt8literals15string_literalsli1sB5cxx11EPKcm>
- 修改操作:如前所述,std::string_view并不提供修改接口,因为它保存的数据指针是
const _CharT*类型的,无法运行时修改。 - 字符串截取substr():这部分特别提出。因为使用std::string::substr()函数,会对所截取的部分生成一个新的字符串返回(中间又涉及内存动态分配以及拷贝),而std::string_view::substr(),也是返回一个std::string_view,但是依旧不涉及内存的动态分配。只是简单地用改变后的指针和长度生成一个新的std::string_view对象,O(1)操作。代码如下:
constexpr basic_string_view
substr(size_type __pos, size_type __n = npos) const noexcept(false)
{
__pos = _M_check(__pos, "basic_string_view::substr");
const size_type __rlen = std::min(__n, _M_len - __pos);
return basic_string_view{_M_str + __pos, __rlen};
}
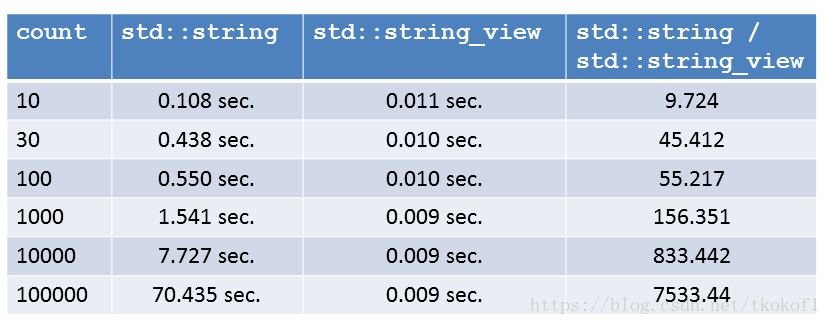
- 关于字符串截取,引用一下其他人的测试结果,性能提高不是一星半点。(来自这里)
使用注意事项
std::string_view/std::string用于项目中,我认为有下面几点需要注意的:
- C++17中,std::string与std::string_view的转换仍然需要手动调用构造函数,没有to_string/to_string_view之类的函数可以调用。
- 以std::string为key的map,如果需要使用std::string_view检索,则需要把less函数设置为通用的,也就是map<std::string, int, std::less<>>,使用全局的比较函数代替std::string的专属std::lessstd::string。C++14后可以使用不同类型的key检索map,使用默认的std::less<>作为比较函数,可以调用通用的比较函数,而std::lessstd::string只能是两个std::string比较。
std::map<std::string, int> map1;
//插入数据到map1,略
std::string k1 = "123";
int v1 = map1[k1]; //OK
auto it_1 = map1.find(k1); //OK
std::string_view k2 = "456";
int v2 = map1[k1]; //ERR,因为默认std::less<std::string>只能两个std::string比较
auto it_2 = map1.find(k1); //ERR,同上
std::map<std::string, int, std::less<>> map2;
//插入数据到map2,略
std::string k3 = "123";
int v3 = map1[k3]; //OK
auto it_3 = map1.find(k3); //OK
std::string_view k4 = "456";
int v4= map1[k4]; //ERR,因为operator []的类型只能与key一样的类型,也就是只能是std::string
auto it_4 = map1.find(k4); //OK,因为C++14可以提供不同类型的key模板
- std::string_view管理的只是指针,试用期间应该注意指针所指向的内存是可访问的;
- 如果使用静态字符串初始化std::string,建议使用
operator s()重载,但是使用这个运算符重载需要使用std::literals,反正我经常会忘记。 - 如果在项目中需要使用下面这种方式生成字符串的:
int num = 100;
//process @num
std::string err_message = "Invalid Number: " + std::to_string(num);
在c++11有可能会报错,因为 "Invalid Number: " 是一个const char*,无法使用operator +(const std::string&),或者改为
std::string err_message = std::string("Invalid Number: ") + std::to_string(num);
在C++17中,可以使用如下方法:
using namespace std::literals;
std::string err_message = "Invalid Number: "s + std::to_string(num);
这样,可以让编译器在构造时调用带长度的构造函数,免去一次使用strlen获取长度的开销。
上古时代的std::string_view及其类似实现
所谓“上古时代”,指的是C++11之前的C++98时代,当时标准库还没有这么充实,开发时需要用到的一些库需要自己实现。那时候一些注重效率的程序就提供了这类的库作为附属实现。如:
- LevelDB提供的Slice实现
- RocksDB提供的Slice实现,这两者的实现原理大致一样,只是接口功能略有出入。
- Google开源的基础库Abseil中的string_view,据说这个库是C++17的string_view库的前身,浏览了一下似乎没有发现
operator sv()的重载。
我的项目中用到的std::string_view的类似实现:针对libhiredis
在上古时代,我的项目中也用到类似std::string_view这种“轻量级字符串”的功能,下面晒晒代码,说说使用这种设计的初衷。
在项目中,我需要用到redis库hiredis,经常需要从库里面取得字符串。比如这样的操作:从redis中scan出一堆key,然后从redis中取出这些key,这些key-value有可能用于输出,有可能用于返回。hiredis是一个C库,快速而简单,然而我不希望在我的应用层库中处理太多细节(诸如分析返回数据的类型,然后又进行错误处理,等等),因为那样会造成大量重复代码(对返回数据的处理),而且会让应用层代码变得很臃肿。于是我自己写了一个简单的adaptor,实现了使用C++的string、vector等类作为参数对hiredis的调用。那么redis返回的字符串,如果封装成std::string,字符串的拷贝会成为瓶颈(因为项目中的value部分是一些稍长的字符串),而且这些来自redis的value返回到应用层只会做一些json解析、protobuf解析之类的操作就被释放掉,所以这就考虑到字符串的拷贝和释放完全是重复劳动,于是自己设计了一个基于RedisReply的Slice实现。
下面只贴出头文件,实现部分就不多贴出来占地方了(代码其实是使用C++11开发的,但是类似的实现可以在C++98中轻易做到,在这里作为一个例子并不过分=_=):
//字符串
//创建这个类,是因为在性能调优的时候发现,生成字符串太多,影响性能
class Slice
{
public:
Slice() = default;
~Slice() = default;
Slice(const char* str, size_t len,
const std::shared_ptr<const redisReply>& reply): str_(str), len_(len), reply_(reply) {}
Slice(const char* str, size_t len):str_(str), len_(len) {}
//下面几个接口,兼容std::string
const char* c_str() const {return str_;}
const char* data() const {return str_;}
size_t length() const {return len_;}
bool empty() const {return str_ == NULL || len_ == 0;}
bool begin_with(const std::string& str) const;
std::string to_string() const;
bool operator==(const char* right) const;
bool operator==(const Slice& right) const;
bool operator!=(const char* right) const;
bool operator!=(const Slice& right) const;
private:
//字符串
const char* str_{NULL};
size_t len_{0};
//字符串所属的Redis返回报文
std::shared_ptr<const redisReply> reply_;
};
之所以不重用LevelDB的Slice,是因为这些字符串都是struct redisReply中分配的,所以使用shared_ptr管理struct redisReply对象,这样就可以不需要担心struct redisReply的释放问题了。
为了这个类的使用方式兼容std::string、Slice,我使用模板实现,下面是我的Redis适配层的实现(局部):
/**********头文件************/
class CustomizedRedisClient
{
public:
//GET
template<class StringType>
std::pair<Status, Slice> get(const StringType& key)
{
return this->get_impl(key.data(), key.length());
}
//....
};
/***********这部分在代码部分实现***********/
//GET实现
//CustomizedRedisClient::Status是另外实现的一个状态码,不在这里讲述
std::pair<CustomizedRedisClient::Status, CustomizedRedisClient::Slice>
CustomizedRedisClient::get_impl(const char* key, size_t key_len)
{
constexpr size_t command_item_count = 2;
const char* command_str[command_item_count];
size_t command_len[command_item_count];
command_str[0] = "GET";
command_len[0] = 3;
command_str[1] = key;
command_len[1] = key_len;
//reply
//get_reply()函数使用redisAppendCommandArgv()和redisGetReply()函数实现,参考libhiredis文档,这样做是为了兼顾key/value中可能有二进制字符
const auto& reply_status = this->get_reply(command_str, command_len, command_item_count);
const redisReply* reply = reply_status.first.get();
if(reply == NULL)
{
return std::make_pair(reply_status.second,
CustomizedRedisClient::Slice());
}
else if(reply->type == REDIS_REPLY_STATUS
|| reply->type == REDIS_REPLY_ERROR)
{
return std::make_pair(CustomizedRedisClient::Status(std::string(reply->str, reply->len)),
CustomizedRedisClient::Slice());
}
else if(reply->type == REDIS_REPLY_NIL)
{
return std::make_pair(CustomizedRedisClient::Status(STATUS_NOT_FOUND),
CustomizedRedisClient::Slice());
}
else if(reply->type != REDIS_REPLY_STRING)
{
return std::make_pair(CustomizedRedisClient::Status(STATUS_INVALID_MESSAGE),
CustomizedRedisClient::Slice());
}
return std::make_pair(CustomizedRedisClient::Status(),
CustomizedRedisClient::Slice(reply->str, reply->len, reply_status.first));
}
后记
追本溯源,是一个极客的优秀素质。
作为C++17文章的第一篇,略显啰嗦,希望以后有恒心把自己的研究成果一直进行下去。
C++17剖析:string_view的实现,以及性能的更多相关文章
- C++17剖析:string在Modern C++中的实现
概述 GCC 8.2提供了两个版本的std::string:一个是基于Copy On Write的,另一个直接字符串拷贝的.前者针对C++11以前的,那时候没有移动构造,一切以效率为先,需要使用COW ...
- 2018/09/17《涂抹MySQL》【性能优化及诊断】学习笔记(七)
读 第十三章<MySQL的性能优化与诊断> 总结 一说性能优化,整个人都像被打了鸡血一样
- MySQL性能剖析工具(pt-query-digest)【转】
这个工具同样来自percona-toolkit 该工具集合的其他工具 MySQL Slave异常关机的处理 (pt-slave-restart) 验证MySQL主从一致性(pt-table-chec ...
- 20个Linux服务器性能调优技巧
Linux是一种开源操作系统,它支持各种硬件平台,Linux服务器全球知名,它和Windows之间最主要的差异在于,Linux服务器默认情况下一般不提供GUI(图形用户界面),而是命令行界面,它的主要 ...
- 高性能MySQL第2,3章性能相关 回顾笔记
1. 基准测试(benchmark) 不管是新手还是专家都要熟悉基准测试,benchmark测试是对系统的一种压力测试,目标是为了掌握在特定压力下系统的行为.也有其他原因:如重现系统状态,或者是 ...
- Linux服务器性能查看分析调优
一 linux服务器性能查看 1.1 cpu性能查看 1.查看物理cpu个数: cat /proc/cpuinfo |grep "physical id"|sort|uniq|wc ...
- 【转】linux服务器性能查看
转载自https://blog.csdn.net/achenyuan/article/details/78974729 1.1 cpu性能查看 1.查看物理cpu个数: cat /proc/cpuin ...
- Linux服务器性能分析与调优
一 linux服务器性能查看 1.1 cpu性能查看 1.查看物理cpu个数: cat /proc/cpuinfo |grep "physical id"|sort|uniq|wc ...
- linux服务器性能查看
1.1 cpu性能查看 1.查看物理cpu个数: cat /proc/cpuinfo |grep "physical id"|sort|uniq|wc -l 2.查看每个物理cpu ...
随机推荐
- [Swift]LeetCode844. 比较含退格的字符串 | Backspace String Compare
Given two strings S and T, return if they are equal when both are typed into empty text editors. # m ...
- Java数据结构和算法 - 什么是2-3-4树
Q1: 什么是2-3-4树? A1: 在介绍2-3-4树之前,我们先说明二叉树和多叉树的概念. 二叉树:每个节点有一个数据项,最多有两个子节点. 多叉树:(multiway tree)允许每个节点有更 ...
- 机器学习入门16 - 多类别神经网络 (Multi-Class Neural Networks)
原文链接:https://developers.google.com/machine-learning/crash-course/multi-class-neural-networks/ 多类别分类, ...
- 10.Git分支-分支管理(git branch命令)、分支开发工作流
1.分支管理 git branch 不仅可以创建和删除分支,还可以做一些其他工作. 1.不带参数的 git branch ,得到本地仓库当前的分支列表.并且会显示,当期所在的分支,也就是HEAD所指 ...
- tensorflow 1.0 学习:十图详解tensorflow数据读取机制
本文转自:https://zhuanlan.zhihu.com/p/27238630 在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找 ...
- Solaris 11 配置IP地址
查看ipipadm show-addr 删除IP地址ipadm delete-addr net0/v4 配置IP地址ipadm create-addr –T static –a local=10.90 ...
- asp.net core AuthenticationMiddleware 在WebApi中的的使用
在.net framework 4.5架构下使用认证(Authentication)授权(Authorization). IIS使用HttpModule进行认证(Authentication),我们可 ...
- asp.net core 系列 18 web服务器实现
一. ASP.NET Core Module 在介绍ASP.NET Core Web实现之前,先来了解下ASP.NET Core Module.该模块是插入 IIS 管道的本机 IIS 模块(本机是指 ...
- arrays.xml中使用integer-array引用drawable图片资源,代码中如何将这些图片资源赋值到ImageView控件中
当我们在arrays.xml文件中声明一些图片资源数组的时候: <?xml version="1.0" encoding="utf-8"?> < ...
- JS执行环境,作用域链及非块状作用域
JS中的执行环境,顾名思义就是变量或函数所执行时的环境.在我的理解中,执行环境和作用域相差不大. 每个函数都有自己的执行环境,当执行流进入一个函数时,函数的环境就会被推入一个环境栈中.而在函数执行之后 ...