4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言
之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松、忆臻、nebulaf91等人的博客以及李航老师的《统计学习方法》后,豁然开朗,于是在此记下一些心得体会。
“最大似然估计”(Maximum Likelihood Estimation, MLE)与“最大后验概率估计”(Maximum A Posteriori Estimation,MAP)的历史可谓源远流长,这两种经典的方法也成为机器学习领域的基础被广泛应用。
有趣的是,这两种方法还牵扯到“频率学派”与“贝叶斯学派”的派别之争,前者认为一件事情发生概率的推断必须依靠数据说话,即认为世界是确定的,我们可以通过重复的大量的数据统计而使结果逼近真实的情况。后者认为世界是不确定的,我们需要对这个世界做出一个预判,然后通过数据的统计去不断地修正这个预判,最终使的概率分布能够最优化的解释这个世界。
2.统计学习三要素
前面讲到的MLE与MAP,其实是统计模型优化求解中众多步骤中的一步。而统计模型是统计学习三要素之一。
统计学习(statistical learning)是利用计算机技术基于数据构建概率统计模型并对数据进行预测及分析的一门学科,即传统意义上的统计机器学习。
统计学习的三要素为:模型(model)、策略(strategy)、算法(algorithm)。
输入空间或者特征空间与输出空间之间所有可能的映射情况成为假设空间,而映射之所以存在是因为统计学习假设输入值与输出值是根据联合概率密度P(X,Y)独立同分布产生的。而模型就是假设空间中的一种特殊情况,当然假设空间中的模型有无数种。
策略就是一种在无限的模型当中找出一种符合当前数据分布的模型的方法,目标是从假设空间中寻找出最优模型。通过定义损失函数或者代价函数来达到这一目的。损失函数是模型预测值f(X)和真值Y的非负实值函数,L(f(X), Y)。
对于监督学习来说,常用的损失函数有0 1损失函数、绝对值损失函数、对数损失函数、平方损失函数等。
算法既是根据已有的策略如何最优化我们的模型,把统计学习问题总结为最优化问题。
3.最大似然估计与最大后验概率
在上面提到的统计学习三要素之一的策略当中,我们已经找到了衡量模型预测结果的方式,即通过损失函数。通过统计损失函数的期望值并使其最小,可以达到最优化函数的左右。
损失函数的期望如下:
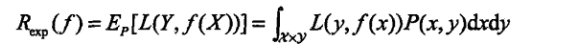
其中P(x,y)是输入值X和输出值Y的联合概率密度分布,我们并不清楚,所以这是期望风险,即理论上真实的损失函数风险值。
期望风险我们无法获知,但是我们可以通过大量实验获得很多损失函数值,对于求平均可以得到经验风险。根据大数定理,当损失函数值趋近于无穷时,经验风险等价于期望风险。

当模型是条件概率分布,损失函数是对数损失函数时,此时的经验风险就是最大似然估计。
最大似然估计就是我们根据已有数据的特征,来推断出现该特征的模型参数 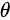 ,目标是使参数的取值使得该数据的分布最符合这种特征。
,目标是使参数的取值使得该数据的分布最符合这种特征。
形象点说,一罐子球,里面有黑白两色,我们有放回的取出100个,其中70个是白球,那么我们根据最大似然估计推断该罐子中70%是白球,因为这种分布情况下我们最有可能取出70个白球(在100个球中)。
最大似然估计是求参数θ, 使似然函数P(x0|θ)最大。最大后验概率估计则是想求θ,使P(x0|θ)P(θ)最大。
因为贝叶斯派认为,光统计事件发生的概率是不全面的,还需要在考虑该事件发生本身的概率,及先验概率。也就是说,虽然一件事情发生于某一个现象关联十分巨大,但是该事件本身发生的概率极小,我们也应当慎重考虑。举个栗子:发现刚才写的代码编译报错,可是我今天状态特别好,这语言我也很熟悉,犯错的概率很低。因此觉得是编译器出错了。 ————别,还是先再检查下自己的代码吧。
这在模型防止过拟合中也起到了很关键的作用。
L1、L2正则化
模型在训练数据表现很好,在测试数据表示很差为过拟合(overfitting)。如果训练数据表现很差则为欠拟合。如下图所示:

欠拟合可以增加模型复杂度,增加模型训练次数等方法解决,这里主要讲过拟合。
过拟合就是为了是模型在训练数据上表示很好而强行增加了模型的复杂度,使得其普适能力差。
为了解决过拟合,可以通过添加惩罚项来解决。此时称为结构风险,而模型的最后变成使结构风险最小化问题。
 其中J(f)为模型的复杂度。
其中J(f)为模型的复杂度。
而当模型的复杂度为模型的先验概率,损失函数是对数损失函数时,此时的结构风险最小化问题即变为最大后验概率估计问题。
而模型的复杂度用什么来衡量的,简单来说既是模型参数的多少,参数越多,模型越复杂,反之越简单。而衡量模型参数多少可以通过0范数、1范数及2范数来解决。
0范数指非零向量个数。1范数指绝对值之和。2范数指通常意义上的模。
使0范数最小及实现模型参数最小。而人们发现在求解过程中0范数求解难度较高,而1范数和0范数可以实现稀疏,1因具有比L0更好的优化求解特性而被广泛应用。L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的正则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦;所以大家比起1范数,更钟爱2范数。
正则化——即使模型结构风险最小的过程。
L1正则化即使L1范数的正则项最小。
L2正则化即使L2范数的正则项最小。
4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化的更多相关文章
- 统计学习三:1.k近邻法
全文引用自<统计学习方法>(李航) K近邻算法(k-nearest neighbor, KNN) 是一种非常简单直观的基本分类和回归方法,于1968年由Cover和Hart提出.在本文中, ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- 【模式识别与机器学习】——PART2 机器学习——统计学习基础——Regularized Linear Regression
来源:https://www.cnblogs.com/jianxinzhou/p/4083921.html 1. The Problem of Overfitting (1) 还是来看预测房价的这个例 ...
- 统计学习三:2.K近邻法代码实现(以最近邻法为例)
通过上文可知k近邻算法的基本原理,以及算法的具体流程,kd树的生成和搜索算法原理.本文实现了kd树的生成和搜索算法,通过对算法的具体实现,我们可以对算法原理有进一步的了解.具体代码可以在我的githu ...
- ML 03、机器学习的三要素
机器学习算法原理.实现与实践——机器学习的三要素 1 模型 在监督学习中,模型就是所要学习的条件概率分布或决策函数.模型的假设空间包含所有可能的条件概率分布或决策函数.例如,假设决策函数是输入变量的线 ...
- WebService基础学习(二)—三要素
一.Java中WebService规范 JAVA 中共有三种WebService 规范,分别是JAX-WS.JAX-RS.JAXM&SAAJ(废弃). 1.JAX-WS规范 ...
- 小白学习之pytorch框架(3)-模型训练三要素+torch.nn.Linear()
模型训练的三要素:数据处理.损失函数.优化算法 数据处理(模块torch.utils.data) 从线性回归的的简洁实现-初始化模型参数(模块torch.nn.init)开始 from torc ...
- [译]针对科学数据处理的统计学习教程(scikit-learn教程2)
翻译:Tacey Wong 统计学习: 随着科学实验数据的迅速增长,机器学习成了一种越来越重要的技术.问题从构建一个预测函数将不同的观察数据联系起来,到将观测数据分类,或者从未标记数据中学习到一些结构 ...
- 机器学习&深度学习经典资料汇总,data.gov.uk大量公开数据
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
随机推荐
- C++11 move语意
C++11带来的move语义 C++11引入了move语义,stl中的容器基本都支持move语义,因此我们在使用stl中的容器的时候,就已经使用过move语义了,在网上看了不少关于mo ...
- 『Tarjan算法 无向图的割点与割边』
无向图的割点与割边 定义:给定无相连通图\(G=(V,E)\) 若对于\(x \in V\),从图中删去节点\(x\)以及所有与\(x\)关联的边后,\(G\)分裂为两个或以上不连通的子图,则称\(x ...
- dotnet core 开发无缝兼容Http和Websocket协议的接口服务
在应用接口开发中往往要针对不同协义开发相应的代理服务,但对于Websocket和http这两种协议来说就有些不同,从实现上来看Websocket可以说是Http的升级子协议, 两者在协议处理上基本一致 ...
- 前后端数据加密传输 RSA非对称加密
任务需求:要求登陆时将密码加密之后再进行传输到后端. 经过半天查询摸索折腾,于是有了如下成果: 加密方式:RSA非对称加密.实现方式:公钥加密,私钥解密.研究进度:javascript与java端皆已 ...
- logback配置信息
<?xml version="1.0" encoding="UTF-8"?> <configuration scan="true&q ...
- SQL修改表字段,加附属属性
GO Go EXEC sys.[sp_addextendedproperty] @name = 'MS_Description',@value = '是否填写表单',@level0type = 'SC ...
- JS引擎线程的执行过程的三个阶段(二)
继续JS引擎线程的执行过程的三个阶段(一) 内容, 如下: 三. 执行阶段 1. 网页的线程 永远只有JS引擎线程在执行JS脚本程序,其他三个线程只负责将满足触发条件的处理函数推进事件队列,等待JS引 ...
- Windows已遇到关键问题,将在一分钟后自动重新启动,请立即保存工作
Windows已遇到关键问题,将在一分钟后自动重新启动,请立即保存工作 1. 把电脑右下角网络断开 2.同时按 "WIN+R" 打开“运行”命令窗口 输入“cmd”命令,按回车键“ ...
- 服务器控件的几个属性 SelectedIndex、SelectedItem、SelectedValue、SelectedItem.Text、selectedItem.value
转自http://blog.csdn.net/iqv520/article/details/4419186 1. SelectedIndex ——选项的索引,为int,从0开始,可读可写 2. Sel ...
- EF 批量 添加 修改 删除
1批量添加 db.T_Investigator.AddRange(list) 2批量删除 db.T_Investigator.RemoveRange(list) 3批量修改 for 循 ...