027 storm面试小题
1.大纲
Storm工作原理是什么?
流的模式是什么?默认是什么?
对于mapreduce如何理解?
Storm的特点和特性是什么?
Storm组件有哪些?
2.Storm工作原理是什么?
相对于hadoop而言,strom的优势在于对于应对大数据两的实时数据处理上,因为hadoop在处理大数据过程中高延时的特点使得其面对实时数据缺乏足够的应对策略,目前strom已经被广泛的应用在诸如金融系统,实时推送系统,预警系统,网站统计等多个场景中,他可伸缩性高,不存在数据丢失,高容错性,高健壮性等特点都使得他在未来拥有更广阔的天地。
以消息队列作为核心技术,使用消息队列作为实时处理系统的数据源,而在消费者那端,使用死循环对消息队列进行监控,使得数据得以实时的被处理和存储。
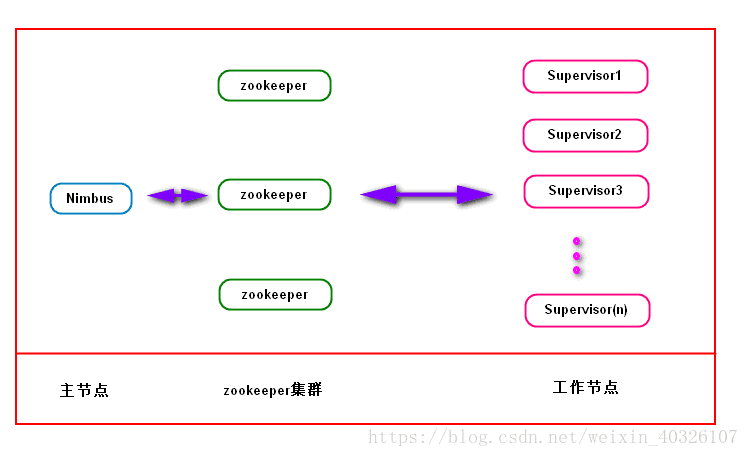
1)集群是基于zookeeper集群存在的,Nimbus和Supervisor都是依赖于zookeeper建立的
2)主节点和工作节点的具体状态都保存在zookeeper中,主节点通过查看工作节点的状态文件是否存在判断工作节点的连接状态
3)主节点和工作接待点之间通过zookeeper集群进行协调,这使得Nimbus和Supervisor之间没有耦合,同时也提高了系统的健壮性
bolt是作为一个消息处理者的角色存在的,它存在的主要作用有两个:接收处理数据和发送数据给下一个bolt。
Bolt处理Stream内部的tuple,bolt可以消费任意数量的输入流,只要将流的方向导入到该blot,同时他也可以发送新的流给其他的bolt。
Bolts处理一个输入tuple,然后调用ack通知strom自己已经处理过这个tuple了,Storm提供一个IBasicBolt会自动调用ack。
Bolts使用OutputCollector来发射tuple到下一级Bolt。
Tuple:Strom将stream中的元素抽象为tuple,每一个tuple都是一个Key List形式的值列表,每一个key都有一个名称name,并且这个可以是一个任意可序列化的类型
3.流的模式是什么?默认是什么?
流是Storm中的核心抽象。一个流由无限的元组序列组成,这些元组会被分布式并行地创建和处理。通过流中元组包含的字段名称来定义这个流。
每个流声明时都被赋予了一个ID。只有一个流的Spout和Bolt非常常见,所以OutputFieldsDeclarer提供了不需要指定ID来声明一个流的函数(Spout和Bolt都需要声明输出的流)。这种情况下,流的ID是默认的“default”。
4.Storm Group分类
Shuffle Grouping
随机分组, 随机派发stream里面的tuple, 保证bolt中的每个任务接收到的tuple数目相同.(它能实现较好的负载均衡)
Fields Grouping
按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到同一任务, 而不同的userid则会被分配到不同的任务
All Grouping
广播发送,对于每一个tuple,Bolts中的所有任务都会收到.
Global Grouping
全局分组,这个tuple被分配到storm中的一个bolt的其中一个task.再具体一点就是分配给id值最低的那个task.
Non Grouping
随机分派,意思是说stream不关心到底谁会收到它的tuple.目前他和Shuffle grouping是一样的效果,
Direct Grouping
直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者具体由消息接收者的哪个task处理这个消息.只有被声明为Direct Stream的消息流可以声明这种分组方法.而且这种消息tuple必须使用emitDirect方法来发射.消息处理者可以通过TopologyContext来或者处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)
localOrShuffleGrouping
是指如果目标Bolt 中的一个或者多个Task 和当前产生数据的Task 在同一个Worker 进程里面,那么就走内部的线程间通信,将Tuple 直接发给在当前Worker 进程的目的Task。否则,同shuffleGrouping。(在工作中使用的频率还是比较高的)
CustomStreamGrouping
自定义流式分组。
5.对于mapreduce如何理解?
- 编程简单:开发人员只需要关注应用逻辑,而且跟Hadoop类似,Storm提供的编程原语也很简单
- 高性能,低延迟:可以应用于广告搜索引擎这种要求对广告主的操作进行实时响应的场景。
- 分布式:可以轻松应对数据量大,单机搞不定的场景
- 可扩展: 随着业务发展,数据量和计算量越来越大,系统可水平扩展
- 容错:单个节点挂了不影响应用
- 消息不丢失:保证消息处理
不过Storm不是一个完整的解决方案。使用Storm时你需要关注以下几点:
- 如果使用的是自己的消息队列,需要加入消息队列做数据的来源和产出的代码
- 需要考虑如何做故障处理:如何记录消息队列处理的进度,应对Storm重启,挂掉的场景
- 需要考虑如何做消息的回退:如果某些消息处理一直失败怎么办?
7.Storm组件有哪些?

Nimbus(主节点):负责资源分配和任务调度。
Supervisor(从节点):负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。---通过配置文件设置当前supervisor上启动多少个worker。worker的数量根据端口号来的!
Worker(进程):运行具体处理组件逻辑的进程(其实就是一个JVM)。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Task(线程):worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。task=线程=executor
Zookeeper(分布式协调服务) :保存任务分配的信息、心跳信息、元数据信息。
8.编程模型
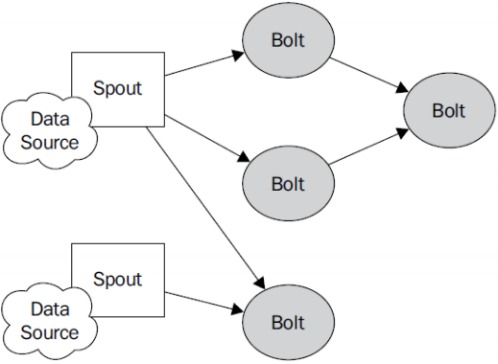
Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
Spout:在一个topology中获取源数据流的组件。 通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
Stream:表示数据的流向。
027 storm面试小题的更多相关文章
- iOS面试小题集锦
1.Object-C有多继承吗?没有的话用什么代替? cocoa 中所有的类都是NSObject 的子类 多继承在这里是用protocol 委托代理 来实现的你不用去考虑繁琐的多继承 ,虚基类的概 ...
- (转载)Autodesk面试技术题解答
Autodesk面试技术题解答 By SmartPtr(http://www.cppblog.com/SmartPtr/) 近一年以来,AUTODESK的面试题在网上是闹的沸沸扬扬, ...
- 一些js小题(一)
一些js小题,掌握这些对于一些常见的面试.笔试题应该很有帮助: var a=10; function aa(){ alert(a); } function bb(){ aa(); } bb();//1 ...
- WEB前端面试真题 - 2000!大数的阶乘如何计算?
HTML5学堂-码匠:求某个数字的阶乘,很难吗?看上去这道题异常简单,却不曾想里面暗藏杀机,让不少前端面试的英雄好汉折戟沉沙. 面试真题题目 如何求"大数"的阶乘(如1000的阶乘 ...
- Linux运维跳槽必备的40道面试精华题(转)
Linux运维跳槽必备的40道面试精华题(转) 下面是一名资深Linux运维求职数十家公司总结的Linux运维面试精华,助力大家年后跳槽找个高薪好工作. 1.什么是运维?什么是游戏运维? 1)运维 ...
- Linux运维跳槽40道面试精华题
Linux运维跳槽40道面试精华题 运维派 3天前 1.什么是运维?什么是游戏运维? 1)运维是指大型组织已经建立好的网络软硬件的维护,就是要保证业务的上线与运作的正常,在他运转的过程中,对他进行维护 ...
- 2018最新大厂Android面试真题
前言 又到了金三银四的面试季,自己也不得不参与到这场战役中来,其实是从去年底就开始看,android的好机会确实不太多,但也还好,3年+的android开发经历还是有一些面试机会的,不过确实不像几年前 ...
- 数据结构+算法面试100题~~~摘自CSDN
数据结构+算法面试100题~~~摘自CSDN,作者July 1.把二元查找树转变成排序的双向链表(树) 题目:输入一棵二元查找树,将该二元查找树转换成一个排序的双向链表.要求不能创建任何新的结点,只调 ...
- 剑指offer 面试10题
面试10题: 题目:大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项.n<=39 n=0时,f(n)=0 n=1时,f(n)=1 n>1时,f(n)=f(n-1 ...
随机推荐
- SpringBoot入门:Hello World
1.Open IDEA,choose "New-->Project" 2.Choose "Spring Initializr" 3. Choose jav ...
- redis3.2.10单实例安装测试
redis3.2.10单实例安装测试 主要是实际使用环境中使用,为了方便快速部署,特意记录如下: # root用户 yum -y install make gcc-c++ cmake bison-de ...
- c++ boost库配置
1.官方下载地址 https://www.boost.org/ 2.下载解压 3.配置VS 4.配置目录
- hadoop记录-如何换namenode机器
namenode机器磁盘IO负载持续承压,造成NAMENODE切换多次及访问异常. 1 初始化新机器1.1 在新器1.1.1.3部署hadoop软件(直接复制standby1.1.1.2节点)1.2 ...
- 服务器代理+jQuery.ajax实现图片瀑布流
服务器代理机制破解浏览器的同源策略 瀑布流功能实现分析 具体实现代码及业务实现分析 一.服务器代理机制破解浏览器同源策略 由于浏览器的同源策略无法请求不同域名下的资源,但是服务器的后台程序并不受同源策 ...
- Ext.net MessageBox提示
Ext.MessageBox.confirm("选择全部", "确定选择?", function (btn) { if (btn !== "yes&q ...
- 2019第十二届全国大学生信息安全实践创新赛线上赛Writeup
本文章来自https://www.cnblogs.com/iAmSoScArEd/p/10780242.html 未经允许不得转载! 1.MISC-签到 下载附件后,看到readme.txt打开后提 ...
- 文件的暂存(git add)
如果我们更改了之前已经被跟踪的main.c,然后执行git status $ git status On branch master Changes not staged for commit: (u ...
- selenium模块
一 介绍 二 安装 三 基本使用 四 选择器 五 等待元素被夹在 元素交互操作 其他 项目联 一 介绍 selenium最初是一个自动化测试的工具,而爬虫中使用它主要是为了解决requests无法直接 ...
- Light OJ 1343 - Aladdin and the Black Stones
题目 link 求偶数子序列 满足 的个数. 分析 首先, 我们先把每一对a[i] + a[j]存起来, 这样就可以把题目的偶数个条件无视了. 设 T[i,j] = a[i] + a[j]; 因为我们 ...