C3D视频特征提取
一.部署
1. 先把项目Clone下来
git clone https://github.com/jfzhang95/pytorch-video-recognition.git
2. 安装环境:
PyTorch 的安装可以参考这里https://pytorch.org/
pip install opencv-python tqdm scikit-learn tensorboardX
3.下载C3D预训练模型:
在项目目录下新建一个models目录,用来存放预训练模型
百度云地址:https://pan.baidu.com/s/1saNqGBkzZHwZpG-A5RDLVw
GoogleDrive:https://drive.google.com/file/d/19NWziHWh1LgCcHU34geoKwYezAogv9fX/view?usp=sharing
二.准备数据
本次实验用的是公开数据集UCF101,
下载地址:https://www.crcv.ucf.edu/datasets/human-actions/ucf101/UCF101.rar
如果是自己准备数据,按照下面方法来做
在项目目录下创建一个data目录,将数据集放在data目录下,每一个视频分类为一个文件夹,视频名称以v开头,”_”分隔,中间为类别名称,g01,g02依次类推,如果视频太长就分割成多个,名称在g01后再加上c01,c02以此类推,每个视频大小控制在500k内。结构如下:
data
├──UCF-101
├── ApplyEyeMakeup
│ ├── v_ApplyEyeMakeup_g01_c01.avi
│ └── ...
├── ApplyLipstick
│ ├── v_ApplyLipstick_g01_c01.avi
│ └── ...
└── Archery
│ ├── v_Archery_g01_c01.avi
│ └── ...
视频名称参见下图:
三.训练模型
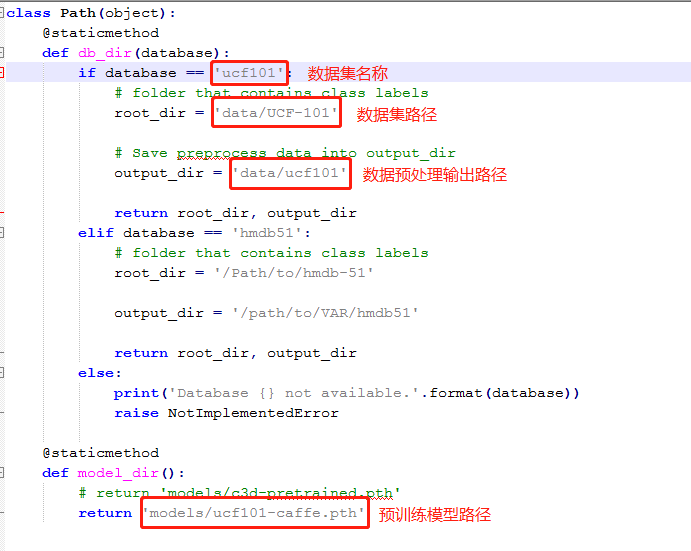
1. 修改数据集和预训练模型路径,在mypath.py文件中需要改四个位置,参考下图:
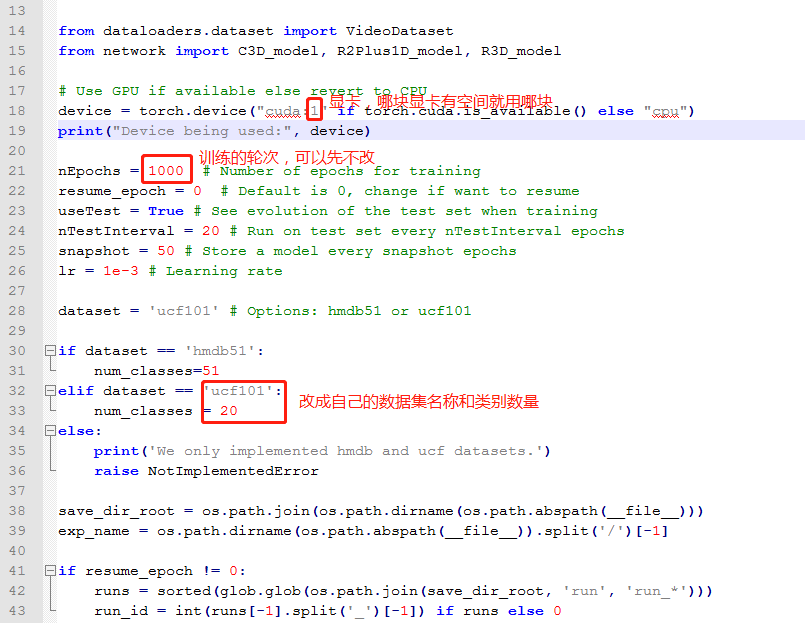
2. 训练模型,在train.py文件中需要修改
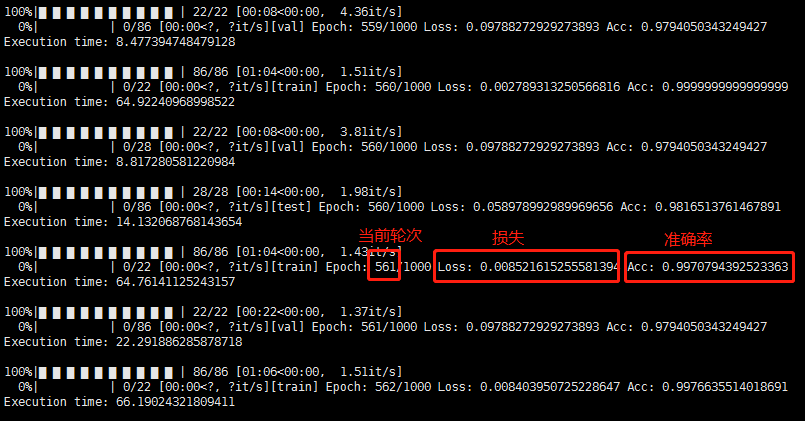
训练过程中的输出:
训练完成后会在run文件夹中生成模型,run目录下最后一个文件夹就是最新模型路径
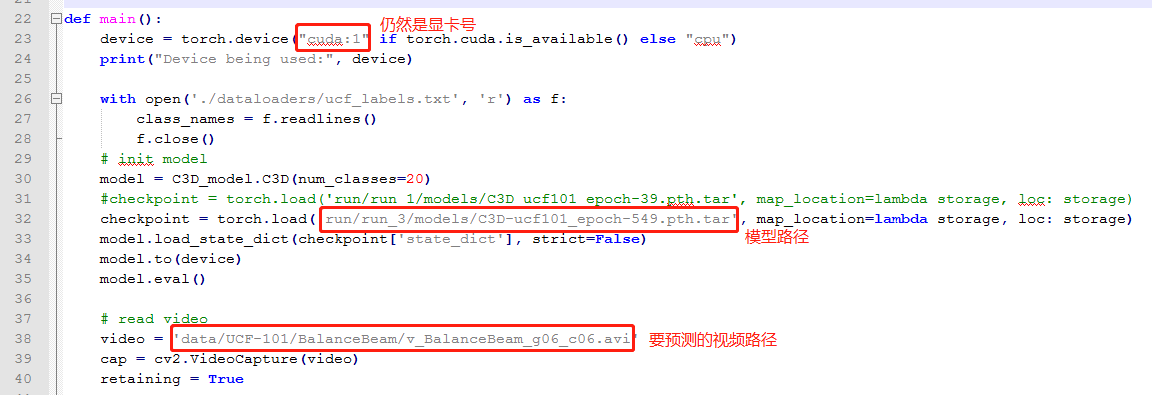
3. 预测,修改inference.py文件
测试结果:

C3D视频特征提取的更多相关文章
- 提取C3D视频特征(官方文档&实践)
C3D Introduction 卷积神经网络(CNN)近年被广泛应用于计算机视觉中,包括分类.检测.分割等任务.这些任务一般都是针对图像进行的,使用的是二维卷积(即卷积核的维度为二维).而基于视频的 ...
- paper 69:Haar-like矩形遍历检测窗口演示Matlab源代码[转载]
Haar-like矩形遍历检测窗口演示Matlab源代码 clc; clear; close all; % Haar-like特征矩形计算 board = 24 % 检测窗口宽度 num = 24 % ...
- A simple test
博士生课程报告 视觉信息检索技术 博 士 生:施 智 平 指导老师:史忠植 研究员 中国科学院计算技术研究所 2005年1月 目 ...
- (转)Haar-like矩形遍历检测窗口演示Matlab源代码
from:http://blog.sina.com.cn/s/blog_736aa0540101kzqb.html clc; clear; close all; % Haar-like特征矩形计算 b ...
- C3D使用指南
C3D GitHub项目地址:https://github.com/facebook/C3D C3D 官方用户指南:https://goo.gl/k2SnLY 1. C3D特征提取 1.1 命令参数介 ...
- Atitti 图像处理 特征提取的科技树 attilax总结
Atitti 图像处理 特征提取的科技树 attilax总结 理论 数学,信号处理,图像,计算机视觉 图像处理 滤波 图像处理 颜色转换 图像处理 压缩编码 图像处理 增强 图像处理 去模糊 图像处理 ...
- python特征提取——pyAudioAnalysis工具包
作者:桂. 时间:2017-05-04 18:31:09 链接:http://www.cnblogs.com/xingshansi/p/6806637.html 前言 语音识别等应用离不开音频特征的 ...
- [AI开发]视频多目标跟踪高级版(离自动驾驶又‘近’了一点点)
**本文恐怕不是完全的标题党** 视频多目标跟踪需要解决的关键点是前后两帧之间的Target Association,这是最难的环节(没有之一).第T帧检测到M个目标,第T+S(S>=1)帧检测 ...
- Papers | 图像/视频增强 + 深度学习
目录 I. ARCNN 1. Motivation 2. Contribution 3. Artifacts Reduction Convolutional Neural Networks (ARCN ...
随机推荐
- linux下磁盘管理(du、df)命令使用
DF :disk free 磁盘可用量 DU: disk usage 磁盘使用 df:列出文件系统的整体磁盘使用量: df参数: -a:列出所有的文件系统,包括系统特有的/proc等文件系统 -k:以 ...
- s21day21 python笔记
s21day21 python笔记 一.内容回顾及补充 内置函数补充 type():查看数据类型 class Foo: pass obj = Foo() if type(obj) == Foo: pr ...
- Python全栈之路----常用模块----序列化(json&pickle&shelve)模块详解
把内存数据转成字符,叫序列化:把字符转成内存数据类型,叫反序列化. Json模块 Json模块提供了四个功能:序列化:dumps.dump:反序列化:loads.load. import json d ...
- Web测试常见问题点汇总
UI测试 [目标] 确保用户可以访问产品所提供的浏览功能.符合企业或行业标准,包含用户易用性,友好性.可操作性等 [关注点] 菜单.对话框以及上边的文字.按钮.错误提示.帮助信息.图标.位置等. [常 ...
- python 迭代器 一个奇怪的解决方法
一般我们在类里面写迭代器都是如下写法: class IterableSomthing: def __iter__(self): return self def __next__(self): retu ...
- 网络操作基础(one)
P12 一.什么是网络操作系统?网络操作系统具有哪些基本功能? 二.网络操作系统具有哪些特征? 三.常用的网络操作系统有哪些?它们各具有什么特点? 四.在网络操作系统中主要可提供哪些? ———— —— ...
- 3,列表的 深 浅 copy
如果列表只有一层,深浅copy是一样一样的,没有什么区别,你修改了copy后的列表,copy前的列表并不会随之改变. 如果列表中嵌套这列表,这是你修改了copy后第二层列表里面的元素,copy前第二层 ...
- ionic页面间跳转的动画实现
1. 在<ion-view>标签中加入: nav-direction="back"或nav-direction="forward" 2.用$stat ...
- Python爬虫初学者学习笔记(带注释)
一,安装编程工具并进入编程界面 首先去https://www.continuum.io/downloads/网站下载Anaconda工具并安装;打开cmd,输入jupyter notebook并回车( ...
- node搭建简易的websocket服务
http协议单向请求,只能客户端向服务器发送消息,然而websocket一旦双方建立连接就可以双方通信,更加深层次的用法是websocket可以做基础,然后不同的客户端可以通过websocket连接可 ...