Raft与MongoDB复制集协议比较
在一文搞懂raft算法一文中,从raft论文出发,详细介绍了raft的工作流程以及对特殊情况的处理。但算法、协议这种偏抽象的东西,仅仅看论文还是比较难以掌握的,需要看看在工业界的具体实现。本文关注MongoDB是如何在复制集中使用raft协议的,对raft协议做了哪些扩展。
阅读本文,需要对MongoDB复制集replication有一定认识,特别是replicat set protocol version。

在带着问题学习分布式系统之中心化复制集一文中,介绍了中心化副本控制协议。在raft(mongodb pv1)中,也是通过先选举出leader(primary),然后通过leader(primary)管理整个复制集。
在3.2以及之后的版本中,mongodb默认使用protocol version 1。从官方的一些资料、视频可以看到,这个是一个raft-like的协议。本文主要从leader-election和log replication这两个角度来对比mongodb rs pv1与raft,并试图分析差异的原因。
需要注意的是,本文所有对MongoDB复制集的分析都是基于MongoDb3.4
本文地址:https://www.cnblogs.com/xybaby/p/10165564.html
leader election
首先对raft协议中leader election做几点总结:
- 同一任期内最多只能投一票,先来先得
- 选举人必须比自己知道的更多(比较term,log index)
- 为了understandability,raft中节点之间没有ranking,公平参与投票
选举、投票资格
为了简化协议,使得raft更容易理解,raft中所有节点都能发起选举、参与投票。但在MongoDB中,有更为丰富的选举控制策略,我们从Replica Set Configuration就能看出来,replica set中的节点可以配置以下属性
members: [
{
_id: <int>,
host: <string>,
arbiterOnly: <boolean>,
buildIndexes: <boolean>,
hidden: <boolean>,
priority: <number>,
tags: <document>,
slaveDelay: <int>,
votes: <number>
},
...
],
- arbiterOnly: Arbiter上没有用户数据,只能投票,不能发起选举,其作用在于用尽量少的资源使得复制集中节点数目为奇数。
- hidden:虽然有数据,但对客户端不可见,可以用来做备份等其他用途。hidden的priority一定是0,因此不可以发起选举,但是可以投票
- priority:
A number that indicates the relative eligibility of a member to become a primary.priority为0时是不能发起选举的。 - votes:是否可以参与投票,mongodb复制集中最多可以有50个节点,但最多只有7个可以投票,其作用在于降低复杂度。
priority
这里再单独强调一下priority,mongodb中
Changing the balance of priority in a replica set will trigger one or more elections. If a lower priority secondary is elected over a higher priority secondary, replica set members will continue to call elections until the highest priority available member becomes primary.
通过rs.reconfig()修改节点的优先级的时候,会触发重新选举。整个复制集会不断发起选举,直到最高优先级的节点成为primary。当然,在选举-投票的过程中,还是必须满足候选者数据足够新的约束。
priority很有用,比如在multi datacenter deploy的情况下,我们可能根据用户的分布情况来确定primary在哪个datacenter。
heartbeat
raft中,只有leader给follower发心跳信息(心跳是没有log-entry的Append Entries rpc),然后follower回复心跳消息。
Followers are passive: they issue no requests on their own but simply respond to requests from leaders and candidates.
在mongodb中,节点两两之间有心跳
Replica set members send heartbeats (pings) to each other every two seconds. If a heartbeat does not return within 10 seconds, the other members mark the delinquent member as inaccessible.

primary handover
在raft中,只有当leader收到来自term更高的节点的消息时,才会切换到follower状态。如果出现网络分割(network partition),那么这个过期的leader还会一直认为自己是leader
If a candidate or leader discovers
that its term is out of date, it immediately reverts to follower
state.
在mongodb中,primary在election timeout时间还没有收到来自majority 节点的消息时,会主动切换成secondary。这样可以避免过期的Primary(stale primary)继续对外提供服务,尤其是MongoDB允许writeConcern:1.
选举过程 - 预投票
raft中,在election timeout超时后,立即会发起选举,执行以下操作
- 增加节点本地的 current term ,切换到candidate状态
- 投自己一票
- 并行给其他节点发送 RequestVote RPCs
- 等待其他节点的回复
- 如果得到majority投票,成为leader
mongodb增加了一个预投票的过程(dry-run),即在不增加新的term的情况下先问问其他节点,是否可能给自己投票,得到大多数节点的肯定回复之后才会发起真正的选举过程。其作用在于尽可能减少不必要的主从切换,这部分后面还会提到。
log replication
复制集中,各个节点数据的一致性是必须要解决的问题。而对于客户端(应用)而言,复制集则需要承诺已提交的数据不能回滚。
同步or异步
在带着问题学习分布式系统之中心化复制集一文中,介绍了复制集中数据的两种复制方式,并分析了各自的优缺点。简而言之,同步方式可靠性更高,但可用性更差,网络延时更大;异步模式则恰好相反。
raft协议则是这两种方式的折中,当log复制到了大多数的节点就可以向客户端返回了。大多数节点既保证了数据的可靠性:数据不会被回滚;又保证了有较高的可用性:只有有超过一半节点存活整个系统就能正常工作。
MongoDB通过Write Concern选项将选择权交给了用户,用户可以根据实际情况来选择将数据复制到了多少节点再向客户端返回。writeconcern有三个参数
- w:写到多少节点即可向客户端返回
- 1,默认值,即写primary即可返回,性能最高,延迟最低
- majority,同raft,写到大多数节点才返回
- tag set,写到指定的节点才返回,用于特殊场景
- j:是否写到journal(保证持久化)
- wtimeout:多长时间如果没有写到
w个节点就向客户端返回错误
由于默认写到primary即可向客户端返回,那么不难想到,如果oplog尚未同步到secondary,primary挂掉,那么新选举出来的Primary可能没有最新的已经向客户端确认的数据,导致数据的回滚,后面会提到mongodb通过catchup来尽量避免回滚。
data flow
在带着问题学习分布式系统之中心化复制集中也给出了两种数据从primary到secondary的方式:主从模式,链式模式。其中,主从模式是priamry推送给所有的secondary,显然raft就是这种模式。
而在MongoDB中,可以通过参数settings.chainingAllowed控制使用主从模式,还是链式模式。默认值为True,即默认情况下,mongodb中secondary可以从其他secondary同步数据,这样secondary可以选择一个离自己最近(心跳延时最小的)节点来复制oplog,在MongoDB中,称oplog的同步源为SyncSource。
push or pull
raft中,leader并行将数据push到follower。而在MongoDB中,primary将数据写到local.oplog.rs,secondary定期从其SyncSource(参考上一节,不一定是从priamry拉数据,也可能是从其他secondary)读取oplog,并应用到本地。
深入浅出MongoDB复制一文中给出了一个oplog拉取的流程

MongoDB选择了pull的策略,显然会加大在writeConcern: majority时的延迟,但对于默认的链式复制,pull是更合适的,因为secondary更清楚自己的SyncSource。
append vs apply
在诸多共识算法中,都是将command封装到有序、持久化的log当中,raft和MongoD也是如此。
对于raft,leader先将log先append到本地的log entries,然后等到收到majority节点的回复后再apply log到状态机,如下入所示:

但是在mongodb中,即使客户端要求writeconcern:majority,primary也是先apply,将变更作用到状态机,再写oplog。之后,secondary再从其SyncSource的local.oplog.rs collection 拉取oplog,本地apply,然后写oplog。
MongoDB先Apply再写oplog,以及异步复制的机制,会导致即使数据无法写到大多数节点(可能primary与其他节点间网络故障),即使向客户端返回写入失败,写到primary的数据也不会回滚。
catchup
catchup既与write concern有关,也跟leader election有关。
mongodb中,有这么一个参数settings.catchUpTimeoutMillis, 其作用是
Time limit in milliseconds for a newly elected primary to sync (catch up) with the other replica set members that may have more recent writes.
The newly elected primary ends the catchup period early once it is fully caught up with other members of the set. During the catchup period, the newly elected primary is unavailable for writes from clients.
也就是说,在primary选举出来之后,会有一段时间,让primary尝试去其他节点读取到更新的写操作(more recent)。直到追加到最新的oplog,或者超时,primary才进入工作状态(接收客户端写请求)
究其原因,MongoDB允许用户自定义writeconcern,且默认只要求写到primary。因此选举的时候即使得到了大多数节点的投票,且primary的数据在这些大多数节点中是最新的,但原来的primary可能没有参与投票,那么就可能导致数据的回滚。catchup能够尽量避免回滚的出现,如果无法在settings.catchUpTimeoutMillis时间内完成catchup,也会将回滚的内容写入一个rollback文件。
差异的思考
MongoDB作为一个分布式数据库系统,既要支持OLTP,又要支持OLAP,既要满足水平伸缩,又要保证高可用、高可靠,还要支持分布式事务(Mongodb 4.x)。因此为了尽量满足不同场景下的业务需求,MongoDB提供了大量的选项,供用户选择,更加灵活。对于复制集这一块而言,选项包括但不限于:
- WriteConcern
- ReadConcern
- ReadPreference
- settings.chainingAllowed
- settings.catchUpTimeoutMillis
所以,作为MongoDB的用户,首先得清楚这些可选项的意义,然后根据自己的业务需求,合理配置。
从这些选项的默认值以及MongoDB的实现,个人觉得,在CAP这个问题上,MongoDB应该是更倾向于A(availability,可用性)的。
而诸如链式复制,Leader Priority这些特性,在分布式系统的部署层面来说都是很有用的,比如multi datacenter,很多分布式存储系统也支持同样的特性。Raft协议虽然说是为工业实现提供了很好的指导,但到具体的应用,还是得有诸多的调整和完善。
dry-run or pre-vote
MongoDB中的预投票是对raft协议很好的改进,之前,我在看Raft论文的时候也想到了一些corner case,在论文中并没有很清楚的阐述,但预投票能很好解决这些问题。
事实上,MongoDB中的预投票(dry-run)并不是独创的,在raft协议的超长版解释Consensus: Bridging Theory and Practice中,raft协议的作者就建议实现pre-vote来增加系统的鲁棒性。而在Four modifications for the Raft consensus algorithm(PS,该文的作者就是MongoDB的开发者)详细阐述了Pre-vote的原因以及实现方法。Pre-vote是为了防止一个隔离的follower不断发起选举 导致term值的激增,以及不必要的主从切换。
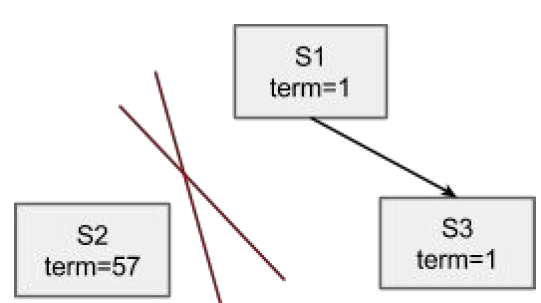
如上图所以,系统由s1 s2 s3三个节点组成,其中s1是leader,另外两个节点是follower。
pre-vote考虑的是这样一种情况,(s2)与(s1 s3)之间出现了网络分割(network partition),那么按照raft算法,s2会不断的尝试发起选举,意味着不断的增加term。那么当网络自愈之后,s2将消息发送到s1 s3. 按照raft论文figure2 Rules for servers
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower
因此s1 会切换到follower, s1 s3 term修改为57,但s2的log 大概率是过旧的(out of date),因此s2无法获得选举,s1 s3会在election timeout后发起选举,其中一个成为term 58的leader。
pre-vote 避免了term inflation,但更重要的是,避免了一次没有必要的重新选举: s1一定会切换到follower,然后s1或者s3再次发起选举,在这个过程中,由于没有leader,整个系统其实是不可用的(至少不可写)。
references
一文搞懂raft算法
replication
MongoDB and Raft
MongoDB复制集技术内幕:工作原理及新版本改进方向
MongoDB 高可用复制集内部机制:Raft 协议
Consensus: Bridging Theory and Practice
Four modifications for the Raft consensus algorithm
Raft与MongoDB复制集协议比较的更多相关文章
- MongoDB复制集与Raft协议异同点分析
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 一.日志复制流程: a.raft leader节点在接收client请求后,先将请求写到日志中,再将日志通过 ...
- MongoDB复制集成员及状态转换
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 复制集(Replica Set)是MongoDB核心组件,相比早期版本采用的主从(Master-Slave) ...
- MongoDB复制集原理
版权声明:本文由孔德雨原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/136 来源:腾云阁 https://www.qclo ...
- MongoDB复制集高可用选举机制(三)
复制集高可用选举机制 在上一章介绍了MongoDB的架构,复制集的架构直接影响着故障切换时的结果.为了能够有效的故障切换,请确保至少有一个节点能够顺利升职为主节点.保证在拥有核心业务系统的数据中心中拥 ...
- MongoDB学习4:MongoDB复制集机制和原理,搭建复制集
1.复制集的作用 1.1 MongoDB复制集的主要意义在于实现服务高可用 1.2 它的实现依赖于两个方面的功能: · 数据写入时将数据迅速复制到另一个独立节点上 · 在接收写入的 ...
- 02 . MongoDB复制集,分片集,备份与恢复
复制集 MongoDB复制集RS(ReplicationSet): 基本构成是1主2从的结构,自带互相监控投票机制(Raft(MongoDB)Paxos(mysql MGR 用的是变种)) 如果发生主 ...
- MongoDB 复制集 (一) 成员介绍
一 MongoDB 复制集简介 MongoDB的复制机制主要分为两种: Master-Slave (主从复制) 这个已经不建议使用 ...
- mongodb 复制集
mongodb 复制集 复制集简介 Mongodb复制集由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写 ...
- MongoDB复制集
1.1 MongoDB复制集简介 一组Mongodb复制集,就是一组mongod进程,这些进程维护同一个数据集合.复制集提供了数据冗余和高等级的可靠性,这是生产部署的基础. 1.1.1 复制集的目的 ...
随机推荐
- jmeter 分布式压测(windows)
单台压测机通常会遇到客户端瓶颈,受制于客户机的性能.可能由于网络带宽,CPU,内存的限制不能给到服务器足够的压力,这个时候你就需要用到分布式方案来解决客户机的瓶颈,压测的结果也会更加接近于真实情况. ...
- SpringBoot整合系列-整合H2
原创作品,可以转载,但是请标注出处地址:https://www.cnblogs.com/V1haoge/p/9959855.html SpringBoot整合H2内存数据库 一般我们在测试的时候习惯于 ...
- Ansible 入门指南 - 安装及 Ad-Hoc 命令使用
安装及配置 ansible Ansilbe 管理员节点和远程主机节点通过 SSH 协议进行通信.所以 Ansible 配置的时候只需要保证从 Ansible 管理节点通过 SSH 能够连接到被管理的远 ...
- 变量内容的删除、取代与替换 (Optional)
变量除了可以直接设置来修改原本的内容之外,有没有办法通过简单的动作来将变量的内容进行微调呢? 举例来说,进行变量内容的删除.取代与替换等!是可以的!我们可以通过几个简单的小步骤来进行变量内容的微调喔! ...
- C# 提取PPT文本和图片的实现方案
在图文混排的文档中,我们可以根据需要将文档中的文字信息或者图片提取出来,通过C#代码可以提取Word和PDF文件中的文本和图片,那么同样的,我们也可以提取PPT幻灯片当中的文本和图片.本篇文档将讲述如 ...
- Java开发笔记(五十二)对象的类型检查
前面介绍了类的多态性,来自于鸡类的实例chicken,既能用来表达公鸡实例,也能用来表达母鸡实例.可是这导致了一个问题,假如在call方法内部需要手工判断输入参数属于公鸡实例还是母鸡实例,那该如何是好 ...
- 20190321-HTML基本结构
目录 1.HTML概念 超文本标记语言 2.HTML版本 HTML HTML5 3.HTML基本结构 基本结构 元素.标签.属性 4.HTML常用标签 内容 1.HTML概念 HTML(HyperTe ...
- iOS----------使用cocoapods遇到的问题
-bash: /usr/local/bin/pod: /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/ruby: bad ...
- android Q build 变化
一 概述 android Q build变化整体上越来越严格,语法上之前能够使用的Q上将不能使用. 二 主要变化 2.1 'USER' 弃用 ‘USER’后面的值会被设置成‘nobody',andr ...
- Python大数据系列-01-关系数据库基本运算
关系数据库基本运算 .tg {border-collapse:collapse;border-spacing:0;} .tg td{font-family:Arial, sans-serif;font ...