论文阅读笔记四十:Deformable ConvNets v2: More Deformable, Better Results(CVPR2018)

论文源址:https://arxiv.org/abs/1811.11168
摘要
可变形卷积的一个亮点是对于不同几何变化的物体具有适应性。但也存在一些问题,虽然相比传统的卷积网络,其神经网络的空间形状更接近于目标物体的形状,但有时会超出ROI区域,从而引入不相关的图像信息进而对提取的特征造成影响。为此,本文提出了改造后的可变形卷积,通过增加建模及更强的训练来改善其聚焦图像相关区域的能力。通过在网路中引入更多的可变形卷积,同时,引入调制机制来扩大可变形的范围。为了有效的利用丰富的建模能力,通过一个proposed的特征模仿机制来指导网络的训练。有利于对一些特征的学习,这些特征反应目标聚焦及R-CNN特征的分类能力。
介绍
由尺寸,位置,视野,部分变形成为目标识别检测中的一个挑战。DCNv1 介绍了两个模型,(1)可变形卷积:标准卷积网格采样点的位置都是前面预处理feature map学习的偏移。(2)可变形RoIpooling,其中,偏移学习RoIPooling中的bins的位置。将上述两个模型嵌入到神经网络中可以按照目标物的特性进行特征表示,通过变形采样及池化模式来适应目标物体的结构。基于上述方法,大幅度提高了目标检测的效果。
为了理解可变形卷积,通过在VOC图像上采样点的位置上增加偏移,并可视化其引起的感受野的变化。观察发现,激活单元的采样位置多聚集在目标物体附近。然而,对目标物体的覆盖并不准确,存在感兴趣区域之外的采样点。通过COCO数据集对图像的空间支持做了深入的分析发现,上述覆盖不准确的现象更加明显,这些发现表明对可变形卷积学习还有更多的潜力。
本文提出的新型可变形卷积网络,成为Deformable ConvNet V2,通过增强的建模能力来对可变形卷积进行学习。主要通过两部分来增强模型:(1)扩大网络中可变形卷积的使用。使用更多偏移学习的卷积层,使DCNv2在更广的特征层级上进行采样。(2)可变形卷积模块的调制机制,每个采样点被学习过的偏移及特征的幅度同时进行调制。因此,网络能够改变样本点的空间分布,同时可以控制其相对影响。
为了进行有效的训练,受神经网络中知识蒸馏相关工作的启发。本文利用了“教师”网络,在进行训练时,其提供相应的指导。本文使用R-CNN作为教师网络。由于R-CNN用于对crop后的图像内容进行分类的网络,因此,不受感兴趣区域之外的信息影响。DCNv2为了模仿这个属性,在训练时增加了一个“特征模仿损失”,用于学习与R-CNN一致的相关特征。基于此方法,增强后的可变形采样为DCNv2提供了较强的训练信号。
经过上述改变后,DCNv2仍为轻量级同时可以嵌入到常规网络中,本文主要嵌在Faster R-CNN及mask R-CNN上,在COCO数据集的检测和分割任务上进行实验,均有较大改进。
可变形网络性能分析
空间支持的可视化:为了更好的理解可变形卷积,本文通过有效感受野,有效采样点位置及错误边界的显著区域,可视化了网络节点的空间支持性。上述三种模态为底层图像区域提供了不同而且互补的视角,有助于增强节点的响应。
1.有效感受野:对于一个网络中的节点,感受野中所有的像素都对响应有同等贡献。贡献度的差异由有效感受野的值表示,其值由相对图像中每个像素点的强度扰动引起的节点响应的梯度计算得到。利用感受野来检测网络节点中的独立像素的相对作用。但此标准对整个图像区域的结构影响不起作用。
2.有效 采样/bin 位置:可视化堆叠卷积层中采样点的位置及RoIPooling 采样bins来理解DCN的性能。然而,网络中节点采样位置的相对贡献没有显示出来。本文将包含相对贡献的采样位置进行可视化,并计算网络节点中对应采样点/bins位置的梯度来代表贡献强度。
3.误差限制显著区域:移除网络图像中的不发生作用的区域对网络节点的响应不会产生影响。本文可以将节点的支持区域确定为最小图像区域,在小的误差范围内提供与完整图像相同的响应。将此最小图像区域称为误差限制显著区域。可以通过逐步遮蔽图像的部分区域并计算节点响应来进行查找。误差限制显著区域利于不同网络支持区域的比较。
可变形卷积网络的空间支持:本文分析了可变形卷积在目标检测中的视觉支持区域,作为backbone 的常规卷积网络由带aligned RoIpooling的Faster R-CNN及ResNet-50组成的目标检测器。ResNet-50中的所有卷积层都应用在整个输入图像。conv5中的常规stride由32个像素减为16个像素,以增加feature map的分辨率。RPN接在ResNet-101的conv4的feature map上。将Fast R-CNN添加到conv5的后面。该Fast R-CNN由aligned RoIpooling层及两个全连接层组成,后接分类及框回归两个分支。
本文按如下操作将目标检测器变为可变形卷积部分。resnet conv5 stage中的3个3x3的卷积层替换为可变形卷积层。aligned RoIpooling替换为可变形RoIpooling。基于COCO数据集进行训练及可视化操作。当偏移学习率设置为0时,可变形Faster R-CNN检测器退化为常规的aligned RoIPooling的Faster R-CNN。
利用三种可视化模式,检查conv5 stage最后一层节点的空间支持。如下图,



观察上图,得出以下结论:(1)常规卷积在一定程度上对几何变形进行建模。有关图像内容的空间支持的变化证明了这一点。由于深度卷积网络较强的表示能力,网络权重的学习以适应某种程度的几何变换。(2)通过引入可变形卷积,网络的对几何变化的建模能力大大增强。使空间支持更适应图像的内容,前景的节点覆盖整个目标,背景上的节点包含了更大的上小文信息。然而,空间支持的范围可能是不精确的,前景节点的有效感受野和误差界限显着区域中包含与检测无关的背景区域信息。(3)提出的三种空间支持的可视化具有更多的信息。常规的卷积网络,沿着格子具有固定的采样位置,但通过其权重来调整有效空间支持。可变形卷积网络相似,其预测受学习的偏移及网络权重共同影响。而单独检查采样位置,可能会导致可变形卷积得到错误的结论。
下图展示了每个RoI检测头的两个全连接层节点的空间支持,后面直接接着两个分类及框回归分支。有效bins位置的可视化,目标前景中的bins从分类分支中得到更多的梯度,因此,对预测产生更多的影响。此结果同样适用于aligned RoIPooling及可变形RoIPooling。在可变形的RoIPooling中,由于引入了可学习的bins offset,因此,相比aligned RoIPooling,可变形RoIPooling更多的bins覆盖前景目标。来自相关的bins更多的信息可用于后续的Fast R-CNN。aligned RoIPooling及可变形RoIPooling中的误差限制显著区域并没有完全关注目标的前景,表明RoI区域外的图像内容对预测产生不利的影响。
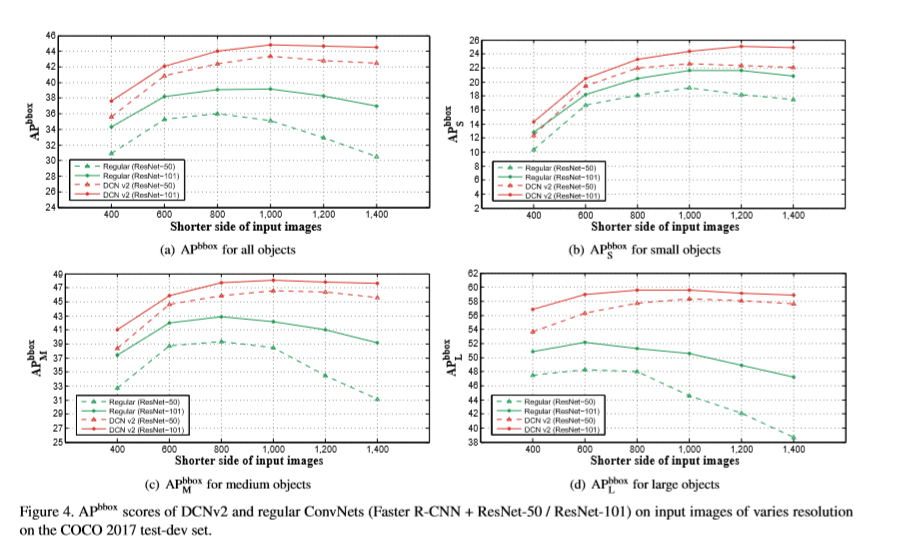
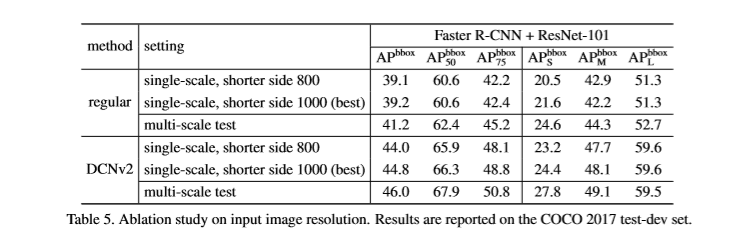
虽然,相比常规卷积网络可变形卷积提高了适应几何变化的能力,但发现其空间支持可能会超出了感兴趣区域。因此对可变形卷积改进,使其更专注于相关图像内容,进而产生更高精度的检测。

More Deformable ConvNets
堆叠更多的可变形卷积层
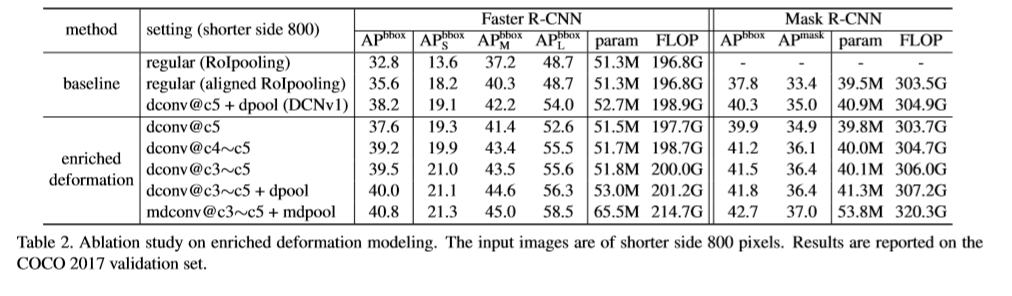
通过将常规卷积层替换为可变形卷积,堆叠更多的卷积层使整个网络对几何变化的建模能力进一步增强。本文将ResNet-50中的conv3,conv4,conv5的所有3x3卷积层替换为可变形卷积,因此网络中有12层可变形卷积层。针对如VOC小规模的数据集当对叠超过3层时,性能就会发生饱和。实验发现,替换resnet中的conv3-conv5的卷积层可以基于COCO数据集在准确率及效率上取得最好的结果。
可变形模块的调制
为了增强可变形卷积网络操纵空间支持区域的能力,引入了调制机制。可变形卷积模块不仅可以调整感知输入特征的偏移,而且可以调制来自不同空间位置/bins的输入特征幅度。极端条件下,可以设置特征幅度为0,来决定不接受来自特定位置/bins的信号。因此,来自对应空间位置的图像内容将显著减少模型的输出,甚至对输出不产生作用。因此,调制机制为网络增加了一个自由度,来调整支持区域。
给定一个具有K个采样位置的卷积核,w k,p k代表第k个位置的权重及预定义的偏移。比如K=9,及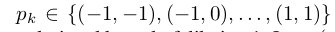 代表一个大小为3x3的卷积核,dilation为1,x(p),y(p)分别代表p位置处的输入feature maps x的特征,输出feature maps y的特征。调制可变形卷积如下表示,
代表一个大小为3x3的卷积核,dilation为1,x(p),y(p)分别代表p位置处的输入feature maps x的特征,输出feature maps y的特征。调制可变形卷积如下表示,

Δpk和Δmk都是通过在相同的输入feature map x上应用的分离卷积层得到的。该卷积层具有与当前卷积层相同分辨率及dilation,输出通道为3K,前面的2K通道,对应偏移的学习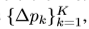 ,剩余的K个通道送入后面的Sigmoid层来获得调制尺寸
,剩余的K个通道送入后面的Sigmoid层来获得调制尺寸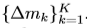 ,分离卷积层中的卷积核初始化为0, ∆pk 与∆mk的初始值分别为0及0.5.用于偏移学习及调制增加的卷积层的学习率设置为当前层的0.1倍。
,分离卷积层中的卷积核初始化为0, ∆pk 与∆mk的初始值分别为0及0.5.用于偏移学习及调制增加的卷积层的学习率设置为当前层的0.1倍。
调制的可变形RoIPooling 层与此相似,对于一个输入的RoI,RoIpooling 将其分为K个空间bins(如7x7) ,每个bin,应用偶数采样间隔的网格(比如2x2)。 对网格进行平均操作作为bin的输出。 ∆pk 及∆mk作为第k个bin的可学习偏移量,及调制尺寸。输出合并特征y(k)如下式,∆pk 与 ∆mk由输入feature map上的分支产生。在此分支上,RoIpooling 产生RoI的features,后接两个1024维的全连接层(由标准方差为0.01的标准高斯分布初始化)。在RoIpoolIng的顶部存在额外的全连接层输出通道数为3K,前2K为标准化后可学习的偏移,其中与RoI的宽和高进行点乘来获得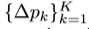 ,剩余的K通道通过一个sigmoid层来标准化得到
,剩余的K通道通过一个sigmoid层来标准化得到 ,增加用来对偏移量进行学习的全连接层的学习率与当前层的学习率相同。
,增加用来对偏移量进行学习的全连接层的学习率与当前层的学习率相同。

R-CNN 特征的模仿
对于常规的卷积网络和可变形的卷积网络 ,对于每个RoI 分类节点的误差限制显著区域都会超出感兴趣区域,进而影响特征的提取,从而影响检测的结果。有人发现冗余的上下文信息是Faster R-CNN检测出错的原因。提出结合R-CNN及Faster R-CNN二者的分类scores作为最终的检测scores。由于R-CNN的分类score主要来自于输入的RoI中剪裁的图像内容,因此,结合起来解决冗余的上下文问题并提高检测精度。然而,由于R-CNN及Faster R-CNN在训练及推理过程中都有所应用,因此,结合的系统速度较慢。
同时,可变形卷积十分利于适应支持区域的调整。DCNv2,调制可变形RoIPooling模块可以通过简单的设置bins的调制尺寸来消除冗余的上下文信息。然而实验发现,即使是调制的可变形卷积,Faster R-CNN在训练时,仍无法较好的学习特征表示。本文怀疑是由于Faster R-CNN的损失函数无法有效的驱动此特征表示的学习,需要额外的指导信息来促进训练。本文在Deformable Faster R-CNN的per-RoI的特征上加入了一个特征模拟损失,迫使其与从裁剪图像中提取的R-CNN特征相类似。辅助训练的目的是为了使可变形Faster R-CNN像R-CNN一样更多的学习到聚焦的特征表示。实验发现,对于图像背景上的负样例RoIs,聚焦表示不是最合适的。对于背景区域,需要考虑更多的上下文信息,来避免产生错误的检测。因此,特征模拟损失只在与目标ground truth有较大重复率的正样例RoIs上执行。
训练可变形Faster R-CNN的网络结构如下图所示,
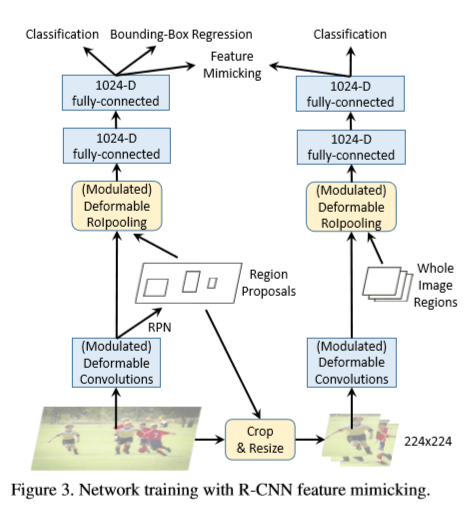
除了有Faster R-CNN,还增加了用于特征模拟的R-CNN分支 ,输入一个用于特征模拟的RoI b,通过裁剪及resize调整得到224x224的patch。R-CNN分支,在pathch进行操作得到一个大小为14x14空间分辨率的feature map,一个调制可变形RoIPooling在feature map上,其中输入的RoI已经覆盖整个图像的patch(左上角为(0,0),宽高为patch的宽及高)。然后,后接两个1024维的全连接层,产生R-CNN对于输入patch的特征表示,表示为  ,一个(C+1)路的softmax分类器接在后面用于分类。特征模拟损失包含,Faster R-CNN的特征表示
,一个(C+1)路的softmax分类器接在后面用于分类。特征模拟损失包含,Faster R-CNN的特征表示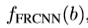 及R-CNN的特征表示
及R-CNN的特征表示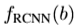 。特征模拟损失函数定义如下,其中Ω表示特征模拟训练采样的RoI集合。
。特征模拟损失函数定义如下,其中Ω表示特征模拟训练采样的RoI集合。
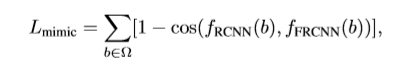
基于SGD的训练,输入一张图片,通过RPN生成32个区域候选框。并随机挑选几张送入Ω中。基于交叉熵损失的分类添加到R-CNN的头部,网络训练由特征模拟损失,R-CNN的分类损失及Faster R-CNN的原始损失共同驱动。新引入的两个损失项的权重初始化为Faster R-CNN的0.1倍。R-CNN及Faster R-CNN二者之间相关模块的参数是共享的,包含backbone层,调制的可变形RoIpooling 模块及后面的两个全连接层。推理时,只有Faster R-CNN部分起作用,因此,不会引入用于R-CNN特征模拟的额外计算量。
实验





参考
[1] R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, S. S¨usstrunk, et al. Slic superpixels compared to state-ofthe-art superpixel methods. IEEE transactions on pattern analysisandmachineintelligence,34(11):2274–2282,2012. 9
[2] J. Ba and R. Caruana. Do deep nets really need to be deep? In NIPS, 2014. 2, 5, 7
[3] P. Battaglia, R. Pascanu, M. Lai, D. J. Rezende, et al. Interaction networks for learning about objects, relations and physics. In NIPS, 2016. 6
[4] D. Britz, A. Goldie, M.-T. Luong, and Q. Le. Massive exploration of neural machine translation architectures. In EMNLP, 2017. 6
论文阅读笔记四十:Deformable ConvNets v2: More Deformable, Better Results(CVPR2018)的更多相关文章
- 论文阅读笔记四十六:Feature Selective Anchor-Free Module for Single-Shot Object Detection(CVPR2019)
论文原址:https://arxiv.org/abs/1903.00621 摘要 本文提出了基于无anchor机制的特征选择模块,是一个简单高效的单阶段组件,其可以结合特征金字塔嵌入到单阶段检测器中. ...
- 论文阅读笔记四十九:ScratchDet: Training Single-Shot Object Detectors from Scratch(CVPR2019)
论文原址:https://arxiv.org/abs/1810.08425 github:https://github.com/KimSoybean/ScratchDet 摘要 当前较为流行的检测算法 ...
- 论文阅读笔记四十八:Bounding Box Regression with Uncertainty for Accurate Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1809.08545.pdf github:https://github.com/yihui-he/KL-Loss 摘要 大规模的目标检测数据集在 ...
- 论文阅读笔记四十四:RetinaNet:Focal Loss for Dense Object Detection(ICCV2017)
论文原址:https://arxiv.org/abs/1708.02002 github代码:https://github.com/fizyr/keras-retinanet 摘要 目前,具有较高准确 ...
- 论文阅读笔记四十二:Going deeper with convolutions (Inception V1 CVPR2014 )
论文原址:https://arxiv.org/pdf/1409.4842.pdf 代码连接:https://github.com/titu1994/Inception-v4(包含v1,v2,v4) ...
- 论文阅读笔记四十五:Region Proposal by Guided Anchoring(CVPR2019)
论文原址:https://arxiv.org/abs/1901.03278 github:code will be available 摘要 区域anchor是现阶段目标检测方法的重要基石.大多数好的 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- 论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)
论文源址:https://arxiv.org/abs/1703.06211 开源项目:https://github.com/msracver/Deformable-ConvNets 摘要 卷积神经网络 ...
- 论文笔记:Deformable ConvNets v2: More Deformable, Better Results
概要 MSRA在目标检测方向Beyond Regular Grid的方向上越走越远,又一篇大作推出,相比前作DCN v1在COCO上直接涨了超过5个点,简直不要太疯狂.文章的主要内容可大致归纳如下: ...
随机推荐
- Python——字典操作
一.取出字典中所有的key-value student={'name':'xiaoming','age':11,'school':'tsinghua'} for key,value in studen ...
- js 实现的页面图片放大器以及 event中的诸多 x
背景: 淘宝.天猫等电商网站浏览图片时可以查看大图的功能: 思路: 思路很简单,两张图片,一张较小渲染在页面上,一张较大是细节图,随鼠标事件调整它的 left & top; 需要的知识点: o ...
- [转载:Q1mi]Bootstrap和基于Bootstrap的登录验证示例
转载自:Q1mi Bootstrap介绍 Bootstrap是Twitter开源的基于HTML.CSS.JavaScript的前端框架. 它是为实现快速开发Web应用程序而设计的一套前端工具包. 它支 ...
- 一丢丢学习之webpack4 + Vue单文件组件的应用
之前刚学了一些Vue的皮毛于是写了一个本地播放器https://github.com/liwenchi123000/Local-Music-Player,如果觉得ok的朋友可以给个star. 就是很简 ...
- shell实战之日志脱敏-2.0
cfg # This is generated to be a configuration file. # kay # // # This is a parameter for crontab and ...
- Oracle 查看链接数、创建索引等的DDL语句
select count(*),machine from v$session group by machine 今天打算将一个数据库的索引在另一个测试库上重新创建一遍,研究了一下. set pages ...
- .pyc是个什么 python的执行过程
1. Python是一门解释型语言? 我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在.如果是解释型语言, ...
- 更换gcc工具链
title: 更换gcc工具链 date: 2019/1/16 19:27:51 toc: true --- 更换gcc工具链 下载后解压到一个临时目录先看看文件结构 mkdir tmp tar xj ...
- kubernetes云平台管理实战: 服务发现和负载均衡(五)
一.rc控制器常用命令 1.rc控制器信息查看 [root@k8s-master ~]# kubectl get replicationcontroller NAME DESIRED CURRENT ...
- command not found
1.问题(problem) #wget gzip.x86_64 0:1.5-10.el7 -bash: wget command not found 2.解决(solution) 两个都能用 yum ...