Python爬虫与一汽项目【一】爬取中海油,邮政,国家电网问题总结
项目介绍
中国海洋石油是爬取的第一个企业,之后依次爬取了,国家电网,中国邮政,这三家公司的源码并没有多大难度,
采购信息地址:
国家电网电子商务平台
http://ecp.sgcc.com.cn/project_list.jsp?site=global&column_code=014001001&project_type=1
中国海洋石油集团有限公司
https://buy.cnooc.com.cn/cbjyweb/001/001001/moreinfo.html
中国邮政
http://www.chinapost.com.cn/html1/category/181313/7294-1.htm
项目地址:
https://github.com/code-return/Crawl_faw
实现过程与方法
1.中国海洋石油集团有限公司
中海油的信息页面很友好,并没有多大难度,实现顺序如下:
#获取首页内容
def get_one_page(url):
... #解析网页
def parse_one_page(html):
... #获取最大页码
def getMaxpage(html):
... #获取二级页面的文本内容
def getContent(url):
... #主函数
def main(): url = "https://buy.cnooc.com.cn/cbjyweb/001/001001/moreinfo.html"
html = get_one_page(url)
parse_one_page(html)
page_num = getMaxpage(html)
#拼接翻页的url,并返回翻页的源代码
for i in range(2,page_num + 1):
next_url = url.replace('moreinfo',str(i))
next_html = get_one_page(next_url)
parse_one_page(next_html)
在主函数中需实现翻页爬取的功能,这里通过先获取网页最大页码,然后根据页码设置循环,我们从第二页开始解析网页。
在网页解析函数parse_one_page(html)中,主要实现,获取网页中的标题,发布时间,href,获取该内容之后对数据进行筛选,存储
def time_restrant(date): # 时间判断函数,判断是否当年发布的消息
thisYear = int(datetime.date.today().year)
thisMonth = int(datetime.date.today().month)
thisday = int(datetime.date.today().day)
year = int(date.split('-')[0])
month = int(date.split('-')[1])
day = int(date.split('-')[2])
#if ((thisYear - year <= 1) or (thisYear - year == 2 and month >= thisMonth)): # 爬取24个月内的信息
# if (thisYear == year and month == thisMonth and day == thisday): # 这里是设置时间的地方
#if (thisYear == year and month == thisMonth):
if (thisYear == year):
#if thisYear == year:
return True
else:
return False
def title_restraint(title,car_count, true_count): # 标题判断函数,判断标题中是否有所需要的“车”的内容
global most_kw_arr
global pos_kw_arr
global neg_kw_arr
car_count += 1
if title.find(u"车") == -1: # or title.find(u"采购公告"):
return False,car_count, true_count
else:
#car_count += 1
neg_sign = 0
pos_sign = 0 for neg_i in neg_kw_arr:
if title.find(neg_i) != -1: # 出现了d_neg_kw中的词
neg_sign = 1
break for pos_i in pos_kw_arr:
if title.find(pos_i) != -1: # 出现了d_pos_kw中的词
pos_sign = 1
break if neg_sign == 1:
return False,car_count, true_count
else:
if pos_sign == 0:
return False,car_count, true_count
elif pos_sign == 1:
true_count += 1
return True,car_count, true_count
将数据筛选完毕之后,对数据进行存储
def store(title, date, content, province, url): # 向nbd_message表存储车的信息
title, content = removeSingleQuote(title, content)
sql = "insert into nbd_message (title,time,content,province,href) values('%s','%s','%s','%s','%s')" % (
title, date, content, province, url)
return mySQL("pydb", sql, title, date, province) def store_nbd_log(car_count, true_count, province_file): # 向nbd_spider_log表存储爬取日志信息
sql = "insert into nbd_spider_log (total_num,get_num,pro_name,spider_time) values('%d','%d','%s','%s')" % (
car_count, true_count, province_file,str(datetime.date.today())
流程结束
2.中国邮政
邮政的页面更加单一,但是邮政问题在于,
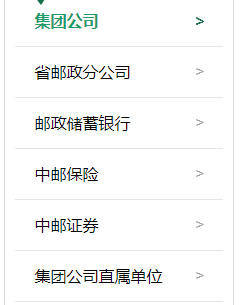
其每个单位都有单独的链接来展示其不同业务部门的招标信息,经过对比我发现,这个下属部门的首页链接,就差了最后一点不一样,因此我偷了个懒,多加了个循环
def main():
"""
urls中分别对应着集团公司,省邮政分公司,邮政储蓄银行,中邮保险,集团公司直属单位
"""
urls = ['7294-','7331-','7338-','7345-','7360-']
for i in range(0,len(urls)):
strPost = '1.htm'#url后缀
base_url = "http://www.chinapost.com.cn/html1/category/181313/" + str(urls[i])
url = base_url + strPost
html = get_one_page(url)
# print(html)
parse_one_page(html)
page_num = getMaxpage(html)
getMaxpage(html)
for i in range(2,page_num + 1):
next_url = base_url + strPost.replace('1',str(page_num))
next_html = get_one_page(next_url)
parse_one_page(next_html)
邮政完成
3.国家电网
国家电网是我遇到的第一个问题,他的问题在于,在所需要的每个公告里面的href中,给出的不是通常的二级页面链接,而是JavaScript的两个参数,
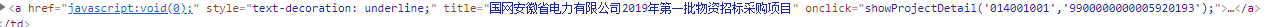
href=”javascript:void(0);”这个的含义是,让超链接去执行一个js函数,而不是去跳转到一个地址,
而void(0)表示一个空的方法,也就是不执行js函数。
为什么要使用href=”javascript:void(0);”
javascript:是伪协议,表示url的内容通过javascript执行。void(0)表示不作任何操作,这样会防止链接跳转到其他页面。这么做往往是为了保留链接的样式,但不让链接执行实际操作, <a href="javascript:void(0)" onClick="window.open()"> 点击链接后,页面不动,只打开链接 <a href="#" onclick="javascript:return false;"> 作用一样,但不同浏览器会有差异
而二级页面的链接与属性onclick里面的两个数字有关!!!因此我用onclick的两个参数,进行二级页面的拼接,
hrefAttr = selector.xpath("//*[@class='content']/div/table[@class='font02 tab_padd8']/tr/td/a/@onclick")
for i in range(0,len(hrefAttr)):
#获取二级页面的跳转参数,以便进行二级页面url拼接
string = str(hrefAttr[i])
attr1 = re.findall("\d+",string)[0]
attr2 = re.findall("\d+",string)[1]
结语
继续搬砖......
Python爬虫与一汽项目【一】爬取中海油,邮政,国家电网问题总结的更多相关文章
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- Python爬虫与一汽项目【二】爬取中国东方电气集中采购平台
网站地址:https://srm.dongfang.com/bid_detail.screen 东方电气采购的页面看似很友好,实际上并不好爬取 在观察网页的审查元素之后发现,1处的网页响应只是单纯的一 ...
- Python爬虫与一汽项目【综述】
项目来源 这个爬虫项目是 去年实验室去一汽后的第一个项目(基本交工,现在处于更新维护阶段).内容大概是,获取到全国31个省份政府的关于汽车的招标公告,再用图形界面的方式展示爬虫内容.在完成政府招标采购 ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- python爬虫入门新手向实战 - 爬取猫眼电影Top100排行榜
本次主要爬取Top100电影榜单的电影名.主演和上映时间, 同时保存为excel表个形式, 其他相似榜单也都可以依葫芦画瓢 首先打开要爬取的网址https://maoyan.com/board/4, ...
- 小白学 Python 爬虫(25):爬取股票信息
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- Lucene.net 的性能探究--Lucene.net 的并发处理能力到底有多强?
这篇博客并不是证明Lucene.net的性能有多强悍,实际上Lucene.net的并发能力并不让人很满意,这得看你怎么用它. 因为Lucene 本身就是一个搜索引擎的基础框架,相当于一辆车子的发动机, ...
- Java 非静态内部类中可以定义静态变量或方法吗?
如图: 这个问题的答案是不可以 由于内部类的实例化是由外部类实例化之后加载的,如果外部类还没有实例化,这时候调用内部类的静态成员,此时内部类还没有被加载,却要开始创建静态成员,这是矛盾的,所以java ...
- SaaS的先鋒:多合一讯息处理器
在Rocketbots,我们的使命是改善企业与客户之间的关係.全球有超过40亿个消息传递帐户,人们花在上线对话的时间比任何其他活动都多.这种转变,创造了一个更高效及贴身的沟通.随著消费者越来越多要求, ...
- NetBeans配置subli
NetBeans主题设置: ①.去https://netbeansthemes.com/rank/网址下载喜欢的主题 ②.然后打开NetBeans-->工具->选项->外观-> ...
- v-for同时循环一个对象和数组
<!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8&quo ...
- linux1
虚拟内存:内核通过磁盘上的存储空间来实现虚拟内存,这块区域称为交换空间.内核不断交换空间和实际的物理内存之间反复交换虚拟内存中的内容 linux运行中的程序叫做进程. 内核创建了第一个进程,叫做Ini ...
- 栈->栈的应用
e.g.1 数制转换 十进制数N和其它d进制数的转换是计算机实现计算的基本问题,其解决方法很多,其中一个简单算法基于下列原理. 假设编写一个程序:对于输入的任意一个非负十进制整数,打印输出与其等值的八 ...
- less命令查看文件时的常用操作
下键或者回车:往下一行 D:往下半页 空格和f:往下一页 上键:往上一行 B:往上一页 shift+G:直接切到末尾 ?+搜索条件:从下往上搜索 /+搜索条件:从上往下搜索
- UML用例关系一览
- 2019年 Gratner数据分析平台对比 - PowerBI大幅领先
先睹为快,看看你正在用的工具在哪里? 文末见2017-2018图 对比2019年, 1.ThoughtSpot好像发展很快 2.IBM...... 3.Microstrategy好像表现还不错 4.L ...