分词工具Hanlp基于感知机的中文分词框架
结构化感知机标注框架是一套利用感知机做序列标注任务,并且应用到中文分词、词性标注与命名实体识别这三个问题的完整在线学习框架,该框架利用1个算法解决3个问题,时自治同意的系统,同时三个任务顺序渐进,构成流水线式的系统。本文先介绍中文分词框架部分内容。
中文分词
训练
只需指定输入语料的路径(单文档时为文件路径,多文档时为文件夹路径,灵活处理),以及模型保存位置即可:
命令行
java -cp hanlp.jar com.hankcs.hanlp.model.perceptron.Main -task CWS -train -reference data/test/pku98/199801.txt -model data/test/perceptron/cws.bin
API
public void testTrain() throws Exception
{
PerceptronTrainer trainer = new CWSTrainer();
PerceptronTrainer.Result result = trainer.train(
"data/test/pku98/199801.txt",
Config.CWS_MODEL_FILE
);
// System.out.printf("准确率F1:%.2f\n", result.prf[2]);
}
事实上,视语料与任务的不同,迭代数、压缩比和线程数都可以自由调整,以保证最佳结果:
/**
* 训练
*
* @param trainingFile 训练集
* @param developFile 开发集
* @param modelFile 模型保存路径
* @param compressRatio 压缩比
* @param maxIteration 最大迭代次数
* @param threadNum 线程数
* @return 一个包含模型和精度的结构
* @throws IOException
*/
public Result train(String trainingFile, String developFile,
String modelFile, final double compressRatio,
final int maxIteration, final int threadNum) throws IOException
单线程时使用AveragedPerceptron算法,收敛较好;多线程时使用StructuredPerceptron,波动较大。关于两种算法的精度比较,请参考下一小节。目前默认多线程,线程数为系统CPU核心数。请根据自己的需求平衡精度和速度。
准确率
在sighan2005的msr数据集上的性能评估结果如下:
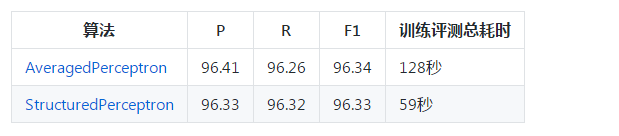
l 语料未进行任何预处理
l 只使用了7种状态特征,未使用词典
l 压缩比0.0,迭代数50
l 总耗时包含语料加载与模型序列化
l 对任意PerceptronTagger,用户都可以调用准确率评估接口:
/**
* 性能测试
*
* @param corpora 数据集
* @return 默认返回accuracy,有些子类可能返回P,R,F1
* @throws IOException
*/
public double[] evaluate(String corpora) throws IOException
速度
目前感知机分词是所有“由字构词”的分词器实现中最快的,比自己写的CRF解码快1倍。新版CRF词法分析器框架复用了感知机的维特比解码算法,所以速度持平。

l 测试时需关闭词法分析器的自定义词典、词性标注和命名实体识别
l 测试环境 Java8 i7-6700K
测试
测试时只需提供分词模型的路径即可:
public void testCWS() throws Exception
{
PerceptronSegmenter segmenter = new PerceptronSegmenter(Config.CWS_MODEL_FILE);
System.out.println(segmenter.segment("商品和服务"));
}
正常情况下对商品和服务的分词结果为[商品, 和, 服务]。建议在任何语料上训练时都试一试这个简单的句子,当作HelloWorld来测试。若这个例子都错了,则说明语料格式、规模或API调用上存在问题,须仔细排查,而不要急着部署上线。
另外,数据包中已经打包了在人民日报语料1998年1月份上训练的模型,不传路径时将默认加载配置文件中指定的模型。
在本系统中,分词器PerceptronSegmenter的职能更加单一,仅仅负责分词,不再负责词性标注或命名实体识别。这是一次接口设计上的新尝试,未来可能在v2.0中大规模采用这种思路去重构。
分词工具Hanlp基于感知机的中文分词框架的更多相关文章
- 深度学习实战篇-基于RNN的中文分词探索
深度学习实战篇-基于RNN的中文分词探索 近年来,深度学习在人工智能的多个领域取得了显著成绩.微软使用的152层深度神经网络在ImageNet的比赛上斩获多项第一,同时在图像识别中超过了人类的识别水平 ...
- 自制基于HMM的中文分词器
不像英文那样单词之间有空格作为天然的分界线, 中文词语之间没有明显界限.必须采用一些方法将中文语句划分为单词序列才能进一步处理, 这一划分步骤即是所谓的中文分词. 主流中文分词方法包括基于规则的分词, ...
- java分词工具hanlp介绍
前几天(6月28日),在第23届中国国际软件博览会上,hanlp这款自然语言处理工具荣获了“2019年第二十三届中国国际软件博览会优秀产品”. HanLP是由一系列模型预算法组成的工具包,结合深度神经 ...
- 基于CRF的中文分词
http://biancheng.dnbcw.info/java/341268.html CRF简介 Conditional Random Field:条件随机场,一种机器学习技术(模型) CRF由J ...
- PHP基于Sphinx+Swcs中文分词的全文的检索
简介 Sphinx是开源的搜索引擎,它支持英文的全文检索.所以如果单独搭建Sphinx,你就已经可以使用全文索引了 但是有些时候我们还要进行中文分词所有scws就出现了,我们也可以使用Coreseek ...
- [Python] 基于 jieba 的中文分词总结
目录 模块安装 开源代码 基本用法 启用Paddle 词性标注 调整词典 智能识别新词 搜索引擎模式分词 使用自定义词典 关键词提取 停用词过滤 模块安装 pip install jieba jieb ...
- Lucene全文搜索之分词器:使用IK Analyzer中文分词器(修改IK Analyzer源码使其支持lucene5.5.x)
注意:基于lucene5.5.x版本 一.简单介绍下IK Analyzer IK Analyzer是linliangyi2007的作品,再此表示感谢,他的博客地址:http://linliangyi2 ...
- 【分词器及自定义】Elasticsearch中文分词器及自定义分词器
中文分词器 在lunix下执行下列命令,可以看到本来应该按照中文”北京大学”来查询结果es将其分拆为”北”,”京”,”大”,”学”四个汉字,这显然不符合我的预期.这是因为Es默认的是英文分词器我需要为 ...
- 基于DAT的中文分词方法的研究与实现
一.从Trie说起 DAT是Double Array Trie的缩写,说到DAT就必须先说一下trie是什么.Trie树是哈希树的一种,来自英文单词"Retrieval"的简写,可 ...
随机推荐
- 《A Knowledge-Grounded Neural Conversation Model》
abstract 现在的大多数模型都可以被应用在闲聊场景下,但是还没有证据表明他们可以应用在更有用的对话场景下.这篇论文提出了一个知识驱动的,带有背景知识的神经网络对话系统,目的是为了在对话中产生更有 ...
- Linux命令 ls 和 ll 的使用方法与基本区别
Linux 命令 ls 和 ll 的使用方法: ll:罗列出当前文件或目录的详细信息,含有时间.读写权限.大小.时间等信息 ,像Windows显示的详细信息.ll是“ls -l"的别名.相当 ...
- reat + cesium。 实现 初始化时自动定位,鼠标移动实时展示坐标及视角高度, 淹没分析
只贴实现淹没分析这块的代码. import styles from './cesium.less'; import React from 'react'; import Cesium from 'ce ...
- C语言---指针变量详解3
指针可以指向一份普通类型的数据,例如 int.double.char 等,也可以指向一份指针类型的数据,例如 int *.double *.char * 等.如果一个指针指向的是另外一个指针,我们就称 ...
- Windows10 VS2017 C++编译Linux程序
#include <cstdio> #include <iostream> #include "unistd.h" using namespace std; ...
- oracle mysql 比较
转载:https://www.cnblogs.com/qq765065332/p/9293029.html 一.数据的存储结构 mysql: 1.对数据的管理可以有很多个用户,登录用户后可以看到该用户 ...
- 终于开始我的java旅程了!
首先今天先装了jdk1.7 ,找了半天,因为官网是都是让你装1.8的最新版本,地址如下: 所有jdk的历史版本: http://www.oracle.com/technetwork/java/java ...
- 微信小程序上传文件遇到的坑
在开发小程序时,使用的花生壳做的内网映射,域名使用花生壳卖的https域名 在做小程序文件上传时,调用接口,老是报错. Caused by: org.apache.commons.fileupload ...
- css尺寸(大小)属性
尺寸属性:用来控制元素大小的属性,单位为长度单位. 尺寸属性的使用场景 当使用相对长度单位定义尺寸时,元素的大小跟随窗口大小变化. 为保证元素的正常显示,需要设定元素的最大.最小长度. 手机端开发时需 ...
- Java NIO 入门
本文主要记录 Java 中 NIO 相关的基础知识点,以及基本的使用方式. 一.回顾传统的 I/O 刚接触 Java 中的 I/O 时,使用的传统的 BIO 的 API.由于 BIO 设计的类实在太 ...