K最邻近分类
最邻近分类是分类方法中比较简单的一种,下面对其进行介绍
1.模型结构说明
最邻近分类模型属于“基于记忆”的非参数局部模型,这种模型并不是立即利用训练数据建立模型,数据也不再被函数和参数所替代。在对测试样例进行类别预测的时候,找出和其距离最接近的
个样例,以其中数量最多的类别作为该样例的类预测结果。
最邻近分类模型的结构可以用下图来说明,图中叉号表示输入的待分类样例,对其分类时选定一个距离范围(虚线圆圈表示的范围),在该范围内包含有
个样例(除去待分类样例外,这里
=5),这里所说的距离并不专指距离度量(如曼哈顿距离、欧氏距离等),它可以是任意一种邻近度度量(在我的博文《数据测量与相似性分析》中有介绍),此时最邻近的5个样例中,有3个“+”例,2个“-”例,故待分类样例的类别定位“+”。为了便于确定类别,
一般取奇数。


2.模型构建
2.1 K值选取
从最邻近分类方法的分类过程可知,
值对模型的误分类率影响较大。
较小时,相当于用较小邻域中的样例进行预测,“学习”的近似误差会减小,但是“学习“的估计误差会增大,且对邻域内的样例非常敏感,若邻近的样例中包含部分噪声,预测结果就会出错,
较大时的情况则相反。
总的来说,值减小意味着整体模型变复杂,容易发生过拟合,
值增大意味着模型变简单,导致忽略“训练”样例中一些有用信息,预测误分类率会增高。在应用中,一般
取较小的值(例如sklearn库中最邻近分类器KNeighborsClassifier中
默认为5),可以通过交叉验证法选择一个合适的
值
2.2 最邻近样例搜索
由于最邻近分类器不需要利用样例进行训练,因此关键点就集中在如何快速进行
邻近样例搜索,这在特征空间维数大和样例数据量大时非常重要。一种容易想到的方法是对所有样例进行线性搜索,但显然这在特征空间高维数、样例量大时不可取。有很多方法可以提高搜索效率,这里介绍其中的一种——
树(kd tree)方法。
树(也是一种二叉树)是一种对
维空间中的样例进行存储以便对其进行快速检索的树形结构,在特征空间为一维时,平衡二叉树是一个不错的选择,但是当特征空间为多维时,平衡二叉树就无能为力了,此时
树就派上用场了。
2.2.1 树构造过程
树的构造过程大致为:首先构造一个根节点,选择
维特征空间中的一个变量
,依据在变量
上的取值的中位数划分样例集(大于或等于中位值、小于中位值),形成左子树和右子树,这个根节点就类似于一个矩形超平面,将样例集划分到平面左右两侧。接着再选择一个变量
,按照样例在变量
上取值的中位值分别对左子树、右子树中的样例进行划分,这个过程相当于在之前被根节点一分为二的左、右超平面内,分别用基于各自空间内
上中位数的矩形超平面再次将子空间进行划分,重复这个过程,直到
树的每个结点上只包含一个样例为止(即叶子结点,从几何空间上看,即划分后两个子区域内没有实例存在)。这个过程中有几点需要单独强调:
(1) 在这个过程中,划分空间时变量优先选择策略可以为:依据子空间内(根节点时为整个样例空间)样例在该变量上取值波动程度(即方差),波动大的优先选择。当然,也可以是随机选择。
(2) 当所有变量都已被用来划分样例、划分仍未结束时,需要接着用所有变量再进行一次划分,不断重复该过程,直到划分停止。
(3) 假设当前选择用变量进行划分,那么本次划分是在各子空间单独进行的,即各子空间内本次划分时,在变量
上选值是依据该子空间内样例的中位值。
(4) 树上对同一层深度的样例划分时,必须使用同一变量,也即是说在一次划分中,各子空间必须使用同一变量。
(5) 划分值(矩形超平面位置)选择的是各子空间内样例在变量上取值的中位数,这种划分策略保证生成的树是平衡的。
(6) 若训练集中存在标称型属性,使用K最邻近分类器则不太合适,因为标称型属性无法参与到距离度量的计算中。
2.2.2 树的构造算法
输入:维空间数据集
,其中
输出:树
- 开始:构造根节点,根节点对应于包含
的
维空间的超矩形区域。选择
为坐标轴,以
- 重复:对深度为
的结点,选择
为切分的坐标轴,
,以该结点的区域中所有实例的
- 结束:直到两个区域没有实例存在时停止。
举一个树构造的例子,给定一个二维空间数据集
树的构造过程为:选择
轴,6个数据点
坐标的中位数为7(5也可以),以平面
=7将空间划分为左、右两个子矩形(子结点),左子矩形以
=4平面一分为二,右子矩形以
=6一分为二,如此递归,得到下图(左)所示的特征空间划分,下图(右)所示的
树。


2.2.3 搜索树
从树的构造过程来看,可以省去对大部分数据点的搜索,从而减少搜索的时间。给定一个目标点(即待分类样例),先找到包含该目标点的叶子结点,然后依次回退到父结点,在这个过程中不断查找与目标点最邻近的样例,当确定不可能存在更近的结点时,结束搜索过程,这个过程可以用下图来说明(此次搜索过程不涉及图中左下子区域中的点,因此未画出)

图中共有A、B、C、D、E、F 5个样例点,其中点F(绿色)输入的待分类样例点,点A(根节点,红色,椭圆)在变量的矩形超平面上,点B(红色,圆形)在变量
的矩形超平面下方,点C、D、E、F 均在变量
的矩形超平面上方。点C(蓝色,椭圆)在变量
的矩形超平面上,点D(蓝色,圆形)在变量
的矩形超平面左边,点E、F在变量
的矩形超平面右边。
首先找到点F所在的叶子结点,即点E(点F与点E在同一区域内),此时点E为最邻近点,计算点F与点E间的距离,得到(蓝色虚线)。接着回到父结点C上,计算父结点C与点F间的距离,发现该距离大于
,故最邻近点仍然为点E,然后以点F为圆心,
为半径作圆(蓝色线条的圆),若该圆与变量
上的矩形超平面相交,则需要对父结点C的另一个子区域(左子树)内的点进行搜索,因为这表明其中可能存在更邻近点;若圆(蓝色线条的圆)与变量
上的矩形超平面不相交,则不必在父结点的另一个子空间内搜索。由于此时圆(蓝色线条的圆)与变量
上的矩形超平面相交,因此需要计算点D与点F间的距离
(红色虚线),结果发现
,故此时点D是最邻近点。
接着再回到结点C的父结点A上,计算点A与点F间的距离并与比较,发现该距离大于
,故点D仍然为最邻近点,然后以点F为圆心,
为半径作圆,该圆与变量
的矩形超平面不相交,故不需要再对结点A的左子树(变量
的矩形超平面下半区域)内的点进行搜索,即点B不可能是最邻近点。
至此为止,在本例中搜索过程结束,需要说明的是,本例中的圆在实际多维特征空间中为超球体,判断超球体与分类矩形超平面是否相交的方法为:待分类点(目标点)与分类超矩形平面的距离(即在当前分类变量上,待分类点与父结点在
上取值的差值的绝对值)是否大于超球体半径。在实际中也只需要依照该过程不断重复,直至搜索到根节点。
树上最邻近点的搜索算法为:
- 在
树上找出包含目标点
的叶子结点:从根节点出发,递归的向下访问
- 以此叶子结点为最邻近点
- 递归的向上回退,在每个结点进行一下操作:
- 如果该结点保存的实例点比当前最近点距离目标点更近,则以该实例点为“当前最近点”
- 当前最近点一定存在于该结点的一个子结点对应的区域。检查该子结点父结点的另一子结点对应的区域是否有更近点。具体的,检查另一子结点对应的区域是否与以目标点为球心、以目标点与“当前最近点”间距离为半径的超球体相交。如果相交,可能在另一子结点对应的区域内存在距离目标点更近的点,移动到另一子结点。接着递归的进行最邻近搜索。如果不想交,则向上回退。
- 当退回到根结点时,结束搜索,最后的“当前最近点”即为
以上的过程是的情况,对于
的情况,搜索的方式和
时一样,但在找最近的
个点时,首先要保证找到数量足够的点,在前
次搜索时不必考虑距离问题,直接将这
个点当做“当前最近
个点”,接下来的搜索就要考虑距离问题了,以这
个点中最远距离作为“当前最近距离”,当找到更近的点时,对“当前最近距离”进行更新。
3.对距离进行加权处理
当数据中类分布不平衡时,会出现以下这种情况,假设
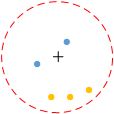
蓝色的点表示类1,橙色的点表示类2,依据KNN算法中对类别的判定规则,此时样本的类别被预测为类2,但是从图中可以明显的看出待分类样本离类别1的点更近、更应该将其归为类1,为了处理这种情况,可以采用距离加权的方式,距离越近的点赋予其更大的权值。权值的计算方式有多种,这里介绍一种常用的方式——采用高斯函数计算权值。
高斯函数的定义形式为
其中表示曲线的高度,
表示曲线中心的偏移,
表示半峰宽度(函数峰值一半处两点相距宽度),高斯函数的曲线图形大致为

值可以设为1,
值可以为0,
值可以采用交叉验证法选择合适的值,在距离为0时,权值为1,距离越远,则权值越小,但不会为0。计算出
个最邻近数据的权重后,待分类数据的类别与第
个数据的类别相同的概率为
式中表示第
个数据的权值,将邻近的
数据中属于同一类的数据的权值求和,那个类别上权值最大,就将待分类数据的类别定为该类。
4.K最邻近分类方法的优缺点
4.1 优点
- 无需参数估计,无需训练,属于消极学习方法
- 对个别异常值不敏感,当然,前提时
值不能过小
- 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
4.2 缺点
- 计算复杂度高,涉及到距离的计算机排序操作
- 采用
- 类别预测数据慢
- 仅适用于数据样本大的情况,数据样本量小时容易误分类
K最邻近分类的更多相关文章
- 数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法. 分类问题的应用场景:分 ...
- k最邻近算法——使用kNN进行手写识别
上篇文章中提到了使用pillow对手写文字进行预处理,本文介绍如何使用kNN算法对文字进行识别. 基本概念 k最邻近算法(k-Nearest Neighbor, KNN),是机器学习分类算法中最简单的 ...
- sklearn_k邻近分类
# K邻近分类#--------------------------------# coding:utf-8 import pandas as pd from sklearn.neighbors im ...
- 监督学习-KNN最邻近分类算法
分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术建立分类模型,从而对没有分类的数据进行分类的分析方法. 分类问题的应用场景:用于将事物打上一 ...
- K邻近分类算法
# -*- coding: utf-8 -*- """ Created on Thu Jun 28 17:16:19 2018 @author: zhen "& ...
- KNN邻近分类算法
K邻近(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法了.它采用测量不同特征值之间的距离方法进行分类.它的思想很简单:计算一个点A与其他所有点之间的距离,取出与该点最近的 ...
- 机器学习PR:k近邻法分类
k近邻法是一种基本分类与回归方法.本章只讨论k近邻分类,回归方法将在随后专题中进行. 它可以进行多类分类,分类时根据在样本集合中其k个最近邻点的类别,通过多数表决等方式进行预测,因此不具有显式的学习过 ...
- 2-KNN(K最邻近算法)
KNN基本思想: 1.事先存在已经分类好的样本数据(如分别在A类.B类.C类等) 2.计算待分类的数据(叫做新数据)与所有样本数据的距离 3.选择K个与新数据距离最近的的样本,并统计这K个样本所属的分 ...
- k最邻近算法——加权kNN
加权kNN 上篇文章中提到为每个点的距离增加一个权重,使得距离近的点可以得到更大的权重,在此描述如何加权. 反函数 该方法最简单的形式是返回距离的倒数,比如距离d,权重1/d.有时候,完全一样或非常接 ...
随机推荐
- JS学习之路一
1.准备 ①安装vscode 地址:https://vscode.en.softonic.com/ ②安装node.js node -v npm -v 地址:https://nodejs.org/zh ...
- MySQL数据库规范 (设计规范+设计规范+操作规范)
I 文档定义 1.1 编写目的 为了在软件生命周期内规范数据库相关的需求分析.设计.开发.测试.运维工作,便于不同团队之间的沟通协调,以及在相关规范上达成共识,提升相关环节的工作效率和系统的可维护性. ...
- pytest文档40-pytest.ini配置用例查找规则(面试题)
前言 面试题:pytest如何执行不是test开头的用例?如执行 xxx_*.py这种文件的用例. pytest.ini 配置文件可以修改用例的匹配规则. pytest命令行参数 cmd打开输入pyt ...
- Android adb实现原理
adb定义: adb(Android Debug Bridge) 安卓调试桥,包含adb client.adb server和adbd三部分. adb client:运行在PC上,即DDMS或者在Wi ...
- Vue 路由模块入门
前端路由 路由是根据不同的 url 展示不同的内容或页面: 前端路由是客户端浏览器可以不依赖服务端,不需要重新请求,可根据不同的URL渲染不同的视图页面 单页面的路由方式有两种: 哈希模式(利用has ...
- abstract关键字的说法
含有abstract修饰符的class即为抽象类,abstract 类不能创建的实例对象.含有abstract方法的类必须定义为abstract class,abstract class类中的方法不必 ...
- VirtualBox 安装Ubuntu(16.04/18.04)时显示不全的解决方法
是是系统分辨率不同导致的问题 Alt+鼠标左键 (16.04版本亲测有效,18.04版本亲测无效)或者Win+鼠标左键 (18.04版本亲测有效)拖动安装界面,即可显示内容.
- MFiX做增量编译的时候不要删掉*.mod和*.inc文件
其实之前发现了这个问题,但是没有记录,过了好久又忘了.具体问题是,在做增量编译的之前,都会习惯性地删除多余文件再编译,随手就把*.mod和*.inc这类中间文件也删了,结果修改完代码执行 make - ...
- zctf2016_note2:一个隐蔽的漏洞点挖掘
代码量挺大的,逆起来有难度 功能挺全,啥都有 main函数 add函数,有heaparray并且无pie保护,考虑unlink show函数,可以泄漏地址用 edit函数,有两种edit方式 dele ...
- PHP代码审计04之strpos函数使用不当
前言 根据红日安全写的文章,学习PHP代码审计的第四节内容,题目均来自PHP SECURITY CALENDAR 2017,讲完题目会用一个实例来加深巩固,这是之前写的,有兴趣可以去看看: PHP代码 ...