kafka对接Rancher日志
kafka对接Rancher日志
概述
Rancher应用商店自带的kafka可以方便的对接Rancher日志,但是不支持sasl认证。
如果有认证需求,可以使用bitnami仓库的kafka,这个kafka带有相关的认证参数,可以很方便的开启sasl相关的认证。
参考:https://github.com/bitnami/charts/tree/master/bitnami/kafka
环境准备
| 软件 | 版本 |
|---|---|
| kubernetes | v1.19.3 |
| Rancher | v2.4.8 | v2.5.2 |
| kafka | 2.6.0 |
| kafka-chart | 11.8.9 |
| helm | 3.4.0 |
正常对接kafka集群
如果是需要开启SASL认证,可以直接跳到后面开启SASL认证方式的内容
1、helm添加bitnami库
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
2、下载 kafka 对应的chart压缩文件
bitnami库国内可能访问不太友好,需要翻一下墙。。。
helm pull bitnami/kafka --version 11.8.9
上述命令会下载一个kafka-11.8.9-tgz的压缩文件,解压该文件
tar -zxvf kafka-11.8.9-tgz
查看解压目录内容
# cd kafka/
# ls
charts Chart.yaml files README.md requirements.lock requirements.yaml templates values-production.yaml values.yaml
可以看到有两个values文件,分别是values.yaml和values-production.yaml,
其中values.yaml会启动一个最简单的kafka集群,
而values-production.yaml中的配置会包含更多面向生产的配置,例如启用持久化存储,启用sasl相关认证等。
3、启动kafka集群
最简化启动kafka集群,可以添加这两个参数,取消持久化存储
kubectl create ns kafka
## 进入到kafka目录下再执行下面的命令
helm install kafka -n kafka -f values.yaml --set persistence.enabled=false --set zookeeper.persistence.enabled=false .
或者如果k8s有持久化存储,可以设置storage Class,将xxx替换为对应的storage Class
helm install kafka -n kafka -f values.yaml --set global.storageClass=xxx .
执行完helm install后会输出以下内容
NAME: kafka
LAST DEPLOYED: Wed Nov 25 17:04:50 2020
NAMESPACE: kafka
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
** Please be patient while the chart is being deployed **
Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:
kafka.kafka.svc.cluster.local
Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:
kafka-0.kafka-headless.kafka.svc.cluster.local:9092
To create a pod that you can use as a Kafka client run the following commands:
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:2.6.0-debian-10-r57 --namespace kafka --command -- sleep infinity
kubectl exec --tty -i kafka-client --namespace kafka -- bash
PRODUCER:
kafka-console-producer.sh \
--broker-list kafka-0.kafka-headless.kafka.svc.cluster.local:9092 \
--topic test
CONSUMER:
kafka-console-consumer.sh \
--bootstrap-server kafka.kafka.svc.cluster.local:9092 \
--topic test \
--from-beginning
查看pod、svc状态
# kubectl get pod,svc -n kafka
NAME READY STATUS RESTARTS AGE
pod/kafka-0 0/1 Pending 0 34s
pod/kafka-client 1/1 Running 0 3d21h
pod/kafka-zookeeper-0 1/1 Running 0 34s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kafka ClusterIP 10.43.97.41 <none> 9092/TCP 34s
service/kafka-headless ClusterIP None <none> 9092/TCP,9093/TCP 34s
service/kafka-zookeeper ClusterIP 10.43.127.105 <none> 2181/TCP,2888/TCP,3888/TCP 34s
service/kafka-zookeeper-headless ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 34s
4、操作kafka集群
根据helm创建成功的提示,我们可以创建客户端去执行kafka相关的操作
创建kafka-client的pod
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:2.6.0-debian-10-r57 --namespace kafka --command -- sleep infinity
进入到容器
kubectl -n kafka exec -it kafka-client bash
生产者
kafka有生产者和消费者的概念,生产者会生产数据,消费者去消费生产者产生的数据,具体可以先了解一下相关的概念
首先生产者先生产数据,执行如下命令,可以进入到生产者的input端
kafka-console-producer.sh --broker-list kafka-0.kafka-headless.kafka.svc.cluster.local:9092 --topic test
例如我们输入rancher run everywhere
> rancher run everywhere
消费者
然后消费者消费数据
kafka-console-consumer.sh --bootstrap-server kafka.kafka.svc.cluster.local:9092 --topic test --from-beginning
输入上述命令,就可以查看到刚刚在生产者生产的数据
rancher run everything
5、对接Rancher logging
首先在Rancher上创建一个项目,并部署一个nginx应用

接着在跳转到工具 -> 日志,选择Kafka
有两种方式连接到kafka集群,分别是zookeeper和broker,这里以zookeeper访问端点类型为例
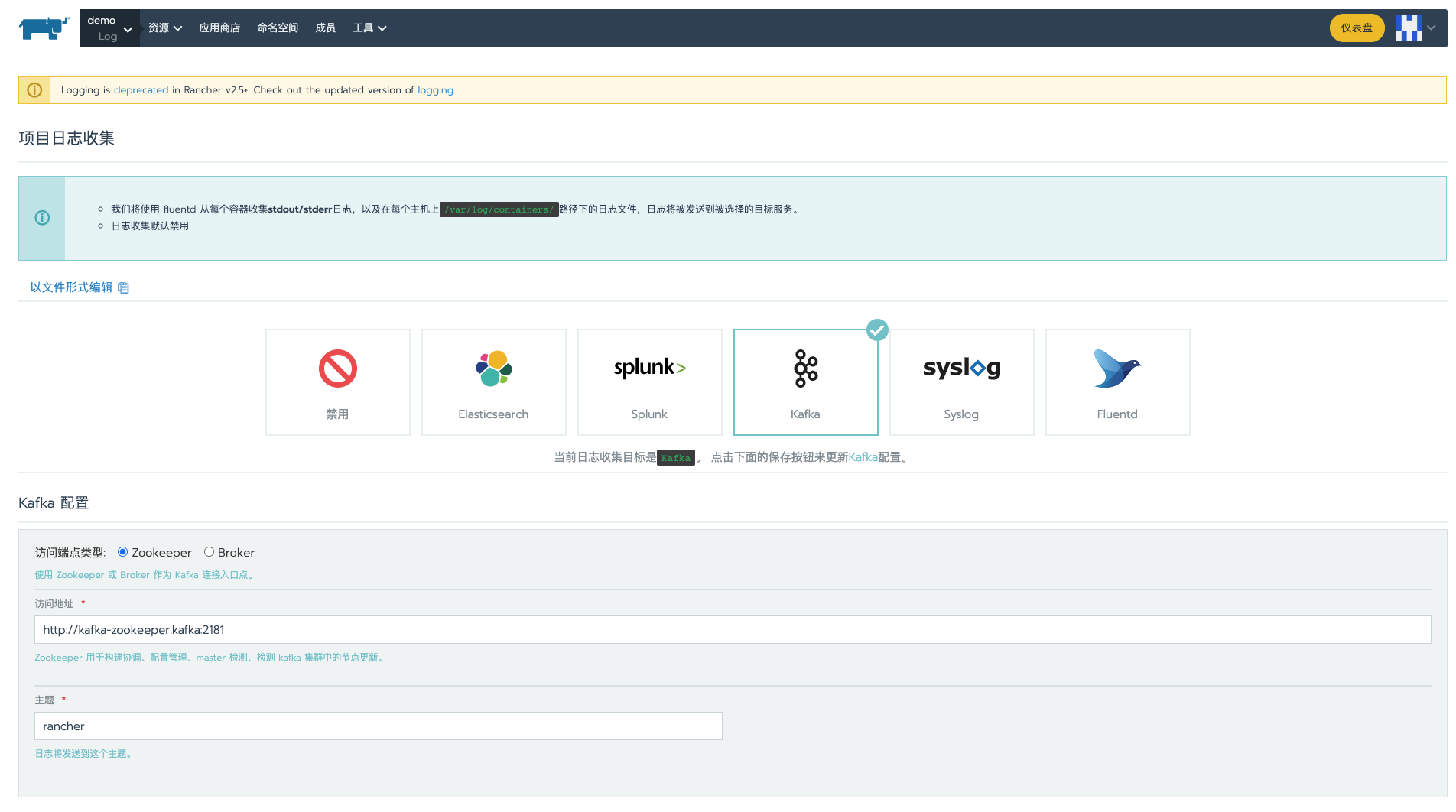
参数解释:
访问地址:http://kafka-zookeeper.kafka:2181,这里填写对应的访问地址,由于选择的是zookeeper,所以填写zookeeper相关的service访问地址,也可以写clusterIP,默认端口是2181
主题:rancher,日志将会发送到这个主题上
其他参数:
刷新时间间隔:默认60s,如果是测试环境,可以设置为10s更快的查看效果
点击测试按钮,等待结果返回验证通过后,点击保存按钮,Rancher会在System项目下创建相应的fluentd工作负载,到这里日志对接基本没问题了
6、验证效果
访问nginx应用,然后等待对应的刷新时间间隔后,在kafka-client中查看是否能消费到数据

开启SASL认证方式
values-production.yaml中的配置会包含更多面向生产的配置,例如启用持久化存储,启用sasl相关认证等,所以可以直接使用这个配置文件进行创建kafka集群,会自动sasl相关认证的功能
1、helm 安装kafka
这里为了方便都关闭了,取消了持久化存储,关闭了相关metric,设置生产环境按需开启
其中autoCreateTopicsEnable设置为true,作用是开启自动创建topic功能,如果关闭这个,则需要手动创建topic才能对接rancher,生产环境也建议关闭掉
helm install kafka -n kafka -f values-production.yaml --set persistence.enabled=false --set zookeeper.persistence.enabled=false --set metrics.kafka.enabled=false --set metrics.jmx.enabled=false --set zookeeper.metrics.enabled=false --set autoCreateTopicsEnable=true .
执行完helm install后会输出以下内容
NAME: kafka
LAST DEPLOYED: Wed Nov 25 18:49:35 2020
NAMESPACE: kafka
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
** Please be patient while the chart is being deployed **
Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:
kafka.kafka.svc.cluster.local
Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:
kafka-0.kafka-headless.kafka.svc.cluster.local:9092
kafka-1.kafka-headless.kafka.svc.cluster.local:9092
kafka-2.kafka-headless.kafka.svc.cluster.local:9092
You need to configure your Kafka client to access using SASL authentication. To do so, you need to create the 'kafka_jaas.conf' and 'client.properties' configuration files by executing these commands:
- kafka_jaas.conf:
cat > kafka_jaas.conf <<EOF
KafkaClient {
org.apache.kafka.common.security.scram.ScramLoginModule required
username="user"
password="$(kubectl get secret kafka-jaas -n kafka -o jsonpath='{.data.client-passwords}' | base64 --decode | cut -d , -f 1)";
};
EOF
- client.properties:
cat > client.properties <<EOF
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-256
EOF
To create a pod that you can use as a Kafka client run the following commands:
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:2.6.0-debian-10-r57 --namespace kafka --command -- sleep infinity
kubectl cp --namespace kafka /path/to/client.properties kafka-client:/tmp/client.properties
kubectl cp --namespace kafka /path/to/kafka_jaas.conf kafka-client:/tmp/kafka_jaas.conf
kubectl exec --tty -i kafka-client --namespace kafka -- bash
export KAFKA_OPTS="-Djava.security.auth.login.config=/tmp/kafka_jaas.conf"
PRODUCER:
kafka-console-producer.sh \
--producer.config /tmp/client.properties \
--broker-list kafka-0.kafka-headless.kafka.svc.cluster.local:9092,kafka-1.kafka-headless.kafka.svc.cluster.local:9092,kafka-2.kafka-headless.kafka.svc.cluster.local:9092 \
--topic test
CONSUMER:
kafka-console-consumer.sh \
--consumer.config /tmp/client.properties \
--bootstrap-server kafka.kafka.svc.cluster.local:9092 \
--topic test \
--from-beginning
可以看到,已经在k8s集群中创建了3个节点的kafka集群
2、创建kafka client端
由于设置了sasl认证,所以需要创建client.properties和kafka_jaas.conf两个文件,并拷贝到client端,client端使用这两个配置文件才能对kafka集群进行相关操作
创建kafka_jaas.conf
cat > kafka_jaas.conf <<EOF
KafkaClient {
org.apache.kafka.common.security.scram.ScramLoginModule required
username="user"
password="$(kubectl get secret kafka-jaas -n kafka -o jsonpath='{.data.client-passwords}' | base64 --decode | cut -d , -f 1)";
};
EOF
创建kafka_jaas.conf
cat > kafka_jaas.conf <<EOF
KafkaClient {
org.apache.kafka.common.security.scram.ScramLoginModule required
username="user"
password="$(kubectl get secret kafka-jaas -n kafka -o jsonpath='{.data.client-passwords}' | base64 --decode | cut -d , -f 1)";
};
EOF
拷贝到client端内
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:2.6.0-debian-10-r57 --namespace kafka --command -- sleep infinity
kubectl cp --namespace kafka client.properties kafka-client:/tmp/client.properties
kubectl cp --namespace kafka kafka_jaas.conf kafka-client:/tmp/kafka_jaas.conf
3、Rancher对接Kafka
SASL认证,只支持通过broker连接入口,所以需要配置broker相关参数
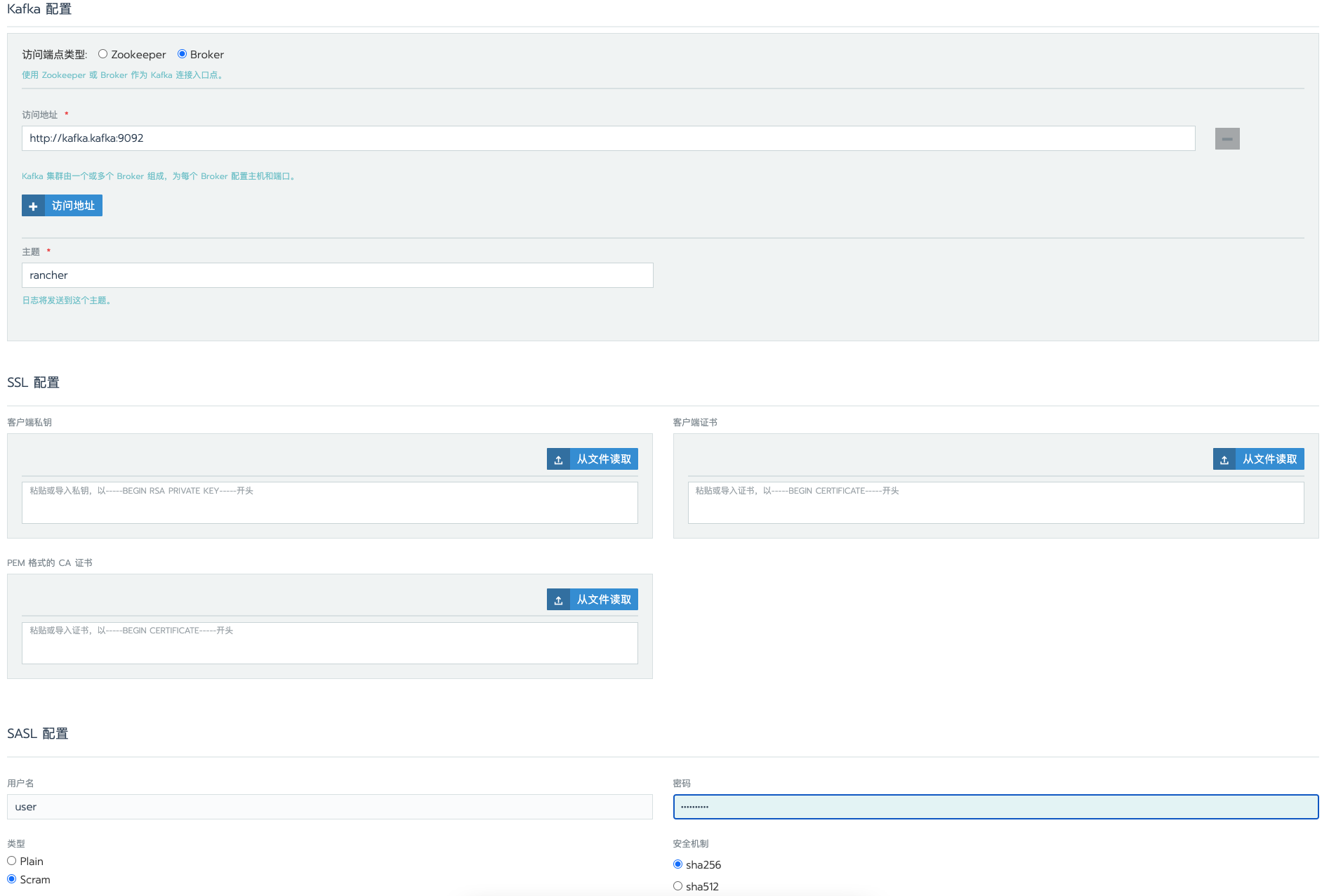
kafka配置
访问端点类型:选择Broker
访问地址:填写kafka serviceIP地址,这里填写http://kafka.kafka:9092
主题:日志发送的主题
SSL配置
如果SASL类型为Scram,则不用配置SSL,反之当SASL类型为Plain时,需要配置SSL
SASL配置
用户名:默认是user,可以在values.yaml中,通过配置auth.jaas.clientUsers修改
密码:默认是随机值,可以通过kubectl get secret kafka-jaas -n kafka -o jsonpath='{.data.client-passwords}' | base64 --decode | cut -d , -f 1这个命令查看,另外也可以通过配置auth.jaas.clientPasswords来修改
类型:Scram
安全机制:sha256
点击测试按钮,等待结果返回验证通过后,点击保存按钮,Rancher会在System项目下创建相应的fluentd工作负载,到这里日志对接基本没问题了
4、验证效果
通过kafka-client查看日志是否对接成功
进入kafka-client pod bash环境
kubectl exec -it kafka-client -n kafka -- bash
由于开启了认证,需要export相关环境变量
最后通过kafka-console-consumer.sh命令查看日志是否发送过来了
export KAFKA_OPTS="-Djava.security.auth.login.config=/tmp/kafka_jaas.conf"
kafka-console-consumer.sh --consumer.config /tmp/client.properties --bootstrap-server kafka.kafka.svc.cluster.local:9092 --topic rancher --from-beginning
效果如下:
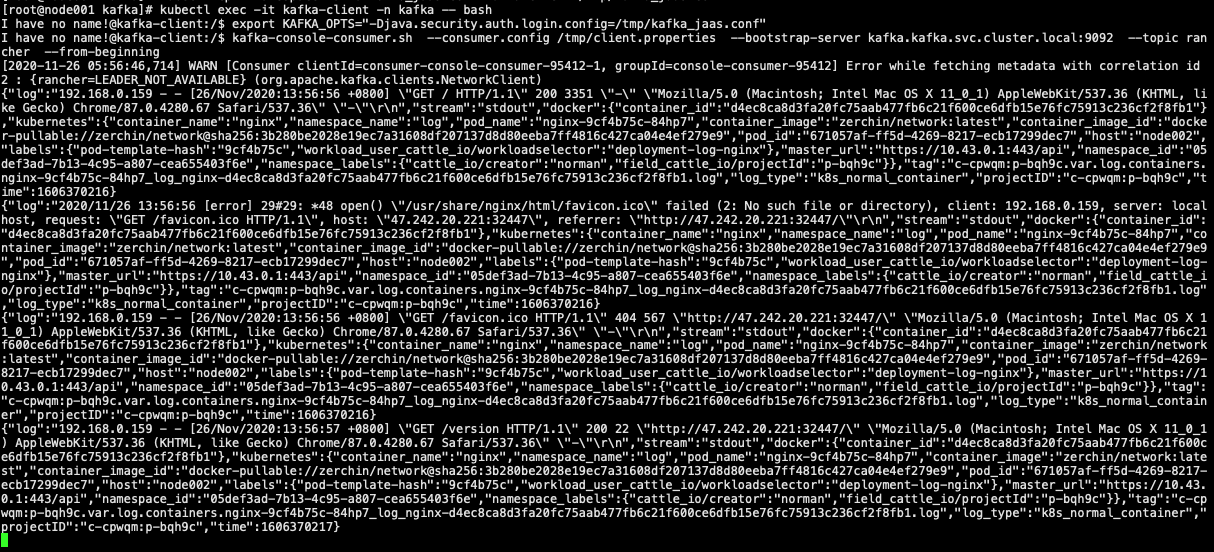
kafka-client相关命令
查看topic 列表
kafka-topics.sh --zookeeper kafka-zookeeper:2181 --list
创建topic
kafka-topics.sh --zookeeper kafka-zookeeper:2181 --topic rancher --create --partitions 1 --replication-factor 1
删除topic
kafka-topics.sh --delete --zookeeper kafka-zookeeper:2181 --topic test
如果delete.topic.enable=true,则会直接删除topic,如果delete.topic.enable=false,则只是把这个 topic 标记为删除(marked for deletion),重启 Kafka Server 后删除
生产者生产数据
kafka-console-producer.sh --producer.config /tmp/client.properties --broker-list kafka-0.kafka-headless.kafka.svc.cluster.local:9092,kafka-1.kafka-headless.kafka.svc.cluster.local:9092,kafka-2.kafka-headless.kafka.svc.cluster.local:9092 --topic rancher
消费者消费生产者的数据
kafka-console-consumer.sh --consumer.config /tmp/client.properties --bootstrap-server kafka.kafka.svc.cluster.local:9092 --topic rancher --from-beginning
kafka对接Rancher日志的更多相关文章
- spark读取 kafka nginx网站日志消息 并写入HDFS中(转)
原文链接:spark读取 kafka nginx网站日志消息 并写入HDFS中 spark 版本为1.0 kafka 版本为0.8 首先来看看kafka的架构图 详细了解请参考官方 我这边有三台机器用 ...
- scribe、chukwa、kafka、flume日志系统对比
scribe.chukwa.kafka.flume日志系统对比 1. 背景介绍许多公司的平台每天会产生大量的日志(一般为流式数据,如,搜索引擎的pv,查询等),处理 这些日志需要特定的日志系统,一 ...
- 项目01-flume、kafka与hdfs日志流转
项目01-flume.kafka与hdfs日志流转 1.启动kafka集群 $>xkafka.sh start 3.创建kafka主题 kafka-topics.sh --zookeeper s ...
- 一次flume exec source采集日志到kafka因为单条日志数据非常大同步失败的踩坑带来的思考
本次遇到的问题描述,日志采集同步时,当单条日志(日志文件中一行日志)超过2M大小,数据无法采集同步到kafka,分析后,共踩到如下几个坑.1.flume采集时,通过shell+EXEC(tail -F ...
- Kafka学习笔记之Kafka自身操作日志的清理方法(非Topic数据)
0x00 概述 本文主要讲Kafka自身操作日志的清理方法(非Topic数据),Topic数据自己有对应的删除策略,请看这里. Kafka长时间运行过程中,在kafka/logs目录下产生了大量的ka ...
- ELK+Kafka集群日志分析系统
ELK+Kafka集群分析系统部署 因为是自己本地写好的word文档复制进来的.格式有些出入还望体谅.如有错误请回复.谢谢! 一. 系统介绍 2 二. 版本说明 3 三. 服务部署 3 1) JDK部 ...
- 【转载】scribe、chukwa、kafka、flume日志系统对比
原文地址:http://www.ttlsa.com/log-system/scribe-chukwa-kafka-flume-log-system-contrast/ 1. 背景介绍许多公司的平台每天 ...
- logstash redis kafka传输 haproxy日志
logstash 客户端收集 haproxy tcp日志 input { file { path => "/data/haproxy/logs/haproxy_http.log&qu ...
- scribe、chukwa、kafka、flume日志系统对比 -摘自网络
1. 背景介绍许多公司的平台每天会产生大量的日志(一般为流式数据,如,搜索引擎的pv,查询等),处理这些日志需要特定的日志系统,一般而言,这些系统需要具有以下特征:(1) 构建应用系统和分析系统的桥梁 ...
随机推荐
- Cocos2d-x extensions库使用问题解决方法
需要在加入头文件#include "cocos-ext.h" 1>e:\cocos\cocos2d-x\cocos2d-x-3.10\extensions\gui\cccon ...
- java数据结构-09双端队列
一.相关概念: (Deque)双端队列能够在队头.队尾进行添加.删除等操作 二.接口设计: 三.代码实现 public class Deque<E> { private List< ...
- Yum 命令出现[Errno 256] No more mirrors to try错误的解决方式
今天我在虚拟机上安装 NetCore 的 SDK 的时候,出现错误,执行命令:"yum install dotnet-sdk-3.1",最后安装失败,很多安装包没有找到镜像.解决方 ...
- Windows10系统下Hadoop和Hive开发环境搭建填坑指南
前提 笔者目前需要搭建数据平台,发现了Windows系统下,Hadoop和Hive等组件的安装和运行存在大量的坑,而本着有坑必填的目标,笔者还是花了几个晚上的下班时候在多个互联网参考资料的帮助下完成了 ...
- Python专题之详解enumerate和zip
enumerate 第一个是枚举函数. 在我们的日常编程过程中,我们经常遇到一个问题. 在C语言和一些古老的语言中没有迭代器的概念,所以当我们想要遍历数组或容器时,我们只能使用下标.使用迭代器,我们的 ...
- C\C++语言重点——指针篇 | 为什么指针被誉为 C 语言灵魂?(一文让你完全搞懂指针)
本篇文章来自小北学长的公众号,仅做学习使用,部分内容做了适当理解性修改和添加了博主的个人经历. 注:这篇文章好好看完一定会让你掌握好指针的本质! 看到标题有没有想到什么? 是的,这一篇的文章主题是「指 ...
- Flink基础:实时处理管道与ETL
往期推荐: Flink基础:入门介绍 Flink基础:DataStream API Flink深入浅出:资源管理 Flink深入浅出:部署模式 Flink深入浅出:内存模型 Flink深入浅出:J ...
- 这么好?中科图新项目经理教你开发LocaSpace功能
LocaSpace是专注于实景三维数据应用的三维数字地球软件,为开发者提供强大.稳定的SDK服务,花费很少的精力即可在自己产品中集成某项功能. 我们将于2018年7月18日至7月20日举办&quo ...
- Java—递归
递归 1. 概述 方法中调用当前方法 2. 递归需要注意的事项 递归次数不能过多,否则内存溢出 3. 案例 3.1 获取指定目录下的文件名 public class AllDirPath { /* * ...
- 开发IDE的一些设置
一.修改和设置idea或eclipse的快捷键: 二.idea的settings的一些设置: settings 可以导出,也可以导入.也可以设置每次新建和新打开一个工程用同一个setting 三.全局 ...