NLP任务梳理总结
NLP任务
前处理任务
前处理任务的结果可作为下游任务输入的额外特征。
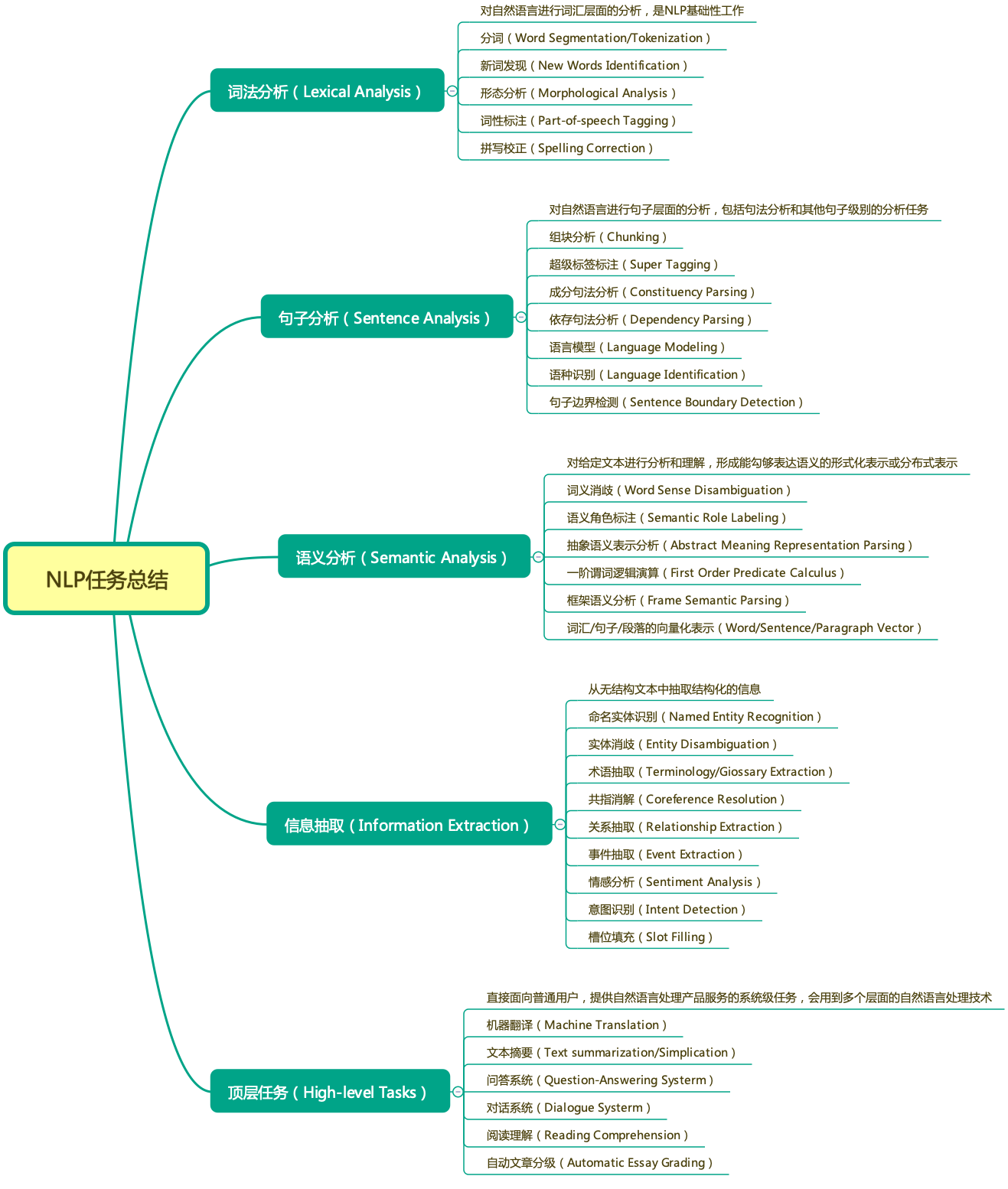
POSTa(词性标注)
往模型中输入句子,对每一个token进行词性的识别。
识别出的词性可以用于下游任务。
Word Segmentation(分词)
对于英文,显然句子有天然的分词。所以分词通常是针对中文句子。
分词之后,模型的输入就可以以词汇作单位,而不再以字作单位。
以下面例子做说明:
将一个句子按字输入模型,训练模型来对每个字来进行二分类决定每个字的对应位置输出N或者Y(N/Y是词的边界标识)

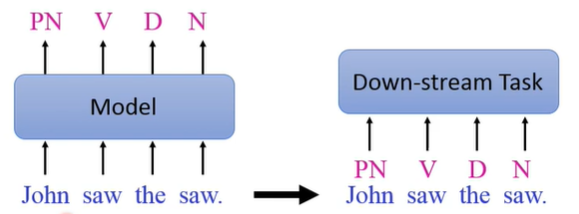
Parsing(语义分析)
给定句子产生树状结构——句子的语法结构。
Coreference Rosolution(共指消解)
从一段文章或者一段对话中找出指代同一个人或事物的所有词汇。

具体NLP任务
Summarization(文本摘要)
抽取式摘要:基于二分类任务,每个句子分开考虑。
衡量文章中句子应不应该放到摘要里面,但是这么做远远不够。

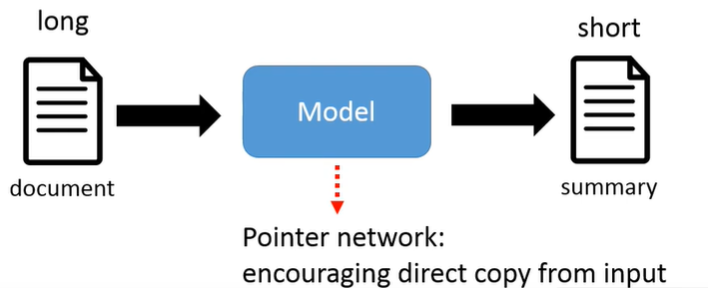
生成式摘要:属于seq2seq模型,输入长文本,模型用自己的语言进行短摘要的生成。
模型的copy能力:输入文本序列和输出摘要很有可能有很多共用词汇,这些共用词汇经过模型的修改整合形成摘要的文本。因此模型需要增加输入copy能力,怎么实现?Pointer network(指针网络)。
Machine Translation(机器翻译)
seq2seq

audio2seq

audio2audio
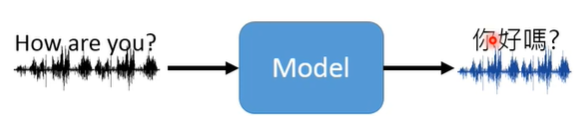
Grammer Error Correction(语法纠正)
seq2seq?
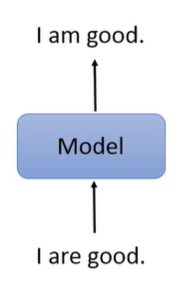
不,杀鸡焉用牛刀。
seq2class
输入句子,做分类,输出要对token要做的动作的标识(C/R/A/D)。

C——复制,保持不变
A——在后面增加词汇
R——置换,把词换个时态或者换成别的词
D——删除
Sentiment Classfication(情感分类)
输入一段文本或者评论,训练模型,输出文本的情感分类(正面/负面)。
seq2class

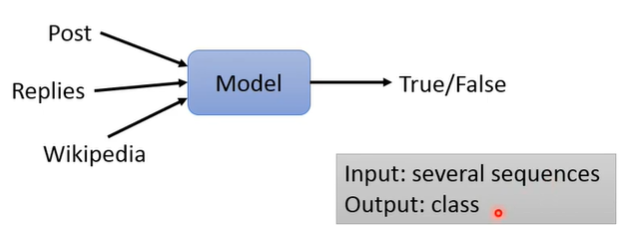
Stance Detection(立场侦测)
seq2class
通过一则博文或者文章以及其下的评论回复来进行评论者所处立场的判断。
立场通常有四类:SDQC(Support、Denying、Querying and Commenting)。
立场侦测经常被用于事实预测:
事实预测:
seq2class
根据新闻消息或者博文的评论立场以及外部的知识判断消息或文章内容的真实性。
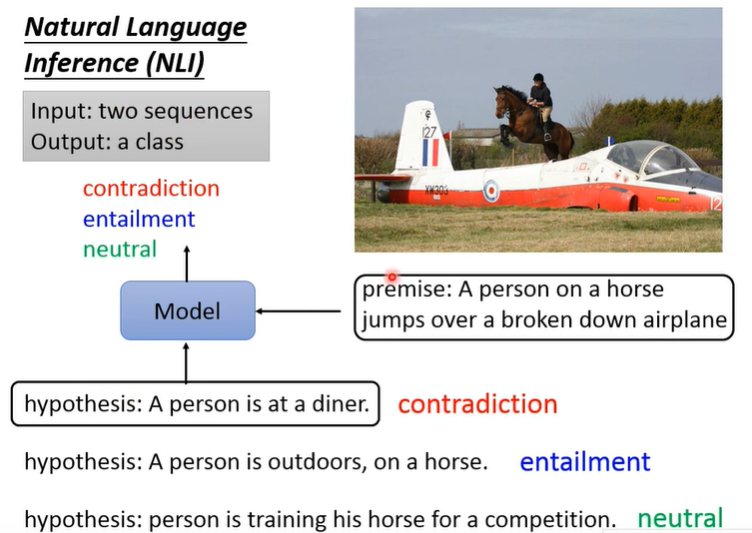
Natural Language Inference(自然语言推理)
seq2class
推理模型的文本输入:premise(前提) + hypothesis(假设)
模型输出:对假设是否成立的判断结果,矛盾/包含(可推得)/中立(contradiction/entailment/neutral)
Question Answering(问答)
传统的基于检索的问答系统
简单的(模组少):
.png)
问题处理——对问题进行格式化,检测其答案的类别
检索资料库——进行文档、文章的检索选择
答案的生成和评估——从候选文章中抽取答案,抽取的答案根据第一步检测到的答案类别评估其正确性
复杂的(模组多):
.png)
和简单架构的区别:
问题处理——模组更多
候选答案生成——综合检索文章得到的候选答案和从自带的有结构资料库中调取的答案
答案评分
融合对等答案,返回答案及其可信度
基于深度学习的QA
seq2seq
输入问题文本和外部结构化/无结构化的知识(大多来自搜索引擎),训练模型得到问题的答案。
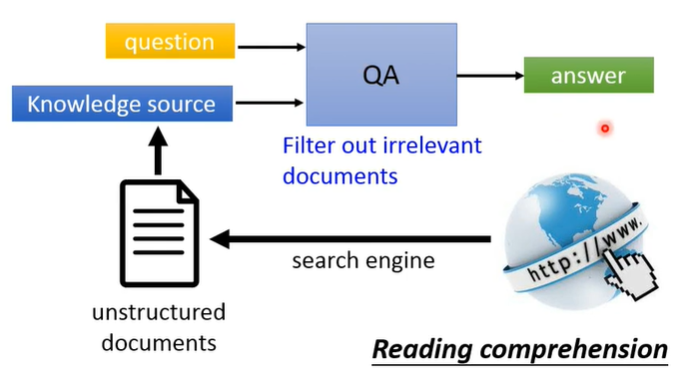
但是要实现直接向模型输入问题和外部知识就生成问题答案还有非常长的一段路要走。目前我们常做的只是从文本中抽取答案。
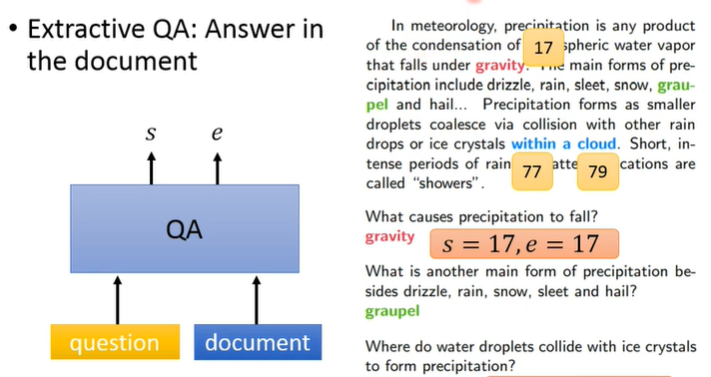
抽取式QA:
seq2seq
答案就在背景文章里面,向模型输入背景文章和问题,其实就是做通常意义上的阅读理解,模型产生抽取的答案文本在文章中的 start position 和 end position。
Dialogue(对话)
对话涉及到自然语言生成(NLG)和自然语言理解(NLU)
Chatting(闲聊)
seq2seq
聊天都是有背景的,所以模型的输入应该是增量式的,模型的输出是根据之前的对话内容产生的。
根据对话的需求可以进行定制:
Task-oriented(任务导向的对话)
seq2seq
需要实现一定的功能,比如提供订票、订餐厅、订酒店等服务

系统架构
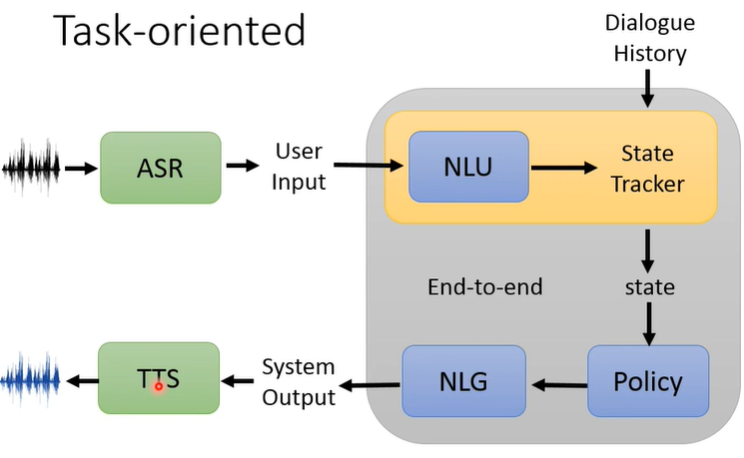
State Tracker记录当前对话的状态
知识图
NER(命名实体识别)
seq2class
识别出句子中的人名、地名、组织等实体

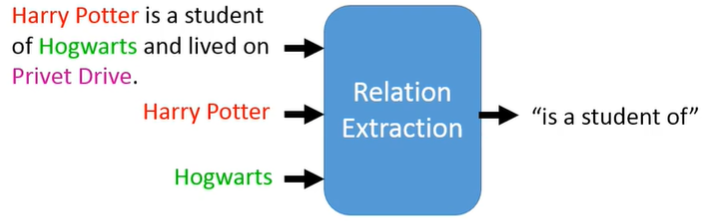
RE(关系抽取)
seq2class
输入文本和文本中两个实体,训练模型得到两个实体之间的关系
关系的种类基本是固定的,因此关系抽取的模型往往是去做一个复杂的分类任务
综合任务
综合任务的意义:看模型是否是真的“理解”了人类语言,能“举一反三”
GLUE
分为三大类
- 文本分类(语法错误检查、文本情感分析)
- 文本相似度计算
- 自然语言推理

Super GLUE
包含8个NLP任务,大多和QA有关
DecaNLP
同一个模型解决10个NLP任务
怎么实现?往QA的方向改造这些任务

总结
根据这些NLP任务的输入输出,把这些任务和任务相关的一些技术手段进行梳理
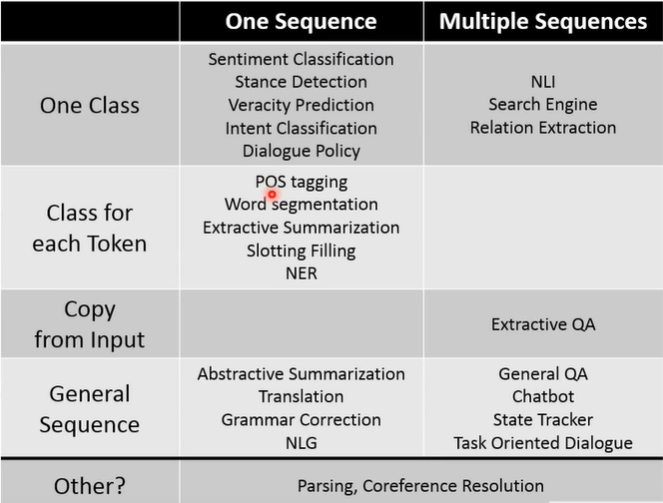
one on one
seq2class
- 情感分析
- 立场检测
- 文本内容辨真伪
- 文本意图识别
- 对话决策
seq2tokenclass
- 词性标注
- 分词
- 抽取式摘要
- 命名实体识别
seq2seq
- 抽象式摘要
- 机器翻译
- 文本语法矫正
- 自然语言生成
n on one
seq2class
- 自然语言推理
- 搜索引擎
- 关系抽取
copy from input
- 抽取式QA
seq2seq
- 常规QA
- 任务导向对话
- 聊天机器人
- State Tracker
others
- 语义分析
- 共指消解
NLP任务梳理总结的更多相关文章
- ICLR2021对比学习(Contrastive Learning)NLP领域论文进展梳理
本文首发于微信公众号「对白的算法屋」,来一起学AI叭 大家好,卷王们and懂王们好,我是对白. 本次我挑选了ICLR2021中NLP领域下的六篇文章进行解读,包含了文本生成.自然语言理解.预训练语言模 ...
- 【NLP】十分钟快览自然语言处理学习总结
十分钟学习自然语言处理概述 作者:白宁超 2016年9月23日00:24:12 摘要:近来自然语言处理行业发展朝气蓬勃,市场应用广泛.笔者学习以来写了不少文章,文章深度层次不一,今天因为某种需要,将文 ...
- 【NLP】前戏:一起走进条件随机场(一)
前戏:一起走进条件随机场 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有 ...
- 【NLP】蓦然回首:谈谈学习模型的评估系列文章(一)
统计角度窥视模型概念 作者:白宁超 2016年7月18日17:18:43 摘要:写本文的初衷源于基于HMM模型序列标注的一个实验,实验完成之后,迫切想知道采用的序列标注模型的好坏,有哪些指标可以度量. ...
- NLP点滴——文本相似度
[TOC] 前言 在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性.而有了文本之间相似性的度 ...
- 【NLP】基于自然语言处理角度谈谈CRF(二)
基于自然语言处理角度谈谈CRF 作者:白宁超 2016年8月2日21:25:35 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】基于机器学习角度谈谈CRF(三)
基于机器学习角度谈谈CRF 作者:白宁超 2016年8月3日08:39:14 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都 ...
- 【NLP】基于统计学习方法角度谈谈CRF(四)
基于统计学习方法角度谈谈CRF 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】条件随机场知识扩展延伸(五)
条件随机场知识扩展延伸 作者:白宁超 2016年8月3日19:47:55 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有应 ...
随机推荐
- Openstack 调整云主机大小失败解决
Openstack 使用调整openstack云主机大小报错 tailf /var/log/nova/nova-compute.log 2017-02-24 18:21:29.088 28511 ER ...
- [Binder深入学习一]Binder驱动——基础数据结构
具体代码路径: kernel/drivers/staging/android/binder.c kernel/drivers/staging/android/binder.h /* * binder_ ...
- Cloudera Manager和CDH安装部署
本次安装采用离线安装的方式,需要提前下载好需要的包. 1. 准备工作 1.1 环境说明 操作系统:RedHat企业级Linux6.5 64-bit Cloudera Manager:5.8.4 CDH ...
- mariadb 数据库集群配置
mariadb集群配置(主从和多主) mariadb主从 主从多用于网站架构,因为主从的同步机制是异步的,数据的同步有一定延迟,也就是说有可能会造成数据的丢失,但是性能比较好,因此网站大多数用的是 ...
- Nginx 配置 HTTPS 完整过程(阿里云申请免费版一年ssl证书)
1. nginx 的 ssl 模块安装 查看 nginx 是否安装 http_ssl_module 模块. $ /usr/local/nginx/sbin/nginx -V 如果出现 configur ...
- 苏大文正节点一 ORA-00603 ORA-27504 ORA-27300 ORA-27301 ORA-27302 BUG
Problem Description --------------------------------------------------- Tue Sep 01 04:05:33 2020 s ...
- ssh 远程执行命令 nohup 无效问题
昨夜1:00多准备睡觉了,突然一哥们咨询了我一个问题. 他A机器上远程执行B机器(ssh user@ip "command")上的脚本,B上的服务并没有起来. 看了下截图,脚本确实 ...
- a标签包裹div的问题
示例代码 1 <a href="#"> 2 <div> 3 <a href="#"></a> 4 </di ...
- 读完这篇,让你真正理解Redis持久化
什么叫持久化? 用一句话可以将持久化概括为:将数据(如内存中的对象)保存到可永久保存的存储设备中. 持久化的主要应用是将内存中的对象存储在数据库中,或者存储在磁盘文件中. XML 数据文件中等等. 也 ...
- 简述application.properties和application.yml 以及 @ConfigurationProperties 和@PropertySource @Value 和@ImportResource的用法,区别
问题: 如何在application.properties和application.yml中配置String,Date,Object,Map,List类型的属性,并且idea能提示 先写一个Perso ...