分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集)、DAG:Direct Acyclic Graph(有向无环图)、SparkContext、Transformations、Actions。
1 Spark简介
1.1 什么是spark
Spark:基于内存计算的大数据并行计算框架,用于构建大型的、低延迟的数据分析应用程序。
Spark特点:
- 运行速度快:使用先进的DAG(有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MR快100倍,基于磁盘的执行速度快10倍。
- 容易使用:支持多语言(scala、python、R)进行编程,简洁的API设计使用户轻松构建并行程序,也可以用spark shell进行交互式编程。
- 通用性:提供技术栈,包括SQL查询、流式计算、机器学习和图算法组件。
- 运行模式多样:可独立运行集群模式、hadoop、EC2云环境,并且可以访问HDFS、Cassandra、Hbase、Hive等多种数据源。
1.2 spark的生态系统
大数据处理主要包括三个类型:
- 复杂的批量数据处理:时间跨度通常在数十分钟到数小时之间,比如Hadoop MR就可以进行批量数据处理。
- 基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟之间,比如Impala进行交互式查询(与Hive类似,但底层引擎不同提供了实时交互式SQL查询)
- 基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒之间,比如开源流计算框架Storm。
但是存在几个问题:同时部署三种不同的软件,各场景之间无法做到无缝共享,需要进行格式转换;维护成本高;难以对同一个集群中的各个系统进行统一的资源协调和分配。
spark解决了这些问题,形成了一个完整的生态系统,既能提供内存计算框架,也支持SQL即时查询、实时流式计算、机器学习和图计算等。Spark可以部署在资源管理器YARN上,提供一站式的大数据解决方案。
Spark生态系统图:

Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX 等组件,各个组件的具体功能如下:
- Spark Core[处理引擎]:Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache Spark,就是指Spark Core;
- Spark SQL[访问和接口]:Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
- Spark Streaming:Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等;
- MLlib(机器学习):MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作;
- GraphX(图计算):GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
1.3 spark运行架构
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
Spark运行架构图:
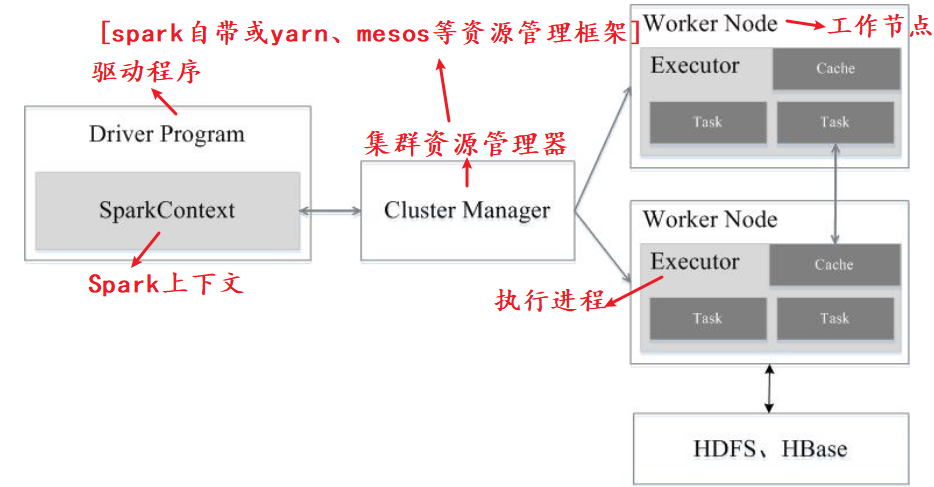
Spark所采用的Executor[执行进程]有两个优点:
- 一是利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动开销;
- 二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到HDFS等文件系统里,因而有效减少了IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写IO性能。
spark 运行流程图:
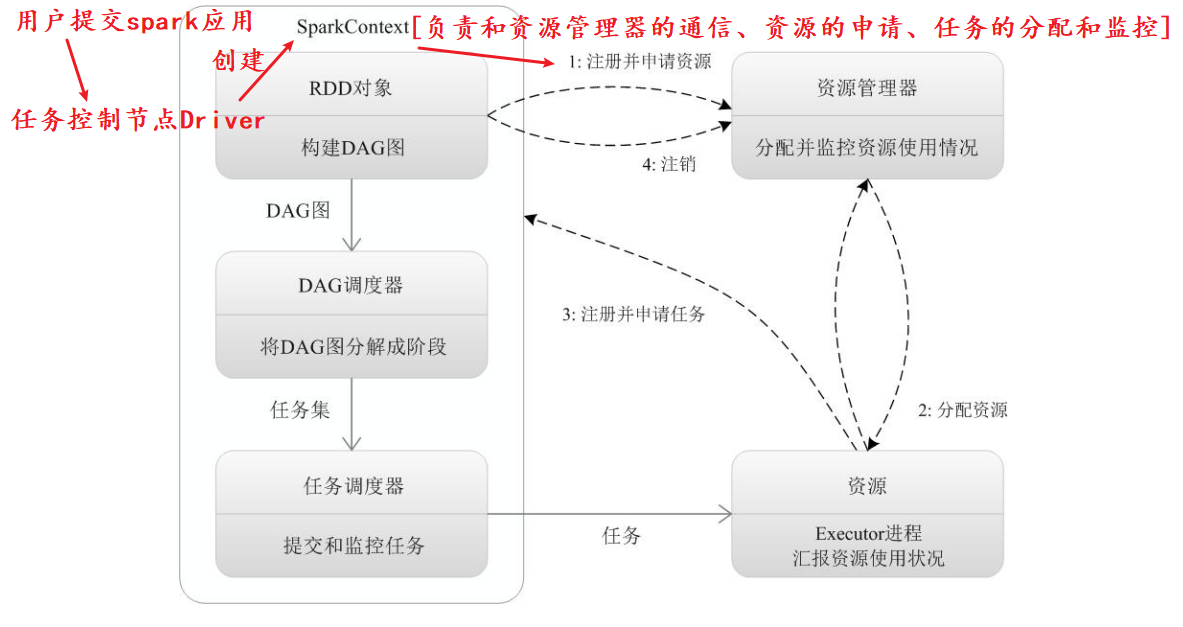
(1)当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源;
(2)资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上;
(3)SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor;
(4)任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
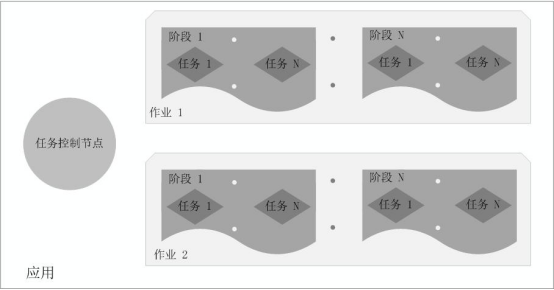
spark各概念相关关系:
1.4 spark相对于hadoop的优势
Hadoop的缺点:
- 表达能力有限
- 磁盘IO开销大
- 延迟高
Spark的优点:
- spark的计算模式也属于MapReduce,但是不局限与此,还提供了多种数据集操作类型,编程模型比MR更灵活。
- Spark提供了内存计算,中间结果直接放在内存中,带来了更高的迭代运算效率。
- Spark机制更优:spark基于DAG的任务调度机制,MR是基于迭代执行机制。
- Spark提供了API,spark代码量比Hadoop少2-5倍,同时spark还提供了实时交互式编程反馈,可以方便验证、调整算法。
spark的作用:主要用于替代Hadoop中的MR计算模型,并不能完全替换Hadoop。
2 Spark环境搭建
2.1 基础环境
|
名称 |
版本 |
下载地址 |
|
VMware Workstation Pro |
VMware-workstation-full-15.5.2 |
http://www.vmware.com/ |
|
Ubuntu |
ubuntu-18.04.4-desktop-amd64.iso |
https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/18.04.4/ubuntu-18.04.4-desktop-amd64.iso |
|
java |
jdk-8u231-linux-x64.tar.gz |
https://www.oracle.com/java/technologies/javase-downloads.html |
|
scala |
scala-2.11.7.tgz |
https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz |
|
Hadoop |
hadoop-2.7.7.tar.gz |
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz |
|
spark |
spark-2.4.5-bin-hadoop2.7.tgz |
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz |
2.2 安装步骤
spark安装前提:
- 虚拟机
- 配置hadoop用户
spark安装内容主要包括:
- 安装jdk
- 安装hadoop
- 安装scala
- 安装spark
2.2.1 安装 master 虚拟机
- 1.打开VMware——新建虚拟机——选择典型安装——稍后安装操作系统
- 2.虚拟机名称master
- 3.内存大小建议 8G
- 4.安装时选择最小安装
- 5.等待系统安装完成
2.2.2 配置名为 hadoop 的用户
//1.打开master虚拟机,按住Ctrl+Alt+T进入终端
//2.创建hadoop用户
sudo useradd -m hadoop -s /bin/bash
//3.为hadoop用户设置密码
sudo passwd Hadoop
//4.为hadoop用户添加管理员权限
sudo adduser hadoop sudo
//5.切换用户
su hadoop
2.2.3 修改虚拟机主机名以及hosts文件,这里以修改主节点主机名称为例,其他节点类似。
//1.查看当前主机名,并修改为master
sudo cat /etc/hosts
//2.修改sudo vim /etc/hosts文件
//集群配置,如有两个节点时,两个从节点的主机依次修改为slave1,slave2
//将主节点和两个从节点的ip和主机名添加到hosts文件中,执行命令
sudo vim /etc/hosts
//3.配置SSH免验证登录,保证master、slave1、slave2可以互相免密登录,参考网址如下:
https://jingyan.baidu.com/article/60ccbceb02bd4264cab197b9.html
//现在确认能否不输入口令就用ssh登录localhost:
$ ssh localhost
//如果不输入口令就无法用ssh登陆localhost,执行下面的命令[如果没有ssh目录,需要手动去进行安装]
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys

2.2.4 安装jdk
//1.下载jdk,解压到路径/opt/java,重命名为jdk
//2.在文件/etc/profile里配置环境变量,执行命令,vi /etc/profile,添加如下内容
export JAVA_HOME=/opt/java/jdk
export JRE_HOME=/opt/java/jdk/jre
export PATH=${JAVA_HOME}/bin:$PATH
//3.环境变量生效
source /etc/profile
//4.验证是否配置好
Java –version
PS:安装JDK出现找不到目录,原因是32位和64位的包不兼容,所以一定要注意下载系统对应的版本。
2.2.5 安装hadoop
//1.下载hadoop压缩包到路径/opt/,重命名为hadoop
//2. 配置环境变量vi /etc/profile
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH HADOOP_HOME HADOOP_CONF_DIR
//3.修改配置文件vi /opt/hadoop/etc/hadoop/hadoop-env.sh
//修改该文件里的java环境变量为实际的
export JAVA_HOME=/opt/java/jdk
//4.修改配置文件vi /opt/hadoop/etc/hadoop/slaves[目的:控制从节点,datanode、nodemanager在哪些机器上]
master
//ps:如果有子节点,配置子节点名称
//5.配置vi /opt/hadoop/etc/hadoop/core-site.xml[master是对应的主机名]
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
//6.配置vi /opt/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/dfs/name</value>
<description>namenode的目录位置,对应的目录需要存在value里面的路径</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/dfs/data</value>
<description>datanode的目录位置,对应的目录需要存在value里面的路径</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>hdfs系统的副本数量</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
<description>备份namenode的http地址,master是主机名</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<description>hdfs文件系统的web hdfs使能标致</description>
</property>
</configuration>
//7.配置vi /opt/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指明MapRreduce的调度框架为yarn</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>指明MapReduce的作业历史地址</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description>指明MapReduce的作业历史web地址</description>
</property>
</configuration>
//8. 配置vi /opt/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
//集群配置时,hadoop的配置文件修改完了,用scp命令将修改好的hadoop文件传入到子节点即可
//9.环境变量生效
source /etc/profile
//10.环境变量生效,执行命令
hadoop version

2.2.6 安装scala
//1.下载相应版本的scala压缩包到/opt/并解压,重命名为scala
//2.在/etc/profile里增加scala环境变量
export SCALA_HOME=/opt/scala
export PATH=${SCALA_HOME}/bin:$PATH
//3.环境变量生效
source /etc/profile
//4.验证是否配置好
scala –version

2.2.7 安装spark
//1.下载相应版本的spark压缩包到/opt/并解压,重命名为spark
//2.在/etc/profile里增加spark环境变量,vi /etc/profile
export SPARK_HOME=/opt/spark
export PATH=${SPARK_HOME}/bin:$PATH
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.8.1-src.zip:$PYTHONPATH
export PATH=$SPARK_HOME/python:$PATH
//3.修改配置文件vi /opt/spark/conf/spark-env.sh
//首先使用如下命令生成spark-env.sh文件:
cp spark-env.sh.template spark-env.sh
//接下来修改该文件配置vi spark-env.sh
export JAVA_HOME=/opt/java/jdk
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_HOME=/opt/spark
export SCALA_HOME=/opt/scala
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=5G
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_EXECUTOR_CORES=1
export SPARK_EXECUTOR_MEMORY=1G
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native
//4.修改配置文件/opt/spark/conf/slaves,首先使用如下命令生成slaves文件
cp slaves.template slaves
//接着修改配置内容master
//由于是单机,所以没有配置子节点,如果有,比如slave1、slave2,要配置在这。至此,spark的配置文件就修改完了,我们用scp命令将修改好的spark文件传入到子节点即可,不要忘记修改子节点的环境变量
//4.添加java的环境配置文件
sudo vi /opt/spark/sbin/spark-config.sh
//添加一行
export JAVA_HOME=/opt/java/jdk
2.2.8 启动
//1.自定义一个启动脚本,方便启动
//在路径/opt/spark/sbin下创建文件spark-start-all.sh,编辑文件内容如下:
#!/bin/bash
echo -e "start the cluster"
echo -e "start the hadoop"
echo -e "start the hdfs"
/opt/hadoop/sbin/start-dfs.sh[启动Datanode、NameNode、SecondaryNameNode]
echo -e "start the yarn"
/opt/hadoop/sbin/start-yarn.sh[启动NodeManager、ResourceManager]
echo -e "start the spark"
cd /opt/spark
./sbin/start-master.sh[启动Master]
./sbin/start-slaves.sh [启动worker]
jps
echo -e "end"
//2.执行脚本,启动集群
cd /opt/spark/sbin
sh spark-start-all.sh
//启动后可以看到相应的进程启动起来了
2.2.9 执行一个实例
//1.到spark的bin路径下执行./spark-shell命令进入scala的交互模式
//2.编写scala语句,准备数据,在/home/hadoop/Documents下建立一个wordcount.txt文件
,到hadoop的bin路径下执行命令
hadoop fs -mkdir -p /Hadoop/Input
//将本地文件上传到hdfs
hadoop fs -put /home/hadoop/Documents/wordcount.txt /Hadoop/Input
val file=sc.textFile("hdfs://localhost:9000/Hadoop/Input/wordcount.txt")
val rdd=file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
rdd.collect()
rdd.collect().foreach {println}
//执行后可以看到Scala为spark的源生语言,也可以采用python语言,执行方式可以通过以下方式:运行 pyspark、提交python程序、在web页面查看集群情况
总结:
//安装环境vi /etc/profile内添加的所有内容
export JAVA_HOME=/opt/java/jdk
export JRE_HOME=/opt/java/jdk/jre
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH HADOOP_HOME HADOOP_CONF_DIR
export SCALA_HOME=/opt/scala
export PATH=${SCALA_HOME}/bin:$PATH
export SPARK_HOME=/opt/spark
export PATH=${SPARK_HOME}/bin:$PATH
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.8.1-src.zip:$PYTHONPATH
export PATH=$SPARK_HOME/python:$PATH
3 Spark编程基础
3.1 RDD的设计与运行原理
3.1.1 RDD设计背景
在实际应用中,存在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。虽然,类似Pregel等图计算框架也是将结果保存在内存当中,但是,这些框架只能支持一些特定的计算模式,并没有提供一种通用的数据抽象。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
3.1.2 RDD概念及特性
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
- RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
- RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型。
- "行动":用于执行计算并指定输出的形式。
- "转换":指定RDD之间的相互依赖关系。
- "行动"和"转换"的区别:
- 转换操作:(比如map、filter、groupBy、join等)接受RDD并返回RDD。
- 行动操作:(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
- RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用。
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。
RDD典型的执行过程:
- RDD读入外部数据源(或者内存中的集合)进行创建;
- RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
- 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。例如: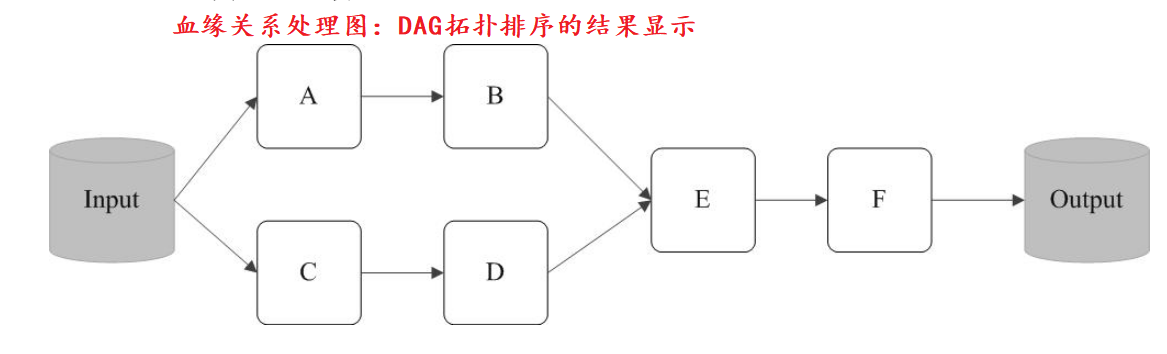
上述这一系列处理称为一个“血缘关系(Lineage)”,即DAG拓扑排序的结果。采用惰性调用,通过血缘关系连接起来的一系列RDD操作就可以实现管道化(pipeline),避免了多次转换操作之间数据同步的等待,而且不用担心有过多的中间数据,因为这些具有血缘关系的操作都管道化了,一个操作得到的结果不需要保存为中间数据,而是直接管道式地流入到下一个操作进行处理。
实例:
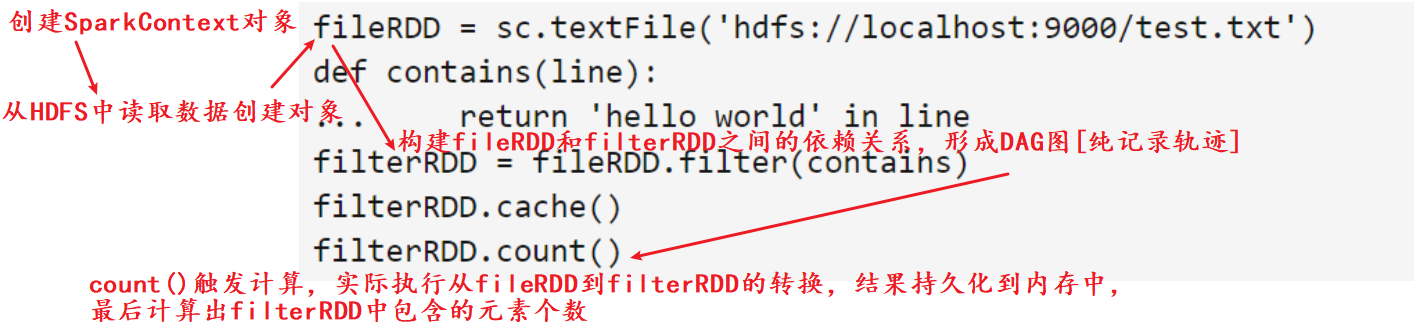
这个程序的执行过程如下:
- 创建这个Spark程序的执行上下文,即创建SparkContext对象;
- 从外部数据源(即HDFS文件)中读取数据创建fileRDD对象;
- 构建起fileRDD和filterRDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;
- 执行到第6行代码时,count()是一个行动类型的操作,触发真正的计算,开始实际执行从fileRDD到filterRDD的转换操作,并把结果持久化到内存中,最后计算出filterRDD中包含的元素个数。
3.1.3 RDD特性
- 高效的容错性:RDD中数据只读,不可修改,如果需要修改,必须从父RDD转换到子RDD,由此不同RDD之间建立了血缘关系。其次,RDD提供的转换操作都是一些粗粒度的操作(比如map、filter、join),RDD依赖关系只需要记录这种粗粒度的转换操作。
- 中间结果持久化到内存:数据在内存中的多个RDD操作之间进行传递,不需要到磁盘上,避免了不必要的读写磁盘开销。遇到多次调用不同的行动操作,可以通过持久化(缓存)机制避免这种重复计算的开销。
//persist()方法对一个RDD标记为持久化,并不会马上计算生成RDD并把它持久化,而是要等到第一个行动操作触发真正计算以后,才会把计算结果进行持久化,持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用。
//persist()的圆括号中包含的是持久化级别参数,比如persist(MEMORY_ONLY)表示将RDD作为反序列化的对象存储与JVM中,如果内存不足,超出的分区将会被存放在硬盘上。
eg:
list = ["Hadoop","Spark","Hive"]
rdd = sc.parallelize(list)
rdd.cache() //会调用persist(MEMORY_ONLY),但是,语句执行到这里,并不会缓存rdd,这是rdd还没有被计算生成
print(rdd.count()) //第一次行动操作,触发一次真正从头到尾的计算,这时才会执行上面的rdd.cache(),把这个rdd放到缓存中
print(','.join(rdd.collect())) //第二次行动操作,不需要触发从头到尾的计算,只需要重复使用上面缓存中的rdd。
- 存放的数据可以是java对象,避免了不必要的对象序列化和反序列化开销。
3.1.3.1 RDD之间的依赖关系
RDD中不同的操作会使得不同RDD中的分区会产生不同的依赖。RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency)。
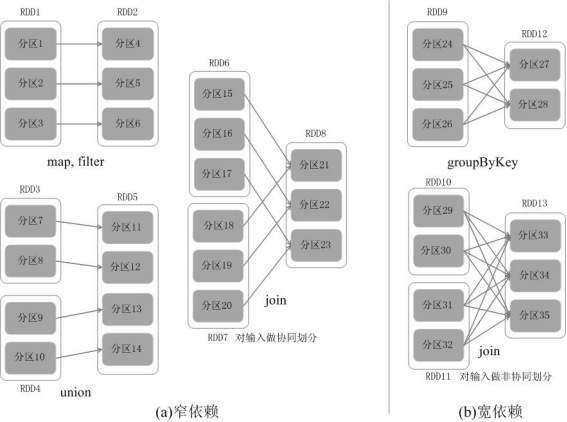
窄依赖[1对1或多对1]:表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区。窄依赖典型的操作包括map、filter、union等
宽依赖[1对多]:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。宽依赖典型的操作包括groupByKey、sortByKey等
区别:Spark的这种依赖关系设计,使其具有了天生的容错性,大大加快了Spark的执行速度。因为,RDD数据集通过“血缘关系”记住了它是如何从其它RDD中演变过来的,血缘关系记录的是粗颗粒度的转换操作行为,当这个RDD的部分分区数据丢失时,它可以通过血缘关系获取足够的信息来重新运算和恢复丢失的数据分区,由此带来了性能的提升。相对而言,在两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父RDD分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大。此外,Spark还提供了数据检查点和记录日志,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark会对数据检查点开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。
3.1.5 RDD阶段划分
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分阶段,具体划分方法是:在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中。
DAG阶段划分图:

由上述论述可知,把一个DAG图划分成多个“阶段”以后,每个阶段都代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集合。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给Executor运行。
3.1.6 RDD运行过程
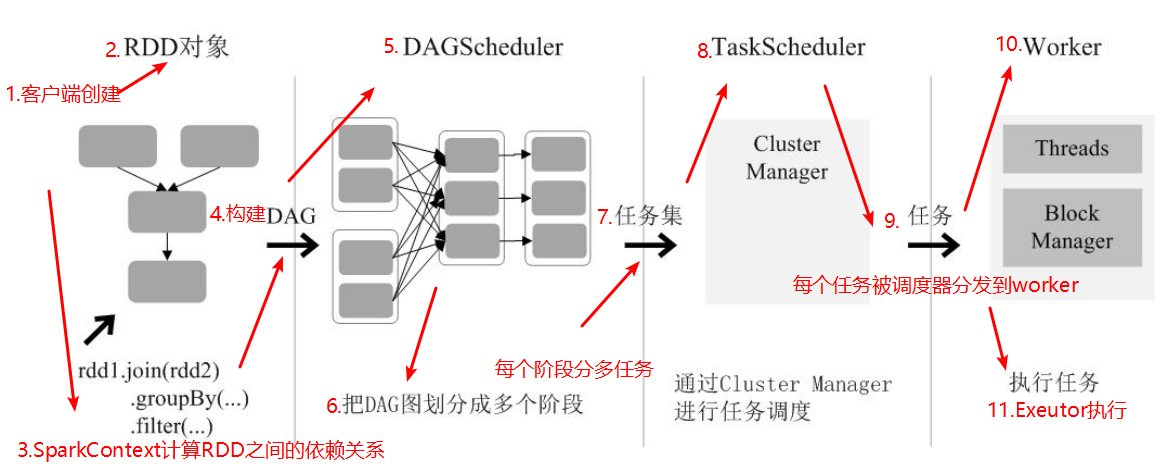
通过上述对RDD概念、依赖关系和阶段划分的介绍,结合之前介绍的Spark运行基本流程, RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
3.2 RDD编程
3.2.1 RDD创建
有两种方式可以实现RDD创建:
- 读取一个外部数据集。比如,从本地文件加载数据集,或者从HDFS文件系统、HBase、Cassandra、Amazon S3等外部数据源中加载数据集。Spark支持文本文件、SequenceFile文件(Hadoop提供的SequenceFile是一个由二进制序列化过的key/value的字节流组成的文本存储文件)和其他符合Hadoop InputFormat格式的文件。
- 调用SparkContext的parallelize方法,在driver中一个已经存在的集合(数组)上创建。
eg:
//1.从本地文件系统中加载数据创建RDD
textFile=sc.textFile("file:///home/hadoop/Document/wordcount.txt")
textFile.collect()
//2.从HDFS文件系统中加载数据
textFile=sc.textFile("hdfs://localhost:9000/Hadoop/Input/wordcount.txt")
textFile.collect()
//3.通过并行集合(数组)创建RDD
nums=[1,2,3,4,5]
rdd=sc.parallelize(nums)
rdd.collect()
3.2.2 RDD基本运算
RDD基本运算分2种:
- Transformation(转换):仅仅是定义逻辑,并不会立即执行,即lazy特性,目的是将一个RDD转为新的RDD。
- Action(执行):不会产生新的RDD,而是直接运行,得到我们想要的结果。
A.Transformation
eg:
//map(func): 返回一个新的RDD,func会作用于每个map的key,func的返回值即是新的数据。为了便于后面的计算,这一步一般在数据处理的最前面将数据转换为(K, V)的形式,例如计数的过程中首先要datas.map(lambda a, (a, 1))将数据转换成(a, 1)的形式以便后面累加。例如:
rdd = sc.parallelize(["Hadoop","Spark","Hive","Spark"])
pairRDD = rdd.map(lambda word : (word,1)).collect()
//mappartitions(func, partition): 和map不同的地方在于map的func应用于每个元素,而这里的func会应用于每个分区,能够有效减少调用开销,减少func初始化次数。减少了初始化的内存开销。但是map如果数据量过大,计算后面的时候可以将已经计算过的内存销毁掉,但是mappartitions中如果一个分区太大,一次计算的话可能直接导致内存溢出。
//filter(func): 返回一个新的RDD,func会作用于每个map的key,返回的仅仅是返回True的数据组成的集合,返回None或者False或者不返回都表示被过滤掉。例如:
rdd = sc.parallelize([1,2,3,4,5])
rdd.filter(lambda x:x>2).collect()
//filtMap(func): 返回一个新的RDD,func可以一次返回多个元素,最后形成的是所有返回的元素组成的新的数据集。例如:
rdd = sc.parallelize([1,2,3,4,5])
sorted(rdd.flatMap(lambda x:[(x,x), (x,x)]).collect())
//mapValues(func): 返回一个新的RDD,对RDD中的每一个value应用函数func。例如:
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd. mapValues(lambda x:x+1).collect()
//distinct(): 去除重复的元素。例如:
rdd = sc.parallelize([1, 1, 2, 3, 4])
rdd.distinct(2).collect()
//subtractByKey(other): 删除在RDD1中的RDD2中key相同的值. 例如:
rdd1 = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd2 = sc.parallelize([("a", 1), ("c", 1), ("d", 1)])
rdd1. subtractByKey(rdd2).collect()
//groupByKey(numPartitions=None): 将(K, V)数据集上所有Key相同的数据聚合到一起,得到的结果是(K, (V1, V2…))。例如:
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd.groupByKey().map(lambda x : (x[0], list(x[1]))).collect()
//reduceByKey(func, numPartitions=None): 将(K, V)数据集上所有Key相同的数据聚合到一起,func的参数即是每两个K-V中的V。可以使用这个函数来进行计数,例如reduceByKey(lambda a,b:a+b)就是将key相同数据的Value进行相加。例如:
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd.reduceByKey(lambda x,y:x+y).collect()
//reduceByKeyAndWindow(func,invFunc,windowdurartion,slideDuration=None,numPartitions=None,filterFunc=None): 与reduceByKey类似,不过它是在一个时间窗口上进行计算,由于时间窗口的移动,有增加也有减少,所以必须提供一个逻辑和func相反的函数invFunc,
//例如func为(lambda a, b: a+b),那么invFunc一般为(lambda a, b: a-b),其中a和b都是key相同的元素的value。另外需要注意的是,程序默认会缓存一个时间窗口内所有的数据以便后续能进行inv操作,所以如果窗口太长,内存占用可能会非常高。
//join(other, numPartitions=None): 将(K, V)和(K, W)类型的数据进行类似于SQL的JOIN操作,得到的结果是这样(K, (V, W))
rdd1 = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd2 = sc.parallelize([("a", 1), ("c", 1), ("d", 1)])
rdd1.join(rdd2).collect()
//union(other): 并集运算,合并两个RDD
rdd1 = sc.parallelize([1,2,3])
rdd2 = sc.parallelize([2,3,4])
rdd1.union(rdd2).collect()
//intersection(other): 交集运算,保留在两个RDD中都有的元素
rdd1 = sc.parallelize([1,2,3])
rdd2 = sc.parallelize([2,3,4])
rdd1.intersection(rdd2).collect()
//leftOuterJoin(other): 左外连接
rdd1 = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd2 = sc.parallelize([("a", 1), ("c", 1), ("d", 1)])
rdd1.leftOuterJoin(rdd2).collect()
//rightOuterJoin(other): 右外连接
rdd1 = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd2 = sc.parallelize([("a", 1), ("c", 1), ("d", 1)])
rdd1.rightOuterJoin(rdd2).collect()
B.Action(行动)
collect(): 以数组的形式,返回数据集中所有的元素
count(): 返回数据集中元素的个数
take(n): 返回数据集的前N个元素
takeOrdered(n): 升序排列,取出前N个元素
takeOrdered(n, lambda x: -x): 降序排列,取出前N个元素
first(): 返回数据集的第一个元素
min(): 取出最小值
max(): 取出最大值
stdev(): 计算标准差
sum(): 求和
mean(): 平均值
countByKey(): 统计各个key值对应的数据的条数
lookup(key): 根据传入的key值来查找对应的Value值
foreach(func): 对集合中每个元素应用func
综合实例:
//一个综合实例
//题目:给定一组键值对(“spark”,2),(“hadoop”,6),(“hadoop”,4),(“spark”,6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
rdd = sc.parallelize([("spark",2),("hadoop",6),("hadoop",4),("spark",6)])
rdd.mapValues(lambda x : (x,1)).reduceByKey(lambda x,y : (x[0]+y[0],x[1] + y[1])).mapValues(lambda x : (x[0] / x[1])).collect()
3.3 Spark共享变量
在默认情况下,当spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。
场景:需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。spark为了适应这种需求,提供了两种类型的变量:广播变量(broadcast varialbes)和累加器(accumulators)。
- 广播变量(broadcast varialbes):把变量在所有节点的内存之间进行共享。
- 累加器(accumulators):支持在所有不同节点之间进行累加计算(比如计数或者求和)。
A.广播变量
程序开发人员在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。通过这种方式,就可以非常高效地给每个节点(机器)提供一个大的输入数据集的副本。Spark的“动作”操作会跨越多个阶段(stage),对于每个阶段内的所有任务所需要的公共数据,Spark都会自动进行广播。通过广播方式进行传播的变量,会经过序列化,然后在被任务使用时再进行反序列化。这就意味着,显式地创建广播变量只有在下面的情形中是有用的:当跨越多个阶段的那些任务需要相同的数据,或者当以反序列化方式对数据进行缓存是非常重要的。
eg:
broadcastVar = sc.broadcast([1, 2, 3])
broadcastVar.value
B. 累加器
仅仅被相关操作累加的变量,通常可以被用来实现计数器(counter)和求和(sum)。一个数值型的累加器,可以通过调用SparkContext.accumulator()来创建。运行在集群中的任务,就可以使用add方法来把数值累加到累加器上,但是,这些任务只能做累加操作,不能读取累加器的值,只有任务控制节点(Driver Program)可以使用value方法来读取累加器的值。
#eg:
accum = sc.accumulator(0)
sc.parallelize([1, 2, 3, 4]).foreach(lambda x : accum.add(x))
accum.value
3.4 数据读写
3.4.1 Spark文件数据读写
#1、本地文件系统的数据读写累加器
textFile = sc.textFile("file:///home/hadoop/Documents/wordcount.txt")
textFile.saveAsTextFile("file:///home/hadoop/Documents/wordcountback.txt") //数据存储
#2、分布式文件系统HDFS的数据读写
textFile = sc.textFile("hdfs://localhost:9000/Hadoop/Input/wordcount.txt")
textFile.saveAsTextFile("hdfs://localhost:9000/Hadoop/Input/wordcountback.txt")
#3、JSON格式数据读写
from pyspark import SparkContext
import json
sc = SparkContext('local','JSONAPP')
inputFile = "file:///opt/examples/resources/people.json"
jsonStrs = sc.textFile(inputFile)
result = jsonStrs.map(lambda s : json.loads(s))
print(result.collect())
4 Spark SQL
4.1 认识sparkSQL
SparkSQL:spark的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象就是DataFrame。
SparkSQL的作用:提供一个抽象(DataFrame)并且作为分布式SQL查询引擎。DataFrame:它可以根据很多源进行构建,包括:结构化的数据文件,hive中的表,外部的关系型数据库,以及RDD。
SparkSQL运行原理:将SparkSQL转换为RDD,然后提交到集群执行。Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所以Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!所以我们类比的理解:Hive---SQL-->MapReduce,Spark SQL---SQL-->RDD。都是一种解析传统SQL到大数据运算模型的引擎,属于数据分析的范围。
SparkSQL特性:
- 容易集成:安装Spark的时候,已经集成好了。不需要单独安装。
- 统一的数据访问方式:JDBC、JSON、Hive、parquet文件(一种列式存储文件,是SparkSQL默认的数据源,hive中也支持)
- 完全兼容Hive。可以将Hive中的数据,直接读取到Spark SQL中处理。
- 一般在生产中,基本都是使用hive做数据仓库存储数据,然后用spark从hive读取数据进行处理。
- 支持标准的数据连接:JDBC、ODBC。
4.2 DataFrame与RDD区别
DataFrame:类似于关系型数据库中的表。组织成命名列的数据集,DataFrames可以从各种来源构建。最简单的理解我们可以认为DataFrame就是Spark中的数据表(类比传统数据库)。
DataFrame的结构如下:DataFrame(表)是Spark SQL对结构化数据的抽象。DataFrame API支持的语言有Scala,Java,Python和R。
- DataFrame(表)= Schema(表结构) + Data(表数据)
DataFrame与RDD的区别:
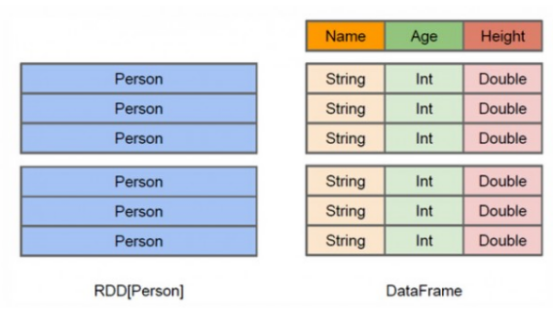
RDD是分布式的 Java对象的集合,比如,RDD[Person]是以Person为类型参数,但是,Person类的内部结构对于RDD而言却是不可知的。DataFrame是一种以RDD为基础的分布式数据集,也就是分布式的Row对象的集合(每个Row对象代表一行记录),提供了详细的结构信息,也就是我们经常说的模式(schema),Spark SQL可以清楚地知道该数据集中包含哪些列、每列的名称和类型。
和RDD一样,DataFrame的各种变换操作也采用惰性机制,只是记录了各种转换的逻辑转换路线图(是一个DAG图),不会发生真正的计算,这个DAG图相当于一个逻辑查询计划,最终,会被翻译成物理查询计划,生成RDD DAG,按照之前介绍的RDD DAG的执行方式去完成最终的计算得到结果。
DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化。
4.3 DataFrame编程
1. SparkSession与SparkContext
从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能。
SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。SparkSession亦提供了HiveQL以及其他依赖于Hive的功能的支持。
SparkSession 直接读取,不管文件是什么类型,txt也好,csv也罢,输出格式都是 dataframe。SparkContext 不管读什么文件,输出格式都是 RDD。
在 shell 操作中,原生创建了 SparkSession,故无需再创建,创建了也不会起作用。SparkContext 叫 sc,SparkSession 叫 spark。
2. DataFrame创建及操作
#1.json文件创建.首先,准备样例数据。Spark已经为我们提供了几个样例数据,就保存在“$SPARK_HOME/examples/src/main/resources/”这个目录下,这个目录下有样例数据people.json。
#接着,准备python程序:
from pyspark.sql import SparkSession
spark=SparkSession.builder.getOrCreate()
df = spark.read.json("file:///opt/spark/examples/src/main/resources/people.json")
df.show()
#2.常见操作
# 打印模式信息
df.printSchema()
# 选择多列
df.select(df.name,df.age + 1).show()
# 条件过滤
df.filter(df.age > 20 ).show()
# 分组聚合
df.groupBy("age").count().show()
# 排序
df.sort(df.age.desc()).show()
#多列排序
df.sort(df.age.desc(), df.name.asc()).show()
#对列进行重命名
df.select(df.name.alias("username"),df.age).show()
3.RDD转换DataFrame
1、利用反射机制推断RDD模式:利用反射来推断包含特定类型对象的RDD的schema,适用对已知数据结构的RDD转换。主要会用到toDF()方法。
#设计程序
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
from pyspark import SparkContext
from pyspark.sql.types import Row
def f(x):
rel = {}
rel['name'] = x[0]
rel['age'] = x[1]
return rel
sc = SparkContext( 'local', 'test')
peopleRdd = sc.textFile("file:///opt/spark/examples/src/main/resources/people.txt").map(lambda line : line.split(',')).map(lambda x: Row(**f(x)))
sqlContext = SQLContext(sc)
peopleDF=peopleRdd.toDF()
#必须注册为临时表才能供下面的查询使用
peopleDF.createOrReplaceTempView("people")
spark = SparkSession(sc)
personsDF = spark.sql("select * from people")
personsDF.show()
personsDF.rdd.map(lambda t : "Name:"+t[0]+","+"Age:"+t[1]).foreach(print)
#执行:/opt/spark/bin/spark-submit /opt/examples/src/rddToDataFrame.py
2、使用编程方式定义RDD模式:使用编程接口,构造一个schema并将其应用在已知的RDD上。使用createDataFrame(rdd, schema)编程方式定义RDD模式。
from pyspark.sql.types import Row
from pyspark.sql.types import StructType
from pyspark.sql.types import StructField
from pyspark.sql.types import StringType
from pyspark import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext( 'local', 'test')
#生成 RDD
peopleRDD = sc.textFile("file:///opt/spark/examples/src/main/resources/people.txt")
#定义一个模式字符串
schemaString = "name age"
#根据模式字符串生成模式
fields = list(map( lambda fieldName : StructField(fieldName, StringType(), nullable = True), schemaString.split(" ")))
schema = StructType(fields)
#从上面信息可以看出,schema描述了模式信息,模式中包含name和age两个字段
rowRDD = peopleRDD.map(lambda line : line.split(',')).map(lambda attributes : Row(attributes[0], attributes[1]))
spark = SparkSession(sc)
peopleDF = spark.createDataFrame(rowRDD, schema)
#必须注册为临时表才能供下面查询使用
peopleDF.createOrReplaceTempView("people")
results = spark.sql("SELECT * FROM people")
results.rdd.map( lambda attributes : "name: " + attributes[0]+","+"age:"+attributes[1]).foreach(print)
map(lambda attributes : Row(attributes[0], attributes[1]))就会生成一个Row对象,这个对象里面包含了两个字段的值,这个Row对象就构成了rowRDD中的其中一个元素。因为people有3行文本,所以,最终,rowRDD中会包含3个元素,每个元素都是org.apache.spark.sql.Row类型。实际上,Row对象只是对基本数据类型(比如整型或字符串)的数组的封装,本质就是一个定长的字段数组。peopleDF = spark.createDataFrame(rowRDD, schema),这条语句就相当于建立了rowRDD数据集和模式之间的对应关系,从而我们就知道对于rowRDD的每行记录,第一个字段的名称是schema中的“name”,第二个字段的名称是schema中的“age”。
执行:
/opt/spark/bin/spark-submit /opt/examples/src/rddToDataFrameschema.py
4. DataFrame保存为文件
1、 第一种保存方法
使用select(“name”, “age”)确定要把哪些列进行保存,然后调用write.format(“csv”).save ()保存成csv文件。另外,write.format()支持输出 json,parquet, jdbc, orc, libsvm, csv, text等格式文件,如果要输出文本文件,可以采用write.format(“text”),但是,需要注意,只有select()中只存在一个列时,才允许保存成文本文件,如果存在两个列,比如select(“name”, “age”),就不能保存成文本文件。
#提交任务:/opt/spark/bin/spark-submit /opt/examples/src/saveDataFrame.py
from pyspark.sql import SparkSession
spark=SparkSession.builder.getOrCreate()
peopleDF = spark.read.format("json").load("file:///opt/spark/examples/src/main/resources/people.json")
peopleDF.select("name", "age").write.format("csv").save("file:///opt/examples/resources/newpeople.csv")
2、第二种保存方法
把DataFrame转换成RDD,然后调用saveAsTextFile()保存成文本文件。
#实例:
#提交任务:/opt/spark/bin/spark-submit /opt/examples/src/saveDataFrame1.py
from pyspark.sql import SparkSession
spark=SparkSession.builder.getOrCreate()
peopleDF = spark.read.format("json").load("file:///opt/spark/examples/src/main/resources/people.json")
peopleDF.rdd.saveAsTextFile("file:///opt/examples/resources/newpeople1.csv")
#再次把newpeople1.txt中的数据加载到RDD中,可以直接使用newpeople1.txt目录名称,而不需要使用part-00000文件。
textFile = sc.textFile("file:///opt/examples/resources/newpeople1.csv")
textFile.collect()
4.4 读写Parquest(DataFrame)
Spark SQL可以支持Parquet、JSON、Hive等数据源,并且可以通过JDBC连接外部数据源。Parquet是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。Parquet是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与Parquet配合的组件有:
- 查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL。
- 计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite。
- 数据模型: Avro, Thrift, Protocol Buffers, POJOs。
1. 读取Parquest文件
Spark已经为我们提供了parquet样例数据,就保存在“/usr/local/spark/examples/src/main/resources/”这个目录下,有个users.parquet文件,这个文件格式比较特殊,如果你用vim编辑器打开,或者用cat命令查看文件内容,肉眼是一堆乱七八糟的东西,是无法理解的。只有被加载到程序中以后,Spark会对这种格式进行解析。
#实例
提交任务:/opt/spark/bin/spark-submit /opt/examples/src/parquetRead.py
#程序代码
from pyspark.sql import SparkSession
spark=SparkSession.builder.getOrCreate()
parquetFileDF = spark.read.parquet("file:///opt/spark/examples/src/main/resources/users.parquet")
parquetFileDF.createOrReplaceTempView("parquetFile")
namesDF = spark.sql("SELECT * FROM parquetFile")
namesDF.show()
2.存储为Parquet文件
可以将DataFrame保存为Parquet文件。
#例如
#提交任务:/opt/spark/bin/spark-submit /opt/examples/src/parquetWrite.py
#程序代码
#将json文件读取保存为Parquet文件
from pyspark.sql import SparkSession
spark=SparkSession.builder.getOrCreate()
peopleDF = spark.read.json("file:///opt/spark/examples/src/main/resources/people.json")
peopleDF.write.parquet("file:///opt/examples/resources/peopleback.parquet")
#读取存储的peopleback.parquet文件
parquetFileDF = spark.read.parquet("file:///opt/examples/resources/peopleback.parquet")
parquetFileDF.createOrReplaceTempView("parquetFile")
namesDF = spark.sql("SELECT * FROM parquetFile")
namesDF.show()
4.5 MYSQL读写
1 MYSQL环境准备
首先,按照教程安装好mysql数据库。教程如下:https://www.cnblogs.com/duaimili/p/9955608.html
修改数据库用户名/密码为root/hadoop:https://blog.csdn.net/JYL1159131237/article/details/88378574
//下面我们要新建一个测试Spark程序的数据库,数据库名称是“spark”,表的名称是“student”。
//1、 在Linux中启动MySQL数据库
service mysql start
mysql -u root -p
//2、 完成数据库和表的创建,以及样例数据的录入
create database spark;
use spark;
create table student (id int(4), name char(20), gender char(4), age int(4));
alter table student change id id int auto_increment primary key;
insert into student values(1,'Xueqian','F',23);
insert into student values(2,'Weiliang','M',24);
select * from student;
//3、下载一个MySQL的JDBC驱动,下载地址:https://mvnrepository.com/artifact/mysql/mysql-connector-java/8.0.20
//然后把该驱动程序拷贝到spark的安装目录下
cp mysql-connector-java-8.0.20.jar /opt/spark/jars
//4、启动已经安装在Linux系统中的mysql数据库
service mysql start
//5、启动一个pyspark,而且启动的时候,要附加一些参数。启动pyspark时,须指定mysql连接驱动jar包
pyspark --jars /opt/spark/jars/mysql-connector-java-8.0.20.jar --driver-class-path /opt/spark/jars/mysql-connector-java-8.0.20.jar
2 MYSQL读
执行以下命令连接数据库,读取数据,并显示。
from pyspark.sql import SparkSession
spark=SparkSession.builder.getOrCreate()
jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/spark").option("driver","com.mysql.jdbc.Driver").option("dbtable", "student").option("user", "root").option("password", "hadoop").load()
jdbcDF.show()
3 MYSQL写
现在我们开始在pyspark中编写程序,往spark.student表中插入两条记录。
from pyspark.sql.types import Row
from pyspark.sql.types import StructType
from pyspark.sql.types import StructField
from pyspark.sql.types import StringType
from pyspark.sql.types import IntegerType
spark=SparkSession.builder.getOrCreate()
studentRDD = spark.sparkContext.parallelize(["3 Rongcheng M 26","4 Guanhua M 27"]).map(lambda line : line.split(" ")) #下面要设置模式信息
schema = StructType([StructField("name", StringType(), True),StructField("gender", StringType(), True),StructField("age",IntegerType(), True)])
rowRDD = studentRDD.map(lambda p : Row(p[1].strip(), p[2].strip(),int(p[3])))
#建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
studentDF = spark.createDataFrame(rowRDD, schema)
prop = {}
prop['user'] = 'root'
prop['password'] = 'hadoop'
prop['driver'] = "com.mysql.jdbc.Driver"
studentDF.write.jdbc("jdbc:mysql://localhost:3306/spark",'student','append', prop)
4.6 Hive读写
4.6.1 Hive环境准备
//1、下载并解压hive包,下载地址:
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.7/apache-hive-2.3.7-bin.tar.gz。下载后存放到目录/opt,文件夹改名为hive。
//2、配置环境变量,编辑~/.bashrc文件vim ~/.bashrc,在最前面一行添加:
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
//保存退出后,运行source ~/.bashrc使配置立即生效。
//3、配置/opt/ hive/conf下的hive-site.xml,将hive-default.xml.template重命名为hive-default.xml;新建一个文件touch hive-site.xml,并在hive-site.xml中粘贴如下配置信息。配置完成后,拷贝hive-site.xml到/opt/spark/conf路径下,为了让Spark能够访问Hive。
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?serverTimezone=GMT%2B8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>300</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/hive/warehouse</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>
//3、启动并登陆mysql
service mysql start
mysql -u root –p
//4、在mysql里新建hive数据库
create database hive;
//注:这个hive数据库与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据。
//5、配置mysql允许hive接入:
grant all on *.* to root@localhost identified by 'hadoop';
//注:这里的root和hadoop是前面在mysql数据库的账号密码。将所有数据库的所有表的所有权限赋给root用户,与 hive-site.xml中配置的数据库连接账号密码一致。
flush privileges;
//6、初始化metastore database,执行命令
schematool -initSchema -dbType mysql
//Hive 分布现在包含一个用于 Hive Metastore 架构操控的脱机工具,名为 schematool.此工具可用于初始化当前 Hive 版本的 Metastore 架构。此外,其还可处理从较旧版本到新版本的架构升级。
//7、启动metastore ,Hive的meta数据支持以下三种存储方式。3种方式不同的配置方式参考:https://blog.csdn.net/reesun/article/details/8556078,本文用的是第三种:远端mysql,前面已经在hive-site.xml文件里配置:配置完成后,在路径/opt/hive/bin执行命令
hive --service metastore
//8、启动hive,在路径/opt/hive/bin执行命令
hive
//启动成功后会进入hive
//9、在Hive中创建数据库和表。便于后面小节进行hive读写实例使用。
create database if not exists sparktest;
show databases;
create table if not exists sparktest.student(
id int,
name string,
gender string,
age int);
use sparktest;
show tables;
insert into student values(1,'Xueqian','F',23);
insert into student values(2,'Weiliang','M',24);
select * from student;
4.6.2 连接Hive读数据
现在我们看如何使用Spark读写Hive中的数据。注意,操作到这里之前,你一定已经按照前面的各个操作步骤,启动了Hadoop、Hive、MySQL和pyspark(包含Hive支持)。
//在进行编程之前,我们需要做一些准备工作,我们需要修改“/opt/spark /conf/spark-env.sh”这个配置文件,增加以下配置项
export CLASSPATH=$CLASSPATH:/opt/hive/lib
export HIVE_CONF_DIR=/opt/hive/conf
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/hive/lib/mysql-connector-java-8.0.20.jar
经过了前面如此漫长的准备过程,现在终于可以编写调试Spark连接Hive读写数据的代码了。
//eg:
from pyspark.sql import SparkSession
hive_context = SparkSession.builder.appName("foo").enableHiveSupport().getOrCreate()
hive_context.sql('use sparktest')
hive_context.sql('select * from student').show()
4.6.3 连接Hive写数据
//编写程序向Hive数据库的sparktest.student表中插入两条数据。程序设计:
from pyspark.sql.types import Row
from pyspark.sql.types import StructType
from pyspark.sql.types import StructField
from pyspark.sql.types import StringType
from pyspark.sql.types import IntegerType
from pyspark.sql import SparkSession saprk = SparkSession.builder.appName("foo").enableHiveSupport().getOrCreate()
spark.sql('use sparktest')
studentRDD = spark.sparkContext.parallelize(["3 Rongcheng M 26","4 Guanhua M 27"]).map(lambda line : line.split(" "))
schema = StructType([StructField("id",IntegerType(), True),StructField("name", StringType(), True),StructField("gender", StringType(), True),StructField("age",IntegerType(), True)])
rowRDD = studentRDD.map(lambda p : Row(int(p[0]),p[1].strip(), p[2].strip(),int(p[3])))
studentDF = spark.createDataFrame(rowRDD, schema)
studentDF.createOrReplaceTempView("tempTable")
spark.sql('insert into student select * from tempTable')
//执行结果:成功插入2条数据。
//数据存储在hive-site.xml里配置的/usr/hive/warehouse的hdfs路径下。
5 sparkcore项目实战
1、如何从HBase表中读取数据
2、日志数据ETL保存到HBase表
3、从HBase表读取数据进行新增用户统计分析
分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)的更多相关文章
- S2X环境搭建与示例运行
S2X环境搭建与示例运行 http://dbis.informatik.uni-freiburg.de/forschung/projekte/DiPoS/S2X.html 环境 Maven proje ...
- JDK开发环境搭建及环境变量配置
Java配置----JDK开发环境搭建及环境变量配置 1. 下载安装安装JDK开发环境 http://www.oracle.com/technetwork/java/javase/downloads/ ...
- Ubuntu 16.04 Go环境搭建 Go环境+Sublime配置
Ubuntu 16.04 Go环境搭建 Go环境+Sublime配置 1. 安装Go 下载地址https://golang.org/dl/ (需要翻下) 下载到类似go1.8.3.linux-amd6 ...
- Android 程序分析环境搭建-开发环境搭建
1.1 JDK 安装 JDK 的配置,初学java 开发,那是必须会的. 下载,遇到的问题就是要注册oracle 的账号,还有你要下载特定版本,比如jdk 1.7,jdk 1.6,很难找到在哪里.解 ...
- HHvm Apache 2.4 Nginx建站环境搭建方法安装运行WordPress博客
HHvm Apache 2.4 Nginx建站环境搭建方法安装运行WordPress博客 VPS主机 2014年06月02日 17:20 评论» 文章目录 Debian上安装 Ce ...
- Hibernate框架 初识 ORM概念 搭建Hibernate环境 Hibernate Api
ORM概念 在学习 Hibernate 之前,我们先来了解ORM 对象关系映射 O, Object 对象 R,Realtion 关系 (关系型数据库: MySQL, Oracle…) M,Ma ...
- Spark On Yarn搭建及各运行模式说明
之前记录Yarn:Hadoop2.0之YARN组件,这次使用Docker搭建Spark On Yarn 一.各运行模式 1.单机模式 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spa ...
- Android 程序分析环境搭建-静态分析环境搭建
1.2 静态分析环境搭建 这里主要讲一些用的比较顺手的工具,一并列出来,Uaa,等环境配置, 2,notepad++ ,everything , Jdgui ,idea, ida ,Fiddler , ...
- react介绍、环境搭建、demo运行实例
React官网:https://reactjs.org/docs/create-a-new-react-app.html cnpm网址:http://npm.taobao.org/ 1.react介绍 ...
- 【Java学习系列】第1课--Java环境搭建和demo运行
本文地址 分享提纲: 1. java环境的搭建 2. java demo代码运行 3.参考文档 本人是PHP开发者,一直感觉Java才是程序的王道(应用广,科班出身),所以终于下决心跟一跟. 主要是给 ...
随机推荐
- IAuthorizationFilter学习笔记(权限控制)以及非全局的filter
第一步:新建类CheckLoginFilter实现接口IAuthorizationFilter.请注意接口位于命名空间using System.Web.Mvc; public void OnAutho ...
- C语言中宏的作用
在C语言#define机制中包括了一个规定,与允许把参数替换到文本中,这种实现通常称为宏或宏定义.下面是宏的声明方式: #define name(parameter-list) ...
- gcc编译链接用到的环境变量
PATH ---- 可执行程序寻找路径 C_INCLUDE_PATH ---- 头文件寻找路径 CPLUS_INCLUDE_PATH --- g++ 头文件路径 LD_LIBRARY_PATH ...
- 痞子衡嵌入式:JLink Script文件基础及其在IAR下调用方法
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是JLink Script文件基础及其在IAR下调用方法. JLink可以说是MCU开发者最熟悉的调试工具了,相比于其他调试器(比如DAP ...
- DevOps,你真的了解吗?
与大数据和PRISM(NSA的监控项目之一),DevOps(开发运维)如今是科技人士挂在嘴边的热词,但遗憾的是,类似圣经,每个人都引用DevOps的只言片语,但真正理解并能执行的人极少.根据CA的一项 ...
- LeetCode283移动零问题java高效解法
一.题目: 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序. 示例: 输入: [0,1,0,3,12] 输出: [1,3,12,0,0] 说明: 1.必须 ...
- Redis订阅
1.Redis订阅简介 进程间的一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息. 2.Redis订阅命令 3.Redis订阅的使用 先订阅后发布后才能收到消息, 1 可以一次性订 ...
- 基于Opencv识别,矫正二维码(C++)
参考链接 [ 基于opencv 识别.定位二维码 (c++版) ](https://www.cnblogs.com/yuanchenhui/p/opencv_qr.html) OpenCV4.0.0二 ...
- 思维导图VS金字塔原理
作为常识,思维导图制作的核心元素是关键词,而金字塔原理制作的核心元素则是拓展的概要句子,这两种方式是当今人们常用的思维工具,本文对其做了对比,希望对你的选择有所帮助. 金字塔原理结构:从上到下三角形结 ...
- ABBYY FineReader 15 PDF文档查看功能
PDF文档查看功能是ABBYY FineReader 15(Windows系统)OCR文字识别软件中PDF编辑器的一项基础功能,可供用户查看,搜索PDF文档,无需进入编辑模式,也可复制其中的文本,图片 ...