爬虫入门到放弃系列02:html网页如何解析

前言
上一篇文章讲了爬虫的概念,本篇文章主要来讲述一下如何来解析爬虫请求的网页内容。
一个简单的爬虫程序主要分为两个部分,请求部分和解析部分。请求部分基本一行代码就可以搞定,所以主要来讲述一下解析部分。对于解析,最常用的就是xpath和css选择器,偶尔也会使用正则表达式。
不论是xpah还是css,都是通过html元素或者其中某些属性来选中符合条件的元素节点。
以斗罗大陆的部分html为例。
<div class="detail_video">
<div class="video_title_collect cf">
<h1 class="video_title_cn">
<a target="_blank" _stat="info:title" href="http://v.qq.com/x/cover/m441e3rjq9kwpsc.html">斗罗大陆</a>
<span class="title_en" itemprop="alternateName"></span>
<i class="dot"></i>
<span class="type">动漫</span>
</h1>
</div>
<div class="video_type cf">
<div class="type_item">
<span class="type_tit">别 名:</span>
<span class="type_txt">斗罗大陆动画版</span>
</div>
<div class="type_item">
<span class="type_tit">地 区:</span>
<span class="type_txt">内地</span>
</div>
<div class="type_item">
<span class="type_tit">更新集数:</span>
<span class="type_txt">更新至141集</span>
</div>
</div>
<div class="video_type video_type_even cf">
<div class="type_item">
<span class="type_tit">出品时间:</span>
<span class="type_txt">2018</span>
</div>
<div class="type_item">
<span class="type_tit">更新时间:</span>
<span class="type_txt">每周六10:00更新1集</span>
</div>
</div>
<div class="video_tag cf">
<span class="tag_tit">标 签: </span>
<div class="tag_list">
<a class="tag" href="http://v.qq.com/x/search?q=%E6%88%98%E6%96%97" target="_blank" _stat="info:tag">战斗</a>
</div>
</div>
<div class="video_desc">
<span class="desc_tit">简 介:</span>
<span class="desc_txt">
<span class="txt _desc_txt_lineHight" itemprop="description">唐门外门弟子唐三,因偷学内门绝学为唐门所不容,跳崖明志时却发现没有死,反而以另外一个身份来到了另一个世界,一个属于武魂的世界,名叫斗罗大陆。这里没有魔法,没有斗气,没有武术,却有神奇的武魂。这里的每个人,在自己六岁的时候,都会在武魂殿中令武魂觉醒。武魂有动物,有植物,有器物,武魂可以辅助人们的日常生活。而其中一些特别出色的武魂却可以用来修炼并进行战斗,这个职业,是斗罗大陆上最为强大也是最荣耀的职业“魂师”。
小小的唐三在圣魂村开始了他的魂师修炼之路,并萌生了振兴唐门的梦想。当唐门暗器来到斗罗大陆,当唐三武魂觉醒,他能否在这片武魂的世界再铸唐门的辉煌??
</span>
</span>
</div>
</div>
css选择器
很多学习过前端的小伙伴对css选择器比较熟悉,.是class选择器,#是id选择器。这里挑最几个常用的来讲一下,其他用法可百度。
常见语法
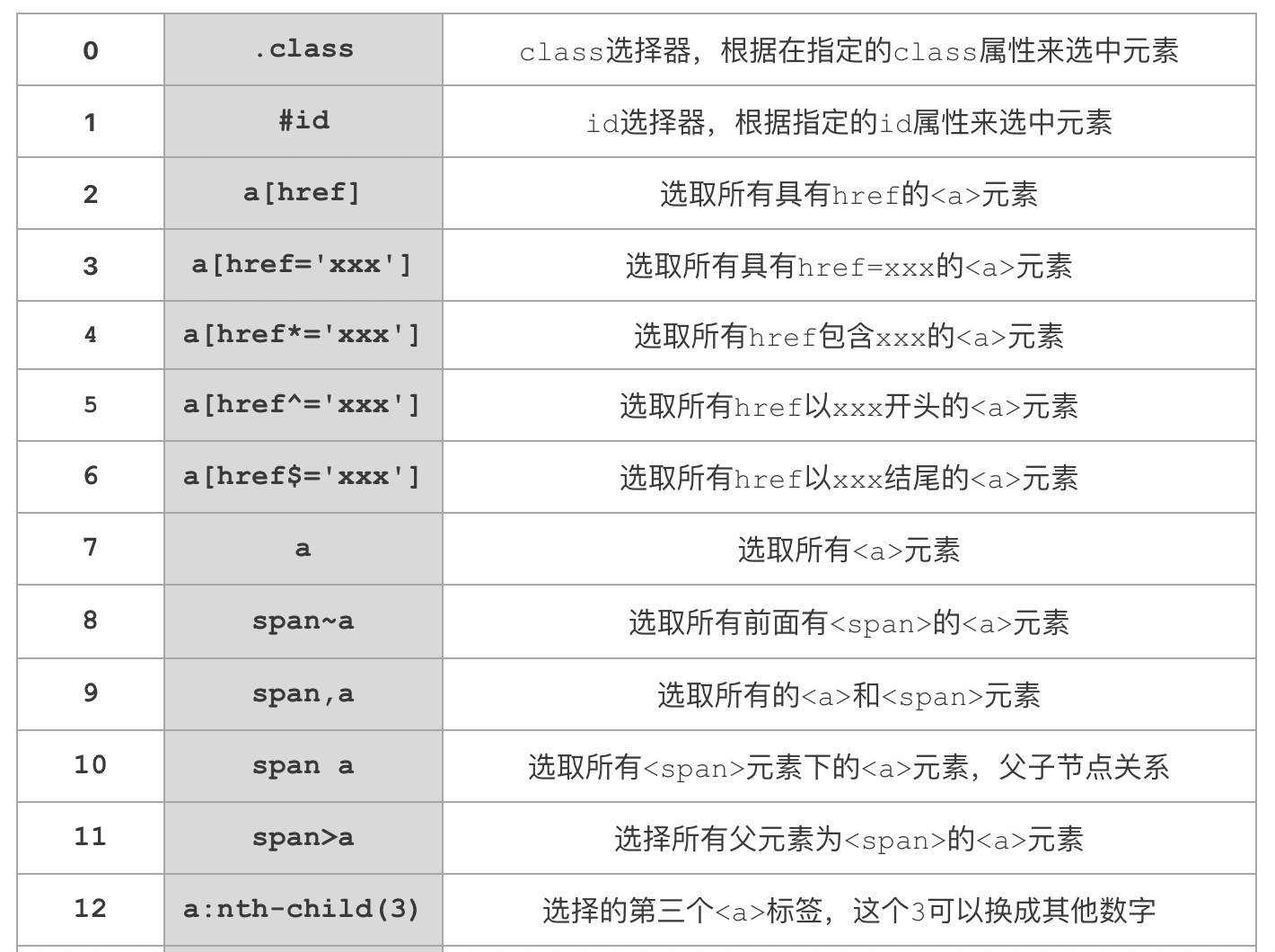
以上就是一些比较常用的css选择器。其中里面的元素a和span只用来举例,可以替换成任意的html元素,href属性也可以替换成元素的其他属性。
样例说明
还是用之前斗罗大陆的程序来说明一下。
import requests
from bs4 import BeautifulSoup
url = 'https://v.qq.com/detail/m/m441e3rjq9kwpsc.html'
# 发起请求,获取页面
response = requests.get(url)
# 解析html,获取数据
soup = BeautifulSoup(response.text, 'html.parser')
# .video_title_cn a 表示class=video_title_cn元素下的<a>
# 这里指的就是<h1 class="video_title_cn">下的<a>,就一个<a>,所以[0]取出此元素
name = soup.select(".video_title_cn a")[0].string
# span.type表示属性class=type的<span>元素
# 这里指的是<span class="type">动漫</span>此元素
category = soup.select("span.type")[0].string
# class=type_txt的<span>有多个,所以根据下标取出列表中对应的元素
# 这里指的是<span class="type_txt">斗罗大陆动画版</span>
alias = soup.select("span.type_txt")[0].string
# <span class="type_txt">内地</span> [1]代表是第二个元素
area = soup.select("span.type_txt")[1].string
# <span class="type_txt">更新至141集</span>
parts =soup.select("span.type_txt")[2].string
# <span class="type_txt">2018</span>
date = soup.select("span.type_txt")[3].string
# <span class="type_txt">每周六10:00更新1集</span>
update = soup.select("span.type_txt")[4].string
# <a class="tag" href="http://v.qq.com/x/search?q=%E6%88%98%E6%96%97" target="_blank" _stat="info:tag">战斗</a>
tag = soup.select("a.tag")[0].string
# <span class="txt _desc_txt_lineHight">
describe = soup.select("span._desc_txt_lineHight")[0].string
print(name, category, alias, parts, date, update, tag, describe, sep='\n')
soup.select()根据css规则选择元素,返回包含一个或多个元素的list。
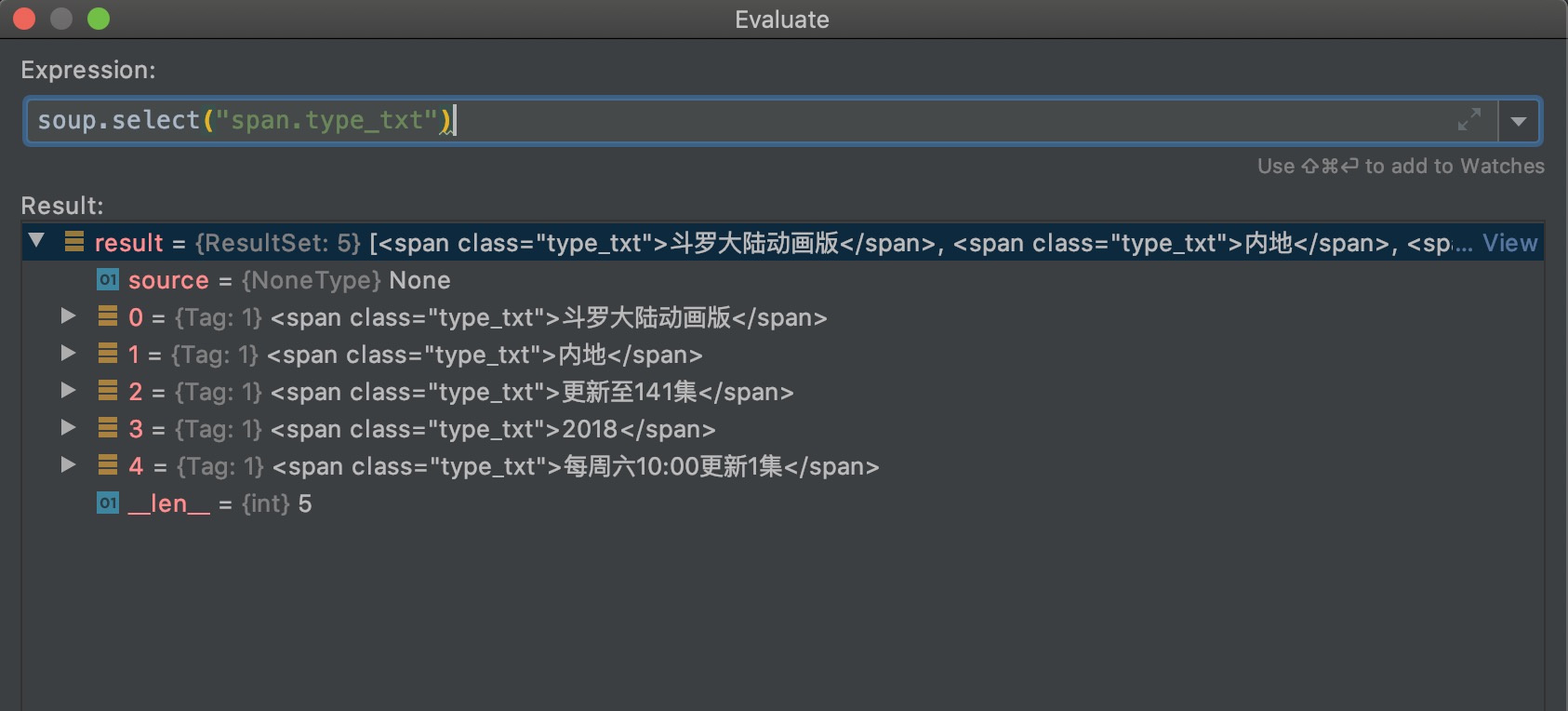
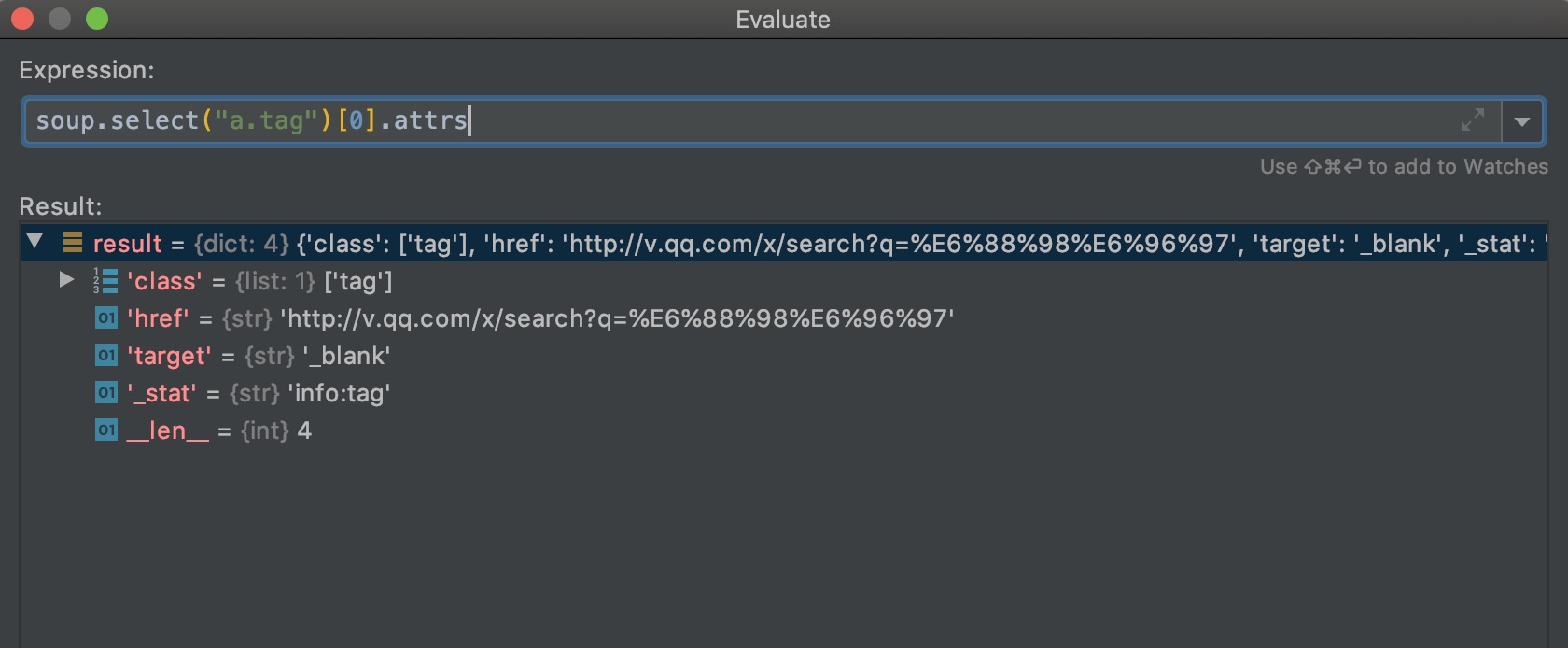
因为html中class="type_txt"的span元素有五个,所以返回了五个元素的列表。遍历列表,每个元素可以通过string属性,来输出元素中间的文本内容;每个元素通过attrs属性,可以获取标签的属性,返回一个字典。
小技巧
如果你要问,不会css选择器能不能写爬虫啊,我肯定不会回答我帮你写啊,我只能告诉你可以!!
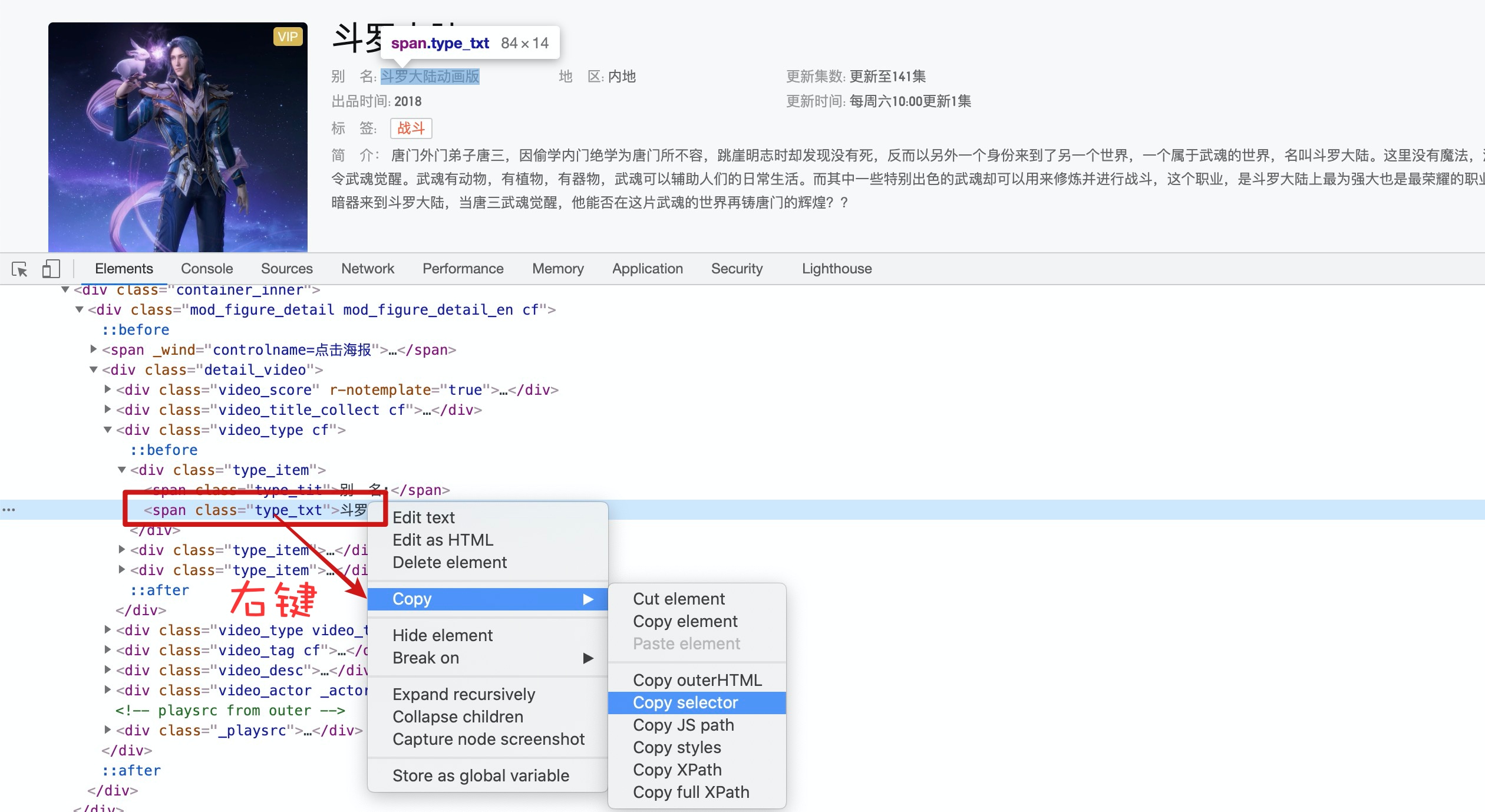
复制的css选择器如下:
body > div:nth-child(3) > div.site_container.container_detail_top > div > div > div > div:nth-child(3) > div:nth-child(1) > span.type_txt
我们用这个测试一下:
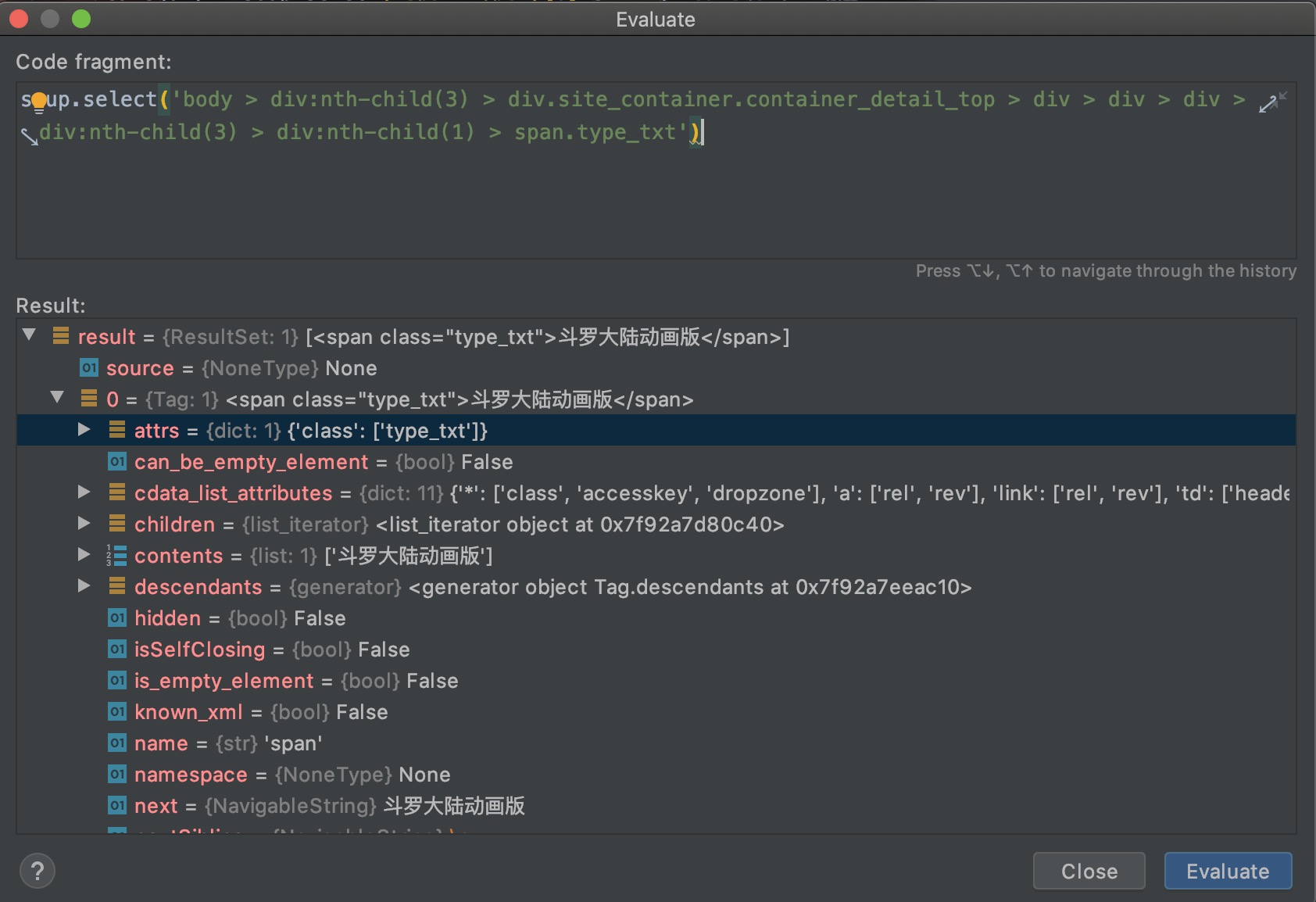
虽然看起来比较长,但还是正确地选择到了span元素。
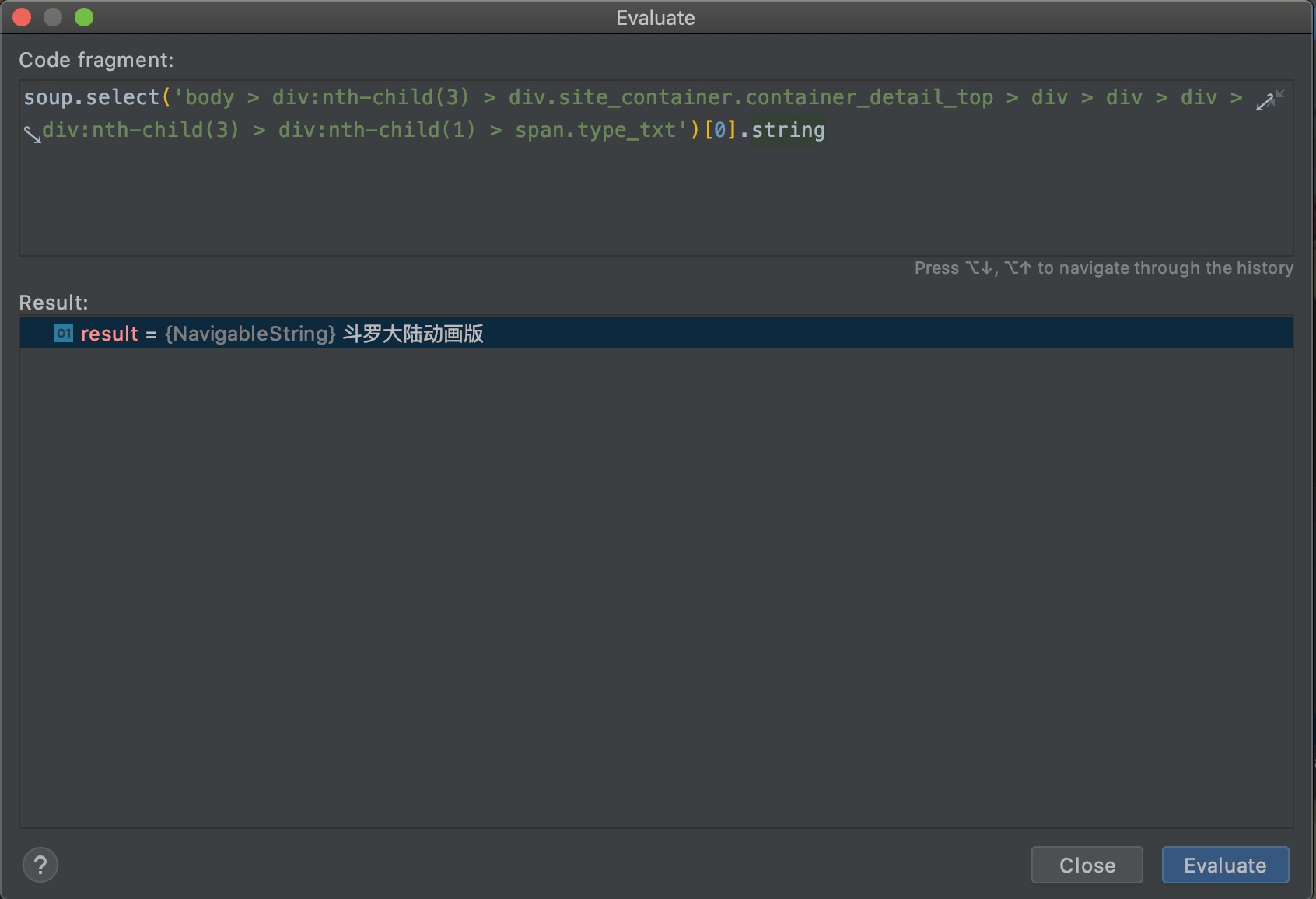
xpath
xpah全名Xml Path Language(xml路径语言),说实话,我没用过xpath,现学现卖。
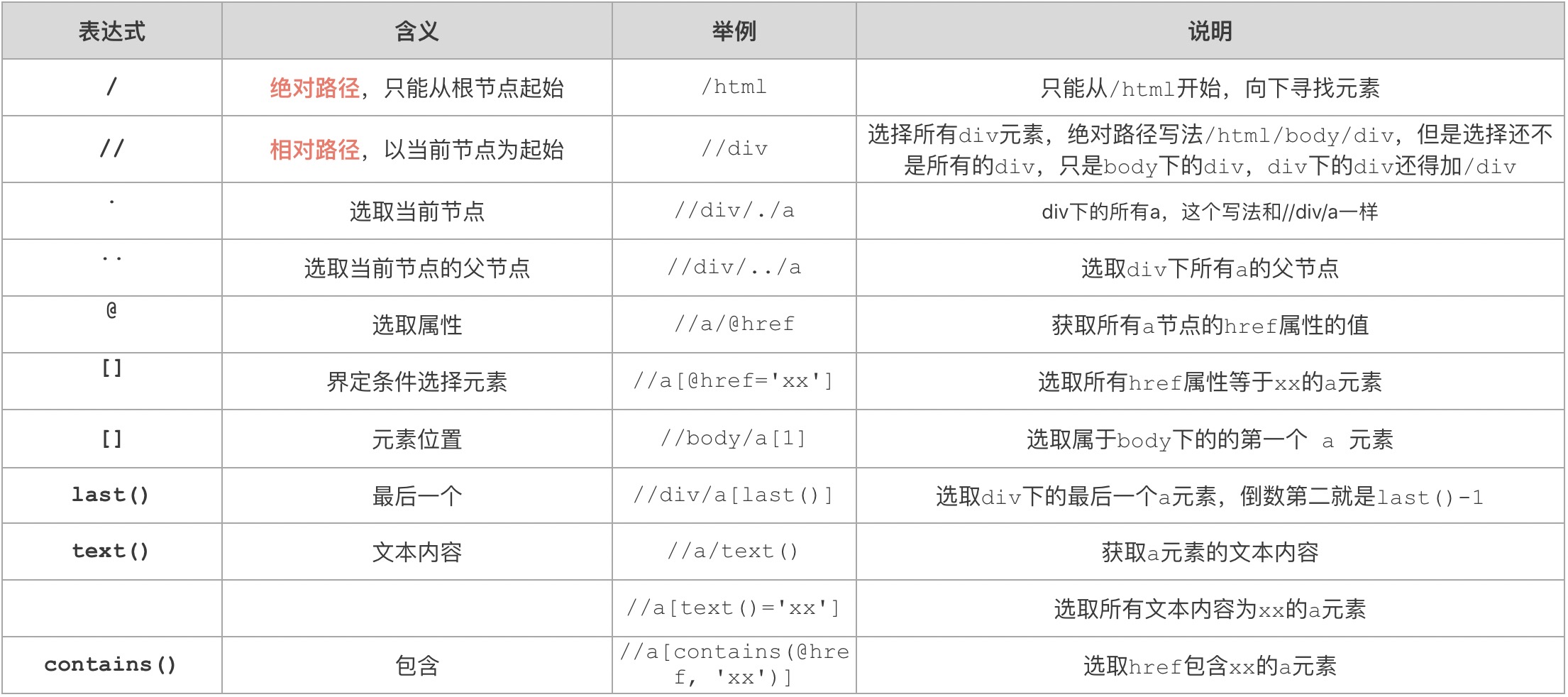
如图是比较常见的xpath语法,我从参考文档、使用测试到整理成表格一共用了半个多小时。从节点选择路径来说,一般相对路径用的比较多。元素后面[]里面的内容就是if条件。
同时,css选择器无法选择元素的父元素,而xpath可以通过../来选择元素的父元素。
样例说明
这个斗罗大陆爬虫样例是博客园的网友从评论区写的,非常感谢。
import requests
from lxml.html import etree
url = 'https://v.qq.com/detail/m/m441e3rjq9kwpsc.html'
response = requests.get(url)
response_demo = etree.HTML(response.text)
# 选择_stat属性为info:title的a元素,/text()表示输出选中的a元素的文本内容
# <a _stat="info:title>斗罗大陆</a>,结果是输出 斗罗大陆
name = response_demo.xpath('//a[@_stat="info:title"]/text()')
# *表示所有节点,所有class="type_txt"的节点的文本
type_txt = response_demo.xpath('//*[@class="type_txt"]/text()')
tag = response_demo.xpath('//*[@class="tag"]/text()')
describe = response_demo.xpath('//*[@class="txt _desc_txt_lineHight"]/text()')
print(name, type_txt, tag, describe, sep='\n')
查看这些变量的值:
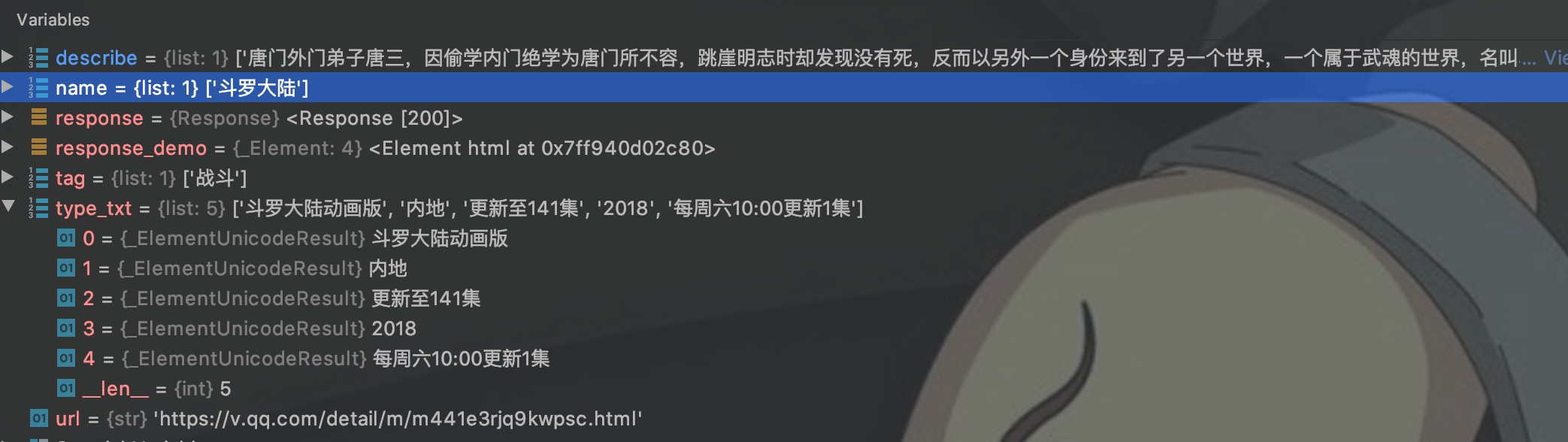
这些变量的类型也是list,也需要用下标或者遍历来取出里面的值。
小技巧
和css一样,不过选择的是Copy Xpath。
复制的xpath:
/html/body/div[2]/div[1]/div/div/div/div[3]/div[1]/span[2]
测试结果:
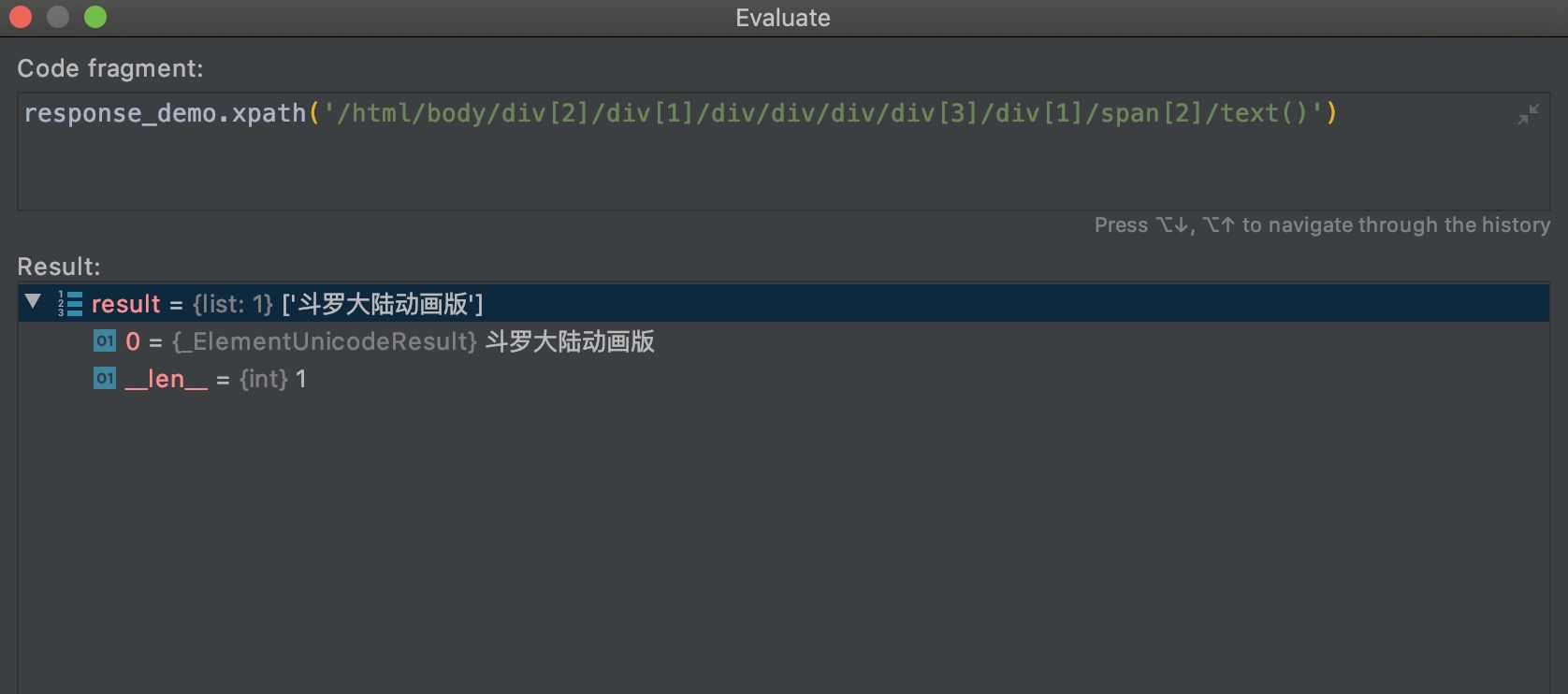
不过要注意的是,xpath一定要对起始点元素做好选择。
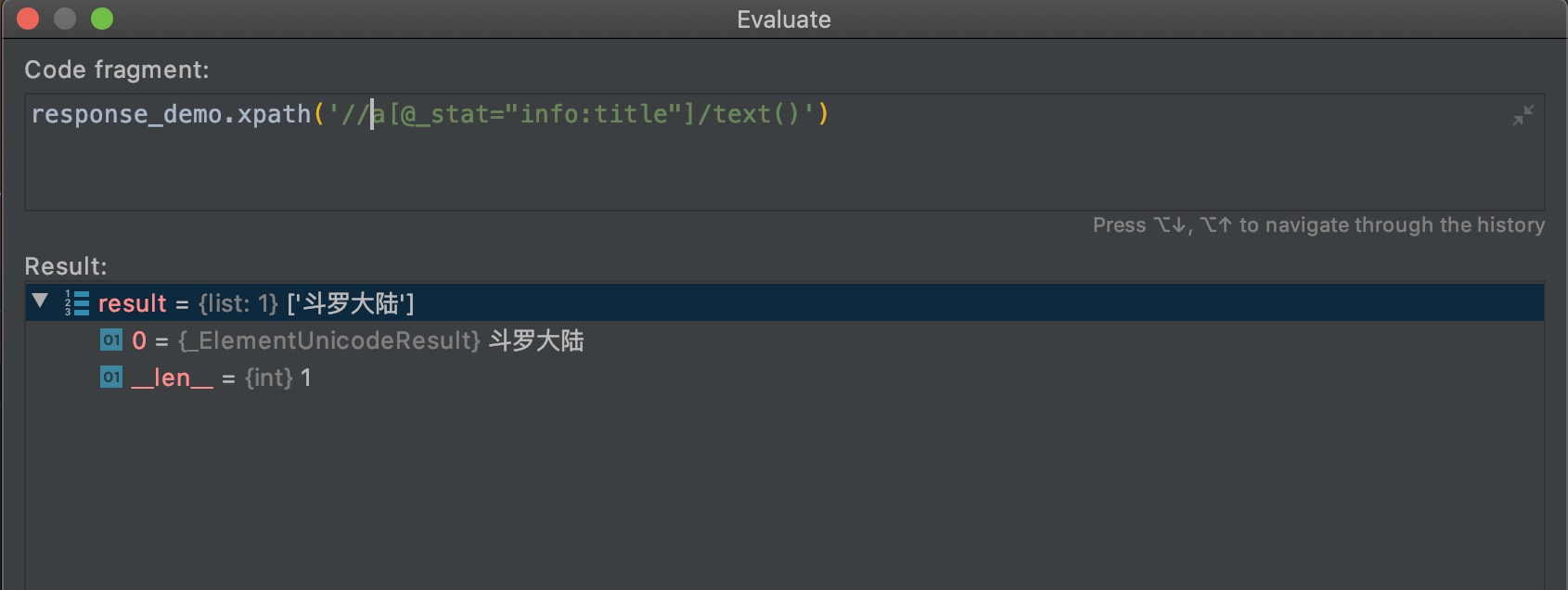
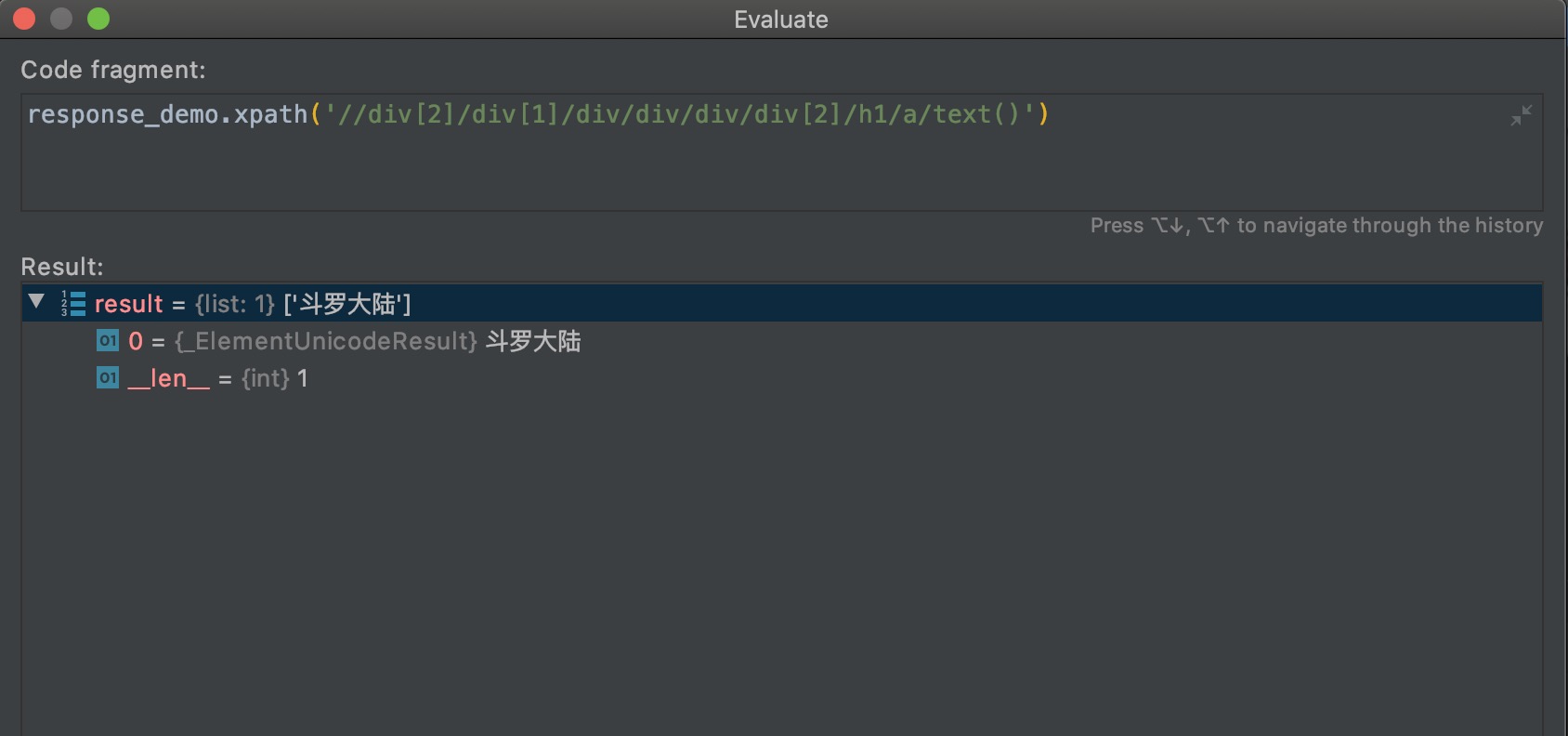
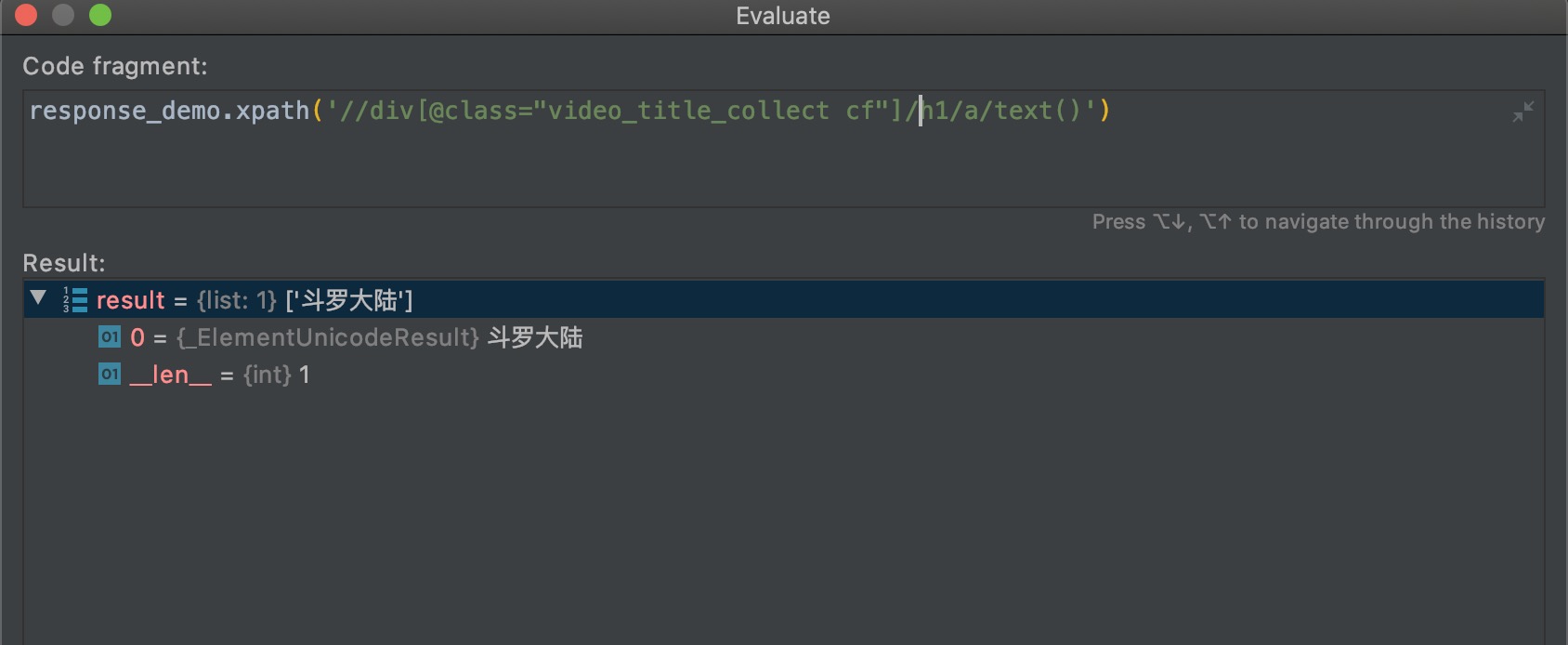
上面三个不一样的xpath输出了同样的结果,起始点元素的选择决定了xpath的复杂度。
性能比较
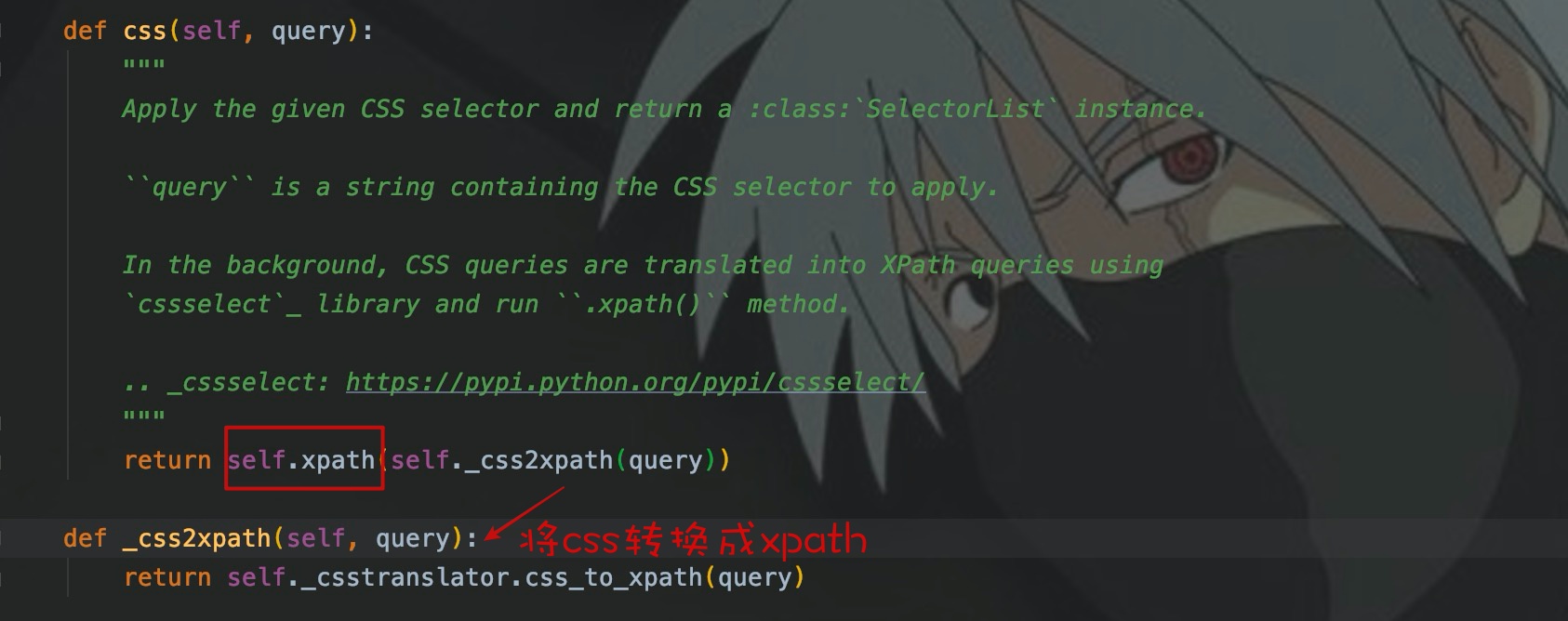
在原生爬虫中,lxml封装的xpath,相对于bs4封装的css性能要好,所以很多人选择使用xpath。在爬虫框架scrapy中,其底层使用的是parsel封装的选择器,css规则最终也会转换成xpath去选择元素,所以css会比xpath慢,因为转换是需要耗时的,但是微乎其微,在实际爬虫程序中基本上感知不到。
结语
本篇文章主要写了一下html的解析,对css选择器和xpath简单的描述了一下。如果想要熟练的使用,还是需要在开发实践中深入理解。
可以根据个人习惯,选择到底是使用css选择器还是xpath,我在scrapy中比较喜欢使用css选择器。因为爬虫也需要控制并发和网站访问频率,所以速度有时候也没有那么重要。期待下一次相遇。
写的都是日常工作中的亲身实践,处于自己的角度从0写到1,保证能够真正让大家看懂。
文章会在公众号 [入门到放弃之路] 首发,期待你的关注。

爬虫入门到放弃系列02:html网页如何解析的更多相关文章
- php从入门到放弃系列-02.php基础语法
php从入门到放弃系列-02.php基础语法 一.学习语法,从hello world开始 PHP(全称:PHP:Hypertext Preprocessor,即"PHP:超文本预处理器&qu ...
- 爬虫入门到放弃系列07:js混淆、eval加密、字体加密三大反爬技术
前言 如果再说IP请求次数检测.验证码这种最常见的反爬虫技术,可能大家听得耳朵都出茧子了.当然,也有的同学写了了几天的爬虫,觉得爬虫太简单.没有啥挑战性.所以特地找了三个有一定难度的网站,希望可以有兴 ...
- 爬虫入门到放弃系列05:从程序模块设计到代理IP池
前言 上篇文章吧啦吧啦讲了一些有的没的,现在还是回到主题写点技术相关的.本篇文章作为基础爬虫知识的最后一篇,将以爬虫程序的模块设计来完结. 在我漫(liang)长(nian)的爬虫开发生涯中,我通常将 ...
- php从入门到放弃系列-01.php环境的搭建
php从入门到放弃系列-01.php环境的搭建 一.为什么要学习php 1.php语言适用于中小型网站的快速开发: 2.并且有非常成熟的开源框架,例如yii,thinkphp等: 3.几乎全部的CMS ...
- [大数据从入门到放弃系列教程]第一个spark分析程序
[大数据从入门到放弃系列教程]第一个spark分析程序 原文链接:http://www.cnblogs.com/blog5277/p/8580007.html 原文作者:博客园--曲高终和寡 **** ...
- [大数据从入门到放弃系列教程]在IDEA的Java项目里,配置并加入Scala,写出并运行scala的hello world
[大数据从入门到放弃系列教程]在IDEA的Java项目里,配置并加入Scala,写出并运行scala的hello world 原文链接:http://www.cnblogs.com/blog5277/ ...
- php从入门到放弃系列-04.php页面间值传递和保持
php从入门到放弃系列-04.php页面间值传递和保持 一.目录结构 二.两次页面间传递值 在两次页面之间传递少量数据,可以使用get提交,也可以使用post提交,二者的区别恕不赘述. 1.get提交 ...
- php从入门到放弃系列-03.php函数和面向对象
php从入门到放弃系列-03.php函数和面向对象 一.函数 php真正的威力源自它的函数,内置了1000个函数,可以参考PHP 参考手册. 自定义函数: function functionName( ...
- K8S从入门到放弃系列-(16)Kubernetes集群Prometheus-operator监控部署
Prometheus Operator不同于Prometheus,Prometheus Operator是 CoreOS 开源的一套用于管理在 Kubernetes 集群上的 Prometheus 控 ...
随机推荐
- ElasticSearch教程——自定义分词器(转学习使用)
一.分词器 Elasticsearch中,内置了很多分词器(analyzers),例如standard(标准分词器).english(英文分词)和chinese(中文分词),默认是standard. ...
- Popup中ListBox的SelectChange事件关闭弹出窗体后主窗体点击无效BUG
WPF的BUG!弹出框的 自定义控件里有Popup, Popup里面放一个ListBox 在ListBox中的SelectionChange事件触发关闭弹出框后,主窗体存在一定概率卡死(但点击标题又能 ...
- 使用OpenCV进行简单的人像分割与合成
图像合成 实现思路 通过背景建模的方法,对源图像中的动态人物前景进行分割,再将目标图像作为背景,进行合成操作,获得一个可用的合成影像. 实现步骤如下. 使用BackgroundSubtractorMO ...
- 【Linux】1、命令行及命令参数
命令行及命令参数 文章目录 命令行及命令参数 1.命令行提示符 2.命令和命令参数 简单的命令 date ls 命令参数 短参数(一个字母) 长参数(多个字母) 参数的值 其它参数 3.小结 4.参考 ...
- oracle查看用户的系统权限,角色以及数据库对象权限
select * from dba_sys_privs where GRANTEE='monkey'; select * from dba_role_privs where GRANTEE='monk ...
- 修改主机名后VCS的修改
转:https://blog.csdn.net/nauwzj/article/details/6733135 一. 单机改主机名需更改以下文件: /etc/hosts /etc/hostname.hm ...
- 在Firefox上使用Chrome的crx扩展程序
假如你喜欢使用Firefox火狐浏览器,可是发现有个很喜欢很想用的扩展只发布了支持Chrome的crx格式--Firefox从57版以后使用了WebExtension API作为新附加组件的开发标准, ...
- Linux下安装配置rocketmq (单个Master、双Master)
一.环境: centos7(2台虚拟机):192.168.64.123:192.168.64.125 apache-maven-3.2.5(官网要求maven版本是3.2.x,版本不同,编译rocke ...
- linux 文件目录权限
文件目录权限: 什么是文件权限: 在Linux中,每个文件都有所属的所有者,和所有组,并且规定了文件的所有者,所有组以及其他人对文件的,可读,可写,可执行等权限. 对于目录的权限来说,可读是读取目录文 ...
- 你真的了解Android系统启动流程吗?Android高级工程师必看系列,已开源
前言 从毕业到现在面试也就那么几家公司,单前几次都比较顺利,在面到第三家时都给到了我offer!前面两次找工作,没考虑到以后需要什么,自己的对未来的规划是什么,只要有份工作,工资符合自己的要求就行!所 ...