jvm学习第一天
第一部分-jvm初识
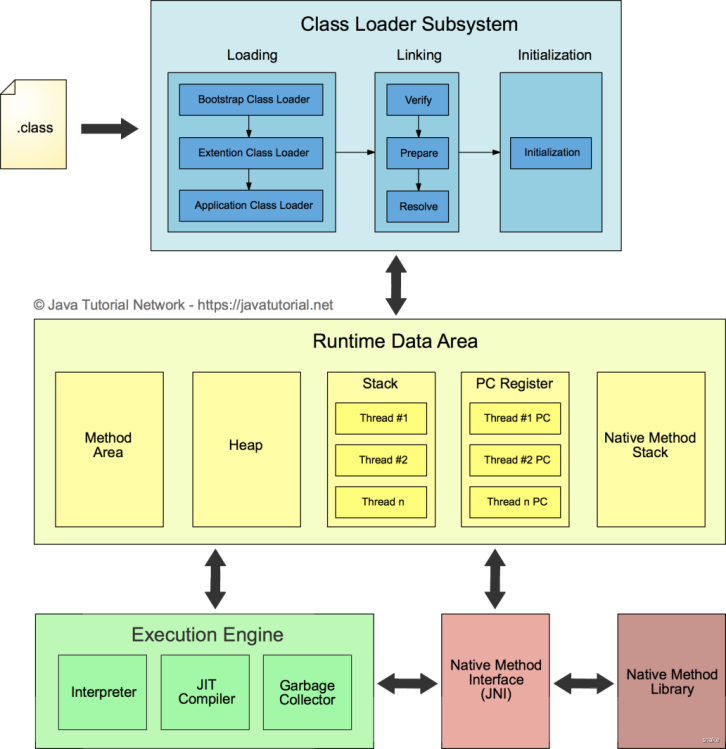
0.jvm概览图
JVM由三个主要的子系统构成
- 类加载子系统
- 运行时数据区(内存结构)
- 执行引擎运行时数据区(内存结构)
1.什么是jvm
定义:
- ①. JVM 是 java虚拟机,是用来执行java字节码(二进制的形式)的虚拟计算机
- ②. jvm是运行在操作系统之上的,与硬件没有任何关系
Java的跨平台就是靠jvm实现的
- ①. 跨平台:由Java编写的程序可以在不同的操作系统上运行:一次编写,多处运行
- ②. 原理:编译之后的字节码文件和平台无关,需要在不同的操作系统上安装一个对应版本的虚拟机(JVM)

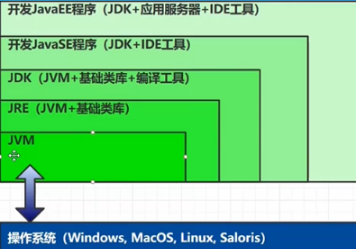
与jre、jdk、操作系统的关系图
2.jvm组成部分
- 1.类加载子系统
- 2.运行时数据区 [ 我们核心关注这里 的栈、堆、方法区 ]
- 3.执行引擎(一般都是JIT编译器和解释器共存)JIT编译器(主要影响性能):编译执行; 一般热点数据会进行二次编译,将字节码指令变成机器指令。将机器指令放在方法区缓存。
解释器(负责相应时间):逐行解释字节码
3.常见的jvm
- ①. Sun HotSpot(它是Sun JDK和OpenJDK中所带的虚拟机,也是目前使用范围最广的Java虚拟机,默认就是这种虚拟机)
- ②. BEA JRocket
- ③. iBM J9
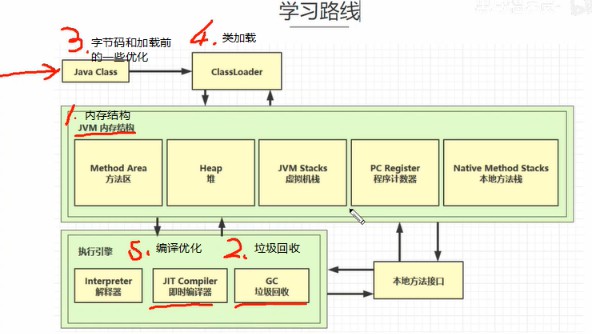
4.学习路线
第二部分-运行时数据区
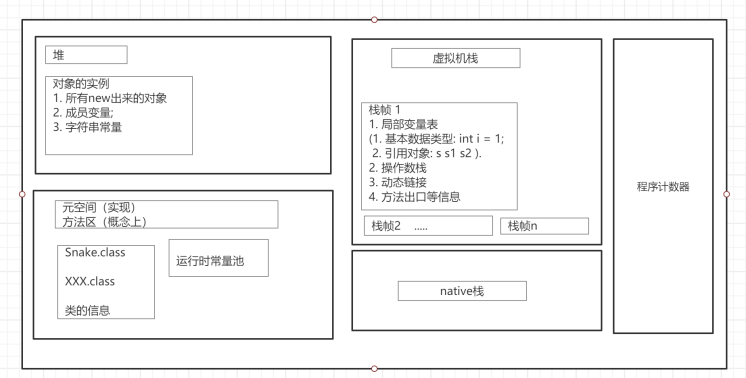
程序计数器学习

1.程序计数器_作用
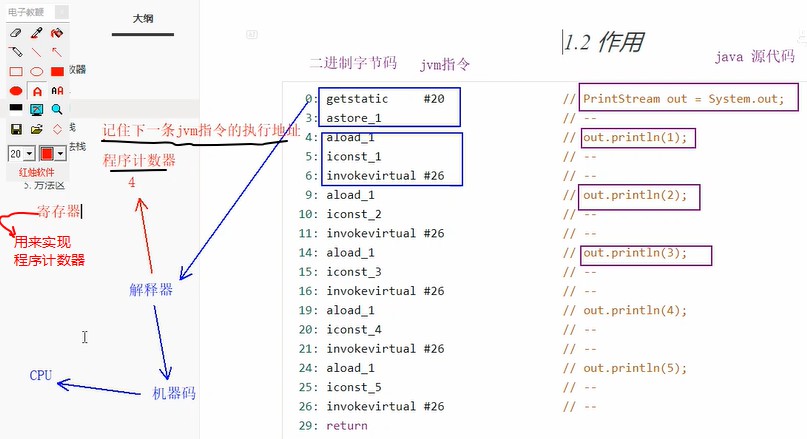
2.程序计数器_特点

栈学习
栈的结构特点:先进后出,线程栈是私有的,每个线程运行都需要开辟一个栈空间,一个栈对应着多个栈帧,栈帧就是线程中的一个个方法,每次调用对应的方法,就会入栈。
1.栈

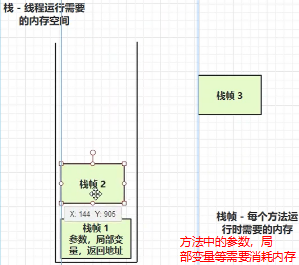
2.栈的演示
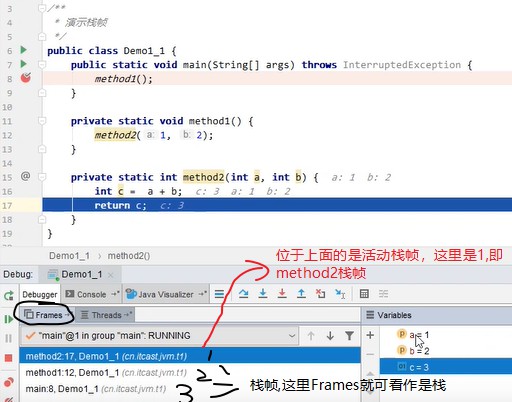
3.栈问题辨析
1.垃圾回收是否涉及栈内存?
不涉及,随着出栈,内存就会释放了
2.栈内存分配越大越好么?
也不是的,栈内存越大,单个线程占用的内存就很大,这样线程数就会减少。没有对应的栈帧使用也是一种浪费。
分配栈内存的参数:

3.方法内的局部变量是否线程安全?
讲这个之前,先说明一个问题,Java中的参数传递是值传递还是引用传递?
值传递(pass by value)是指在调用函数时将实际参数
复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
引用传递(pass by reference)是指在调用函数时将实际参数的地址直接传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
java中都是“值传递”,关键看这个值是什么,简单变量就是复制了具体值,对简单变量的修改不会影响到实际参数;引用变量就是复制了地址,而根据这个地址,可以查找到堆中的对象,对对象进行修改,这样虽然没有改变地址值,但是已经把地址指向的引用对象给改变了。而字符串等一些类型是不可变的,当然不会被修改.如果有疑问,可以再查看文章这里。


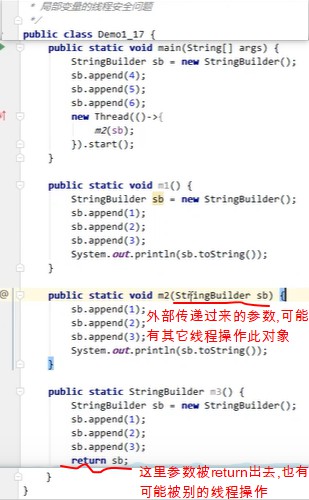
这边为了演示这个线程安全问题,自己写了个小代码模拟了下,结果如下:
//因为自己在在线工具编写运行的,故格式不是太好看哈
public class HelloWorld {
public static void main(String []args) throws Exception {
StringBuilder sb = new StringBuilder();
Thread t1 = new Thread(()-> {
m2(sb);
});
t1.start();
for(int i=0;i<10000;i++){
sb.append("a");
}
t1.join();
System.out.println(sb.length());
System.out.println("Hello World!");
}
public static void m2(StringBuilder sb){
for(int i=0;i<10000;i++){
sb.append("b");
}
}
}
4次运算结果如下,可以看到,确实出现了并发问题:

4.栈内存溢出
- 栈帧过多导致栈内存溢出
- 栈帧过大导致栈内存溢出
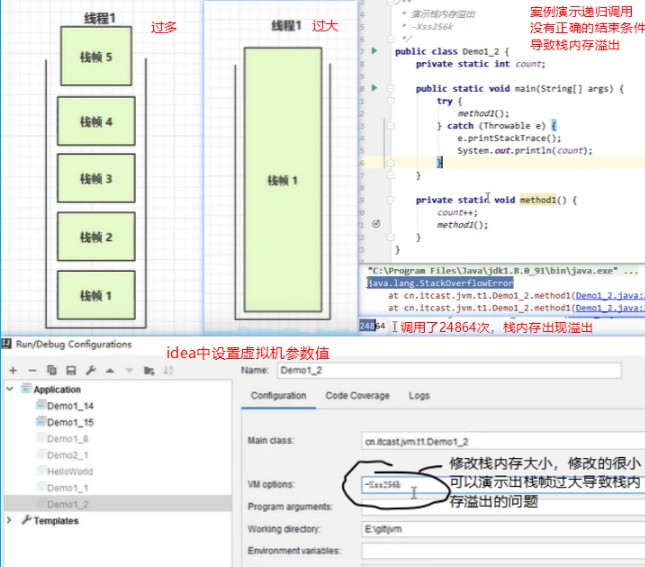
常见的还有json转换时2个对象互相引用导致的无限递归现象导致的栈内存溢出。
5.线程诊断——cpu占用过高

6.线程诊断--排查死锁问题,迟迟得不到结果
7.本地方法栈
堆学习
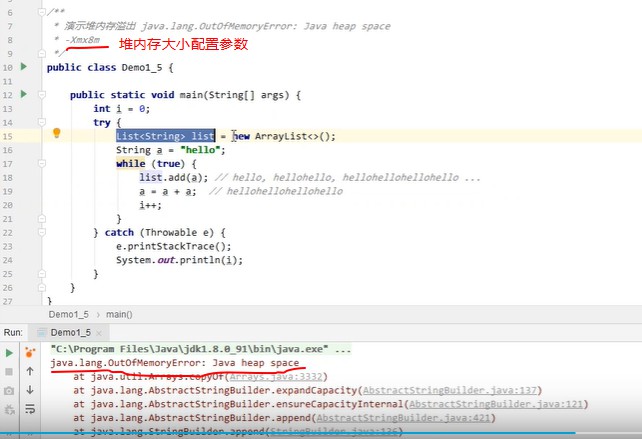
1.堆-定义

2.堆-内存溢出
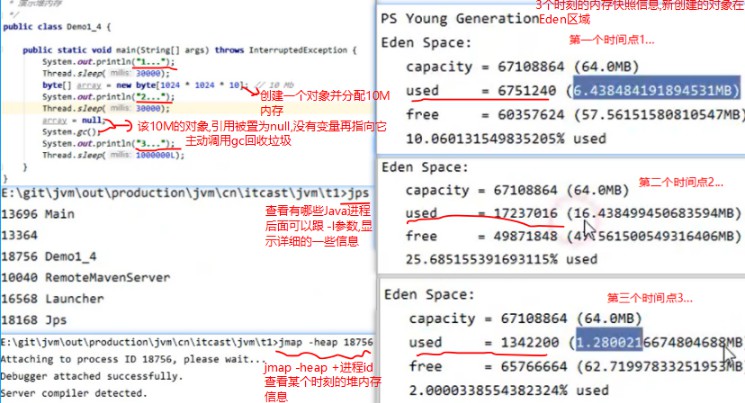
3.堆-内存诊断-jmap

4.堆-内存诊断-jconsole
如配置好Java环境变量等信息,可直接在dos窗口输入jconsole命令使用:
JConsole可视化工具介绍
5.堆内存诊断-jvirsualvm
jvirsualvm类似jconsole,使用方式也类似,但是功能更加强大,可以抓取某个时刻的堆内存信息并筛选出占用内存最大的一些对象,进行分析
垃圾回收后,内存仍然占用很高案例演示分析,模拟代码如下:
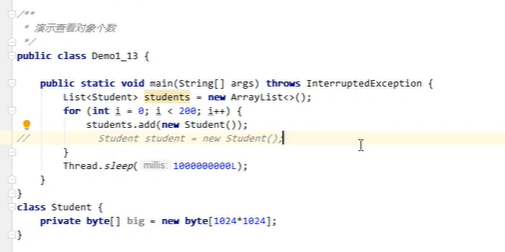
建议本知识点看视频
方法区学习
1.方法区-定义
官方jdk1.8方法区定义:

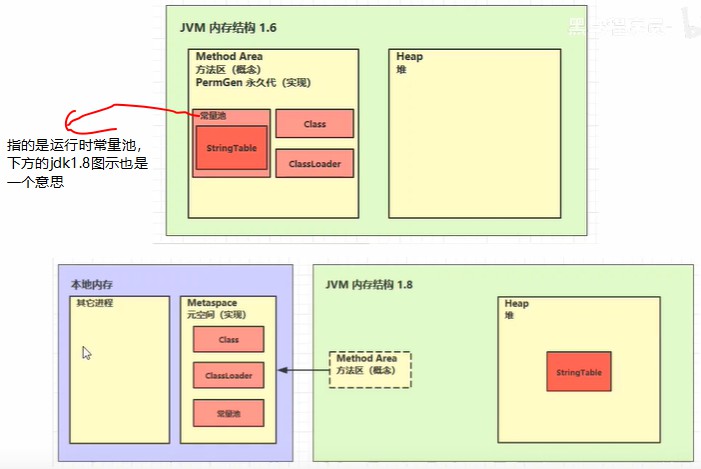
方法区只是一个概念性的,具体实现由jvm厂商来定,这里讲的是hotspot的,jdk1.6的时候方法区使用的是堆中永久代的空间实现的,而jdk1.8之后,使用的是元空间,即本地操作系统的内存。
jdk6和jdk8方法区及堆部分对比图:
2.方法区-内存溢出1
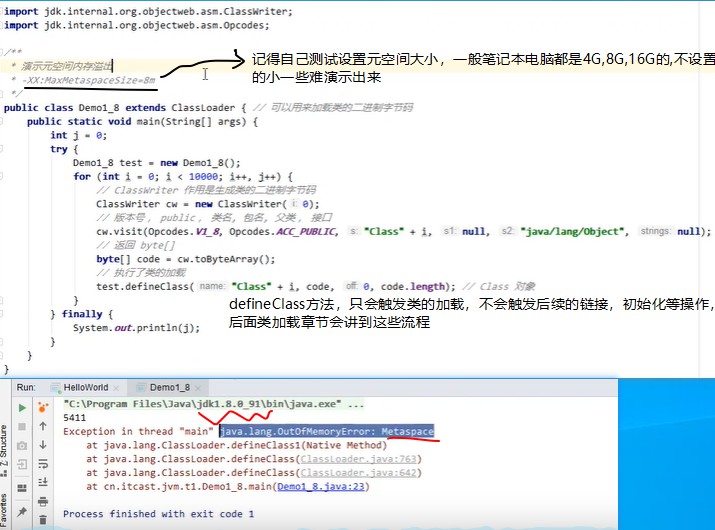
jdk1.8方法区内存溢出演示:
jdk1.6方法区内存溢出演示:
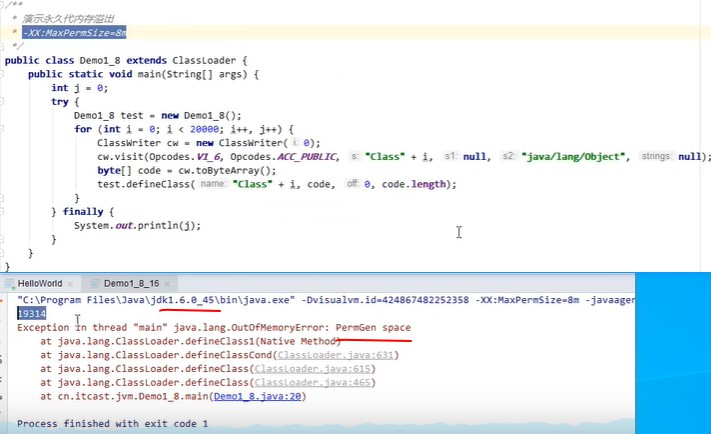
知道就行了,没必要安装2个jdk版本演示

动态代理,实际框架中会使用到区动态生成类,还是有可能产生很多类。
3.方法区-常量池
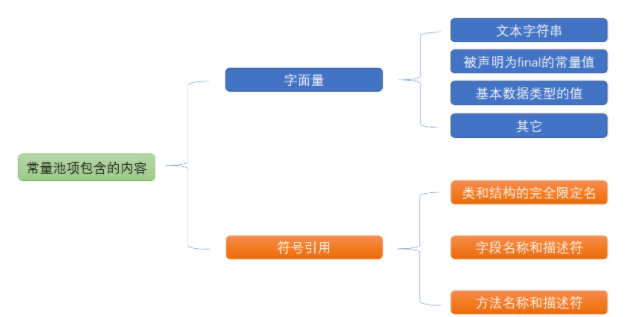
常量池,也叫 Class 常量池(常量池==Class常量池)。Java文件被编译成 Class文件,Class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项就是常量池,常量池是当Class文件被Java虚拟机加载进来后存放在方法区 各种字面量 (Literal)和 符号引用 。
在Class文件结构中,最头的4个字节用于 存储魔数 (Magic Number),用于确定一个文件是否能被JVM接受,再接着4个字节用于 存储版本号,前2个字节存储次版本号,后2个存储主版本号,再接着是用于存放常量的常量池常量池主要用于存放两大类常量:字面量和符号引用量,字面量相当于Java语言层面常量的概念,如文本字符串,声明为final的常量值等,符号引用则属于编译原理方面的概念。如下:
二进制字节码主要包括三个部分:1.类基本信息 2.常量池 3.类方法定义,包含了虚拟机指令,演示如下
首先创建一个类HelloWorld:
public class HelloWorld{
public static void main(String[] args){
System.out.println("hello world,梦开始的地方");
}
}
执行javap -v HelloWorld.class命令,-v参数是显示反编译后的详细信息
反编译后得到信息如下:
Classfile /C:/Users/wcc/Desktop/HelloWorld.class
Last modified 2020-11-27; size 453 bytes
MD5 checksum cf3eaa5935519c06e9824a9acad03192
Compiled from "HelloWorld.java"
public class HelloWorld
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER //截止到这里都是类基本信息
Constant pool:
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #18 // hello world,梦开始的地方
#4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #21 // HelloWorld
#6 = Class #22 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 main
#12 = Utf8 ([Ljava/lang/String;)V
#13 = Utf8 SourceFile
#14 = Utf8 HelloWorld.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = Class #23 // java/lang/System
#17 = NameAndType #24:#25 // out:Ljava/io/PrintStream;
#18 = Utf8 hello world,梦开始的地方
#19 = Class #26 // java/io/PrintStream
#20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V
#21 = Utf8 HelloWorld
#22 = Utf8 java/lang/Object
#23 = Utf8 java/lang/System
#24 = Utf8 out
#25 = Utf8 Ljava/io/PrintStream;
#26 = Utf8 java/io/PrintStream
#27 = Utf8 println
#28 = Utf8 (Ljava/lang/String;)V //截止到这里是常量池部分,下面就是一些构造方法,main方法等方法定义
{
public HelloWorld();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 1: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String hello world,梦开始的地方
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return //该类的方法主要就是执行的main方法,
LineNumberTable:
line 3: 0
line 4: 8
}
SourceFile: "HelloWorld.java"


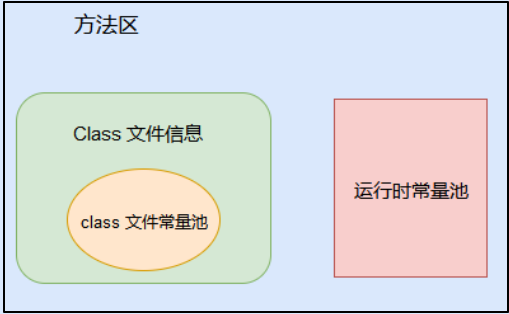
4.方法区-运行时常量池
运行时常量池是方法区的一部分。运行时常量池是当Class文件被加载到内存后,Java虚拟机会 将Class文件常量池里的内容转移到运行时常量池里(运行时常量池也是每个类都有一个)。运行时常量池相对于Class文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是并非预置入Class文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中。
方法区的Class文件信息,Class常量池和运行时常量池的三者关系
StringTable-字符创常量池(串池)学习
字符串常量池又称为:字符串池,全局字符串池,英文也叫String Pool。 在工作中,String类是我们使用频率非常高的一种对象类型。JVM为了提升性能和减少内存开销,避免字符串的重复创建,其维护了一块特殊的内存空间,这就是我们今天要讨论的核心:字符串常量池。字符串常量池由String类私有的维护。
1.StringTable-面试题
先看几道面试题,如果没有疑问,下面的章节就不用看啦哈哈

2.StringTable-常量池和串池关系
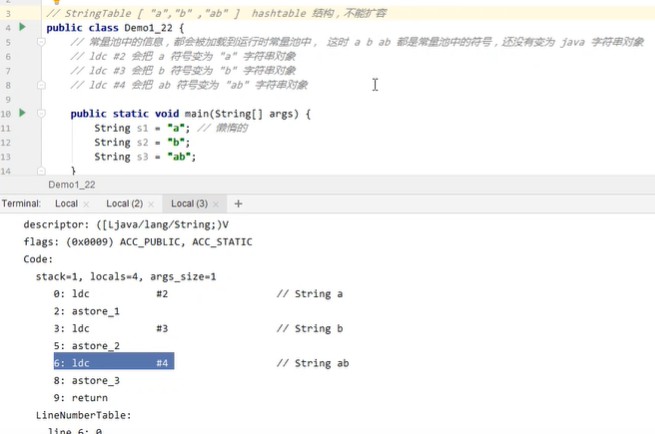
3.StringTable-字符串变量拼接
是针对jdk8版本的反编译,可能9之后又有新的优化,暂时先不分析了。

反编译后的变量表:

4.StringTable-编译期优化

5.StringTable-字符串延迟加载演示

6.StringTable-intern


7.StringTable面试题
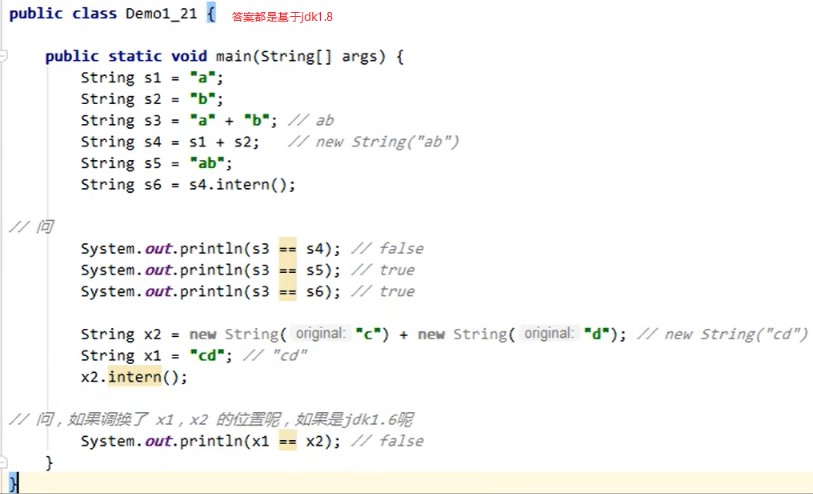
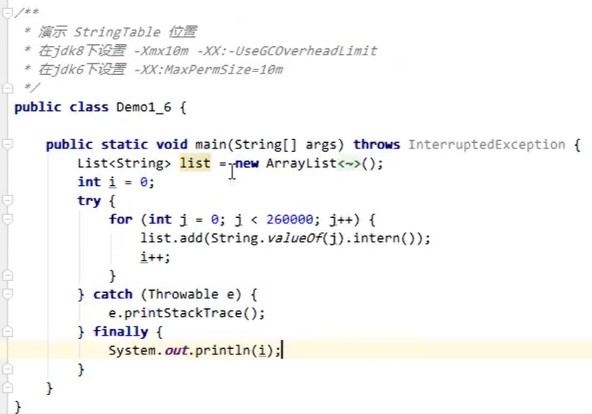
8.StringTable位置变化
StringTable(字符串常量池)为什么要调整到堆中?
jdk7中将StringTable放到了堆空间中。因为永久代的回收效率很低,在full GC的时候才会触发。而Full GC是老年代空间不足、永久代空间不足时才会触发。这就导致StringTable回收效率不高。而我们开发中会有大量的字符串被创建,回收效率低,导致永久代内存不足。放到堆里,能及时回收内存。
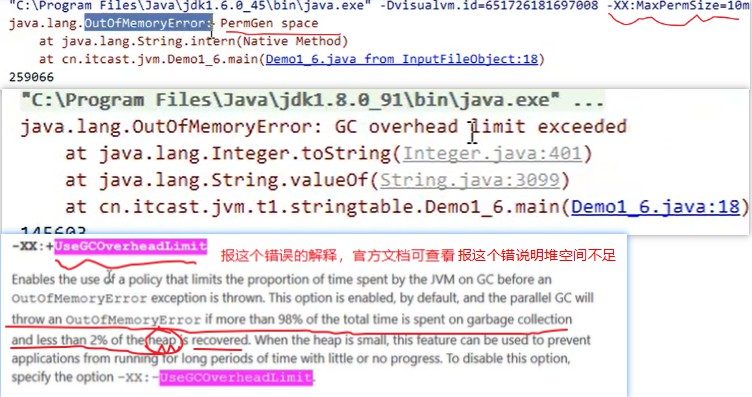
案例演示证明1.6之后StringTable位置的变化:
思路,如果是1.6当有大量字符串对象时,会报永久代空间不足,1.7之后是堆空间不足
9.StringTable垃圾回收
很多人认为jvm字符串常量不会被回收的,其实这个说法的有误区的,我们通过一些jvm参数可以看到StringTable的垃圾回收。
这里可以查看我记录的另一篇文章,StringTable垃圾回收的演示
10.StringTable调优
主要从以下2个方面去考虑:
1、StringTableSize
jvm的默认桶的大小:
Number of buckets : 60013 = 480104 bytes, avg 8.000
添加参数增加桶的个数(最小值可以设置为1009):
-XX StringTableSize=200000
减少桶的冲突,可以提高jvm的效率
public static void main(String[] args) {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(new File("f:\\test.txt"))));
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
line.intern();
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
- 通过读取文件将文件中的每一行逐行加入到StringTable中,修改桶的大小来测试所需要的时间(文件为8145行)
| StringTableSize | Time |
| ---- | ---- |
| 1024 | 116 ms |
| 4096 | 87 ms |
2、考虑字符串对象是否入池
运用intern方法将字符串入池,保证相同的字符串只存储一份(在串池中如果已经有相同的字符串对象就不会再创建该字符串对象了)
public static void main(String[] args) {
try {
List<String> list = new ArrayList<>();
System.in.read();
for (int i = 0; i < 30; i++) {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(new File("f:\\test.txt"))));
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
//不入池
list.add(line);
//入池
//list.add(line.intern());
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
}
System.in.read();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
直接内存部分
是操作系统的内存部分,并不属于Java虚拟机,在nio部分再详细学习下会
1.直接内存

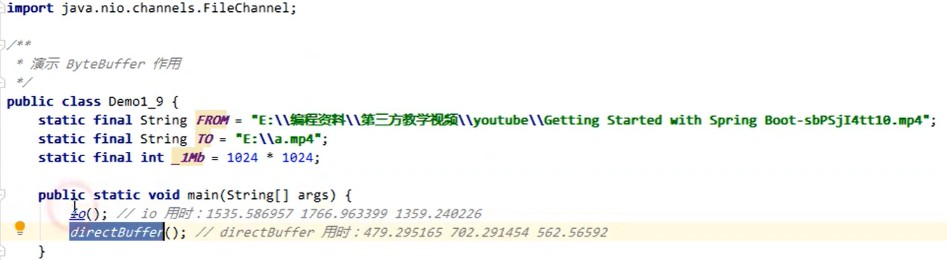
案例演示传统IO读取文件和使用Java NIO direct buffer读取文件耗时演示,由于自己还没有用过nio,后面需要自己手写下这块的代码。并会单独学习nio的知识并撰写文章。
案例代码截图:
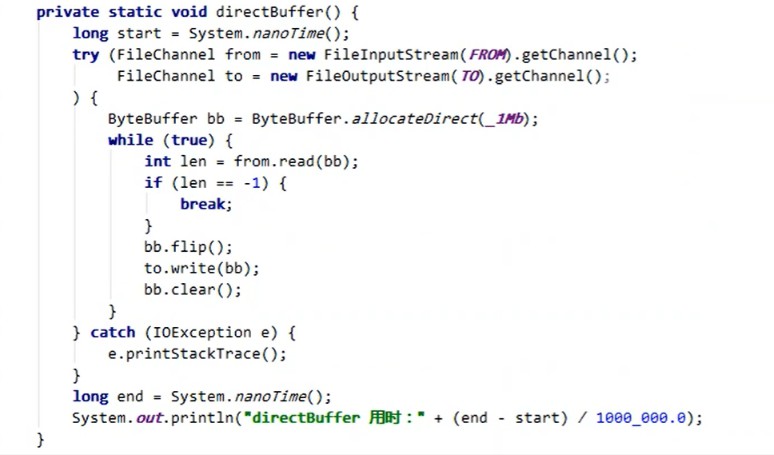
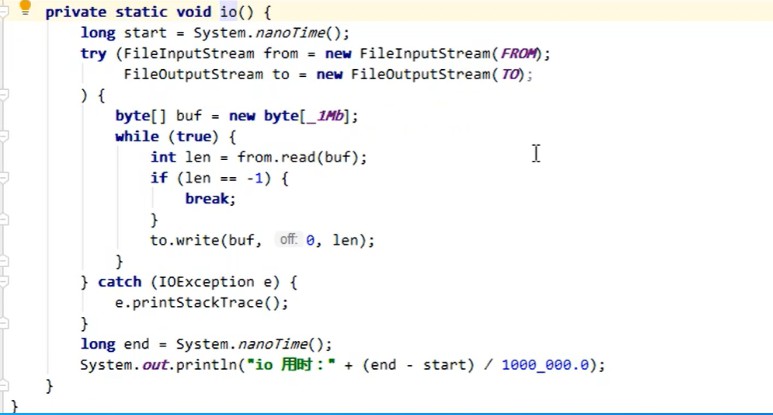
结果展示,时间相差还是很多的,上次面试还被问道nio,很有必要学下这里

2.直接内存-基本使用
JDK8将方法区的实现从堆内存移至直接内存
- 不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域
- 直接内存是在Java堆外的、直接向系统申请的内存区间
- 来源于NIO,通过存在堆中的DirectByteBuffer操作Native内存(NIO在JDK4引入,JDK7引入NIO2)
- 通常,访问直接内存的速度会优于Java堆。即读写性能高
* 因此处于性能考虑,读写频繁的场合可能会考虑使用直接内存
* Java的NIO库允许Java程序使用直接内存,用于数据缓冲区。
| IO | NIO |
| ---- | ---- |
| byte[] / char[] | Buffer |
| Stream | Channel |
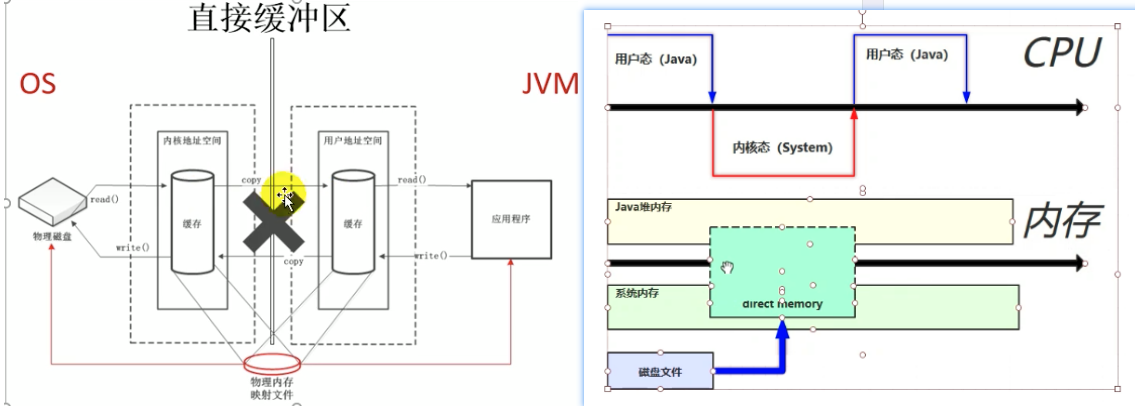
**非直接缓冲区 **
读写文件,需要与磁盘交互,需要由用户态切换到内核态。在内核态时,需要内存如右的操作。使用IO,见下图。这里需要两分内存存储重复数据,效率低。

直接缓冲区
使用NIO时,如下图所示。操作系统划出的直接缓存区可以被java代码直接访问,只有一份,NIO适合对大文件的读写操作。
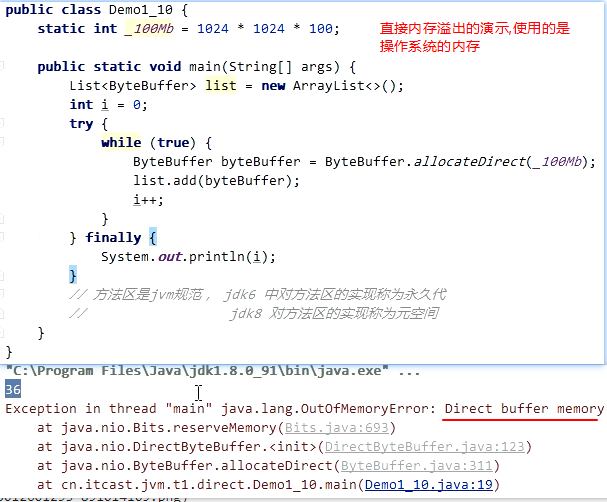
3.直接内存-内存溢出

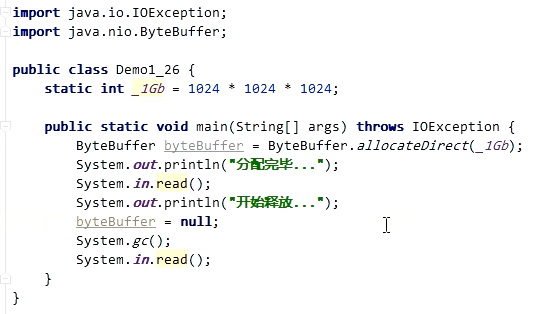
4.直接内存-释放原理
演示直接内存释放
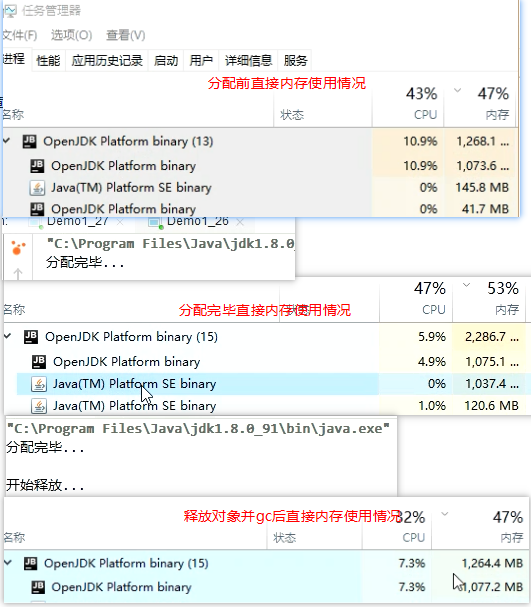
Java中使用Unsafe类分配释放直接内存的演示,尽量不要使用这个类,这里只是演示下
垃圾回收并不能释放直接内存,底层是通过调用unsafe实现的
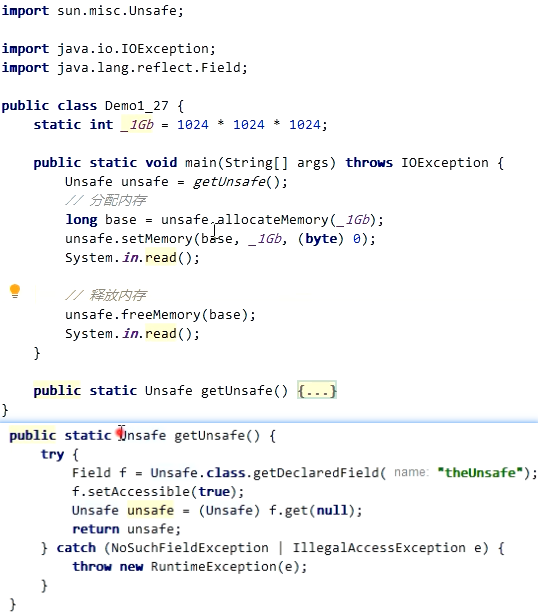
为什么垃圾回收时可以释放直接内存呐,真正的原因

System.gc不能回收堆外内存,但是会回收已经没有使用了DirectByteBuffer对象,该对象被回收的时候会将cleaner对象放入队列中,在Reference的线程中调用clean方法来回收堆外内存。这里暂时知道就行了,后面再补文章,这篇文章已经很长了,写了3天了。。。我太难了,后续补
5.直接内存-禁用显示回收对直接内存的影响
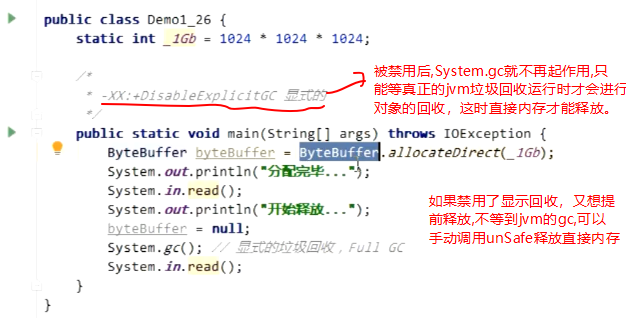
终于搞完啦,可以睡觉了,明天开始第二天的学习,已经凌晨2点了。。。。我去,希望头发依然多多,我爱你头发,别离开俺,晚安
jvm学习第一天的更多相关文章
- JVM学习第一篇思考:一个Java代码是怎么运行起来的-上篇
JVM学习第一篇思考:一个Java代码是怎么运行起来的-上篇 作为一个使用Java语言开发的程序员,我们都知道,要想运行Java程序至少需要安装JRE(安装JDK也没问题).我们也知道我们Java程序 ...
- JVM学习第一天(虚拟机的前世今生与与Java的内存区域)
其实说JVM的时候有很多人会懵, 也很不理解,我会写Java代码就可以了,我干嘛要学这个,其实不是的,学习JVM是很有必要性的; 为什么要了解JVM 1:写出更好,更健壮的Java程序; 2:提高Ja ...
- JVM学习篇-第一篇
JVM学习篇-第一篇 JDK( Java Development Kit): Java程序设计语言.Java虚拟机.Java类库三部分统称为JDK,JDK是用于支持Java程序开发的最小环境** ...
- JVM学习(4)——全面总结Java的GC算法和回收机制
俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!涉及到的知识点总结如下: 一些JVM的跟踪参数的设置 Java堆的分配参数 -Xmx 和 –Xms 应该保持一个什么关系,可以让系统的 ...
- JVM学习(3)——总结Java内存模型
俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!涉及到的知识点总结如下: 为什么学习Java的内存模式 缓存一致性问题 什么是内存模型 JMM(Java Memory Model)简 ...
- Java学习第一天
Java学习第一天 对于网络管理员或者黑客必须知道的八个cmd命令 详情请参考:http://www.2cto.com/os/201608/533964.html nbtstat ...
- java jvm学习笔记七(jar包的代码认证和签名)
欢迎装载请说明出处:http://blog.csdn.net/yfqnihao 前言: 如果你循序渐进的看到这里,那么说明你的毅力提高了,jvm的很多东西都是比较抽像的,如果不找相对应的代码来辅助理解 ...
- java之jvm学习笔记六-十二(实践写自己的安全管理器)(jar包的代码认证和签名) (实践对jar包的代码签名) (策略文件)(策略和保护域) (访问控制器) (访问控制器的栈校验机制) (jvm基本结构)
java之jvm学习笔记六(实践写自己的安全管理器) 安全管理器SecurityManager里设计的内容实在是非常的庞大,它的核心方法就是checkPerssiom这个方法里又调用 AccessCo ...
- java之jvm学习笔记三(Class文件检验器)
java之jvm学习笔记三(Class文件检验器) 前面的学习我们知道了class文件被类装载器所装载,但是在装载class文件之前或之后,class文件实际上还需要被校验,这就是今天的学习主题,cl ...
随机推荐
- linux系统重启网卡后网络不通(NetworkManager篇)
一.故障现象 RHEL7.6系统,使用nmcli绑定双网卡后,再使用以下命令重启network服务后主机网络异常,导致无法通过ssh远程登录系统. # systemctl restart n ...
- java实现发送短信验证码
java实现短信验证码发送 由于我们使用第三方平台进行验证码的发送,所以首先,我们要在一个平台进行注册. 在这里我选择是秒嘀科技,因为新人注册会赠送十元,足够测试使用了. 注册完成后,我们需要获取自己 ...
- #3使用html+css+js制作网页 制作登录网页
#3使用html+css+js制作网页 制作登录网页 本系列链接 2制作登录网页 2.1 准备 2.1.1 创建文件夹 2.1.2 创建主文件 2.2 html部分 2.2.1 网站信息 2.2.2 ...
- Scrapy使用RabbitMQ做任务队列
前言 一个月没更博客了,这个月也搞了不少东西,但是公司对保密性要求挺高,很多东西都没有办法写出来 想来想去,还是写一篇最近写Scrapy中遇到的跳转问题 如果你的业务需求是遇到301/302/303跳 ...
- golang遍历时修改被遍历对象
目录 前言 遍历切片 遍历map 总结 前言 很多时候需要将遍历对象中去掉某些元素,或者往遍历对象中添加元素,这时候就需要小心操作了. 对于go语言中的一些注意事项我做了总结和示例,留下点笔记. 遍历 ...
- TCP/IP五层模型-应用层-DNS协议
1.定义:域名解析协议,把域名解析成对应的IP地址. 2.分类:①迭代解析:DNS所在服务器若没有可以响应的结果,会向客户机提供其他能够解析查询请求的DNS服务器地址,当客户机发送查询请求时,DNS ...
- 虚拟机Linux安装Oracle容器并实现局域网其他主机访问查询
该文涉及Docker下Oracle容器的安装,主机端口的设置实现局域网内终端均能连接上Oracle数据库,图解如下: 一.关于Docker安装oracle容器可以参考下面博文: https://blo ...
- 【Java】Java关键字、含义
Java关键字 来自 Java 核心技术卷I 基础知识(原书第10 版)/( 美)凯S 霍斯特曼(Cay S . Horstmann )著: 周立新等译一北京:机械工业出版社, 2016 . 8 Ja ...
- wmic 操作文件的datafile
wmic datafile /?动词有ASSOC,CALL,CREATE,DELETE,GET,LIST 这几个 命令:wmic datafile where "filename='dsc0 ...
- 解决ubuntu获取root账号并开通ssh
1.设置root密码 sudo passwd root 2.修改etc/ssh/sshd_config文件 su - root vi /etc/ssh/sshd_config LoginGraceTi ...