阿里云DataWorks实践:数据集成+数据开发
简介
什么是DataWorks:
- DataWorks(数据工场,原大数据开发套件)是阿里云重要的PaaS(Platform-as-a-Service)平台产品,为您提供数据集成、数据开发、数据地图、数据质量和数据服务等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。
- DataWorks支持多种计算和存储引擎服务,包括离线计算MaxCompute、开源大数据引擎E-MapReduce、实时计算(基于Flink)、机器学习PAI、图计算服务Graph Compute和交互式分析服务等,并且支持用户自定义接入计算和存储服务。DataWorks为您提供全链路智能大数据及AI开发和治理服务。
学习路径:
实践案例目标:将MongoDB数据库中的目标日志集合同步至阿里云DataWorks中,在DataWorks中进行日志解析处理后,将处理后的新数据同步到MongoDB数据库的新集合中,整个业务流程的执行间隔尽量缩短。
实践案例步骤:
- 准备阿里云账号并登录
- 创建并配置工作空间
- 购买独享数据集成资源组并绑定
- 创建并配置数据源
- 配置并创建MaxCompute表
- 创建业务流程
- 创建并配置离线数据增量同步节点
- 下载IntelliJ IDEA的MaxCompute Studio插件并配置
- 使用MaxCompute Studio开发MapReduce功能的Java程序
- 将MapReduce功能程序打包上传为资源
- 创建并配置ODPS MR节点
- 关联各个节点
- 提交业务流程并查看运行结果
步骤
一、准备阿里云账号并登录
Ⅰ、注册阿里云账号
官方文档:准备阿里云账号
步骤图示:
官网首页点击右上角"立即注册"。
选择注册方式进行注册。
注册完成后,官网首页右上角可登录账号。
登录成功后,点击右上角"我的阿里云"图标,会出现账户信息边栏。

在边栏中点击"账号管理",进入账号管理页面。
在账号管理页面完成实名认证。

完成实名认证后,鼠标箭头悬停在页面右上角的头像上,在出现的悬浮框中点击"AccessKey管理",进入AccessKey管理页面。
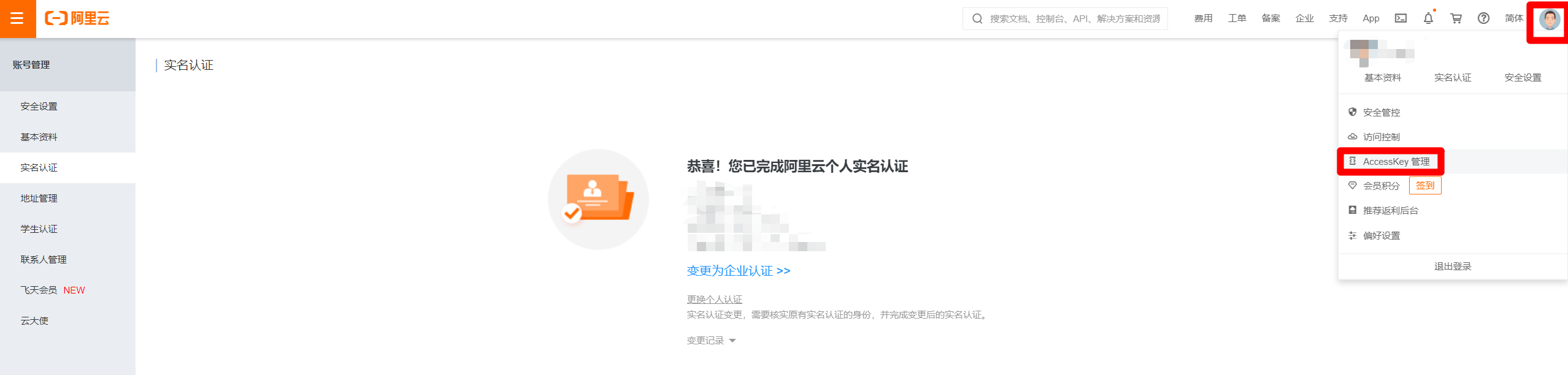
目前阿里云官方建议禁用主账号的AccessKey,使用RAM子用户AccessKey来进行API调用,因此点击"开始使用子用户AccesssKey",进入RAM访问控制页面,进行下一步:创建RAM子账号。
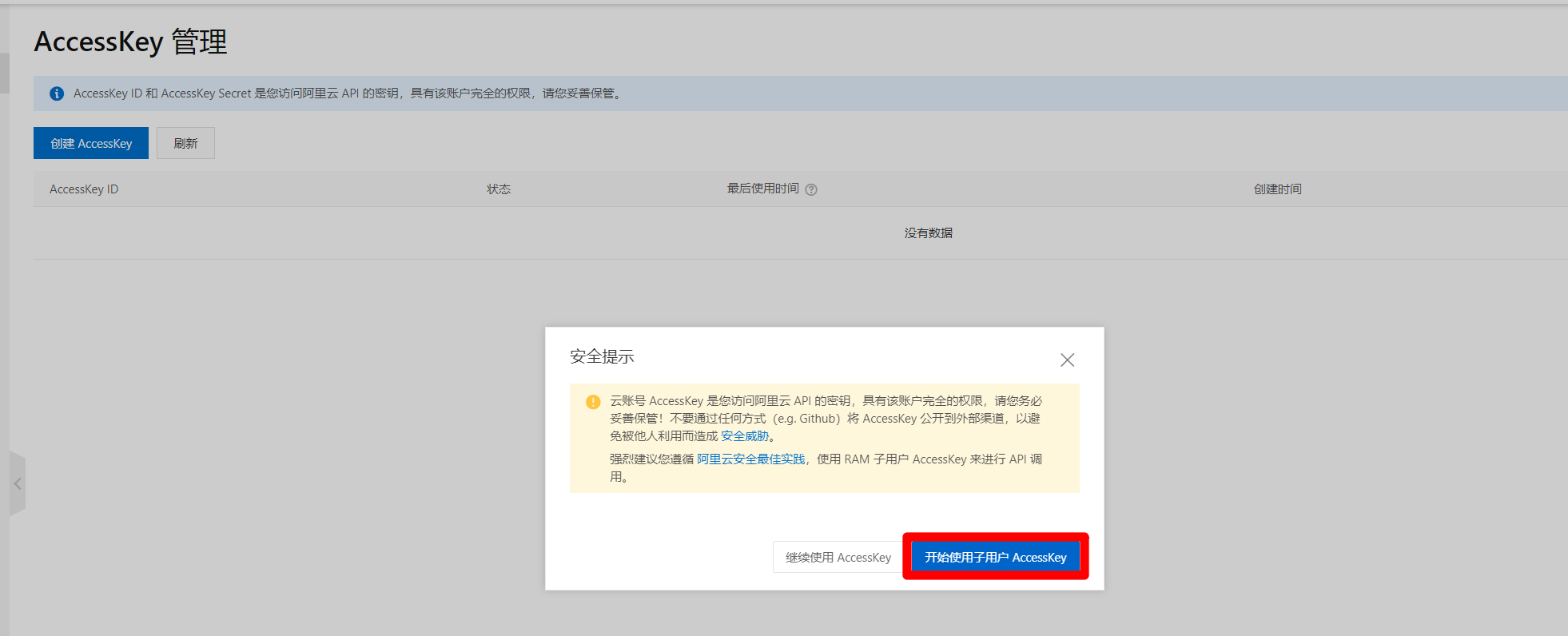
Ⅱ、创建RAM子账号
官方文档:准备RAM用户
步骤图示:
在RAM访问控制页面,点击"创建用户"按钮,进入创建用户页面。
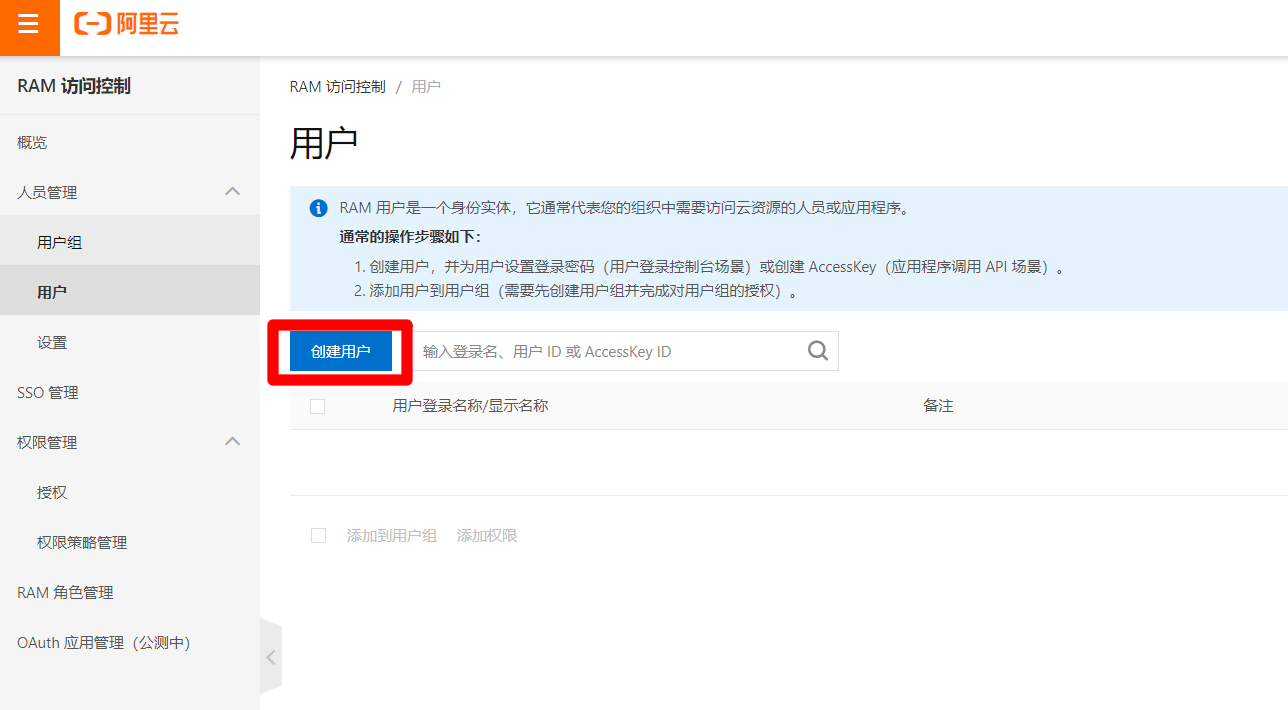
在创建用户页面,填写账户信息,勾选"控制台访问"与"编程访问",下面的密码选项根据需求自主选择,完成后点击"确定",创建成功后,及时保存AccessKey相关信息(下载CSV文件)。
选择RAM访问控制页面左侧菜单栏的"人员管理"中的"用户组"标签,在切换后的页面中点击"创建用户组",完善用户组信息后,点击"确定"按钮,完成用户组的创建。
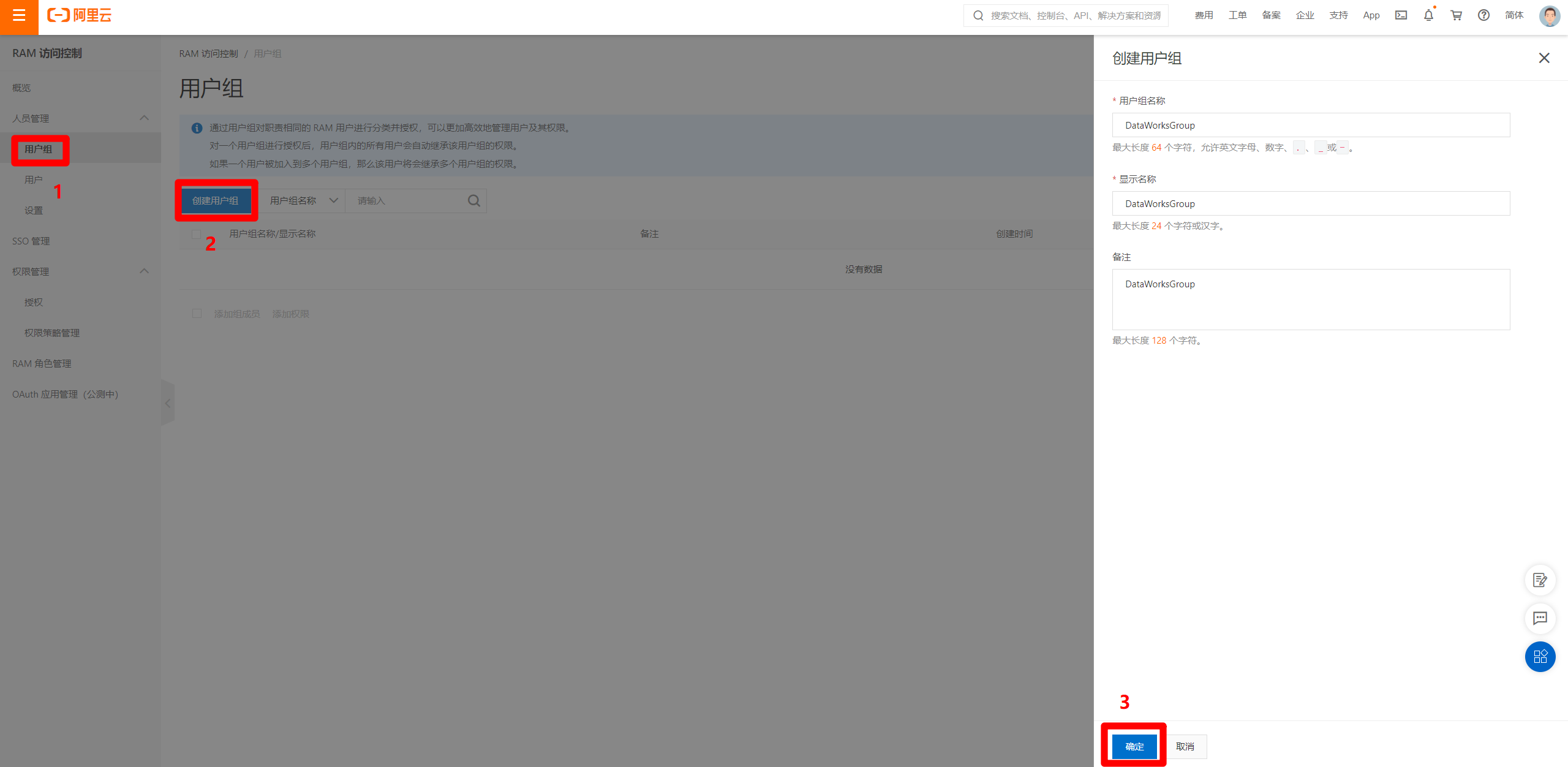
选中创建好的用户组,点击"添加组成员",在弹出的边栏中,选中刚才创建好的RAM用户,点击"确定",将RAM用户绑定到用户组。
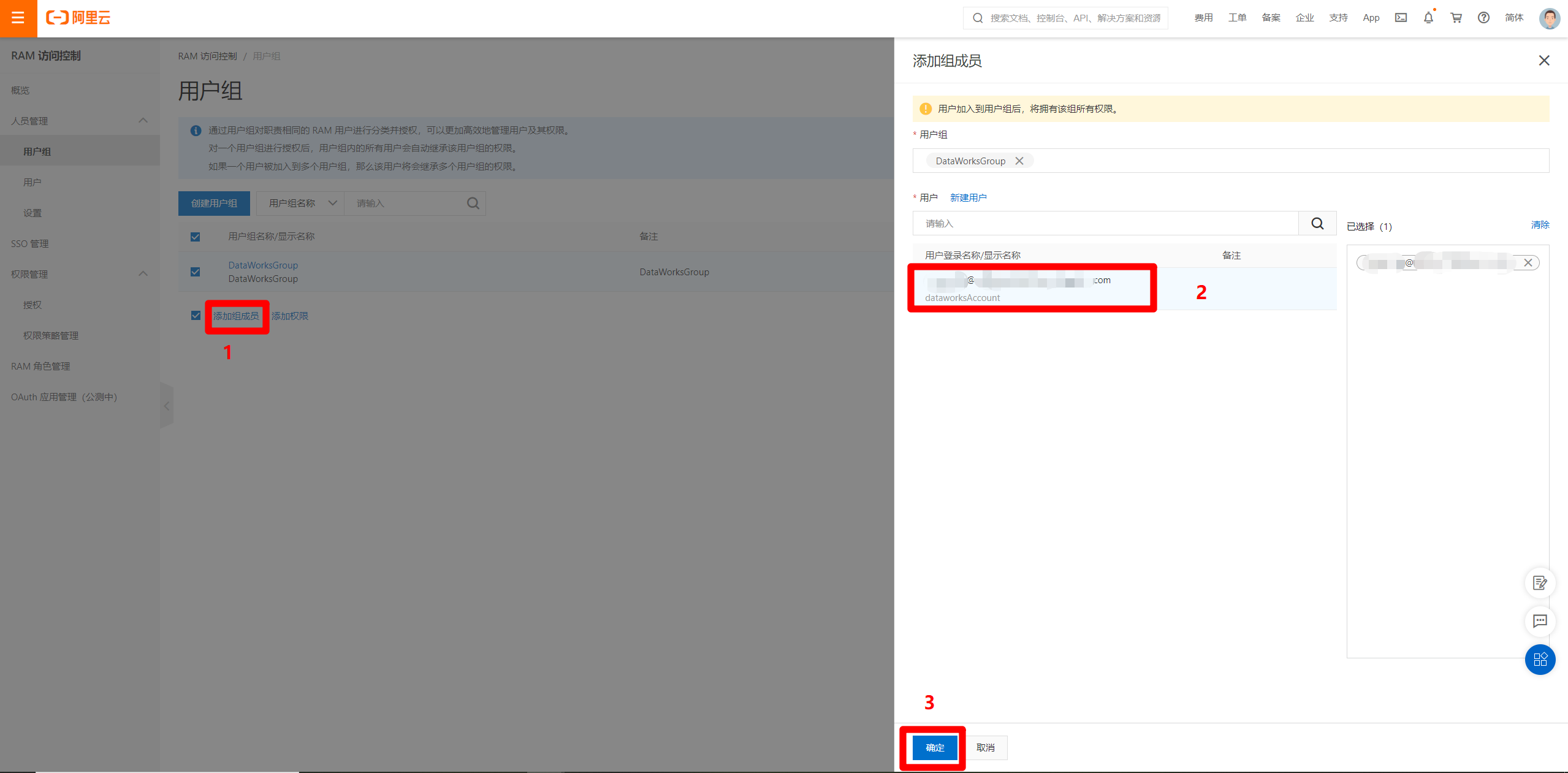
选中刚才的用户组,点击"添加权限",在弹出的边栏中,根据需求选择授权范围,然后选择权限添加。根据需求尽量选择小权限添加,当前先添加DataWorks使用权限,之后有别的权限需求再进行添加。选择好权限后,点击"确定"完成。
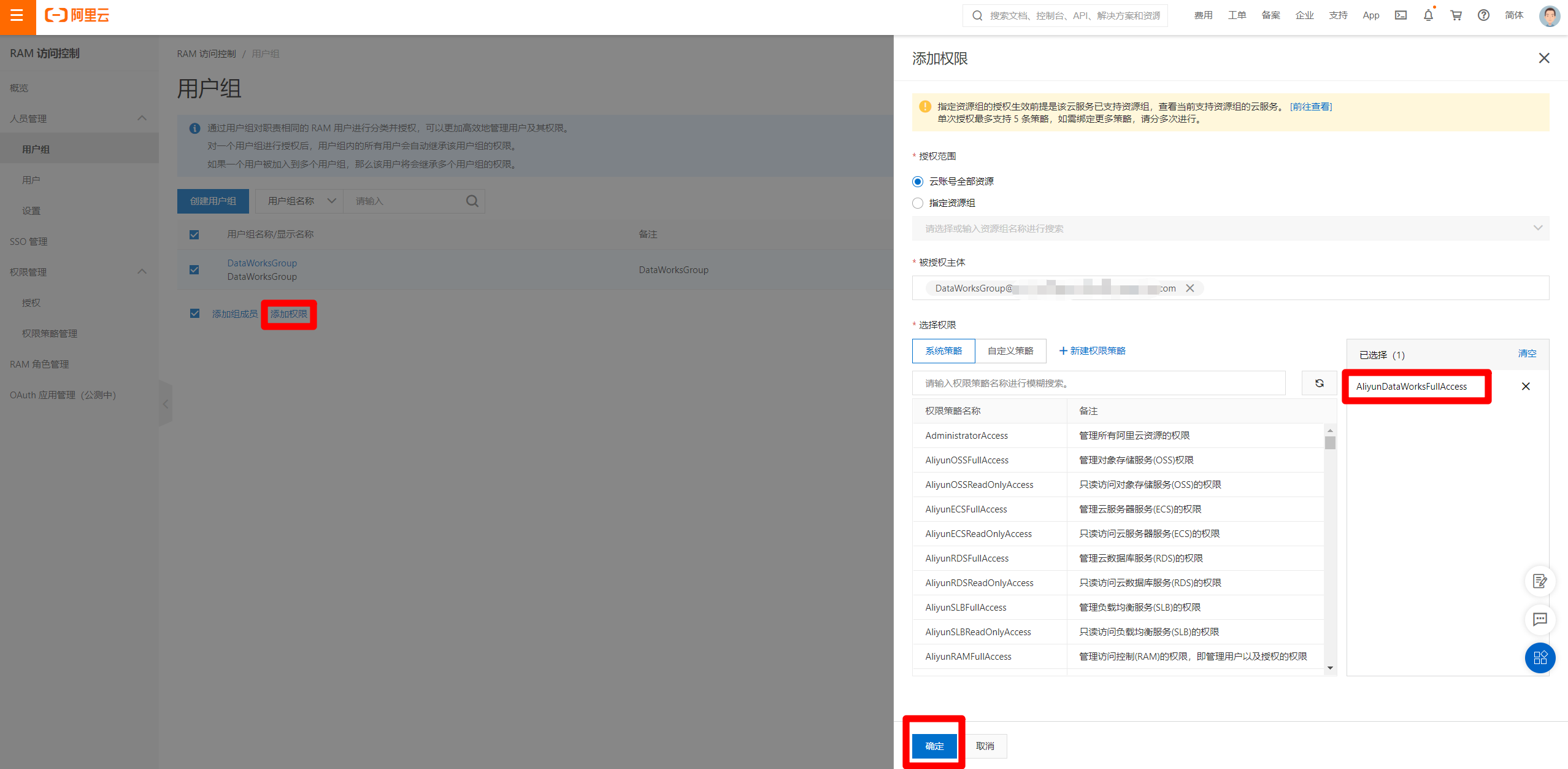
完成权限添加后,点击右上角"我的阿里云"图标,在出现账户信息边栏下方,点击退出登录,退出当前阿里云账号。
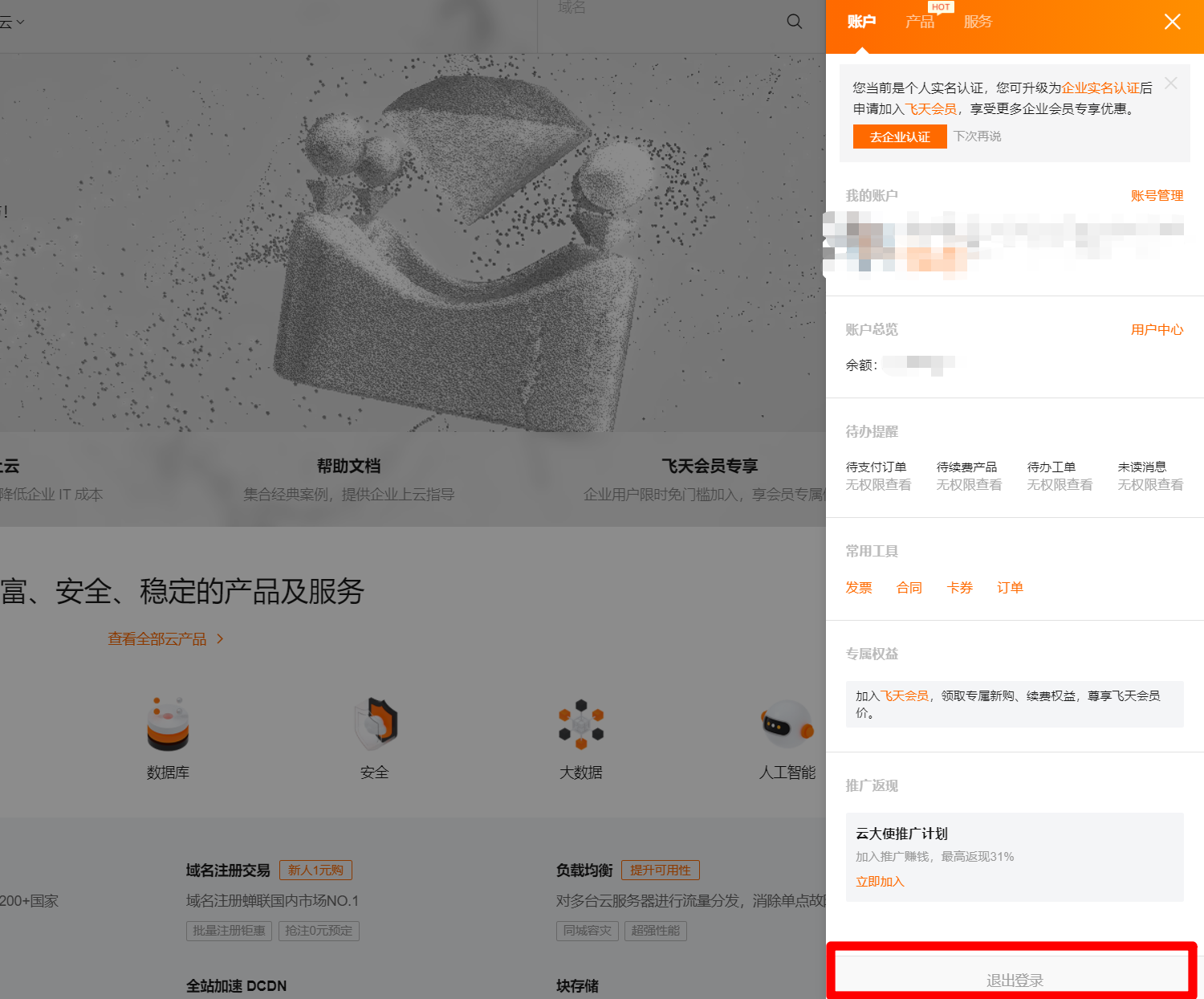
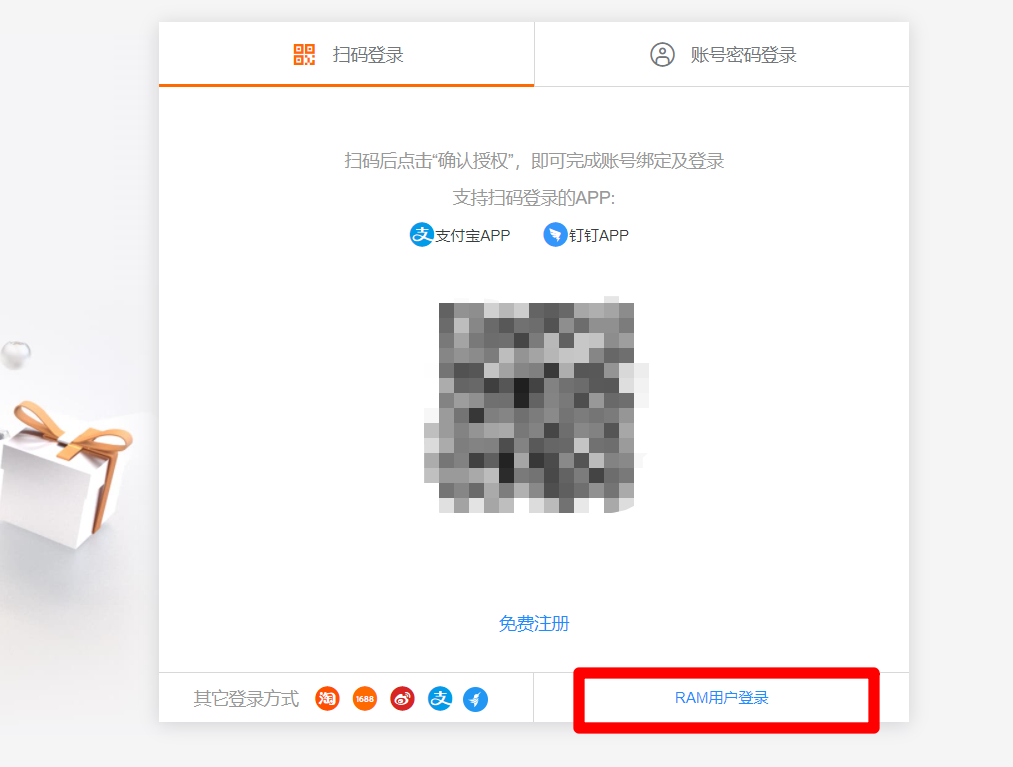
退出登录后,点击阿里云首页右上方"登录",在登录页面中点击"RAM用户登录",使用RAM账号进行登录。遵循阿里云安全最佳实践,之后均使用RAM账号进行DataWorks开发操作,在需要添加权限、购买阿里云产品等特殊情况时,再使用阿里云主账户进行操作(不同的浏览器可以分别登录不同账号)。
二、创建并配置工作空间
官方文档:创建工作空间
步骤图示:
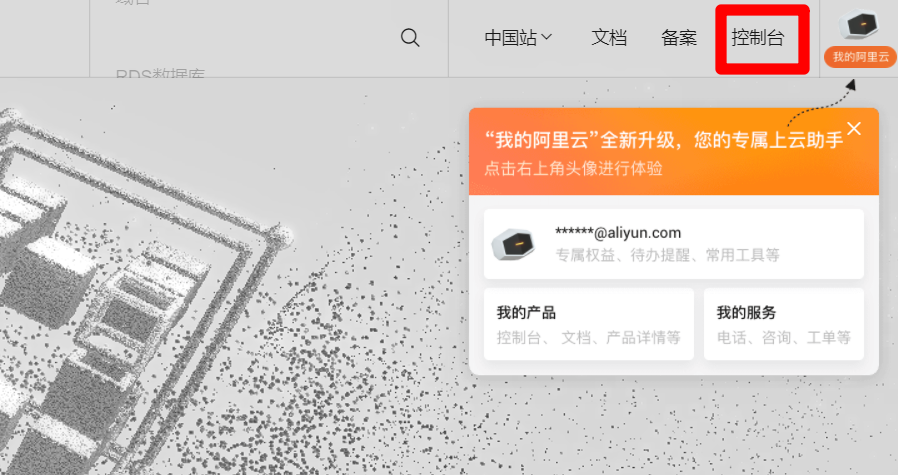
RAM账号登录成功后,在阿里云首页右上方点击"控制台",进入管理控制台页面。
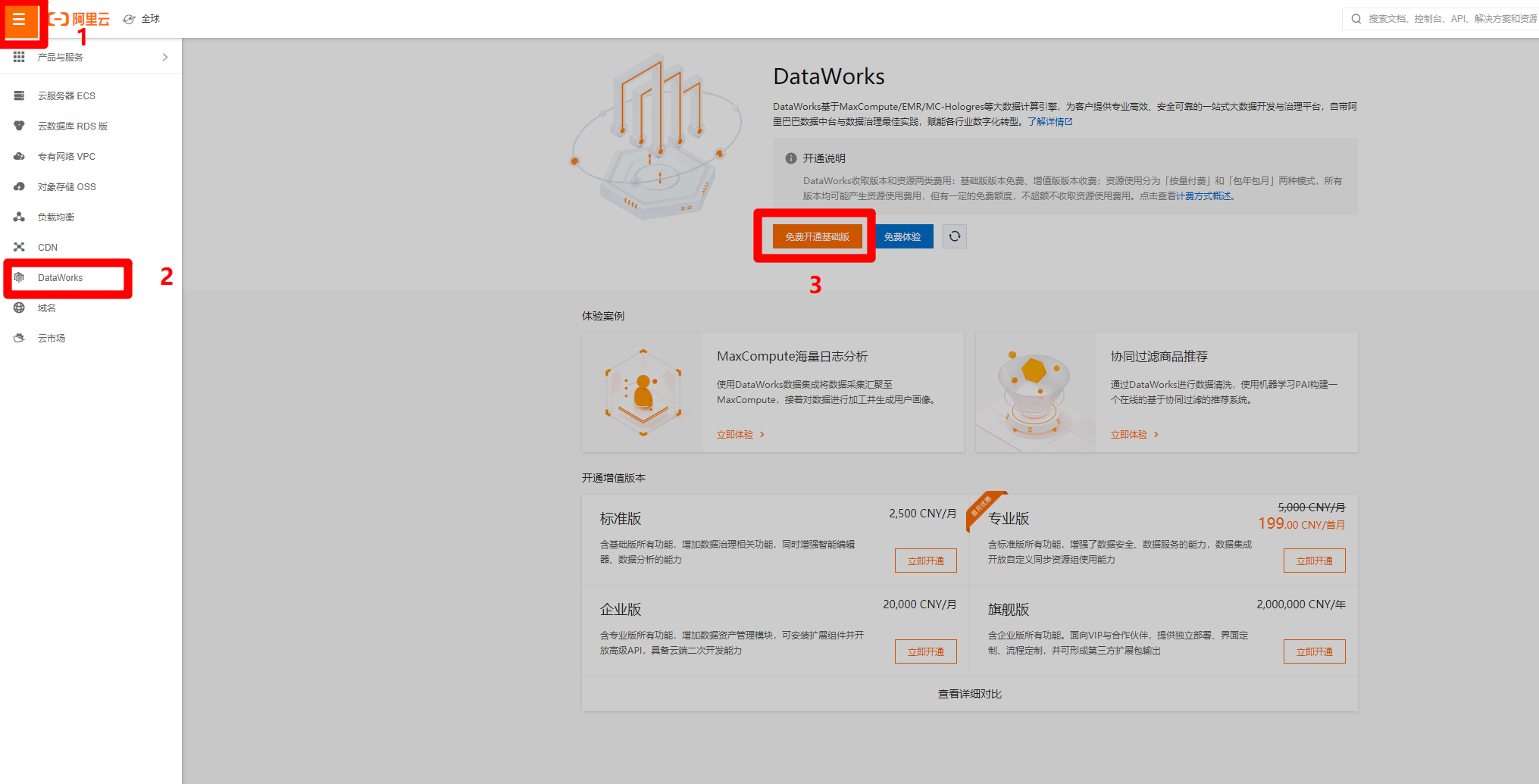
在管理控制台页面,点击左上角的菜单按钮,会出现侧边菜单栏,点击"DataWorks"标签,页面会切换到对应的DataWorks页面,点击"免费开通基础版",进入DataWorks购买页面,购买完成后要回到此页面。
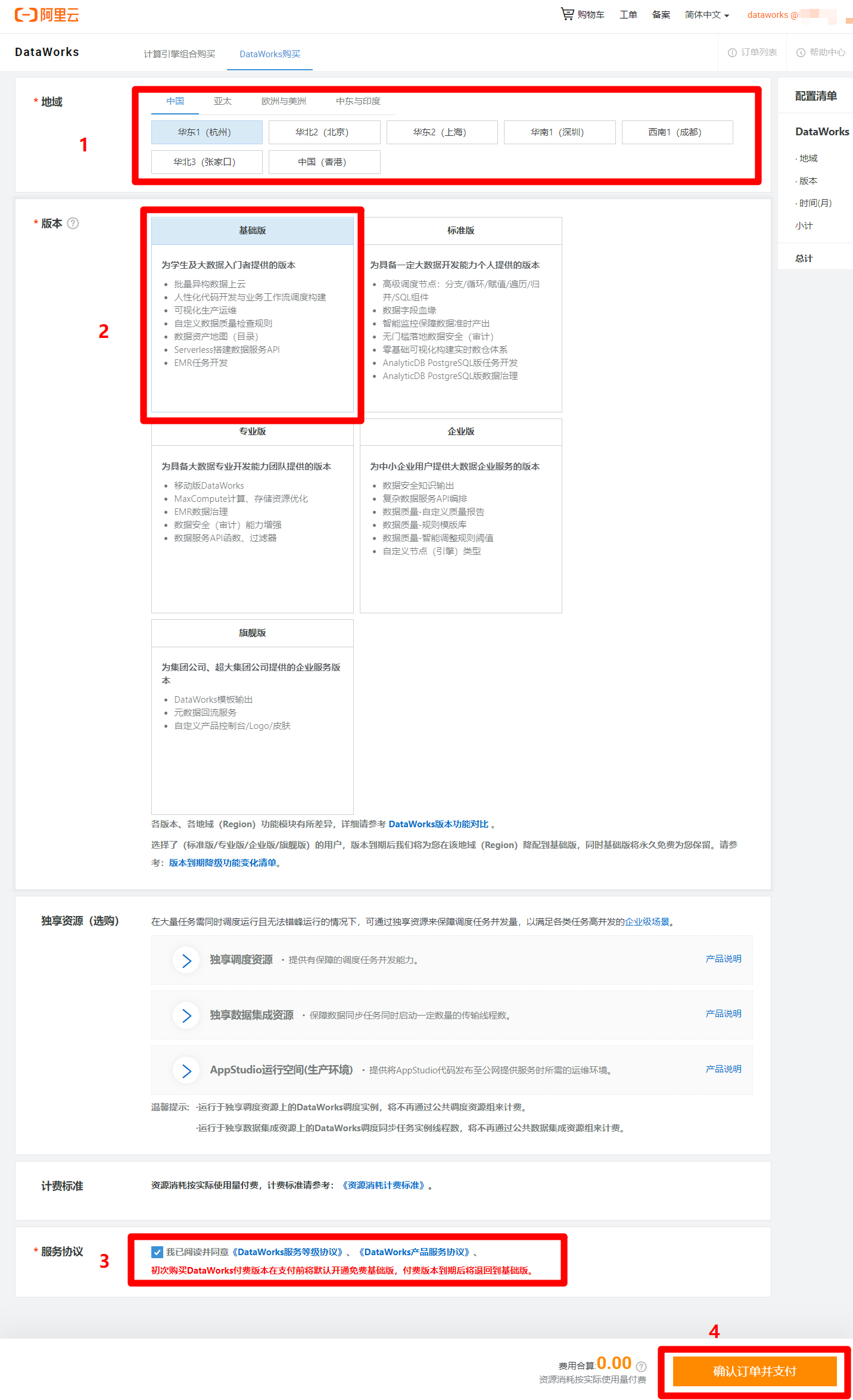
在DataWorks购买页面,根据自己需求选择地域(可以选择离自己最近的地域),版本选择基础版(其他版本需要付费)即可满足本次实践需求,然后勾选同意服务协议,点击"确认订单并支付",完成DataWorks基础版的开通。
完成DataWorks基础版的开通后,回到刚才的管理控制台页,重新点击"DataWorks"标签,可以进入新的DataWorks控制台页,点击左侧菜单栏的"工作空间列表",切换到工作空间列表页,点击"创建工作空间"按钮,准备创建一个新的工作空间。
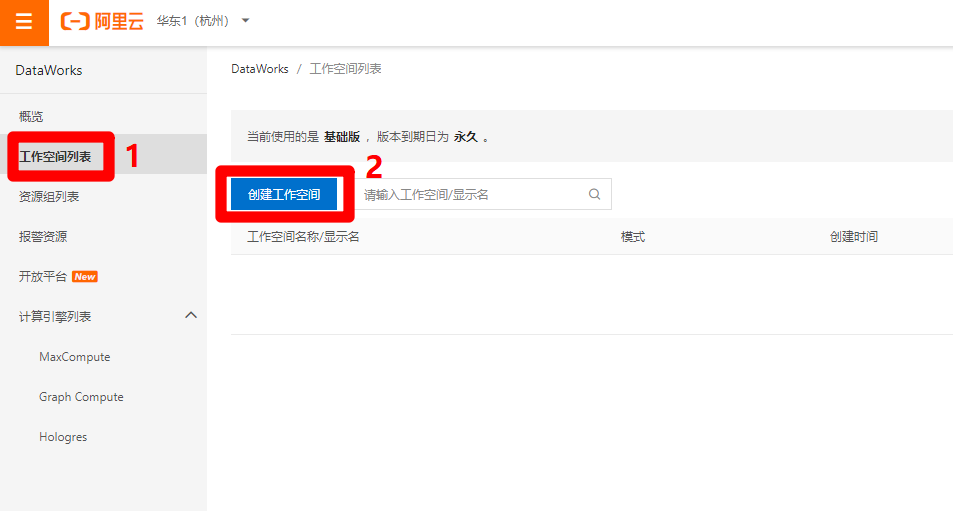
点击"创建工作空间"按钮后,页面右侧会弹出边栏,填写工作空间名称等信息,为简化操作流程,本次实践选择"简单模式"进行演示,完成后点击"下一步",将选择工作空间引擎。
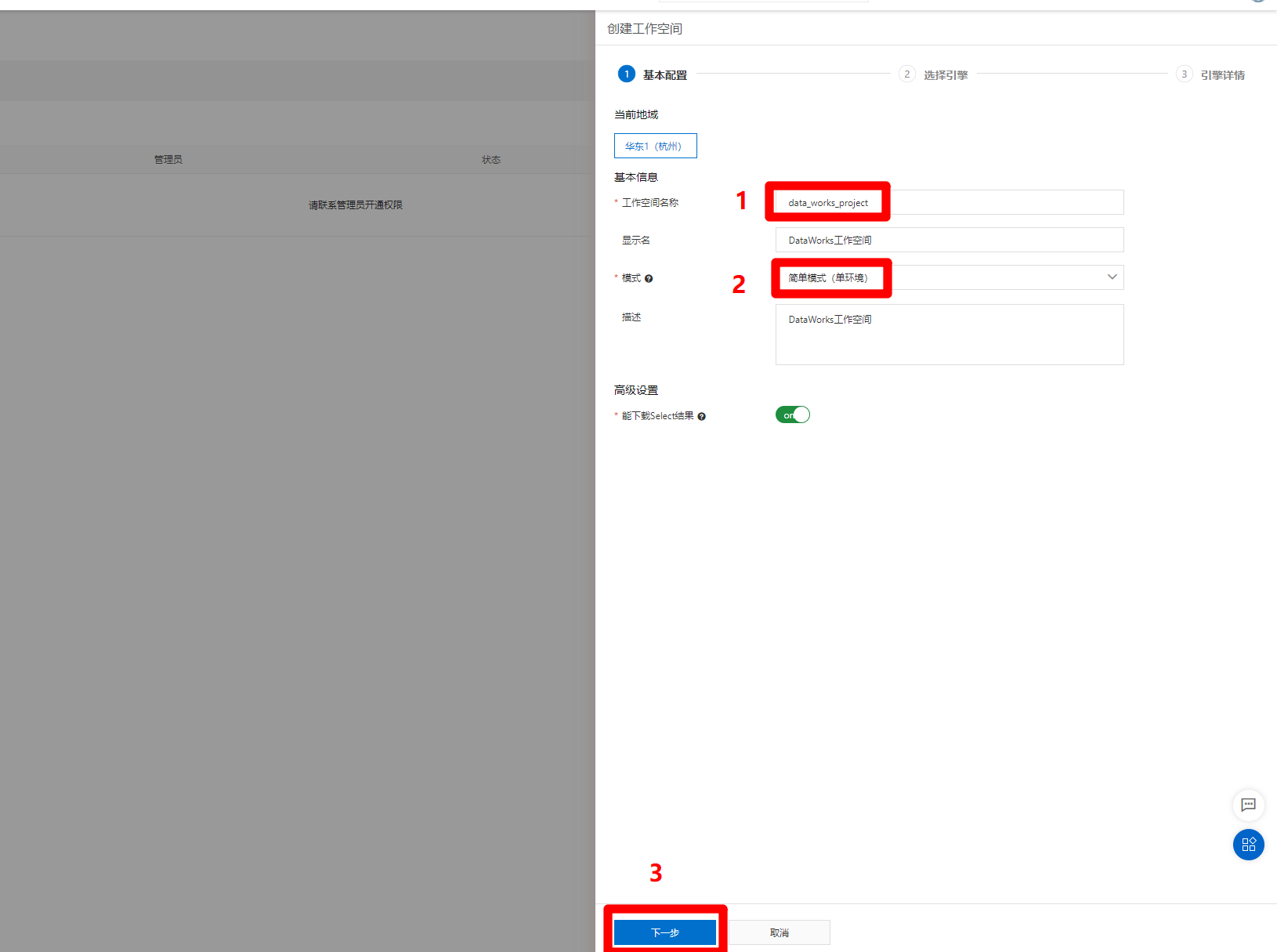
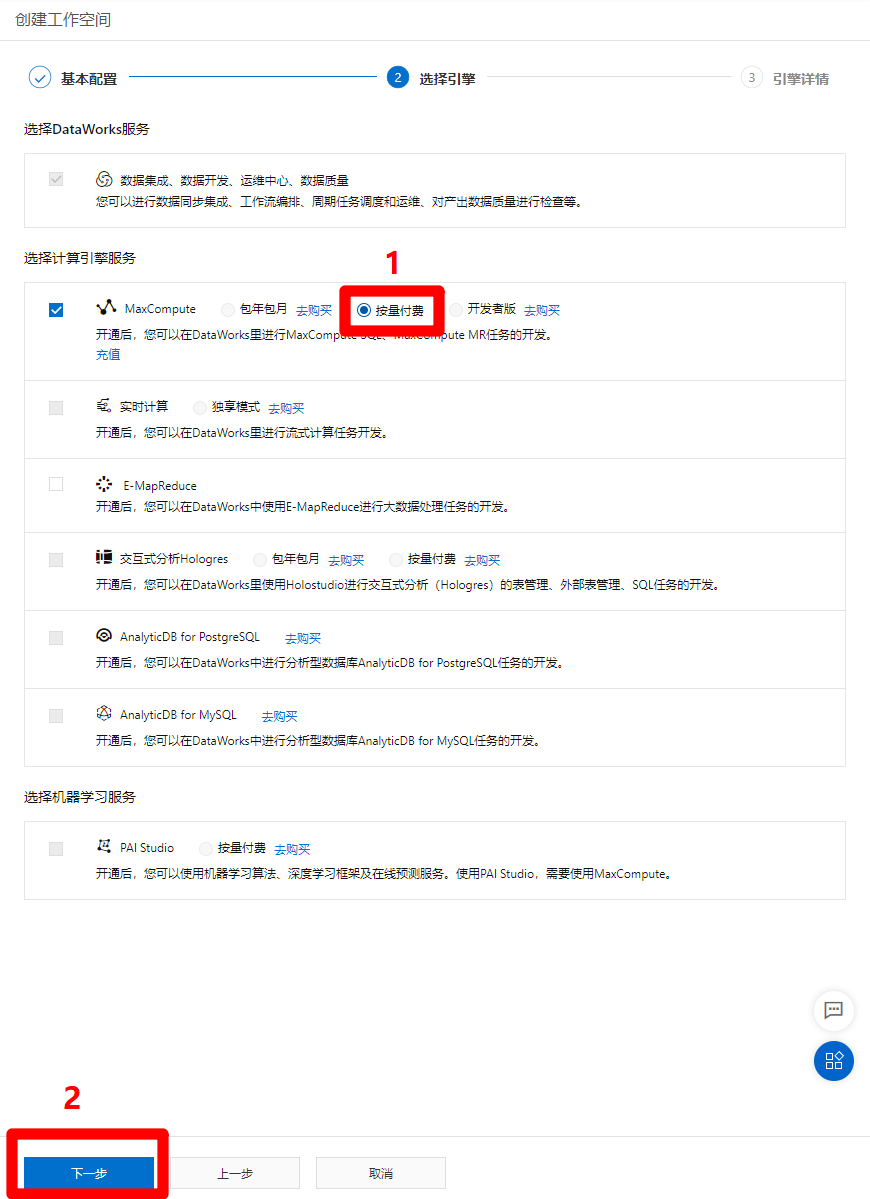
进入选择引擎页面,需要选择计算引擎服务为MaxCompute,此时还未开通MaxCompute服务,点击"MaxCompute"标签里的"按量付费"选项后的"去购买"链接,跳转到MaxCompute购买页面,购买完成后要回到此页面。
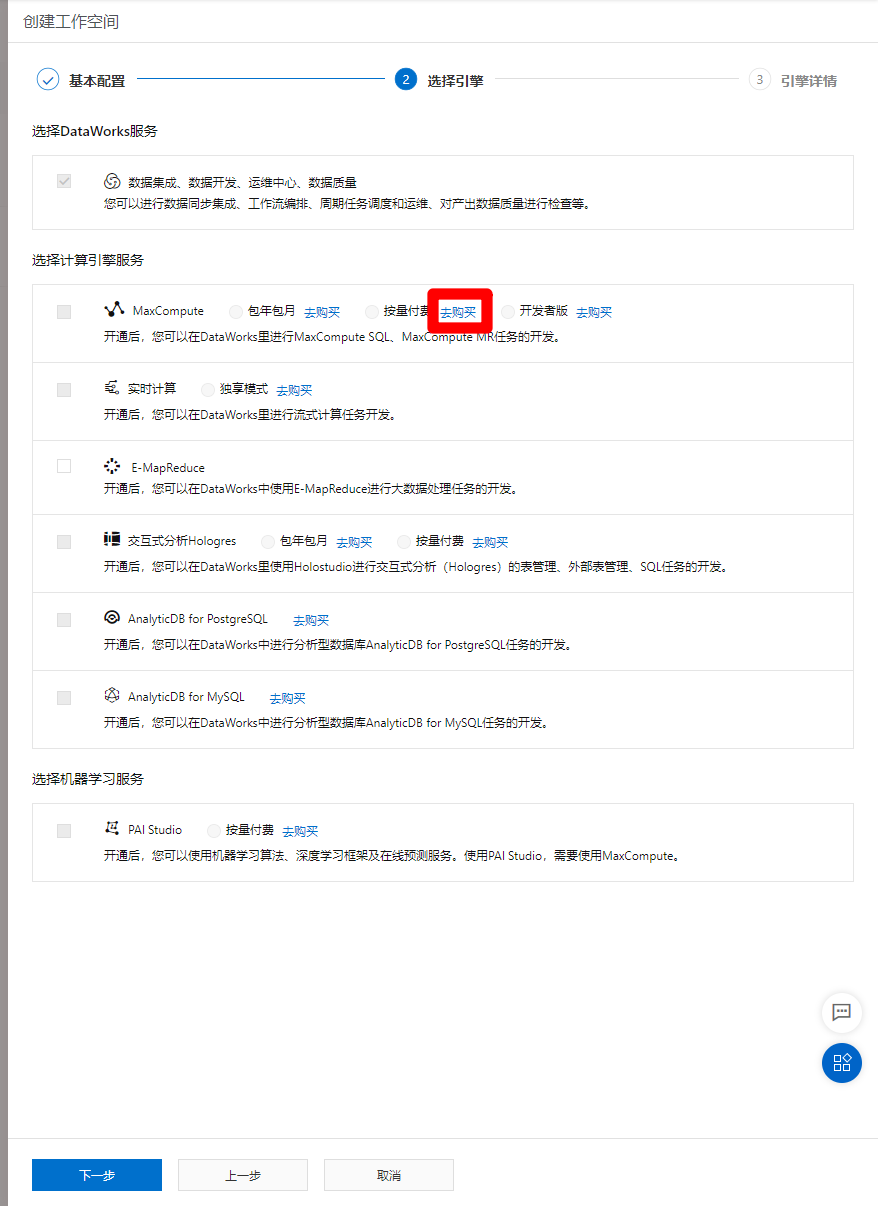
进入MaxCompute购买页面,商品类型选择"按量计费",区域根据自己的需求选择,规格类型选择"标准版",然后点击"立即购买",完成MaxCompute服务的激活。
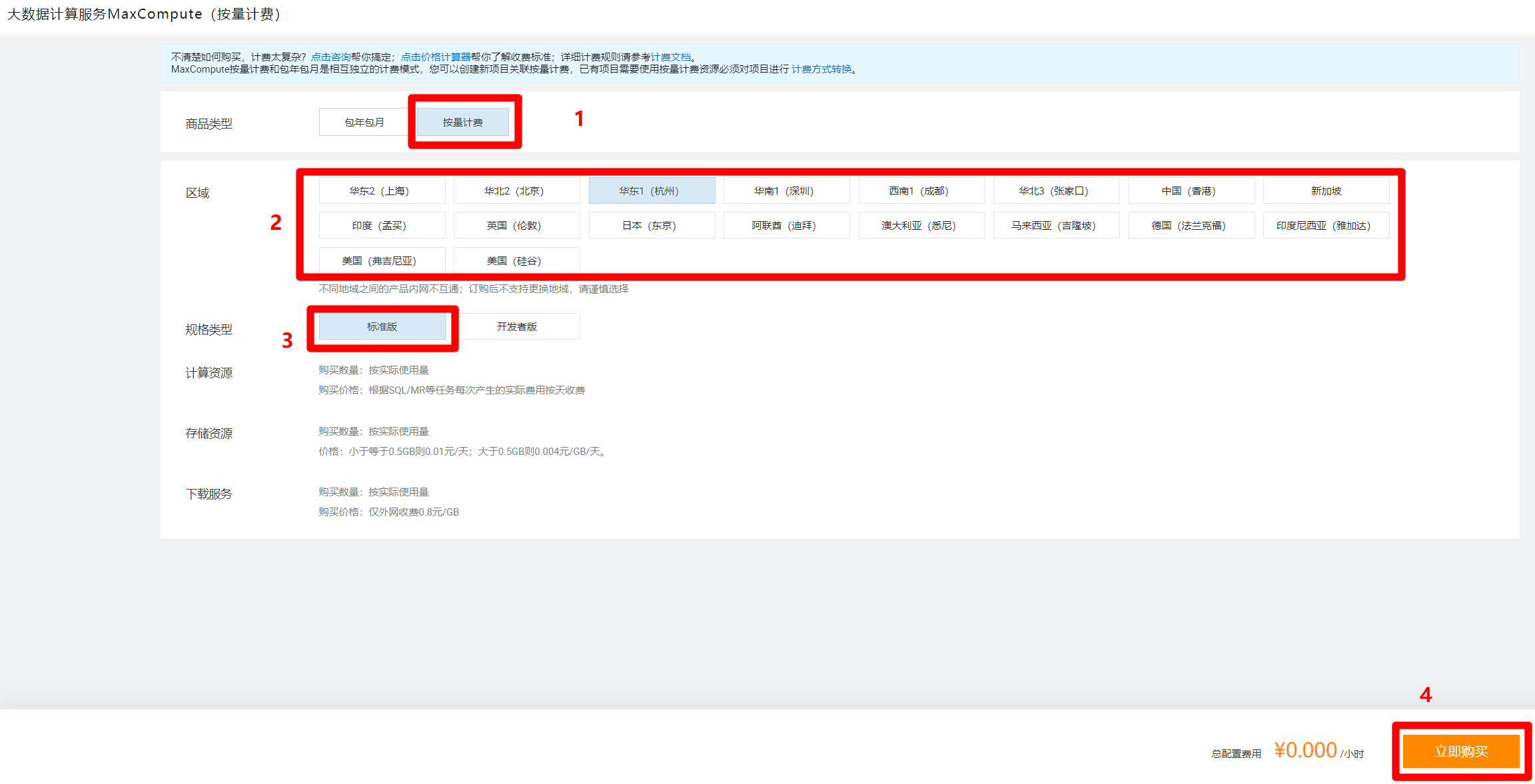
MaxCompute服务激活后,回到创建工作空间的选择引擎页面,选中"MaxCompute"标签里的"按量付费"选项(若页面没有刷新,无法选中,点一下"上一步",再点一下"下一步"来刷新页面),然后点击"下一步",准备配置引擎详情。
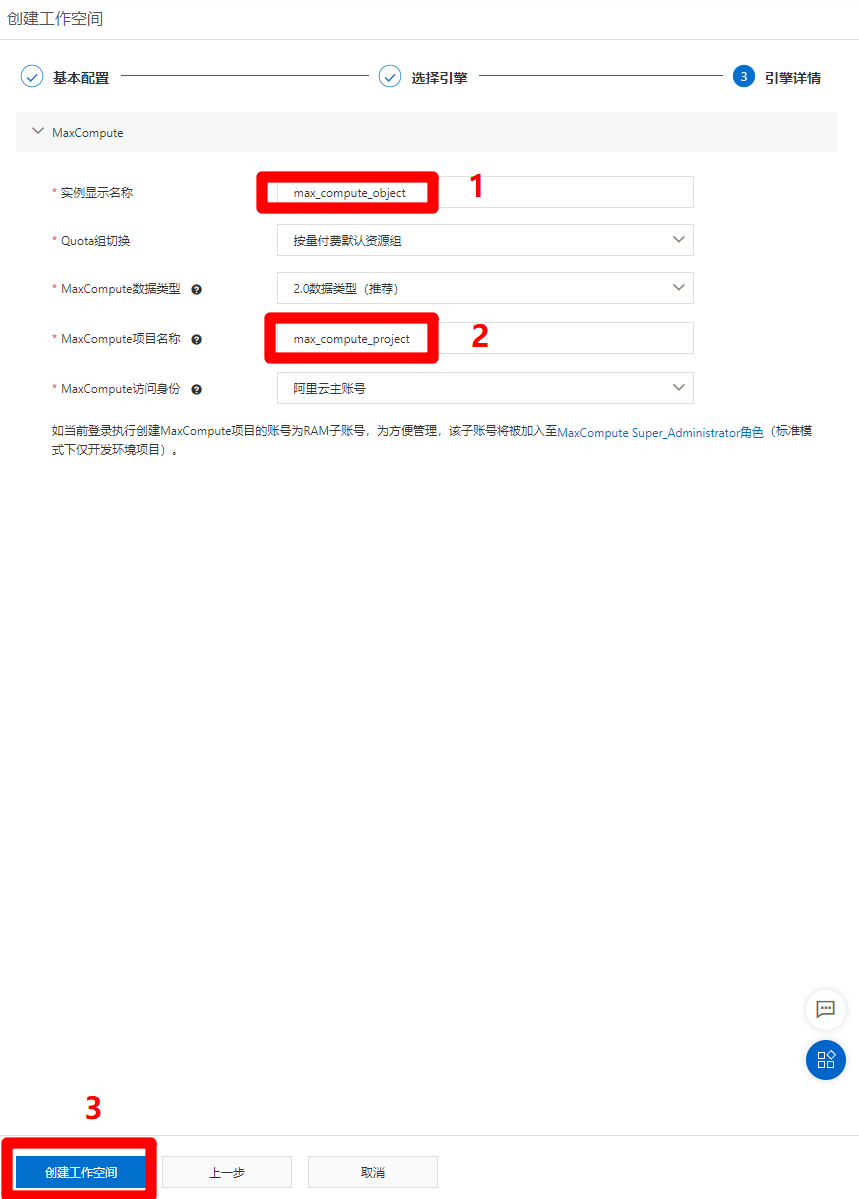
进入引擎详情页面,自主填写实例显示名称和MaxCompute项目名称,其他配置选项保持默认即可,然后点击"创建工作空间",完成工作空间的创建。
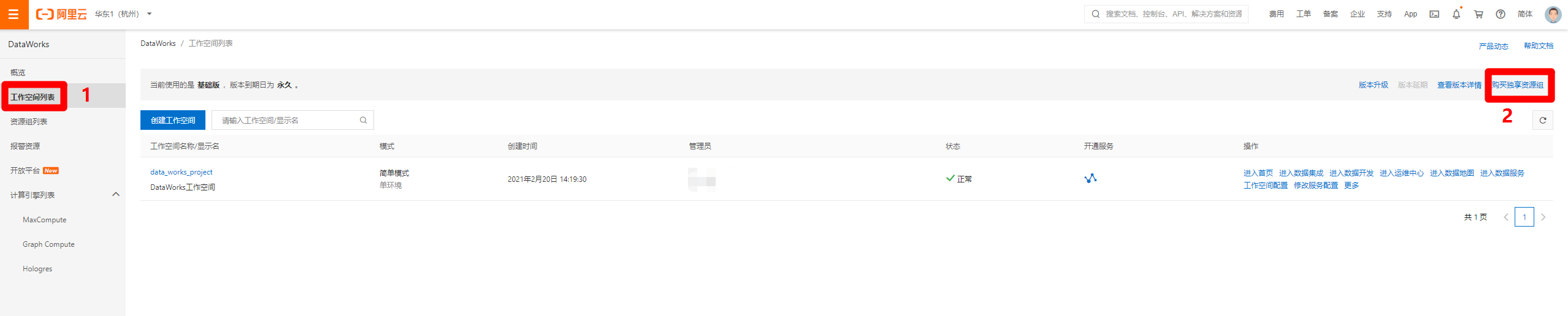
三、购买独享数据集成资源组并绑定
注意:由于本人在其他业务流程中使用了数据集成中"一键实时同步至MaxCompute的功能"(不支持MongoDB数据源),而实时同步功能仅支持运行在独享数据集成资源组上,因此购买了独享数据集成资源组。而本次实践中也就使用了之前购买的独享数据集成资源组(不用白不用)。而本次实践由于只使用了离线同步功能,也可使用公共资源组(免费)进行数据集成,如要使用公共资源组,可跳过此步骤。
官方文档:新增和使用独享数据集成资源组
步骤图示:
进入DataWorks控制台页面,在左侧菜单栏切换到"工作空间列表"页面,点击页面右上角的"购买独享资源组",打开DataWorks独享资源购买页面。
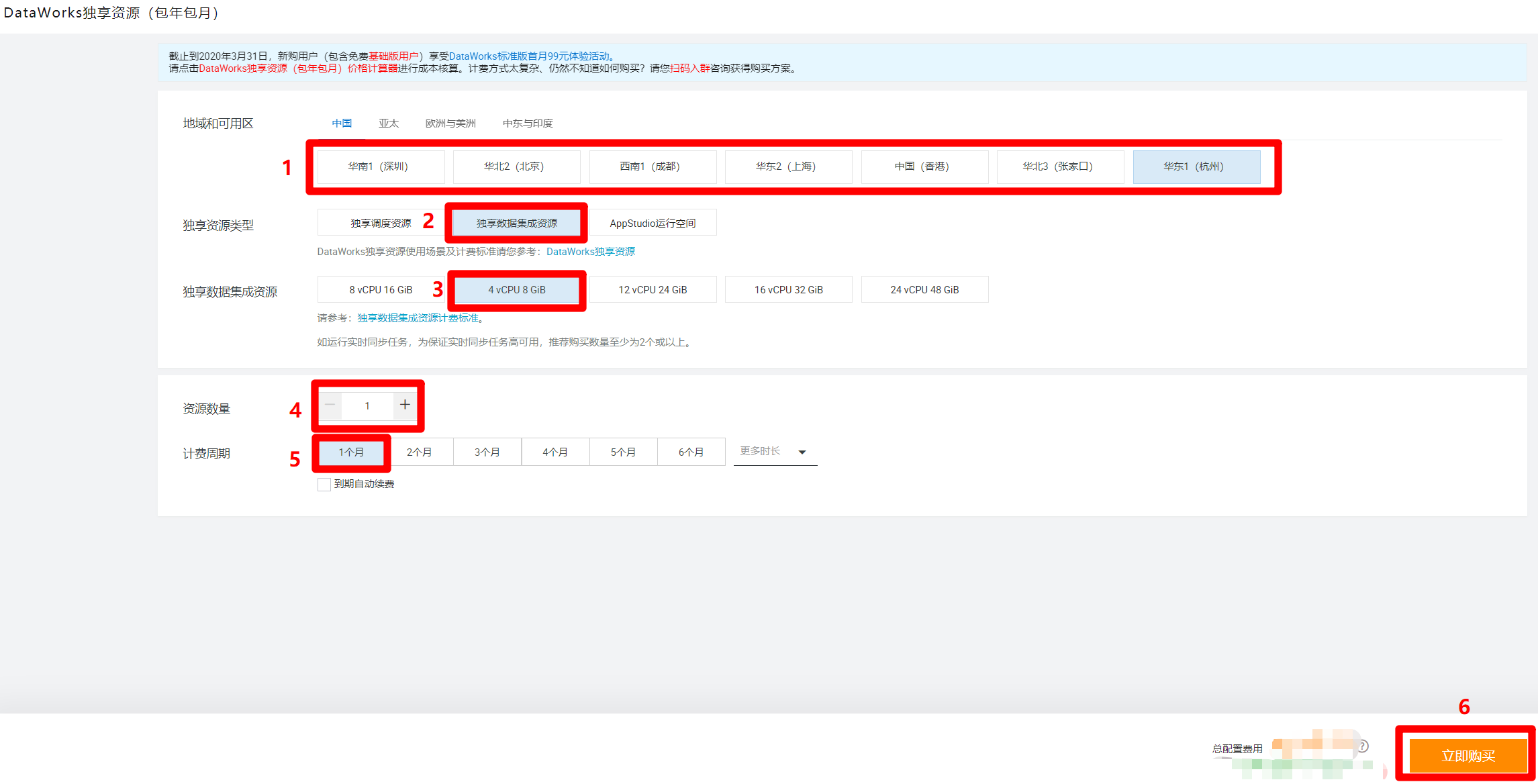
进入DataWorks独享资源购买页面,根据自己的需求选择地域和可用区(要与工作空间所在的地域相同),独享资源类型选择"独享数据集成资源",本次实践只需购买最低限度的独享集成资源,因此下面选项依次选择"4 vCPU 8 GiB"、"1"、"1个月",然后点击"立即购买",完成独享数据集成资源的购买。
完成独享数据集成资源组的购买后,进入DataWorks控制台页面,在左侧菜单栏切换到"资源组列表"页面,然后点击"创建独享资源组",会出现右侧边栏。资源组类型选择"独享数据集成资源组",资源组名称自主填写,资源组备注自主填写,订单号选择刚才购买的独享数据集成资源的订单号,然后点击"确定",完成独享数据集成资源组的创建。
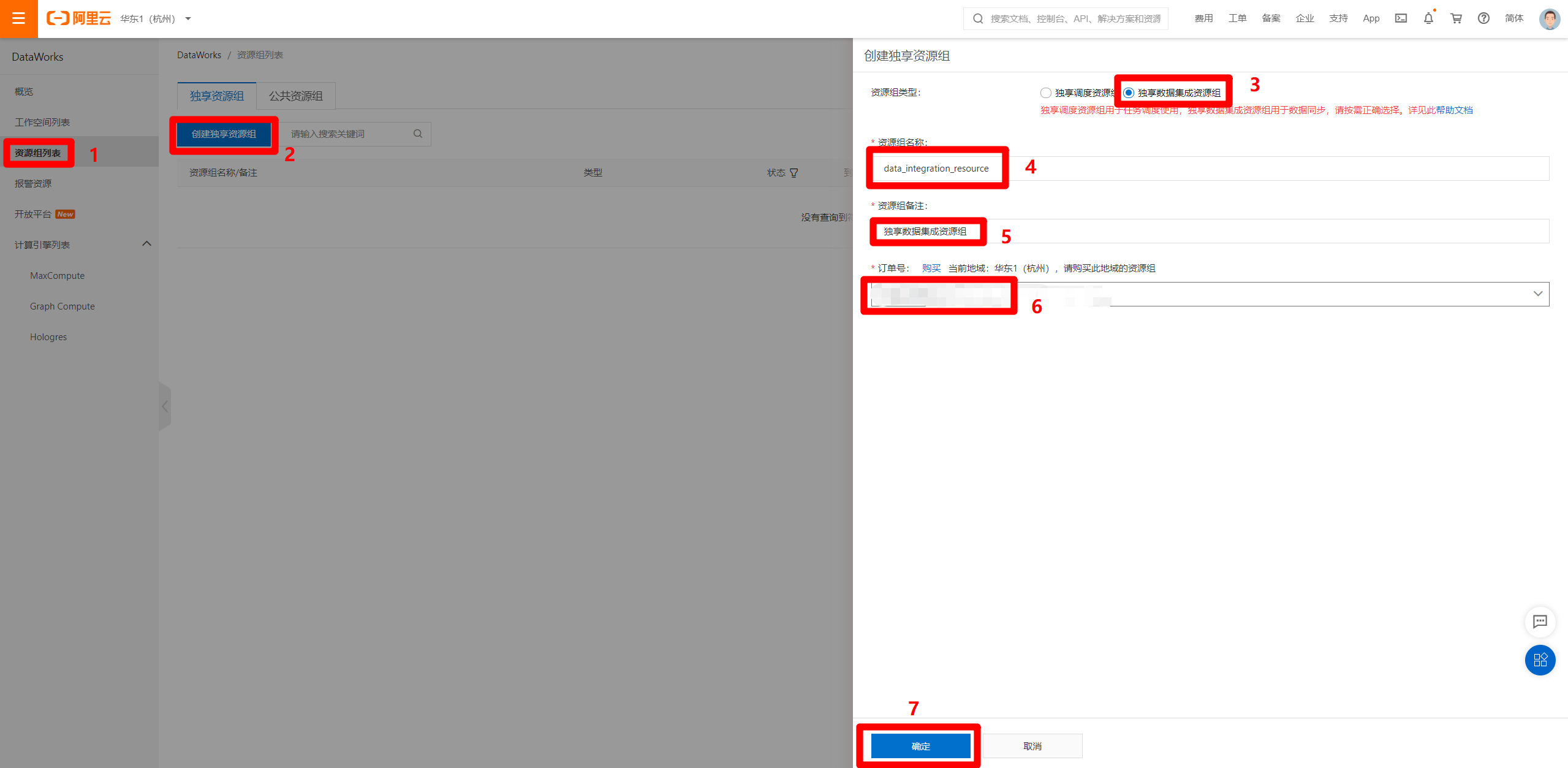
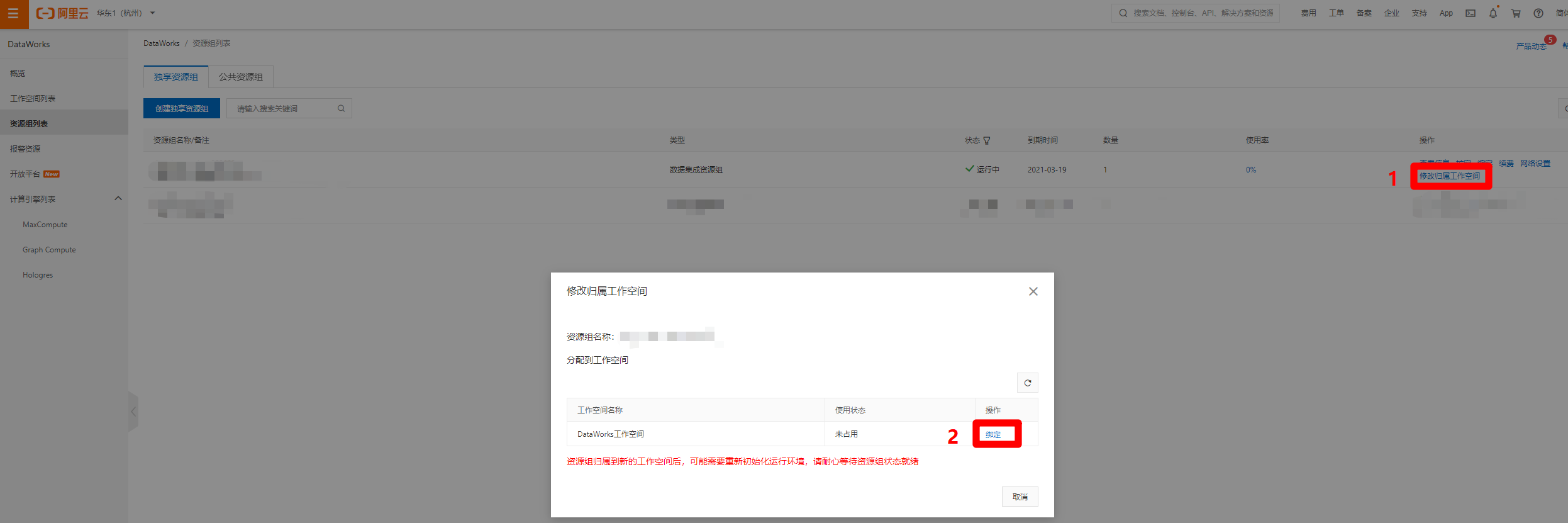
创建好独享数据集成资源组后,在资源组列表页面中,点击刚创建完成的资源组右端的"修改归属工作空间"链接,会出现修改归属工作空间的弹出框,选择刚才创建的工作空间,点击右端对应的"绑定",完成独享数据集成资源组与工作空间的绑定。
四、创建并配置数据源
官方文档:配置数据源
步骤图示:
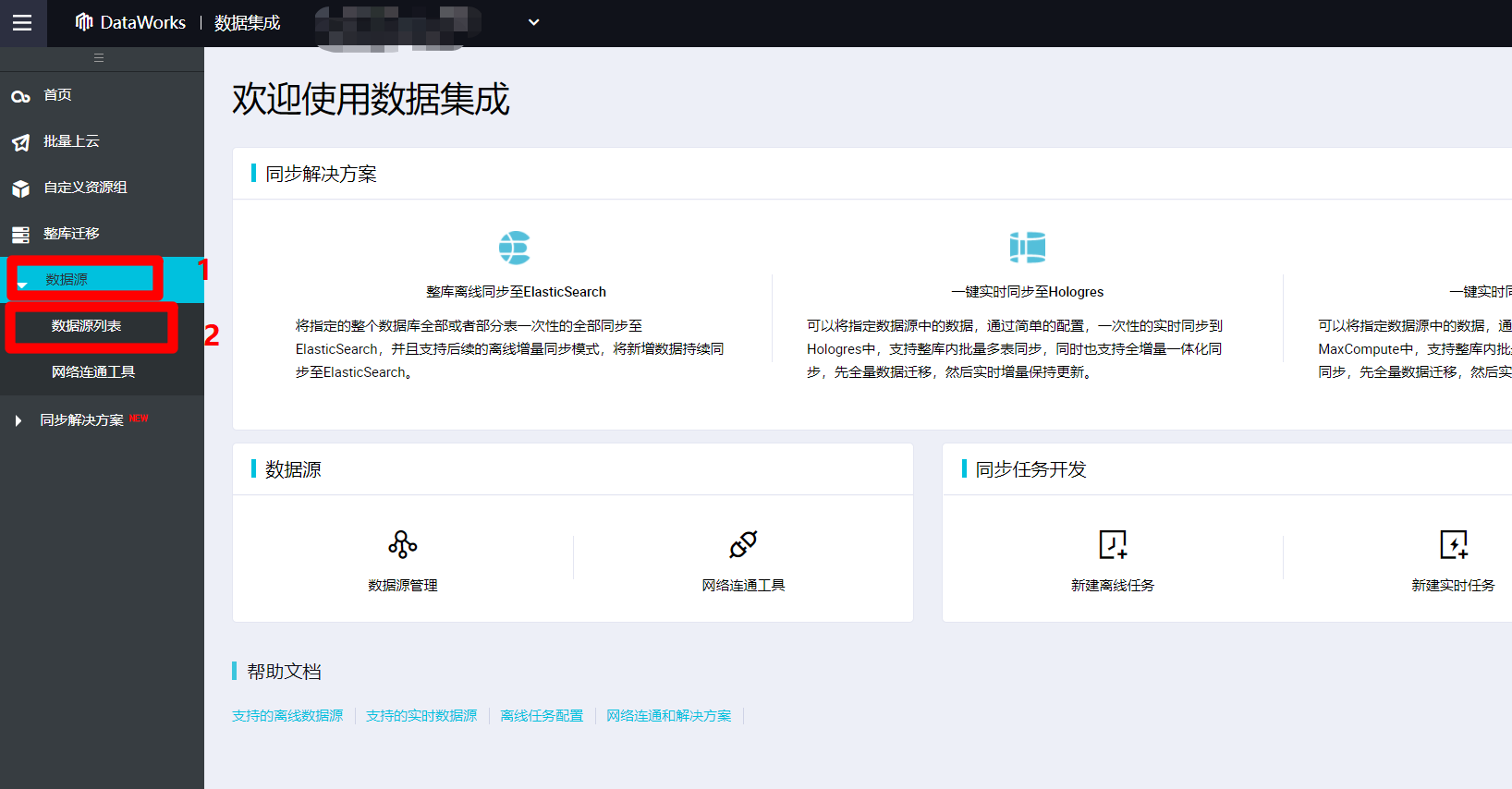
在DataWorks控制台的工作空间列表页面中,点击目标工作空间右端"操作"列中的"进入数据集成"链接,打开数据集成页面。

进入数据集成页面中,点击展开左侧菜单栏中的"数据源"项,在其展开的子菜单中,点击"数据源列表",打开数据源管理页面。
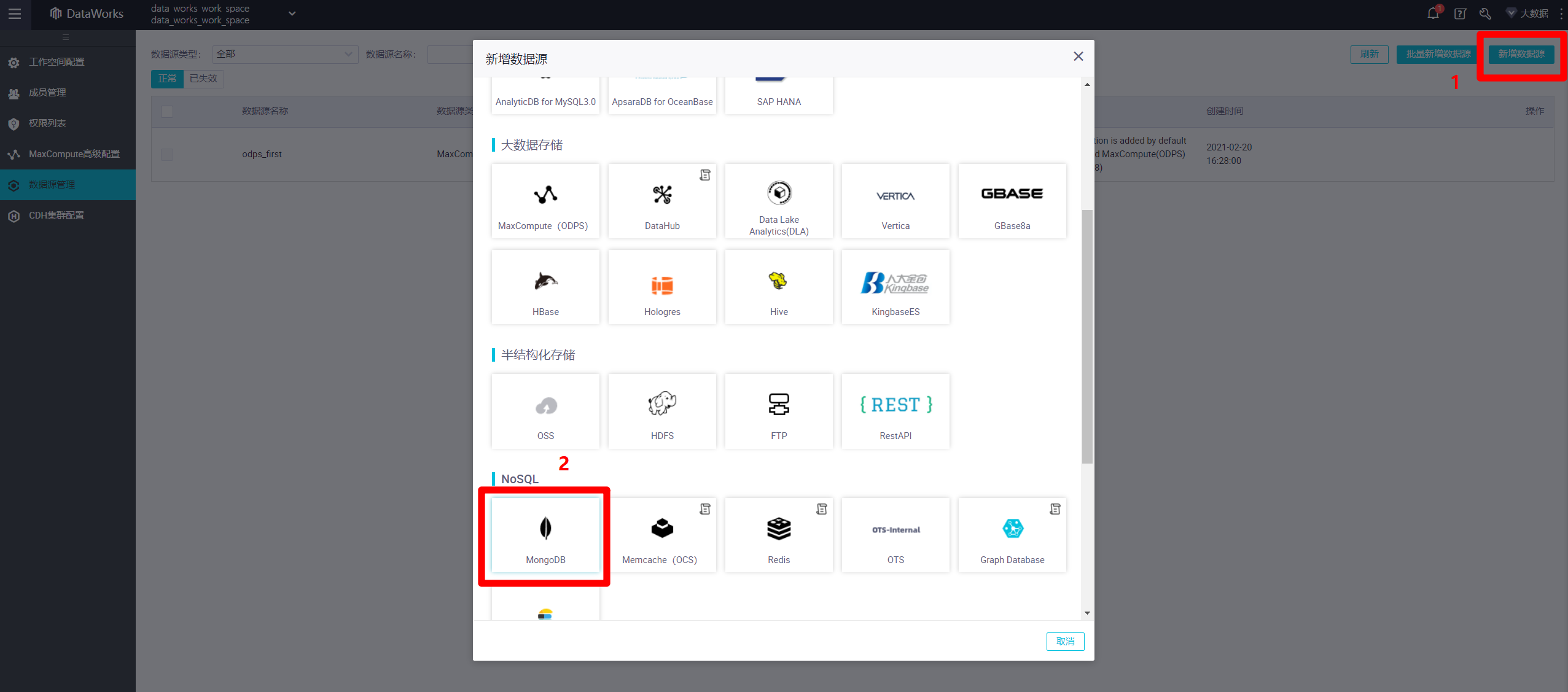
进入数据源管理页面中,点击页面右上角的"新增数据源",会出现新增数据源的弹出框。本次实践的目标数据源为MongoDB数据库,因此在弹出框中找到"NoSQL"标签下"MongoDB"图标,点击该图标,会出现新的"新增MongoDB数据源"弹出框。
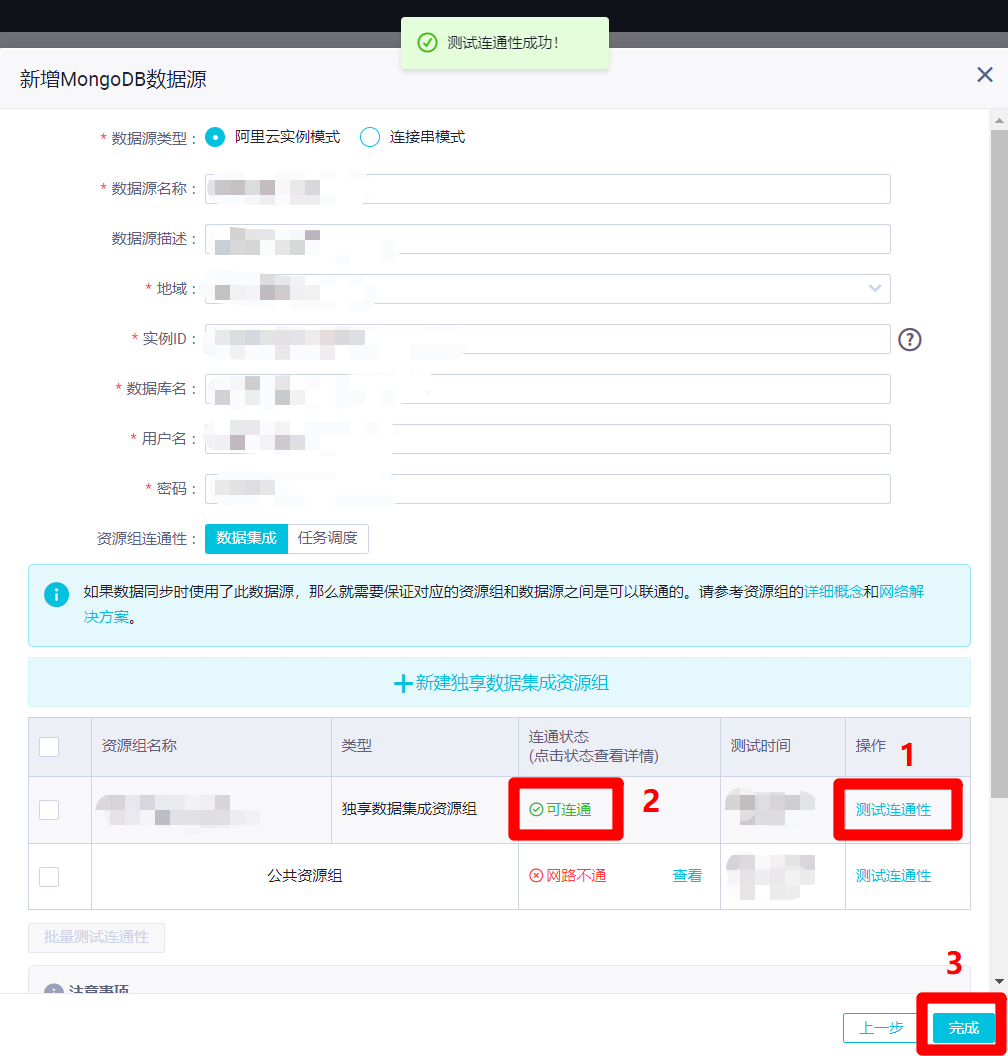
在新增MongoDB数据源的弹出框中,需要填写数据源相关信息。本次实践的MongoDB数据源为阿里云云数据库MongoDB版,所以数据源类型选择"阿里云实例模式",自主填写数据源名称和数据源描述,地域选择数据源所在地域,实例ID填写数据源的实例ID(通过后面的问号图标,可进入MongoDB管理控制台的实例列表,复制"实例ID"填写),自主填写正确的数据库名、用户名、密码。然后点击下面表格中"独享数据集成资源组"这一行的"测试连通性",此时会连通失败,需要添加独享数据集成资源绑定的交换机网段至数据库的白名单内(若使用的是公共资源组,则需要添加DataWorks工作空间所在区域的白名单IP至数据库的白名单内)。因此下一步要打开DataWorks控制台的"资源组列表"页面去找到相关信息。
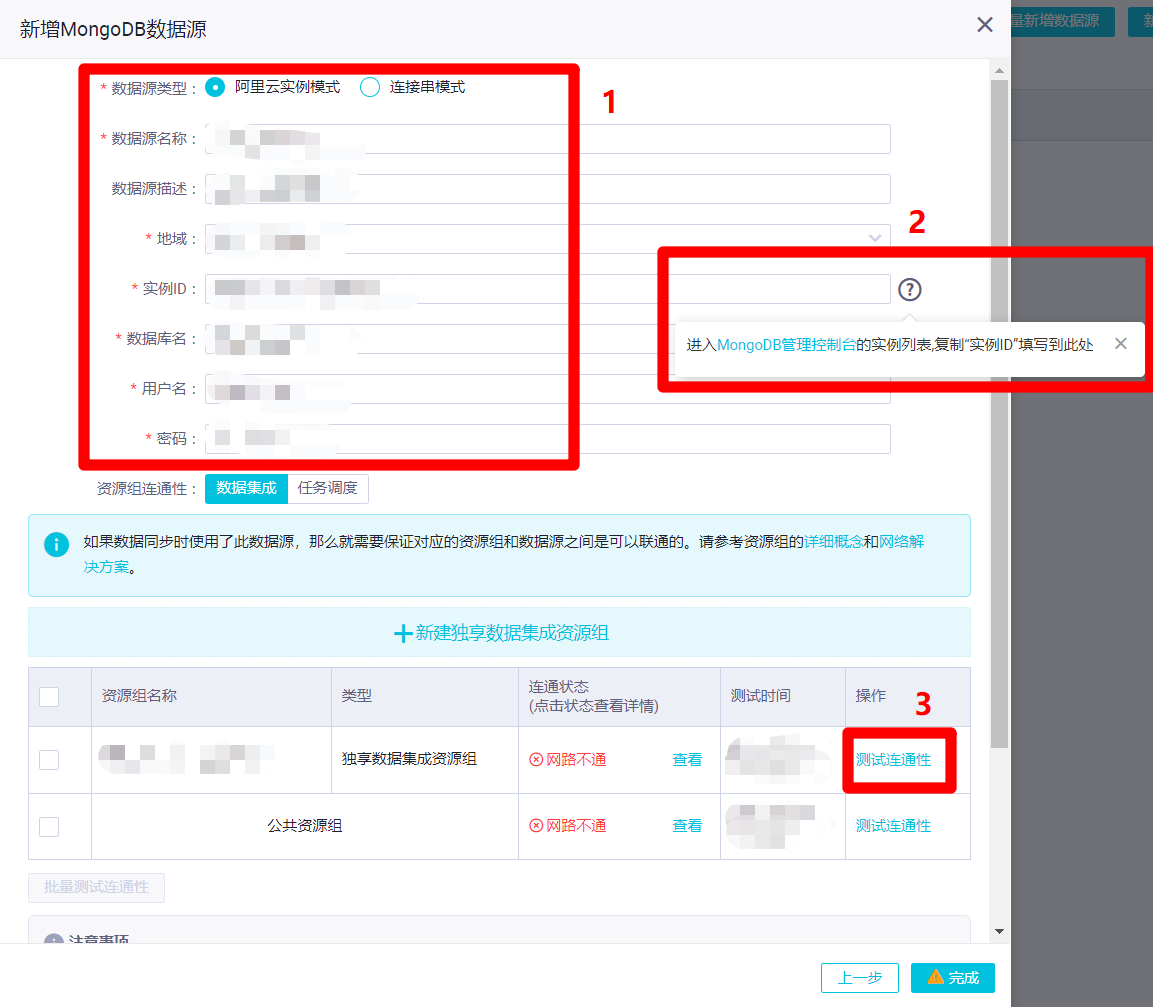
进入"资源组列表"页面中,点击目标独享数据集成资源组的"操作"列中的"查看信息"链接,会出现"独享资源组"的弹出框,复制"EIP地址"和"网段"的内容,下一步打开MongoDB管理控制台,准备添加数据库的IP白名单。
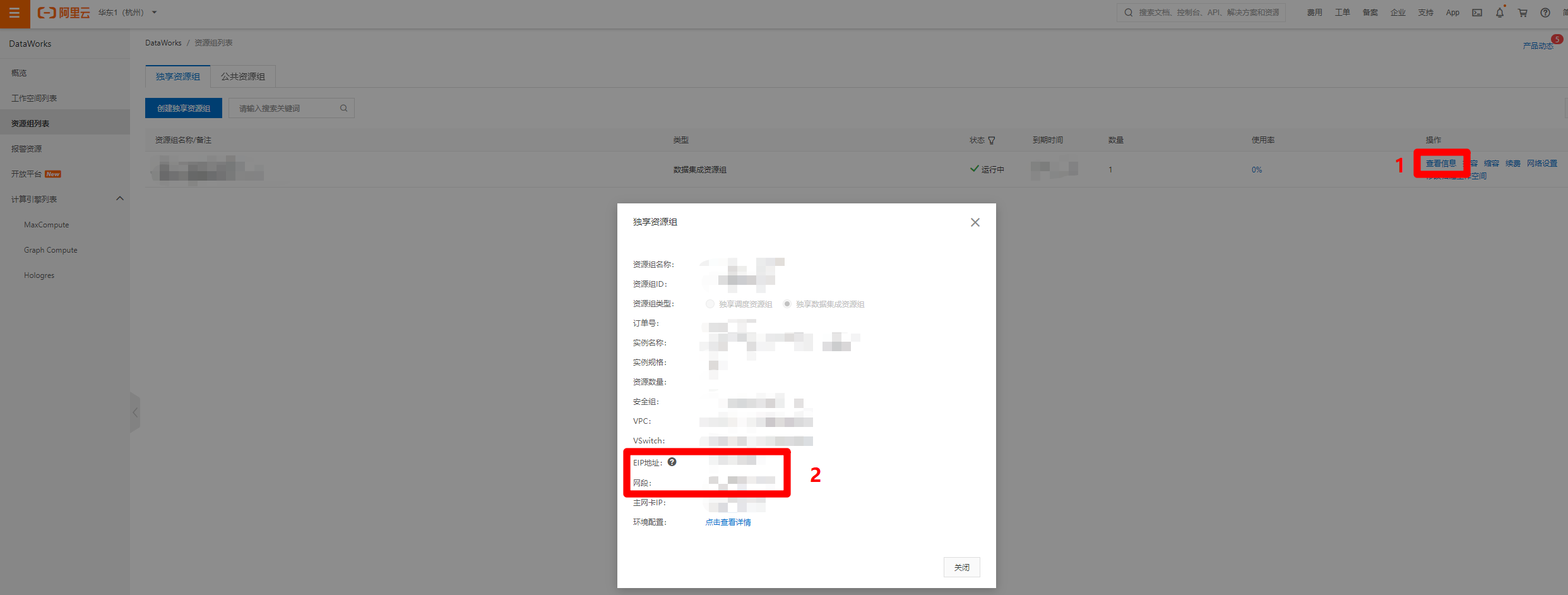
进入MongoDB管理控制台,选择"副本集实例列表",找到目标MongoDB实例的行,展开后面的"操作"列,点击"管理"选项,打开目标MongoDB实例的管理页面。
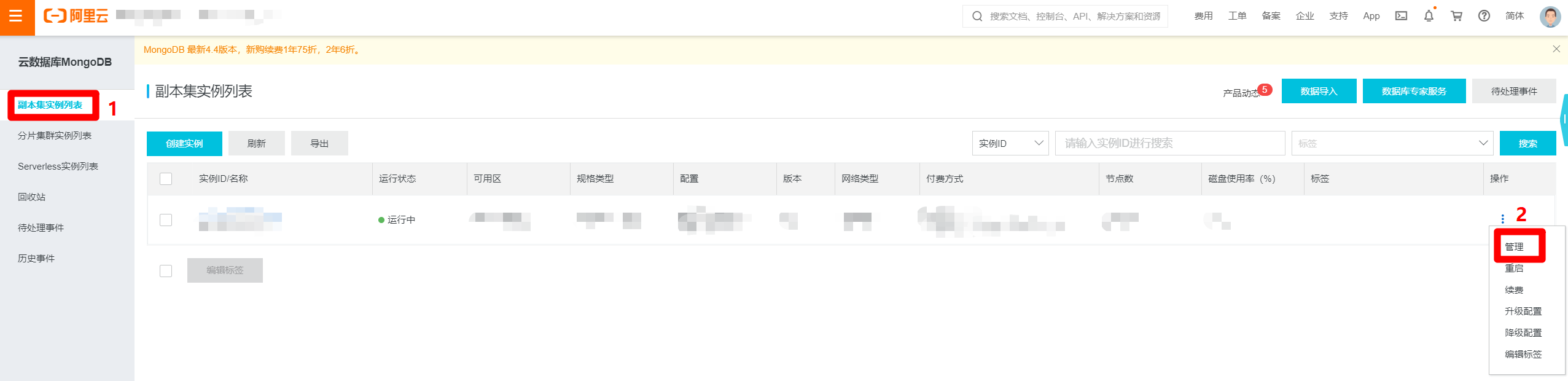
进入MongoDB实例的管理页面中,在左侧菜单栏点击"白名单设置"切换到对应页面。点击页面中的"添加白名单分组"按钮,会出现右侧"添加白名单分组"边栏。在边栏中自主填写分组名,并将刚才独享资源组的"EIP地址"和"网段"的内容填写到"允许访问IP名单"文本框中,用英文逗号分隔,然后点击"确定",完成将独享资源组网段添加到数据源白名单的操作,下一步回到新增MongoDB数据源的页面。
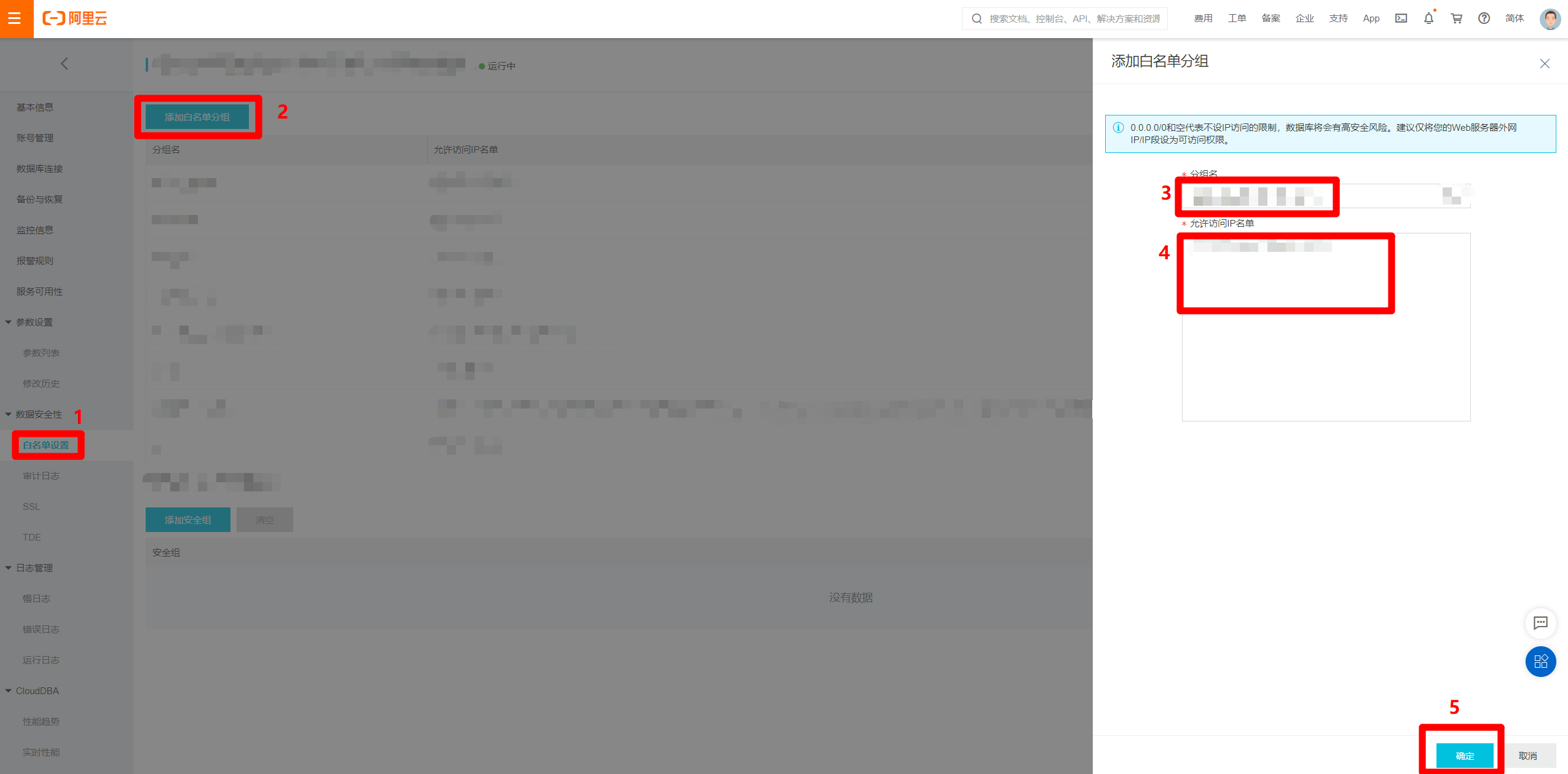
在新增MongoDB数据源的页面中,再次点击"测试连通性",此时连通状态变为"可连通",然后点击"完成",完成MongoDB数据源的创建。
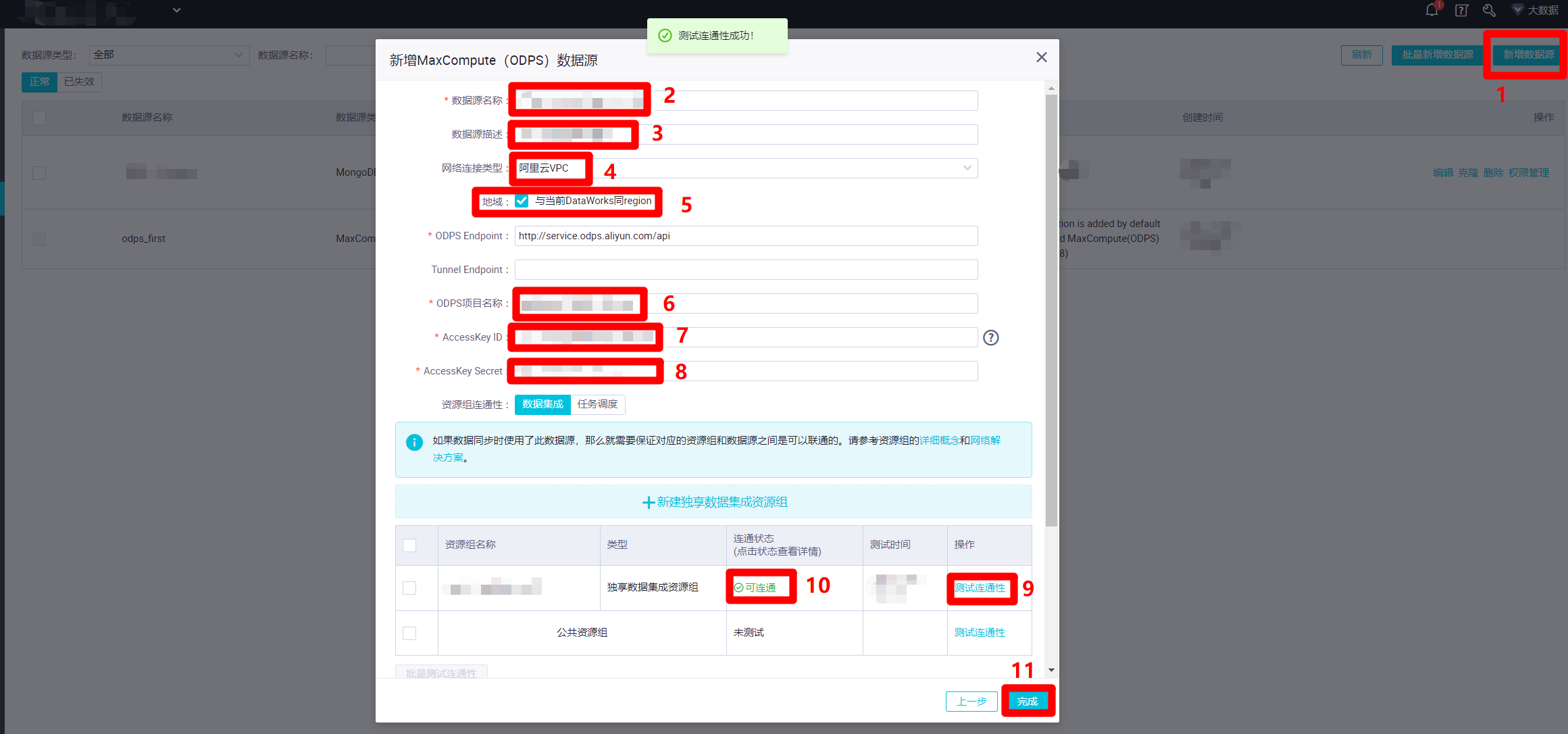
同理,也创建一个新的MaxCompute数据源(默认的MaxCompute数据源"odps_first"直接用来运行任务会出问题)。在数据源管理页面中,点击"新增数据源",会出现"新增MaxCompute(ODPS)数据源"弹出框。在弹出框中,自主填写"数据源名称"、"数据源描述","网络连接类型"选择"阿里云VPC","地域"勾选"与当前DataWorks同region","ODPS项目名称"填写当前的DataWorks工作空间名称,"AccessKey ID"填写当前登录的RAM账号的AccessKey ID,"AccessKey Secret"填写当前登录的RAM账号的AccessKey Secret。然后同样点击下面表格中"独享数据集成资源组"这一行的"测试连通性",确认"连通状态"为"可连通"。点击"完成",完成MaxCompute数据源的创建。
五、配置并创建MaxCompute表
官方文档:创建MaxCompute表
步骤图示:
在DataWorks控制台的工作空间列表页面中,点击目标工作空间所在行的"操作"列中的"进入数据开发"链接,打开"DataStudio(数据开发)"页面。

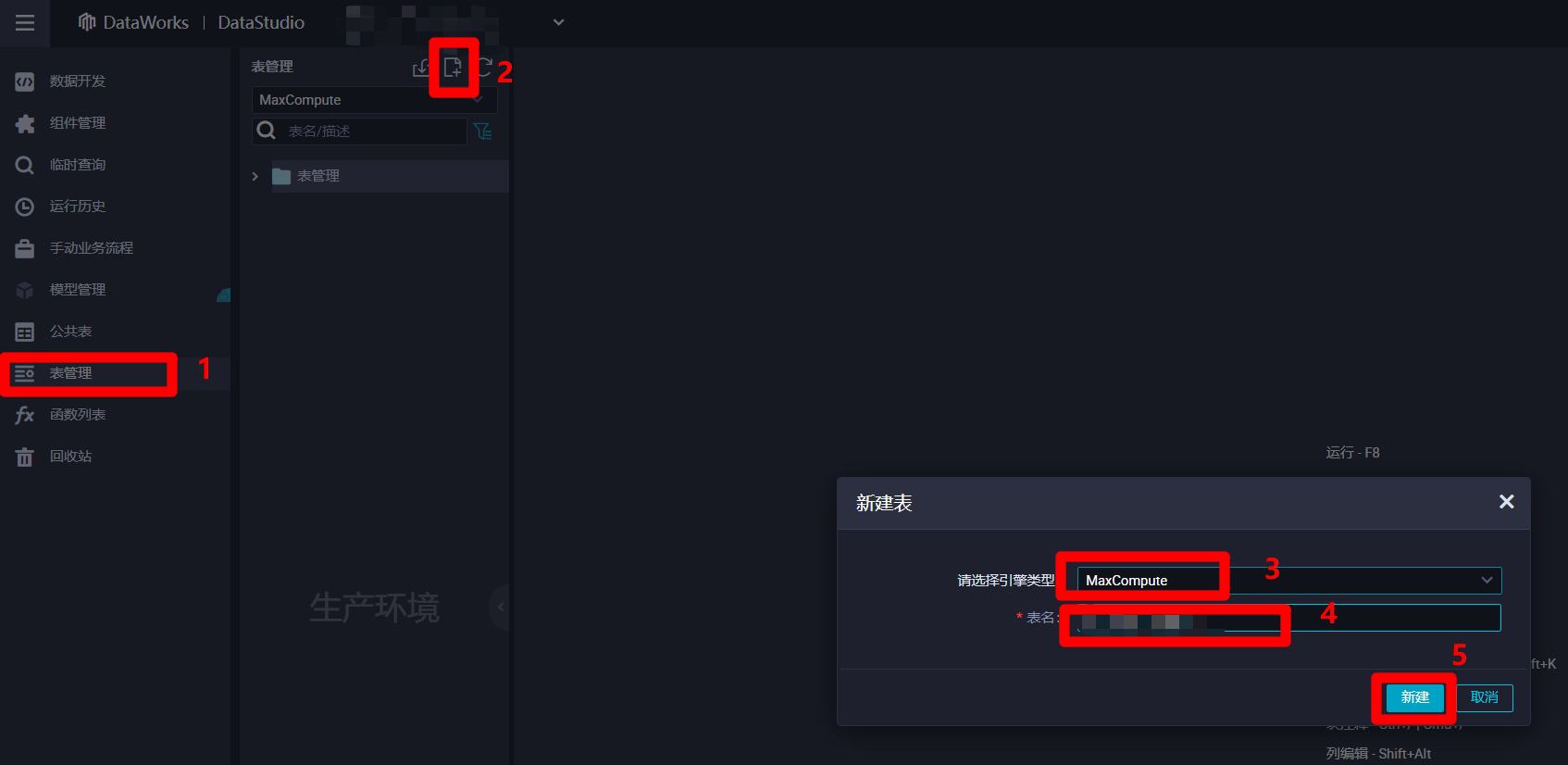
进入"DataStudio(数据开发)"页面中,点击左侧菜单栏中的"表管理"项,切换到表管理页面。然后点击表管理菜单中的新建按钮,会出现"新建表"弹出框,准备新建一张输入表用于保存来自数据源的离线同步日志数据。在弹出框中选择引擎类型为"MaxCompute",自主填写表名,然后点击新建,会出现MaxCompute表的编辑页面。
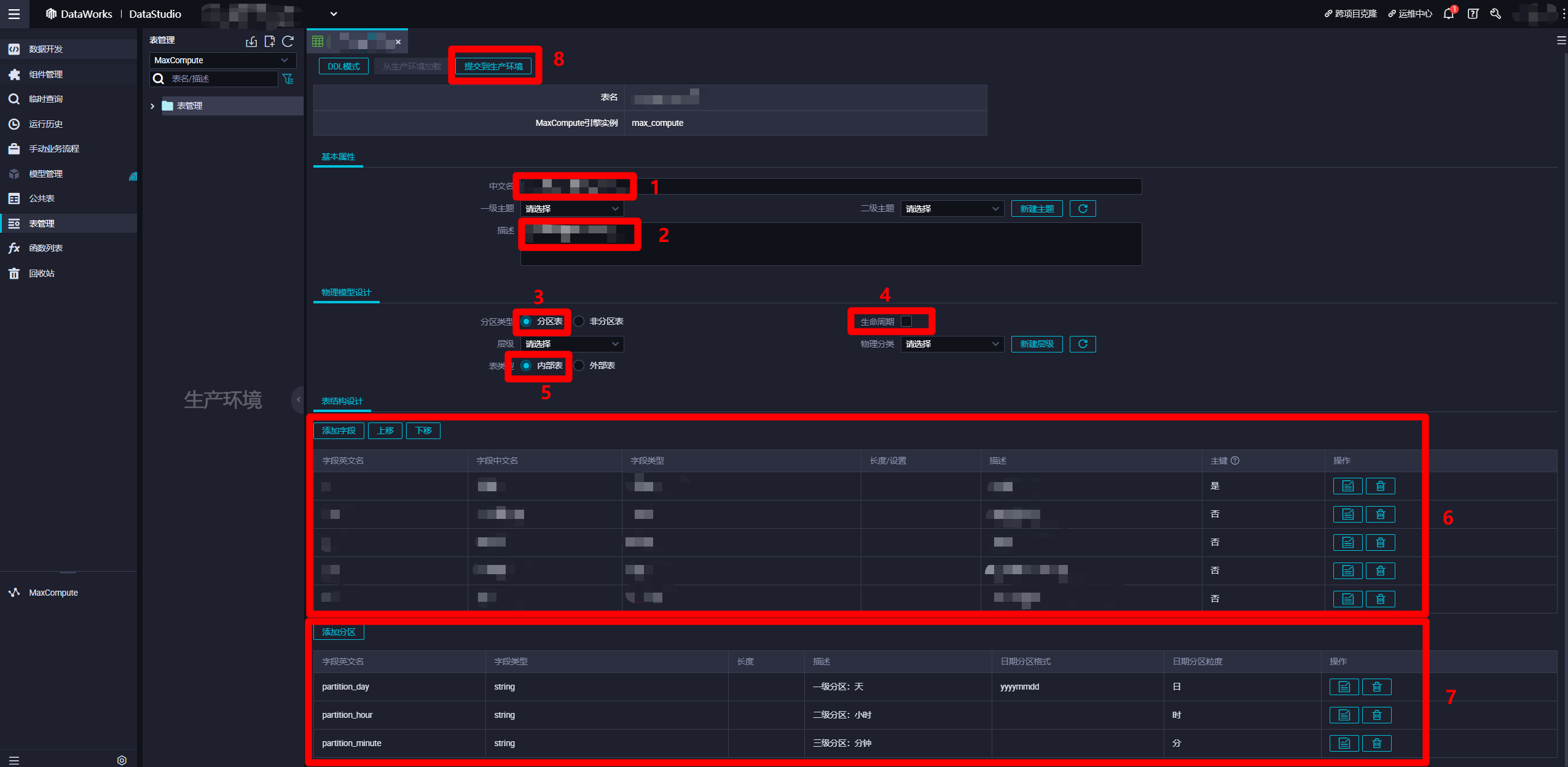
在MaxCompute表的编辑页面,"基本属性"模块中,自主填写"中文名"与"描述"。"物理模型设计"模块中,"分区类型"选择"分区表","生命周期"自主勾选(超过生命周期的未更新数据会被清除),"表类型"选择"内部表"。"表结构设计"模块中,自主添加字段,分区添加日、时、分三种粒度的分区,其中日级分区的"日期分区格式"可以填写日期格式(例如:yyyymmdd)。也可以使用DDL模式设置表结构。设置完表结构后,点击"提交到生产环境",完成"输入表"的创建。同理,自主创建一张类似的"输出表",用于保存此次实践中日志解析完成后产生的数据。至此完成两张MaxCompute表的创建。
六、创建业务流程
官方文档:创建业务流程
步骤图示:
在DataStudio(数据开发)页面,点击左侧菜单栏中的"数据开发"项,切换到数据开发页面。然后点击数据开发菜单中的新建按钮展开子菜单,点击子菜单中的"业务流程",会出现"新建业务流程"弹出框。
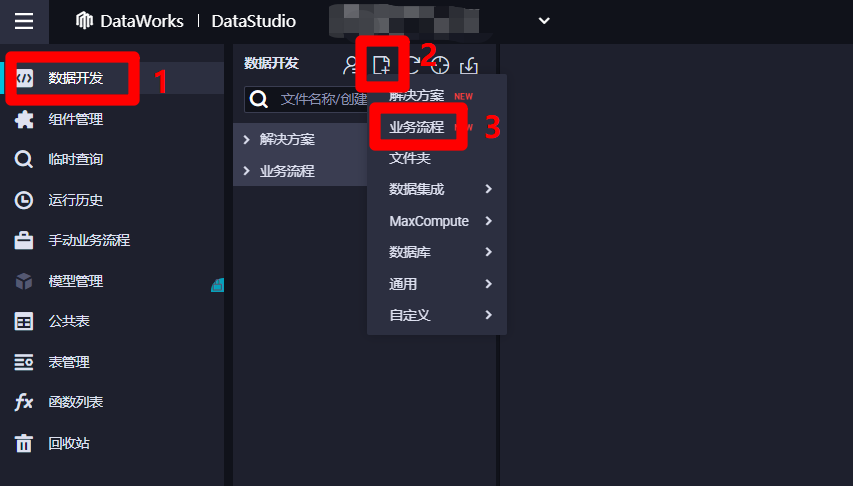
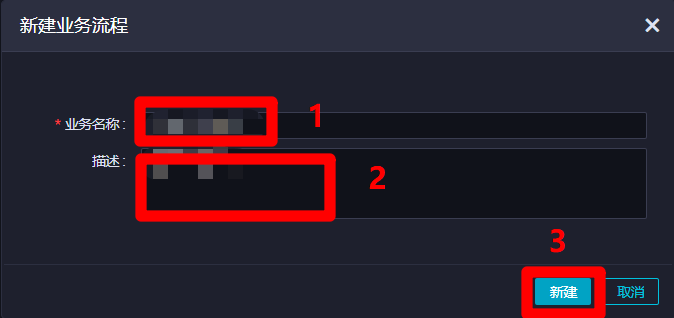
在"新建业务流程"弹出框中,自主填写"业务名称"与"描述",然后点击"新建",新建业务流程成功,自动进入该业务流程管理页面。
七、创建并配置离线数据增量同步节点
官方文档:配置离线同步任务
步骤图示:
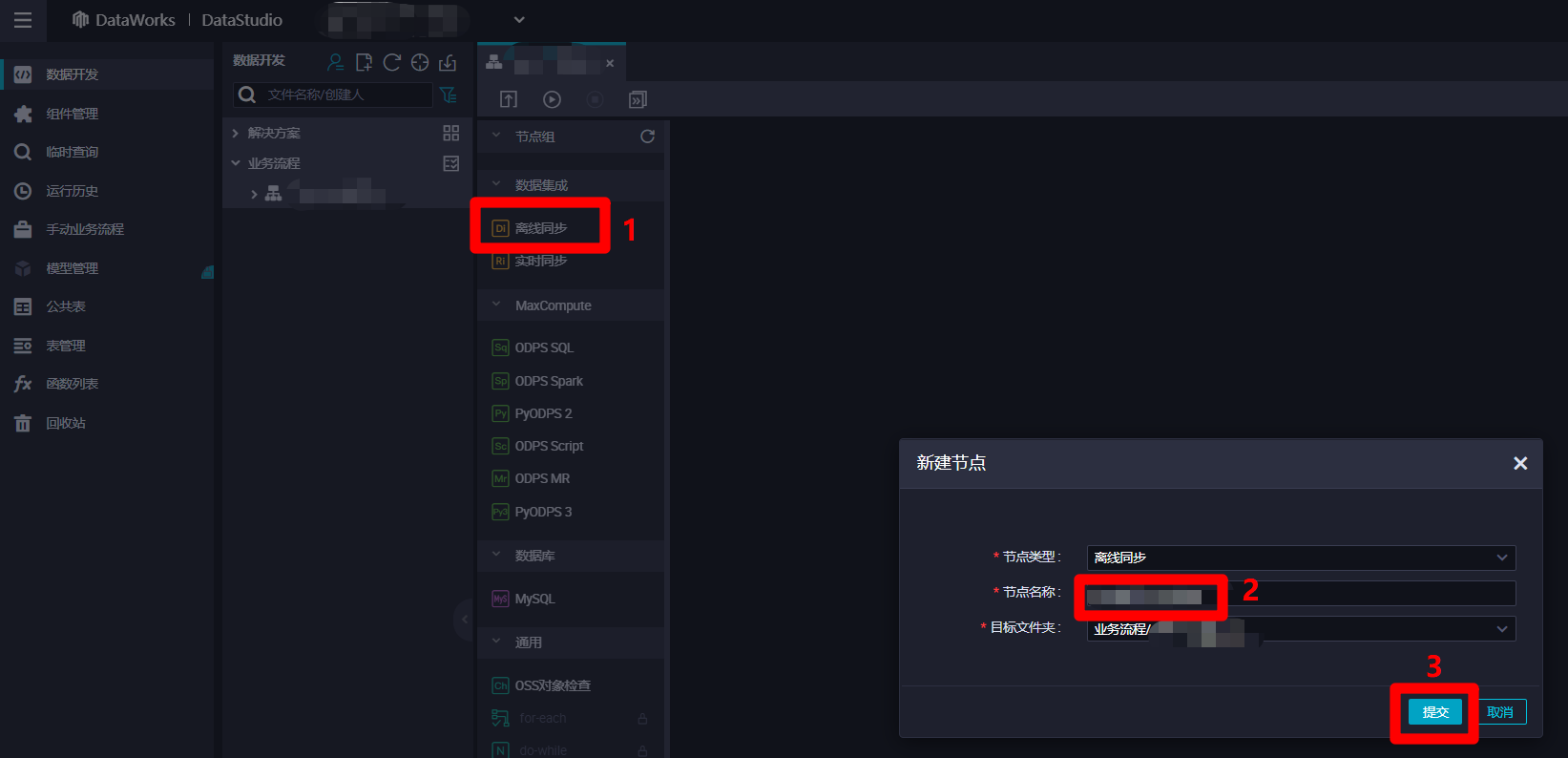
在业务流程管理页面中,点击左侧节点列表中"数据集成"下的"离线同步"项,会出现"新建节点"弹出框。在弹出框中自主填写"节点名称",然后点击"提交",完成离线同步节点的新建。
离线同步节点新建完成后,业务流程管理页面中会出现此节点,双击该节点图标,会进入该离线同步节点的配置页面。
进入离线同步节点配置页面中,展开"01选择数据源"模块中"数据来源"下"数据源"的下拉菜单,找到并选中"MongoDB"项,选中后会看到提示:此数据源不支持向导模式,需要使用脚本模式配置同步任务,点击转换为脚本。由于离线同步节点配置向导还不支持MongoDB数据源的同步,因此点击"点击转换为脚本"链接,节点配置页面会从向导模式转换为脚本模式。
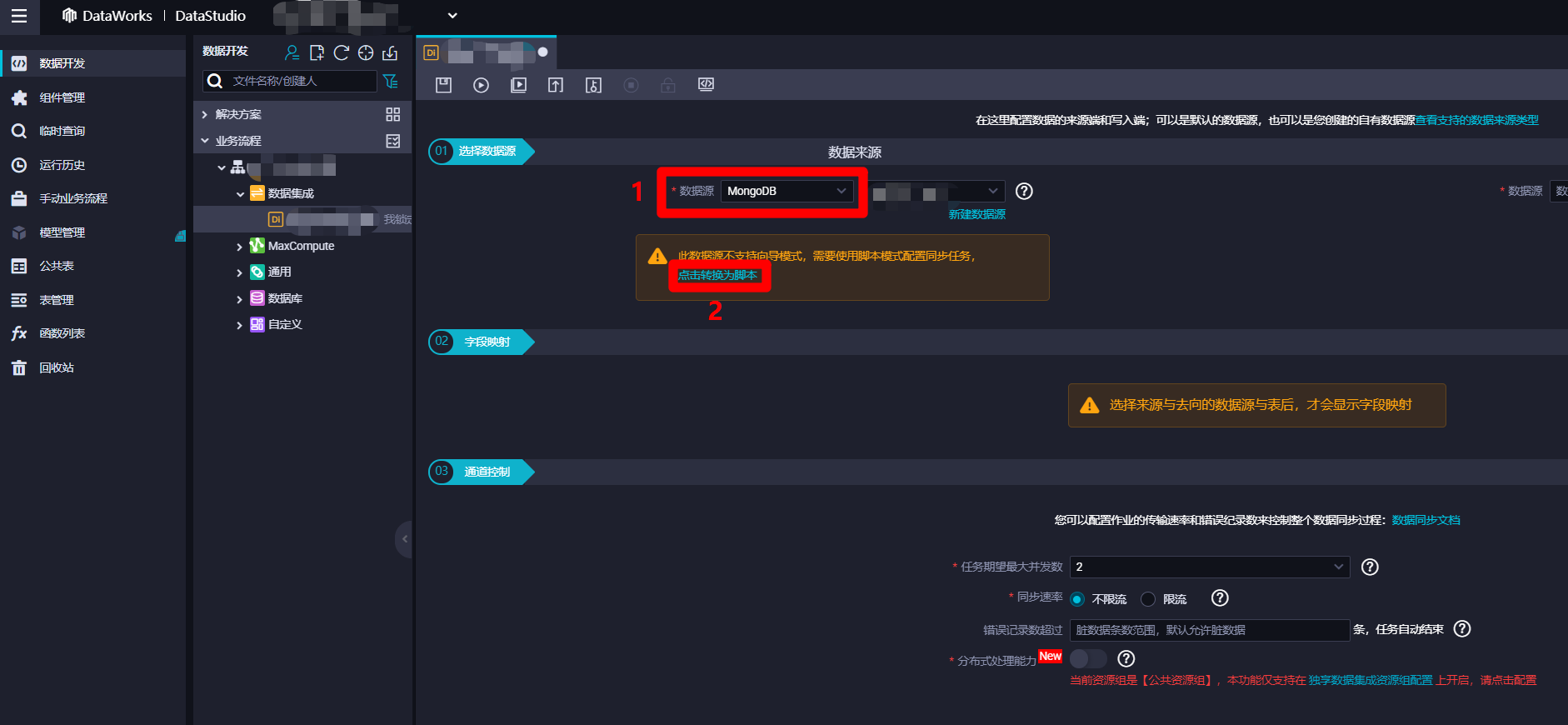
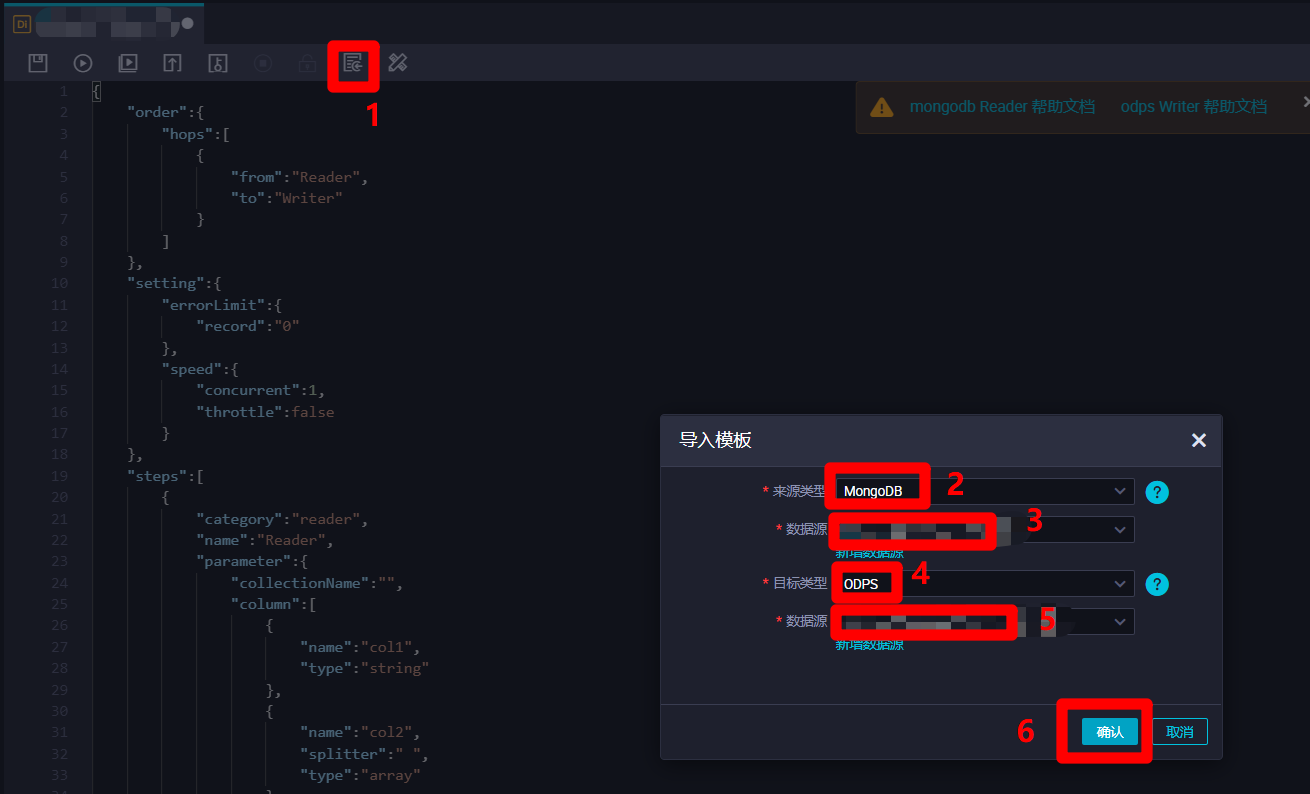
在离线同步节点脚本模式配置页面中,点击上方菜单栏中的导入模板按钮,会出现"导入模板"弹出框。在弹出框中,选择"来源类型"为"MongoDB",自主选择目标MongoDB的"数据源";选择"目标类型"为"ODPS",自主选择目标ODPS的"数据源"。然后点击"确认",配置页面中会自动生成脚本的代码模板,下一步在代码模板的基础上进行脚本的完善。
在离线同步节点脚本模式配置页面中,由于要从MongoDB同步到MaxCompute,根据MongoDB Reader和MaxCompute Writer的官方文档,自主修改完善脚本。在编写脚本时要注意,由于离线同步任务的最小执行间隔为5分钟一次,所以此次实践要在每次离线同步任务定时运行时,获取MongoDB中,定时任务执行时间往前五分钟内的数据,塞入MaxCompute输入表对应的分区中。因此参考DataWorks调度参数的官方文档,在页面右端展开"调度配置"边栏,然后在调度配置边栏的"基础属性"模块下的"参数"文本框中输入:
yyyy_mm_dd_min=$[yyyy-mm-dd-5/24/60] yyyy_mm_dd_max=$[yyyy-mm-dd] yyyymmdd_min=$[yyyymmdd-5/24/60] hh_mi_min=$[hh24:mi-5/24/60] hh_mi_max=$[hh24:mi] hh_min=$[hh24-5/24/60] mi_min=$[mi-5/24/60]。接下来在脚本代码中,在"Reader"部分的"query"项(用于对MongoDB数据进行时间范围筛选)中填写内容:{'date':{'$gte':ISODate('${yyyy_mm_dd_min}T${hh_mi_min}:00.000+0800'),'$lt':ISODate('${yyyy_mm_dd_max}T${hh_mi_max}:00.000+0800')}}。此处"${yyyymmdd_min}"等是引用刚才设置的DataWorks调度参数,而"$gte"、"$lt"、"ISODate()"是MongoDB支持的条件操作符号和函数,将获取数据的时间范围限制为执行时间往前五分钟内。下一步,要在脚本代码中的"Writer"部分的"partition"项(分区)中填写内容:partition_day=${yyyymmdd_min},partition_hour=${hh_min},partition_minute=${mi_min}。此处也是引用刚才设置的DataWorks调度参数,设置数据塞入MaxCompute表的分区为执行时间往前五分钟的时间分区。另外,"Writer"部分的"datasource"项注意要设置为自己新建的MaxCompute数据源。完成脚本的编辑后,下一步进行此离线同步节点的调度配置。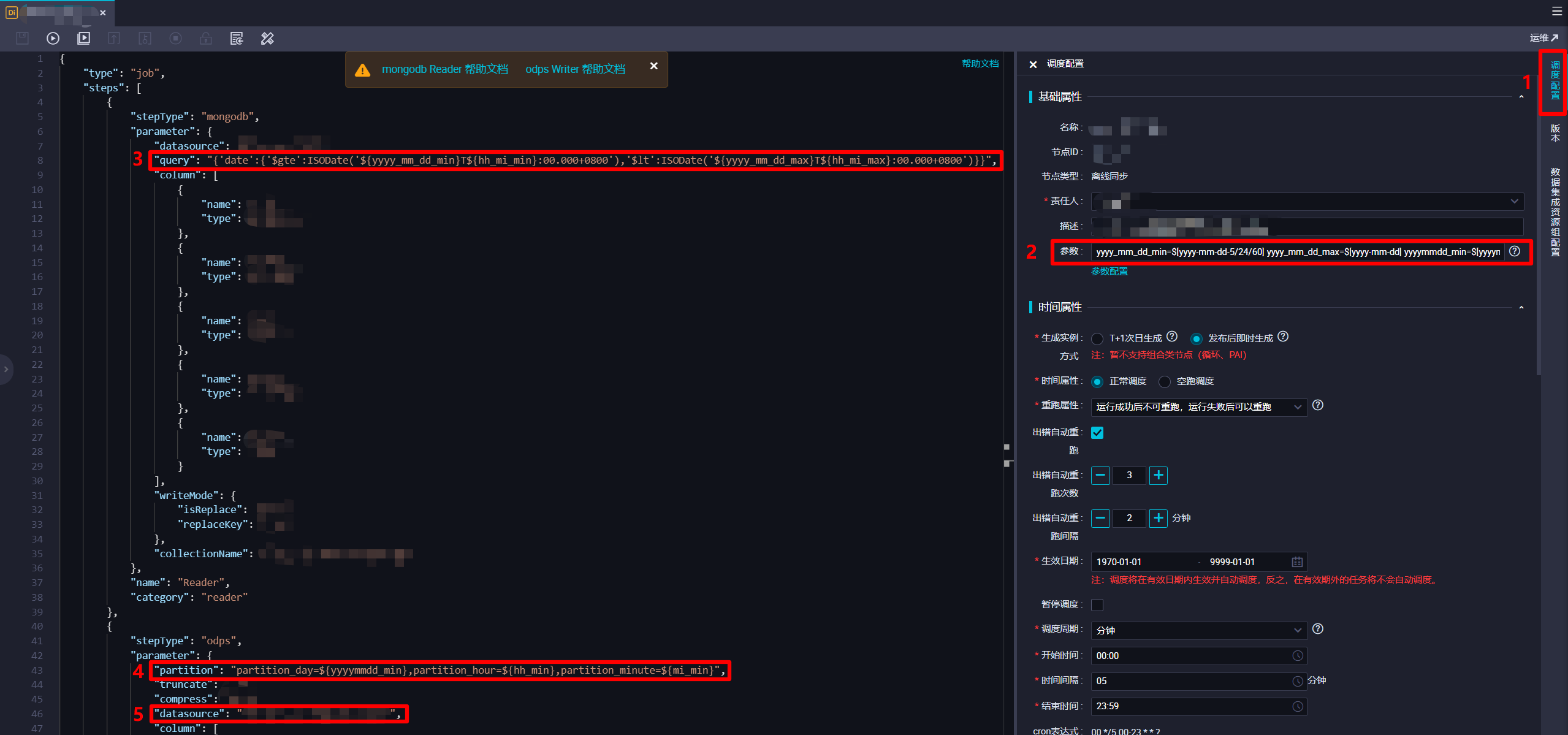
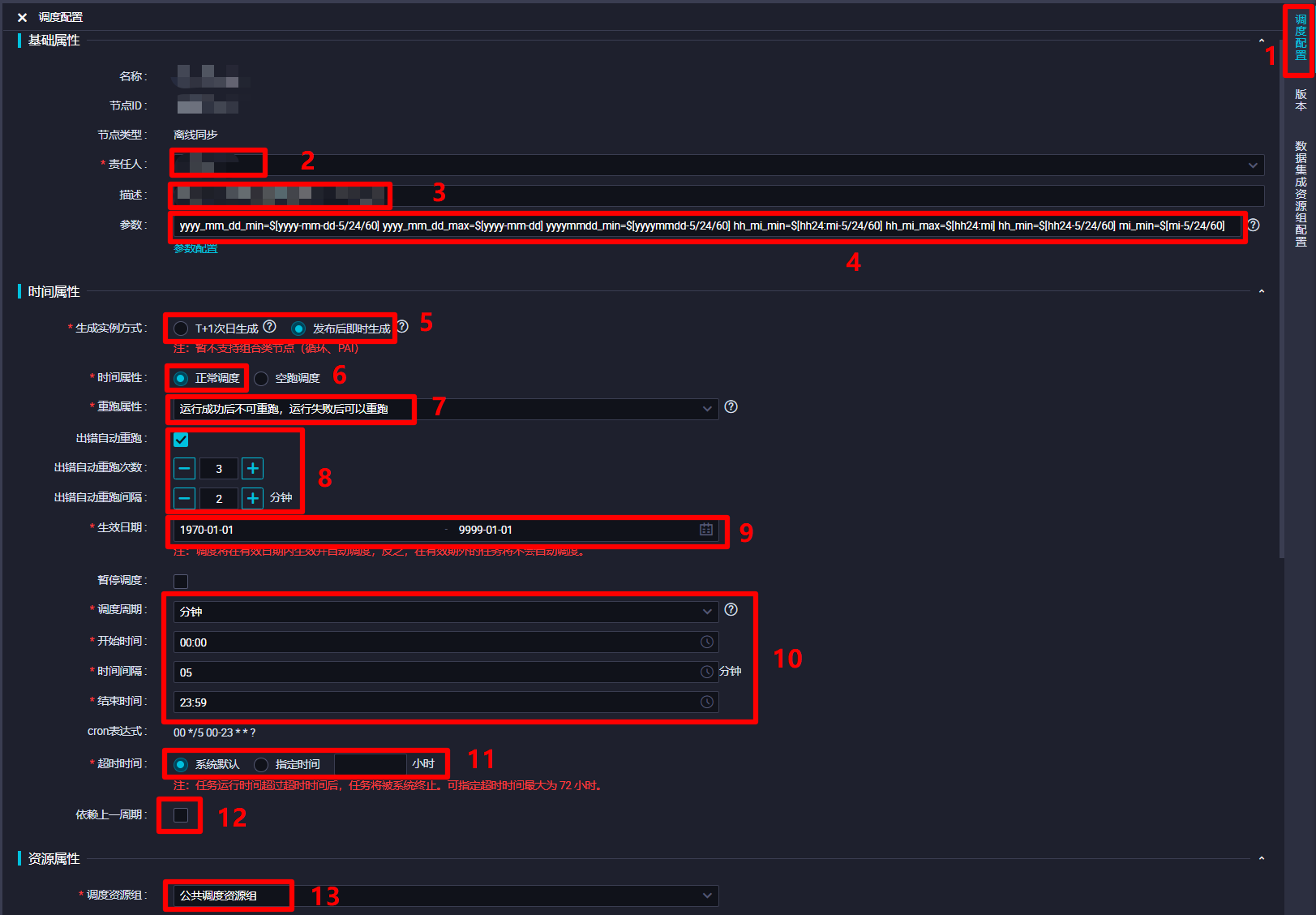
在调度配置边栏中,对该离线同步节点的调度配置进行完善。在"基础属性"模块中,"责任人"选择当前登录的RAM账号;自主填写"描述";"参数"的填写内容上一步中已完成,不再赘述。在"时间属性"模块中,自主选择"生成实例方式",为方便后面快速测试,此次实践选择"发布后即时生成";"时间属性"选择"正常调度";自主选择"重跑属性",通常选择"运行成功后不可重跑,运行失败后可以重跑";勾选"出错自动重跑",自主选择"出错自动重跑次数"、"出错自动重跑间隔",此次实践使用其默认配置的次数与间隔;自主选择"生效日期",此次实践使用其默认配置,让同步任务一直保持生效状态;由于此次实践希望整个业务流程的运行周期间隔尽量短一些,所以设置"调度周期"为"分钟","开始时间"设置为"00:00"(被限制只能设置整时),"时间间隔"设置为最短的"05","结束时间"设置为"23:59"(被限制只能设置小时),以确保该节点跨天也会每五分钟运行一次;自主选择"超时时间",此次实践选择"系统默认";不勾选"依赖上一周期",这样某一周期运行出错不会影响之后的运行周期。"资源属性"模块的"调度资源组"选择默认的"公共调度资源组"即可。"调度依赖"模块暂时不进行配置。"节点上下文"模块在此次实践中不需要配置。完成以上调度配置后,下一步对该节点进行数据集成资源组配置。
点击页面右端菜单栏的"数据集成资源组配置"项,将右边边栏切换到"数据集成资源组配置"页面。在边栏中,"方案"项选择"独享数据集成资源组",然后"独享数据集成资源组"项自主选择独享数据集成资源组。若要使用公共数据集成资源组,"方案"项选择"公共资源组"即可。数据集成资源组配置完成后,点击页面上方菜单栏的保存按钮,完成对离线同步节点的创建与配置。
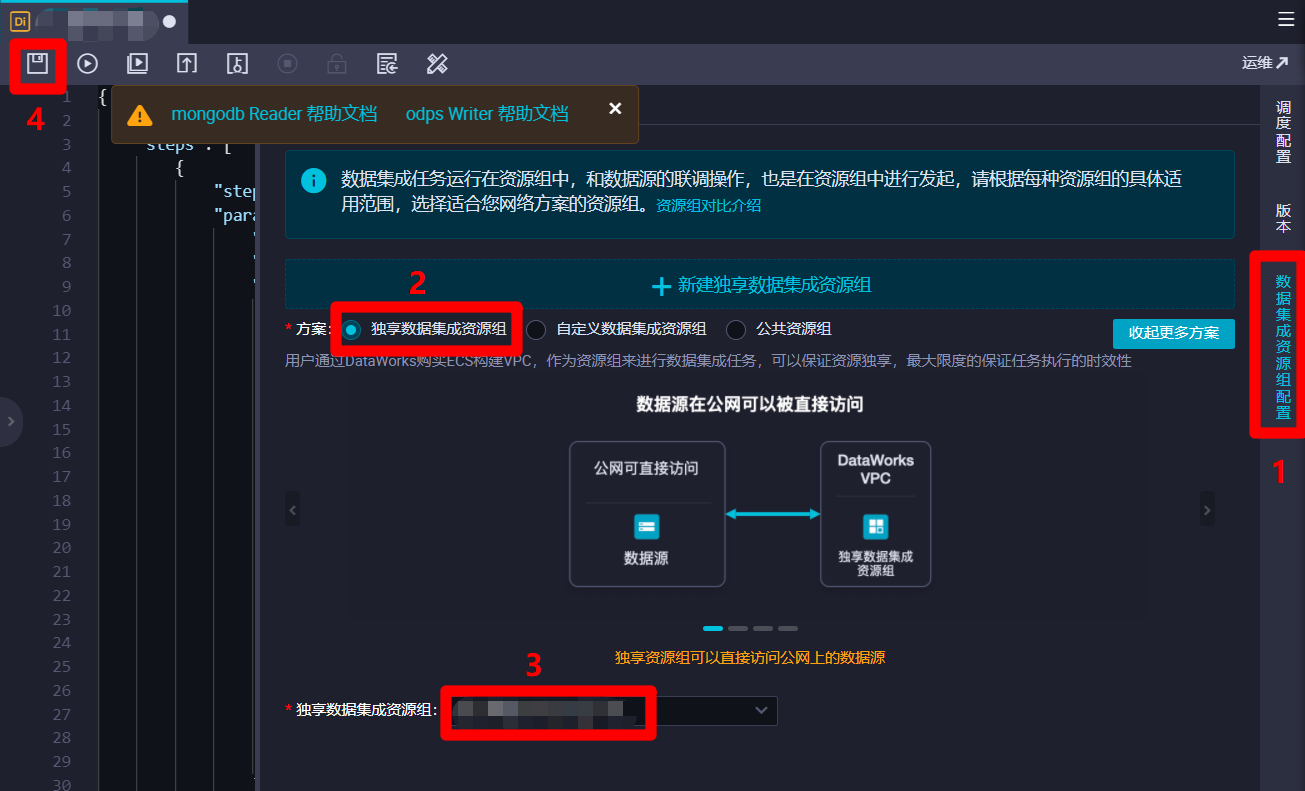
同理,再创建一个类似的离线同步节点,用于将MaxCompute输出表的数据同步到MongoDB的集合中。在编写此脚本时同样有几点要注意,在调度配置边栏的"基础属性"模块下的"参数"文本框中输入:
p_yyyymmdd=$[yyyymmdd-15/24/60] p_hh=$[hh24-15/24/60] p_mi=$[mi-15/24/60]。在脚本的"Reader"部分的"partition"项中填写内容:partition_day=${p_yyyymmdd}/partition_hour=${p_hh}/partition_minute=${p_mi}。在调度配置边栏的"时间属性"模块下,"调度周期"设置"分钟","开始时间"设置"00:00","时间间隔"设置"05","结束时间"设置"23:59"。这样该离线同步节点每次运行时会去同步MaxCompute输出表中十五分钟前的时间分区的数据。至此完成两个离线同步节点的创建与配置,下一步准备开发DataWorks的MapReduce功能的JAR包,用于对日志数据进行解析。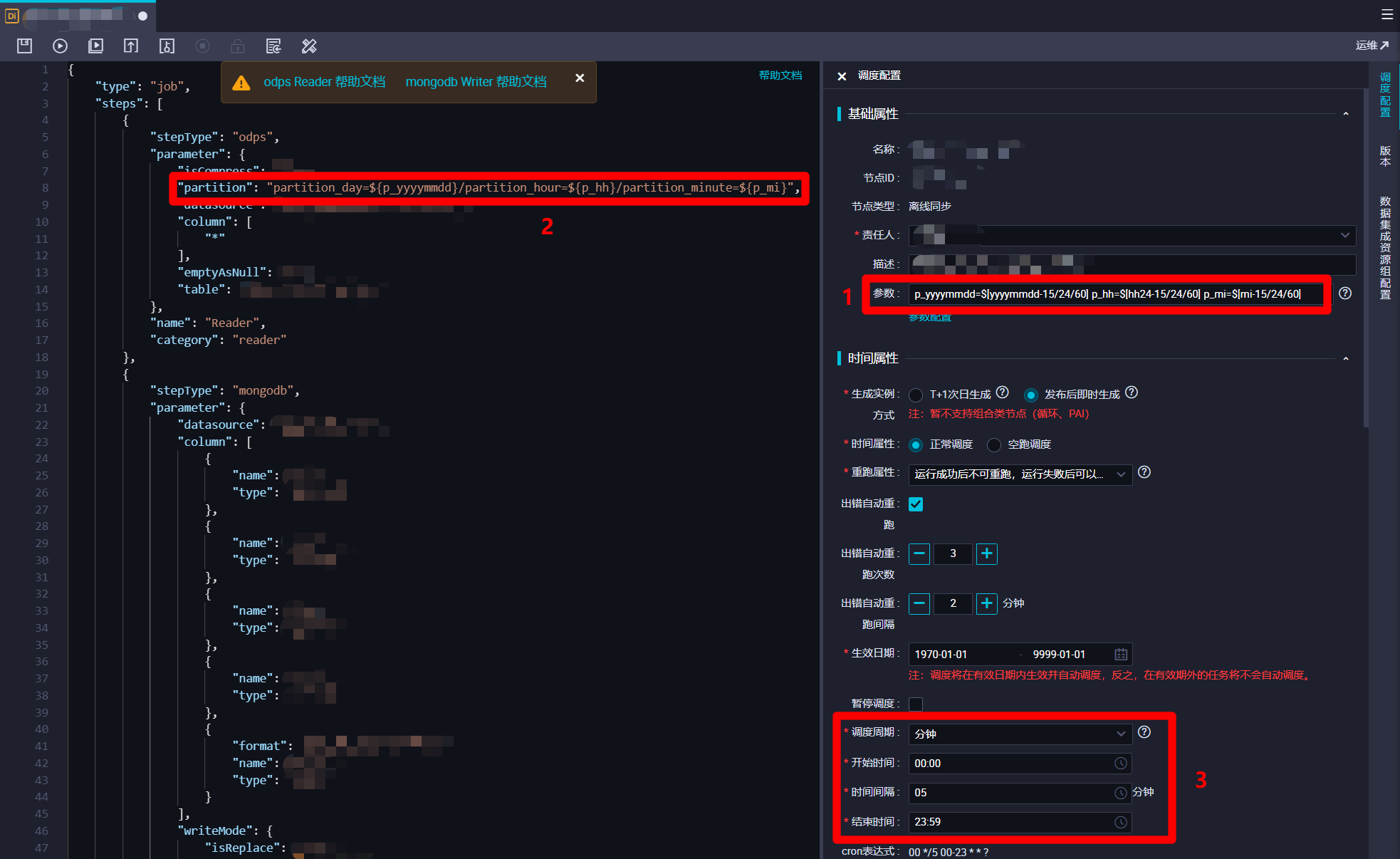
八、下载IntelliJ IDEA的MaxCompute Studio插件并配置
官方文档:安装MaxCompute Studio
步骤图示:
打开IntelliJ IDEA的主界面,展开上方菜单栏的"File"项,点击展开的子菜单中的"Settings...",会出现Settings弹出框。
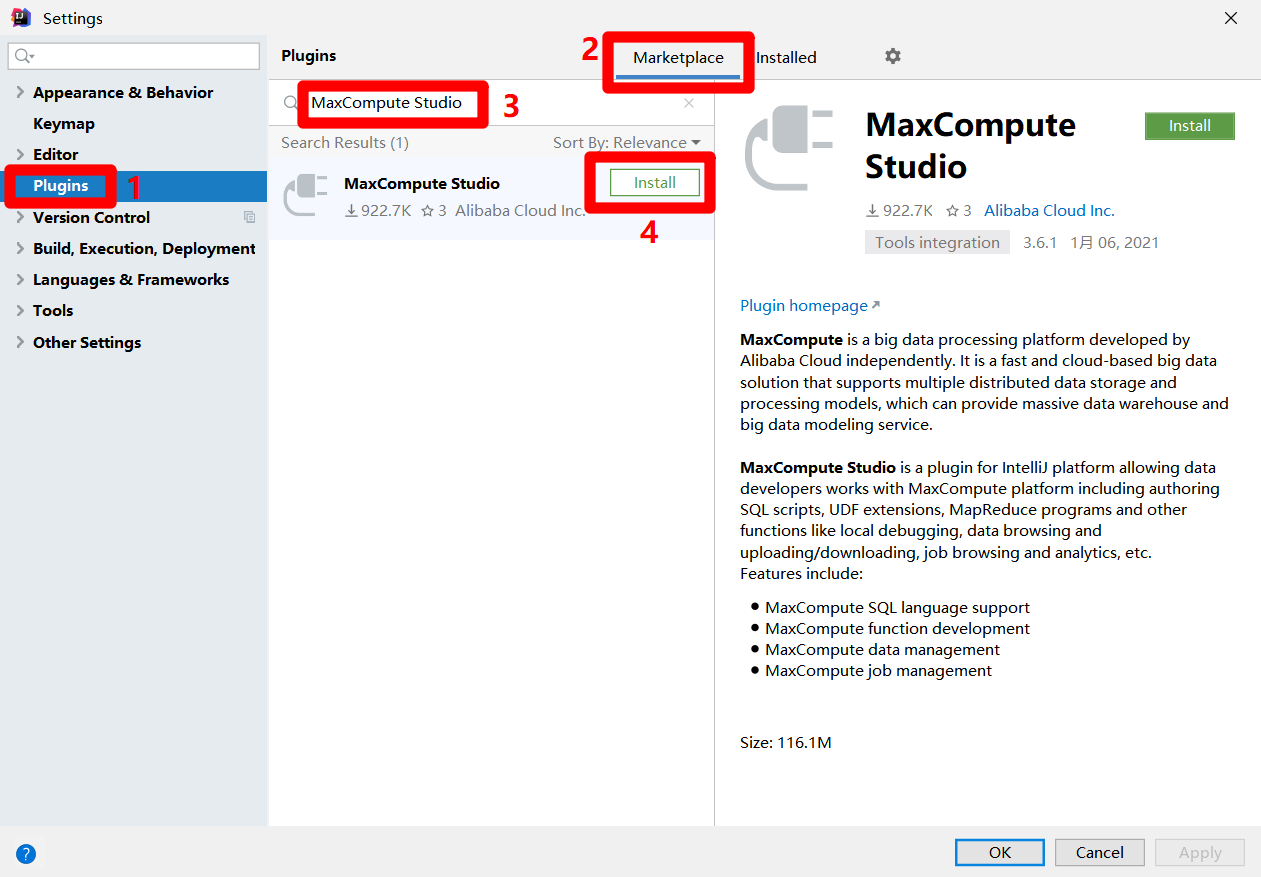
在Settings弹出框中,点击左侧菜单栏中的"Plugins",使弹出框切换到插件页面。在插件页面中,点击上方的"Marketplace"标签,然后再搜索框中输入"MaxCompute Studio",搜索框下方会出现搜索结果。点击MaxCompute Studio阿里云官方插件的"Install"按钮,开始插件的安装。
插件安装完成后,会出现"Restart IDE"按钮,点击该按钮重启IDEA,即可使用MaxCompute Studio插件。下一步准备在IDEA中创建MaxCompute Studio项目,并连接到DataWorks中的MaxCompute项目。
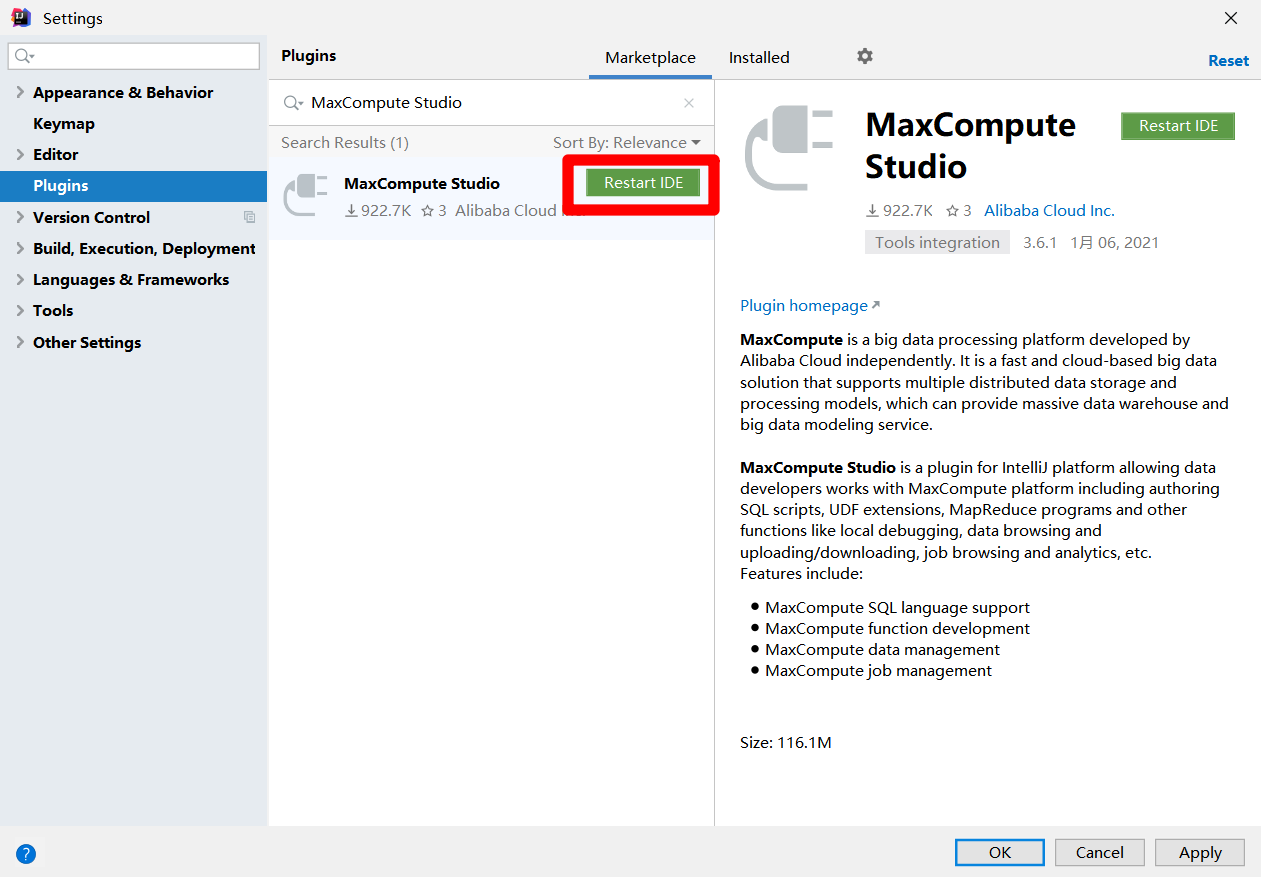
重启IDEA后,展开上方菜单栏的"File"项,在"File"项的子菜单中再次展开"New"项,点击"New"项的子菜单中的"Project..."项,会出现"New Project"弹出框。
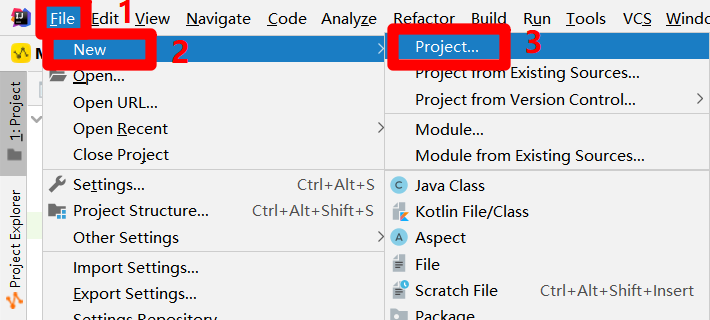
在"New Project"弹出框的左侧菜单栏中点击"MaxCompute Studio",然后点击"Next"按钮,下一步设置项目名称和路径。
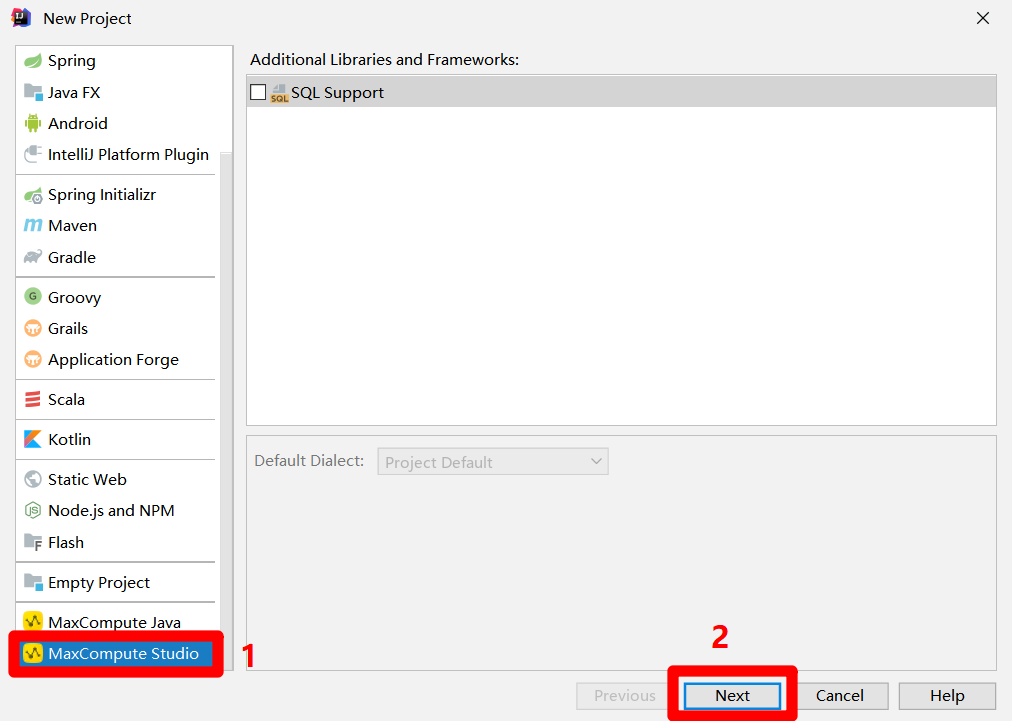
自主填写项目名称到"Project name"中,自主选择项目保存路径到"Project location"中,然后点击"Finish"按钮,完成创建MaxCompute Studio项目,下一步将此项目连接到DataWorks中的MaxCompute项目。
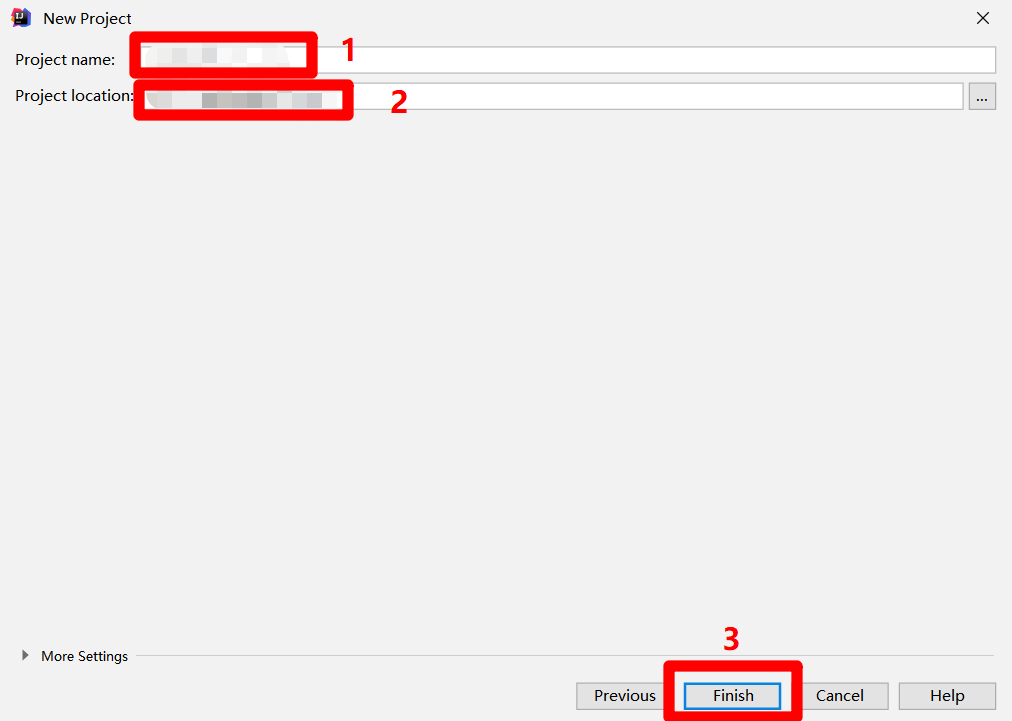
在IntelliJ IDEA的主界面,展开上方菜单栏的"View"项,在"View"项的子菜单中再次展开"Tool Windows"项,点击"Tool Windows"项的子菜单中的"Project Explorer"项,会出现"Project Explorer"左侧边栏。
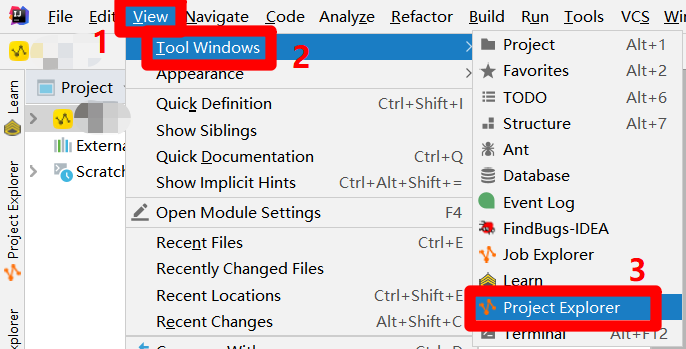
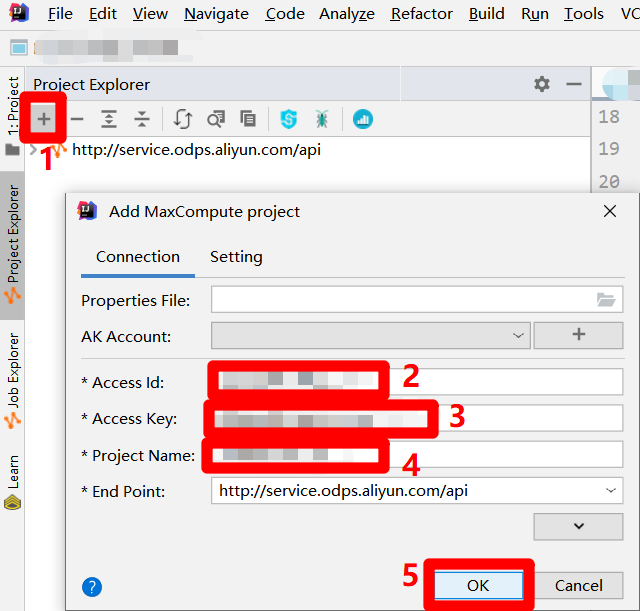
在侧边栏中,点击左上角的"+"图标,会出现"Add MaxCompute project"弹出框。在弹出框中,将正在使用的RAM账号的AccessKey ID填入"Access Id"中,将正在使用的RAM账号的AccessKey Secret填入"Access Key"中,将DataWorks工作空间名称填入"Project Name"中,然后点击"OK",完成MaxCompute项目的连接。成功连接后,便可以在IDEA界面左侧的"Project Explorer"边栏中查看连接到的MaxCompute项目的详情。
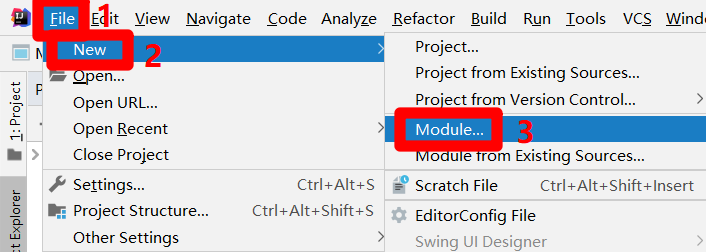
在IntelliJ IDEA的主界面,展开上方菜单栏的"File"项,在"File"项的子菜单中再次展开"New"项,点击"New"项的子菜单中的"Module..."项,会出现"New Module"弹出框。
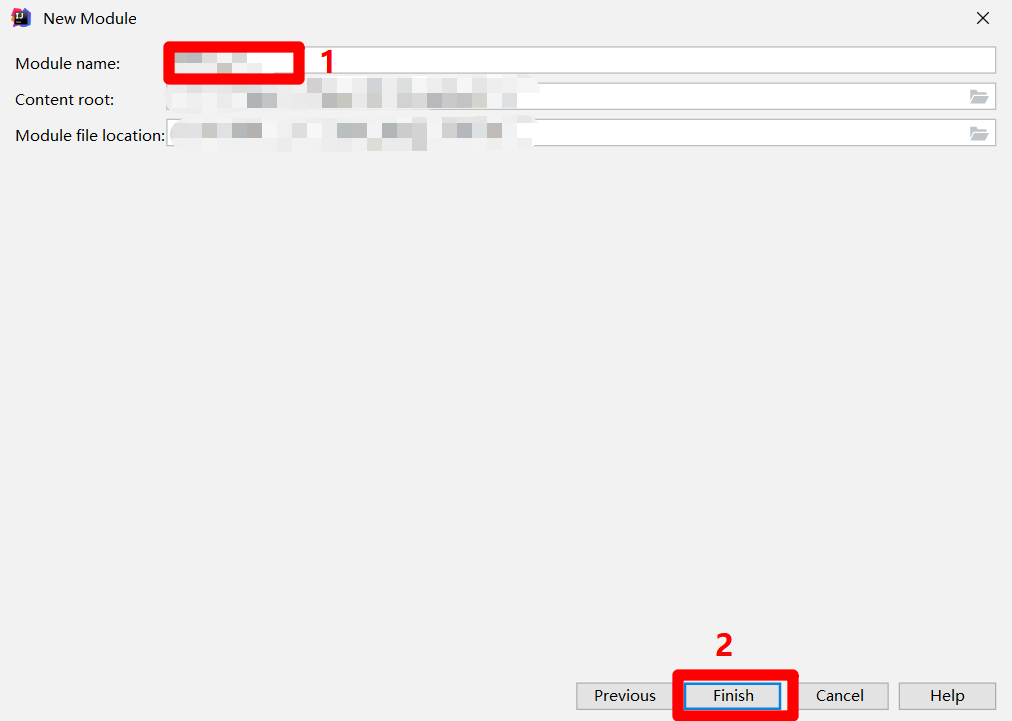
在"New Module"弹出框的左侧菜单中,点击"MaxCompute Java",在弹出框主页面中自主设置"Module SDK"为1.8版本的JDK,然后点击"Next",下一步设置Module名称。
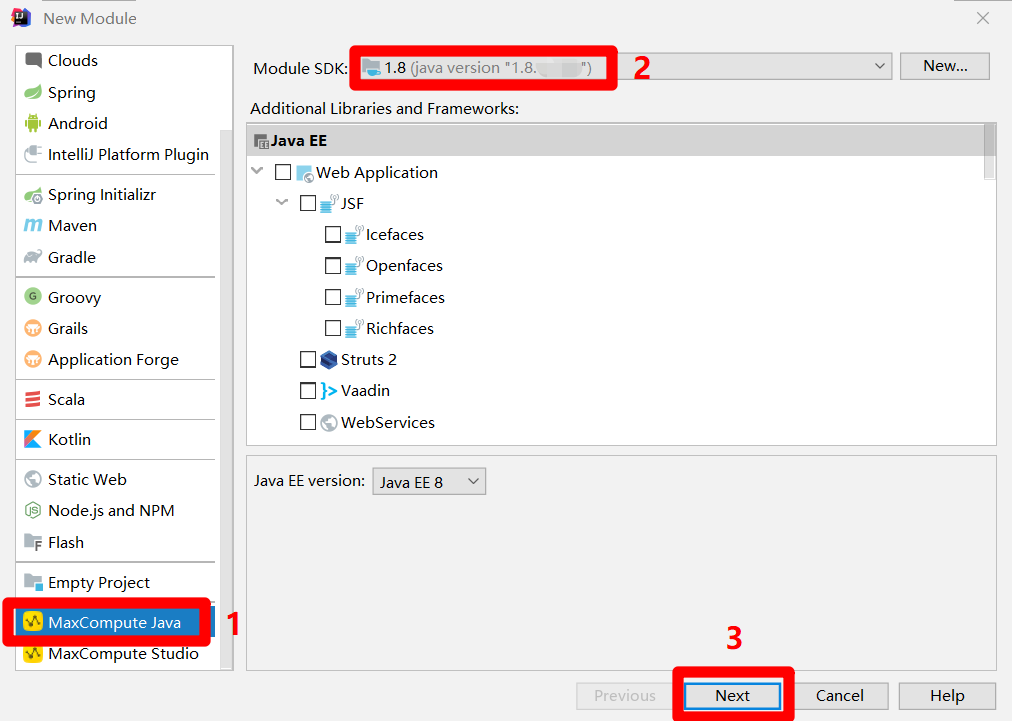
在"Module name"中自主填写模块名称,然后点击"Finish",完成MaxCompute Java模块的创建,在IDEA的"Project"侧边栏中会出现对应的目录结构。至此完成MaxCompute Studio插件的下载与配置。
九、使用MaxCompute Studio开发MapReduce功能的Java程序
官方文档:开发MapReduce功能的Java程序
步骤图示:
在IntelliJ IDEA主界面左侧菜单栏中点击"Project",展开"Project"侧边栏。在侧边栏中展开MaxCompute Studio项目的目录结构,找到MaxCompute Java模块的目录项,依次展开其下的"src"、"main"目录项,选中"main"目录结构下的"java"目录项,鼠标右击调出右键菜单。在右键菜单中展开"New"项,点击"New"项的子菜单中的"MaxCompute Java"项,会出现"Create new MaxCompute java class"弹出框。
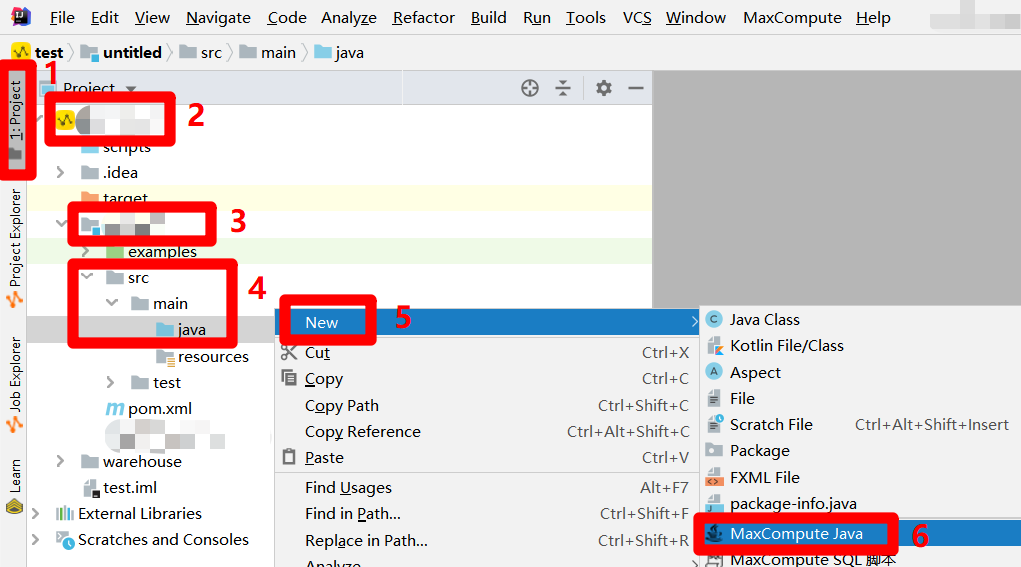
在"Create new MaxCompute java class"弹出框下方的菜单中点选"Driver"项,然后在弹出框的"Name"文本框中自主输入Driver名称(例如:MainDriver),按"Enter"键完成Driver文件的创建。
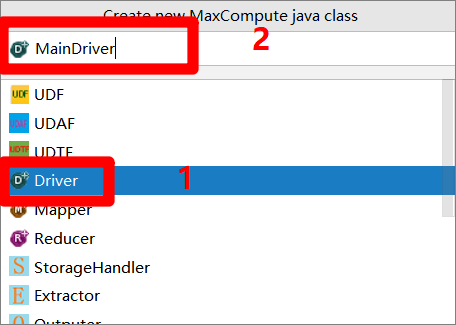
Driver创建完成后,在"Project"侧边栏中找到Driver文件,双击打开其编辑页面。在编辑页面中,可以看到自动生成了一些Java代码模板,而该Driver类中只有一个main方法,表明此Driver类是整个MapReduce功能的Java程序的入口。我们用与创建Driver类同样的方式,创建Mapper类与Reducer类,然后根据MapReduce示例程序的官方文档,自主完成Driver类、Mapper类、Reducer类的开发,实现所需的功能(例如本次实践中进行了日志解析功能的实现),这里不深入展开详细的过程。开发结束前,请自主进行本地测试,使程序通过本地编译和测试,确保功能可用。

十、将MapReduce功能程序打包上传为资源
官方文档:打包、上传Java程序
步骤图示:
完成MapReduce功能的Java程序开发后,要对程序进行打包获得JAR包。在IntelliJ IDEA主界面的"Project"侧边栏中选中Driver文件,鼠标右击调出右键菜单。在右键菜单中点击"Deploy to server...",会出现"Package a jar and submit resource"弹出框。
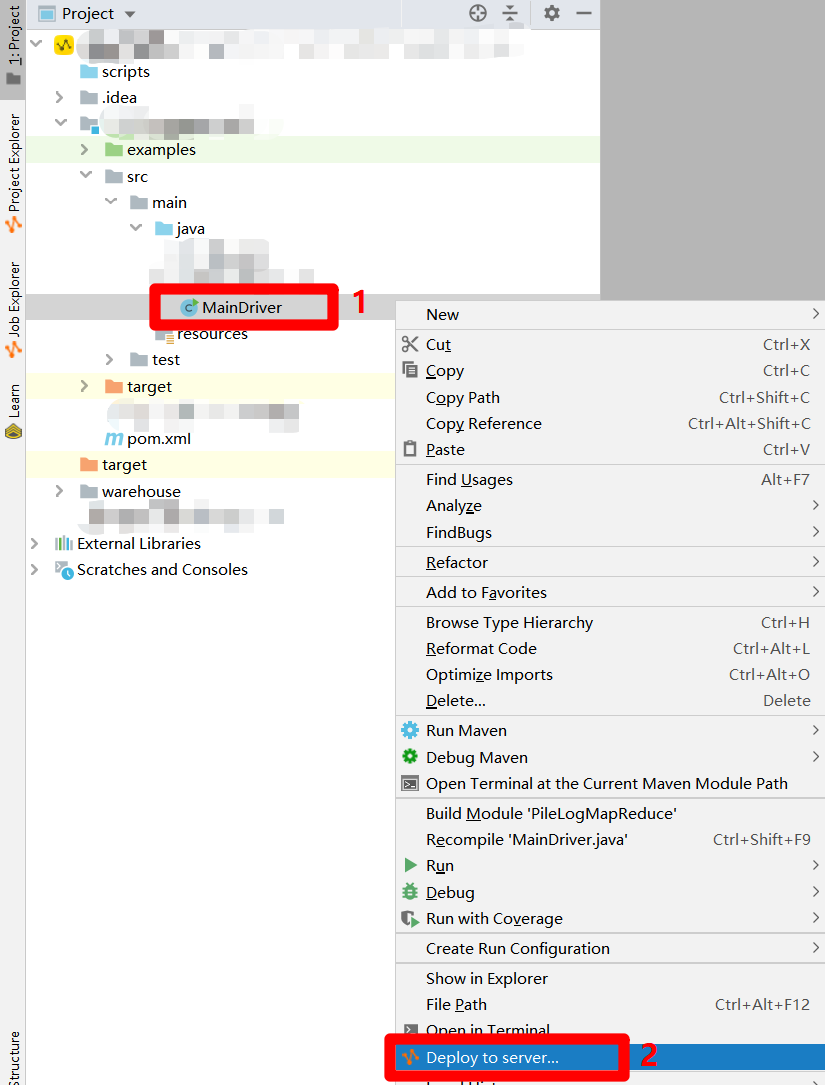
在"Package a jar and submit resource"弹出框中,由于之前已经配置过MaxCompute项目的连接,此时会自动填写各项参数,只需点击"OK"按钮,即可完成打包,下一步要将JAR包上传为资源。

在"Project"侧边栏中展开MaxCompute Java模块下的"target"目录项,在"target"目录结构中选中上一步生成的JAR包。然后展开主界面上方菜单栏中的"MaxCompute"项,点击展开的子菜单中的"添加资源",会出现"Add Resource"弹出框。
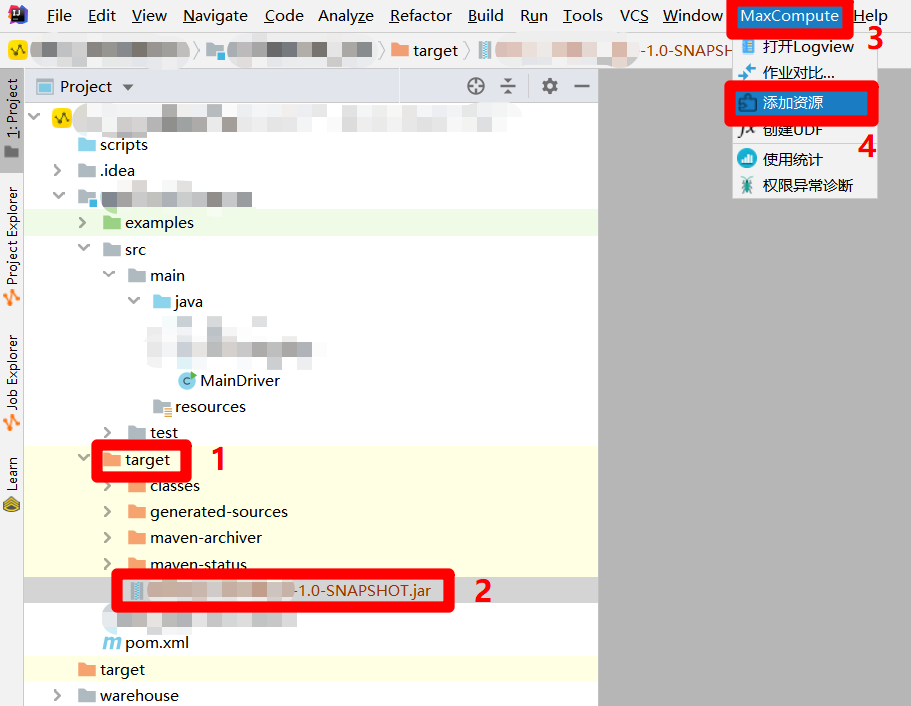
在"Add Resource"弹出框中,因为刚才选中了生成的JAR包,此时会自动填写各项参数,只需点击"OK"按钮,即可将JAR包添加为阿里云MaxCompute项目中的资源,下一步要将此资源添加到业务流程的资源文件夹中。
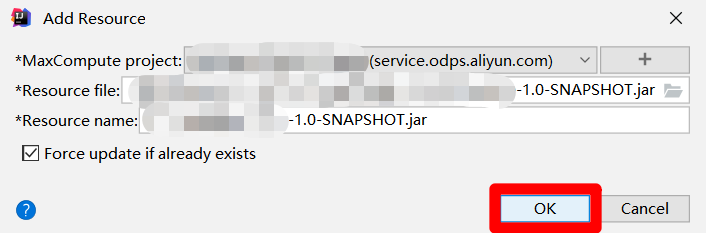
打开阿里云的"DataStudio(数据开发)"页面,展开页面左侧菜单栏中的"MaxCompute"项,点击"MaxCompute"菜单下的"MaxCompute资源",菜单栏右边的页面会切换到"MaxCompute资源"编辑页面。在"MaxCompute资源"编辑页面中选中刚才上传的JAR包资源,然后点击页面下方的"添加到数据开发"按钮,会出现"新建资源"弹出框。在"新建资源"弹出框中,参数"目标文件夹"里自主选择之前创建的业务流程,然后点击"新建"按钮,成功将Jar包添加到业务流程的资源中,下一步将资源进行提交。
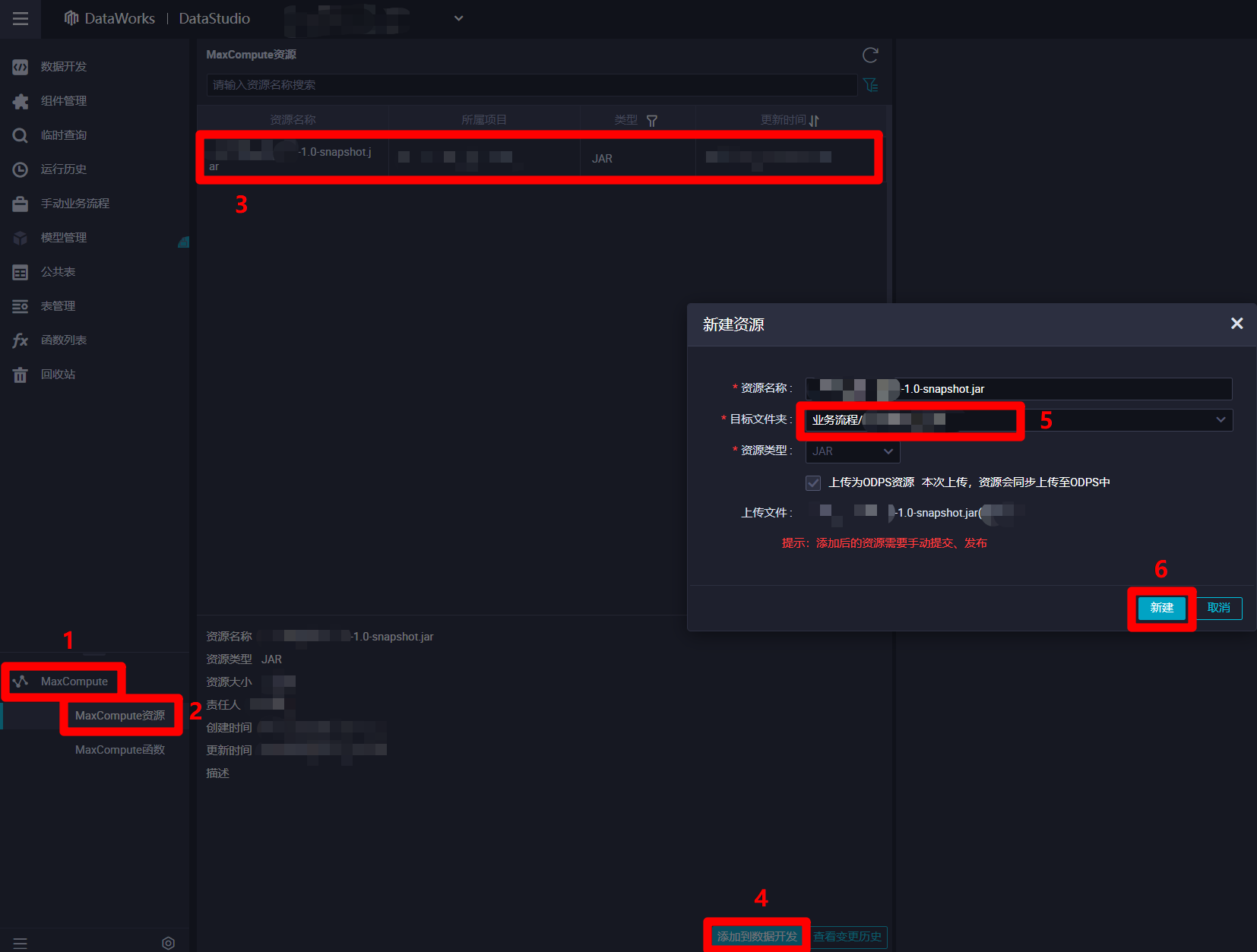
在DataWorks的"数据开发"页面中,展开当前业务流程的列表,在列表中依次展开"MaxCompute"、"资源"项,双击刚添加的JAR包资源,进入该资源的编辑页面,然后点击页面上方菜单栏中的提交按钮,会出现"提交新版本"弹出框。
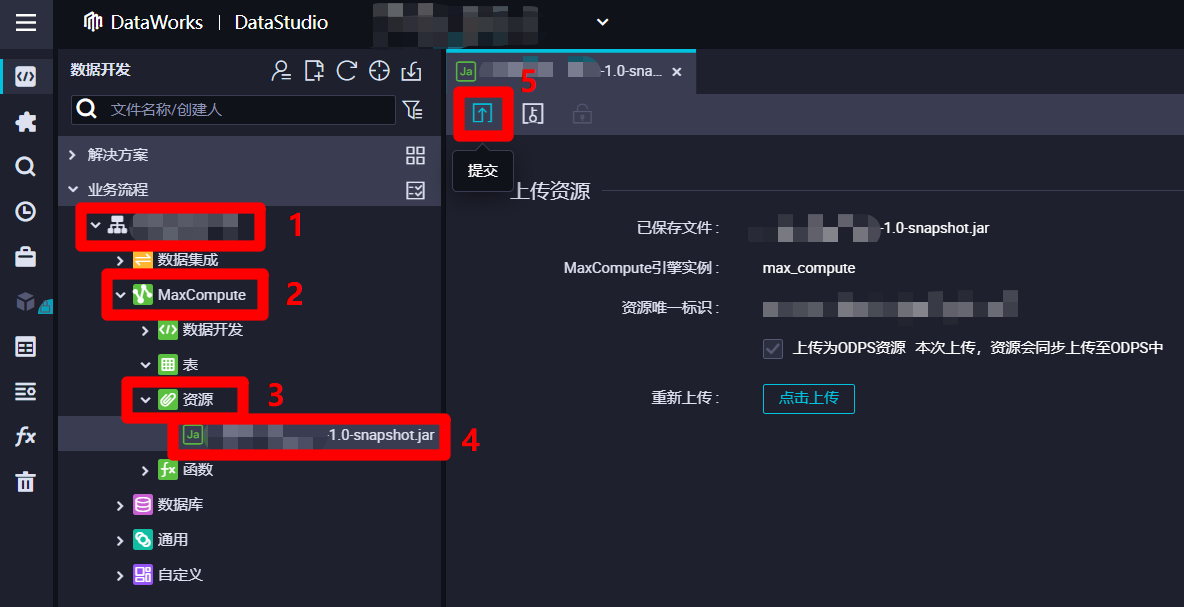
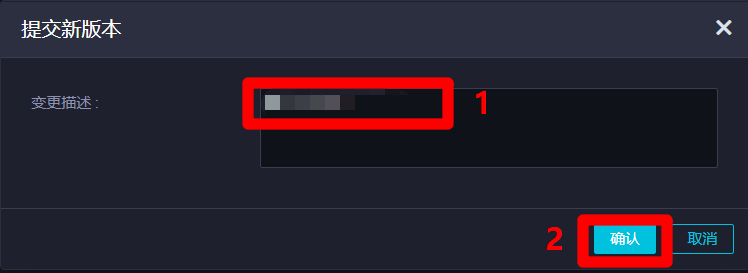
在"提交新版本"弹出框中,自主填写"变更描述",然后点击"确认",完成资源的提交。资源提交成功后,在业务流程正式运行的时候,节点才能找到此资源。
十一、创建并配置ODPS MR节点
官方文档:创建ODPS MR节点
步骤图示:
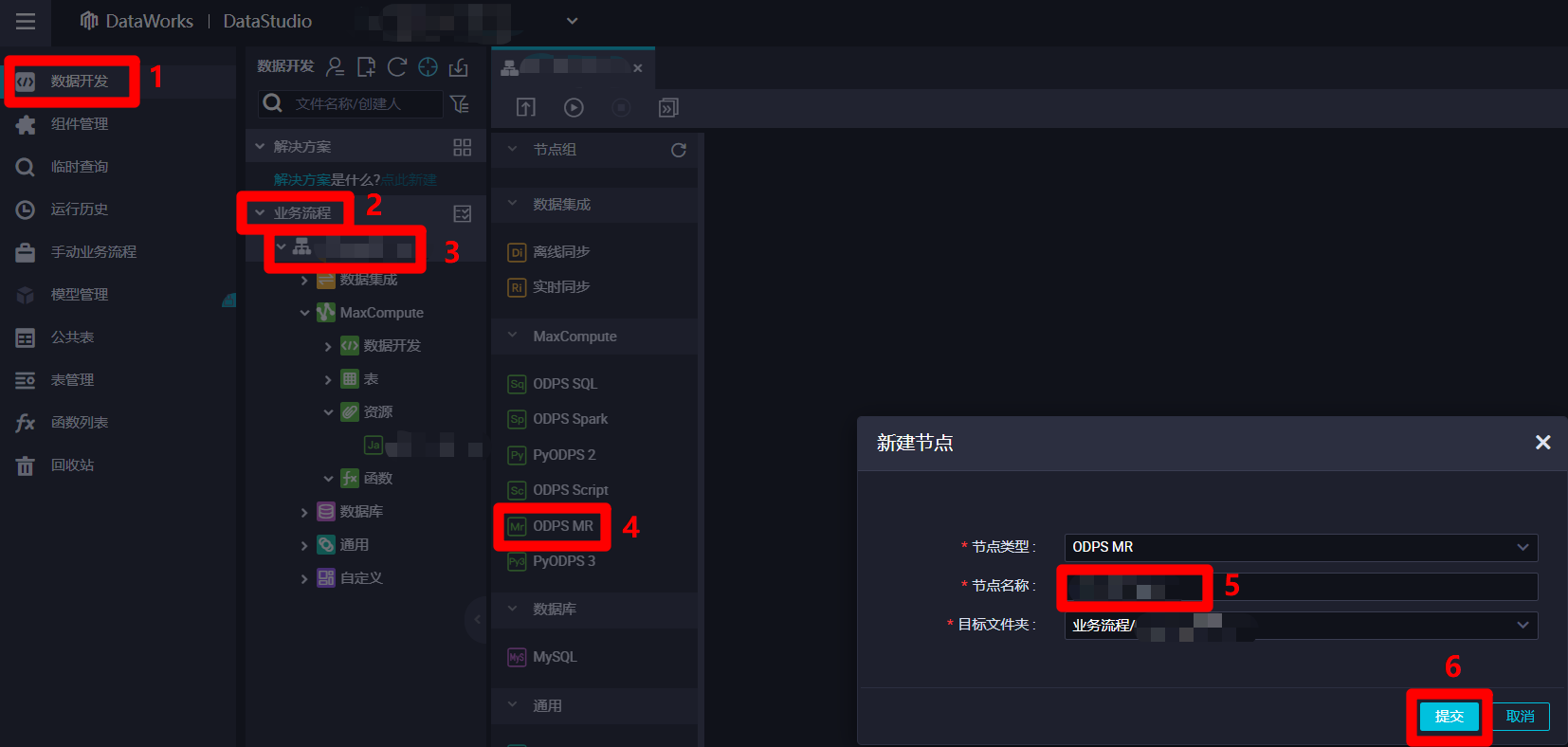
在阿里云的"DataStudio(数据开发)"页面中,点击左侧菜单栏中的"数据开发"项,菜单栏右边的页面会切换到"数据开发"页面。在"数据开发"页面中,展开"业务流程"列表,在"业务流程"列表中,双击目标业务流程,打开目标业务流程的编辑页面。在业务流程编辑页面的左侧菜单栏中双击"ODPS MR"项,会出现"新建节点"弹出框。在"新建节点"弹出框中,自主填写"节点名称",然后点击"提交"按钮,完成ODPS MR节点的创建。
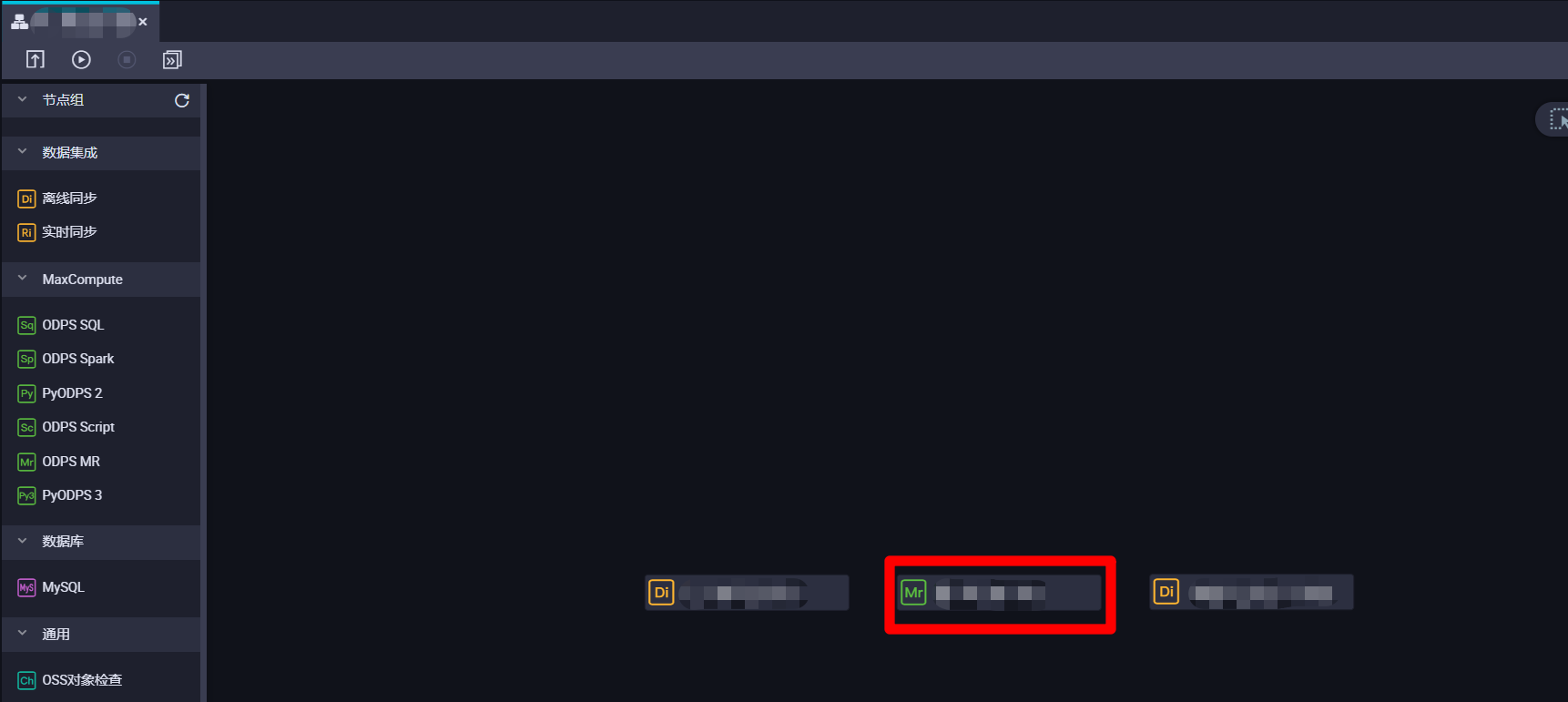
完成ODPS MR节点的创建后,在业务流程的编辑页面中,双击刚创建的ODPS MR节点,进入ODPS MR节点的编辑页面。
在ODPS MR节点的编辑页面中,编辑区域的末尾添加一行代码:
--@resource_reference{""}。并将光标放到两个双引号之间,下一步准备引入刚添加的资源。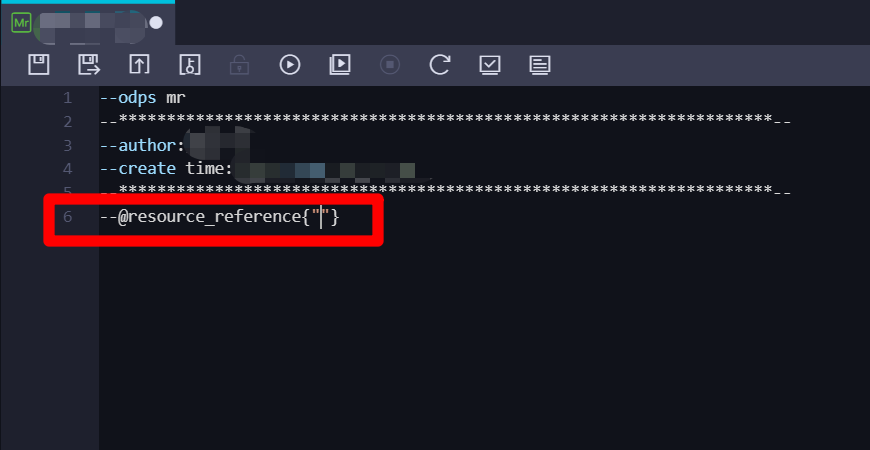
在ODPS MR节点编辑页面左边的"数据开发"页面中,展开当前业务流程的列表,在列表中依次展开"MaxCompute"、"资源"项,选中刚添加的JAR包资源,鼠标右击调出右键菜单。在右键菜单中点击"引用资源",刚才ODPS MR节点编辑区域的光标所在位置就会自动添加引用资源的名称,并在编辑区域的开头自动生成一行代码,下一步准备添加一行调用JAR包资源运行的代码。
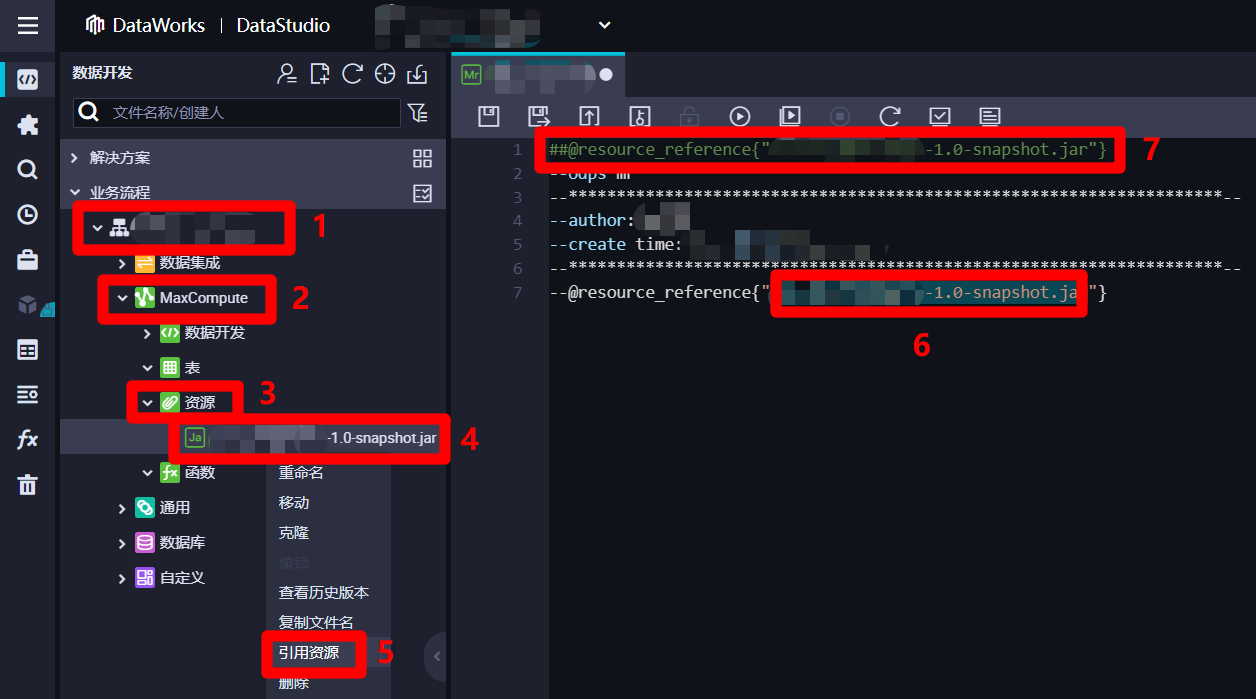
在编辑区域末尾,再添加一行调用JAR包资源的Driver类的main方法的代码,格式类似于
jar -resources *-*.*-SNAPSHOT.jar -classpath ./*-*.*-SNAPSHOT.jar *.*Driver <in_table>[|<partition_key>=<val>[/<partition_key>=<val>...]] <out_table>[|<partition_key>=<val>[/<partition_key>=<val>...]]。此行代码的前半部分("in_table"之前的部分),用于指定调用的JAR包资源的名称和位置,以及其中的Driver类的全类名;代码的后半部分("in_table"以后的部分),是Driver类中main方法的入参(对应形参String[] args),因此后半部分MaxCompute输入表与输出表的代码格式,是根据之前自主编写Driver类时main方法中的解析方式来填写的,上面的示例代码仅供参考,请自主完善。本次实践中,MaxCompute输入表或输出表需要指定时间分区,也跟之前一样使用调度参数动态指定,因此在调度配置边栏的"基础属性"模块下的"参数"文本框中输入:p_yyyymmdd=$[yyyymmdd-10/24/60] p_hh=$[hh24-10/24/60] p_mi=$[mi-10/24/60],在MaxCompute输入表与输出表指定分区的代码部分填写内容:partition_day=${p_yyyymmdd}/partition_hour=${p_hh}/partition_minute=${p_mi}。完成ODPS MR节点的代码编辑后,下一步准备进行其调度配置。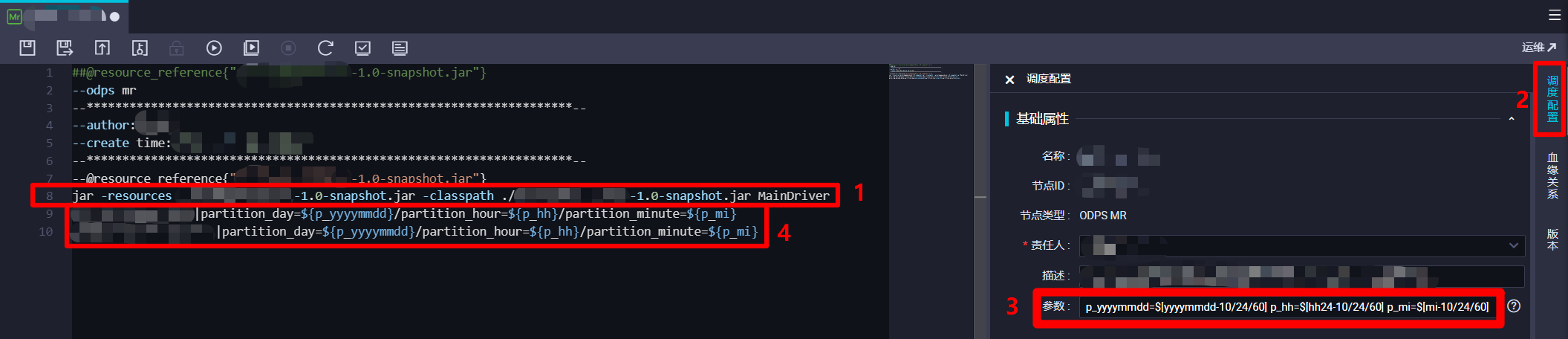
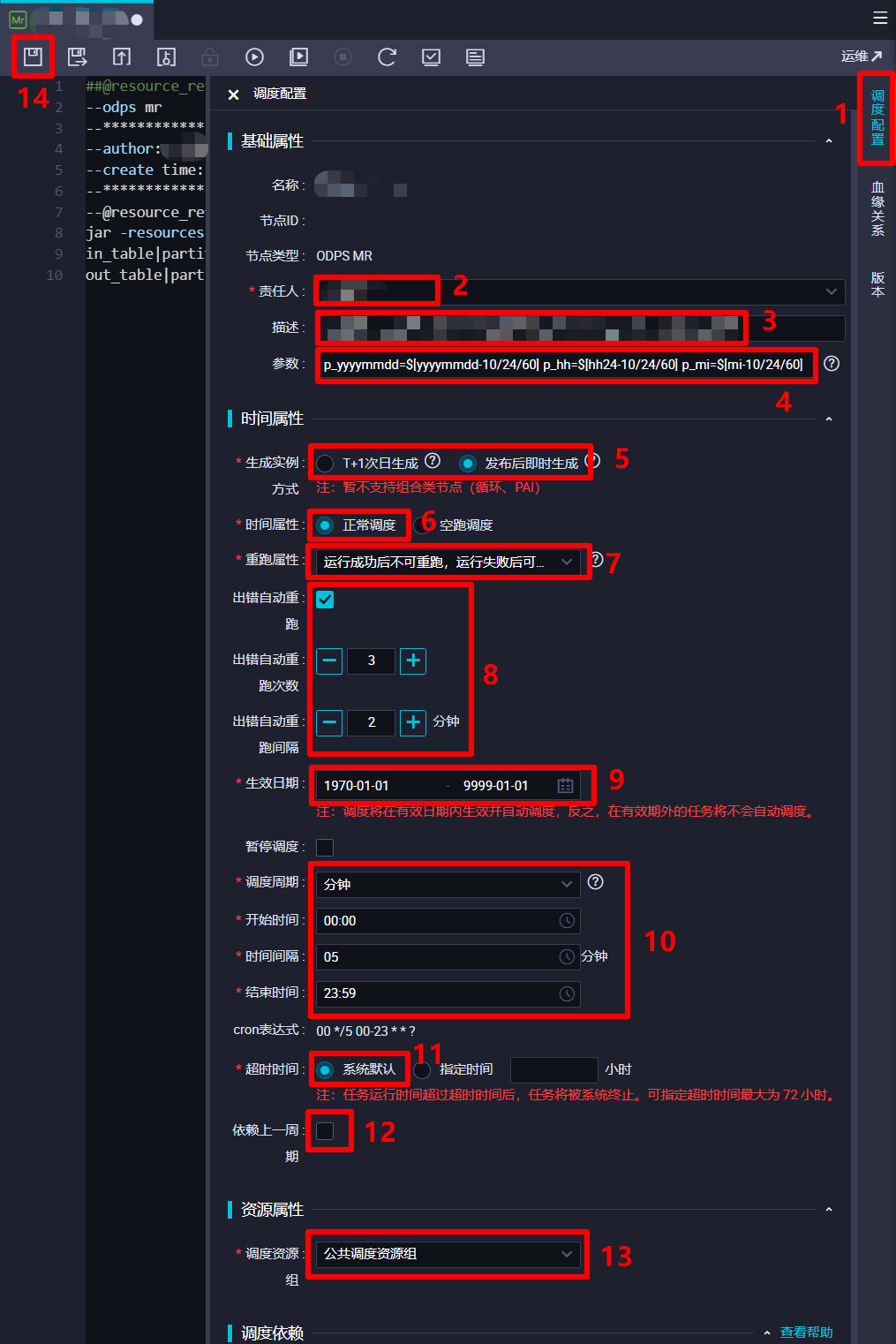
在调度配置边栏中,对该ODPS MR节点的调度配置进行完善。在"基础属性"模块中,"责任人"选择当前登录的RAM账号;自主填写"描述";"参数"的填写内容上一步中已完成,不再赘述。在"时间属性"模块中,自主选择"生成实例方式",为方便后面快速测试,此次实践选择"发布后即时生成";"时间属性"选择"正常调度";自主选择"重跑属性",通常选择"运行成功后不可重跑,运行失败后可以重跑";勾选"出错自动重跑",自主选择"出错自动重跑次数"、"出错自动重跑间隔",此次实践使用其默认配置的次数与间隔;自主选择"生效日期",此次实践使用其默认配置,让同步任务一直保持生效状态;由于此次实践希望整个业务流程的运行周期间隔尽量短一些,所以设置"调度周期"为"分钟","开始时间"设置为"00:00"(被限制只能设置整时),"时间间隔"设置为最短的"05","结束时间"设置为"23:59"(被限制只能设置小时),以确保该节点跨天也会每五分钟运行一次;自主选择"超时时间",此次实践选择"系统默认";不勾选"依赖上一周期",这样某一周期运行出错不会影响之后的运行周期。"资源属性"模块的"调度资源组"选择默认的"公共调度资源组"即可。"调度依赖"模块暂时不进行配置。"节点上下文"模块在此次实践中不需要配置。完成以上调度配置后,点击页面上方菜单栏的保存按钮,完成对ODPS MR节点的创建与配置。
十二、关联各个节点
官方文档:配置节点的调度和依赖属性
步骤图示:
目前业务流程里总共创建并配置了三个节点:一个从MongoDB表到MaxCompute表的离线同步节点,用于获取日志数据,每次同步执行时间往前五分钟到执行时间的数据;一个从MaxCompute表到MaxCompute表的ODPS MR节点节点,用于解析日志数据,每次同步执行时间往前十分钟到执行时间往前五分钟的数据;一个从MaxCompute表到MongoDB表的离线同步节点,用于输出日志数据,每次同步执行时间往前十五分钟到执行时间往前十分钟的数据。本次实践中,这三个节点在业务流程中并行运行,互相之间不存在上下游关系,因此将这三个节点的父节点均设置为工作空间根节点即可。下面进行步骤演示,对三个节点执行同样的操作即可。首先选中一个节点双击,进入节点编辑页面。
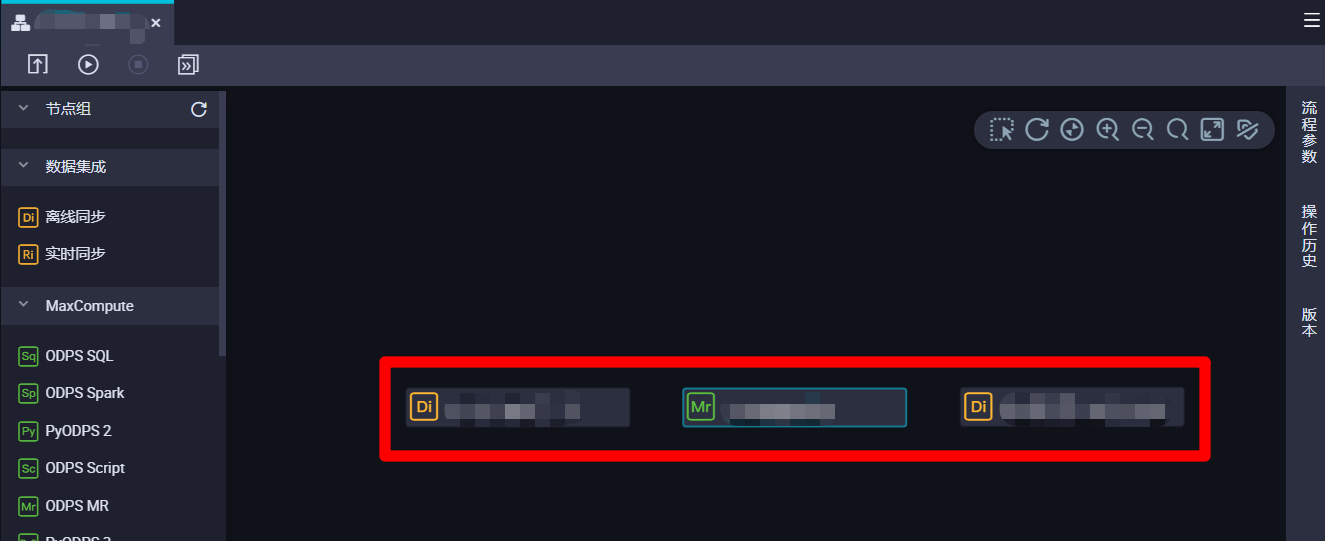
在节点编辑页面右端展开"调度配置"边栏,然后在调度配置边栏的"调度依赖"模块下的参数项"依赖的上游节点"后面点击"使用工作空间根节点"按钮,下面的父节点列表中会自动添加一条工作空间根节点数据。然后点击页面上方菜单栏的提交按钮,会出现"请注意"弹出框。
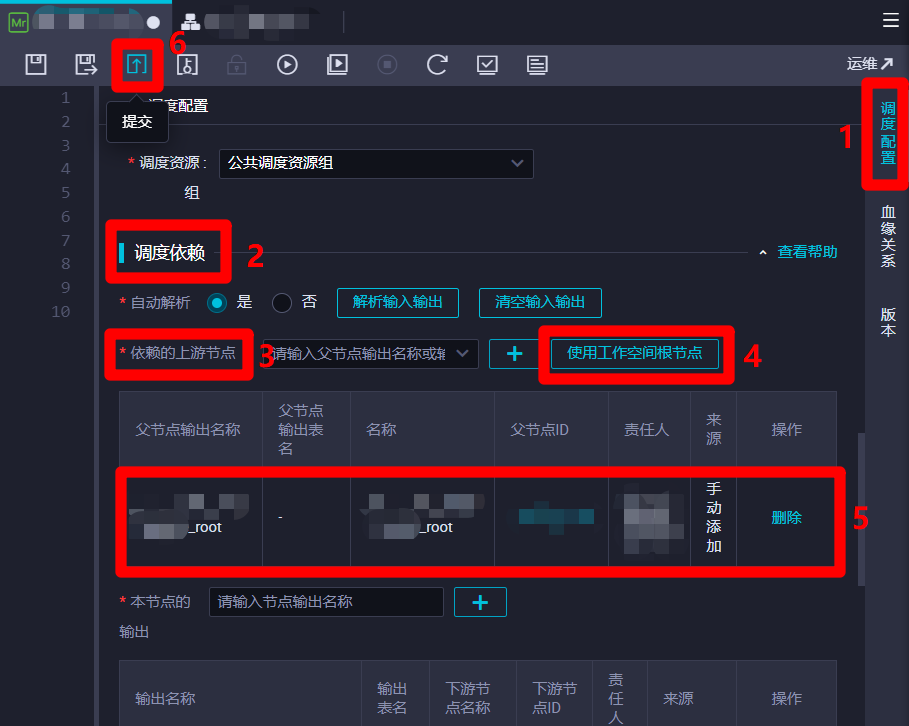
在"请注意"弹出框中,点击"确认"保存修改。保存成功后,会出现"提交新版本"弹出框。
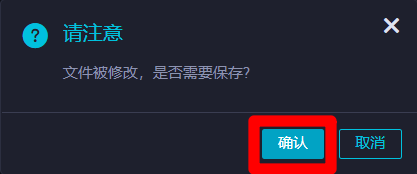
在"提交新版本"弹出框中,自主填写"变更描述",然后点击"确认",完成节点的提交。节点提交后,该节点就会正式运行,开始进行周期调度。至此完成将三个节点绑定到工作空间根节点下的操作,并将三个节点成功进行了提交。
十三、提交业务流程并查看运行结果
官方文档:节点运行及排错
步骤图示:
上一步中,业务流程中的三个节点已经成功进行了提交并开始运行,而在业务流程编辑页面中,点击上方菜单栏的提交按钮,也可以对节点进行统一提交。
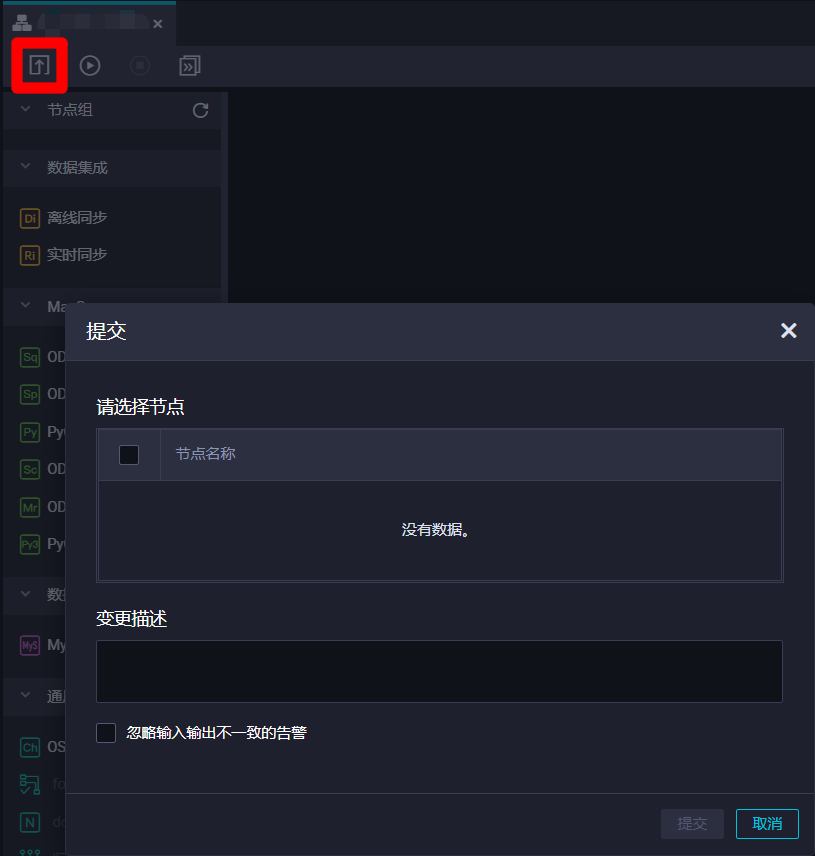
业务流程提交并运行后,我们可以点击页面上方菜单栏中的前往运维按钮,或者页面右上角的"运维中心"链接,打开DataWorks的"运维中心(工作流)"页面,准备查看各个节点周期任务的运行结果。

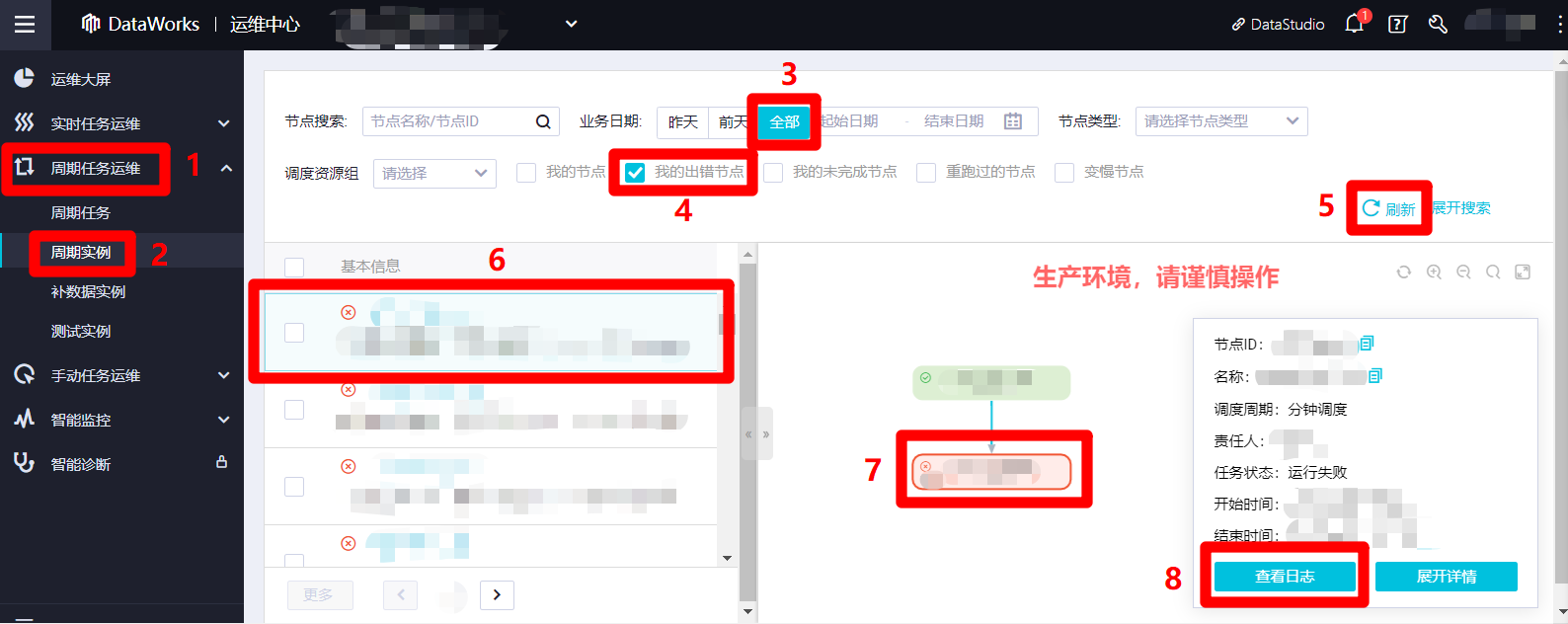
在"运维中心(工作流)"页面左侧菜单栏中展开"周期任务运维"项,在子菜单中点击"周期实例",切换到周期实例列表页面。在周期实例列表页面上方搜索栏中,搜索条件的"业务日期"(业务日期为实际运行日期的前一天)选择"全部",勾选"我的出错节点",自主调整其他搜索选项,点击搜索栏右下角的"刷新"可以更新搜索结果。在下方周期实例列表中点选一个出错实例,列表右侧会出现该出错实例的详情页面。在详情页面中,点选目标出错节点,页面右下角会出现该节点信息的弹出框。在弹出框中点击查看日志,可以打开该出错节点运行时的日志详情页面。根据异常日志内容,我们就可以找到出错原因,进行对应的调整,确保整个业务流程的正常运行。
结语
- 本次实践中,虽然购买使用了独享数据集成资源组,实际上使用公共数据集成资源组也可实现本实践的功能需求。若没有购买独享数据集成资源组,能将整个业务流程的成本降到最低,只需支付MaxCompute服务的流量费用。
- 本次实践仅使用了阿里云的离线同步、离线计算功能,如果要使用实时同步、实时计算功能,通常需要购买开通相应的服务。
- 使用RAM账号操作过程中,经常会出现权限不足的情况,这时候用另一种浏览器登录主账户,即可较为方便地在一台电脑上进行授权或购买阿里云服务,避免在一个浏览器上来回登录。
- 在实践过程中经常会出现陌生的术语,或者找不到某一个需求对应的模块在哪里,或者操作过程中出现了错误进行不下去,可以多在阿里云关键字搜索页面中思考关键字查询对应的文档,实在解决不了,就提交工单咨询阿里云的技术人员即可。
阿里云DataWorks实践:数据集成+数据开发的更多相关文章
- 【阿里云-大数据】阿里云DataWorks学习视频汇总
阿里云DataWorks学习视频汇总 注意:本文档中引用的视频均来自阿里云官方的帮助文档,本文档仅仅是汇总整理,方便学习. 阿里云DataWorks帮助文档链接:https://help.aliyun ...
- 阿里云DataWorks正式推出Stream Studio:为用户提供大数据实时计算的数据中台
5月15日 阿里云DataWorks正式推出Stream Studio,正式为用户提供大数据的实时计算能力,同时标志着DataWorks成为离线.实时双计算领域的数据中台. 据介绍,Stream St ...
- 阿里云377秒完成100TB数据排序:秒三星百度
阿里云377秒完成100TB数据排序:秒三星百度 今日,Sort Benchmark 在官方网站公布了 2015 年排序竞赛的最终成绩.其中,阿里云用不到 7 分钟(377 秒)就完成了 100TB ...
- 阿里云dataworks数据工场用户使用子账号
如果您是第一次使用子账号登录数加平台和使用DataWorks,您需要获知以下内容: 该子账号所属主账号的企业别名. 该子账号的用户名和密码. 该子账号的AccessKey ID和AccessKey S ...
- 重磅干货免费下载!阿里云RDS团队论文被数据库顶会SIGMOD 2018收录
ACM SIGMOD数据管理国际会议是由美国计算机协会(ACM) 数据管理专业委员会(SIGMOD)发起.在数据库领域具有最高学术地位的国际性学术会议. SIGMOD和另外两大数据库会议VLDB.IC ...
- 初探Node-red结合阿里云数据库,定时显示数据
在最近的项目中,隔壁项目组推荐了一个很好的基于node.js开源IOT框架Node-Red,它的优点很明显,使用可视化编程的方式,实现了大部分需要在物联网领域的技术,而且能很好的对接各个云平台,快捷部 ...
- 实时计算轻松上手,阿里云DataWorks Stream Studio正式发布
Stream Studio是DataWorks旗下重磅推出的全新子产品.已于2019年4月18日正式对外开放使用.Stream Studi是一站式流计算开发平台,基于阿里巴巴实时计算引擎Flink构建 ...
- 阿里云API网关(7)开发指南-API参考
网关指南: https://help.aliyun.com/document_detail/29487.html?spm=5176.doc48835.6.550.23Oqbl 网关控制台: https ...
- CDH6.1.1阿里云安装实践
概念介绍 CDH概览 CDH是Apache Hadoop和相关项目的最完整.最受测试和最流行的发行版.CDH提供Hadoop的核心元素-可伸缩存储和分布式计算-以及基于web的用户界面和重要的企业功能 ...
随机推荐
- Java安全之jar包调试技巧
Java安全之jar包调试技巧 调试程序 首先还是创建一个工程,将jar包导入进来 调试模式的参数 启动中需要加入特定参数才能使用debug模式,并且需要开放调试端口 JDK5-8: -agentli ...
- F - Team Queue
有n个队伍. 对于每个ENQUEUE x 命令. 如果x所在的队伍已经在队列中, 则x排在队列中它的队伍的尾巴, 否则排在队列的末尾. 可以理解为队列中的队列的味道. Queues and Prio ...
- HDU-6703 array (线段树)
题意 一个长度为n的排列a,\(\forall i\in [1,n] ,1\le a_i \le n\) , m次操作,每次操作: (1,pos),把 \(a_{pos}\) 变为\(a_{pos} ...
- HDU4622 Reincarnation【SAM】
HDU4622 Reincarnation 给出一个串,每次询问其一个子串有多少不同的子串 按每个后缀建立\(SAM\)不断往后加字符,然后记录答案,查询的时候直接用即可 //#pragma GCC ...
- Codeforces Round #340 (Div. 2) E. XOR and Favorite Number
time limit per test 4 seconds memory limit per test 256 megabytes input standard input output standa ...
- Musical Theme POJ - 1743 后缀数组
A musical melody is represented as a sequence of N (1<=N<=20000)notes that are integers in the ...
- 使用docker时报错“net/http: TLS handshake timeout”
问题原因 :该命令默认从docker远端镜像仓库中拉取镜像,但由于远端仓库的服务器是在国外,我们国内有的用户很可能都访问不到 解决:使用国内镜像仓库 docker pull registry.dock ...
- .Net反编译实践记录
去壳 去壳可以使用 de4dot,源码在 这里.可用版本 下载地址. 使用方式为:.\de4dot.exe [path] 修改代码 反编译修改代码可以使用 dnSpy,源码在 这里.可用版本 下载地址 ...
- Redis 主从复制(Replication)
为了保证服务的可用性,现代数据库都提供了复制功能,同时在多个进程中维护一致的数据状态. Redis 支持一主多从的复制架构,该功能被简化成了一条 SLAVEOF 命令,下面通过条命令来解析 Redis ...
- Leetcode(105)-从前序与中序遍历序列构造二叉树
根据一棵树的前序遍历与中序遍历构造二叉树. 注意:你可以假设树中没有重复的元素. 例如,给出 前序遍历 preorder = [3,9,20,15,7] 中序遍历 inorder = [9,3,15, ...