ARM函数调用总结
ARM架构寄存器介绍
ARM架构下处理器有7种工作模式:
1. USR模式:正常用户模式,在USR模式下进程正常执行
2. FIQ模式(Fast Interrupt Request):处理快速中断模式,用于高速数据传送或者通道处理。
3. IRQ模式((Interrupt Request):用于处理普通中断。
4. SVC模式(Supervisor):操作系统的保护模式,用于处理软件中断。
5. ABT中止模式(Abort mode):处理存储器故障模式、实现虚拟存储器和存储器保护两种功能。
6. UND 未定义(Undefined):处理未定义的指令陷阱,并且支持硬件协处理器的软件仿真。
7. SYS 系统模式(System):操作系统模式,用于运行特权操作系统任务。
在这7种模式中,除开USR用户模式之外的其余6种模式都被称为特权模式。在特权模式下的程序能够访问全部的系统资源,也能够随意地完成处理器模式的切换。而除开系统模式外的五种特权模式又称为异常模式。大多数的用户程序运行在用户模式下。如果需要切换处理器模式的时候,程序会抛出异常处理,模式的切换便会在异常处理中完成。
在ARM架构中一共有 37 个寄存器(包含了31个通用寄存器和6个状态寄存器):
1. 31个通用寄存器包括:
R0-R15, R13_svc, R14_svc, R13_abt, R14_abt, R13_und, R14_und, R13_irq, R14_irq, R8_fiq-R14_fiq
2. 6个状态寄存器包括:
CPSR, SPSR_svc, SPSR-abt, SPSR_und, SPSR_irq, SPSR_fiq
这里主要对通用寄存器做介绍:
1. 不分组寄存器R0~R7
在所有模式下,未分组寄存器都代表着一个物理寄存器,不分组寄存器没有被操作系统用作特定用途。
2. 分组寄存器R8~R12
当前所访问的寄存器与现在处理器运行的模式有关。当处于fiq快速中断模式的时候,访问的寄存器是R8_fiq~R12_fiq;而在除开fiq模式以外模式时,访问的寄存器是R8~R12。
其中R11又被称为FP寄存器,即frame pointer栈帧指针寄存器。
R12是内部调用暂时寄存器 ip。它在过程链接胶合代码中用于此角色。在过程调用之间,可以将它用于任何用途。被调用函数在返回之前不必恢复 R12。
3. R13、R14:
R13,R4寄存器分别对应着6个不同的物理寄存器
用户模式与系统模式共用同一种寄存器外,其余5个物理寄存器对应其余5种运行模式。为方便区分采用对应模式的记号来区分不同的物理寄存器:R13_,R14_ R13_usr、R13_fiq、R13_irq、R13_svc、R13_abt、R13_und,R14_usr、R14_fiq、R14_irq、R14_svc、R14_abt、R14_und。
R13/sp:R13在ARM指令集中通常用作堆栈指针。
R14/lr:R14被称为子程序连接寄存器或者连接寄存器LR。在执行BL子程序调用指令的时候,可以从R14中得到R15(程序计数器PC)的备份。在其他情况下,R14可以当作普通的通用寄存器。
在7种模式下,LR都能够用于保存子程序的返回地址。当采用BL或BLX指令调用子程序时,处理器会把PC的当前值复制到R14中;然后在执行完子程序后,再将R14的值返回到PC中,处理器通过这种方法完成子程序的调用返回。
4. 程序计数器—R15/PC
R15时程序计数器(PC)所对应的物理寄存器,因为ARM体系结构采用多级流水线技术, R15会指向当前指令后两条指令的地址,即PC读取值为当前指令的地址再加8个字节。PC寄存器中目前所保存的值即为下一条执行的指令。
ARM架构函数调用过程介绍
简单程序分析,当参数小于4个时:
/*test1.c*/
#include <stdio.h> int foo1(int m,int n,int p)
{
int x = m + n + p;
return x;
} int main(int argc,char** argv)
{
int x,y,z,result;
x=;
y=;
z=;
result = foo1(x,y,z);
printf("result=%d\n",result);
return ;
}
在main函数中定义了x,y,z,result,四个局部变量,然后调用了foo1()函数做进一步加法,并且返回最后得到的值。程序用arm-linux-gcc静态编译后得到可以在arm开发板上可执行程序test1,利用arm-linux-objdump对逆向后可以得到我们需要的可执行程序汇编代码:
//省略不相关代码
0000826c <foo1>:
826c: e52db004 push {fp} ; (str fp, [sp, #-]!)
: e28db000 add fp, sp, #
: e24dd01c sub sp, sp, #
: e50b0010 str r0, [fp, #-]
827c: e50b1014 str r1, [fp, #-]
: e50b2018 str r2, [fp, #-]
: e51b2010 ldr r2, [fp, #-]
: e51b3014 ldr r3, [fp, #-]
828c: e0822003 add r2, r2, r3
: e51b3018 ldr r3, [fp, #-]
: e0823003 add r3, r2, r3
: e50b3008 str r3, [fp, #-]
829c: e51b3008 ldr r3, [fp, #-]
82a0: e1a00003 mov r0, r3
82a4: e28bd000 add sp, fp, #
82a8: e8bd0800 pop {fp}
82ac: e12fff1e bx lr 000082b0 <main>:
82b0: e92d4800 push {fp, lr}
82b4: e28db004 add fp, sp, #
82b8: e24dd010 sub sp, sp, #
82bc: e3a0300b mov r3, #
82c0: e50b3014 str r3, [fp, #-]
82c4: e3a03016 mov r3, #
82c8: e50b3010 str r3, [fp, #-]
82cc: e3a03021 mov r3, # ; 0x21
82d0: e50b300c str r3, [fp, #-]
82d4: e51b0014 ldr r0, [fp, #-]
82d8: e51b1010 ldr r1, [fp, #-]
82dc: e51b200c ldr r2, [fp, #-]
82e0: ebffffe1 bl 826c <foo1>
82e4: e1a03000 mov r3, r0
82e8: e50b3008 str r3, [fp, #-]
82ec: e59f301c ldr r3, [pc, #] ; <main+0x60>
82f0: e1a00003 mov r0, r3
82f4: e51b1008 ldr r1, [fp, #-]
82f8: eb000347 bl 901c <_IO_printf>
82fc: e59f0010 ldr r0, [pc, #] ; <main+0x64>
: eb000354 bl <_IO_puts>
: e24bd004 sub sp, fp, #
: e8bd4800 pop {fp, lr}
830c: e12fff1e bx lr
: andeq r3, r6, r4, lsl r2
: andeq r3, r6, r0, lsr #
//省略不相关代码
将程序test1拷贝到arm开发板中,利用gdbserver开始调试。

在main函数开始执行前,在栈空间中就有其他数据了,在此时test1的栈空间布局大致如下图所示:

完成foo1函数栈底和栈顶的确定后,程序继续完成参数传递的过程。此时r0,r1,r2寄存器中分别保存着11,22,33,test1程序会将三个参数通过寄存器压入foo1函数的栈空间中:
Str r0, [r11, #-16]
Str r1, [r11, #-20]
Str r2, [r11, #-16]
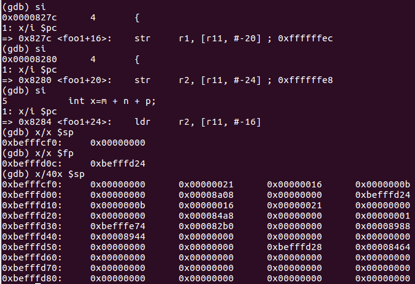
Foo1函数栈空间也因此改变:

完成参数传递后,程序将会开始执行int x=m + n + p;而整个加法过程都是借助寄存器中完成的,然后程序期望将得到的值返回到main函数中,因此需要将结果放入到r0寄存器中,在此过程中,栈并没有发生变化。
ldr r3, [r11, #-8]
mov r0, r3
接下来程序将会执行返回到main函数的过程,sp指针返回到栈底地址后,然后执行指令ldmfd sp!,{r11}(以sp存放的数据作为地址,将地址中的数据加载进r11中,然后sp+4,)sp指针已经返回到了main函数的栈顶,fp指向了main函数的main函数的栈底。此时lr寄存器的值为0x82e4,

在执行bx lr指令后,返回到main函数中,pc(下一条指令)为0x82e4
当参数大于4的时候:
/*test2.c*/
#include <stdio.h> int foo1(int m,int n, int p,int q,int i,int j)
{
int x=m + n + p + q + i + j;
return x;
}
void main()
{ int x,y,z,a,b,c,result;
x=;
y=;
z=;
a=;
b=;
c=;
result = foo1(x,y,z,a,b,c);
printf("result=%d\n",result);
printf("hello world\n");
}
用与test1相同的方法可以得到test2和其汇编代码:
//省略不相关代码
0000826c <foo1>:
826c: e52db004 push {fp} ; (str fp, [sp, #-]!)
: e28db000 add fp, sp, #
: e24dd01c sub sp, sp, #
: e50b0010 str r0, [fp, #-]
827c: e50b1014 str r1, [fp, #-]
: e50b2018 str r2, [fp, #-]
: e50b301c str r3, [fp, #-]
: e51b2010 ldr r2, [fp, #-]
828c: e51b3014 ldr r3, [fp, #-]
: e0822003 add r2, r2, r3
: e51b3018 ldr r3, [fp, #-]
: e0822003 add r2, r2, r3
829c: e51b301c ldr r3, [fp, #-]
82a0: e0822003 add r2, r2, r3
82a4: e59b3004 ldr r3, [fp, #]
82a8: e0822003 add r2, r2, r3
82ac: e59b3008 ldr r3, [fp, #]
82b0: e0823003 add r3, r2, r3
82b4: e50b3008 str r3, [fp, #-]
82b8: e51b3008 ldr r3, [fp, #-]
82bc: e1a00003 mov r0, r3
82c0: e28bd000 add sp, fp, #
82c4: e8bd0800 pop {fp}
82c8: e12fff1e bx lr 000082cc <main>:
82cc: e92d4800 push {fp, lr}
82d0: e28db004 add fp, sp, #
82d4: e24dd028 sub sp, sp, # ; 0x28
82d8: e3a0300b mov r3, #
82dc: e50b3020 str r3, [fp, #-]
82e0: e3a03016 mov r3, #
82e4: e50b301c str r3, [fp, #-]
82e8: e3a03021 mov r3, # ; 0x21
82ec: e50b3018 str r3, [fp, #-]
82f0: e3a0302c mov r3, # ; 0x2c
82f4: e50b3014 str r3, [fp, #-]
82f8: e3a03037 mov r3, # ; 0x37
82fc: e50b3010 str r3, [fp, #-]
: e3a03042 mov r3, # ; 0x42
: e50b300c str r3, [fp, #-]
: e51b3010 ldr r3, [fp, #-]
830c: e58d3000 str r3, [sp]
: e51b300c ldr r3, [fp, #-]
: e58d3004 str r3, [sp, #]
: e51b0020 ldr r0, [fp, #-]
831c: e51b101c ldr r1, [fp, #-]
: e51b2018 ldr r2, [fp, #-]
: e51b3014 ldr r3, [fp, #-]
: ebffffcf bl 826c <foo1>
832c: e1a03000 mov r3, r0
: e50b3008 str r3, [fp, #-]
: e59f301c ldr r3, [pc, #] ; <main+0x8c>
: e1a00003 mov r0, r3
833c: e51b1008 ldr r1, [fp, #-]
: eb000349 bl 906c <_
//省略不相关代码
由于在test2中将会继续执行result = foo1(x,y,z,a,b,c);因此需要将参数传递到foo1函数中,但是由于参数大于4个参数,r0-r3寄存器不能将其全部传递,因此后两个参数通过栈来完成参数传递的目的,前四个参数依然通过r0-r3的4个寄存器来传递。

而寄存器r0=11,r1=22,r2=33,r3=44
foo1函数栈空间的开辟,将r0-r3寄存器中存储的数据拷贝到栈中
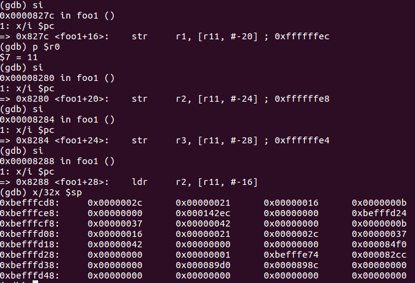
栈布局变化为

前四个参数都从栈上拷贝到寄存器中并且完成了加法,得到结果r2=110(11+22+33+44)
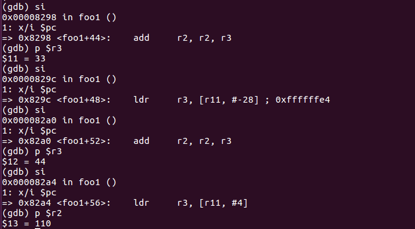
在加法过程中我们可以发现55与66并没有保存在foo1的栈空间中,而是在栈顶fp的上方,因此需要将位于栈顶上方的值(也就是位于main函数栈底的值)拷贝进入寄存器再进行操作。
ldr r3, [fp, #]
dd r2, r2, r3
ldr r3, [fp, #]
add r3, r2, r3
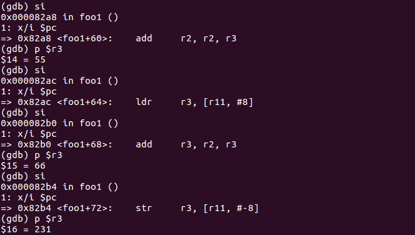
终于得到了最后的结果r3=231(110+55+66),由于后续操作与test1类似,就不再赘述了。
Arm架构函数调用总结
1.在开始函数调用时,将新函数所需要的参数赋值分别给从r0开始到r3为止的寄存器,若大于4个参数时,将其余的参数压入栈中。
2.然后调用bl指令将pc寄存器中的地址赋值给lr寄存器作为子函数的返回地址,并且将子函数的地址拷贝到pc中,由此离开原函数进入到子函数中。
3.将r11(原函数的栈底地址)压入栈中,作为子函数的栈底fp,并把此时栈底地址放入r11中,sp移动预留局部变量存储空间,确定了子函数的栈底和栈顶地址。
4.将r0到r3寄存器存储的值复制到子函数的栈中,然后开始进一步操作
5. 在完成子函数目的后,将需要返回的值放入r0寄存器,利用ldmfd指令出栈,然后利用bx lr返回原函数中,完成整个函数调用过程。
ARM函数调用总结的更多相关文章
- 通过反汇编理解函数调用机制(x86和ARM)
如下,一个简单的程序 #include <stdio.h> int add(int a, int b) { return a + b; } void main() { , b = ; in ...
- ARM系统中函数调用过程中的参数传递-转
在 嵌入式软件编程中,经常会用到函数调用,之前在学习如何在C语言中嵌入汇编时有了解到C语言之前的参数调用是使用寄存器R0传递第一个参数,R1传递到第 二个..一直到R3传递第四个参数.但是实际上有时可 ...
- ARM 汇编与C调用的若干问题(一般函数调用情况)
ARM 汇编与C之间的函数调用需要符合ATPCS,建议函数的形参不超过4个,如果形参个数少于或等于4,则形参由R0,R1,R2,R3四个寄存器进行传递:若形参个数大于4,大于4的部分必须通过堆栈进行传 ...
- ARM指令中的函数调用
1. 重要寄存器 SP 栈指针, 每一种异常模式都有其自己独立的r13,它通常指向异常模式所专用的堆栈,也就是说五种异常模式.非异常模式(用户模式和系统模式),都有各自独立的堆栈,用不同的堆栈指针来 ...
- ARM处理器的堆栈和函数调用,以及与Sparc的比较
主要描述一下ARM处理器的堆栈和函数调用过程,并和Sparc处理器进行对比分析. 主要内容来自以下网址.该网站是个学习ARM汇编的好地方.对该篇文章注解一下,并和Sparc对比. https://az ...
- iOS逆向工程之Hopper中的ARM指令
虽然前段时间ARM被日本软银收购了,但是科技是无国界的,所以呢ARM相关知识该学的学.现在看ARM指令集还是倍感亲切的,毕竟大学里开了ARM这门课,并且做了不少的实验,当时自我感觉ARM这门课学的还是 ...
- iOS程序破解——ARM汇编基础
原文在此:http://www.cnblogs.com/mddblog/p/4951650.html 一.Thumb指令与ARM指令 Thumb指令为16位,因此存储代码的密度高,节省存储空间.但是功 ...
- ARM Cortex-M0权威指南高清中文版pdf免费分享下载
版 次:1 页 数:433 字 数:655000 印刷时间:2013-8-1 开 本:16开 纸 张:胶版纸 印 次:1 包 装:平装 丛书名:清华开发者书库 国际标准书号ISBN:978730233 ...
- ARM 开发工具 Keil和DS-5的比较。
http://www.eeboard.com/bbs/thread-25219-1-1.html 如今ARM体系架构的处理器在嵌入式市场上呼风唤雨,从低端的MCU应用到高端的多媒体消费电子,移动设备领 ...
随机推荐
- Netty(二):如何处理io请求?
文接上一篇.上篇讲到netty暴露一个端口出来,acceptor, handler, pipeline, eventloop 都已准备好.但是并没体现其如何处理接入新的网络请求,今天我们就一起来看看吧 ...
- C#LeetCode刷题之#590-N叉树的后序遍历(N-ary Tree Postorder Traversal)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/4092 访问. 给定一个 N 叉树,返回其节点值的后序遍历. 例如 ...
- three.js 制作机房(上)
three.js使用的人太少了,一个博文就几百个人看,之前发js基础哪怕是d3都会有几千的阅读量,看看以后考虑说一说d3了,哈哈.吐槽完毕回归正题.前几天郭先生看到网上有人开发了3D机房,正愁博客没什 ...
- Android开发进程0.1 轮播图 Scrollview Fragment
轮播图的实现 轮播图通过banner可以较为便捷的实现 1.添加本地依赖,在dependence中搜索相关依赖 2.添加banner的view组件 3.创建适配器GlideImageLoader ex ...
- Mac开发工具
便捷管理你的Mac App Homebrew:https://brew.sh/index_zh-cn 强大的文本编辑器 Sublime Text:http://www.sublimetext.com ...
- ESLint 使用简介
C 语言诞生之初,程序员编写的代码风格各异,在移植时会出现一些因为不严谨的代码段导致无法被编译器执行的问题.于是在 1979 年,一款叫 lint[1] 的程序被开发出来,能够通过扫描源代码检测潜在的 ...
- powerMock和mockito使用
powerMock和mockito powermock和mockito都是做mock的框架,powermock在mockito的基础上扩展而来,支持mockito的操作(也支持别的mock框架比如ea ...
- 实战分享丨MySQL 与Django版本匹配相关经验
摘要:关于MySQL 与Django版本匹配相关知识的经验分享. run: (env) E:\PythonPro\PyDjangoProDemo011\xuanyuaniotpro>python ...
- 【Spring】看了这篇Spring事务原理,我才知道我对Spring事务的误解有多深!
写在前面 有很多小伙伴们留言说,冰河,你能不能写一篇关于Spring事务的文章呢?我:可以啊,安排上了!那还等什么呢?走起啊!! 事务的基本原理 Spring事务的本质其实就是数据库对事务的支持,没有 ...
- git pull冲突的解决方案
处理步骤: 1.先将本地修改存储起来 $ git stash 这样本地的所有修改就都被暂时存储起来 .使用git stash list可以看到保存的信息: git stash暂存修改 其中stash@ ...