Trino总结
文章目录
- 1.Trino与Spark SQL的区别分析
- 2.Trino与Spark SQL解析过程对比
- 3.Trino基本概念
- 4.Trino架构
- 5.Trino SQL执行流程
- 6.Trino Task执行流程
- 相关参考:
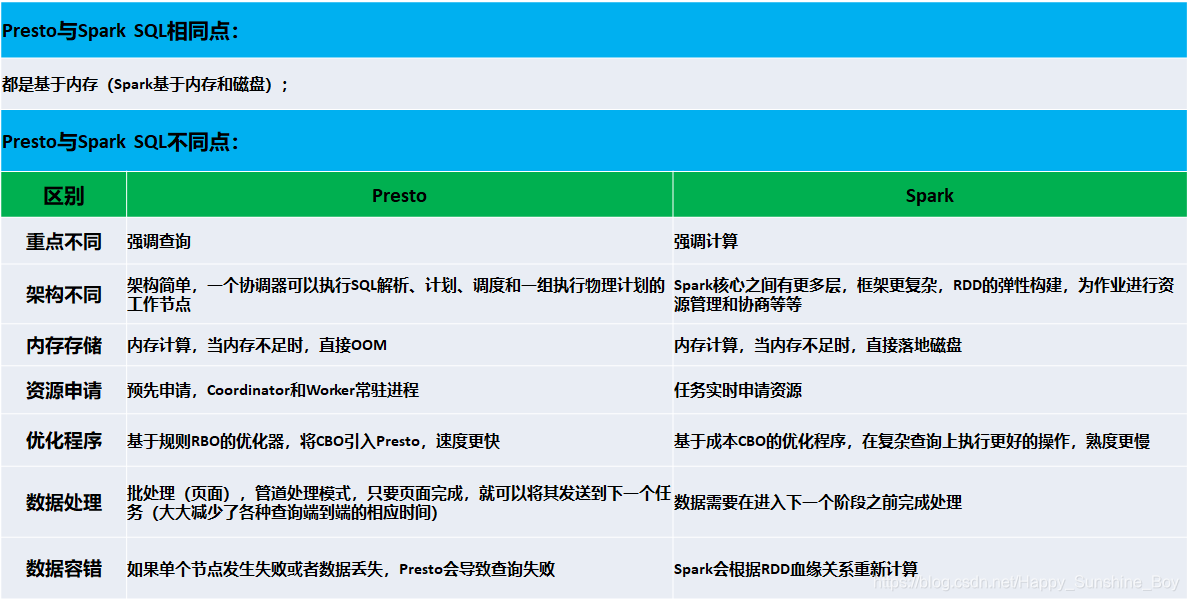
1.Trino与Spark SQL的区别分析
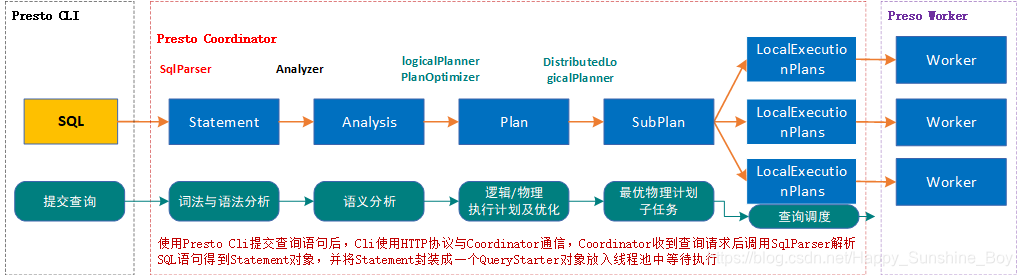
2.Trino与Spark SQL解析过程对比
- Trino
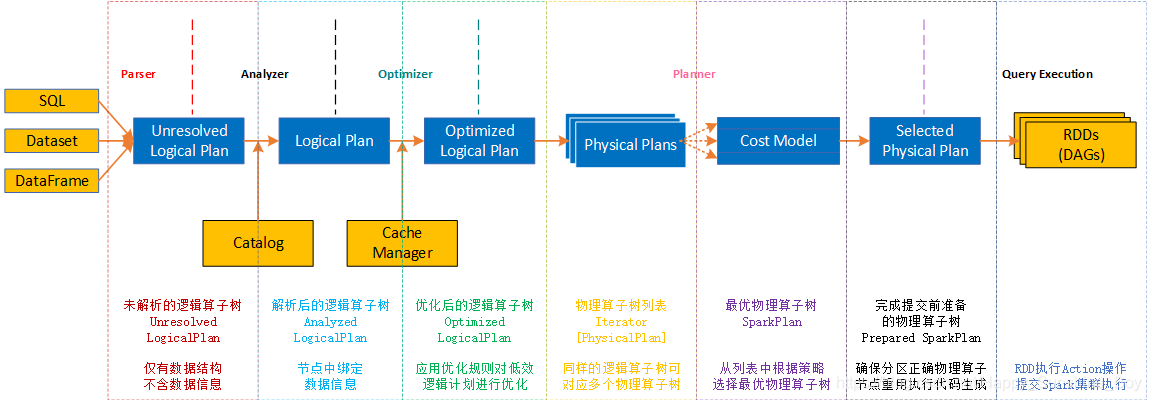
- Spark SQL
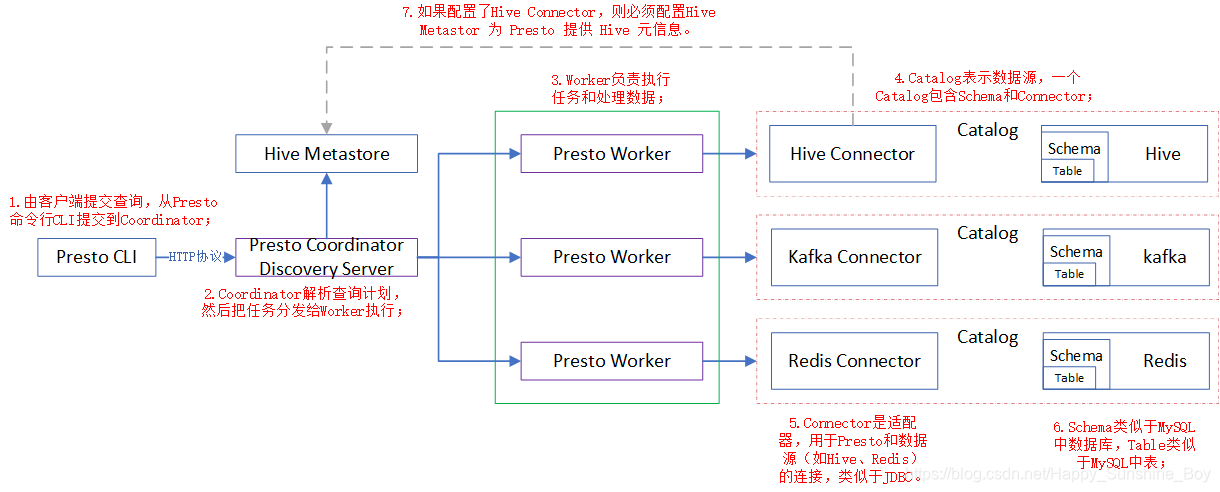
3.Trino基本概念

4.Trino架构

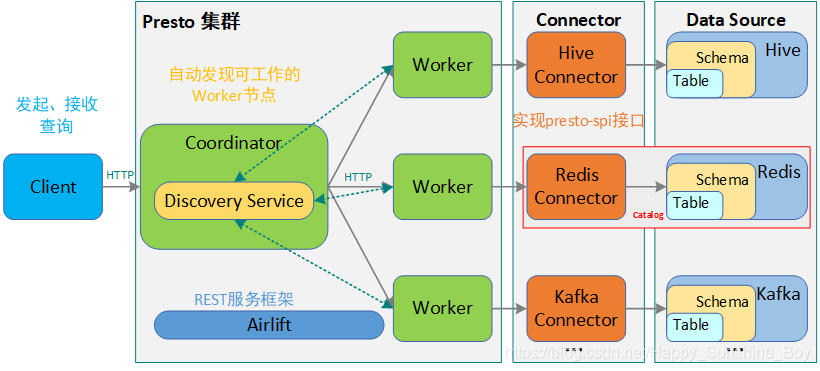
5.Trino SQL执行流程
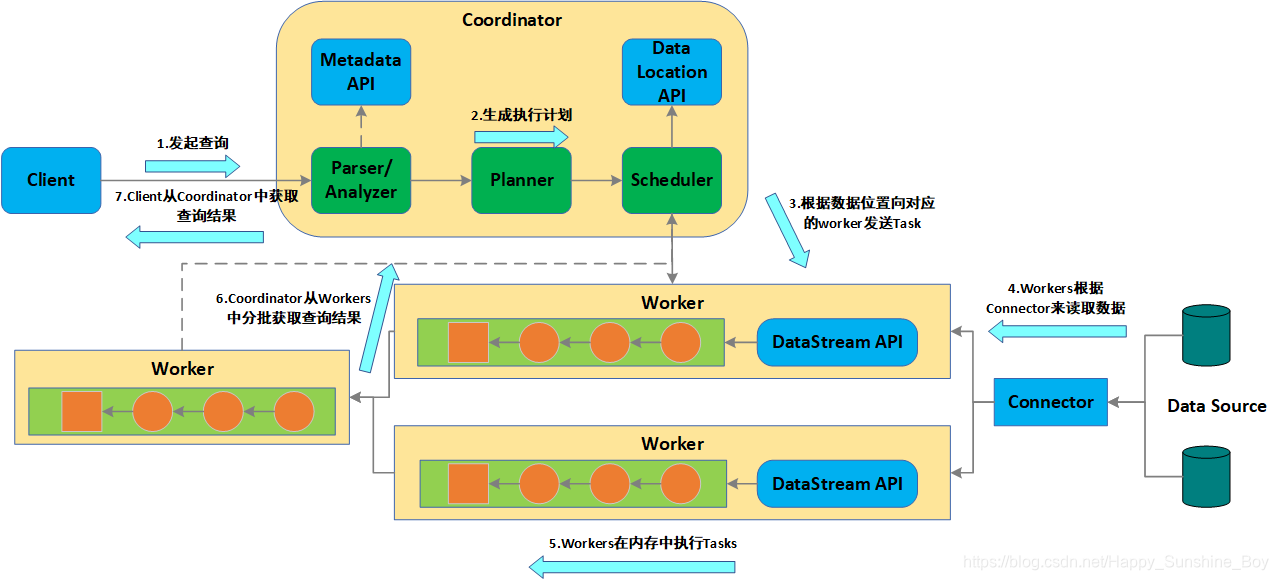
6.Trino Task执行流程
任务调度:
1.分配多少个任务?
2.每个任务分配到哪些机器节点上?拓扑调度算法 (Topology Aware Scheduling strategy)
答:Presto把集群资源划分成两级结构(Machine,集群);【两层结构】分配算法如下:
2.1 当分配一个Split时候,会给定Split的一个地址,这个地址代表期望的分配地址;(尽量距离数据源最近的地址)
2.2 从Machine层开始查找,首先查看Machine上已经分配的Split个数是否已满,若未满则分配该机器;
2.3 若Machine资源池已满,则到集群级别找一台机器,这台机器的资源池使用量小于50%,则分配这台机器。否则分配失败;
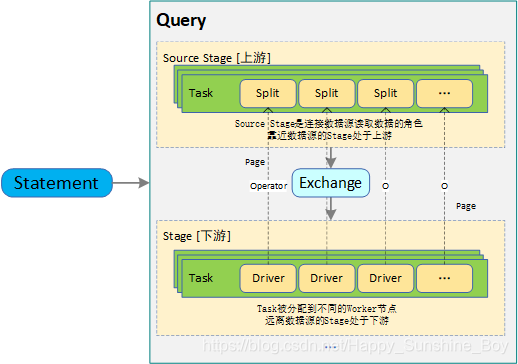
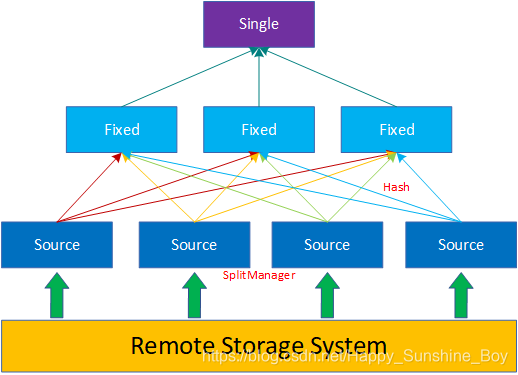
相关参考:
- CentOS7环境下部署PrestoSQL-345版本三节点集群详细过程
- PrestoSQL-345集群连接MySQL5.7
- PrestoSQL-345集群连接Hive3.1.0
- Trino(Presto345) on Hive知识总结及TPC-DS测试
- PrestoSQL-345集群连接Kafka2.2.1
- PrestoSQL-345集群连接Redis5.0.5
- PrestoSQL-345集群连接Phoenix5.0.0-HBase2.0.0-未成功
- PrestoSQL-345集群连接Elasticsearch7.3.2
- PrestoSQL-345可视化Client yanagishima22.0部署
- PrestoSQL-345集群连接TPC-DS
Trino总结的更多相关文章
- windows(wsl)下的trino编译和升级注意事项
最近在进行旧版本的prestosql和prestodb升级相关的操作,尝试自己编译了一下,这里记录一下过程和遇到问题的处理. 因为Trino不支持windows下的编译,如果使用windows最方便的 ...
- Trino Worker 规避 OOM 思路
背景 Trino 集群如果不做任何配置优化,按照默认配置上线,Master 和 Worker 节点都很容易发生 OOM.本文从 Trino 内存设计出发, 分析 Trino 内存管理机制,到限制与优化 ...
- 对话Apache Hudi VP, 洞悉数据湖的过去现在和未来
Apache Hudi是一个开源数据湖管理平台,用于简化增量数据处理和数据管道开发,该平台可以有效地管理业务需求,例如数据生命周期,并提高数据质量.Hudi的一些常见用例是记录级的插入.更新和删除.简 ...
- Pulsar云原生分布式消息和流平台v2.8.0
Pulsar云原生分布式消息和流平台 **本人博客网站 **IT小神 www.itxiaoshen.com Pulsar官方网站 Apache Pulsar是一个云原生的分布式消息和流媒体平台,最初创 ...
- Java 框架、库和软件的精选列表(awesome java)
原创翻译,原始链接 本文为awesome系列中的awesome java Awesome Java Java 框架.库和软件的精选列表 项目 Bean映射 简化 bean 映射的框架 dOOv - 为 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- Thoughtworks Technology Radar #26 技术雷达26期
Thoughtworks Technology Radar #26 Techniques Adopt Four key metrics Google Cloud's DevOps Research a ...
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
随机推荐
- Unity射击实例讲解—主角创建
前言: 经过三分钟的思考决定换个标题,这两天其实游戏制作进度推了大半了,加入了许多自我创作的素材,不过想一想用来讲解的实例不该这么花哨,决定还是参照我的一些教材做一些简单的示例不然要说的东西太多,本人 ...
- js上 十七、数组-3
十七.数组-3 #课堂案例 \1. 封装一个chunk(arr,size)的函数,把该数组arr按照指定的size分割成若干个数组块. 例如:chunk([1,2,3,4],2) 返回结果:[[1,2 ...
- vue第十七单元(电商项目逻辑处理,电商划分)
第十七单元(电商项目逻辑处理,电商划分) #课程目标 1.什么是电商项目 2.什么是B2B,B2C,C2C模式,常见的电商项目 3.移动端电商项目常见的逻辑处理 4.[知识扩展]传统系统架构及分布式系 ...
- Spring中的注解@Value("#{}")与@Value("${}")的区别
1 @Value("#{}") SpEL表达式 @Value("#{}") 表示SpEl表达式通常用来获取bean的属性,或者调用bean的某个方法.当然还有可 ...
- mysql中sql行列转换
1.列转行 select class_id,MAX(CASE kemu when '语文' then score ELSE 0 end)as '语文' ,MAX(CASE kemu when '数学' ...
- 容器编排系统K8s之Dashboard部署
前文我们了解了k8s的访问控制第三关准入控制相关插件的使用,回顾请参考:https://www.cnblogs.com/qiuhom-1874/p/14220402.html:今天我们来了解下k8s的 ...
- Asp.net Core 2.0 实现Cookie会话
与1.0版本相比微软做了一些调整.详细请参考官方文档,我这里就讲2.0的吧 1.首先要在 根目录下 Startup.cs 类中启用 cookie会话,有两处要配置 第一处在 public void ...
- MySQL不会丢失数据的秘密,就藏在它的 7种日志里
本文收录在 GitHub 地址 https://github.com/chengxy-nds/Springboot-Notebook 进入正题前先简单看看MySQL的逻辑架构,相信我用的着. MySQ ...
- Hive数据导入Hbase
方案一:Hive关联HBase表方式 适用场景:数据量不大4T以下(走hbase的api导入数据) 一.hbase表不存在的情况 创建hive表hive_hbase_table映射hbase表hbas ...
- 如何快速搭建hadoop集群
安装好虚拟机,重命名为master 配置网卡 命令:vi /etc/sysconfig/network-scripts/ifcfg-en(按tab键) 这里要配置ip,网关,域名解析 例如我的 IPA ...