大数据系列1:一文初识Hdfs
最近有位同事经常问一些Hadoop的东西,特别是Hdfs的一些细节,有些记得不清楚,所以趁机整理一波。
会按下面的大纲进行整理:
- 简单介绍
Hdfs - 简单介绍
Hdfs读写流程 - 介绍
Hdfs HA实现方式 - 介绍
Yarn统一资源管理器 - 追一下
Hdfs读写的源码
同时也有其他方面的整理,有兴趣可以看看:
算法系列-动态规划(4):买卖股票的最佳时机
数据库仓库系列(一)什么是数据仓库为什么要数据仓库
罗拉的好奇
| 对话记录 |
|---|
|
罗拉 八哥,最近我们不是在建立数据仓库嘛 |
|
八哥 额,你先说说你对Hdfs了解多少? |
|
罗拉 我只是听说这个使用分布式存储的框架,可以存储海量的数据,在大数据领域很常用 |
|
八哥 就这?那就有点尴尬,看来我得从头开始给你介绍了,所以今晚的碗你洗 |
|
罗拉 如果你说的我都懂了,那没问题 |
|
八哥 行,成交 |
查个户口
要想了解Hdfs,就得先查一下他的户口。
Hdfs全名叫做Hadoop分布式文件系统(Hadoop Distributed File System)这货跟Hadoop还有关系。
那没办法,先去看看Hadoop又是啥玩意。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的优势进行高速运算和存储。
目前的Hadoop有一个强大的生态系统,如下:
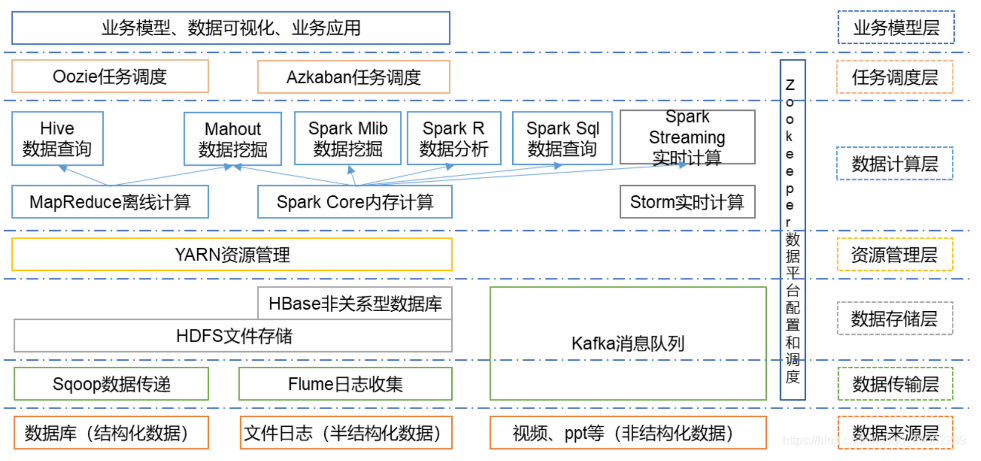
其中有几个为核心的组件,如下:
- Hdfs(
Hadoop Distributed File System):可提供高吞吐量的分布式文件系统 - Yarn:用于任务调度和集群资源管理的框架(这玩意是2.0后的重大突破)
- MapReduce:基于Yarn上,用于大数据集群并行处理的系统。(现在更多的被当作思想来看,或者高手才手撸这玩意)
核心组件随着Hadoop更新,在1.x与2.x有显著的区别,如下:
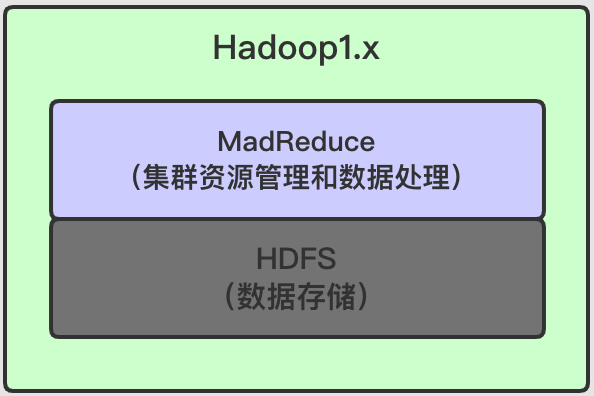
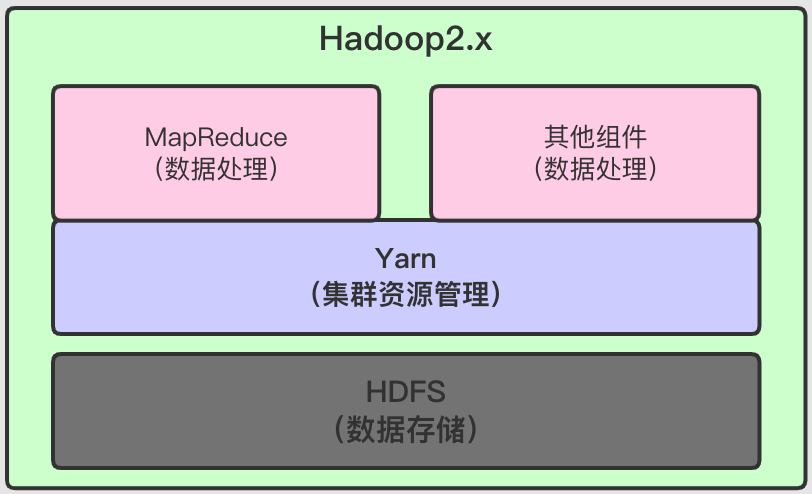
从上面两图中我们可以发现,Hadoop1.x和Hadoop2.x的主要区别就是2.x引入了Yarn。
之所以说这是一个大的突破主要是因为以下几点:
- 在
1.x中MapReduce不仅负责数据的计算,还负责集群作业的调度和资源(内存,CPU)管理(自己即是也是工人,全能型人才),拓展性差,应用场景单一。 - 在
2.x中,引入了Yarn,负责集群的资源的统一管理和调度。MapReduce则运行在Yarn之上,只负责数据的计算。分工更加明确。 - 由于
Yarn具有通用性,可以作为其他的计算框架的资源管理系统, 比如(Spark,Strom,SparkStreaming等)。
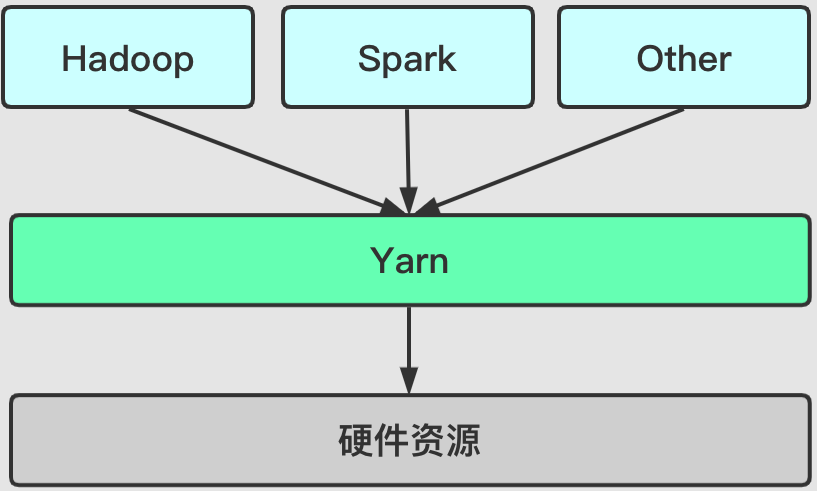
而Yarn作为统一的资源管理和调度,带来了三个显著的效益:
- 提高资源利用率:通过统一资源管理和调度,各个不同的组件可以共享集群资源,提高资源的利用率,避免各自为战出现资源利用不充分甚至资源紧张的情况。
- 降低运维成本:只需对集群进行统一的管理,降低工作量。
- 数据共享:共享集群通过共享集群之间的数据和资源,有效提高数据移动的效率和降低时间成本
共享集群资源架构图:
以后会专门写一篇Yarn的文章,此处不再详细展开。
有了上面的介绍,我们就看看Hdfs是到底做了什么。
Hdfs
Hdfs的设计目标
在大数据我们经常会通过分布式计算对海量数据进行存储和管理。
Hdfs就是在这样的需求下应运而生,它基于流数据模式访问和能够处理超大的文件。
并且可以在在廉价的机器上运行并提供数据容错机制,给大数据的处理带来很大便利。
Hdfs设计之初,就有几个目标:
| 目标 | 实现方式或原因 |
|---|---|
| 硬件故障 | 硬件故障是常态 需要有故障检测,并且快速自动的从故障中恢复的机制 |
| 流式访问 | Hdfs强调的是数据访问高吞吐量,而不是访问的低延迟性 |
| 大型数据集 | 支持大型数据集的文件系统 为具有数百甚至更多阶段的集群提供数据的存储与计算 |
| 简单一致性 | 一次写入,多次读取 一旦文件建立,写入,关闭就不能从任意的位置进行改变 ps:在 2.x后可以在文件末尾追加内容 |
| 移动计算比移动数据容易 | 利用数据的本地性,提高计算的效率 |
| 平台可移植性 | 使用Java语言构建 任何支持 Java的计算机都可以运行Hdfs |
Hdfs框架构设计
接下来我们看看Hdfs集群的框架
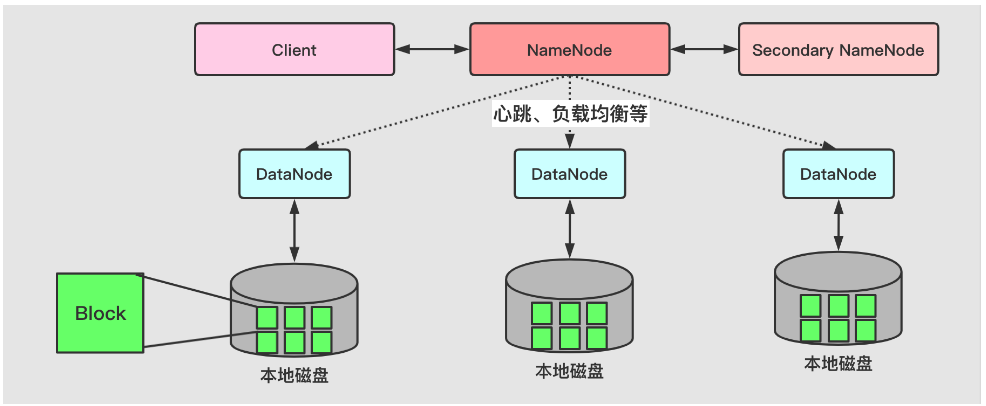
从上图可以明显的看出,Hdfs是一个典型的主/从架构。
我们看看它有什么组件
NameNode
Master由一个NameNode组成,是一个主服务器,主要功能如下:
- 负责管理文件系统的命名空间,存储元数据(文件名称、大小、存储位置等)
- 协调客户端对文件的访问
NameNode会将所有的文件和文件夹存储在一个文件系统的目录树中,并且记录任何元数据的变化。
我们知道Hdfs会将文件拆分为多个数据块保存,其中文件与文件块的对应关系也存储在文件系统的目录树中,由NameNode维护。
除了文件与数据块的映射信息,还有一个数据块与DataNode 的映射信息,
因为数据块最终是存储到DataNode中。我们需要知道一个文件数据块存在那些DataNode中,
或者说DataNode中有哪些数据块。这些信息也记录在NameNode中。
从上图中可以看到,NameNode与DataNode之间还有心跳。
NameNode会周期性的接收集群中DataNode的“心跳”和“块报告”。
通过“心跳”检测DataNode的状态(是否宕机),决定是否需要作出相关的调整策略。
“块报告”包含DataNode上所有数据块列表的信息
DataNode
DataNode是Hdfs的从节点,一般会有多个DataNode(一般一个节点一个DataNode)。
主要功能如下:
- 管理它们所运行节点的数据存储
- 周期性向NameNode上报自身存储的“块信息”
这里的管理指的是在Client对Hdfs进行数据读写操作的时候,会接收来自NameNode的指令,执行数据块的创建、删除、复制等操作。
DataNode中的数据保存在本地磁盘。
Blcok
从上图可以看出,在内部,一个文件会被切割为多个块(Blocks),这些块存储在一组Datanodes中,同时还有对Block进行备份(Replication)。
Hdfs文件以Block的形式存储,默认一个Block大小为128MB(1.x为64Mb)
简单来说就是一个文件会被切割为多个128MB的小文件进行储存,如果文件小于128MB则不切割,按照实际的大小存储,不会占用整个数据块的大小。
关于
Hdfs读写后续会写一个源码追踪的文章,到时候就知道如何实现按照实际大小存储了。
默认Block之所以是128M,主要是降低寻址开销和获得较佳的执行效率。
因为Block越小,那么切割的文件就越多,寻址耗费的时间也会越多。
但如果Block太大,虽然切割的文件比较少,寻址快,但是单个文件过大,执行时间过长,发挥不了并行计算的优势。
每个
Block的元数据也记录在NameNode中,可以说Block的大小一定程度也会影响整个集群的存储能力
同时为了容错,一般会有三个副本,副本的存放策略一般为:
| 备份编号 | 位置 |
|---|---|
| 1 | Standalone模式:上传文件的节点Cluster模式:随机选一台内存充足的机器 |
| 2 | 与1号备份同机架的不同节点 |
| 3 | 不同机架的节点 |
备份除了容错,也是数据本地性(移动计算)的一个强有力支撑。
Secondary NameNode
有一说一,
Secondary NameNode 取了一个标题党的的名字,这个让人感觉这就是第二个NameNode。
实际上不是,在介绍 Secondary NameNode 之前,我们得先了解NameNode是怎么存储元数据的。
我们之前说的Hdfs的元数据信息主要存在两个文件中:fsimage和edits。
fsimage:文件系统的映射文件,存储文件的元数据信息,包括文件系统所有的目录、文件信息以及数据块的索引。edits:Hdfs操作日志文件,记录Hdfs对文件系统的修改日志。
NameNode 对这两个文件的操作如下图:
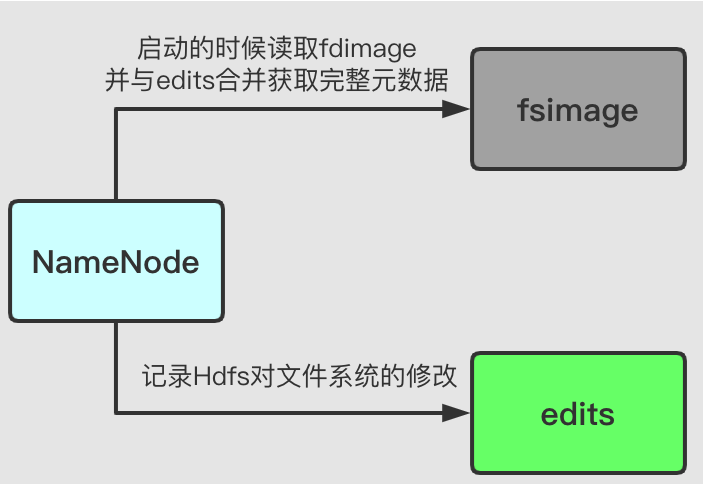
从这张图中,可以知道,在NameNode启动的时候,会从fsimage中读取Hdfs的状态,
同时会合并fsimage与edits获得完整的元数据信息,并将新的Hdfs状态写入fsimage。
并使用一个空的edits文件开始正常操作。
但是在产品化的集群(如Ambari或ClouderManager)中NameNode是很少重启的,在我的工作场景中,重启基本就是挂了。
这也意味着当NameNode运行了很长时间后,edits文件会变得很大。
在这种情况下就会两个问题:
edits文件随着操作增加会变的很大,怎么去管理这个文件是一个又是一个问题。NameNode的重启会花费很长时间,因为经过长时间运行,Hdfs会有很多改动(edits)要合并到fsimage文件上。
既然明白了痛点所在,那自然是需要对症下药,核心问题就是edits会越来越大,导致重启操作时间变长,只要解决这个问题就完事了。
我们只需要保证我们fsimage是最新的,而不是每次启动的时候才合并出完整的fsimage就可以了,也就是更新快照。
这就是是我们需要介绍的Secondary NameNode的工作。
Secondary NameNode 用于帮助NameNode管理元数据,从而使得NameNode可以快速、高效的工作。
简单的说Secondary NameNode的工作就是定期合并fsimage和edits日志,将edits日志文件大小控制在一个限度下。
因为内存需求和
NameNode在一个数量级上,所以通常secondary NameNode和NameNode运行在不同的机器上。
下面看看这个过程是怎么发生的
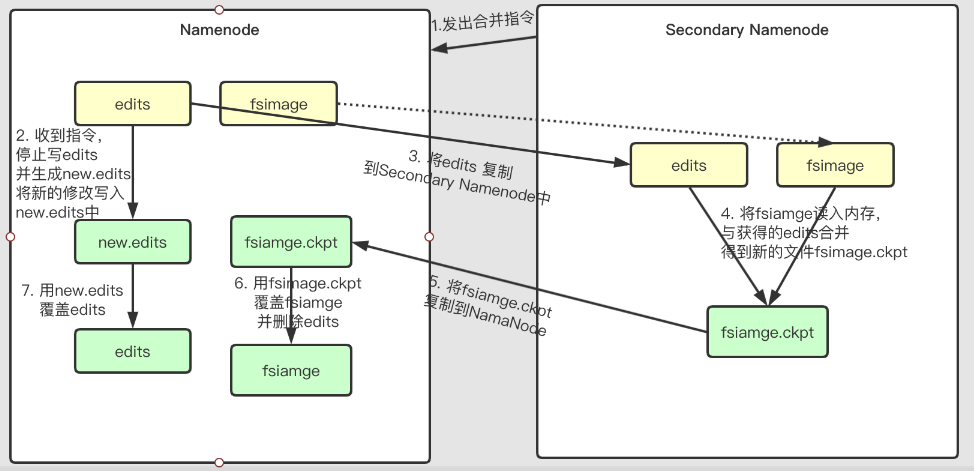
ps:图中有个虚线,就是在传输
edits的时候会不会传输fsimage?这个在最后面会有相关说明
这些步骤简单的总结就是:
在Secondary NameNode端:
Secondary NameNode定期到NameNode更新edits- 将更新到的
edits与自身的fsimage或重新下载的fsimage合并获得完整的fsiamge.ckpt - 将
fsimage.ckpt发送给NameNode
在NameNode端:
- 在
Secondary NameNode发出合并信号的时候,将更新日志写到一个新的new.edits中,停用旧的edits。 - 在
Secondary NameNode将新的fsimage.ckpt发过来后,将旧的fsimage用新的fsimage.ckpt替换,同时将久的edits用new.edits替换。
那么合并的时机是什么?主要有两个参数可以配置:
fs.checkpoint.period:指定连续两次检查点的最大时间间隔, 默认值是1小时。fs.checkpoint.size:定义了edits日志文件的最大值,一旦超过这个值会导致强制执行检查点(即使没到检查点的最大时间间隔)。默认值是64MB。
所以,Secondary NameNode 并不是第二个NameNode的意思,只是NameNode的一个助手。更准确的理解是它仅仅是NameNode的一个检查点(CheckPoint)。
同时,我们所说的HA,也就是高可用,也不是只
Secondary NameNode,详细的会有专门的文章介绍。
有个坑
在Secondary NameNode 执行合并的时候,有一个步骤3,通过http Get的方式从NameNode获取edits文件。
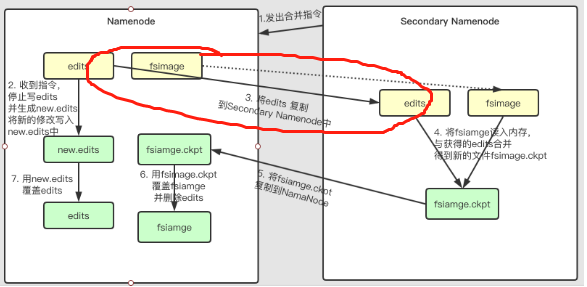
在这一步骤中,到底需不需要把NameNode中的fsimage也获取过来,目前我看了挺多资料,挺矛盾的。
在Hadoop权威指南中说明如下:

从这里看,应该是同是获得了fsimage与edits。
但是,在官网中有一个描述:
The secondary NameNode stores the latest checkpoint in a directory which is structured the same way as the primary NameNode’s directory.
So that the check pointed image is always ready to be read by the primary NameNode if necessary.
Secondary NameNode将最新的检查点存储在与主NameNode目录结构相同的目录中。
所以在NameNode需要的时候,会去读取检查点的镜像image。
并且在Secondary NameNode in Hadoop中关于Secondary NameNode有这样的一个描述:
NameNode当前目录的截图如下:
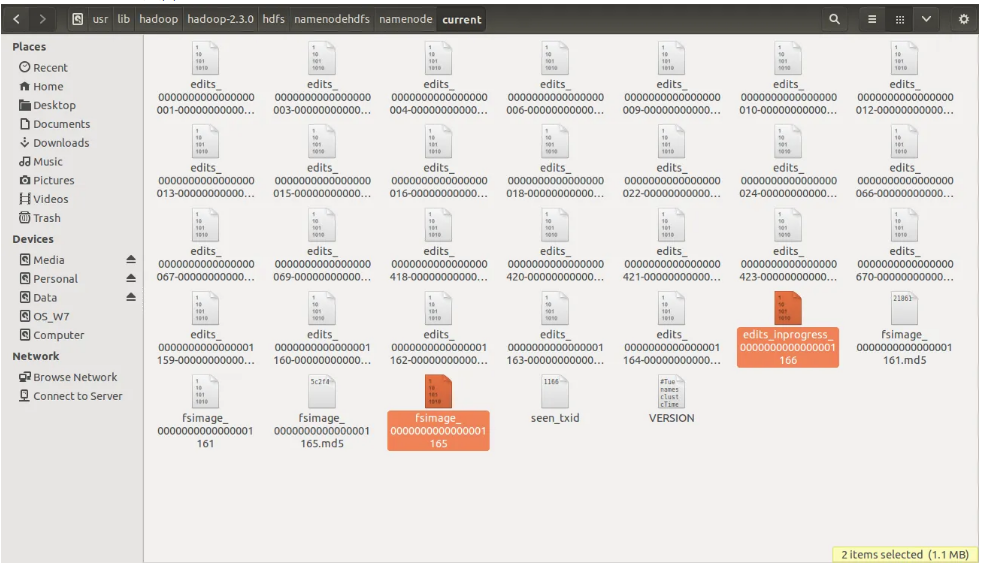
fsimage 的当前版本号位165,从最后一个检查点fsimage165正在进行的edits_inprogress日志编号为166,
在下次namenode重启时,它将与fsimage165合并,fsimage166将被创建。
Secondary NameNode 当前目录的截图如下:
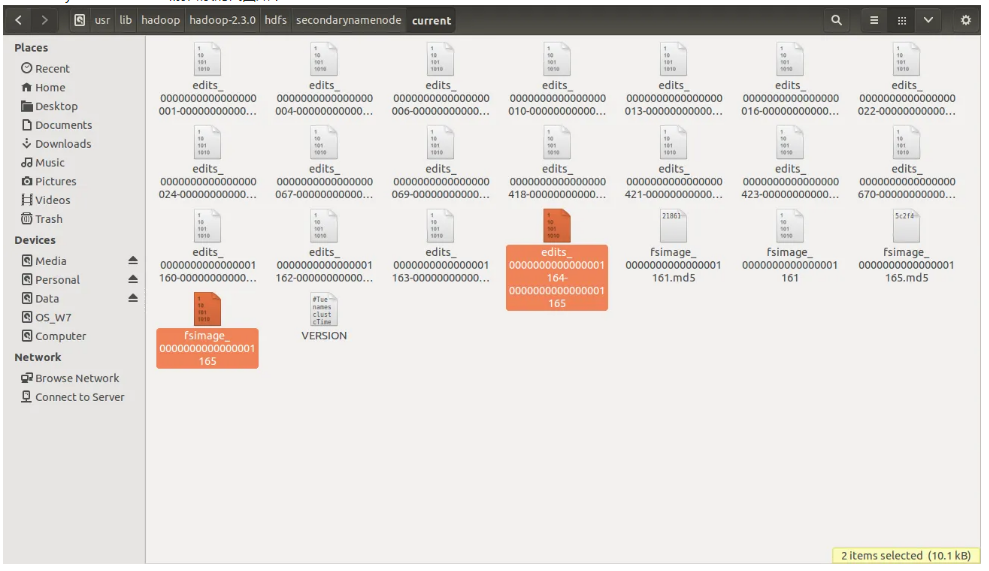
注意,在namenode中没有对应的实时编辑edits_inprogress_166版本。
此时有fsimage165,那么在进行合并的时候不需要从NameNode把fsimage也传输过来吧?
但是执行合并的时候输出的日志:
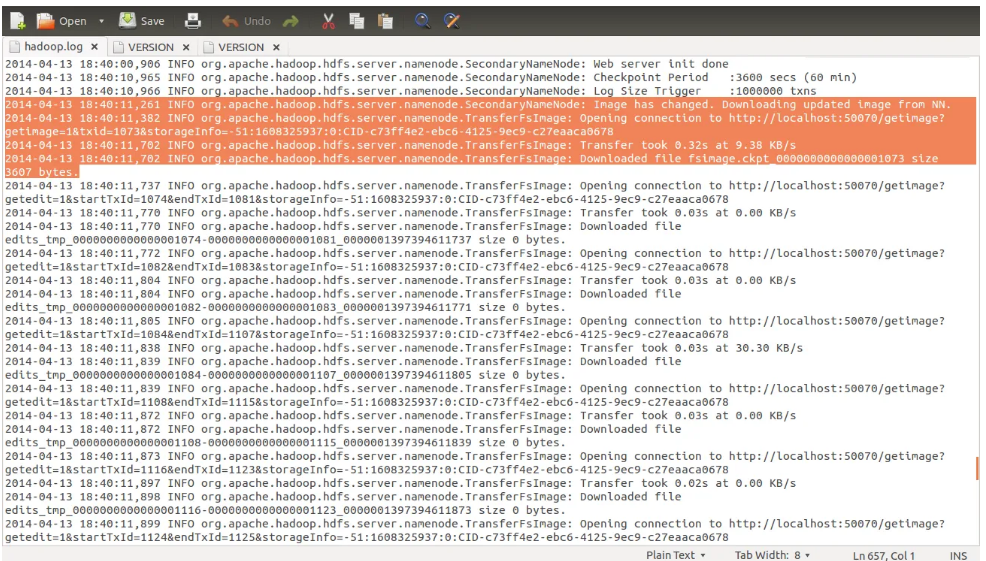
这看起来好像是需要下载fsimage
瞬间蒙圈了。
没办法只能去老老实实去瞄一下源码了:
下面只展示核心代码:
//org.apache.Hadoop.hdfs.server.namenode.SecondaryNameNode#doCheckpoint
/**
* 创建一个新的检查点
* @return image 是否从NameNode获取
*/
@VisibleForTesting
@SuppressWarnings("deprecated")
public boolean doCheckpoint() throws IOException {
//告诉namenode在一个新的编辑文件中开始记录事务,将返回一个用于上传合并后的image的token。
CheckpointSignature sig = namenode.rollEditLog();
//是否重新加载fsimage
boolean loadImage = false;
//这里需要reload fsImage有两种情况
//1. downloadCheckpointFiles中判断fsiamge变化情况
//2. 是否发生checkpointImage 和并错误
loadImage |= downloadCheckpointFiles(
fsName, checkpointImage, sig, manifest) |
checkpointImage.hasMergeError();
//执行合并操作
doMerge(sig, manifest, loadImage, checkpointImage, namesystem);
}
// org.apache.Hadoop.hdfs.server.namenode.SecondaryNameNode#downloadCheckpointFiles
/**
* 从name-node 下载 fsimage 和 edits
* @return true if a new image has been downloaded and needs to be loaded
* @throws IOException
*/
static boolean downloadCheckpointFiles(...) throws IOException {
//根据Image的变化情况决定是否download image
if (sig.mostRecentCheckpointTxId ==
dstImage.getStorage().getMostRecentCheckpointTxId()) {
LOG.info("Image has not changed. Will not download image.");
} else {
LOG.info("Image has changed. Downloading updated image from NN.");
MD5Hash downloadedHash = TransferFsImage.downloadImageToStorage(
nnHostPort, sig.mostRecentCheckpointTxId,
dstImage.getStorage(), true, false);
dstImage.saveDigestAndRenameCheckpointImage(NameNodeFile.IMAGE,
sig.mostRecentCheckpointTxId, downloadedHash);
}
// download edits
for (RemoteEditLog log : manifest.getLogs()) {
TransferFsImage.downloadEditsToStorage(
nnHostPort, log, dstImage.getStorage());
}
// true if we haven't loaded all the transactions represented by the downloaded fsimage.
return dstImage.getLastAppliedTxId() < sig.mostRecentCheckpointTxId;
}
// org.apache.Hadoop.hdfs.server.namenode.SecondaryNameNode#doMerge
void doMerge(...) throws IOException {
//如果需要load iamge 就reload image
if (loadImage) dstImage.reloadFromImageFile(file, dstNamesystem);
Checkpointer.rollForwardByApplyingLogs(manifest, dstImage, dstNamesystem);
// 清除旧的fsimages 和edits
dstImage.saveFSImageInAllDirs(dstNamesystem, dstImage.getLastAppliedTxId());
}
从上面的核心代码可以看到,进行合并的时候,是否需要从NameNode load fsiamge是要看情况的。
不过目前fsiamge 是否改变这点没有深入看源码,
猜测大概是初次启动NameNode时,合并出新的fsiamge(如上面的image_165与 edits_166 合并出来的image_166)。
与当前Secondary NameNode 中的image_165不一致了,所以需要重新拉取,
具体以后有时间再看看。
但是只要记住有些场景下会把fsimage load下来,有些场景不会就可以了。
后续的内容
“怎么样,罗拉,这个简单的介绍可以吧”?
“还行,但是就这么简单?”罗拉狐疑。
“简单?这都是经过前人的努力才搞出来的,而且这是简单的介绍,实际上我们现在再生产用的和这个其实都不太一样了。”
“有多大差别?”
“我现在这里没有给你介绍Hdfs读写流程,还有现在NameNode其实还存在问题,统一的资源管理Yarn也没说,早着呢。”
“还有,想真正掌握,还的去追下源码看看这个操作是怎么实现的。就我现在说的这些,去面试都过不了。”八哥无限鄙视
“哦,那就是说你讲的不完善,今晚的碗我不洗,等你讲完了再说。”
“这么赖皮的嘛?....”
后面有几个点会单独拿出来写个文章,主要是以下几个方面的内容:
- Hdfs读写流程
- Yarn统一资源管理
- Hdfs HA(高可用)
- Hdfs读写源码解析(会用3.1.3的源码)
本文为原创文庄,转载请注明出处!!!
欢迎关注【兔八哥杂谈】
大数据系列1:一文初识Hdfs的更多相关文章
- 大数据系列4:Yarn以及MapReduce 2
系列文章: 大数据系列:一文初识Hdfs 大数据系列2:Hdfs的读写操作 大数据谢列3:Hdfs的HA实现 通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- 玩转大数据系列之Apache Pig高级技能之函数编程(六)
原创不易,转载请务必注明,原创地址,谢谢配合! http://qindongliang.iteye.com/ Pig系列的学习文档,希望对大家有用,感谢关注散仙! Apache Pig的前世今生 Ap ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据系列之并行计算引擎Spark部署及应用
相关博文: 大数据系列之并行计算引擎Spark介绍 之前介绍过关于Spark的程序运行模式有三种: 1.Local模式: 2.standalone(独立模式) 3.Yarn/mesos模式 本文将介绍 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
随机推荐
- .NET生态系统掠影
如果你是一名开发人员,想要进入到.NET的世界,你需要知道都有哪些可能.由于.NET Framework是..NET生态系统中最流行的技术,你可以用它来构建各种各样的应用程序,但是最近,出现了一些新的 ...
- 关于META-INF下的spring.factories文件
spring.factories 文件是springboot提供的一种实例化bean方式 org.springframework.boot.autoconfigure.EnableAutoConfig ...
- java保持同一时间同一账号只能在一处登录
//登录页面 login.jsp <%@ page language="java" contentType="text/html; charset=UTF-8&qu ...
- springcloud组件gateway断言(Predicate)
Spring Cloud Gateway是SpringCloud的全新子项目,该项目基于Spring5.x.SpringBoot2.x技术版本进行编写,意在提供简单方便.可扩展的统一API路由管理方式 ...
- C# 使用 log4net 日志组件
一. 什么是 log4net Apache log4net 库是帮助程序员将日志语句输出到各种输出目标的工具,它是从Java中的Log4j迁移过来的一个.Net版的开源日志框架.log4net 的一 ...
- [每日一题]面试官问:Async/Await 如何通过同步的方式实现异步?
关注「松宝写代码」,精选好文,每日一题 时间永远是自己的 每分每秒也都是为自己的将来铺垫和增值 作者:saucxs | songEagle 一.前言 2020.12.23 日刚立的 flag,每日一 ...
- 2021升级版微服务教程—为什么会有微服务?什么是SpringCloud?
2021升级版SpringCloud教程从入门到实战精通「H版&alibaba&链路追踪&日志&事务&锁」 教程全目录「含视频」:https://gitee.c ...
- 风炫安全web安全学习第三十六节课-15种上传漏洞讲解(一)
风炫安全web安全学习第三十六节课 15种上传漏洞讲解(一) 文件上传漏洞 0x01 漏洞描述和原理 文件上传漏洞可以说是日常渗透测试用得最多的一个漏洞,因为用它获得服务器权限最快最直接.但是想真正把 ...
- Hive表的基本操作
目录 1. 创建表 2. 拷贝表 3. 查看表结构 4. 删除表 5. 修改表 5.1 表重命名 5.2 增.修.删分区 5.3 修改列信息 5.4 增加列 5.5 删除列 5.6 修改表的属性 1. ...
- html 垂直并列显示
笔者在制作登陆网页的时候,发现让input居中十分困难,笔者在网上搜了好久都没有结果,所以就想出了一个硬核的纯html的解决方法 直接上代码: <div style="text-ali ...