Clickhouse 在大数据分析平台 - 留存分析上的应用
导语 | 本文实践了对于千万级别的用户,操作总数达万级别,每日几十亿操作流水的留存分析工具秒级别查询的数据构建方案。同时,除了留存分析,对于用户群分析,事件分析等也可以尝试用此方案来解决。
文章作者:陈璐,腾讯高级数据分析师
背景
你可能听说过Growingio、神策等数据分析平台,本文主要介绍实现留存分析工具相关的内容。留存分析是一种用来分析用户参与情况/活跃程度的分析模型,可考查进行初始行为后的用户中,有多少人会进行后续行为,这是衡量产品对用户价值高低的重要指标。如,为评估产品更新效果或渠道推广效果,我们常常需要对同期进入产品或同期使用了产品某个功能的用户的后续行为表现进行评估 [1]。大部分数据分析平台主要包括如图的几个功能(以神策
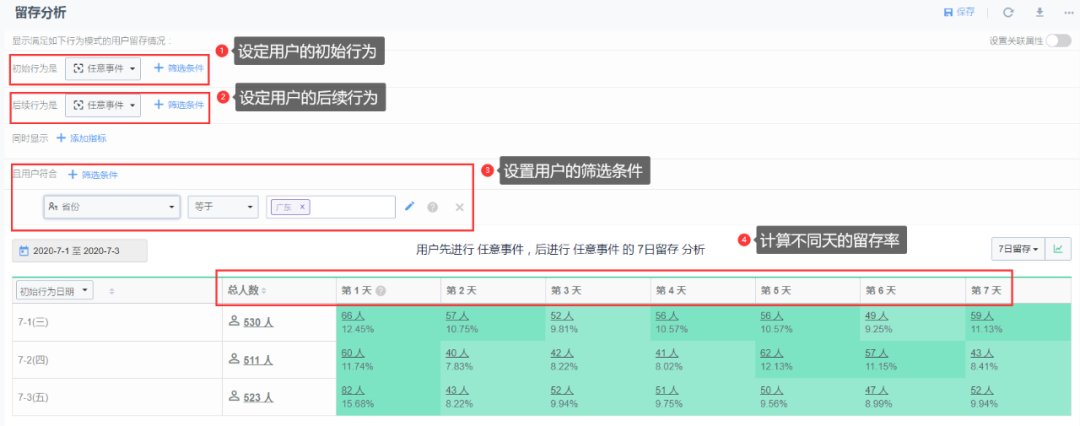
本文主要介绍留存分析工具的优化方案(只涉及数据存储和查询的方案设计,不涉及平台)。
我想每个数据/产品同学在以往的取数分析过程中,都曾有一个痛点,就是每次查询留存相关的数据时,都要等到天荒地老,慢!而最近采用优化方案的目的也是为了提高查询的效率和减少数据的存储,可以帮助产品快速地查询/分析留存相关的数据。优化方案的核心是在Clickhouse中使用Roaringbitmap对用户进行压缩,将留存率的计算交给高效率的位图函数,这样既省空间又可以提高查询速度。希望本实践方案可以给你带来一些帮助和启示。下面主要分3个部分详细介绍:Roaringbitmap简介、思路与实现、总结与思考。
一、Roaringbitmap 简介
下面先简单介绍一下高效的位图压缩方法Roaringbitmap。先来看一个问题:
给定含有40亿个不重复的位于[0,2^32-1]区间内的整数集合,如何快速判定某个数是否在该集合内?
显然,如果我们将这40亿个数原样存储下来,需要耗费高达14.9GB的内存,这是难以接受的。所以我们可以用位图(bitmap)来存储,即第0个比特表示数字0,第1个比特表示数字1,以此类推。如果某个数位于原集合内,就将它对应的位图内的比特置为1,否则保持为0,这样就能很方便地查询得出结果了,仅仅需要占用512MB的内存,不到原来的3.4% [3]。但是这种方式也有缺点:比如我需要将1~5000w这5000w个连续的整数存储起来,用普通的bitmap同样需要消耗512M的存储,显然,对于这种情况其实有很大的优化空间。2016年由S. Chambi、D. Lemire、O. Kaser等人在论文《Better bitmap performance with Roaring bitmaps》与《Consistently faster and smaller compressed bitmaps with Roaring》中提出了roaringbitmap,主要特点就是可以极大程度地节约存储及提供了快速的位图计算,因此考虑用它来做优化。对于前文提及的存储连续的5000w个整数,只需要几十KB。
它的主要思路是:将32位无符号整数按照高16位分桶,即最多可能有2^16=65536个桶,论文内称为container。存储数据时,按照数据的高16位找到container(找不到就会新建一个),再将低16位放入container中。也就是说,一个roaringbitmap就是很多container的集合 [3],具体细节可以自行查看文末的参考文章。
二、思路与实现
我们的原始数据主要分为:
1.用户操作行为数据table_oper_raw
包括时间分区(ds)、用户标识id(user_id)和用户操作行为名称(oper_name),如:20200701|6053002|点击首页banner 表示用户6053002在20200701这天点击了首页banner(同一天中同一个用户多次操作了同一个行为只保留一条)。实践过程中,此表每日记录数达几十亿行。
2.用户属性数据table_attribute_raw
表示用户在产品/画像中的属性,包括时间分区(ds)、用户标识(user_id)及各种用户属性字段(可能是用户的新进渠道、所在省份等),如20200701|6053002|小米商店|广东省。实践过程中,此表每日有千万级的用户数,测试属性在20+个。
现在我们需要根据这两类数据,求出某天操作了某个行为的用户在后续的某一天操作了另一个行为的留存率,比如,在20200701这天操作了“点击banner”的用户有100个,这部分用户在20200702这天操作了“点击app签到”的有20个,那么对于分析时间是20200701,且“点击banner”的用户在次日“点击app签到”的留存率是20%。同时,还需要考虑利用用户属性对留存比例进行区分,例如只考虑广东省的用户的留存率,或者只考虑小米商店用户的留存率,或者在广东的小米商店的用户的留存率等等。一般来说,求留存率的做法就是两天的用户求交集,例如前文说到的情况,就是先获取出20200701的所有操作了“点击banner”的用户标识id集合假设为S1,然后获取20200702的所有操作了“点击app签到”的用户标识id集合假设为S2,最后求解S1和S2的交集:
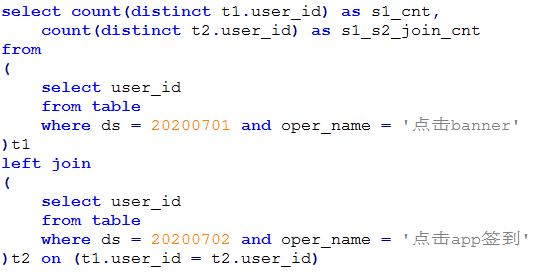
可以看到,当s1和s2的集合中用户数都比较大的时候,join的速度会比较慢。
在此我们考虑前文说到的bitmap,假若每一个用户都可以表示成一个32位的无符号整型,用bitmap的形式去存储,S1和S2的求交过程就是直接的一个位比较过程,这样速度会得到巨大的提升。而Roaringbitmap对数据进行了压缩,其求交的速度在绝大部分情况下比bitmap还要快,因此这里我们考虑使用Roaringbitmap的方法来对计算留存的过程进行优化。
1.数据构建
整个过程主要是:首先对初始的两张表——用户操作数据表table_oper_raw和用户筛选维度数据表table_attribute_raw中的user_id字段进行编码,将每个用户映射成唯一的id(32位的无符号整型),分别得到两个新表table_oper_middle和table_attribute_middle。再将他们导入clickhouse,使用roaringbitmap的方法对用户进行压缩存储,最后得到压缩后的两张表table_oper_bit和table_attribute_bit,即为最终的查询表。流程图如下:
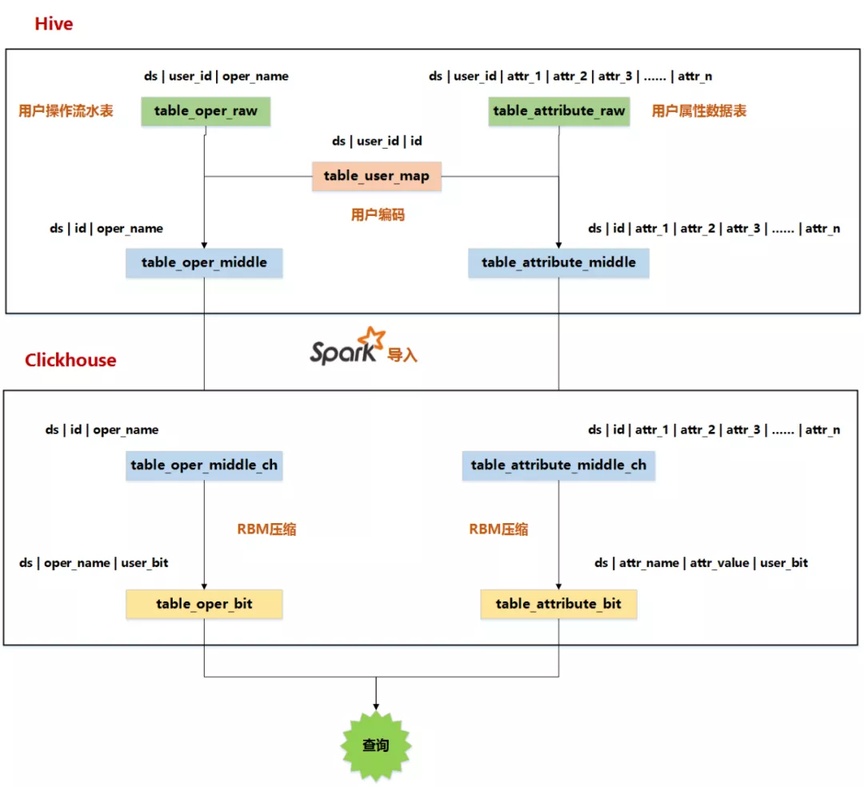
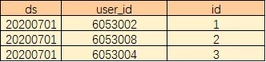
(1).生成用户id映射表
首先,需要构建一个映射表table_user_map,包含时间分区(ds)、用户标识id(user_d)及映射后的id(id),它将每个用户(String类型)映射成一个32位的无符号整型。这里我们从1开始编码,这样每个用户的标识就转化成了指定的一个数字。
(2).初始数据转化
分别将用户操作数据表和用户筛选维度数据中的imei字段替换成对应的数值,生成编码后的用户操作数据:

和用户筛选维度数据:

(3).导入clickhouse
首先在clickhouse中创建相同结构的表,如table_oper_middle_ch:

同样的,在clickhouse中创建表tableattributemiddle_ch。然后用spark将这两份数据分别导入这两张表。这一步导入很快,几十亿的数据大概10分多钟就可以完成
(4).Roaringbitmap压缩
对于用户操作流水数据,我们先建一个可以存放bitmap的表table_oper_bit,建表语句如下:
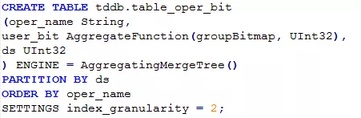
用户属性数据table_attribute_bit也类似:

这里索引粒度可设置小值,接着用聚合函数groupBitmapState对用户id进行压缩:
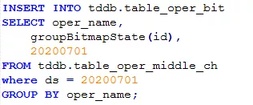
这样,对于用户操作数据表,原本几十亿的数据就压缩成了几万行的数据,每行包括操作名称和对应的用户id形成的bitmap:

同样的,用户属性的数据也可以这样处理,得到table_attribute_bit表,每行包括某个属性的某个属性值对应的用户的id形成的bitmap:

至此,数据压缩的过程就这样完成了。
2.查询过程
首先,简要地介绍下方案中常用的bitmap函数(详细见文末的参考资料):1.bitmapCardinality
返回一个UInt64类型的数值,表示bitmap对象的基数。用来计算不同条件下的用户数,可以粗略理解为count(distinct)2.bitmapAnd
为两个bitmap对象进行与操作,返回一个新的bitmap对象。可以理解为用来满足两个条件之间的and,但是参数只能是两个bitmap3.bitmapOr
为两个bitmap对象进行或操作,返回一个新的bitmap对象。可以理解为用来满足两个条件之间的or,但是参数也同样只能是两个bitmap。如果是多个的情况,可以尝试使用groupBitmapMergeState举例来说,假设20200701这天只有[1,2,3,5,8]这5个用户点击了banner,则有:
# 返回5
select bitmapCardinality(user_bit)
from tddb.table_oper_bit
where ds = 20200701 AND oper_name = '点击banner'
又如果20200701从小米商店新进的用户是[1,3,8,111,2000,100000],则有:
# 返回3,因为两者的重合用户只有1,3,8这3个用户
select bitmapCardinality(bitmapAnd(
(SELECT user_bit
FROM tddb.table_oper_bit
WHERE (ds = 20200701) AND (oper_name = '点击banner')),
(SELECT user_bit
FROM tddb.table_attribute_bit
WHERE ds = 20200701 and (attr_id = 'first_channel') and (attr_value IN ('小米商店')))))
有了以上的数据生成过程和bitmap函数,我们就可以根据不同的条件使用不同的位图函数来快速查询,具体来说,主要是以下几种情况:
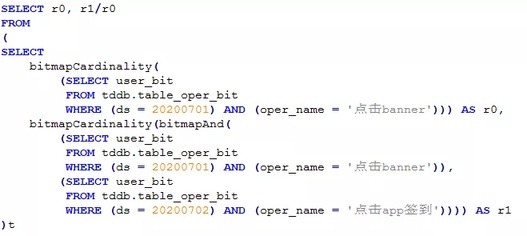
a. 操作了某个行为的用户在后续某一天操作了另一个行为的留存:
如“20200701点击了banner的用户在次日点击app签到的留存人数”,就可以用以下的sql快速求解:
b. 操作了某个行为并且带有某个属性的用户在后续的某一天操作了另一个行为的留存:
如“20200701点击了banner且来自广东/江西/河南的用户在次日点击app签到的留存人数”:

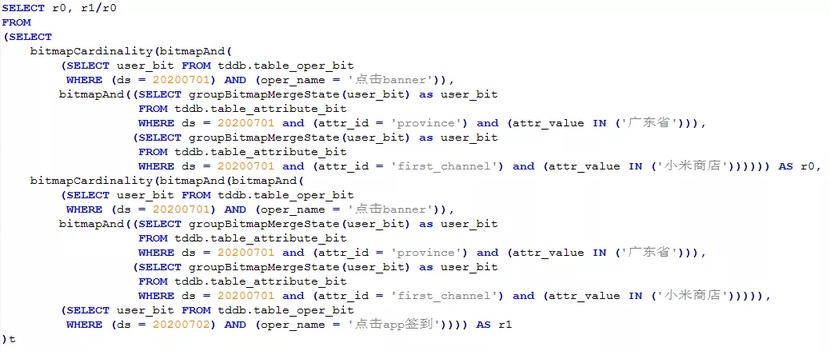
c. 操作了某个行为并且带有某几个属性的用户在后续的某一天操作了另一个行为的留存:
如“20200701点击了banner、来自广东且新进渠道是小米商店的用户在次日点击app签到的留存人数”:
3.实践效果
根据这套方案做了实践,对每日按时间分区、用户、操作名称去重后包括几十亿的操作记录,其中包含千万级别的用户数,万级别的操作数。最后实现了:
存储
原本每日几十G的操作流水数据经压缩后得到的表table_oper_bit为4GB左右/天。而用户属性表table_attribute_bit为500MB左右/天
查询速度
clickhouse集群现状:12核125G内存机器10台。clickhouse版本:20.4.7.67。查询的表都存放在其中一台机器上。测试了查询在20200701操作了行为oper_name_1(用户数量级为3000+w)的用户在后续7天内每天操作了另一个行为oper_name_2(用户数量级为2700+w)的留存数据(用户重合度在1000w以上),耗时0.2秒左右

反馈
最后和前端打通,效果也是有了明显的优化,麻麻再也不用担心我会转晕~

三、总结与思考
总的来说,本方案的优点是:
存储小,极大地节约了存储
查询快,利用bitmapCardinality、bitmapAnd、bitmapOr等位图函数快速计算用户数和满足一些条件的查询,将缓慢的join操作转化成位图间的计算
适用于灵活天数的留存查询
便于更新,用户操作数据和用户属性数据分开存储,便于后续属性的增加和数据回滚
另外,根据本方案的特点,除了留存分析工具,对于用户群分析,事件分析等工具也可以尝试用此方案来解决。PS : 作者初入坑ch,对于以上内容,有不正确/不严谨之处请轻拍~ 欢迎交流~
参考文献:
[1] 解析常见的数据分析模型——留存分析:https://www.sensorsdata.cn/blog/jie-xi-chang-jian-de-shu-ju-fen-xi-mo-xing-liu-cun-fen-xi/
[2] RoaringBitmap数据结构及原理:https://blog.csdn.net/yizishou/article/details/78342499
[3] 高效压缩位图RoaringBitmap的原理与应用:https://www.jianshu.com/p/818ac4e90daf
[4] 论文:Better bitmap performance with Roaring bitmaps:https://arxiv.org/abs/1402.6407v9?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+DanielLemiresArticlesOnArxiv+(Daniel+Lemire%27s+articles+on+arXiv)
[5] Clickhouse文档-位图函数:https://clickhouse.tech/docs/zh/sql-reference/functions/bitmap-functions/

关注“腾讯云大数据”公众号,技术交流、最新活动、服务专享一站Get~
Clickhouse 在大数据分析平台 - 留存分析上的应用的更多相关文章
- 使用Kylin构建企业大数据分析平台的4种部署方式
本篇博客重点介绍如何使用Kylin来构建大数据分析平台.根据官网介绍,其实部署Kylin非常简单,称为非侵入式安装,也就是不需要去修改已有的 Hadoop大数据平台.你只需要根据的环境下载适合的Kyl ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 使用Apache Kylin搭建企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM.eBay做过大数据.云架构的开发,现在是Kylige ...
- 《基于Apache Kylin构建大数据分析平台》
Kyligence联合创始人兼CEO,Apache Kylin项目管理委员会主席(PMC Chair)韩卿 武汉市云升科技发展有限公司董事长,<智慧城市-大数据.物联网和云计算之应用>作者 ...
- Net Core SignalR 测试,可以用于unity、Layair、白鹭引擎、大数据分析平台等高可用消息实时通信器。
SignalR介绍 SignalR介绍来源于微软文档,不过多解释.https://docs.microsoft.com/zh-cn/aspnet/core/signalr/introduction?v ...
- Apache Kylin大数据分析平台的演进
转:http://mt.sohu.com/20160628/n456602429.shtml 我是来自Kyligence的李扬,是上海Kyligence的联合创始人兼CTO.今天我主要来和大家分享一下 ...
- DKH大数据分析平台解决方案优势说明
大数据技术的发展与应用已经在深刻地改变和影响我们的日常生活与工作,可以预见的是在大数据提升为国家战略层面后,未来的几年里大数据技术将会被更多的行业应用. 相信很多人对于大数据技术的应用还是处于一个非常 ...
- 永洪BI——国内领军的一站式大数据分析平台
平台: CentOS 类型: 虚拟机镜像 软件包: jdk-7.79-linux yonghongbi.sh basic software big data business intelligence ...
- HDFS+ClickHouse+Spark:从0到1实现一款轻量级大数据分析系统
在产品精细化运营时代,经常会遇到产品增长问题:比如指标涨跌原因分析.版本迭代效果分析.运营活动效果分析等.这一类分析问题高频且具有较高时效性要求,然而在人力资源紧张情况,传统的数据分析模式难以满足.本 ...
随机推荐
- CURLOPT_FOLLOWLOCATION
curl爬取过程中,设置CURLOPT_FOLLOWLOCATION为true,则会跟踪爬取重定向页面,否则,不会跟踪重定向页面
- 云服务器-Ubuntu更新系统版本-更新Linux内核-服务器安全配置优化-防反弹shell
购入了一台阿里云的ESC服务器,以前都用CentOS感觉Yum不怎么方便,这次选的Ubuntu16.04.7 搭好服务之后做安全检查,发现Ubuntu16.04版本漏洞众多:虽然也没有涉及到16.04 ...
- Android light系统分析
光线系统包括:背光,闪光,led指示灯 一.内核层 Led-class.c (kernel-3.10\drivers\leds) 这个文件给HAL层提供接口 led_brightn ...
- 攻克solo第六课(大调音阶与真的爱你)
在本期文章中,笔者将通过guitar pro7和大家分享大调音阶的知识. 不知道大家有没有试着使用my song book里面的谱子,反正笔者是觉得赚大了,并且找了囊括民谣.爵士到摇滚在内不同风格的谱 ...
- 对于MySQL数据库四种隔离等级
对于MySQL事务有四种隔离级别,分别是以下四种: 1.读未提交 2.读提交 3.可重复读 4.串行化(加锁) 对于隔离我们都是说在并发的情况下发生的事情,读取的数据在并发的情况下会发生什么情况. 并 ...
- jquery删除文件
1 <div class="panel panel-default"> 2 <div class="panel-body"> 3 < ...
- Python判断是否为数字
前言 Python isdigit()方法检测字符串是否只由数字组成. isdigit()方法语法: str.isdigit() 如果字符串只包含数字则返回 True 否则返回 False. 示例 x ...
- get、post、
1.get请求 get请求会把参数放在url后面,中间用?隔开,也可以把参数放在请求body中,如果参数中有中文,http传的时候requests框架会将中文换成urlencode编码 2.get和p ...
- 记安装Wampsever
遇到的问题: Wampsever 启动所有服务后图标为黄色 localhost 问题:显示 IIS Windows 在用 localhost 访问本机的php文件和用ip地址(不是127.0.0.1) ...
- 20191017_datatable.select() 数据源中没有dataRow
filterStr =" 记录时间 >= '2019/10/17 00:00:00' and 记录时间 <='2019/10/20 23:59:59' " 代码: dg ...