http请求工作流程
一、HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
1、客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.oakcms.cn。
2、发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3、服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4、释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5、客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示
二、HTTP请求消息Request
客户端发送一个HTTP请求到服务器,其请求消息,由请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,格式如图所示:
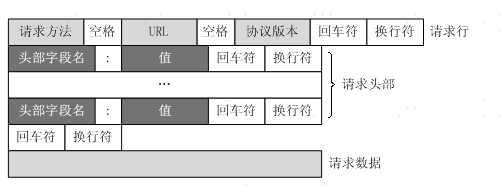
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本
Get请求例子,使用Charles抓取的request: GET /562f25980001b1b106000338.jpg HTTP/1.1
Host img.mukewang.com
User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept image/webp,image/*,*/*;q=0.8
Referer http://www.imooc.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language zh-CN,zh;q=0.8
第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本.
GET说明请求类型为GET,[/562f25980001b1b106000338.jpg]为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。
第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息
从第二行起为请求头部,HOST将指出请求的目的地.User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等
第三部分:空行,请求头部后面的空行是必须的,即使第四部分的请求数据为空,也必须有空行。
第四部分:请求数据也叫主体,可以添加任意的其他数据。这个例子的请求数据为空。
POST请求例子,使用Charles抓取的request: POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive name=Professional%20Ajax&publisher=Wiley
第一部分:请求行,第一行指明使用的是post请求,以及http1.1版本。
第二部分:请求头部,第二行至第六行。
第三部分:空行,第七行的空行。
第四部分:请求数据,第八行
HTTP请求方法
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
三、HTTP之响应消息Response
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文,其格式如下图所示:
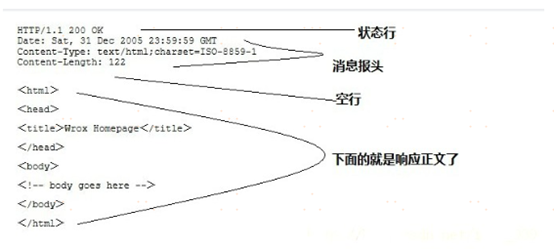
样例:
HTTP/1.1 200 OK Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8 <html>
<head></head>
<body>
<!--body goes here-->
</body>
</html>
第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成
第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
第二部分:消息报头,用来说明客户端要使用的一些附加信息
第二行和第三行为消息报头,Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8
第三部分:空行,消息报头后面的空行是必须的
第四部分:响应正文,服务器返回给客户端的文本信息。空行后面的html部分为响应正文。
HTTP之状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态码
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
http请求工作流程的更多相关文章
- scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返 ...
- Scrapy中的核心工作流程以及POST请求
五大核心组件工作流程 post请求发送 递归爬取 五大核心组件工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, ...
- 1.说一下的 dubbo 的工作原理?注册中心挂了可以继续通信吗?说说一次 rpc 请求的流程?
作者:中华石杉 面试题 说一下的 dubbo 的工作原理?注册中心挂了可以继续通信吗?说说一次 rpc 请求的流程? 面试官心理分析 MQ.ES.Redis.Dubbo,上来先问你一些思考性的问题.原 ...
- struts2工作流程
struts2的框架结构图 工作流程 1.客户端请求一个HttpServletRequest的请求,如在浏览器中输入http://localhost: 8080/bookcode/Reg.action ...
- gitlab工作流程简介
gitlab工作流程简介 新建项目流程 创建/导入项目 可以选择导入github.bitbucket项目,也可以新建空白项目,还可以从SVN导入项目 建议选择private等级 初始化项目 1.本地克 ...
- Git 工作流程
Git 作为一个源码管理系统,不可避免涉及到多人协作. 协作必须有一个规范的工作流程,让大家有效地合作,使得项目井井有条地发展下去.”工作流程”在英语里,叫做”workflow”或者”flow”,原意 ...
- Spark基本工作流程及YARN cluster模式原理(读书笔记)
Spark基本工作流程及YARN cluster模式原理 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark基本工作流程 相关术语解释 Spark应用程序相关的几 ...
- NSURLSession使用说明及后台工作流程分析
原文摘自http://www.cocoachina.com/industry/20131106/7304.html NSURLSession是iOS7中新的网络接口,它与咱们熟悉的NSURLConne ...
- 了解SpringMVC框架及基本工作流程
传统原生的JSP+Servlet在开发上过程上虽然简单明了,JSP页面传递数据到Servlet,Servlet整理数据(逻辑开发)或者从数据库提取数据接着再转发到JSP页面上,但是其似乎只能止步于此, ...
随机推荐
- Spring Cloud系列之使用Feign进行服务调用
在上一章的学习中,我们知道了微服务的基本概念,知道怎么基于Ribbon+restTemplate的方式实现服务调用,接着上篇博客,我们学习怎么基于Feign实现服务调用,请先学习上篇博客,然后再学习本 ...
- 「从零单排canal 06」 instance模块源码解析
基于1.1.5-alpha版本,具体源码笔记可以参考我的github:https://github.com/saigu/JavaKnowledgeGraph/tree/master/code_read ...
- 从包含10个无符号数的字节数组array中选出最小的一个数存于变量MIN中,并将该数以十进制形式显示出来。
问题 从包含10个无符号数的字节数组array中选出最小的一个数存于变量MIN中,并将该数以十进制形式显示出来. 代码 data segment arrey db 0,1,2,4,6,5,7,9,8, ...
- Python性能分析与优化PDF高清完整版免费下载|百度云盘
百度云盘|Python性能分析与优化PDF高清完整版免费下载 提取码:ubjt 内容简介 全面掌握Python代码性能分析和优化方法,消除性能瓶颈,迅速改善程序性能! 对于Python程序员来说,仅仅 ...
- luogu P1721 [NOI2016]国王饮水记 斜率优化dp 贪心 决策单调性
LINK:国王饮水记 看起来很不可做的样子. 但实际上还是需要先考虑贪心. 当k==1的时候 只有一次操作机会.显然可以把那些比第一个位置小的都给扔掉. 然后可以得知剩下序列中的最大值一定会被选择. ...
- ARC 093 F Dark Horse 容斥 状压dp 组合计数
LINK:Dark Horse 首先考虑1所在位置. 假设1所在位置在1号点 对于此时剩下的其他点的方案来说. 把1移到另外一个点 对于刚才的所有方案来说 相对位置不变是另外的方案. 可以得到 1在任 ...
- 谁来教我渗透测试——黑客必须掌握的Linux基础
上一篇我们学习了Windows基础,今天我们来看一看作为一名渗透测试工程师都需要掌握哪些Linux知识.今天的笔记一共分为如下三个部分: Linux系统的介绍 Linux系统目录结构.常用命令 Lin ...
- 025_go语言中的通道同步
代码演示 package main import "fmt" import "time" func worker(done chan bool) { fmt.P ...
- 002_HyperLedger Fabric安装部署
上一次我们把HyperLedger Fabric的环境全部搭建好了,下面开始正式的HyperLedger Fabric安装部署 首先需要安装编译工具gcc,用命令yum install -y gcc安 ...
- SkyWalking APM8.1.0 搭建与项目集成使用
SkyWalking介绍 SkyWalking是什么? SkyWalking是一个可观测性分析平台和应用性能管理系统,提供分布式跟踪.服务网格遥测分析.度量聚合和可视化一体化解决方案,并支持多种开发语 ...