【小白学PyTorch】11 MobileNet详解及PyTorch实现
文章来自微信公众号【机器学习炼丹术】。我是炼丹兄,欢迎加我微信好友交流学习:cyx645016617。
@
本来计划是想在今天讲EfficientNet PyTorch的,但是发现EfficientNet是依赖于SENet和MobileNet两个网络结构,所以本着本系列是给“小白”初学者学习的,所以这一课先讲解MobileNet,然后下一课讲解SENet,然后再下一课讲解EfficientNet,当然,每一节课都是由PyTorch实现的。
1 背景
Mobile是移动、手机的概念,MobileNet是Google在2017年提出的轻量级深度神经网络,专门用于移动端、嵌入式这种计算力不高、要求速度、实时性的设备。
2 深度可分离卷积
主要应用了深度可分离卷积来代替传统的卷积操作,并且放弃pooling层。把标准卷积分解成:
- 深度卷积(depthwise convolution)
- 逐点卷积(pointwise convolution)。
这么做的好处是可以大幅度降低参数量和计算量。
2.2 一般卷积计算量
我们先来回顾一下什么是一般的卷积:
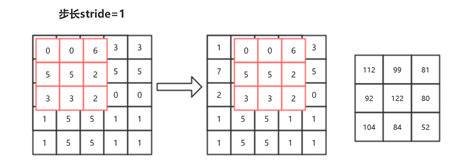
先说一下题目:特征图尺寸是H(高)和W(宽),尺寸(边长)为K,M是输入特征图的通道数,N是输出特征图的通道数。
现在简化问题,如上图所示,输入单通道特征图,输出特征图也是单通道的, 我们知道每一个卷积结果为一个标量,从输出特征图来看,总共进行了9次卷积。每一次卷积计算了9次,因为每一次卷积都需要让卷积核上的每一个数字与原来特征图上对应的数字相乘(这里只算乘法不用考虑加法)。所以图6.18所示,总共计算了:
\(9*9=3*3*3*3=81\)
如果输入特征图是一个2通道的 ,那么意味着卷积核也是要2通道的卷积核才行,此时输出特征图还是单通道的。这样计算量就变成:
\(9*9*2=3*3*3*3*2=162\)
原本单通道特征图每一次卷积只用计算9次乘法,现在因为输入通道数变成2,要计算18次乘法才能得到输出中的1个数字。现在假设输出特征图要输出3通道的特征图。 那么就要准备3个不同的卷积核,重复上述全部操作3次才能拿的到3个特征图。所以计算量就是:
\(9*9*2*3=3*3*3*3*2*3=486\)
现在解决原来的问题:特征图尺寸是H(高)和W(宽),卷积核是正方形的,尺寸(边长)为K,M是输入特征图的通道数,N是输出特征图的通道数。 那么这样卷积的计算量为:
\(H*W*K*K*M*N\)
这个就是卷积的计算量的公式。
2.2 深度可分离卷积计算量
- 深度可分离卷积(Depthwise Separable Convolution,DSC)
假设在一次一般的卷积中,需要将一个输入特征图64×7×7,经过3×3的卷积核,变成128×7×7的输出特征图。计算一下这个过程需要多少的计算量:
\(7*7*3*3*64*128=3612672\)
如果用了深度可分离卷积,就是把这个卷积变成两个步骤:
- Depthwise:先用64×7×7经过3×3的卷积核得到一个64×7×7的特征图。注意注意!这里是64×7×7的特征图经过3×3的卷积核,不是64×3×3的卷积核!这里将64×7×7的特征图看成64张7×7的图片,然后依次与3×3的卷积核进行卷积;
- Pointwise:在Depthwise的操作中,不难发现,这样的计算根本无法整合不同通道的信息,因为上一步把所有通道都拆开了,所以在这一步要用64×1×1的卷积核去整合不同通道上的信息,用128个64×1×1的卷积核,产生128×7×7的特征图。
最后的计算量就是:
\(7*7*3*3*64+7*7*1*1*64*128=429632\)
计算量减少了百分之80以上。
分解过程示意图如下:
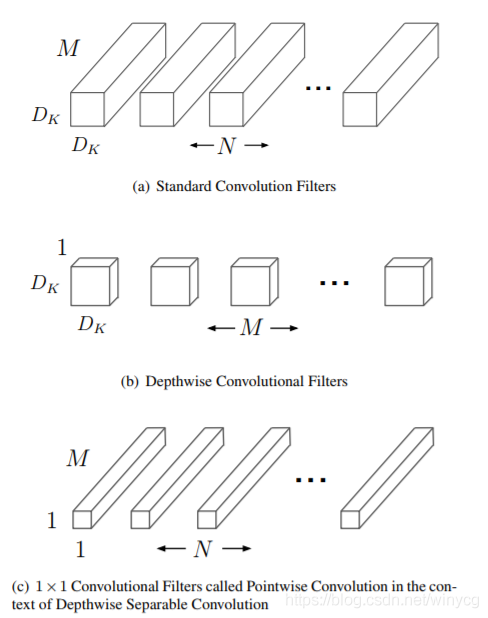
在图中可以看到:
- (a)表示一般卷积过程, 卷积核都是M个通道,然后总共有N和卷积核,意味着输入特征图有M个通道,然后输出特征图有N个通道。
- (b)表示depthwise过程, 总共有M个卷积核,这里是对输入特征图的M个通道分别做一个卷积,输出的特征图也是M个通道的;
- (c)表示pointwise过程,总共有N个\(1 \times 1\)的卷积核,这样来整合不同通道的信息,输出特征图有N个通道数。
2.3 网络结构

左图表示的是一般卷积过程,卷积之后跟上BN和ReLU激活层,因为DBC将分成了两个卷积过程,所以就变成了图右这种结构,Depthwise之后加上BN和ReLU,然后Pointwise之后再加上Bn和ReLU。
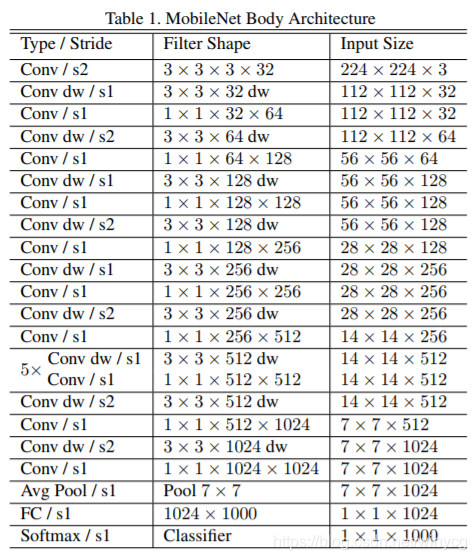
从整个网络结构可以看出来:
- 除了第一层为标准的卷积层之外,其他的层都为深度可分离卷积。
- 整个网络没有使用Pooling层。
3 PyTorch实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class Block(nn.Module):
'''Depthwise conv + Pointwise conv'''
def __init__(self, in_planes, out_planes, stride=1):
super(Block, self).__init__()
self.conv1 = nn.Conv2d\
(in_planes, in_planes, kernel_size=3, stride=stride,
padding=1, groups=in_planes, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv2 = nn.Conv2d\
(in_planes, out_planes, kernel_size=1,
stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
class MobileNet(nn.Module):
# (128,2) means conv planes=128, conv stride=2,
# by default conv stride=1
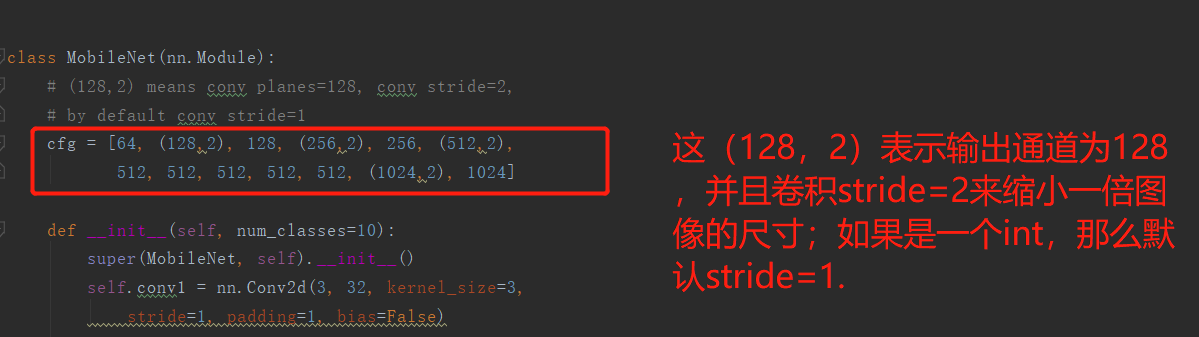
cfg = [64, (128,2), 128, (256,2), 256, (512,2),
512, 512, 512, 512, 512, (1024,2), 1024]
def __init__(self, num_classes=10):
super(MobileNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x if isinstance(x, int) else x[0]
stride = 1 if isinstance(x, int) else x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
net = MobileNet()
x = torch.randn(1,3,32,32)
y = net(x)
print(y.size())
> torch.Size([1, 10])
正常情况下这个预训练模型都会输出1024个线性节点,然后这里我自己加上了一个1024->10的一个全连接层。
我们来看一下这个网络结构:
print(net)
输出结果:
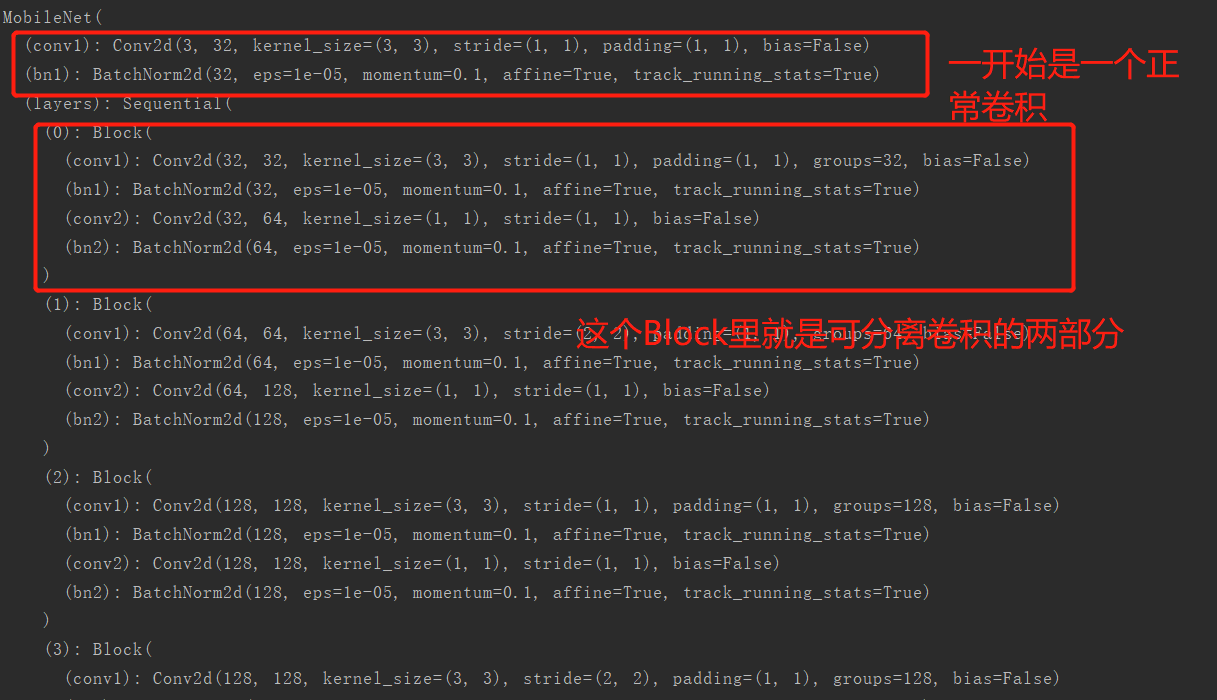
然后代码中:
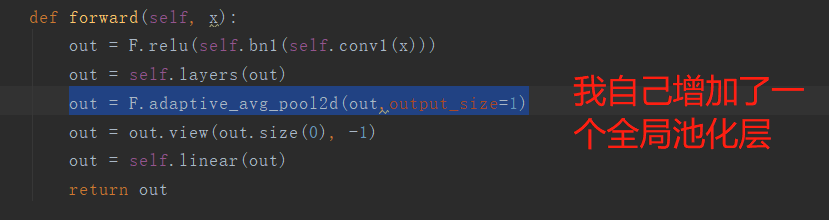
关于模型通道数的设置部分:
MobileNet就差不多完事了,下一节课为SENet的PyTorch实现和详解。
文章来自微信公众号【机器学习炼丹术】。我是炼丹兄,欢迎加我微信好友交流学习:cyx645016617。
【小白学PyTorch】11 MobileNet详解及PyTorch实现的更多相关文章
- Pytorch autograd,backward详解
平常都是无脑使用backward,每次看到别人的代码里使用诸如autograd.grad这种方法的时候就有点抵触,今天花了点时间了解了一下原理,写下笔记以供以后参考.以下笔记基于Pytorch1.0 ...
- Linux0.11信号处理详解
之前在看操作系统信号这一章的时候,一直是云里雾里的,不知道信号到底是个啥玩意儿..比如在看<Unix环境高级编程>时,就感觉信号是个挺神奇的东西.比如看到下面这段代码: #include& ...
- 【小白学PyTorch】12 SENet详解及PyTorch实现
文章来自微信公众号[机器学习炼丹术].我是炼丹兄,有什么问题都可以来找我交流,近期建立了微信交流群,也在朋友圈抽奖赠书十多本了.我的微信是cyx645016617,欢迎各位朋友. 参考目录: @ 目录 ...
- 【小白学PyTorch】13 EfficientNet详解及PyTorch实现
参考目录: 目录 1 EfficientNet 1.1 概述 1.2 把扩展问题用数学来描述 1.3 实验内容 1.4 compound scaling method 1.5 EfficientNet ...
- 【小白学PyTorch】10 pytorch常见运算详解
参考目录: 目录 1 矩阵与标量 2 哈达玛积 3 矩阵乘法 4 幂与开方 5 对数运算 6 近似值运算 7 剪裁运算 这一课主要是讲解PyTorch中的一些运算,加减乘除这些,当然还有矩阵的乘法这些 ...
- Pytorch数据读取详解
原文:http://studyai.com/article/11efc2bf#%E9%87%87%E6%A0%B7%E5%99%A8%20Sampler%20&%20BatchSampler ...
- 【Linux】一步一步学Linux——Linux系统目录详解(09)
目录 00. 目录 01. 文件系统介绍 02. 常用目录介绍 03. /etc目录文件 04. /dev目录文件 05. /usr目录文件 06. /var目录文件 07. /proc 08. 比较 ...
- Appium自动化(11) - 详解 Applications 类里的方法和源码解析
如果你还想从头学起Appium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1693896.html 前言 Applications 类 ...
- 4..一起来学hibernate之Session详解
后续... 后续... 后续... 后续... 后续... 后续... 后续... 后续... 后续... 后续... 后续... 后续... 后续... 后续... 后续...
随机推荐
- Android开发进程0.1 轮播图 Scrollview Fragment
轮播图的实现 轮播图通过banner可以较为便捷的实现 1.添加本地依赖,在dependence中搜索相关依赖 2.添加banner的view组件 3.创建适配器GlideImageLoader ex ...
- vue keep-alive 不生效和多级(三级以上)缓存失败
vue keep-alive https://cn.vuejs.org/v2/api/#keep-alive keep-alive 不生效的可能原因 如果安装官方的写法,已经正常完成keep-aliv ...
- 【译】GitHub 为什么挂?官方的可行性报告为你解答
本文翻译自 GitHub 官方博客<Introducing the GitHub Availability Report> 原文链接:https://github.blog/2020-07 ...
- 国人开源了一款小而全的 Java 工具类库,厉害啊!!
最近栈长看到了一款小而全的 Java 工具类库:Hutool,Github 已经接近 14K Star 了,想必一定很优秀,现在推荐给大家,很多轮子不要再造了! Hutool 是什么 Hutool 是 ...
- Windows下 Navicat Premium 15安装教程(图文,含注册)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明. 本文链接:https://www.cnblogs.com/zhangzhicheng1996/ ...
- CSS动画实例:跳跃的字符
1.翻转的字符 在页面中放置一个类名为container的层作为容器,在该层中放置5个字符区域,HTML代码描述如下: <div class="container"> ...
- SpringBoot--- 使用SpringSecurity进行授权认证
SpringBoot--- 使用SpringSecurity进行授权认证 前言 在未接触 SpringSecurity .Shiro 等安全认证框架之前,如果有页面权限需求需要满足,通常可以用拦截器, ...
- 【踩坑笔记】layui之单选和复选框不显示
直接上代码,下面前端页面代码,使用layui框架: <div class="layui-form-item"> <div class="lay ...
- openstack vnc 报1006的错误
1.问题现象 创建完虚拟机以后,通过nova get-vnc-console命令,获取虚机的vnc连接地址,在浏览器中打开该连接,报1006错误 2.vnc的原理图 3.定位分析 1)分别在控制节点和 ...
- latex:矩阵环境
矩阵的最大列数值是在MaxMatrixCols计数器中设定的,默认值是10.可使用计数器设置命令修改其值,例如需要用到15列:\setcounter{MaxMatrixCols}{15};当超宽矩阵排 ...