C语言实现数据结构的邻接矩阵----数组生成矩阵、打印、深度优先遍历和广度优先遍历
写在前面
图的存储结构有两种:一种是基于二维数组的邻接矩阵表示法。
另一种是基于链表的的邻接表表示法。
在邻接矩阵中,可以如下表示顶点和边连接关系:

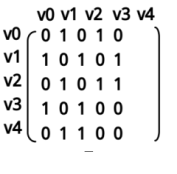
说明:
将顶点对应为下标,根据横纵坐标将矩阵中的某一位置值设为1,表示两个顶点向联接。
图示表示的是无向图的邻接矩阵,从中我们可以发现它们的分布关于斜对角线对称。
我们在下面将要讨论的是下图的两种遍历方法(基于矩阵的):
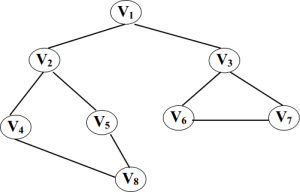
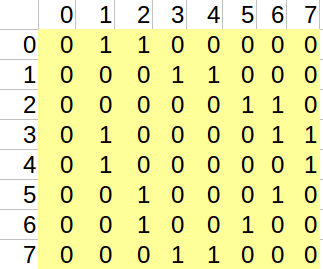
我们已经说明了我们要用到的是邻接矩阵表示法,那么我首先要来构造图:
1.深度优先遍历算法
分析深度优先遍历
从图的某个顶点出发,访问图中的所有顶点,且使每个顶点仅被访问一次。这一过程叫做图的遍历。
深度优先搜索的思想:
①访问顶点v;
②依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
③若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
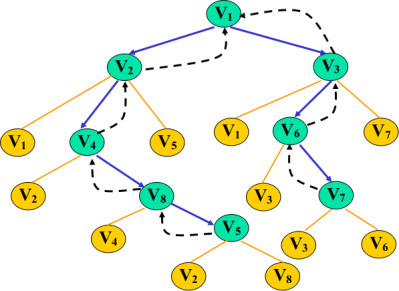
比如:
在这里为了区分已经访问过的节点和没有访问过的节点,我们引入一个一维数组bool visited[MaxVnum]用来表示与下标对应的顶点是否被访问过,
流程:
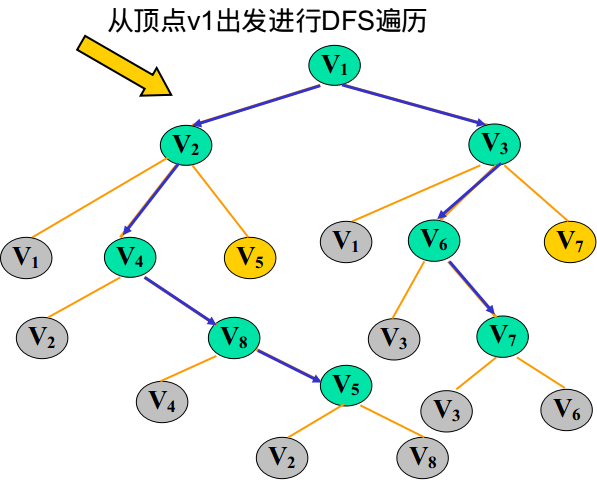
☐ 首先输出 V1,标记V1的flag=true;
☐ 获得V1的邻接边 [V2 V3],取出V2,标记V2的flag=true;
☐ 获得V2的邻接边[V1 V4 V5],过滤掉已经flag的,取出V4,标记V4的flag=true;
☐ 获得V4的邻接边[V2 V8],过滤掉已经flag的,取出V8,标记V8的flag=true;
☐ 获得V8的邻接边[V4 V5],过滤掉已经flag的,取出V5,标记V5的flag=true;
☐ 此时发现V5的所有邻接边都已经被flag了,所以需要回溯。(左边黑色虚线,回溯到V1,回溯就是下层递归结束往回返)
☐
☐ 回溯到V1,在前面取出的是V2,现在取出V3,标记V3的flag=true;
☐ 获得V3的邻接边[V1 V6 V7],过滤掉已经flag的,取出V6,标记V6的flag=true;
☐ 获得V6的邻接边[V3 V7],过滤掉已经flag的,取出V7,标记V7的flag=true;
☐ 此时发现V7的所有邻接边都已经被flag了,所以需要回溯。(右边黑色虚线,回溯到V1,回溯就是下层递归结束往回返)
深度优先搜索的代码
2.广度优先搜索算法
分析广度优先遍历
所谓广度,就是一层一层的,向下遍历,层层堵截,还是这幅图,我们如果要是广度优先遍历的话,我们的结果是V1 V2 V3 V4 V5 V6 V7 V8。
广度优先搜索的思想:
① 访问顶点vi ;
② 访问vi 的所有未被访问的邻接点w1 ,w2 , …wk ;
③ 依次从这些邻接点(在步骤②中访问的顶点)出发,访问它们的所有未被访问的邻接点; 依此类推,直到图中所有访问过的顶点的邻接点都被访问;
说明:
为实现③,需要保存在步骤②中访问的顶点,而且访问这些顶点的邻接点的顺序为:先保存的顶点,其邻接点先被访问。 这里我们就想到了用标准模板库中的queue队列来实现这种先进现出的服务。
老规矩我们还是走一边流程:
说明:
☐将V1加入队列,取出V1,并标记为true(即已经访问),将其邻接点加进入队列,则 <—[V2 V3]
☐取出V2,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V3 V4 V5]
☐取出V3,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V4 V5 V6 V7]
☐取出V4,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V5 V6 V7 V8]
☐取出V5,并标记为true(即已经访问),因为其邻接点已经加入队列,则 <—[V6 V7 V8]
☐取出V6,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V7 V8]
☐取出V7,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V8]
☐取出V8,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[]
两种表示法:
邻接矩阵完整代码:
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
//邻接矩阵
#define OK 1
#define ERROR 0 #define MAXNUM 10 typedef int Status;
typedef char ElemType;
typedef struct
{
int vnum; //顶点数
int anum; //弧/边数
ElemType vex[MAXNUM]; //存储顶点
int arc[MAXNUM][MAXNUM]; //存储边关系
}MGraph; int Location(MGraph G, ElemType e)
{
int v;
for (v = 0; v<G.vnum; v++)
if (G.vex[v] == e)return v;
return -1; } Status CreateGraph(MGraph &G, int vnum, int anum, ElemType v[], ElemType a[]) //数组生成图
{
int k;
G.vnum = vnum; //获取数组顶点数
G.anum = anum; //获取数组边数
for (k = 0; k<G.vnum; k++)
G.vex[k] = v[k];
for (int i = 0; i<G.vnum; i++)
{
for (int j = 0; j<G.vnum; j++)
G.arc[i][j] = 0;
}
int t = 0;
int p, q;
for (k = 0; k<G.anum; k++)
{
ElemType m, n;
m = a[t++];
n = a[t++];
t++;
p = Location(G, m);
q = Location(G, n);
G.arc[p][q] = 1;
G.arc[q][p] = 1;
}
return OK;
} void Print(MGraph G)
{
int v;
printf("顶点序列为:\n");
for (v = 0; v<G.vnum; v++)
printf("%3c", G.vex[v]);
printf("\n");
printf("边的二维数组关系:\n");
for (int i = 0; i<G.vnum; i++)
{
for (int j = 0; j<G.vnum; j++)
printf("%3d", G.arc[i][j]);
printf("\n");
}
printf("\n");
} int FirstAdjVex(MGraph G, int i)
{
int v;
if (i<0 || i >= G.vnum)return -1;
for (v = 0; v<G.vnum; v++)
if (G.arc[i][v] == 1)return v;
return -1;
} int NextAdjVex(MGraph G, int i, int j)
{
if (i<0 || i >= G.vnum)return -1;
if (j<0 || j >= G.vnum)return -1;
for (int v = j + 1; v<G.vnum; v++)
if (G.arc[i][v] == 1)return v;
return -1;
} //DFS遍历
int visited[MAXNUM];
void DFS(MGraph G, int v);
void DFSTraverse(MGraph G)
{
printf("深度优先遍历为:\n");
int v;
for (v = 0; v<G.vnum; v++)
visited[v] = 0;
for (v = 0; v<G.vnum; v++)
{
if (visited[v] == 0)DFS(G, v);
}
}
void DFS(MGraph G, int v)
{
printf("%3c", G.vex[v]);
visited[v] = 1;
int w = FirstAdjVex(G, v);
while (w != -1)
{
if (visited[w] == 0)DFS(G, w);
w = NextAdjVex(G, v, w);
}
} //BFS遍历
typedef struct QNode
{
ElemType data;
struct QNode *next;
}QNode, *QueuePtr; //定义队列的指针类型为QueuePtr,定义队列结点内存空间类型为QNode
typedef struct
{
QueuePtr front; //front为头指针,指向头结点。Q.front->next指针存在头结点的指针域(即其存着首结点的地址),是头结点的指针,指向首结点
QueuePtr rear;
}LinkQueue; //定义队列结点类型为LinkQueue Status InitQueue(LinkQueue &Q)
{
Q.front = (QNode*)malloc(sizeof(QNode));
if (!Q.front)return ERROR;
Q.front->next = NULL;
Q.rear = Q.front;
return OK;
} Status EnQueue(LinkQueue &Q, ElemType e) //入队
{
QueuePtr p;
p = (QNode*)malloc(sizeof(QNode)); //生成新结点p
if (!p)return ERROR;
p->next = NULL; //新结点的指针p->next置空
p->data = e; //新结点暂存e
Q.rear->next = p; //队尾结点的指针Q.rear->next指向新结点p
Q.rear = p; //队尾指针Q.rear指向p
return OK;
} Status DeQueue(LinkQueue &Q, ElemType &e) //出队
{
QueuePtr p;
if (Q.rear == Q.front) //确保队列有首结点
return ERROR;
p = Q.front->next; //指针p暂存被删结点(首结点)的地址
Q.front->next = p->next; //头结点的指针Q.front->next指向首结点的下一结点
e = p->data;
if (Q.front->next == Q.rear) //判断原队列是否只有首结点
Q.rear = Q.front;
free(p);//清空
return OK;
} bool EmptyQueue(LinkQueue Q) //判空
{
if (Q.front == Q.rear)return true;
else return false;
} void BFS(MGraph G)
{
printf("广度优先遍历为:\n");
int v;
LinkQueue Q;
InitQueue(Q);
for (v = 0; v<G.vnum; v++) //初始化
visited[v] = 0;
for (v = 0; v<G.vnum; v++)
{
if (visited[v] == 1)continue;
printf("%3c", G.vex[v]);
visited[v] = 1;
EnQueue(Q, G.vex[v]);
while (EmptyQueue == 0)
{
int v;
ElemType e;
DeQueue(Q, e);
v = Location(G, e);
int w = FirstAdjVex(G, v);
while (w != -1)
{
w = NextAdjVex(G, v, w);
if (visited[w] = 1)continue;
printf("%3c", G.vex[w]);
EnQueue(Q, G.vex[w]);
visited[w] = 1;
}
}
}
} int main()
{
MGraph G;
ElemType v[] = "abcdef"; //顶点数组
ElemType a[] = "ab,ac,ad,be,ce,df"; //边数组
CreateGraph(G, 6, 6, v, a);
Print(G);
DFSTraverse(G);
printf("\n");
BFS(G);
printf("\n");
system("pause");
return 0;
}//
邻接表完整代码:
#include<stdio.h>
#include<malloc.h> #define OK 1
#define ERROR 0 #define MAXNUM 10 typedef int Status;
typedef char ElemType;
typedef struct ANode
{
int adjvex; //邻接点域
struct ANode *next; //邻接点指针域
}ANode; //ANode为单链表的指针类型
typedef struct
{
ElemType data;
ANode *firstarc; //定义单链表的头指针为firstarc
}VNode; //VNode为顶点数组元素的类型
typedef struct
{
int vnum,anum; //顶点数,边数
VNode vex[MAXNUM]; //顶点集
}ALGraph; //ALGraph邻接表类型 int Location(ALGraph G, ElemType e)
{
int v;
for (v = 0; v<G.vnum; v++)
if (G.vex[v].data == e)return v;
return -1;
} Status CreatGraph(ALGraph &G, int vnum, int anum, ElemType v[], ElemType a[])
{
int k, t = 0;
G.vnum = vnum;
G.anum = anum;
for (k = 0; k<G.vnum; k++)
{
G.vex[k].data = v[k];
G.vex[k].firstarc = NULL;//易忘记
}
for (k = 0; k<G.anum; k++)
{
ElemType m, n;
ANode *p1, *p2, *p3;
int p, q;
m = a[t++];
n = a[t++];
t++;
p = Location(G, m);
q = Location(G, n);
p1 = (ANode*)malloc(sizeof(ANode));
if (p1 == NULL)return ERROR;
p1->adjvex = q;
p1->next = NULL;
if (G.vex[p].firstarc == NULL)
G.vex[p].firstarc = p1;
else
{
p3 = G.vex[p].firstarc;
while (p3->next)
p3 = p3->next;
p3->next = p1;
}
p2 = (ANode*)malloc(sizeof(ANode));
if (!p2)return ERROR;
p2->adjvex = p;
p2->next = NULL;
if (G.vex[q].firstarc == NULL)
G.vex[q].firstarc = p2;
else
{
p3 = G.vex[p].firstarc;
while (p3->next)
p3 = p3->next;
p3->next = p2;
} }
return OK;
} int FirstAdjVex(ALGraph G, int v)
{
if (v<0 || v >= G.vnum)return -1;
if (G.vex[v].firstarc != NULL)
return G.vex[v].firstarc->adjvex;
return -1;
} int NextAdjVex(ALGraph G, int v, int w)
{
ANode *p;
p = G.vex[v].firstarc;
if (v<0 || v >= G.vnum)return -1;
if (w<0 || w >= G.vnum)return -1;
while (p&&p->adjvex != w)
p = p->next;
if (p != NULL || p->next != NULL)
return p->next->adjvex;
return -1;
} //DFS
int visited[MAXNUM];
void DFS(ALGraph G, int v);
void DFSTraverse(ALGraph G)
{
printf("深度遍历为:\n");
int v;
for (v = 0; v<G.vnum; v++)
visited[v] = 0;
for (v = 0; v<G.vnum; v++)
if (visited[v] == 0)DFS(G, v);
printf("\n");
}
void DFS(ALGraph G, int v)
{
int w;
printf("%3c", G.vex[v].data);
visited[v] = 1;
w = FirstAdjVex(G, v);
while (w != -1)
{
if (visited[w] == 0)DFS(G, w);
w = NextAdjVex(G, v, w);
} } //BFS遍历-链队列
typedef struct QNode
{
ElemType data;
struct QNode *next;
}QNode, *QueuePtr;
typedef struct
{
QueuePtr front;
QueuePtr rear;
}LinkQueue; Status InitQueue(LinkQueue &Q)
{
Q.front = (QNode*)malloc(sizeof(QNode));
if (!Q.front)return ERROR;
Q.front->next = NULL;
Q.rear = Q.front;
return OK;
}
//入队
Status EnQueue(LinkQueue &Q, ElemType e)
{
QueuePtr p;
p = (QNode*)malloc(sizeof(QNode));
if (!p)return ERROR;
p->next = NULL;
p->data = e;
Q.rear->next = p;
Q.rear = p;
return OK;
} //出队
Status DeQueue(LinkQueue &Q, ElemType &e)
{
QueuePtr p;
if (Q.rear == Q.front)
return ERROR;
p = Q.front->next;
Q.front->next = p->next;
if (Q.front->next == Q.rear)
Q.rear = Q.front;
e = p->data;
free(p);//清空
return OK;
} //判空
bool EmptyQueue(LinkQueue Q)
{
if (Q.front == Q.rear)return true;
else return false;
} //BFS
void BFS(ALGraph G)
{
printf("广度优先遍历为:\n");
int v;
LinkQueue Q;
InitQueue(Q);
for (v = 0; v<G.vnum; v++)//初始化
visited[v] = 0;
for (v = 0; v<G.vnum; v++)
{
if (visited[v] == 1)continue;
printf("%3c", G.vex[v].data);
visited[v] = 1;
EnQueue(Q, G.vex[v].data);
while (EmptyQueue == 0)
{
int v;
ElemType e;
DeQueue(Q, e);
v = Location(G, e);
int w = FirstAdjVex(G, v);
while (w != -1)
{
w = NextAdjVex(G, v, w);
if (visited[w] = 1)continue;
printf("%3c", G.vex[w].data);
EnQueue(Q, G.vex[w].data);
visited[w] = 1;
}
}
}
} int main()
{
ALGraph G;
ElemType v[] = "abcdef";
ElemType a[] = "ab,ac,ad,be,ce,df";
CreatGraph(G, 6, 6, v, a);
DFSTraverse(G);
BFS(G);
getchar();
return 0;
}
C语言实现数据结构的邻接矩阵----数组生成矩阵、打印、深度优先遍历和广度优先遍历的更多相关文章
- C++编程练习(9)----“图的存储结构以及图的遍历“(邻接矩阵、深度优先遍历、广度优先遍历)
图的存储结构 1)邻接矩阵 用两个数组来表示图,一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中边或弧的信息. 2)邻接表 3)十字链表 4)邻接多重表 5)边集数组 本文只用代码实现用 ...
- 邻接矩阵c源码(构造邻接矩阵,深度优先遍历,广度优先遍历,最小生成树prim,kruskal算法)
matrix.c #include <stdio.h> #include <stdlib.h> #include <stdbool.h> #include < ...
- 邻接表c源码(构造邻接矩阵,深度优先遍历,广度优先遍历,最小生成树prim,kruskal算法)
graph.c #include <stdio.h> #include <stdlib.h> #include <limits.h> #include " ...
- 数据结构与算法之PHP用邻接表、邻接矩阵实现图的广度优先遍历(BFS)
一.基本思想 1)从图中的某个顶点V出发访问并记录: 2)依次访问V的所有邻接顶点: 3)分别从这些邻接点出发,依次访问它们的未被访问过的邻接点,直到图中所有已被访问过的顶点的邻接点都被访问到. 4) ...
- 数据结构5_java---二叉树,树的建立,树的先序、中序、后序遍历(递归和非递归算法),层次遍历(广度优先遍历),深度优先遍历,树的深度(递归算法)
1.二叉树的建立 首先,定义数组存储树的data,然后使用list集合将所有的二叉树结点都包含进去,最后给每个父亲结点赋予左右孩子. 需要注意的是:最后一个父亲结点需要单独处理 public stat ...
- 20145205 java语言实现数据结构实验一
数据结构实验要求 综合类实验设计3 已知有一组数据a1a2a3a4--anb1b2b3b4--bm,其中ai均大于bj,但是a1到an和b1到bm不是有序的,试设计两到三个算法完成数据排序,且把bj数 ...
- (2)redis的基本数据结构是动态数组
redis的基本数据结构是动态数组 一.c语言动态数组 先看下一般的动态数组结构 struct MyData { int nLen; ]; }; 这是个广泛使用的常见技巧,常用来构成缓冲区.比起指针, ...
- [C] 在 C 语言编程中实现动态数组对象
对于习惯使用高级语言编程的人来说,使用 C 语言编程最头痛的问题之一就是在使用数组需要事先确定数组长度. C 语言本身不提供动态数组这种数据结构,本文将演示如何在 C 语言编程中实现一种对象来作为动态 ...
- 图的建立(邻接矩阵)+深度优先遍历+广度优先遍历+Prim算法构造最小生成树(Java语言描述)
主要参考资料:数据结构(C语言版)严蔚敏 ,http://blog.chinaunix.net/uid-25324849-id-2182922.html 代码测试通过. package 图的建 ...
随机推荐
- CCF-202006-1线性分类器
1 def judga(lis1,z): #判断列表lis1中点是否都在线z的一侧 s=0 for i in lis1: if z[0]+i[0]*z[1]+i[1]*z[2]>0: s+=1 ...
- selenium定位方法(一)
selenium定位方法-(一) 1.定位页面元素的方式(By类的方法) 1)id定位:通过页面元素的id属性值来定位一个页面元素 注意事项:如果每次刷新网页之后元素的id属性值都不同,说 ...
- JVM大作业5——指令集
JVM的每一个线程都有一个虚拟机栈,方法调用时,JVM会在虚拟机栈内为该方法创建一个栈帧. 一条线程,只有正在执行的方法对应的栈帧时可活动的,这个栈帧被称为当前栈帧,当前栈帧对应的方法被称为当前方法, ...
- 模型层中QuerySet的学习
创建对象 使用关键字参数实例化模型实例来创建一个对象,然后调用save()把它保存到数据库中 pub_obj = models.Publisher(title='奥利给出版社') pub_obj.sa ...
- A+B in Hogwarts (20)(模拟)
时间限制 1000 ms 内存限制 65536 KB 代码长度限制 100 KB 判断程序 Standard (来自 小小) 题目描述 If you are a fan of Harry Potter ...
- SpringSecurity中的Authentication信息与登录流程
目录 Authentication 登录流程 一.与认证相关的UsernamePasswordAuthenticationFilter 获取用户名和密码 构造UsernamePasswordAuthe ...
- Linux 用户与权限
这些天一直在看Linux的命令但是却没有写文章,因为感觉没有必要,哪些简单的命令,vi cat cd 啥的,是个做开发的就知道,所以就没写; 用户管理 第一个我们知道的用户就是Root 没错哦,这就是 ...
- IOException的子类
ChangedCharSetException, CharacterCodingException, CharConversionException, ClosedChannelException, ...
- Python中自己不熟悉的知识点记录
重点笔记: Python 它是动态语言 动态语言的定义:动态编程语言 是 高级程序设计语言 的一个类别,在计算机科学领域已被广泛应用.它是一类 在 运行时可以改变其结构的语言 : ...
- 10行实现最短路算法——Dijkstra
今天是算法数据结构专题的第34篇文章,我们来继续聊聊最短路算法. 在上一篇文章当中我们讲解了bellman-ford算法和spfa算法,其中spfa算法是我个人比较常用的算法,比赛当中几乎没有用过其他 ...