RabbitMQ安装、集群搭建、概念解析
RabbitMQ安装、集群搭建、概念解析
基本概念
为什么会产生MQ
1.解耦:采用异步方式实现业务需求达到解耦的目的。
2.缓冲流量,削峰填谷:
问:为什么会有流量冲击?
答:采用“直接调用”,会有一个缺点,下游消息接收方无法控制到达自己的流量,如果调用方不进行限速,很有可能把下游压垮。
举个例子,秒杀业务: 上游发起下单操作,下游完成秒杀业务逻辑(库存检查,库存冻结,余额检查,余额冻结,订单生成,余额扣减,库存扣减,生成流水,余额解冻,库存解冻) 上游下单业务简单,每秒发起了10000个请求,下游秒杀业务复杂,每秒只能处理2000个请求,很有可能上游不限速的下单,导致下游系统被压垮,引发雪崩。
所以可以升级为MQ-client拉模式。
MQ-client根据自己的处理能力,每隔一定时间,或者每次拉取若干条消息,实施流控,达到保护自身的效果。并且这是MQ提供的通用功能,无需上下游修改代码。
RabbitMQ就是对于消息中间件的一种实现,市面上还有很多很多实现, 比如ActiveMQ、ZeroMQ、kafka,以及阿里开源的RocketMQ等等。
安装说明
RabbitMQ有两种方法可以安装:
1、使用Package Cloud或Bintray上的Yum存储库安装软件包。
2、下载软件包并使用rpm安装。此选项将需要手动安装所有软件包依赖项。
本文档介绍的是第二种
安装前提
由于RabbitMQ是由Erlang语言开发,所以需要先安装Erlang,解决依赖关系后,就可以安装RabbitMQ了。同时,在安装Erlang前,需要先安装socat,socat主要就是用于在两个数据流之间建立通道,RabbitMQ建立通道需要socat工具的支持。
安装步骤
安装socat
- yum -y install socat
下载RPM包
版本需要对应
具体对应关系请参考官方文档:https://www.rabbitmq.com/which-erlang.html
- #erlang 适用于3.8.4-3.8.5的RabbitMQ
- wget https://github.com/rabbitmq/erlang-rpm/releases/download/v22.3.4.4/erlang-22.3.4.4-1.el7.x86_64.rpm
- #适用于RHEL Linux 7.x,CentOS 7.x,Fedora 24+的RPM(支持systemd)
- wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.5/rabbitmq-server-3.8.5-1.el7.noarch.rpm
安装Erlang
- # rpm包路径执行
- rpm -ivh erlang-22.3.4.4-1.el7.x86_64.rpm
安装RabbitMQ
- # rpm包路径执行
- rpm -ivh rabbitmq-server-3.8.5-1.el7.noarch.rpm
配置
端口开启白名单
安装成功以后需要把15672端口开启白名单
- #查看防火墙开启端口
- firewall-cmd --list-ports
- #开启15672端口
- firewall-cmd --zone=public --add-port=15672/tcp --permanent
- #重启防火墙
- systemctl restart firewalld
- #查看端口可以知道添加成功,然后去浏览器打开网页
- firewall-cmd --list-ports
启用management插件
启用插件以后才可以在浏览器访问MQ的管理端
- rabbitmq-plugins enable rabbitmq_management
启动RabbitMQ服务、启动RabbitMQ应用
- service rabbitmq-server start或nohup rabbitmq-server –detached &
- rabbitmqctl start_app
创建配置文件
在/etc/rabbitmq/路径下创建配置文件:rabbitmq-env.conf
写入节点名称:
- NODENAME=rabbit@rabbitmq_node01
标红部分需要和hosts文件保持一致,可以修改hosts文件,加入以下配置
- 127.0.0.1 rabbitmq_node01
注意:如果缺少了这个步骤的话,后面创建的虚拟主机和用户信息,在服务器重启以后会被自动删除,导致用户无法登录。
修改日志路径和持久化数据路径
该步骤不是必要的(默认路径是/var/lib/rabbitmq和/var/log/rabbitmq,如果不需要修改,该步骤可以略过)
注意:该步骤配置会导致原来的数据丢失(包括用户信息和虚拟主机信息),所以如果你创建用户以后才执行该步骤,执行结束以后需要重新创建用户信息和虚拟主机信息。
1、 关闭MQ服务
- service rabbitmq-server stop
2、创建自己的路径
- mkdir -p /opt/weishidv/rabbitmq/mnesia
- mkdir -p /opt/weishidv/rabbitmq/log
- chmod -R 777 /opt/weishidv/rabbitmq
- chown -R rabbitmq:rabbitmq /opt/weishidv/rabbitmq/mnesia
- chown -R rabbitmq:rabbitmq /opt/weishidv/rabbitmq/log
3、修改配置文件:rabbitmq-env.conf,加入以下配置:
- MNESIA_BASE=/opt/weishidv/rabbitmq/mnesia
- LOG_BASE= /opt/weishidv/rabbitmq/log
4、开启服务
- service rabbitmq-server start
创建虚拟主机
交换机、队列和绑定都是基于虚拟主机来实现业务操作的,每个虚拟主机下面持有一组交换机、队列和绑定,起到隔离的作用,MQ默认有一个虚拟主机 /
- rabbitmqctl add_vhost 【Vhost_Name】
创建用户
- rabbitmqctl add_user admin 【password】
设置用户权限、修改用户角色
- #使用户admin具有【Vhost_Name】这个virtual host中所有资源的配置、读、写权限
- rabbitmqctl set_permissions -p "【Vhost_Name】" admin ".*" ".*" ".*"
- #赋予administrator角色(有最高权限),每种角色的作用请参考下面的概念
- rabbitmqctl set_user_tags admin administrator
设置开机自启动
- chkconfig rabbitmq-server on
安装结束…
卸载步骤
停止MQ应用
- rabbitmqctl stop_app
停止MQ服务
- service rabbitmq-server stop
卸载MQ
- yum -y remove rabbitmq-server.noarch
卸载erlang
- yum list | grep erlang
- yum -y remove erlang-22.3.4.4-1.el7.x86_64
删除相关文件
- #删除相关的文件和文件夹
- rm -rf /usr/lib64/erlang
- rm -rf /var/lib/rabbitmq
集群搭建
节点数建议
官网建议用奇数个节点搭建集群,因为集群里面的若干功能需要集群成员之间达成共识(即类似于领导者选举必须满足过半机制,具体机制可参考:https://www.cnblogs.com/kevingrace/p/12433503.html)。
并且强烈不建议使用两个节点搭建集群。
官网说明:
https://www.rabbitmq.com/clustering.html#node-count
集群方案说明
集群主要分为两种:普通集群和镜像集群(高可用集群)
该文档介绍的是镜像集群搭建
普通集群
以两个节点(A、B)为例来进行说明。
A和B两个节点仅有相同的元数据,即队列的结构,但消息实体只存在于其中一个节点中。当消息进入A节点的Queue后,consumer从B节点消费时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立Queue。否则无论consumer连A或B,出口总在A,会产生瓶颈。当A节点故障后,B节点无法取到A节点中还没有消费的消息实体。如果做了消息持久化,那么得等A节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象。
镜像集群
在普通集群的基础上,把需要的队列做成镜像队列,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取,也就是说多少节点消息就会备份多少份。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用。
由于镜像队列之间消息自动同步,且内部有选举master机制,即使master节点宕机也不会影响整个集群的使用,达到去中心化的目的,从而有效的防止消息丢失及服务不可用等问题。
要强调的是:
1、互为镜像的是队列,并非节点,也就是说队列的master可以分布在不同的节点上。一个queue第一次创建的node为它的master节点,其它node为slave节点。
2、消息的读写都是在master上进行。slave节点仅提供备份功能,如果master节点挂了的话会从slave节点中选择一个存活时间最长的节点升级为master节点。
3、无论客户端的请求打到master还是slave,最终数据都是从master节点获取。
当请求打到master节点时,master节点直接将消息返回给client,同时master节点会将queue的最新状态广播到slave节点。当请求打到slave节点时,slave节点需要将请求先重定向到master节点,master节点将将消息返回给client,同时master节点会将queue的最新状态广播到slave节点。
镜像集群的原理参考地址:https://www.rabbitmq.com/ha.html#behaviour
搭建步骤
1、 主机信息
- 10.0.2.100 #以下称 节点1
- 10.0.2.101 #以下称 节点2
- 10.0.2.102 #以下称 节点3
2、 RabbitMQ节点之间相互寻址需要用到域名,所以需要修改所有节点的/etc/hosts文件保持一致
- 127.0.0.1 rabbitmq_node01
- ::1 rabbitmq_node01
- 10.0.2.101 rabbitmq_node02
- 10.0.2.102 rabbitmq_node03
3、 配置文件修改
rabbitmq-env.conf ,用于配置RabbitMQ服务器使用的环境变量
每个节点都需要新增,然后写入节点的名称,新增路径:/etc/rabbitmq/rabbitmq-env.conf
- NODENAME=rabbit@rabbitmq_node01
- NODENAME=rabbit@rabbitmq_node02
- NODENAME=rabbit@rabbitmq_node03
4、 RabbitMQ节点和CLI工具使用cookie来确定是否允许它们彼此通信。为了使两个节点能够通信,它们必须具有相同的Erlang cookie。Cookie只是一串字母数字字符,最大长度为255个字符。文件路径为:/var/lib/rabbitmq/.erlang.cookie
- 将节点1的/var/lib/rabbitmq/.erlang.cookie复制到节点2和节点3(节点1执行)
- scp –p port /var/lib/rabbitmq/.erlang.cookie root@rabbitmq_node02:/var/lib/rabbitmq
- #修改文件权限只读(2、3节点执行)
- chmod 400 /var/lib/rabbitmq/.erlang.cookie
- chown -R rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
5、 为了链接集群中的三个节点,例如节点2和节点3要入节点1,在此之前,必须重新设置两个新加入的成员。首先将节点2与节点1一起加入集群。所以,在节点2上,停止RabbitMQ应用程序并加入节点1集群,然后重新启动节点2的RabbitMQ应用程序。请注意,必须先重置节点才能加入现有集群。重置节点将删除该节点上先前存在的所有资源和数据。
在节点2里面:
- #停止MQ应用,如果报错,需要重启MQ服务和应用在执行如下命令
- rabbitmqctl stop_app
- #重置节点
- rabbitmqctl reset
- # 节点2加入到节点1的集群中 --ram表示节点2为RAM节点,默认为disc
- rabbitmqctl join_cluster rabbit@rabbitmq_node01 --ram
- #开启MQ应用
- rabbitmqctl start_app
注意:disk和RAM节点
节点可以是disk节点或RAM节点,默认是disc节点(注意: disk和disc可以互换使用)。RAM节点仅将内部数据库表存储在RAM中,可用于提高队列,交换或绑定流失率较高的群集的性能。RAM节点不提供更高的消息速率。由于RAM节点仅将内部数据库表存储在RAM中,因此它们必须在启动时从对等节点同步数据,这意味着一个群集必须至少包含一个disk节点。因此,不可手动删除集群中最后剩余的disk节点。
6、 在节点3里配置
- rabbitmqctl stop_app
- rabbitmqctl reset
- rabbitmqctl join_cluster rabbit@rabbitmq_node01 --ram
- rabbitmqctl start_app
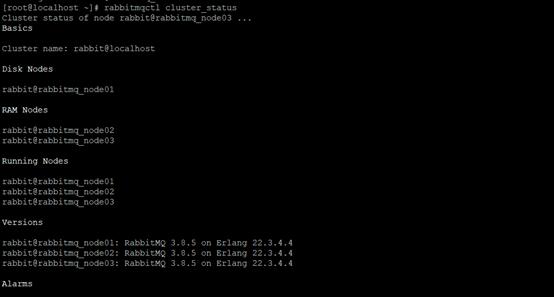
7、 查看集群状态(任意节点执行),可以看到三个节点已加入集群:
- rabbitmqctl cluster_status
8、 集群高可用配置(主节点执行),在普通集群的基础上添加一些镜像策略即可
- #对虚拟主机mailMsgHost下的所有的队列进行镜像,并在集群的两个节点上完成镜像
- rabbitmqctl set_policy -p mailMsgHost ha-two "^" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
最佳镜像数量参考官网:
https://www.rabbitmq.com/ha.html#replication-factor
大致意思:对于3个或更多节点的群集,建议复制到多数节点,例如3节点群集中的2个节点或5节点群集中的3个节点。
rabbitmqctl set_policy具体参数的含义可以参考:
https://my.oschina.net/genghz/blog/1840262#h3_4
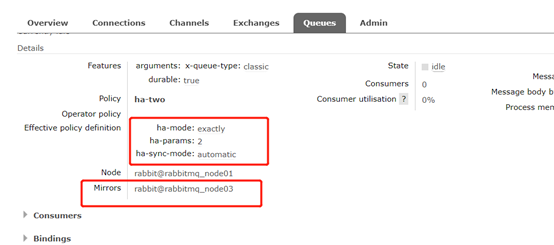
9、 搭建成功
队列中出现如下图所示即表示镜像集群搭建成功
10、集群节点剔除
- #先停止该节点应用
- rabbitmqctl stop_app
- #剔除
- rabbitmqctl forget_cluster_node node_name
常用操作命令
应用管理
- #开启MQ服务器
- service rabbitmq-server start
- #关闭MQ服务器
- service rabbitmq-server stop
- #重启MQ服务器
- service rabbitmq-server restart
- #关闭MQ应用
- rabbitmqctl stop_app
- #启动MQ应用
- rabbitmqctl start_app
- #查看MQ状态
- rabbitmqctl status
用户管理
- #添加用户
- rabbitmqctl add_user username password
- #删除用户
- rabbitmqctl delete_user username
- #修改密码
- rabbitmqctl change_password username newpassword
- #列出所有用户及角色信息
- rabbitmqctl list_users
用户权限管理
- rabbitmqctl set_permissions -p VHostPath User ConfP WriteP ReadP
用户权限指用户对exchange,queue的操作权限,包括配置权限,读写权限。配置权限会影响到exchange,queue的声明和删除。读写权限影响到从queue里取消息,向exchange发送消息以及queue和exchange的绑定(bind)操作等等
授权分三个操作:
读:有关消费消息的任何操作,包括"清除"整个队列
写:发布消息
配置:队列和交换机的创建和删除
- #对wskp_user用户授权,禁止配置、只能写virus开头的交换机、可以读取任何队列
- rabbitmqctl set_permissions -p mailMsgHost wskp_user " " "virus.*" ".*"
- 说明:
- 双引号中的信息为正则表达式
- ".*" 表示配置任何队列和交换机
- "virus.*"表示只能配置名字以"virus"开头的队列和交换机
- " " 不匹配队列和交换机
- #查看所有策略
- rabbitmqctl list_policies -p 【vhost】
- #删除指定策略
- rabbitmqctl clear_policy -p 【vhost】【name】
- #列出每一个队列的主服务器和镜像服务器,下图中的三个队列test1、test2、test3分别是在node1、node2、node3三个主机上创建的,可以看出,他的主节点就是创建队列的节点,镜像节点是随机的其他任意节点。
- rabbitmqctl list_queues -p 【vhost】name policy pid slave_pids
镜像策略管理
RabbitMQ各类角色
none、management、policymaker、monitoring、administrator
none
不能访问 management
plugin,即普通的生成这和消费者。
management
用户可以通过AMQP做的任何事外加:
列出自己可以通过AMQP登入的virtual hosts
查看自己的virtual hosts中的queues, exchanges 和 bindings
查看和关闭自己的channels 和 connections
查看有关自己的virtual
hosts的“全局”的统计信息,包含其他用户在这些virtual hosts中的活动。
policymaker
management可以做的任何事外加:
查看、创建和删除自己的virtual
hosts所属的policies和parameters
monitoring
management可以做的任何事外加:
列出所有virtual hosts,包括他们不能登录的virtual hosts
查看其他用户的connections和channels
查看节点级别的数据如clustering和memory使用情况
查看真正的关于所有virtual
hosts的全局的统计信息
administrator
policymaker和monitoring可以做的任何事外加:
创建和删除virtual hosts
查看、创建和删除users
查看创建和删除permissions
关闭其他用户的connections
管理端参数详解
Overview
Totals
所有队列的阻塞情况
Ready:等待消费的消息总数。
Unacked:等待消费确认(ack)的消息总数。
Total:总数
Ready+Unacked。
Disk read:队列从磁盘读取消息的速率。
Disk write:队列从磁盘写入消息的速率。
Connections:client的tcp连接的总数。
Channels:通道的总数。
Exchange:交换机的总数。
Queues:队列的总数。
Consumers:消费者的总数。
Nodes
启动一个broker(RabbitMQ服务)就会产生一个node
Name:broker名称(节点名称)。
File descriptors:文件描述符。为防止某一单一进程打开过多文件描述符而耗尽系统资源,对进程打开文件数做了限制;
Socket
descriptors:对网络套接字数量和限制。当限制被耗尽时,RabbitMQ将停止接受新的网络连接。
Erlang processes:erlang启动的进程数。
Memory:当前broker占用的内存。
Disk space:当前broker占用的硬盘。
Uptime:当前broker持续运行的时长。
Info:一些节点的属性,比如节点类型。
Reset stats:重置这个节点或所有节点。
Churn statistics
流失统计
Connection operations :连接操作,创建连接和关闭连接的速率。
Channel operations:通道操作,创建通道和关闭通道的速率。
Queue operations:队列操作,客户端声明队列,创建队列和删除队列的速率。
Ports and contexts
监听端口信息
Protocol:协议。amqp为5672(MQ服务默认TCP监听端口),http为15672(管理端访问端口),clustering为25672(用于集群环境各个节点之间的通信的端口)。
Node:节点名称
Port:占用端口
修改端口:
新增配置文件:/etc/rabbitmq/rabbitmq.conf
官网地址:https://www.rabbitmq.com/management.html
- #数据管理端口
- listeners.tcp.default = 5672
- #界面管理端口
- management.tcp.port = 15672
- management.tcp.ip = 0.0.0.0
Export definitions
可以导出目前服务中的一些信息,比如用户,虚拟主机,权限,参数,交换,队列和绑定。
Import definitions
和上面相反,可以导入信息,导入的定义将与当前定义合并。 如果在导入过程中发生错误,则所做的任何更改都不会回滚。
Connections
当前所有客户端活动的连接。包括生产者和消费者。
Virtual host:所属的虚拟主机。
Name:连接名称。
Node:连接的节点名称。
User name:使用的用户名。
State:当前的状态,running:运行中;idle:空闲。
SSL/TLS:为保证通信的安全性,通常使用SSL/TLS加密通信。
Protocol:使用的协议。
Channels:创建的通道总数。
From client:每秒发出的数据包。
To client:每秒收到的数据包。
Channels
当前连接所有创建的通道。
channel:通道名称。
Virtual host:所属的虚拟主机。
User name:使用的用户名。
Mode:通道保证模式。 C: confirm(确认机制)。T:transactional(事务)。
State :当前的状态,running:运行中;idle:空闲。
Unconfirmed:通道中待发送确认的消息总数。
Prefetch:通道预取计数。避免了rabbitmq一直往消费端发送数据,导致消费端出现无限制的缓冲区问题。消息预取定义了信道上或者消费者允许的最大未确认的消息数量。一旦未确认数达到了设置的值,RabbitMQ将停止发送更多消息。
代码配置:
- channel.basicQos(100, false);
Unacker:通道中待消费确认的消息总数。
publish:producter pub消息的速率。
confirm:producter confirm消息的速率。
deliver/get:consumer 获取消息的速率。
ack:consumer ack消息的速率。
官网参考:https://www.rabbitmq.com/channels.html
Exchanges
交换机属性
Virtual host:所属的虚拟主机。
Name:交换机名称。
Type:交换机类型。具体交换机类型大概有四种,具体区别可以参考官网:
https://www.rabbitmq.com/tutorials/amqp-concepts.html#exchanges
Features:一些属性,是否持久化、是否有策略等等
Message rate in:消息进入交换机的速率。
Message rate out:消息出去交换机的速率。
添加exchange
Virtual host:所属的虚拟主机
Name:交换机名称
Type:交换机类型
Durability:是否持久化,Durable表示持久化,Transient表示不持久化;RabbitMQ关闭后,没有持久化的Exchange将被清除。
Auto delete:是否自动删除,如果没有与之绑定的Queue,直接删除该交换机。
Internal:如果yes,就是该Producer无法直接将消息发送给该Exchange,只能将消息发送给另一个Exchange再路由到该Exchange。一般用不到。
Arguments: alternate-exchange,备用交换机,如果消息无法路由该该交换机的话就把消息发送到该备用交换机。
官网参考:https://www.rabbitmq.com/tutorials/amqp-concepts.html
死信交换机
它的作用其实是用来接收死信消息的。
什么是死信消息呢?一般出现如下几种情况时消息会变为死信消息:
1、消费者使用basic.reject或 basic.nack,并将requeue参数设置为false
2、消息达到过期时间(超过了TTL限制)
3、队列长度达到最大长度限制
死信交换(DLX)其实就是一个正常的交换机。它们可以是任何通常的类型,并且可以照常声明。可以在队列申明的时候通过设置参数来设置该队列的死信交换机。如果该队列设置了死信交换机以后,该队列里面的消息出现以上三种情况的时候,消息就会被发送到该死信交换机中,然后通过路由键被路由到对应的队列里面供另外的消费这消费。
代码实现参考(配置类新增如下配置):
- //测试队列
- @Bean
- public Queue newQueue() {
- Map<String, Object> arguments = new HashMap<String, Object>();
- arguments.put("x-message-ttl", 5000 * 6);//5*6=30 秒钟
- arguments.put("x-dead-letter-exchange", "dead-letter-exchange");//死信交换机
- arguments.put("x-dead-letter-routing-key", "dead-letter-routing-key");//死信交换机路由键
- return new Queue("test-dead-letter-queue", true, false, false, arguments);
- }
- //死信队列
- @Bean
- public Queue deadLetterQueue() {
- return new Queue("dead-letter-queue", true);
- }
- //死信交换机
- @Bean
- public DirectExchange deadLetterExchange() {
- return new DirectExchange("dead-letter-exchange", true, false);
- }
- //死信交换机和死信队列绑定
- @Bean
- public Binding deadLetterBinding() {
- return BindingBuilder.bind(deadLetterQueue()).to(deadLetterExchange()).with("dead-letter-routing-key");
- }
该案例中,如果一个消息被路由到了test-dead-letter-queue队列超过30秒还未被消费的话,该条消息就会被发送到dead-letter-exchange交换机进而被路由到dead-letter-queue队列,这个时候只需要创建一个监听类监听dead-letter-queue队列,即可实现死信消息的消费。说明:申明一个队列test-dead-letter-queue,设置了过期时间为30秒,并设置了死信交换机dead-letter-exchange和路由键dead-letter-routing-key,再申明一个队列dead-letter-queue和交换机dead-letter-exchange,并把交换机、队列和路由键绑定。
Queues
队列属性
Virtual host:所属的虚拟主机。
Name:队列名称。队列名称最多可以包含255个字节的UTF-8字符。自己声明的队列名称尽量不要以以“ amq”开头。
Node:队列所属节点。
Type:队列类型。
Features:显示一些参数,比如队列类型、消息是否持久化等等。
State:当前的状态,running:运行中;idle:空闲。
Ready:等待消费的消息总数。
Unacked:等待消费确认的消息总数。
Total:总数 Ready+Unacked。
incoming:消息进入的速率。
deliver/get:消息获取的速率。
ack:消息消费确认的速率。
添加queue
Virtual host:所属虚拟主机
Type:队列类型
Quorum:仲裁队列,官网指出目前还不支持某些功能。
Classic:经典队列,一般的队列都默认是classic。
Name:队列名称
Node:所属节点
Auto delete:消费者失去连接的时候是否自动删除队列
Arguments:
x-message-ttl:给队列上消息的过期时间。
x-expires:队列自动删除前的空闲等待时间。
x-max-length:设置队列中可以拥有的消息的数量,超过这个数量将会从队列头开始丢弃、若有死信exchange,则会推送到dlx中。
x-max-length-bytes:和上一个参数作用相同,一个是个数,一个是字节大小。
x-overflow:设置队列溢出的行为。 队列达到了最大长度时消息将发生什么情况。 有效值为drop-head,拒绝发布或拒绝发布dlx。
x-dead-letter-exchange:死信交换机,如果消息被拒绝或者过期,将重新发布到该交换机。
x-dead-letter-routing-key:以上交换机的路由键,在消息发送到死信交换器时会使用该路由键,如果不设置,则使用消息的原来的路由键值。
x-single-active-consumer:默认false,如果设置了true,需要确保一次只有一个消费者从队列中消费消息。
x-max-priority:默认不开启,表示队列中的消息优先级属性的分级,开启了的队列,在发送消息到该队列时可以设置message属性:priority的大小(值为0-255)。
x-queue-mode:默认无需配置(default),消息尽量维护在内存中,如果配置了,则会尽早的把内存中的消息持久化到磁盘上,减小内存开销,value是{“default”,“lazy"}。
x-queue-master-locator:在集群模式下设置镜像队列的主节点信息:1.random:随机一个节点作为主节点;2.min-masters:表示主节点配置在拥有主节点数量最少的集群节点上;3.client-local使用与client端连接的集群节点作为主节点。
官网参考:https://www.rabbitmq.com/queues.html
Admin
用户属性。
Name:名称。
Tags:角色标签,只能选取一个。具体角色参考:[RabbitMQ各类角色]章节。
Can access virtual hosts:允许进入的虚拟主机。
Has password:是否设置了密码。
添加user
Username:用户名。
Password/no password:是否有密码,如果有,请设置密码。
Tags:用户的角色
Virtual Hosts
虚拟主机属性,虚拟主机提供逻辑分组和资源分离。
当一个客户端需要连接到RabbitMQ时,它需要指定要连接的虚拟主机名称。如果身份验证成功并且提供的用户名被授予了该虚拟主机的权限,则建立连接成功。
可以设置连接到虚拟主机的客户端数量:
数量限制
在某些情况下,希望限制虚拟主机中队列或并发客户端连接的最大允许数量。从RabbitMQ
3.7.0开始,可以通过每个主机限制来实现。
- rabbitmqctl set_vhost_limits -p vhost_name '{"max-connections": 256}'
具体配置可参考:https://www.rabbitmq.com/vhosts.html#client-connections
删除虚拟主机(谨慎操作)
删除虚拟主机将永久删除其下的所有实体(队列,交换,绑定,策略,权限等)。
Name:虚拟主机名称。
Users:该主机下的用户。
States:运行状态。
Ready:该主机下等待消费的消息总数。
Unacked:该主机下等待消费确认的消息总数。
Total:该主机下的消息总数 Ready+Unacked。
From client:自客户端到服务端的网络速率。
To client:服务端到客户端的网络速率。
Publish:客户端生产消息的速率。
deliver/get:客户端消息获取的速率。
添加virtual host
Name:虚拟主机名称。
Description:描述性息。
Tags:角色信息。
官网参考:https://www.rabbitmq.com/vhosts.html
Feature Flags
功能标志。
在混合版本集群中(例如,某些版本为3.7.x,而某些版本为3.8.x),某些节点支持一些不同的功能,在某些情况下的功能不同,或者功能不完全相同:毕竟它们是不同的版本。
Feature Flags是一种机制,用于控制在所有集群节点上已启用或可用的功能。如果启用了Feature Flags,则集群中所有节点的相关功能也将启用。如果没启用,则集群中的所有节点将禁用该功能。
例子1:
比如NodeA和NodeB是集群节点,NodeA节点支持:Toaster、Coffee
maker和Juicer
machine,NodeB节点支持:Toaster、Coffee maker,那么这个时候就可以启用Coffee maker功能,但是没法启用Juicer machine,因为NodeB不支持这个功能。
例子2:
一样的两个几点集群,这个时候如果节点B挂掉了,在节点B挂掉的时候,接单A启用了Juicer machine功能,那么节点B重新启动以后就没法再加入这个集群环境了。
列出节点支持的Feature Flags:
- rabbitmqctl list_feature_flags
启用某一个Feature Flags:
- rabbitmqctl enable_feature_flag 【name】
Name:功能标志的名称。
State:启用或禁用:如果功能标志启用或禁用,不支持:如果集群中的一个或多个节点不支持这个功能标志(因此它不能被启用)。
Description:功能标志的描述。
官网参考:https://www.rabbitmq.com/feature-flags.html
Policies
策略
除了一些需要强制配置的属性之外,RabbitMQ中的队列和交换还具有可选参数。这些由客户端在声明队列(交换机)并控制各种可选功能时提供。
一般的业务场景种,都是直接通过客户端代码中配置,但是这样的话不够方便,比如需要修改TTL值或镜像参数,如果在客户端修改的话,修改完以后需要重新部署或队列重新声明。所以引入了Policies,可以直接在管理端进行这些参数的配置。
一个策略按名称匹配一个或多个队列(使用正则表达式模式)。换句话说,可以使用策略一次为多个队列配置可选参数。
Operator Policy:是给服务提供商或公司基础设施部门用来设置某些需要强制执行的通用规则(一般不用操作)。
User Policy:是给业务应用用来设置的规则。
新增策略
在设置Policy时需要注意,因为Policy是根据parttern匹配队列的,因此可能会出现多个Policy都匹配到同一个队列的情况,此时会依据以下规则进行排序选出实际生效的策略:
1、首先根据priority排序,值越大的优先级越高;
2、相同priority则根据创建时间排序,越晚创建的优先级越高。
Virtual host:所属虚拟机。
Name:可以是任何东西,但建议使用不带空格的基于ASCII的名称
Pattern:根据正则表达式去匹配Queues/Exchanges名称,具体表达式请参考正则表达式概念,其实就是正则表达式匹配一个字符串。
Apply to:策略只能匹配队列,只能匹配交换或两者都匹配。创建策略时。
Priority:策略的优先级。
Definition:一组键/值对。
max-length:队列最大长度。
max-length-bytes:队列最大长度字节数。
overflow:设置队列溢出行为。有效值为drop-head,拒绝发布或拒绝发布死信交换机。
dead-letter-exchange:死信交换机,消息过期后转发的交换机。
dead-letter-routing-key:死信交换机路由键。
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes 。
all:表示在集群所有的节点上进行镜像,无需设置ha-params。
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定 。
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定。
ha-params: ha-mode 模式需要用到的参数。
ha-mode如果配置了exactly:
ha-params参数将表示集群中队列种副本(主服务器和镜像服务器)的数量。
如果为1,表示单个副本(即仅只有队列主服务器)。
如果为2表示2个副本(即主服务器和1个队列镜像)。 这个时候如果运行队列主服务器的节点挂了,则会根据配置的镜像升级策略将队列镜像自动升级为主服务器。
如果群集中的节点数少于该参数,则该队列将镜像到所有节点。
如果群集中的节点数很多,并且包含镜像的节点出现故障,则将在另一个节点上创建新的镜像,即把其他节点升级为镜像节点。
具体参考:https://www.rabbitmq.com/ha.html#mirroring-arguments
ha-sync-mode: 镜像队列中消息的同步方式,有效值为automatic(自动),manually(手动)。
ha-promote-on-shutdown:when-synced,当主节点挂掉以后从节点不接管,等待主节点恢复,always,从节点主动接管。
ha-promote-on-failure:异常情况下从节点如何替代主节点,比如断网,默认参数always,参数值意思跟ha-promote-on-shutdown一样。
message-ttl:消息过期时间。
Expires:是否自动过期。
queue-mode:参考队列部分。
queue-master-locator:参考队列部分。
alternate-exchange:参考交换机部分。
官网参考:https://www.rabbitmq.com/parameters.html#policies
Limits
在某些情况下,希望限制虚拟主机中队列或并发客户端连接的最大允许数量。从RabbitMQ 3.7.0开始,可以通过每个主机限制来实现。
如果要禁用客户端与虚拟主机的连接,请将限制设置为零。
如果要取消限制,请将其设置为负值。
Virtual host:虚拟主机
Limit:maxconnections最大连接数,maxqueues最大队列数
Value:最大数量
也可以通过命令的方式修改:
- rabbitmqctl set_vhost_limits -p vhost_name '{“最大连接数”:256}'
官网参考:https://www.rabbitmq.com/vhosts.html#limits
Cluster
修改集群节点的名称
RabbitMQ安装、集群搭建、概念解析的更多相关文章
- RabbitMQ入门教程(十四):RabbitMQ单机集群搭建
原文:RabbitMQ入门教程(十四):RabbitMQ单机集群搭建 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://b ...
- RabbitMQ之集群搭建
1.RabbitMQ集群模式RabbitMQ集群中节点包括内存节点(RAM).磁盘节点(Disk,消息持久化),集群中至少有一个Disk节点. 2.普通模式(默认) 对于普通模式,集群中 ...
- rabbitmq普通集群搭建详细步骤
由于工作需求,需要安装rabbitmq,学习之余,记录一下安装过程 准备基础编译环境yum install gcc glibc-devel make ncurses-devel openssl-dev ...
- Consul安装集群搭建
1 consul的安装和配置 1.1 consul agent 命令介绍 下载consul_1.0.0_linux_amd64.zip解压,里面只有一个consul可执行文件,其中,consul最常用 ...
- RabbitMQ镜像集群搭建
RabbitMQ 官网 https://www.rabbitmq.com/ 小编使用的系统环境是CentOS7.4 系统 IP hostname CentOS7.4 1.1.1.1 hostname0 ...
- RabbitMQ单机集群搭建出现Error: unable to perform an operation on node 'rabbit1@ClusterNode1'
参考链接:https://www.cnblogs.com/daryl/archive/2017/10/13/7645749.html 全部步骤和参考链接相同. 前八部都正常,在第九步会报错Error: ...
- rabbitmq安装集群
centos 7.3 64 172.18.39.241 k8s-mini-241172.18.39.242 k8s-mini-242172.18.39.243 k8s-master-243 vim / ...
- MongoDB——基本使用及集群搭建
文章目录 什么是MongoDb? 基本概念 与关系型数据库的比较 Mongo的高效性 文件存储 基本使用 启动/连接服务 基础操作命令 高可用集群搭建 概念 环境准备 实践 应用场景 总结 什么是Mo ...
- rabbitMQ 安装,集群搭建, 编码
RabbitMQ 一.背景 命令行工具: http://www.rabbitmq.com/man/rabbitmqctl.1.man.html 介绍入门文章: http://blog.csdn.net ...
随机推荐
- 使用pip安装模块,出现Cannot unpack file xxx的问题的解决
在windows下使用pip 豆瓣源安装gevent时出现错误 解决办法: pip install -i https://pypi.douban.com/simple/ --trusted-host ...
- 进阶6:连接查询 一、sql92标准
#进阶6:连接查询/*含义:又称多表查询,当查询的字段来自于多个表时,就会用到连接查询 笛卡尔乘积现象:表1 有m行,表2有n行,结果=m*n行 发生原因:没有有效的连接条件如何避免:添加有效的连接条 ...
- 超详细的阿里字节Spring面试技术点总结(建议收藏)
前言 Spring作为现在最流行Java开发技术,其内部源码设计非常优秀. Spring这个词对于Java开发者想必不会陌生,可能你每天都在使用Spring,享受着Spring生态提供的服务.现在很多 ...
- Magento 2 Factory Objects
In object oriented programming, a factory method is a method that’s used to instantiate an object. F ...
- 区块链入门到实战(22)之以太坊(Ethereum) – 账号(地址)
作用: 外部账号 – 用户使用的账号,账户余额. 合约账号 – 智能合约使用的账号,每个智能合约都有一个账号,内存和账户余额 以太坊(Ethereum)网络中,有2种账号: 外部账号 – 用户使用的账 ...
- IDEA下Maven项目搭建踩坑记----2.项目编译之后 在service层运行时找不到 com.dao.CarDao
项目写的差不多 想运行一下,然后发现运行到Service层的时候报错说找不到Dao层文件 ,纠结半天之后看了下编译好的项目文件,发现mapper文件下边是空的, 于是就百度找一下原因,结果说是IDEA ...
- 从String类型发散想到的一些东西
值类型 引用类型 值类型表示存储在栈上的类型,包括简单类型(int.long.double.short).枚举.struct定义: 引用类型表示存在堆上的类型,包括数组.接口.委托.class定义: ...
- WebApis中BOM的学习
1.1. 常用的键盘事件 1.1.1 键盘事件 <script> // 常用的键盘事件 //1. keyup 按键弹起的时候触发 document.addEventListener('ke ...
- 4300 字Python列表使用总结,用心!
今天列表专题的目录如下: 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这 ...
- 点击穿透事件-----CSS新属性
面试被问,一脸懵,被提示,还蒙,好丢脸的感觉....赶紧百度了解 .noclick{ pointer-events: none; /* 上层加上这句样式可以实现点击穿透 */ } 就是说重叠在一起的两 ...