从连接器组件看Tomcat的线程模型——BIO模式
在高版本的Tomcat中,默认的模式都是使用NIO模式,在Tomcat 9中,BIO模式的实现Http11Protocol甚至都已经被删除了。但是了解BIO的工作机制以及其优缺点对学习其他模式有有帮助。只有对比后,你才能知道其他模式的优势在哪里。
Http11Protocol表示阻塞式的HTTP协议的通信,它包含从套接字连接接收、处理、响应客户端的整个过程。它主要包含JIoEndpoint组件和Http11Processor组件。启动时,JIoEndpoint组件将启动某个端口的监听,一个请求到来后将被扔进线程池,线程池进行任务处理,处理过程中将通过协议解析器Http11Processor组件对HTTP协议解析,并且通过适配器Adapter匹配到指定的容器进行处理以及响应客户端。
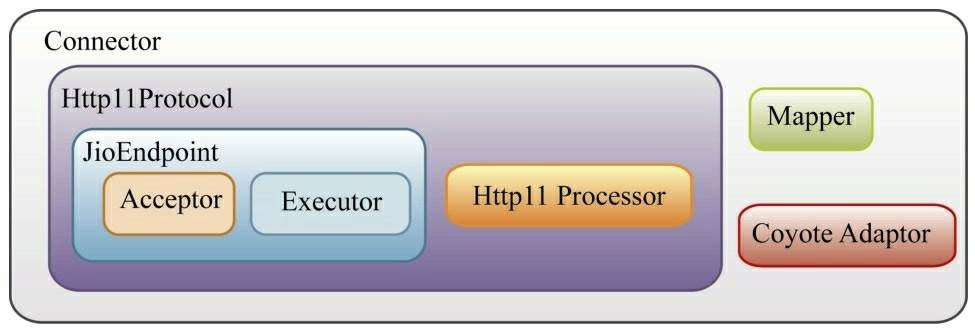
这里我们结合Spring Boot中内嵌的Tomcat来看看连接器的工作原理。建议使用低版本的Spring Boot,高版本的Spring Boot中,都已经使用Tomcat 9了。Tomcat 9已经删除了BIO的实现模式。这边我选择的Spring Boot版本是2.0.0.RELEASE。
要怎么看Connector组件的源代码
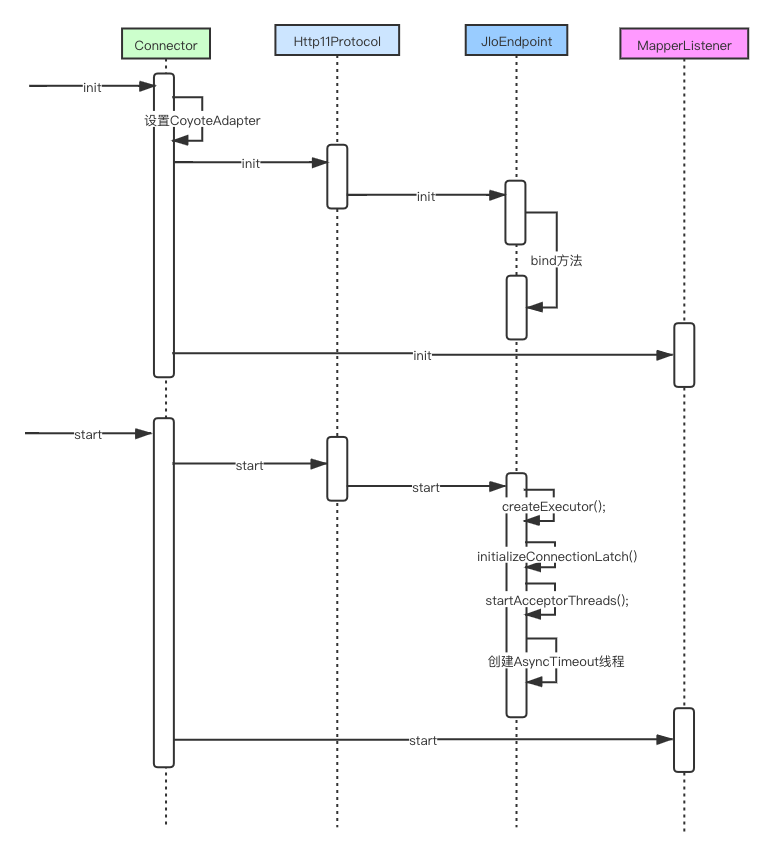
我们现在要开始通过Connector组件的源代码来分析连接器组件的工作过程。但是Tomcat的源代码这么多,我们到底要怎么看这个代码呢?之前的文章中总结了Tomcat的启动流程,如下图所示:

上面的时序图给我们分析Connector组件的源代码提供了思路:从连接器组件的init方法和start方法开始分析。
Connector组件工作时序图
Spring Boot中内嵌 的Tomcat默认使用的都是NIO模式,想要研究BIO模式还要自己折腾一番。Spring Boot中提供了WebServerFactoryCustomizer接口,我们可以实现这个接口来对Servlet容器工厂进行自定义配置。下面是我自己实现的一个配置类,只是简单地将IO模型设置成了BIO模式,假如你还需要进行其他配置也可以在里面进行额外配置。
@Configuration
public class TomcatConfig {
@Bean
public WebServerFactoryCustomizer tomcatCustomer() {
return new TomcatCustomerConfig();
}
public class TomcatCustomerConfig implements WebServerFactoryCustomizer<TomcatServletWebServerFactory> {
@Override
public void customize(TomcatServletWebServerFactory factory) {
if (factory != null) {
factory.setProtocol("org.apache.coyote.http11.Http11Protocol");
}
}
}
}
经过上面的配置后,Tomcat的连接器组件就会以BIO的模式处理请求。
由于Tomcat整理的代码非常多,想要在一篇文章中分析所有的代码是不太现实的。这边,我梳理了连接器组件工作的时序图,根据这个时序图,我分析了几个关键的代码点,其他细节大家可以根据我的时序图自己看代码,这块代码也不是很复杂。
这边的重点代码是在JIoEndpoint的init()方法和start()方法。JIoEndpoint的init()方法主要是做了ServerSocket的端口绑定。具体代码如下:
@Override
public void bind() throws Exception {
// Initialize thread count defaults for acceptor
if (acceptorThreadCount == 0) {
acceptorThreadCount = 1;
}
// Initialize maxConnections
if (getMaxConnections() == 0) {
// User hasn't set a value - use the default
setMaxConnections(getMaxThreadsWithExecutor());
}
if (serverSocketFactory == null) {
if (isSSLEnabled()) {
serverSocketFactory =
handler.getSslImplementation().getServerSocketFactory(this);
} else {
serverSocketFactory = new DefaultServerSocketFactory(this);
}
}
//这边做了ServerSocket的端口绑定
if (serverSocket == null) {
try {
if (getAddress() == null) {
//没指定具体地址,Tomcat会监听所有地址过来的请求
serverSocket = serverSocketFactory.createSocket(getPort(),
getBacklog());
} else {
//指定了具体地址,Tomcat只监听这个地址过来的请求
serverSocket = serverSocketFactory.createSocket(getPort(),
getBacklog(), getAddress());
}
} catch (BindException orig) {
String msg;
if (getAddress() == null)
msg = orig.getMessage() + " <null>:" + getPort();
else
msg = orig.getMessage() + " " +
getAddress().toString() + ":" + getPort();
BindException be = new BindException(msg);
be.initCause(orig);
throw be;
}
}
}
再来看JIoEndpoint的start方法。
public void startInternal() throws Exception {
if (!running) {
running = true;
paused = false;
//创建线程池
if (getExecutor() == null) {
createExecutor();
}
//创建ConnectionLatch
initializeConnectionLatch();
//创建accept线程,这个线程是请求处理的初始线程
startAcceptorThreads();
// Start async timeout thread
Thread timeoutThread = new Thread(new AsyncTimeout(),
getName() + "-AsyncTimeout");
timeoutThread.setPriority(threadPriority);
timeoutThread.setDaemon(true);
timeoutThread.start();
}
}
上面的代码中,需要我们重点关注的就是startAcceptorThreads()方法。我们看下这个Accept线程的具体实现。
protected final void startAcceptorThreads() {
int count = getAcceptorThreadCount();
acceptors = new Acceptor[count];
//根据配置,设置一定数量的accept线程
for (int i = 0; i < count; i++) {
acceptors[i] = createAcceptor();
String threadName = getName() + "-Acceptor-" + i;
acceptors[i].setThreadName(threadName);
Thread t = new Thread(acceptors[i], threadName);
t.setPriority(getAcceptorThreadPriority());
t.setDaemon(getDaemon());
t.start();
}
}
Acceptor线程的具体处理实现,重点看run方法。
protected class Acceptor extends AbstractEndpoint.Acceptor {
@Override
public void run() {
int errorDelay = 0;
// Loop until we receive a shutdown command
while (running) {
// Loop if endpoint is paused
while (paused && running) {
state = AcceptorState.PAUSED;
try {
Thread.sleep(50);
} catch (InterruptedException e) {
// Ignore
}
}
if (!running) {
break;
}
state = AcceptorState.RUNNING;
try {
//if we have reached max connections, wait
//达到连接上限,acceptor线程进入等待状态,直到其他线程释放,这是一种简单的通过连接数量进行流量控制的手段
//通过实现AQS组件实现(LimitLatch),思路是先初始化同步器的最大限制值,然后每接收一个套接字就将计数变量累加1,每关闭一个套接字将计数变量减1
countUpOrAwaitConnection();
Socket socket = null;
try {
//accept下个socket连接,如果一直没有连接过来这个方法阻塞
socket = serverSocketFactory.acceptSocket(serverSocket);
} catch (IOException ioe) {
//有异常的话释放一个连接数
countDownConnection();
errorDelay = handleExceptionWithDelay(errorDelay);
throw ioe;
}
// Successful accept, reset the error delay
errorDelay = 0;
//对socket进行适当配置
if (running && !paused && setSocketOptions(socket)) {
// 处理这个socket请求,这边也是重点。
if (!processSocket(socket)) {
countDownConnection();
// Close socket right away
closeSocket(socket);
}
} else {
countDownConnection();
// Close socket right away
closeSocket(socket);
}
} catch (IOException x) {
if (running) {
log.error(sm.getString("endpoint.accept.fail"), x);
}
} catch (NullPointerException npe) {
if (running) {
log.error(sm.getString("endpoint.accept.fail"), npe);
}
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
log.error(sm.getString("endpoint.accept.fail"), t);
}
}
state = AcceptorState.ENDED;
}
}
上面线程处理类中的processSocket(socket)是处理具体请求的方法,这个方法将请求进行了包装然后“扔进”了线程池进行处理。但是这个不是连接器组件的重点,后面会在介绍请求流转时介绍Tomcat怎么处理请求的。
到这边,对Tomcat的BIO模式做了个简单的介绍。其实大家可以看出来,如果对BIO模式进行简化的话就是对传统的ServerSocket的操作,还有就是对请求的处理加上了线程池优化。
BIO模式总结
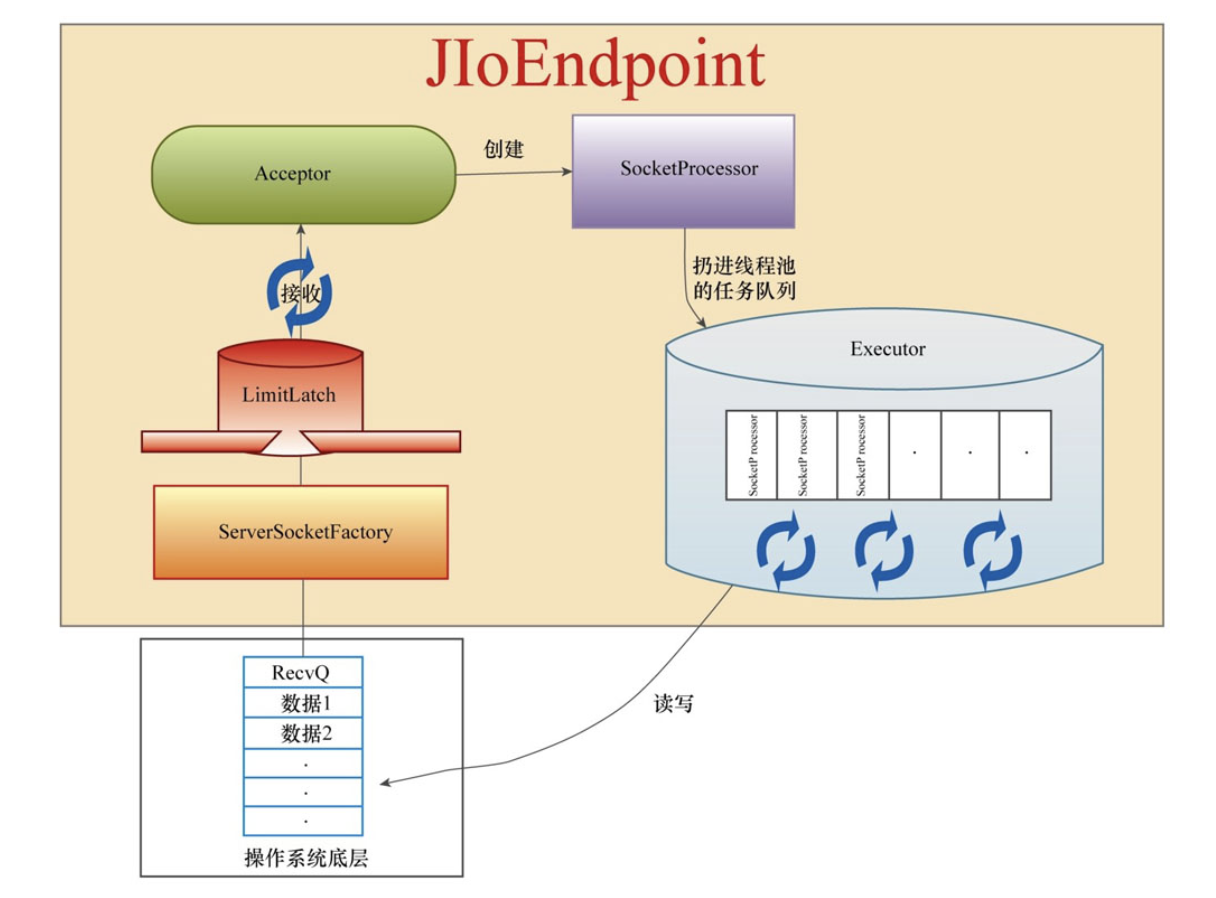
关于上图中的各个组件做下简要说明。
限流组件LimitLatch
LimitLatch组件是一个流量控制组件,目的是为了不让Tomcat组件被大流量冲垮。LimitLatch通过AQS机制实现,这个组件启动时先初始化同步器的最大限制值,然后每接收一个套接字就将计数变量累加1,每关闭一个套接字将计数变量减1。当连接数达到最大值时,Acceptor线程就进入等待状态,不再accept新的socket连接。
需要额外说明的是,当到达最大连接数时(已经LimitLatch组件最大值,acceptor组件阻塞了),操作系统底层还是会继续接收客户端连接,并将请求放入一个队列中(backlog队列)。这个队列是有一个默认长度的,默认值是100。当然,这个值可以通过server.xml的Connector节点的acceptCount属性配置。假如在短时间内,有大量请求过来,连backlog队列都放满了,那么操作系统将拒绝接收后续的连接,返回“connection refused”。
在BIO模式中,LimitLatch组件支持的最大连接数是通过server.xml的Connector节点的maxConnections属性设置的,如果设置成-1,则表示不限制。
接收器组件Acceptor
这个组件的职责非常简单,就是接收Socket连接,对Socket做相应的设置,然后直接丢给线程池处理。accept线程的数量也可以进行配置。
套接字工厂ServerSocketFactory
Acceptor线程在具体accept socket连接时是通过ServerSocketFactory组件获取的。Tomcat中有两个ServerSocketFactory的实现:DefaultServerSocketFactory和JSSESocketFactory。分别对应HTTP和HTTPS的情况。
Tomcat中存在一个变量SSLEnabled用于标识是否使用加密通道,通过对此变量的定义就可以决定使用哪个工厂类,Tomcat提供了外部配置文件供用户自定义。下面的配置中SSLEnabled="true"表示使用加密方式,也就是使用JSSESocketFactory来accept具体的socket连接。
<Connector port="8443" protocol="org.apache.coyote.http11.Http11NioProtocol"
maxThreads="150" SSLEnabled="true">
<SSLHostConfig>
<Certificate certificateKeystoreFile="conf/localhost-rsa.jks"
type="RSA" />
</SSLHostConfig>
</Connector>
线程池组件
Tomcat中的线程池是对JDK中线程池的简单改装。在线程创建策略上有点区别:Tomcat中的线程池在线程数大于coreSize后不会立马将线程提交到队列中,而是先判断活动线程数是否已经达到maxSize,只有达到maxSize后才会将线程提交到队列中。
Connector组件的Executor分为两种类型:共享Executor和私有Executor。共享Executor的话是指在Service组件中定义的Executor。
任务定义器SocketProcessor
在将Socket扔进线程池之前我们需要定义任务怎么处理这个Socket。SocketProcessor就是这个任务定义,这个类实现了Runnable接口。
protected class SocketProcessor implements Runnable {
//进行Debug调试的时候可以从这个类的run方法开始调试
@Override
public void run() {
//对套接字进行处理并输出响应
//对连接限流器LimitLatch减一
//关闭套接字
}
}
SocketProcessor的任务主要分为三个:处理套接字并响应客户端,连接数计数器减1,关闭套接字。其中对套接字的处理是最重要也是最复杂的,它包括对底层套接字字节流的读取, HTTP协议请求报文的解析(请求行、请求头部、请求体等信息的解析),根据请求行解析得到的路径去寻找相应虚拟主机上的Web项目资源,根据处理的结果组装好HTTP协议响应报文输出到客户端。
这边暂时先不分析对套接字的具体处理流程,因为这边文章主要还是将连接器的线程模型,涉及的东西太多容易搞混,关于Tomcat对socket的具体处理后面会写文章分析。
从连接器组件看Tomcat的线程模型——BIO模式的更多相关文章
- 从连接器组件看Tomcat的线程模型——NIO模式
Tomcat8之后,针对Http协议默认使用org.apache.coyote.http11.Http11NioProtocol,也就是NIO模式.通过之前的博客分析,我们知道Connector组件在 ...
- 从连接器组件看Tomcat的线程模型——连接器简介
Connector组件介绍 Connector(连接器)组件是Tomcat最核心的两个组件之一,主要的职责是负责接收客户端连接和客户端请求的处理加工.每个Connector都将指定一个端口进行监听,分 ...
- 性能追击:万字长文30+图揭秘8大主流服务器程序线程模型 | Node.js,Apache,Nginx,Netty,Redis,Tomcat,MySQL,Zuul
本文为<高性能网络编程游记>的第六篇"性能追击:万字长文30+图揭秘8大主流服务器程序线程模型". 最近拍的照片比较少,不知道配什么图好,于是自己画了一个,凑合着用,让 ...
- tomcat 线程模型
最近看到了内网ATA上的一篇断网故障时Mtop触发tomcat高并发场景下的BUG排查和修复(已被apache采纳),引起了我的好奇,感觉原作者对应底层十分了解,写的很复杂.原来对于tomcat的线程 ...
- 一文弄懂-Netty核心功能及线程模型
目录 一. Netty是什么? 二. Netty 的使用场景 三. Netty通讯示例 1. Netty的maven依赖 2. 服务端代码 3. 客户端代码 四. Netty线程模型 五. Netty ...
- Memcached源码分析之线程模型
作者:Calix 一)模型分析 memcached到底是如何处理我们的网络连接的? memcached通过epoll(使用libevent,下面具体再讲)实现异步的服务器,但仍然使用多线程,主要有两种 ...
- Tomcat线程模型分析及源码解读
1 四种线程模型 配置方法:在tomcat conf 下找到server.xml,在<Connector port="8080" protocol="HTTP/1 ...
- 曹工说Tomcat:200个http-nio-8080-exec线程全都被第三方服务拖住了,这可如何是好(上:线程模型解析)
前言 这两年,tomcat慢慢在新项目里不怎么接触了,因为都被spring boot之类的框架封装进了内部,成了内置server,不用像过去那样打个war包,再放到tomcat里部署了. 但是,内部的 ...
- 看我是如何处理自定义线程模型---java
看过我之前文章的园友可能知道我是做游戏开发,我的很多思路和出发点是按照游戏思路来处理的,所以和web的话可能会有冲突,不相符合. 来说说为啥我要自定义线程模型呢? 按照我做的mmorpg或者mmoar ...
随机推荐
- Azure Monitor(一)Application Insights
一,引言 Azure Monitor 是 Azure 中的一项完整堆栈监视服务,是一种收集和分析遥测数据的服务.它提供了一组完整的功能来监视 Azure 资源以及其他云中和本地的资源.Azure Mo ...
- 甜咸粽子党大战,Python爬取淘宝上的粽子数据并进行分析
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 爬虫 爬取淘宝数据,本次采用的方法是:Selenium控制Chrome浏览 ...
- .Net Core Configuration源码探究
前言 上篇文章我们演示了为Configuration添加Etcd数据源,并且了解到为Configuration扩展自定义数据源还是非常简单的,核心就是把数据源的数据按照一定的规则读取到指定的字 ...
- 关于数据库客户端navicat创建新连接失败的问题
如图是navicat创建新连接的截图: 我就有一个疑问了,主机填localhost或者127.0.0.1都是本机,自然是可以连接成功的,那如果填本机的IP地址会怎样呢? 如下图,出现了报错: 说我的访 ...
- python 3内置函数
2018-07-14 enumerate() 用于指定下标 例: m = ['a','b','c'] for i,j in enumerate(m,1): print(i,j) 输出: 1 a 2 b ...
- 入门大数据---Kafka生产者详解
一.生产者发送消息的过程 首先介绍一下 Kafka 生产者发送消息的过程: Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发 ...
- 【转】HBase中Zookeeper,RegionServer,Master,Client之间关系
在2.0之前HDFS中只有一个NameNode,但对于在线的应用只有一个NameNode是不安全的,故在2.0中对NameNode进行抽象,抽象成NamService其下包含有多个NameNode,但 ...
- 平时自己常用的git指令
增删改查 创建标签 $ git tag -a v1.4 -m 'my version 1.4' 用 -a (译注:取 annotated 的首字母)指定标签名字即可 -m 选项则指定了对应的标签说明 ...
- js语法基础入门(5.2)
5.2.循环结构 当一段代码被重复调用多次的时候,可以用循环结构来实现,就像第一个实例中出现的场景一样,需要重复询问对方是否有空,这样就可以使用循环结构来搞定 5.2.1.for循环语句 //语法结构 ...
- Java BigDecimal和double BigDecimal类
BigDecimal类 对于不需要任何准确计算精度的数字可以直接使用float或double,但是如果需要精确计算的结果,则必须使用BigDecimal类,而且使用BigDecimal类也可以进行大数 ...