Spark Standalone模式 高可用部署
本文使用Spark的版本为:spark-2.4.0-bin-hadoop2.7.tgz。
spark的集群采用3台机器进行搭建,机器分别是server01,server02,server03。
其中:server01,server02设置为Master,server01,server02,server03为Worker。
1.Spark
下载地址:
http://spark.apache.org/downloads.html
选择对应的版本进行下载就好,我这里下载的版本是:spark-2.4.0-bin-hadoop2.7.tgz。
2.上传及解压
2.1 下载到本地后,上传到Linux的虚拟机上
scp spark-2.4.0-bin-hadoop2.7.tgz hadoop@server01:/hadoop
2.2 解压
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
2.3 重命名
mv spark-2.4.0-bin-hadoop2.7 spark
3.配置环境
进入spark/conf目录
3.1 复制配置文件
cp slaves.template slaves cp spark-env.sh.template spark-env.sh
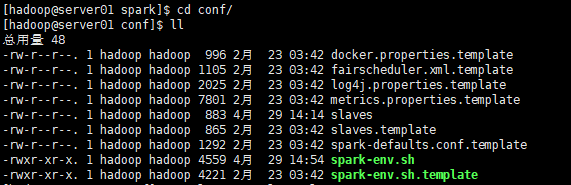
3.2 修改slaves配置文件
spark集群的worker conf配置 slaves
server01
server02
server03
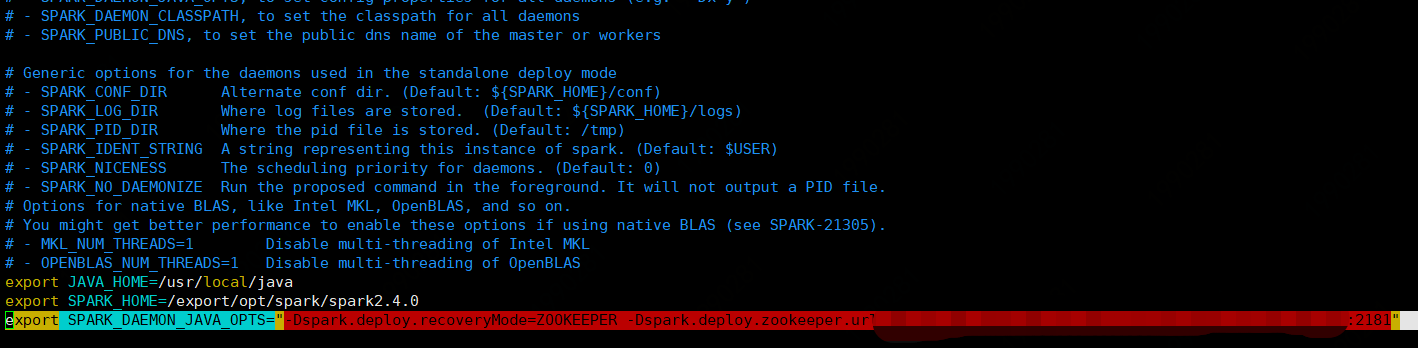
3.3 修改spark-env.sh配置文件
# java环境变量 export JAVA_HOME=/usr/local/java #spark home export SPARK_HOME=/export/opt/spark/spark2.4.0 # spark集群master进程主机host export SPARK_MASTER_HOST=server01 # 配置zk 此处可以独立配置zk list,逗号分隔 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=xxx.xxx.xxx.xxx:2181, xxx.xxx.xxx.xxx:2181……"
如下图
3.4 下发到server02和server03机器上
scp -r /hadoop/spark hadoop@server02:/hadoop scp -r /hadoop/spark hadoop@server03:/hadoop
3.5 修改server02机器上的spark-env.sh的SPARK_MASTER_HOST参数信息
# 增加备用master主机,改为server02,将自己设置为master(备用) export SPARK_MASTER_HOST=server02

3.6 配置环境变量
给server01,server02,server03机器上配置spark的环境变量
export SPARK_HOME=/export/opt/spark/spark2.4.0
export PATH=$PATH:${SPARK_HOME}/bin:${SPARK_HOME}/sbin
#使配置环境生效
source /etc/profile
4. 启动Spark集群
在server01机器上,进入spark目录
4.1 分别启动master和slaves进程
# 启动master进程 sbin/start-master.sh # 启动3个worker进程,也可以每个机器独立启动需要输入两个master地址 sbin/start-slaves.sh
jps查看进程1有既有master又有Worker,2,3只有Worker

4.2 直接使用start-all.sh启动
sbin/start-all.sh

4.3 手动启动server02机器上的master进程
进入spark目录
sbin/start-master.sh
我们可以使用stop-all.sh杀死spark的进程
sbin/stop-all.sh
web页面展示
在浏览器中输入
server01:8080
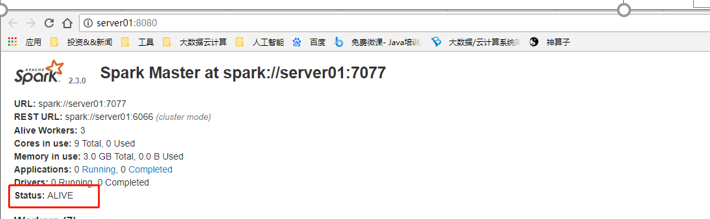
Status:ALIVE 说明master为主Master
server02:8080

总结
部署完成后可以尝试kill掉1的master,然后需要等几分钟后会重启备用master,此时备用切换为主。
另外如果application被杀掉或者jvm出现问题,还可以通过增加参数 --supervise(需要安装,pip install supervise)可以重新启动application。
Spark Standalone模式 高可用部署的更多相关文章
- Redis哨兵模式高可用部署和配置
一.Redis 安装配置 1.下载redis安装包 wget http://download.redis.io/releases/redis-4.0.9.tar.gz 2.解压安装包 tar -zxv ...
- Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三. Spark集群安装 3.1 下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html 这里我们使用 spark-2.1.3-bi ...
- 【原】Spark Standalone模式
Spark Standalone模式 安装Spark Standalone集群 手动启动集群 集群创建脚本 提交应用到集群 创建Spark应用 资源调度及分配 监控与日志 与Hadoop共存 配置网络 ...
- Spark Standalone模式HA环境搭建
Spark Standalone模式常见的HA部署方式有两种:基于文件系统的HA和基于ZK的HA 本篇只介绍基于ZK的HA环境搭建: $SPARK_HOME/conf/spark-env.sh 添加S ...
- eql高可用部署方案
运行环境 服务器两台(后面的所有配置案例都是以10.96.0.64和10.96.0.66为例) 操作系统CentOS release 6.2 必须要有共同的局域网网段 两台服务器都要安装keepali ...
- Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
前期博客 Spark运行模式概述 Spark standalone简介与运行wordcount(master.slave1和slave2) 开篇要明白 (1)spark-env.sh 是环境变量配 ...
- Redis高可用部署及监控
Redis高可用部署及监控 目录 一.Redis Sentinel简介 二.硬件需求 三.拓扑结构 .单M-S结构 .双M-S结构 .优劣对比 四.配置部 ...
- 006.SQLServer AlwaysOn可用性组高可用部署
一 数据库镜像部署准备 1.1 数据库镜像支持 有关对 SQL Server 2012 中的数据库镜像的支持的信息,请参考:https://docs.microsoft.com/zh-cn/previ ...
- kubernetes 1.15.1 高可用部署 -- 从零开始
这是一本书!!! 一本写我在容器生态圈的所学!!! 重点先知: 1. centos 7.6安装优化 2. k8s 1.15.1 高可用部署 3. 网络插件calico 4. dashboard 插件 ...
随机推荐
- Code Forces 1030E
题目大意: 给你n个数,你可以交换一个数的任意二进制位,问你可以选出多少区间经过操作后异或和是0. 思路分析: 根据题目,很容易知道,对于每个数,我们可以无视它的1在那些位置,只要关注它有几个1即可, ...
- 15.深入k8s:Event事件处理及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 概述 k8s的Event事件是一种资源对象,用于展示集群内发生的情况 ...
- C# Socket TCP发送图片与接收图片
如果需要查看更多文章,请微信搜索公众号 csharp编程大全,需要进C#交流群群请加微信z438679770,备注进群, 我邀请你进群! ! ! --------------------------- ...
- 多测师讲解自动化--rf关键字--断言(下)_高级讲师肖sir
断言: 1.1Page Should Contain Maximize Browser Window sleep 2 Comment Page Should Contain hao123 #断言当前页 ...
- BUUCTF-[极客大挑战 2019]HardSQL 1详解
来到sql注入骚姿势,我们一点一点开始学 我们来到这道题,然后尝试注入,结果发现 拼接'or '1'='1 'or '1'='2如果是字符型注入则会报错,然而并没有而是显示的页面一样, 通过常规注入, ...
- SOAP调用Web Service
SOAP调用Web Service (示例位置:光盘\code\ch07\ WebAppClient\ JsService4.htm) <html xmlns="http://www. ...
- 带你了解 MySQL Binlog 不为人知的秘密
MySQL 的 Binlog 日志是一种二进制格式的日志,Binlog 记录所有的 DDL 和 DML 语句(除了数据查询语句SELECT.SHOW等),以 Event 的形式记录,同时记录语句执行时 ...
- Linux文件系统和管理-2文件操作命令(上)
文件操作命令 文件 文件也包括目录 目录是一种特殊的文件 目录 一个目录名分成两部分 所在目录 dirname 父目录的路径 文件名 basename 本身就是两个命令 [root@C8-1 misc ...
- 智能DNS的实现
网络路径远,导致用户访问延迟 各个运营商之间的带宽有阀口. GSLB 就近的返回服务器的地址 CDN网络 内容分发网络 Content Delivery Network CND服务商 阿里 腾讯 蓝汛 ...
- open_spiel 随笔
------------恢复内容开始------------ ------------恢复内容开始------------ 遇到的一些疑惑且已经解决的 1. SPIEL_CHECK_GT()诸如此类的 ...