解Bug之路-NAT引发的性能瓶颈
解Bug之路-NAT引发的性能瓶颈
笔者最近解决了一个非常曲折的问题,从抓包开始一路排查到不同内核版本间的细微差异,最后才完美解释了所有的现象。在这里将整个过程写成博文记录下来,希望能够对读者有所帮助。(篇幅可能会有点长,耐心看完,绝对物有所值~)
环境介绍
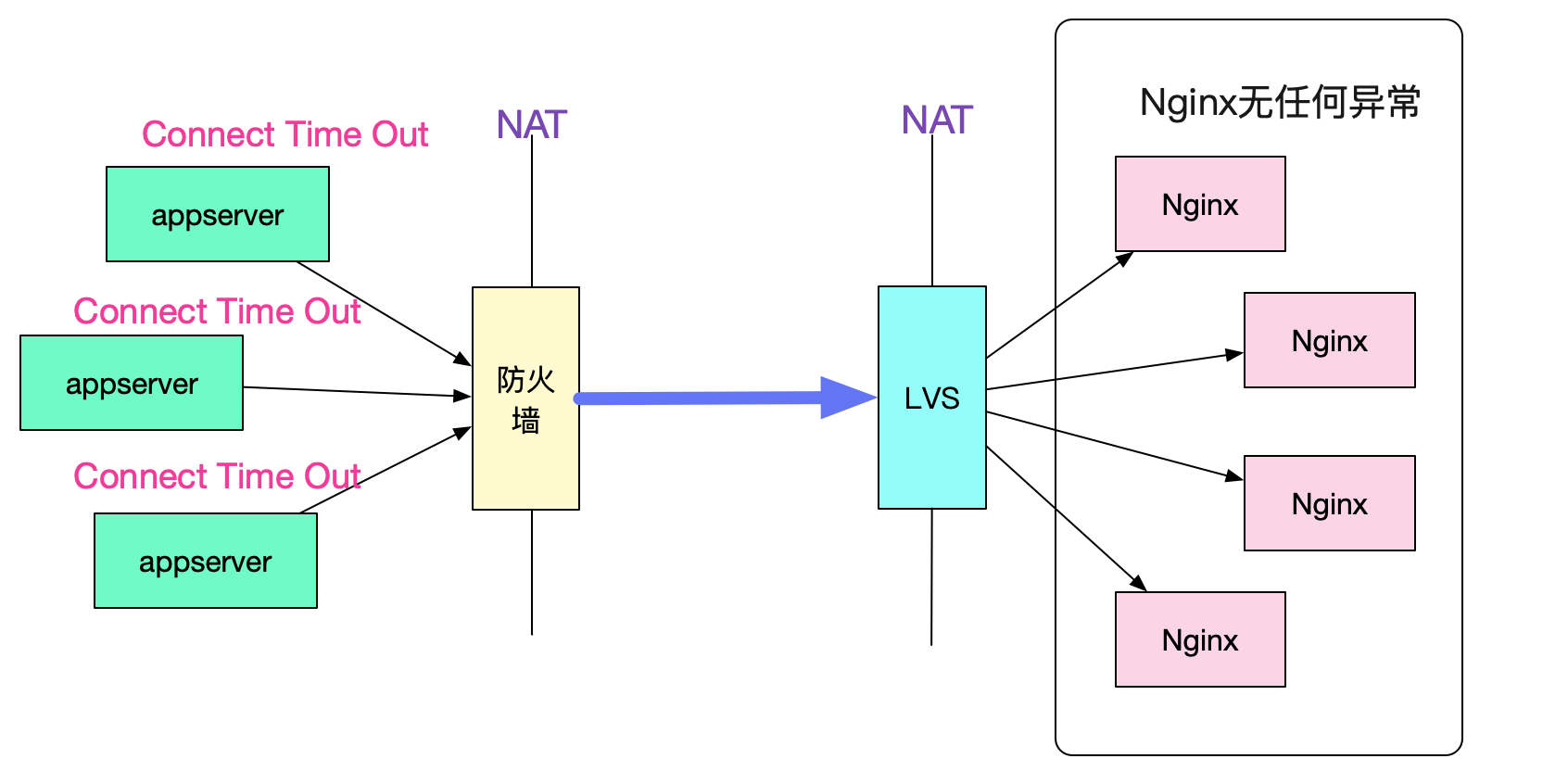
先来介绍一下出问题的环境吧,调用拓扑如下图所示:
调用拓扑图
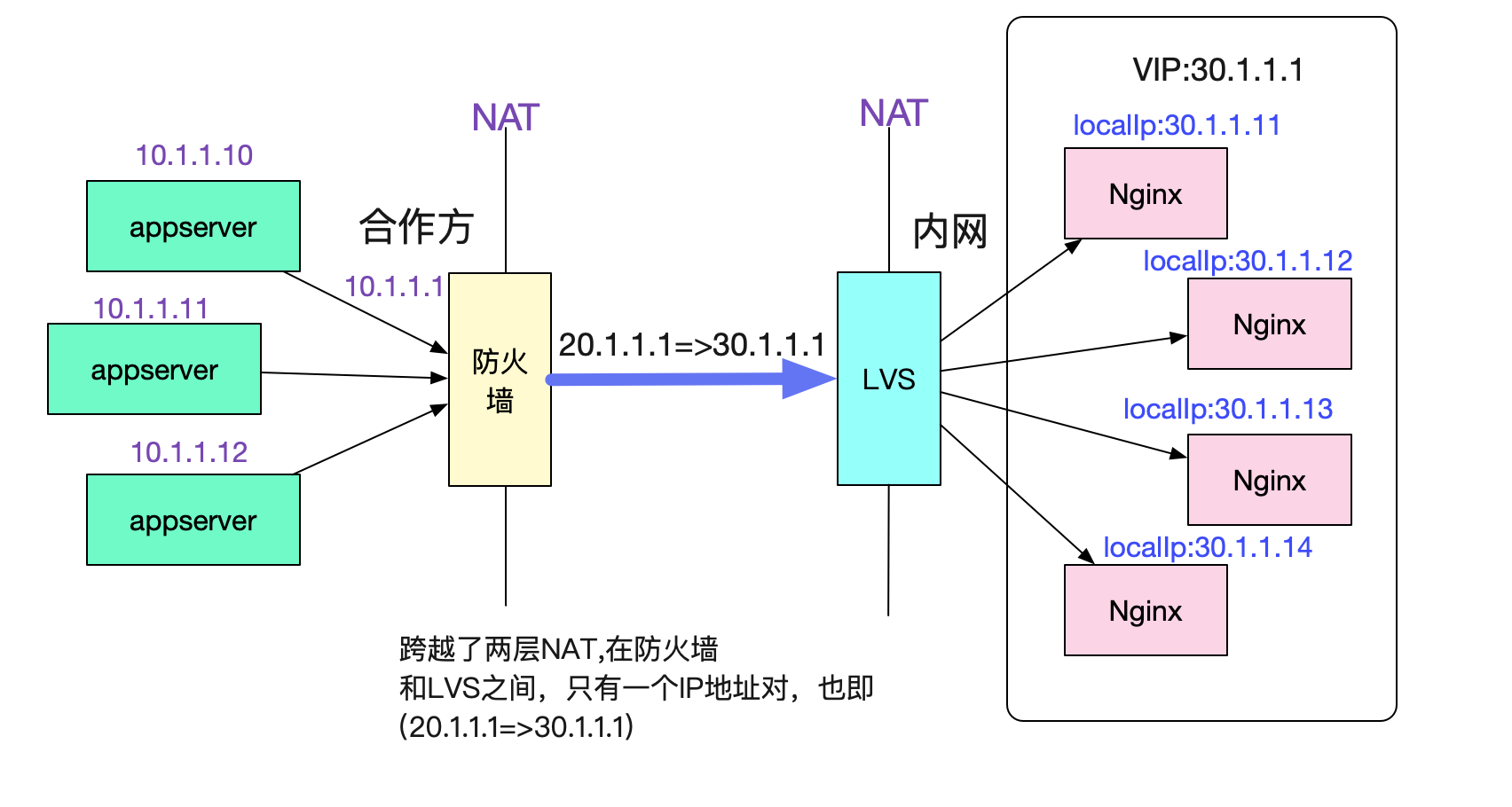
合作方的多台机器用NAT将多个源ip映射成同一个出口ip 20.1.1.1,而我们内网将多个Nginx映射成同一个目的ip 30.1.1.1。这样,在防火墙和LVS之间,所有的请求始终是通过(20.1.1.1,30.1.1.1)这样一个ip地址对进行访问。
同时还固定了一个参数,那就是目的端口号始终是443。
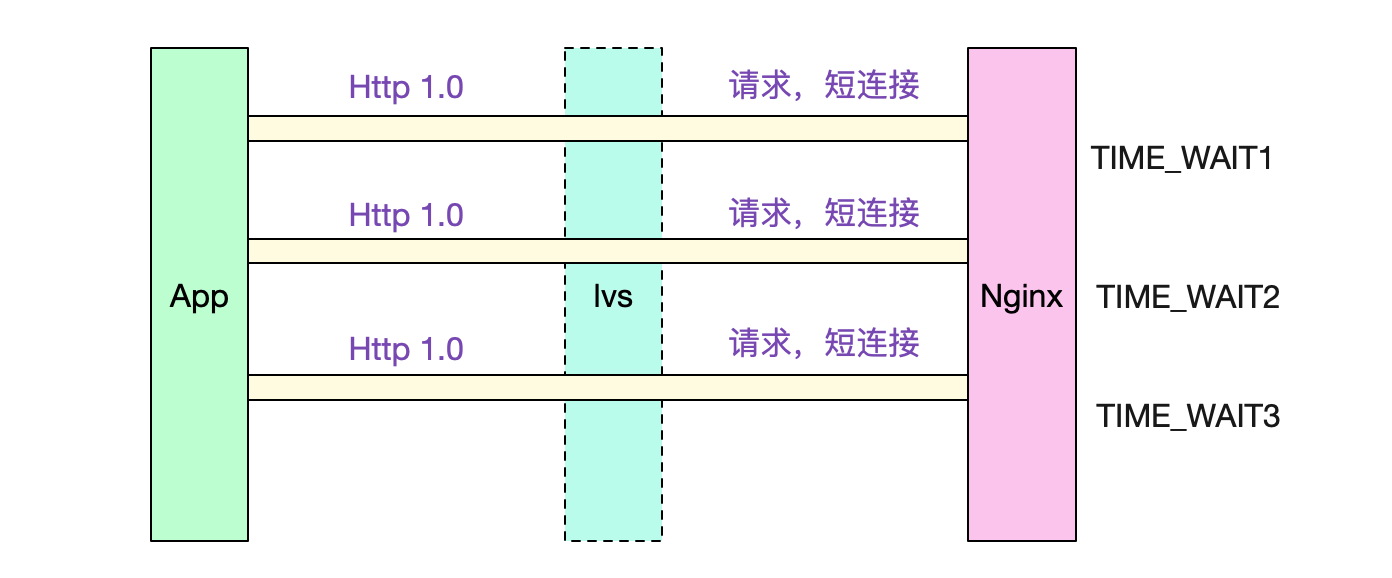
短连接-HTTP1.0
由于对方是采用短连接和Nginx进行交互的,而且采用的协议是HTTP-1.0。所以我们的Nginx在每个请求完成后,会主动关闭连接,从而造成有大量的TIME_WAIT。
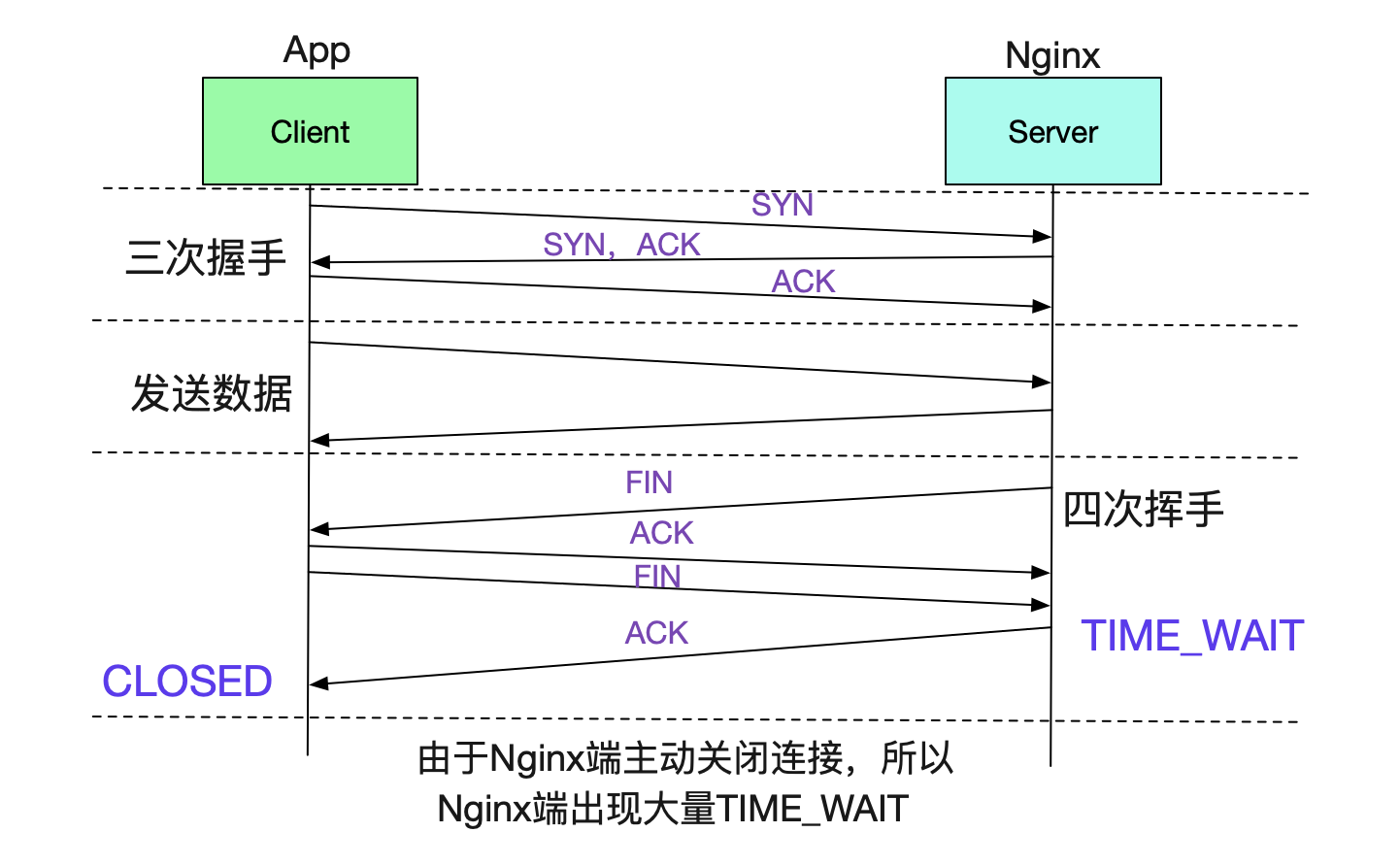
值得注意的是,TIME_WAIT取决于Server端和Client端谁先关闭这个Socket。所以Nginx作为Server端先关闭的话,也必然会产生TIME_WAIT。
内核参数配置
内核参数配置如下所示:
cat /proc/sys/net/ipv4/tcp_tw_reuse 0
cat /proc/sys/net/ipv4/tcp_tw_recycle 0
cat /proc/sys/net/ipv4/tcp_timestamps 1
其中tcp_tw_recycle设置为0。这样,可以有效解决tcp_timestamps和tcp_tw_recycle在NAT情况下导致的连接失败问题。具体见笔者之前的博客:
https://www.cnblogs.com/alchemystar/p/13444964.html
Bug现场
好了,介绍完环境,我们就可以正式描述Bug现场了。
Client端大量创建连接异常,而Server端无法感知
表象是合作方的应用出现大量的创建连接异常,而Server端确没有任何关于这些异常的任何异常日志,仿佛就从来没有出现过这些请求一样。
LVS监控曲线
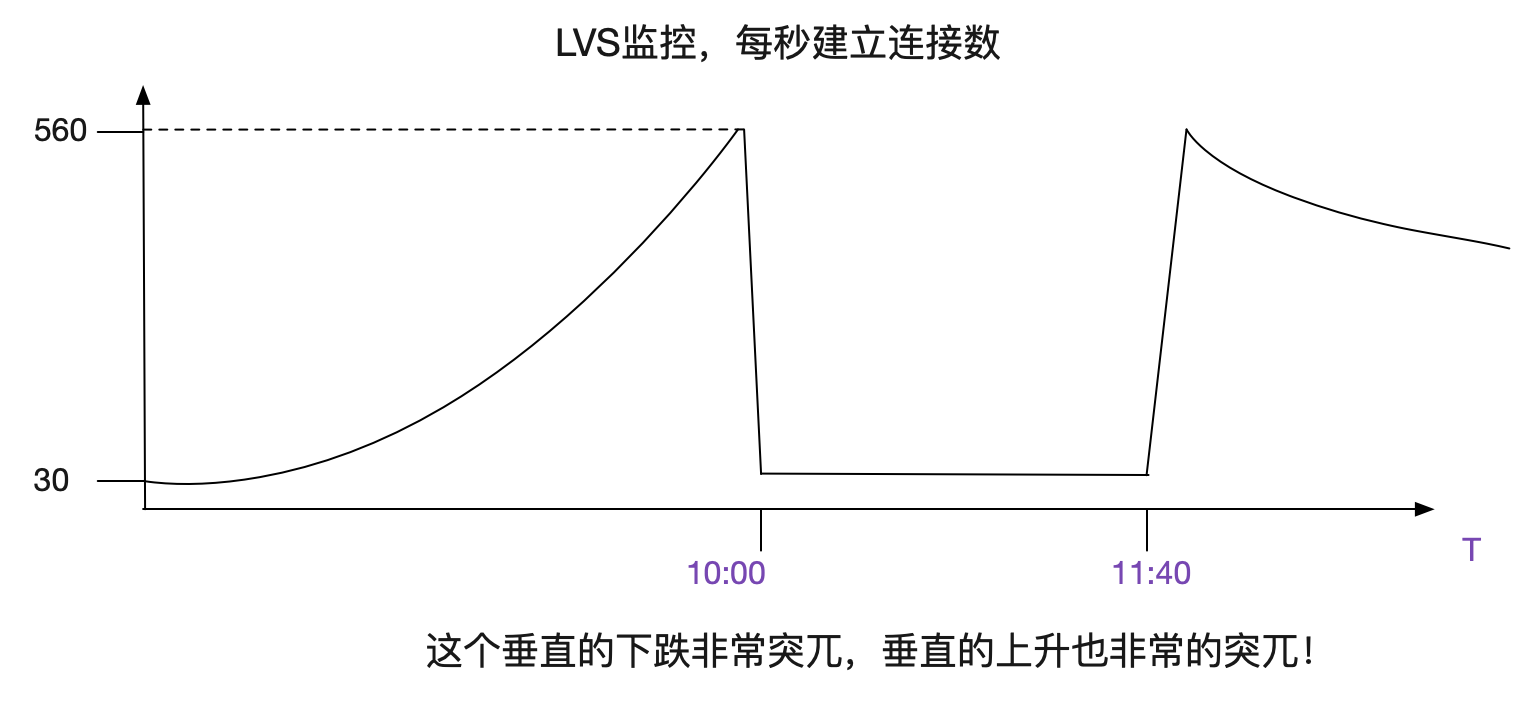
出现问题后,笔者翻了下LVS对应的监控曲线,其中有个曲线的变现非常的诡异。如下图所示:
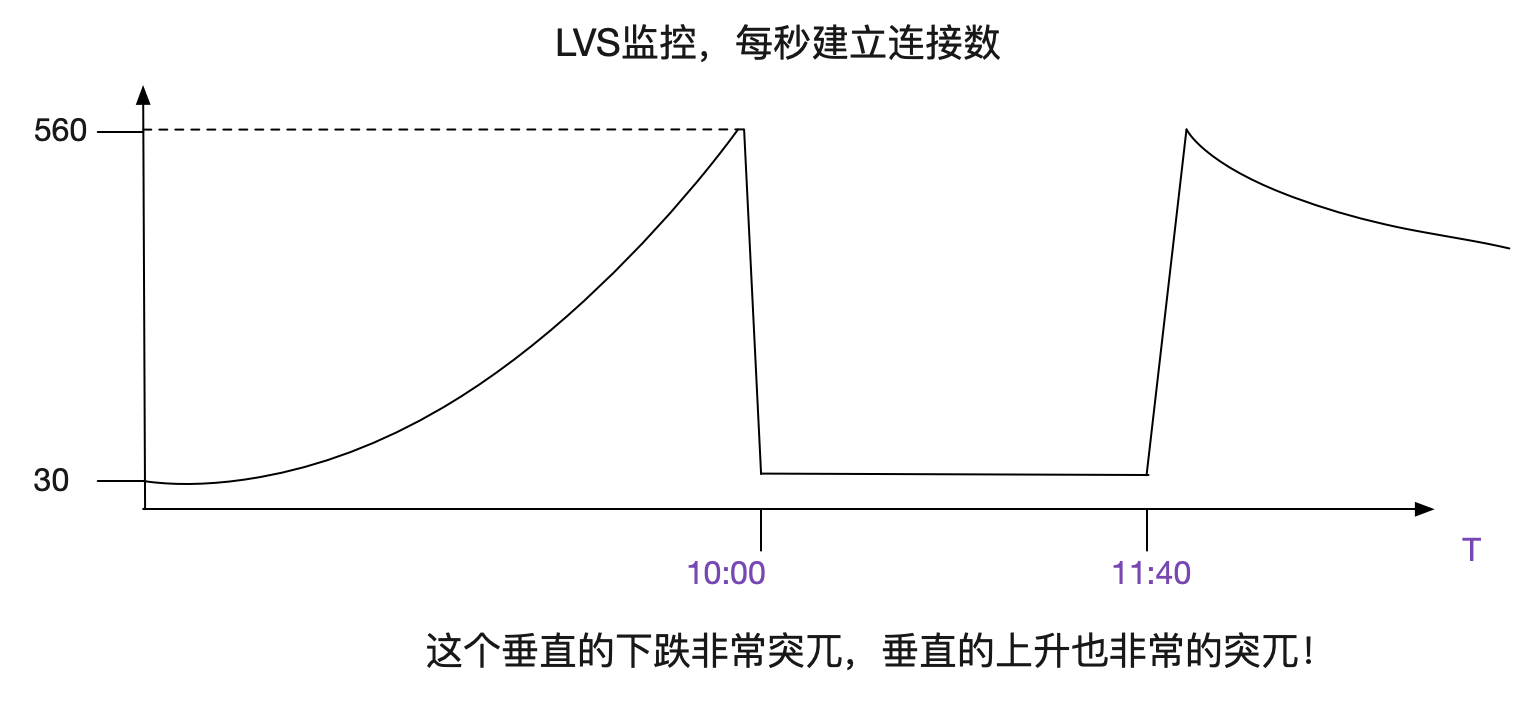
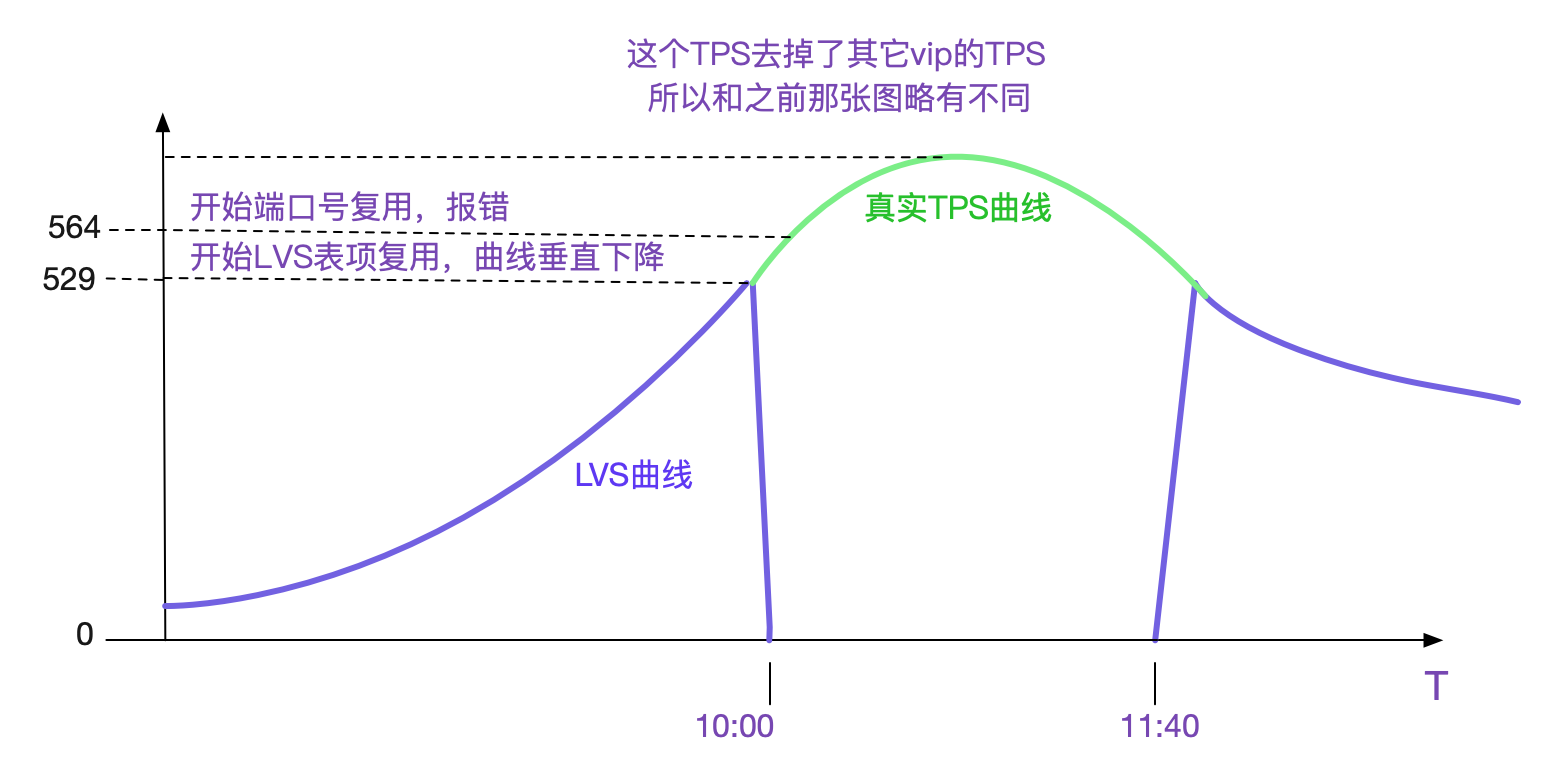
什么情况?看上去像建立不了连接了?但是虽然业务有大量的报错,依旧有很高的访问量,看日志的话,每秒请求应该在550向上!和这个曲线上面每秒只有30个新建连接是矛盾的!
每天发生的时间点非常接近
观察了几天后。发现,每天都在10点左右开始发生报错,同时在12点左右就慢慢恢复。
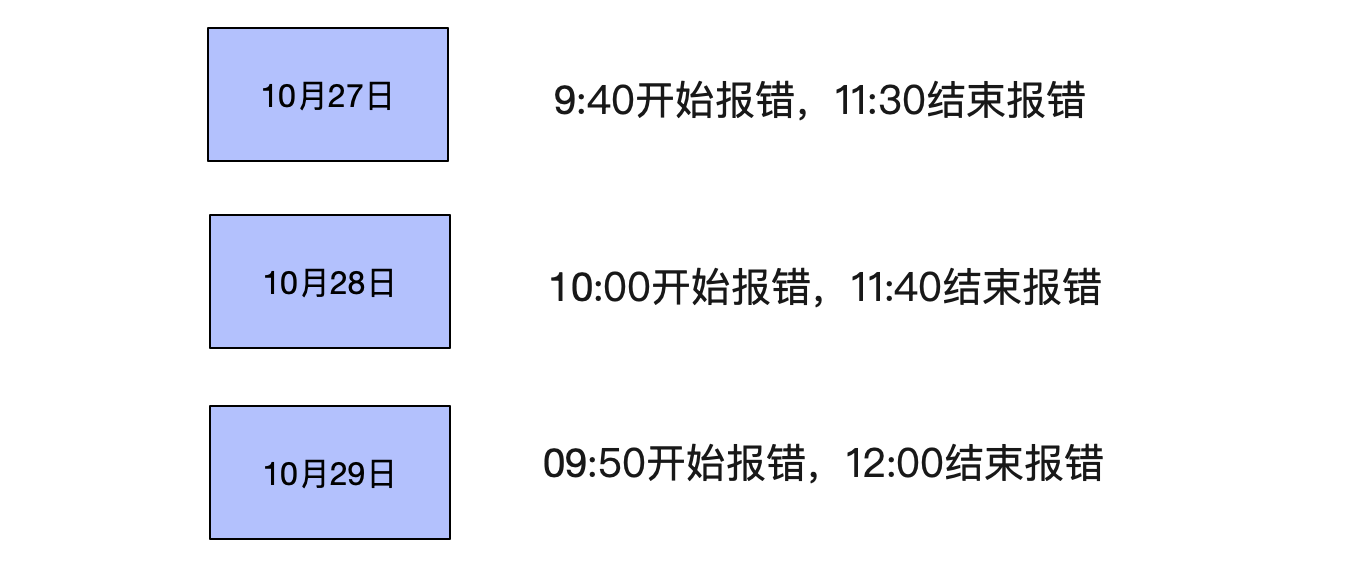
感觉就像每天10点在做活动,导致流量超过了系统瓶颈,进而暴露出问题。而11:40之后,流量慢慢下降,系统才慢慢恢复。难道LVS这点量都撑不住?才550TPS啊?就崩溃了?
难道是网络问题?
难道就是传说中的网络问题?看了下监控,流量确实增加,不过只占了将近1/8的带宽,离打爆网络还远着呢。
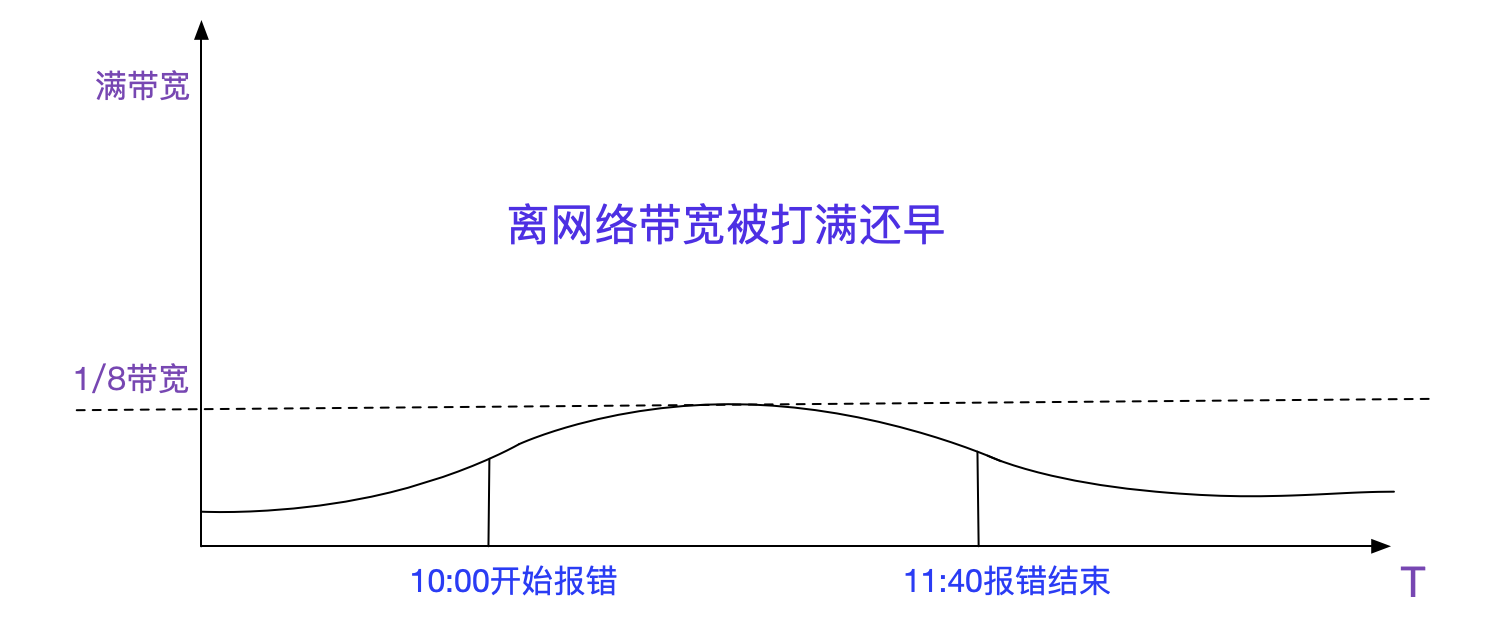
进行抓包
不管三七二十一,先抓包吧!
抓包结果
在这里笔者给出一个典型的抓包结果:
| 序号 | 时间 | 源地址 | 目的地址 | 源端口号 | 目的端口号 | 信息 |
|---|---|---|---|---|---|---|
| 1 | 09:57:30.60 | 30.1.1.1 | 20.1.1.1 | 443 | 33735 | [FIN,ACK]Seq=507,Ack=2195,TSval=1164446830 |
| 2 | 09:57:30.64 | 20.1.1.1 | 30.1.1.1 | 33735 | 443 | [FIN,ACK]Seq=2195,Ack=508,TSval=2149756058 |
| 3 | 09:57:30.64 | 30.1.1.1 | 20.1.1.1 | 443 | 33735 | [ACK]Seq=508,Ack=2196,TSval=1164446863 |
| 4 | 09:59:22.06 | 20.1.1.1 | 30.1.1.1 | 33735 | 443 | [SYN]Seq=0,TSVal=21495149222 |
| 5 | 09:59:22.06 | 30.1.1.1 | 20.1.1.1 | 443 | 33735 | [ACK]Seq=1,Ack=1487349876,TSval=1164558280 |
| 6 | 09:59:22.08 | 20.1.1.1 | 30.1.1.1 | 33735 | 443 | [RST]Seq=1487349876 |
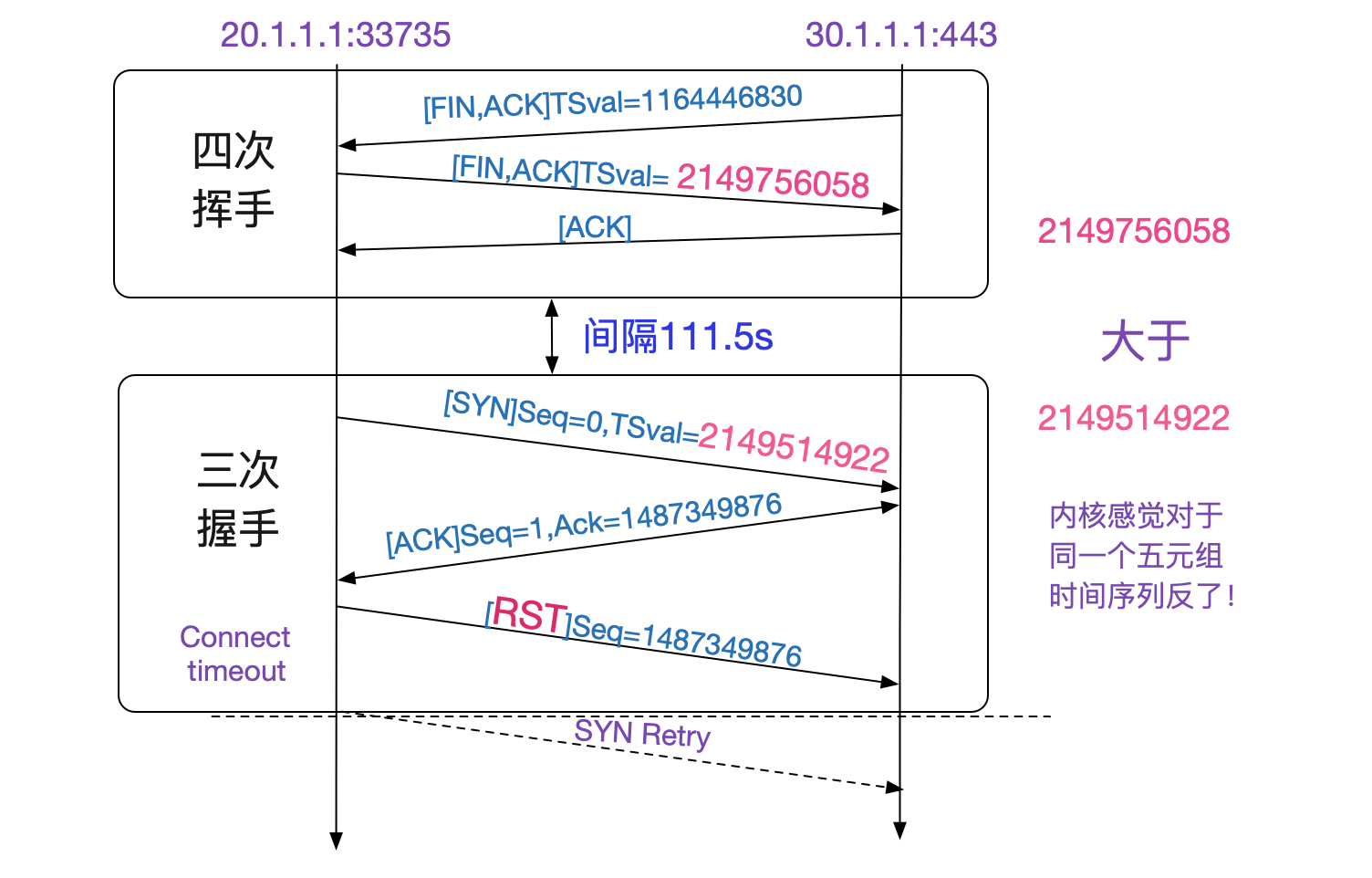
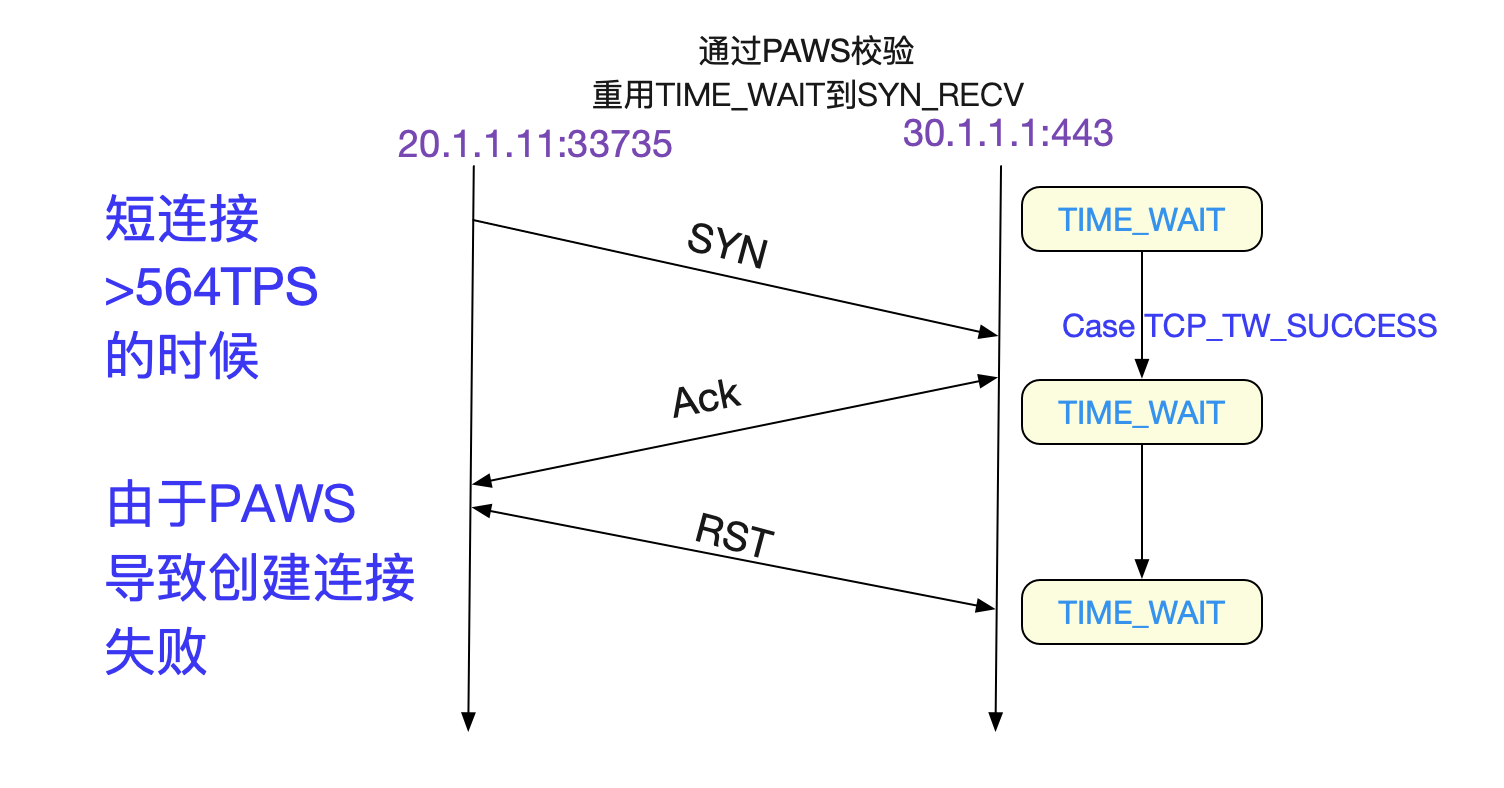
上面抓包结果如下图所示,一开始33735->443这个Socket四次挥手。在将近两分钟后又使用了同一个33735端口和443建立连接,443给33735回了一个莫名其妙的Ack,导致33735发了RST!
现象是怎么产生的?
首先最可疑的是为什么发送了一个莫名其妙的Ack回来?笔者想到,这个Ack是WireShark给我计算出来的。为了我们方便,WireShark会根据Seq=0而调整Ack的值。事实上,真正的Seq是个随机数!有没有可能是WireShark在某些情况下计算错误?
还是看看最原始的未经过加工的数据吧,于是笔者将wireshark的
Relative sequence numbers
给取消了。取消后的抓包结果立马就有意思了!调整过后抓包结果如下所示:
| 序号 | 时间 | 源地址 | 目的地址 | 源端口号 | 目的端口号 | 信息 |
|---|---|---|---|---|---|---|
| 1 | 09:57:30.60 | 30.1.1.1 | 20.1.1.1 | 443 | 33735 | [FIN,ACK]Seq=909296387,Ack=1556577962,TSval=1164446830 |
| 2 | 09:57:30.64 | 20.1.1.1 | 30.1.1.1 | 33735 | 443 | [FIN,ACK]Seq=1556577962,Ack=909296388,TSval=2149756058 |
| 3 | 09:57:30.64 | 30.1.1.1 | 20.1.1.1 | 443 | 33735 | [ACK]Seq=909296388,Ack=1556577963,TSval=1164446863 |
| 4 | 09:59:22.06 | 20.1.1.1 | 30.1.1.1 | 33735 | 443 | [SYN]Seq=69228087,TSVal=21495149222 |
| 5 | 09:59:22.06 | 30.1.1.1 | 20.1.1.1 | 443 | 33735 | [ACK]Seq=909296388,Ack=1556577963,TSval=1164558280 |
| 6 | 09:59:22.08 | 20.1.1.1 | 30.1.1.1 | 33735 | 443 | [RST]Seq=1556577963 |
看表中,四次挥手里面的Seq和Ack对应的值和三次回收中那个错误的ACK完全一致!也就是说,四次回收后,五元组并没有消失,而是在111.5s内还存活着!按照TCPIP状态转移图,只有TIME_WAIT状态才会如此。
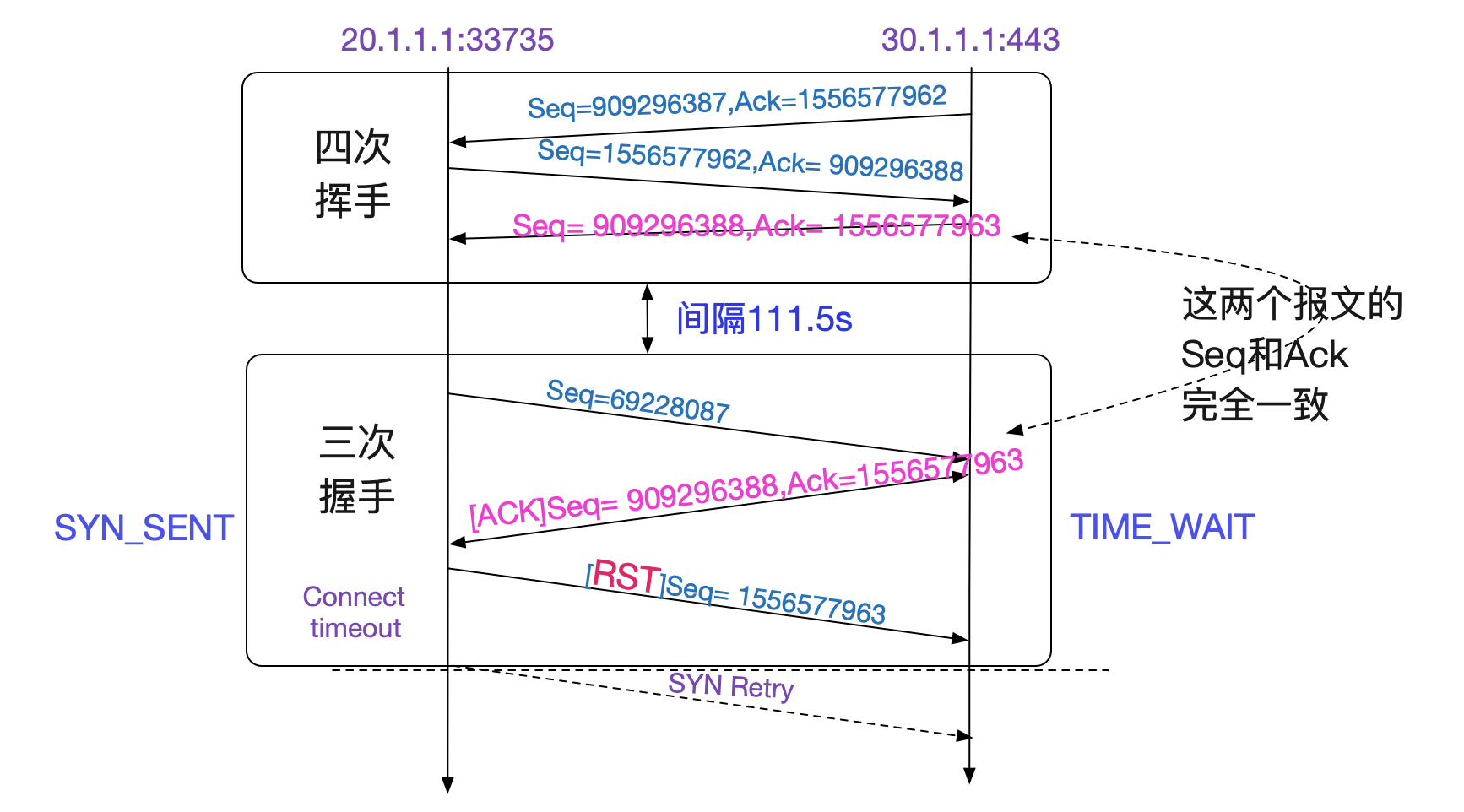
我们可以看看Linux关于TIME_WAIT处理的内核源码:
switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) {
// 如果是TCP_TW_SYN,那么允许此SYN分节重建连接
// 即允许TIM_WAIT状态跃迁到SYN_RECV
case TCP_TW_SYN: {
struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev),
&tcp_hashinfo,
iph->saddr, th->source,
iph->daddr, th->dest,
inet_iif(skb));
if (sk2) {
inet_twsk_deschedule(inet_twsk(sk), &tcp_death_row);
inet_twsk_put(inet_twsk(sk));
sk = sk2;
goto process;
}
/* Fall through to ACK */
}
// 如果是TCP_TW_ACK,那么,返回记忆中的ACK,这和我们的现象一致
case TCP_TW_ACK:
tcp_v4_timewait_ack(sk, skb);
break;
// 如果是TCP_TW_RST直接发送RESET包
case TCP_TW_RST:
tcp_v4_send_reset(sk, skb);
inet_twsk_deschedule(inet_twsk(sk), &tcp_death_row);
inet_twsk_put(inet_twsk(sk));
goto discard_it;
// 如果是TCP_TW_SUCCESS则直接丢弃此包,不做任何响应
case TCP_TW_SUCCESS:;
}
goto discard_it;
上面的代码有两个分支,值得我们注意,一个是TCP_TW_ACK,在这个分支下,返回TIME_WAIT记忆中的ACK和我们的抓包现象一模一样。还有一个TCP_TW_SYN,它表明了在
TIME_WAIT状态下,可以立马重用此五元组,跳过2MSL而达到SYN_RECV状态!
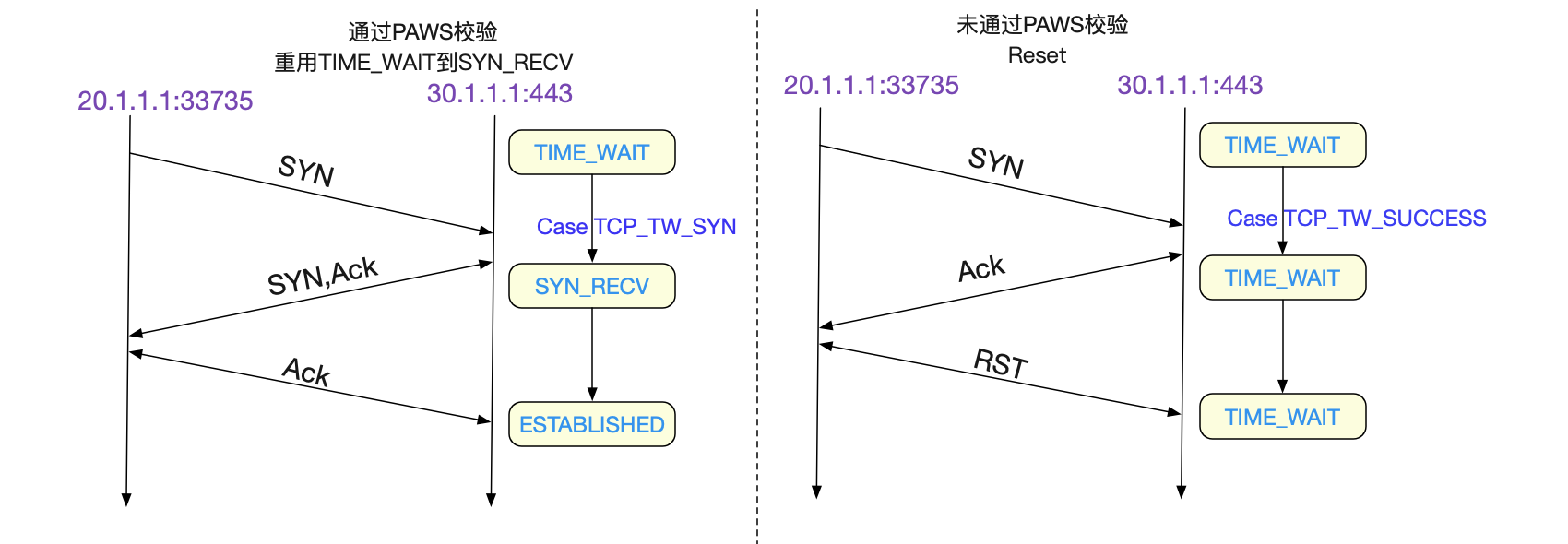
状态的迁移就在于tcp_timewait_state_process这个函数,我们着重看下想要观察的分支:
enum tcp_tw_status
tcp_timewait_state_process(struct inet_timewait_sock *tw, struct sk_buff *skb,
const struct tcphdr *th)
{
bool paws_reject = false;
......
paws_reject = tcp_paws_reject(&tmp_opt, th->rst);
if (!paws_reject &&
(TCP_SKB_CB(skb)->seq == tcptw->tw_rcv_nxt &&
(TCP_SKB_CB(skb)->seq == TCP_SKB_CB(skb)->end_seq || th->rst))) {
......
// 重复的ACK,discard此包
return TCP_TW_SUCCESS;
}
// 如果是SYN分节,而且通过了paws校验
if (th->syn && !th->rst && !th->ack && !paws_reject &&
(after(TCP_SKB_CB(skb)->seq, tcptw->tw_rcv_nxt) ||
(tmp_opt.saw_tstamp &&
(s32)(tcptw->tw_ts_recent - tmp_opt.rcv_tsval) < 0))) {
......
// 返回TCP_TW_SYN,允许重用TIME_WAIT五元组重新建立连接
return TCP_TW_SYN;
}
// 如果没有通过paws校验,则增加统计参数
if (paws_reject)
NET_INC_STATS_BH(twsk_net(tw), LINUX_MIB_PAWSESTABREJECTED);
if (!th->rst) {
// 如果没有通过paws校验,而且这个分节包含ack,则将TIMEWAIT持续时间重新延长
// 我们抓包结果的结果没有ACK,只有SYN,所以并不会延长
if (paws_reject || th->ack)
inet_twsk_schedule(tw, &tcp_death_row, TCP_TIMEWAIT_LEN,
TCP_TIMEWAIT_LEN);
// 返回TCP_TW_ACK,也即TCP重传ACK到对面
return TCP_TW_ACK;
}
}
根据上面源码,PAWS(Protect Againest Wrapped Sequence numbers防止回绕)校验机制如果生效而拒绝此分节的话,LINUX_MIB_PAWSESTABREJECTED这个统计参数会增加,对应于Linux中的命令即是:
netstat -s | grep reject
216576 packets rejects in established connections because of timestamp
这么上去后端的Nginx一统计,果然有大量的报错。而且根据笔者的观察,这个统计参数急速增加的时间段就是出问题的时间段,也就是每天早上10:00-12:00左右。每次大概会增加1W多个统计参数。
那么什么时候PAWS会不通过呢,我们直接看下tcp_paws_reject的源码吧:
static inline int tcp_paws_reject(const struct tcp_options_received *rx_opt,
int rst)
{
if (tcp_paws_check(rx_opt, 0))
return 0;
// 如果是rst,则放松要求,60s没有收到对端报文,认为PAWS检测通过
if (rst && get_seconds() >= rx_opt->ts_recent_stamp + TCP_PAWS_MSL)
return 0;
return 1;
}
static inline int tcp_paws_check(const struct tcp_options_received *rx_opt,
int paws_win)
{
// 如果ts_recent中记录的上次报文(SYN)的时间戳,小于当前报文的时间戳(TSval),表明paws检测通过
// paws_win = 0
if ((s32)(rx_opt->ts_recent - rx_opt->rcv_tsval) <= paws_win)
return 1;
// 否则,上一次获得ts_recent时间戳的时刻的24天之后,为真表明已经有超过24天没有接收到对端的报文了,认为PAWS检测通过
if (unlikely(get_seconds() >= rx_opt->ts_recent_stamp + TCP_PAWS_24DAYS))
return 1;
return 0;
}
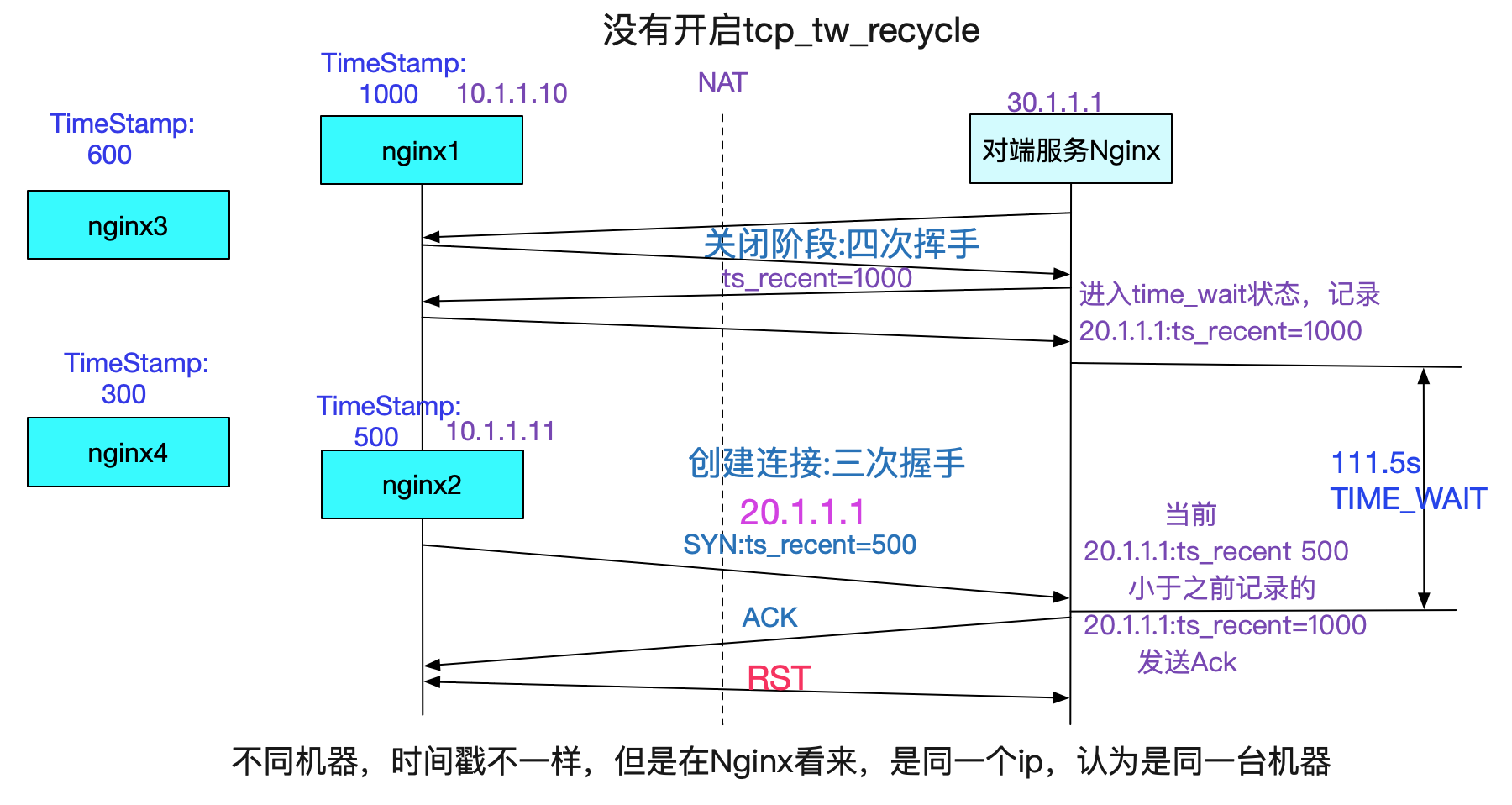
在抓包的过程中,我们明显发现,在四次挥手时候,记录的tsval是2149756058,而下一次syn三次握手的时候是21495149222,反而比之前的小了!
| 序号 | 时间 | 源地址 | 目的地址 | 源端口号 | 目的端口号 | 信息 |
|---|---|---|---|---|---|---|
| 2 | 09:57:30.64 | 20.1.1.1 | 30.1.1.1 | 33735 | 443 | [FIN,ACK]TSval=2149756058 |
| 4 | 09:59:22.06 | 20.1.1.1 | 30.1.1.1 | 33735 | 443 | [SYN]TSVal=21495149222 |
所以PAWS校验不过。
那么为什么会这个SYN时间戳比之前挥手的时间戳还小呢?那当然是NAT的锅喽,NAT把多台机器的ip虚拟成同一个ip。但是多台机器的时间戳(也即从启动开始到现在的时间,非墙上时间),如下图所示:
但是还有一个疑问,笔者记得TIME_WAIT也即2MSL在Linux的代码里面是定义为了60s。为何抓包的结果却存活了将近2分钟之久呢?
TIME_WAIT的持续时间
于是笔者开始阅读器关于TIME_WAIT定时器的源码,具体可见笔者的另一篇博客:
从Linux源码看TIME_WAIT状态的持续时间
https://www.cnblogs.com/alchemystar/p/13883871.html
结论如下
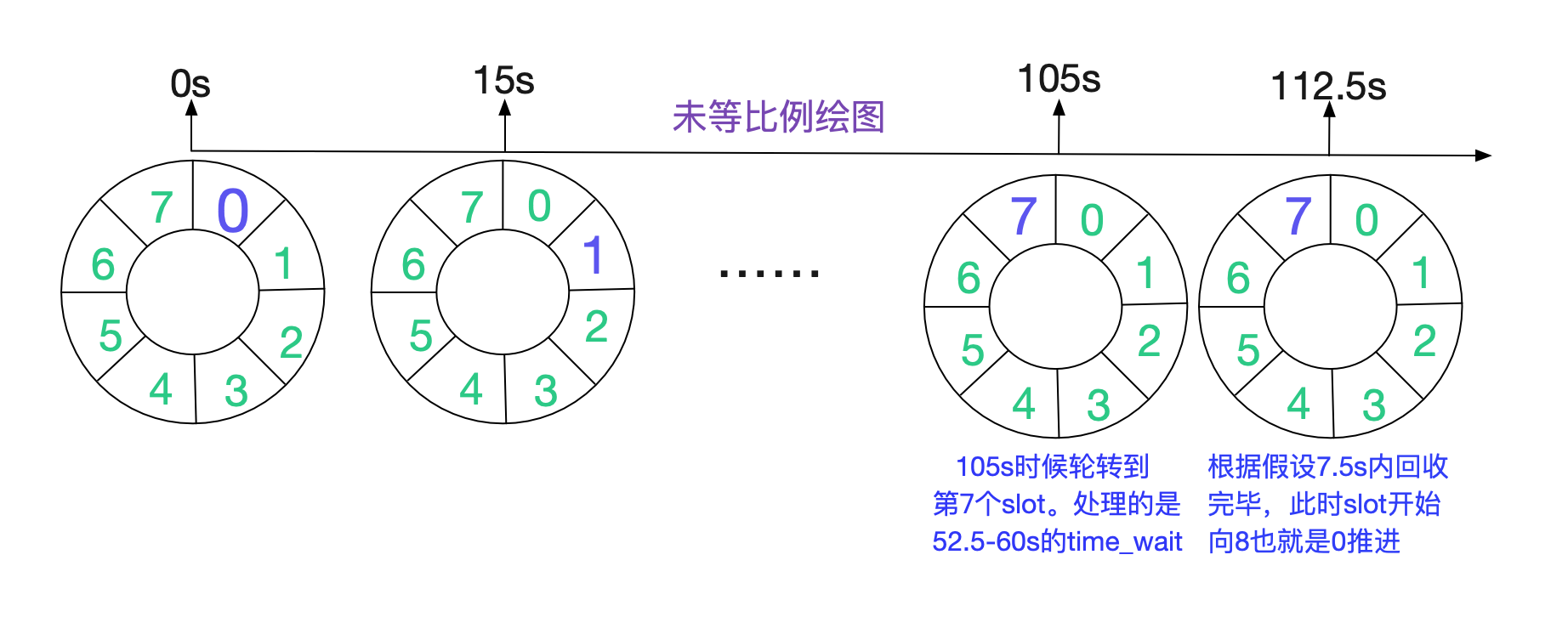
在TIME_WAIT很多的状态下,TIME_WAIT能够存活112.5s,将近两分钟的时间,和我们的抓包结果一致。
当然了,这个计算只是针对Linux 2.6和3.10内核而言,而对红帽维护的3.10.1127内核版本则会有另外的变化,这个变化导致了一个令笔者感到非常奇异的现象,这个在后面会提到。
问题发生条件
如上面所解释,只有在Server端TIME_WAIT还没有消失时候,重用这个Socket的时候,遇上了反序的时间戳SYN,就会发生这种问题。由于NAT前面的所有机器时间戳都不相同,所以有很大概率会导致时间戳反序!
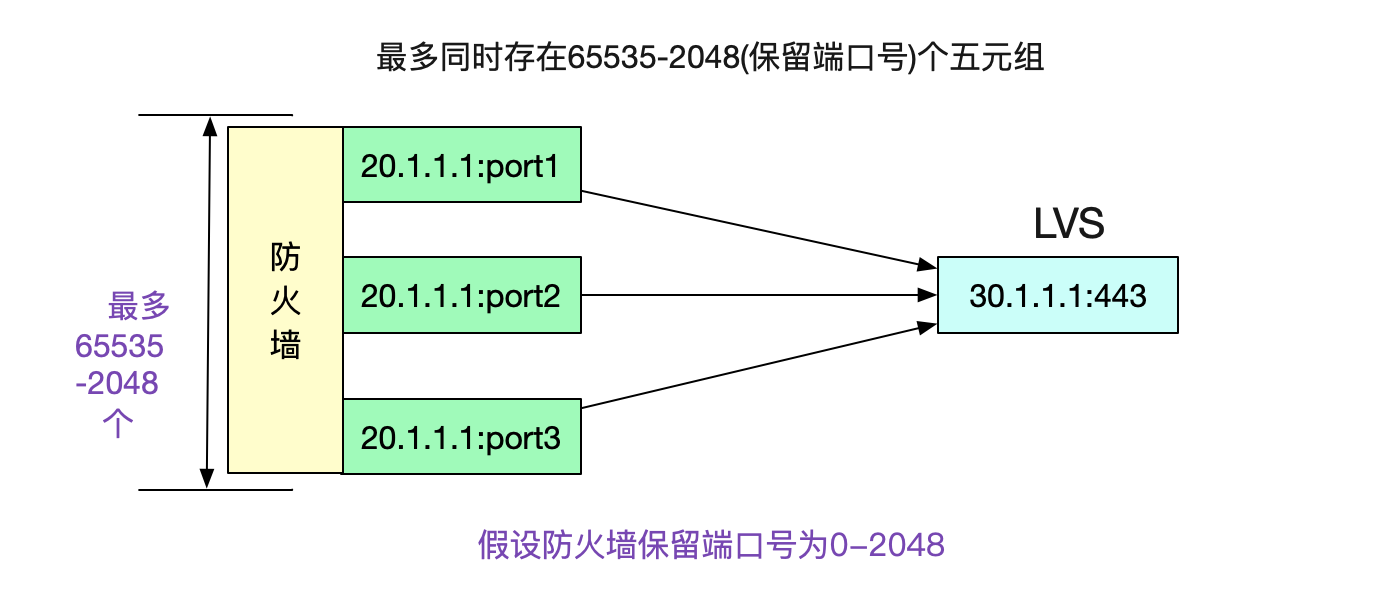
那么什么时候重用TIME_WAIT状态的Socket呢
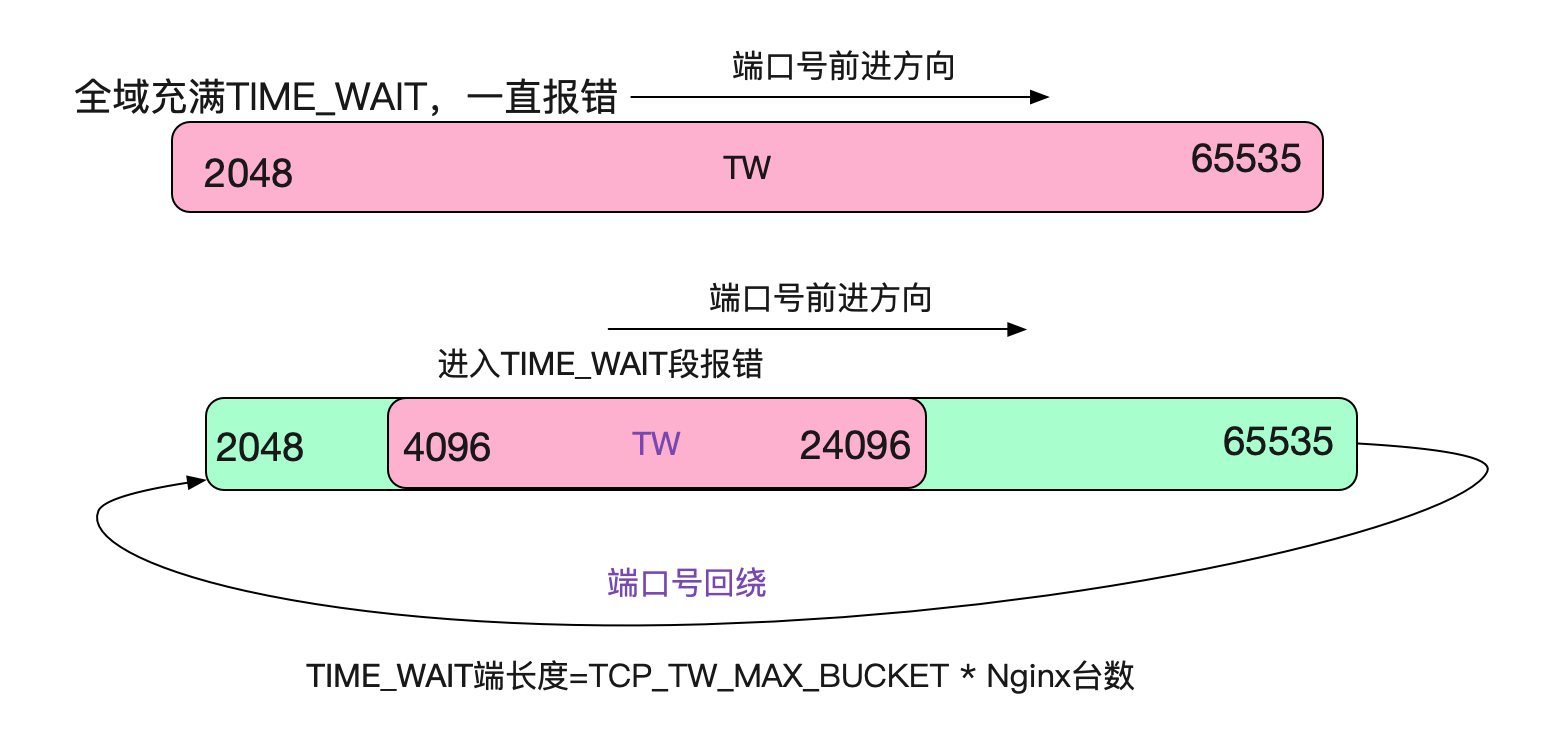
笔者知道,防火墙的端口号选择逻辑是RoundRobin的,也即从2048开始一直增长到65535,再回绕到2048,如下图所示:

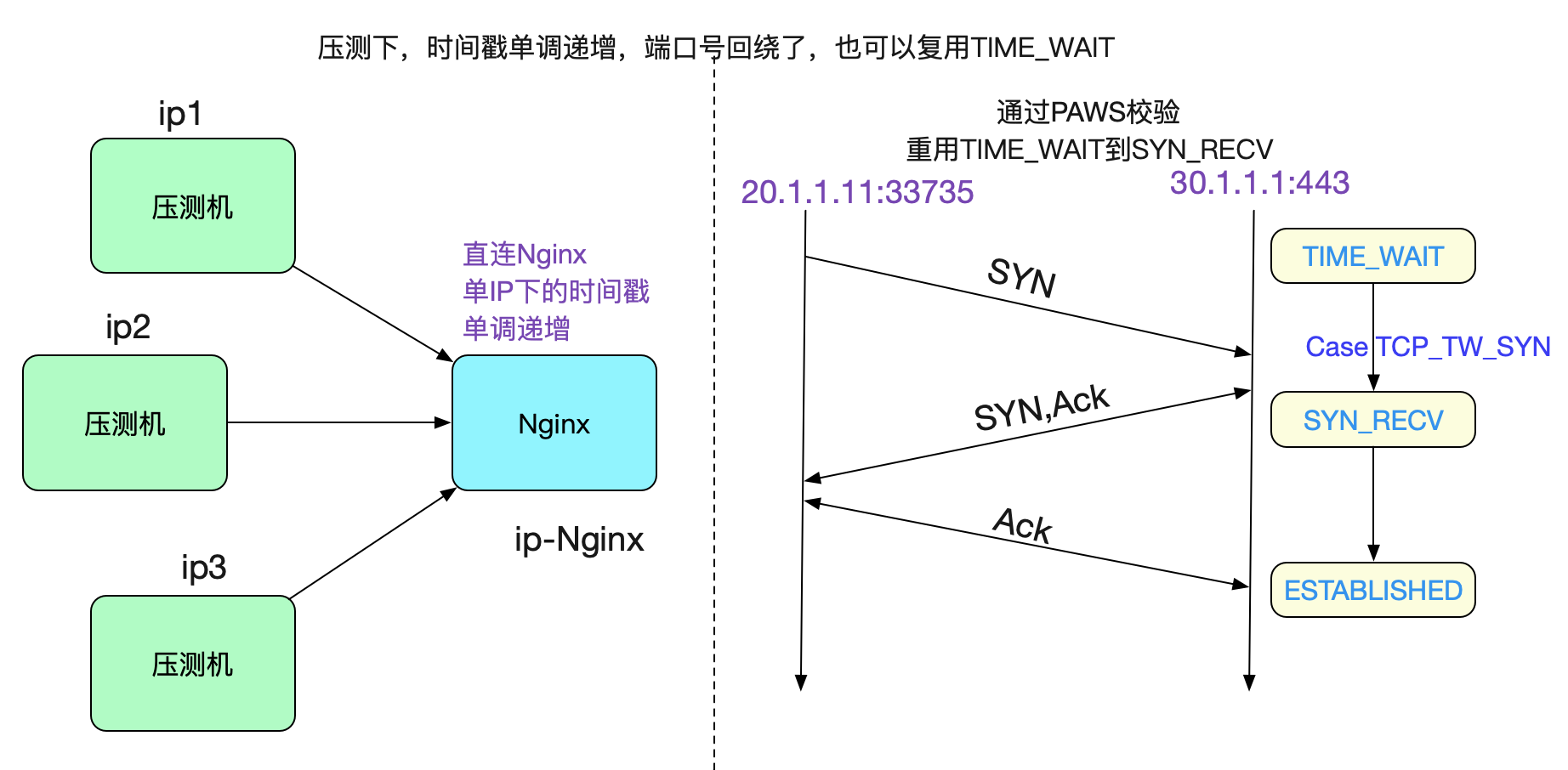
为什么压测的时候不出现问题
但我们在线下压测的时候,明显速率远超560tps,那为何确没有这样的问题出现呢。很简单,是因为
TCP_SYN_SUCCESS这个分支,由于我们的压测机没有过NAT,那么时间戳始终保持单IP下的单调递增,即便>560TPS之后,走的也是TCP_SYN_SUCCESS,将TIME_WAIT Socket重用为SYN_RECV,自然不会出现这样的问题,如下图所示:
如何解释LVS的监控曲线?
等等,564TPS?这个和LVS陡然下跌的TPS基本相同!难道在端口号复用之后LVS就不会新建连接(其实是LVS中的session表项)?从而导致统计参数并不增加?
于是笔者直接去撸了一下LVS的源码:
tcp_conn_schedule
|->ip_vs_schedule
/* 如果新建conn表项成功,则对已有连接数++ */
|->ip_vs_conn_stats
而在我们的入口函数ip\_vs\_in中
static unsigned int
ip_vs_in(unsigned int hooknum, struct sk_buff *skb,
const struct net_device *in, const struct net_device *out,
int (*okfn) (struct sk_buff *))
{
......
// 如果能找到对应的五元组
cp = pp->conn_in_get(af, skb, pp, &iph, iph.len, 0, &res_dir);
if (likely(cp)) {
/* For full-nat/local-client packets, it could be a response */
if (res_dir == IP_VS_CIDX_F_IN2OUT) {
return handle_response(af, skb, pp, cp, iph.len);
}
} else {
/* create a new connection */
int v;
// 找不到对应的五元组,则新建连接,同时conn++
if (!pp->conn_schedule(af, skb, pp, &v, &cp))
return v;
}
......
}
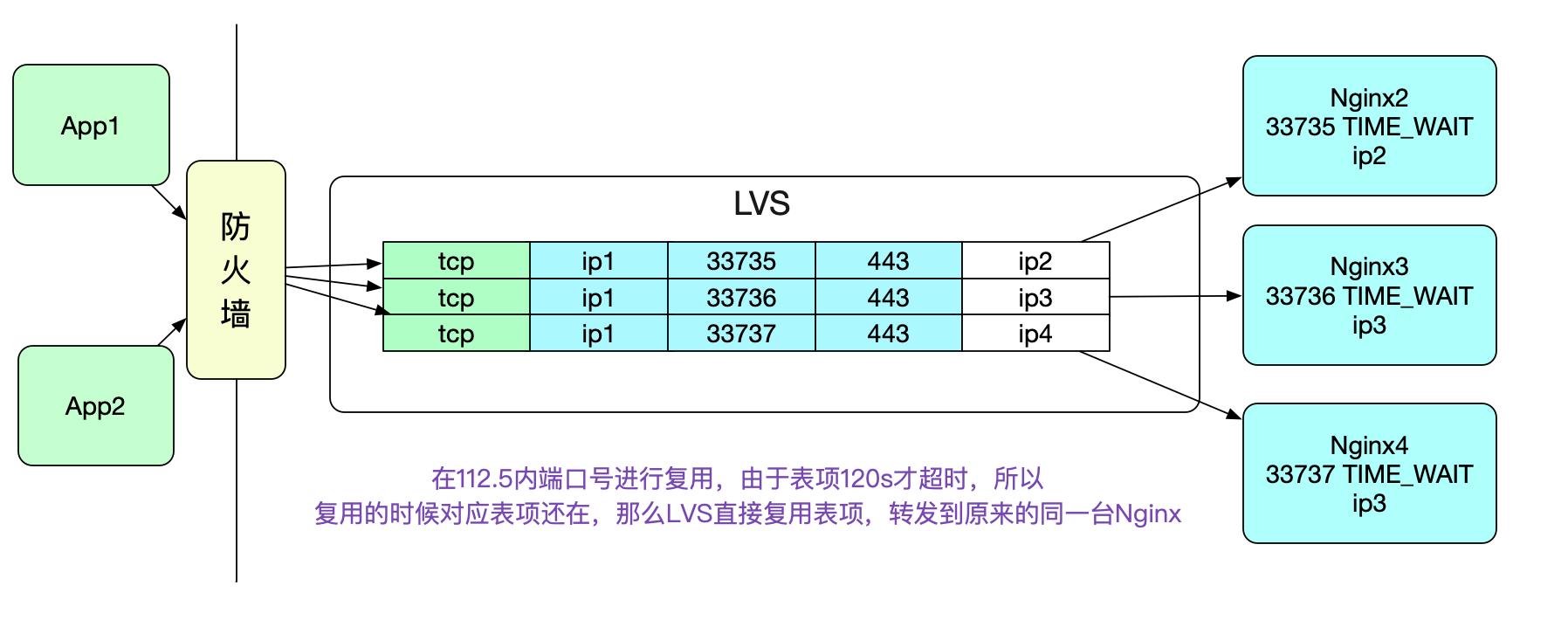
很明显的,如果当前五元组表项存在,则直接复用表项,而不存在,才创建新的表项,同时conn++。而表项需要在LVS的Fintimeout时间超过后才消失(在笔者的环境里面是120s)。这样,在端口号复用的时候,因为<112.5s,所以LVS会直接复用表项,而统计参数不会有任何变化,从而导致了下面这个曲线。
当流量慢慢变小,无法达到重用端口号的条件的时候,曲线又会垂直上升。和笔者的推测一致。也就是说在五元组固定四元的情况下>529tps(63487/120)的时候,在此固定业务下的新建连接数不会增加。
而图中仅存的560-529=>21+个连接创建,是由另一个业务的vip引起,在这个vip上,由于量很小,没有端口复用。但是LVS统计的是总数量,所以在端口号开始复用之后,始终会有少量的新建连接存在。
值得注意的是,端口号复用之后,LVS转发的时候就会直接使用这个映射表项,所以相同的五元组到LVS后会转发给相同的Nginx,而不会进行WRR(Weight Round Robin)负载均衡,表现出了一定的"亲和性"。如下图所示:
NAT下固定ip地址对的性能瓶颈
好了,现在可以下结论了。在ip源和目的地址固定,目的端口号也固定的情况下,五元组的可变量只有ip源端口号了。而源端口号最多是65535个,如果计算保留端口号(0-2048)的话(假设防火墙保留2048个),那么最多可使用63487个端口。
由于每使用一个端口号,在高负载的情况下,都会产生一个112.5s才消失的TIME_WAIT。那么在63487/112.5也就是564TPS(使用短连接)的情况下,就会复用TIME_WAIT下的Socket。再加上PAWS校验,就会造成大量的连接创建异常!
这个论断和笔者观察到的应用报错以及LVS监控曲线一致。
LVS曲线异常事件和报错时间接近
因为LVS是在529TPS时候开始垂直下降,而端口号复用是在564TPS的时候开始,两者所需TPS非常接近,所以一般LVS出现曲线异常的时候,基本就是开始报错的时候!但是LVS曲线异常只能表明复用表项,并不能表明一定有问题,因为可以通过调节某些内核参数使得在端口号复用的时候不报错!
在端口号复用情况下,lvs本身的新建连接数无法代表真实TPS。
尝试修复
设置tcp_tw_max_bucket
首先,笔者尝试限制Nginx所在Linux中最大TIME_WAIT数量
echo '5000' > /proc/sys/net/ipv4/tcp_tw_max_bucket
这基于一个很简单的想法,TIME_WAIT状态越少,那么命中TIME_WAIT状态Socket的概率肯定越小。设置了之后,确实报错量确实减少了好多。但由于TPS超越极限之后端口号不停的回绕,导致还是一直在报错,不会有根本性好转。
如果将tcp_tw_max_bucket设置为0,那么按理论上来说不会出问题了。
但是无疑将TCP精心设计的TIME_WAIT这个状态给废弃了,笔者觉得这样做过于冒险,于是没有进行尝试。
尝试扩展源地址
这个问题本质是由于五元组在限定了4元,只有源端口号可变的情况下,端口号只有
2048-65535可用。那么我们放开源地址的限定,例如将源IP增加到3个,无疑可以将TPS扩大三倍。
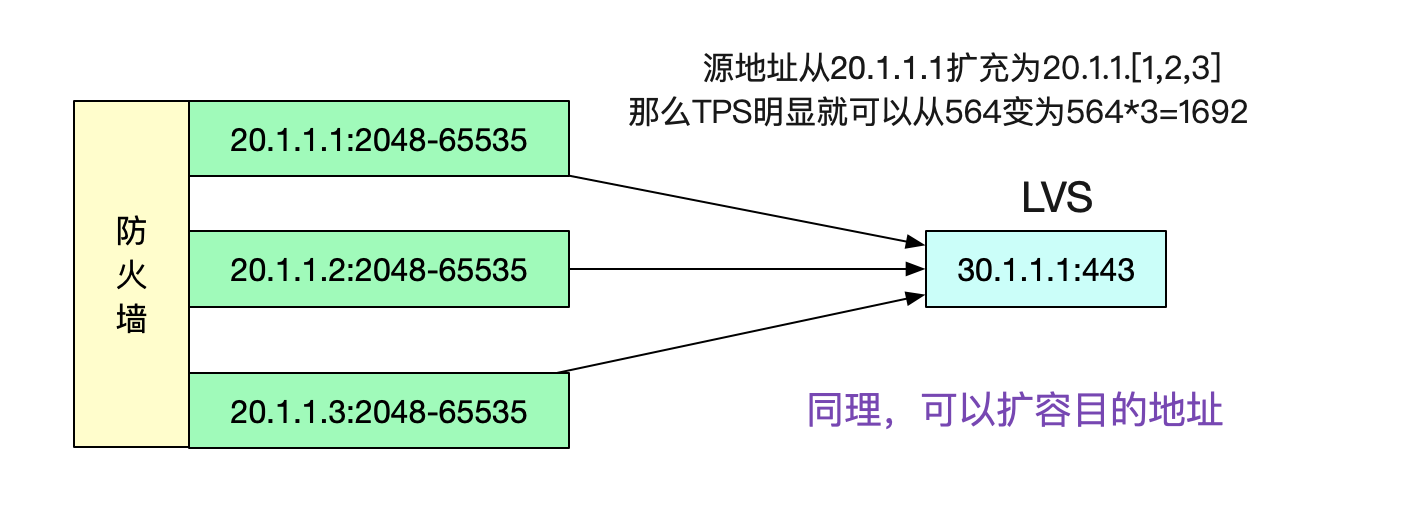
同理,将目的地址给扩容,也能达到类似的效果。
但据网工反映,合作方通过他们的防火墙出来之后就只有一个IP,而一个IP在我们的防火墙上并不能映射成多个IP,多以在不变更它们网络设置的情况下无法扩展源地址。而扩容目的地址,也需要对合作方网络设置进行修改。本着不让合作方改动的服务精神,笔者开始尝试其它方案。
扩容Nginx?没效果
在一开始笔者没有搞明白LVS那个诡异的曲线的时候,笔者并不知道在端口复用的情况下,LVS会表现出"亲和性"。于是想着,如果扩容Nginx后,根据负载均衡原则,正好落到有这个TIME_WAIT五元组的概率会降低,所以尝试着另扩容了一倍的Nginx。但由于之前所说的LVS在端口号复用下的亲和性,反而加大了TIME_WAIT段!
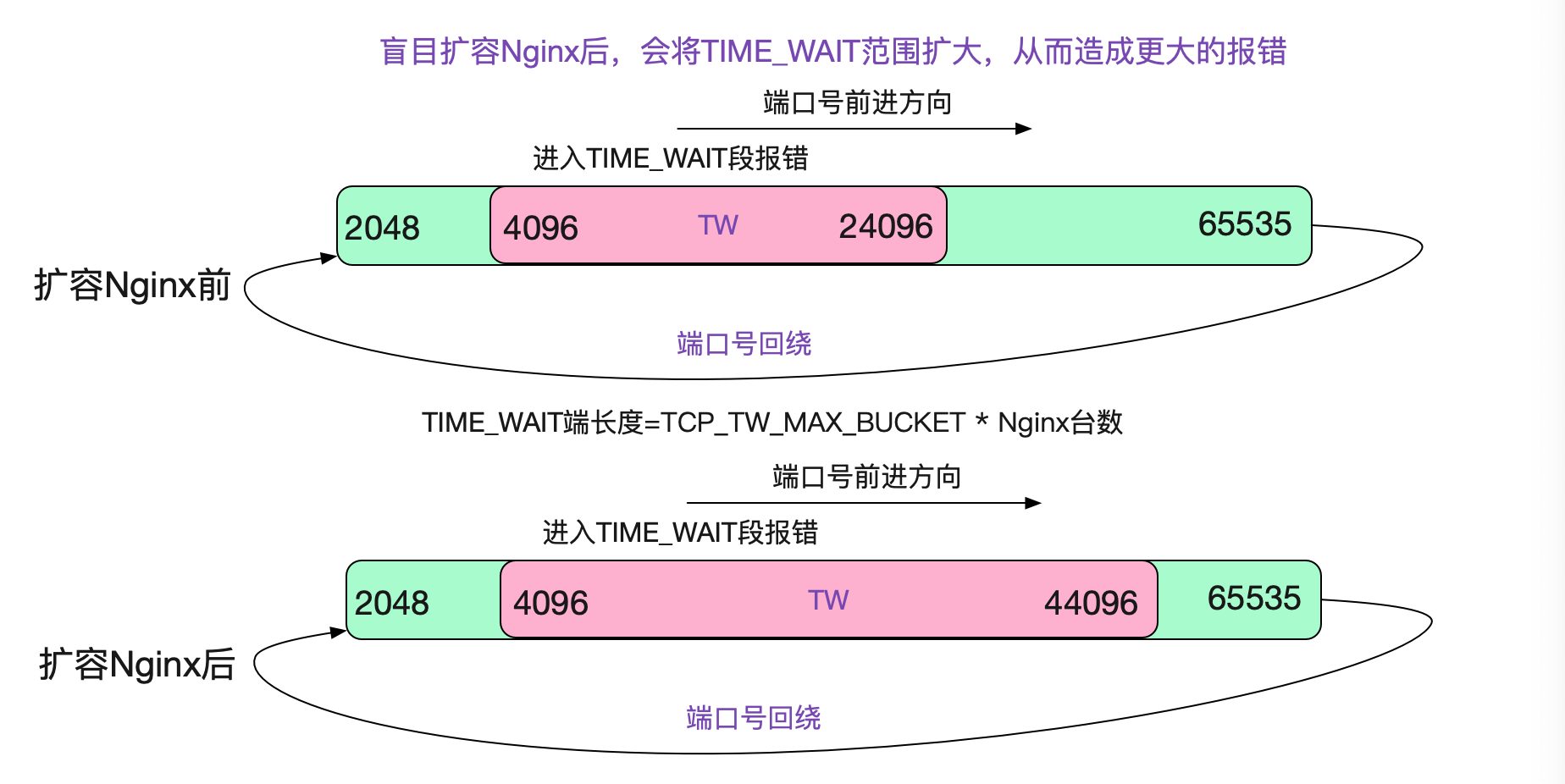
扩容Nginx的奇异现象
在笔者想明白LVS的"亲和性"之后,对扩容Nginx会导致更多的报错已经有了心理预期,不过被现实啪啪啪打脸!报错量和之前基本一样。更奇怪的是,笔者发现非活跃连接数监控(即非ESTABLISHED)状态,会在端口号复用之后,呈现出一种负载不均衡的现象,如下图所示。
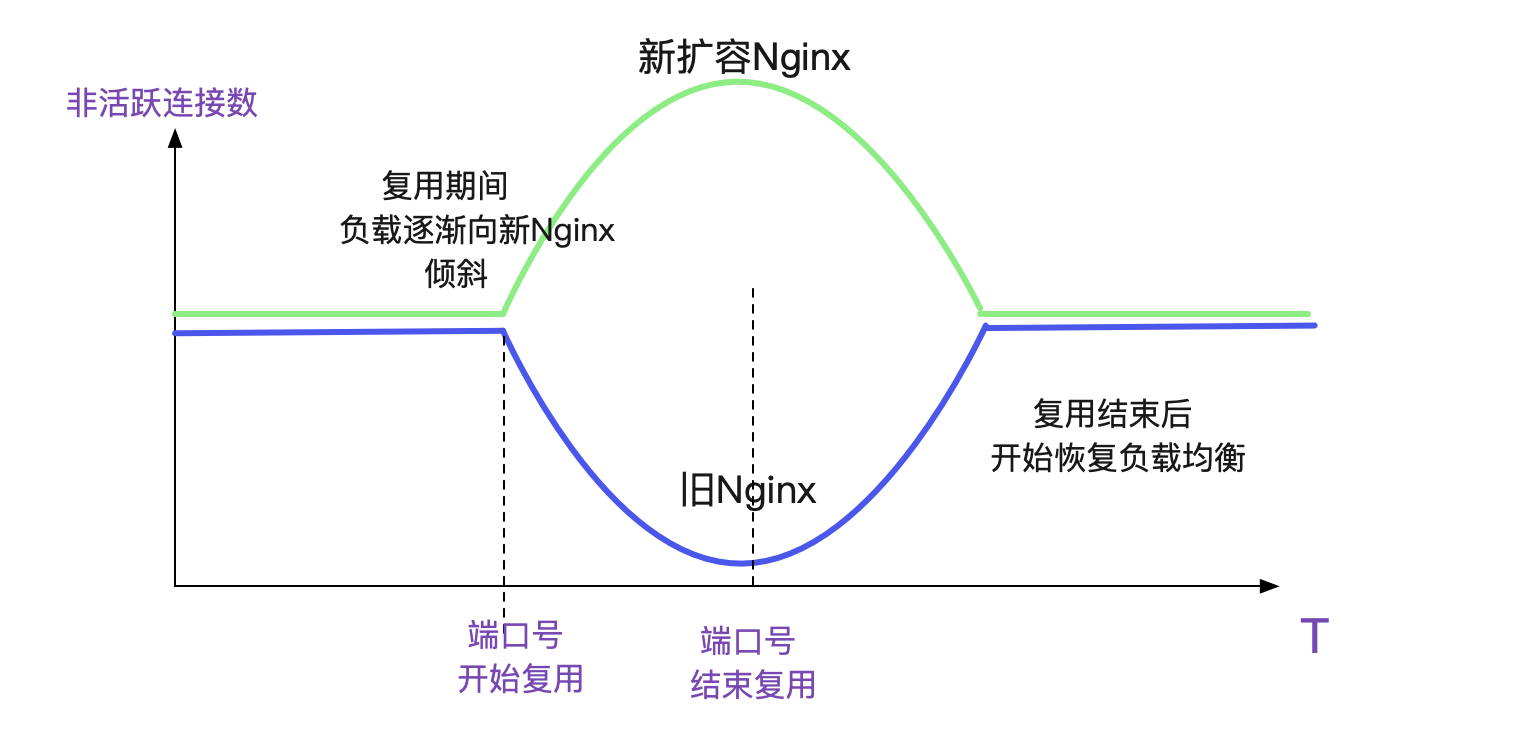
笔者上去新扩容的Nginx看了一下,发现新Nginx只有很少量的由于PAWS引起的报错,增长速率很慢,基本1个小时只有100多。而旧Nginx一个小时就有1W多!
那么按照这个错误比例分布,就很好理解为什么形成这样的曲线了。因为LVS的亲和性,在端口号复用时刻,落到旧Nginx上会大概率失败,从而在Fintimeout到期后,重新选择一个负载均衡的时候,如果落到新Nginx上,按照统计参数来看基本都会成功,但如果还是落到旧Nginx上则基本还会失败,如此往复。就天然的形成了一个优先选择的过程,从而造成了这个曲线。
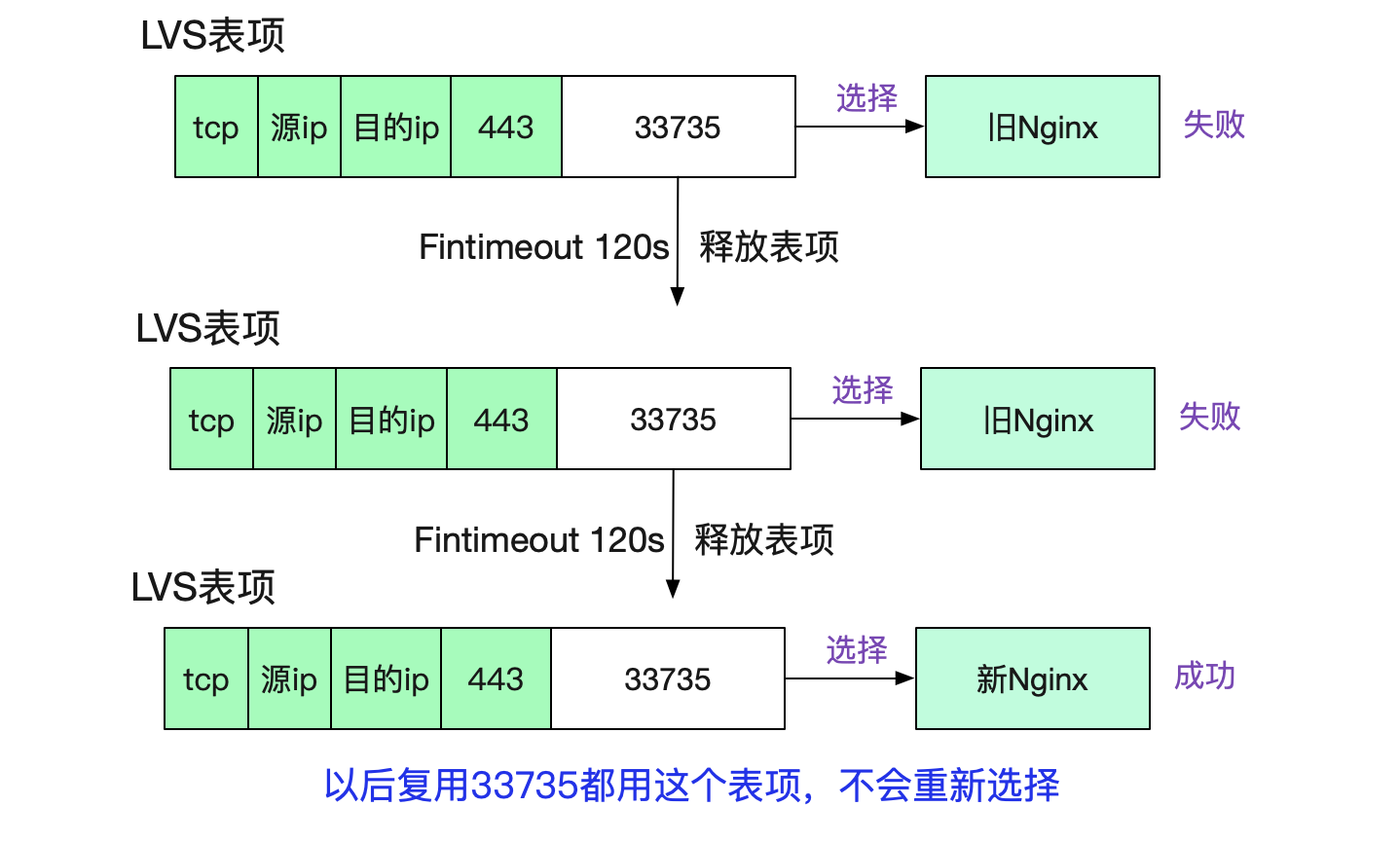
当然实际的过程会比这个复杂一点,多一些步骤,但大体是这个思路。
而在端口复用结束后,不管落到哪个Nginx上都会成功,所以负载均衡又会慢慢趋于均衡。
为什么新扩容的Nginx表现异常优异呢?
新扩容的Nginx表现异常优异,在这个TPS下没有问题,那到底是为什么呢?笔者想了一天都没想明白。睡了一觉之后,对比了两者的内核参数,突然豁然开朗。原来新扩容的Nginx所在的内核版本变了,变成了3.10!
笔者连忙对比起了原来的2.6内核和3.10的内核版本变化,但毫无所得。。。思维有陷入了停滞
Linux官方3.10和红帽的3.10.1127分支差异
等等,我们线上的内核版本是3.10.1127,并不是官方的内核,难道代码有所不同?于是笔者立马下载了3.10.1127的源码。这一比对,终于让笔者找到了原因所在,看如下代码!
void inet_twdr_twkill_work(struct work_struct *work)
{
struct inet_timewait_death_row *twdr =
container_of(work, struct inet_timewait_death_row, twkill_work);
bool rearm_timer = false;
int i;
BUILD_BUG_ON((INET_TWDR_TWKILL_SLOTS - 1) >
(sizeof(twdr->thread_slots) * 8));
while (twdr->thread_slots) {
spin_lock_bh(&twdr->death_lock);
for (i = 0; i < INET_TWDR_TWKILL_SLOTS; i++) {
if (!(twdr->thread_slots & (1 << i)))
continue;
while (inet_twdr_do_twkill_work(twdr, i) != 0) {
// 如果这次没处理完,将rearm_timer设置为true
rearm_timer = true;
if (need_resched()) {
spin_unlock_bh(&twdr->death_lock);
schedule();
spin_lock_bh(&twdr->death_lock);
}
}
twdr->thread_slots &= ~(1 << i);
}
spin_unlock_bh(&twdr->death_lock);
}
// 在这边多了一个rearm_timer,并将定时器设置为1s之后
// 这样,原来需要额外等待的7.5s现在收敛为额外等待1s
if (rearm_timer)
mod_timer(&twdr->tw_timer, jiffies + HZ);
}
如代码所示,3.10.1127对TIME_WAIT的时间轮处理做了加速,让原来需要额外等待的7.5s收敛为额外等待的1s。经过校正后的时间轮如下所示:
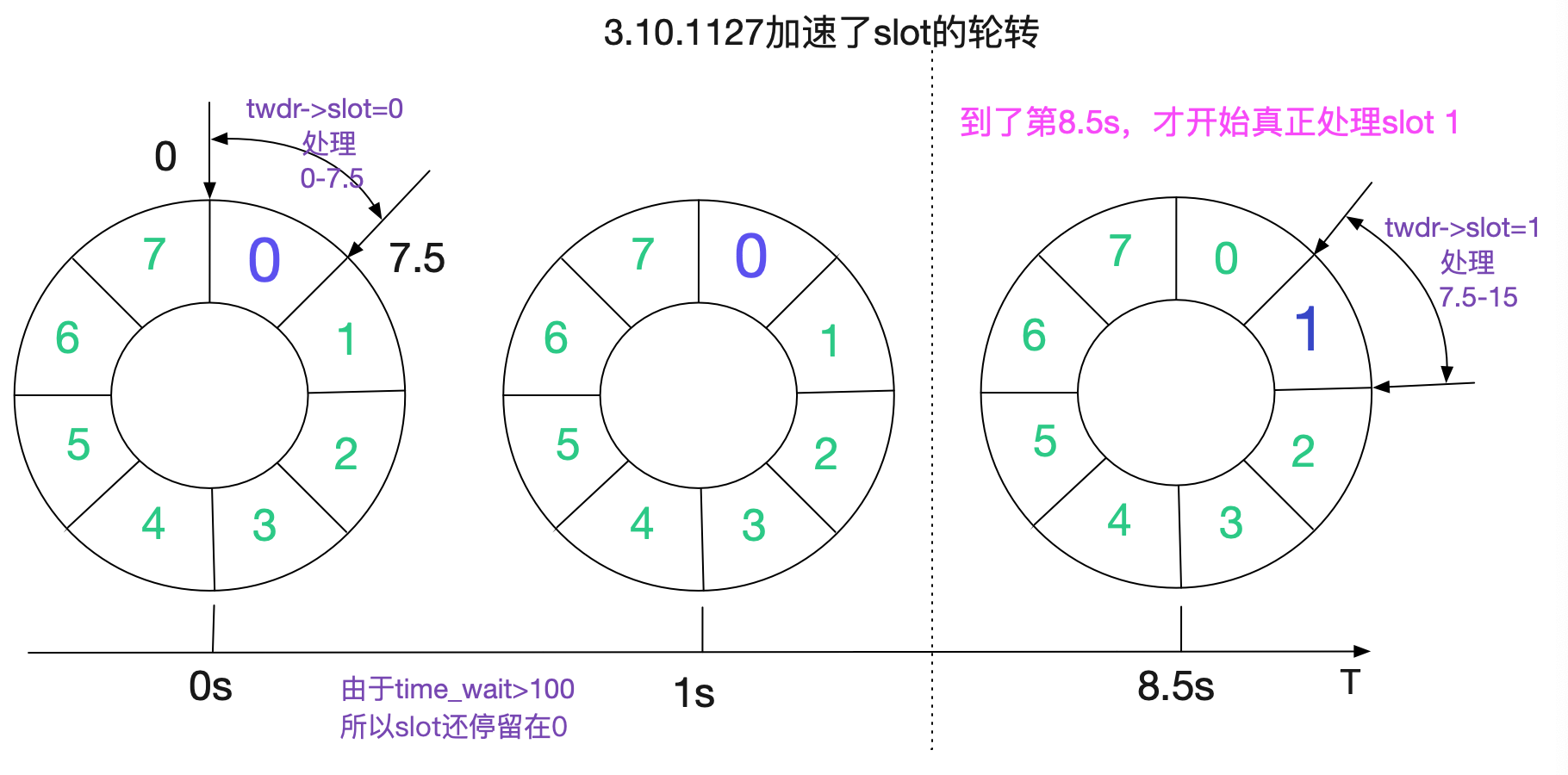
那么TIME_WAIT的存活时间就从112.5s下降到60.5s(计算公式8.5*7+1)。
那么,在这个状态下,我们的端口复用临界TPS就达到了(65535-2048)/60.5=1049tps,由于线上业务量并没有达到这一tps。所以对于新扩容的Nginx,并不会造成TIME_WAIT下的端口复用。所以错误量并没有变多!当然,由于旧Nginx的存在,错误量也没有变少。
但是,由于那个神奇的选择性负载均衡的存在,在端口复用时间越长,每秒钟的报错量会越少!直到LVS的表项全部指到新Nginx集群,就不会再有报错了!
TPS涨到1049tps依旧会报错
当然了,根据上面的计算,在TPS继续上涨到1049后,依旧会产生错误。新版本内核只不过拉高了临界值,所以笔者还是要寻求更加彻底的解决方案。
顺便吐槽一句
Linux TCP的实现对TIME_WAIT的处理用时间轮在笔者看来并不是什么高明的处理方式。
Linux本身对于Timer的处理本身就提供了红黑树这样的方案。放着这样好的方案不用,偏偏去实现一个精度不高还很复杂的时间轮。
所幸在Linux 4.x版本中,摈弃了时间轮,直接使用Linux本身的红黑树方案。感觉自然多了!
关闭tcp_timestamps
笔者一开始并不想修改这个参数,因为修改意味着关闭PAWS校验。要是真有个什么乱序包之类,就少了一层防御手段。但是事到如今,为了不让合作方修改,只能改这个参数了。不过由于是我们是专线!所以风险可控。
echo '0' > /proc/sys/net/ipv4/tcp_tw_max_bucket
运行至今,业务上反馈良好。终于,这个问题终于被解决了!!!!!!
补充一句,关闭tcp_timestamps只是笔者在种种限制下所做的选择,更好的方案应该是扩充源或者目的地址。
总结
解决这个问题真的是一波三折。在问题解决过程中,从LVS源码看到Linux 2.6内核对TIME_WAIT状态的处理,再到3.10内核和3.10.1127内核之间的细微区别。
为了解释所有的疑点,笔者始终在找寻着各种蛛丝马迹。虽然不追寻这些,问题依旧大概率能够通过各种尝试得到解决。但是,那些奇怪的曲线始终萦绕在笔者心头,让笔者日思夜想。然后,突然灵光乍现,找到线索后顿悟的那种感觉实在是太棒了!这也是笔者解决复杂问题源源不断的动力!
欢迎大家关注我公众号,里面有各种干货,还有大礼包相送哦!

解Bug之路-NAT引发的性能瓶颈的更多相关文章
- 解Bug之路-Nginx 502 Bad Gateway
解Bug之路-Nginx 502 Bad Gateway 前言 事实证明,读过Linux内核源码确实有很大的好处,尤其在处理问题的时刻.当你看到报错的那一瞬间,就能把现象/原因/以及解决方案一股脑的在 ...
- 解Bug之路-记一次存储故障的排查过程
解Bug之路-记一次存储故障的排查过程 高可用真是一丝细节都不得马虎.平时跑的好好的系统,在相应硬件出现故障时就会引发出潜在的Bug.偏偏这些故障在应用层的表现稀奇古怪,很难让人联想到是硬件出了问题, ...
- 解Bug之路-TCP粘包Bug
解Bug之路-TCP粘包Bug - 无毁的湖光-Al的个人空间 - 开源中国 https://my.oschina.net/alchemystar/blog/880659 解Bug之路-TCP粘包Bu ...
- 解Bug之路-记一次中间件导致的慢SQL排查过程
解Bug之路-记一次中间件导致的慢SQL排查过程 前言 最近发现线上出现一个奇葩的问题,这问题让笔者定位了好长时间,期间排查问题的过程还是挺有意思的,正好博客也好久不更新了,就以此为素材写出了本篇文章 ...
- 解Bug之路-记一次JVM堆外内存泄露Bug的查找
解Bug之路-记一次JVM堆外内存泄露Bug的查找 前言 JVM的堆外内存泄露的定位一直是个比较棘手的问题.此次的Bug查找从堆内内存的泄露反推出堆外内存,同时对物理内存的使用做了定量的分析,从而实锤 ...
- 解Bug之路-串包Bug
解Bug之路-串包Bug 笔者很热衷于解决Bug,同时比较擅长(网络/协议)部分,所以经常被唤去解决一些网络IO方面的Bug.现在就挑一个案例出来,写出分析思路,以飨读者,希望读者在以后的工作中能够少 ...
- 解Bug之路-记一次对端机器宕机后的tcp行为
解Bug之路-记一次对端机器宕机后的tcp行为 前言 机器一般过质保之后,就会因为各种各样的问题而宕机.而这一次的宕机,让笔者观察到了平常观察不到的tcp在对端宕机情况下的行为.经过详细跟踪分析原因之 ...
- 解Bug之路-记一次线上请求偶尔变慢的排查
解Bug之路-记一次线上请求偶尔变慢的排查 前言 最近解决了个比较棘手的问题,由于排查过程挺有意思,于是就以此为素材写出了本篇文章. Bug现场 这是一个偶发的性能问题.在每天几百万比交易请求中,平均 ...
- 解Bug之路-主从切换"未成功"?
解Bug之路-主从切换"未成功"? 前言 数据库主从切换是个非常有意思的话题.能够稳定的处理主从切换是保证业务连续性的必要条件.今天笔者就来讲讲主从切换过程中一个小小的问题. 故障 ...
随机推荐
- STM32之旅1——LED
STM32之旅1--LED 学习了51单片机后,就要接触到更高级一点的单片机了,比如STM32,ST也有很多款单片机,现在用比较基础的学习--STM32F103RCT6. LED驱动 hal库的使用比 ...
- FRP服务
FRP服务 - Web服务 本服务提供Web内网穿透服务,并且开放端口 443和 80端口. 写在前面:提供公益FRP服务器:frp.dev.boselor.com,服务器在洛杉矶但是请勿用于违法用途 ...
- es使用--新建、删除、增删改数据
# 进入bin目录 cd /czz/elsearch/bin # 后台启动(不加-d参数则是前台启动,日志在控制台) # 后台启动日志如果不配置,在es目录的logs下面 ./elasticsearc ...
- 持续集成工具之Jenkins使用配置
在上一篇博客中,我们主要介绍了DevOps理念以及java环境和jenkins的安装,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13805666.html: ...
- 多测师_git和github_004
git Git(读音为/gɪt/.),是目前世界上最先进的分布式版本控制系统,可以有效.高速的处理从很小到非常大的项目版本管理.Git 是 Linus Torvalds 为了帮助管理 Linux 内核 ...
- 从面试角度学完 Kafka
Kafka 是一个优秀的分布式消息中间件,许多系统中都会使用到 Kafka 来做消息通信.对分布式消息系统的了解和使用几乎成为一个后台开发人员必备的技能.今天码哥字节就从常见的 Kafka 面试题入手 ...
- PHP代码审计03之实例化任意对象漏洞
前言 根据红日安全写的文章,学习PHP代码审计的第三节内容,题目均来自PHP SECURITY CALENDAR 2017,讲完相关知识点,会用一道CTF题目来加深巩固.之前分别学习讲解了in_arr ...
- es6深层次数组深拷贝
let arr = [ { label: '1', children: [1, 2] } ] let a = [{...arr[0]}] ...
- spring boot:用cookie保存i18n信息避免每次请求时传递参数(spring boot 2.3.3)
一,用cookie保存i18n信息的优点? 当开发一个web项目(非api站)时,如果把i18n的选择信息保存到cookie, 则不需要在每次发送请求时都传递所选择语言的参数, 也不需要增加heade ...
- Flink on Yarn三部曲之二:部署和设置
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...