Codeforces Round #541 F. Asya And Kittens
题面:
题目描述:
题目分析:
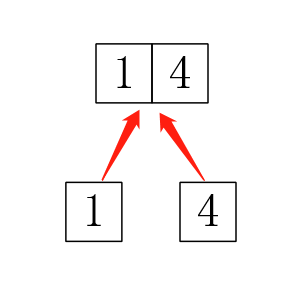
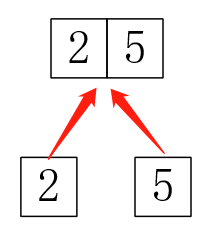
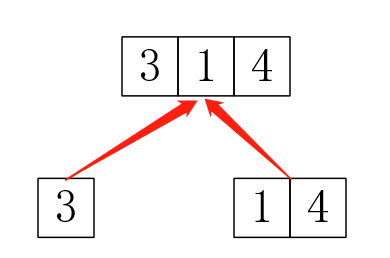
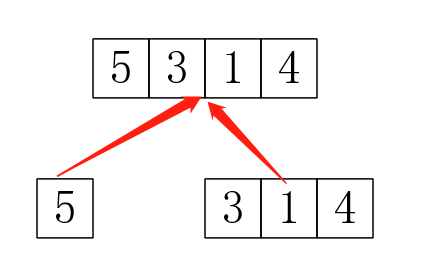
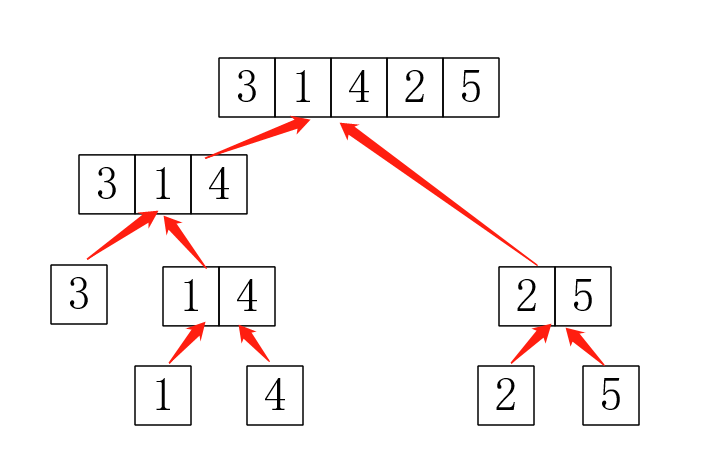
所以问题来了,第一:对于合并3,1我怎么知道是要合并3和1,4,而不是只合并3和1,把4抛弃?这时就要用到并查集,我们可以写一个并查集,查什么呢?当然是查在哪个隔间,然后把两个隔间合并。第二:这个好像只是模拟这个过程啊,怎样保存结果?其中一种做法就是给隔间分配额外的编号,把这个树(记得存树是存树的编号)存下来,然后用递归遍历一次就可以输出结果了(记得这时并查集查的是隔间的编号)。树:
1 #include <bits/stdc++.h> //万能头文件
2 using namespace std;
3 const int maxn = 150000 + 5;
4 int n;
5 int sets[2*maxn], L_node[2*maxn], R_node[2*maxn];
6
7 int F(int x){ //查
8 if(sets[x] == x || !sets[x]) return x;
9 return sets[x] = F(sets[x]);
10 }
11
12 void print(int x){ //输出答案
13 if(x <= n) printf("%d ", x);
14 else {
15 print(L_node[x]);
16 print(R_node[x]);
17 }
18 }
19
20 int main(){
21 cin >> n;
22 int id = n; //隔间编号
23 int x, y;
24 for(int i = 0; i < n-1; i++){
25 scanf("%d%d", &x, &y);
26 x = F(x); //查
27 y = F(y);
28 sets[x] = sets[y] = ++id; //并
29 L_node[id] = x; //记录在哪个隔间
30 R_node[id] = y;
31 }
32 print(id);
33 return 0;
34 }
大佬的代码:(好像用数组模拟链表实现)
1 #include <bits/stdc++.h> //万能头文件
2 using namespace std;
3 const int maxn = 150000 + 5;
4 int n;
5 int sets[maxn], G[maxn], last[maxn];
6
7 int F(int x){ //查
8 if(sets[x] == x) return x;
9 return sets[x] = F(sets[x]);
10 }
11
12 int main(){
13 cin >> n;
14 int x, y;
15
16 //初始化
17 for(int i = 1; i <= n; i++){
18 sets[i] = i;
19 last[i] = i;
20 }
21
22 for(int i = 0; i < n-1; i++){
23 scanf("%d%d", &x, &y);
24 x = F(x);
25 y = F(y);
26 G[last[x]] = y; //x的末尾一个元素接y
27 last[x] = last[y]; //x的末尾一个元素更新为y的末尾一个元素
28 sets[y] = x; //并, 且x为代表元
29 }
30
31 for(int i = F(1); i; i = G[i]){
32 scanf("%d ", i);
33 }
34 return 0;
35 }
Codeforces Round #541 F. Asya And Kittens的更多相关文章
- codeforces #541 F Asya And Kittens(并查集+输出路径)
F. Asya And Kittens Asya loves animals very much. Recently, she purchased nn kittens, enumerated the ...
- Codeforces #541 (Div2) - F. Asya And Kittens(并查集+链表)
Problem Codeforces #541 (Div2) - F. Asya And Kittens Time Limit: 2000 mSec Problem Description Inp ...
- Codeforces 1131 F. Asya And Kittens-双向链表(模拟或者STL list)+并查集(或者STL list的splice()函数)-对不起,我太菜了。。。 (Codeforces Round #541 (Div. 2))
F. Asya And Kittens time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- Codeforces Round #541 (Div. 2) D(并查集+拓扑排序) F (并查集)
D. Gourmet choice 链接:http://codeforces.com/contest/1131/problem/D 思路: = 的情况我们用并查集把他们扔到一个集合,然后根据 > ...
- Codeforces Round #541 (Div. 2) (A~F)
目录 Codeforces 1131 A.Sea Battle B.Draw! C.Birthday D.Gourmet choice(拓扑排序) E.String Multiplication(思路 ...
- Codeforces Round #541 (Div. 2)
Codeforces Round #541 (Div. 2) http://codeforces.com/contest/1131 A #include<bits/stdc++.h> us ...
- Codeforces Round #541
因为这次难得不在十点半(或是更晚),大家都在打,然后我又双叒叕垫底了=.= 自己对时间的分配,做题的方法和心态还是太蒻了,写的时候经常写一半推倒重来.还有也许不是自己写不出来,而是在开始写之前就觉得自 ...
- Educational Codeforces Round 40 F. Runner's Problem
Educational Codeforces Round 40 F. Runner's Problem 题意: 给一个$ 3 * m \(的矩阵,问从\)(2,1)$ 出发 走到 \((2,m)\) ...
- F. Asya And Kittens并查集
F. Asya And Kittens time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
随机推荐
- 导出Excel的异常处理
问题: 提示:"类 Range 的 Select 方法无效" 处理方法: 设置当前工作表 this.worksheet.Activate();
- 1.rabbitmq 集群安装及负载均衡设置
标题 : 1.rabbitmq 集群安装及负载均衡设置 目录 : RabbitMQ 序号 : 1 vim /etc/pam.d/login #对于64位系统,在文件中添加如下行 session req ...
- Java之先行发生原则与volatile关键字详解
volatile关键字可以说是Java虚拟机提供的最轻量级的同步机制,但是它并不容易完全被正确.完整地理解,以至于许多程序员都习惯不去使用它,遇到需要处理多线程数据竞争问题的时候一律使用synchro ...
- Java中的变量之成员变量、本地变量与类变量
Java中的变量: 1.成员变量(实例变量,属性) 2.本地变量(局部变量) 3.类变量(静态属性) 一.成员变量(实例变量,属性) 1.1-成员变量:(在类中定义, 访问修饰符 修饰符 ...
- postion:fixed和margin:0 auto的使用
很多同学将顶部菜单固定,使用postion:fixed,然后使用margin:0 auto进行居中,发现margin:0 auto并不起作用. 通常,我们要让某元素居中,会这样做: #element{ ...
- JWT All In One
JWT All In One OAuth 2.0 JWT JSON Web Tokens https://jwt.io refs https://www.cnblogs.com/xgqfrms/tag ...
- css & auto height & overflow: hidden;
css & auto height & overflow: hidden; {overflow: hidden; height: 100%;} is the panacea! {溢出: ...
- vue & watch props
vue & watch props bug OK watch: { // props // chatObj: () => { // // bug // log(`this.chatObj ...
- 如何通过NGK数字增益平台实现兑换算力
最近币圈里有一个新项目NGK非常火热,很多朋友在经过了了解以后纷纷表示很看好这个项目,那么除了二级市场之外,是否还能有其他的方式可以更低成本地获得NGK代币呢? 答案是肯定的,NGK数字增益平台便是低 ...
- 远程过程调用框架——gRPC
gRPC是一款基于http协议的远程过程调用(RPC)框架.出自google.这个框架可以用来相对简单的完成如跨进程service这样的需求开发. 资料参考: https://blog.csdn.ne ...