支持向量机SVM基本问题
1、SVM的原理是什么?
SVM是一种二类分类模型。它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器。(间隔最大是它有别于感知机)
试图寻找一个超平面来对样本分割,把样本中的正例和反例用超平面分开,并尽可能的使正例和反例之间的间隔最大。
支持向量机的基本思想可以概括为,首先通过非线性变换将输入空间变换到一个高维的空间,然后在这个新的空间求最优分类面即最大间隔分类面,而这种非线性变换是通过定义适当的内积核函数来实现的。SVM实际上是根据统计学习理论依照结构风险最小化的原则提出的,要求实现两个目的:
1)两类问题能够分开(经验风险最小)
2)margin最大化(风险上界最小)既是在保证风险最小的子集中选择经验风险最小的函数。
分为3类支持向量机:
(1)当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
(2)当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
(3)当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
注:以上各SVM的数学推导应该熟悉:硬间隔最大化(几何间隔)—学习的对偶问题—软间隔最大化(引入松弛变量)—非线性支持向量机(核技巧)。
2、SVM的主要特点
(1)非线性映射-理论基础 (2)最大化分类边界-方法核心 (3)支持向量-计算结果 (4)小样本学习方法
(5)最终的决策函数只有少量支持向量决定,避免了“维数灾难”
(6)少数支持向量决定最终结果—->可“剔除”大量冗余样本+算法简单+具有鲁棒性(体现在3个方面)
(7)学习问题可表示为凸优化问题—->全局最小值
(8)可自动通过最大化边界控制模型,但需要用户指定核函数类型和引入松弛变量
(9)适合于小样本,优秀泛化能力(因为结构风险最小) (10)泛化错误率低,分类速度快,结果易解释。
缺点:(1)大规模训练样本(m阶矩阵计算) (2)传统的不适合多分类 (3)对缺失数据、参数、核函数敏感
为什么SVM对缺失数据敏感?
这里说的缺失数据是指缺失某些特征数据,向量数据不完整。SVM没有处理缺失值的策略(决策树有)。而SVM希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失特征数据将影响训练结果的好坏。
3、SVM为什么采用间隔最大化?
当训练数据线性可分时,存在无穷个分离超平面可以将两类数据正确分开。感知机利用误分类最小策略,求得分离超平面,不过此时的解有无穷多个。
线性可分支持向量机利用间隔最大化求得最优分离超平面,这时,解是唯一的。另一方面,此时的分隔超平面所产生的分类结果是最鲁棒的,对未知实例的泛化能力最强。
然后应该借此阐述,几何间隔,函数间隔,及从函数间隔—>求解最小化1/2 ||w||^2 时的w和b。即线性可分支持向量机学习算法—最大间隔法的由来。
svm中最大化的什么,最小化的什么?
在各种对SVM的讲解中,有一个知识点都讲得不够透彻:SVM的目标函数是最大化支持向量的几何间隔,但怎么最后就变成了最小化法向量(斜率)了呢?
可以想像一下,一个超平面,斜率和截距以相同的倍数增大,这个超平面是不变的。也就是说,一个固定的超平面的参数却是不固定的。在我们求最优超平面时,解空间也就变成了无穷大。我们当然可以通过预先给这些参数设定一些约束来缩小解空间。那么,这个约束就是:令支持向量的函数间隔=1。
这个约束的优点有两方面: 在超平面都未确定的情况下,当然谁也不知道支持向量是哪些向量,支持向量的几何间隔也只有一个形式化表达,更别谈“最大化支持向量的几何间隔”该如何具体表达出来了。但有了以上约束,“支持向量的几何间隔”的表达中,谁是支持向量已经不重要了,唯一和样本相关的部分,也就是函数间隔,已变为了1. 其它样本的函数间隔要大于支持向量的函数间隔,这是唯一要满足的约束。此时,这个问题的解空间已经不是无穷大了,有了有意义的解空间。
支持向量回归 本质上跟SVM没什么关系,名字较易让人困惑。但libSVM里都加入了这个功能,不得不说一下。其实是求解一个线性回归问题,但由于对斜率增加了最小范数要求,最优化问题形式上和SVM很像,最后求出的线性函数表达式也跟SVM很像,出现了美妙的与支持向量的内积形式。
4、为什么要将求解SVM的原始问题转换为其对偶问题?
一、是对偶问题往往更易求解(当我们寻找约束存在时的最优点的时候,约束的存在虽然减小了需要搜寻的范围,但是却使问题变得更加复杂。为了使问题变得易于处理,我们的方法是把目标函数和约束全部融入一个新的函数,即拉格朗日函数,再通过这个函数来寻找最优点。)
Note:拉格朗日对偶没有改变最优解,但改变了算法复杂度:原问题—样本维度;对偶问题–样本数量。所以 线性分类—>样本维度<样本数量:原问题求解(liblinear默认); 非线性–升维—>一般导致 样本维度>样本数量:对偶问题求解。
二、自然引入核函数,进而推广到非线性分类问题。
5、解释支持向量
线性可分情况下的定义+线性不可分情况下的定义 。(统计学习方法)
(1)线性可分SVM对SV的几种等价定义 (2)线性SVM对SV的几种等价定义 (3)比较线性可分SVM的SV的定义和线性SVM对于SV定义之间的区别与联系
为什么SVM要引入核函数?
当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
引入映射后的对偶问题:
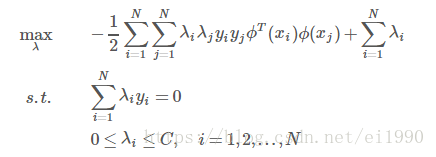
在学习预测中,只定义核函数K(x,y),而不是显式的定义映射函数ϕ。因为特征空间维数可能很高,甚至可能是无穷维,因此直接计算ϕ(x)·ϕ(y)是比较困难的。相反,直接计算K(x,y)比较容易(即直接在原来的低维空间中进行计算,而不需要显式地写出映射后的结果)。
核函数的定义:K(x,y)=<ϕ(x),ϕ(y)>,即在特征空间的内积等于它们在原始样本空间中通过核函数K计算的结果。
除了 SVM 之外,任何将计算表示为数据点的内积的方法,都可以使用核方法进行非线性扩展。
6、svm RBF核函数的具体公式?(高斯核函数,也叫做径向基函数(Radial Basis Function 简称RBF)。它能够把原始特征映射到无穷维)
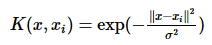
RBF核的优点 :
大小高低都适用。具体来说(1)无穷维,线性核是其特例 (2)与多项式~比,RBF需确定的参数少 (3)某些参数下,与sigmoid~有相似的功能。
Gauss径向基函数则是局部性强的核函数,其外推能力随着参数σ的增大而减弱。
这个核会将原始空间映射为无穷维空间。不过,如果 σ 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果 σ 选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数σ ,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。
7、SVM如何处理多分类问题?
一般有两种做法:一种是直接法,直接在目标函数上修改,将多个分类面的参数求解合并到一个最优化问题里面。看似简单但是计算量却非常的大。
另外一种做法是间接法:对训练器进行组合。其中比较典型的有一对一,和一对多。
一对多,就是对每个类都训练出一个分类器,由svm是二分类,所以将此二分类器的两类设定为目标类为一类,其余类为另外一类。这样针对k个类可以训练出k个分类器,当有一个新的样本来的时候,用这k个分类器来测试,那个分类器的概率高,那么这个样本就属于哪一类。这种方法效果不太好,bias比较高。
svm一对一法(one-vs-one),针对任意两个类训练出一个分类器,如果有k类,一共训练出C(2,k) 个分类器,这样当有一个新的样本要来的时候,用这C(2,k) 个分类器来测试,每当被判定属于某一类的时候,该类就加一,最后票数最多的类别被认定为该样本的类。
8、SVM与LR的区别与联系
联系:(1)分类(二分类) (2)可加入正则化项
区别:(1)LR–参数模型;SVM–非参数模型?(2)目标函数:LR—logistical loss;SVM–hinge loss (3)SVM–support vectors;LR–减少较远点的权重 (4)LR–模型简单,好理解,精度低,可能局部最优;SVM–理解、优化复杂,精度高,全局最优,转化为对偶问题—>简化模型和计算 (5)LR可以做的SVM可以做(线性可分),SVM能做的LR不一定能做(线性不可分)
核函数选取与feature、样本之间的关系 :
(1)fea大≈样本数量:LR or 线性核 (2)fea小,样本数量不大也不小:高斯核 (3)fea大,样本数量多:手工添加特征后转
Kernel函数实际上是输入数据的相似性度量,输入向量组成一个相似度矩阵K(Gram Matrix/Similarity/Kernel Matrix),K是对称半正定的。
K(x,z)是正定核的充要条件是:K(x,z)对应的Gram矩阵实半正定矩阵。
Gram矩阵:矩阵对应点的内积。KTK, KKT
半正定矩阵:设A是实对称矩阵。如果对任意的实非零列矩阵X有XTAX≥0,就称A为半正定矩阵。
当检验一个K是否为正定核函数,要对任意有限输入集{xi…}验证K对应的Gram矩阵实是否为半正定矩阵。
9、SVM是用的是哪个库?Sklearn/libsvm中的SVM都有什么参数可以调节?
用的是sklearn实现的。采用sklearn.svm.SVC设置的参数。本身这个函数也是基于libsvm实现的(PS: libsvm中的二次规划问题的解决算法是SMO)。
SVC函数的训练时间是随训练样本平方级增长,所以不适合超过10000的样本。
对于多分类问题,SVC采用的是one-vs-one投票机制,需要两两类别建立分类器,训练时间可能比较长。
sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
参数:
l C:C-SVC的惩罚参数C?默认值是1.0
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
l kernel :核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
0 – 线性:u’v
1 – 多项式:(gamma*u’*v + coef0)^degree
2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(gamma*u’*v + coef0)
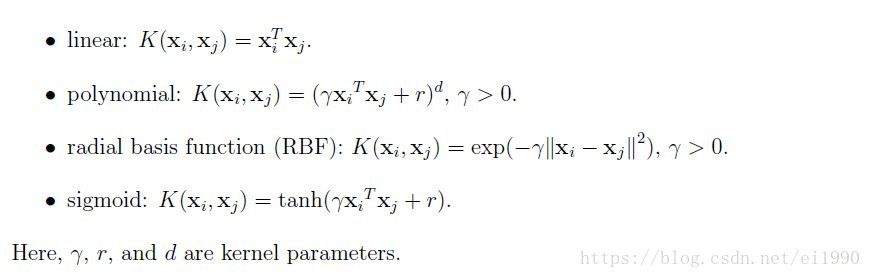
首先介绍下与核函数相对应的参数:
1)对于线性核函数,没有专门需要设置的参数
2)对于多项式核函数,有三个参数。-d用来设置多项式核函数的最高此项次数,也就是公式中的d,默认值是3。-g用来设置核函数中的gamma参数设置,也就是公式中的第一个r(gamma),默认值是1/k(k是类别数)。-r用来设置核函数中的coef0,也就是公式中的第二个r,默认值是0。
3)对于RBF核函数,有一个参数。-g用来设置核函数中的gamma参数设置,也就是公式中的第一个r(gamma),默认值是1/k(k是类别数)。
4)对于sigmoid核函数,有两个参数。-g用来设置核函数中的gamma参数设置,也就是公式中的第一个r(gamma),默认值是1/k(k是类别数)。-r用来设置核函数中的coef0,也就是公式中的第二个r,默认值是0。
l degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
l gamma : ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
l coef0 :核函数的常数项。对于‘poly’和 ‘sigmoid’有用。
l probability :是否采用概率估计?.默认为False
l shrinking :是否采用shrinking heuristic方法,默认为true
l tol :停止训练的误差值大小,默认为1e-3
l cache_size :核函数cache缓存大小,默认为200
l class_weight :类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
l verbose :允许冗余输出?
l max_iter :最大迭代次数。-1为无限制。
l decision_function_shape :‘ovo’, ‘ovr’ or None, default=None3
l random_state :数据洗牌时的种子值,int值
主要调节的参数有:C、kernel、degree、gamma、coef0。
10、SMO算法实现SVM
基本思想:将大优化的问题分解成多个小优化问题,这些小问题往往比较容易求解,并且对他们进行顺序求解的结果与他们作为整体来求解的结果完全一致。
过程:

问题:

转载来源 https://www.cnblogs.com/eilearn/p/8989960.html
支持向量机SVM基本问题的更多相关文章
- 【IUML】支持向量机SVM
从1995年Vapnik等人提出一种机器学习的新方法支持向量机(SVM)之后,支持向量机成为继人工神经网络之后又一研究热点,国内外研究都很多.支持向量机方法是建立在统计学习理论的VC维理论和结构风险最 ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
- 机器学习算法 - 支持向量机SVM
在上两节中,我们讲解了机器学习的决策树和k-近邻算法,本节我们讲解另外一种分类算法:支持向量机SVM. SVM是迄今为止最好使用的分类器之一,它可以不加修改即可直接使用,从而得到低错误率的结果. [案 ...
- 机器学习之支持向量机—SVM原理代码实现
支持向量机—SVM原理代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9596898.html 1. 解决 ...
- 支持向量机SVM——专治线性不可分
SVM原理 线性可分与线性不可分 线性可分 线性不可分-------[无论用哪条直线都无法将女生情绪正确分类] SVM的核函数可以帮助我们: 假设‘开心’是轻飘飘的,“不开心”是沉重的 将三维视图还原 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学支持向量机SVM算法之理论篇1
一步步教你轻松学支持向量机SVM算法之理论篇1 (白宁超 2018年10月22日10:03:35) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- OpenCV 学习笔记 07 支持向量机SVM(flag)
1 SVM 基本概念 本章节主要从文字层面来概括性理解 SVM. 支持向量机(support vector machine,简SVM)是二类分类模型. 在机器学习中,它在分类与回归分析中分析数据的监督 ...
随机推荐
- python血脉贲张的cosplay小姐姐图片
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 基本环境配置 python 3.6 pycharm requests 相关模块pip安装即可 ...
- vue学习06 v-show指令
目录 vue学习06 v-show指令 v-show指令是:根据真假切换元素的显示状态 原理是修改元素的display,实现显示隐藏 指令后面的内容,最终都会解析为布尔值(true和false) 练习 ...
- 注解在Spring中的运用(对象获取、对象单例/多例、值的注入、初始化/销毁方法、获取容器)
1.注解的方式获取对象 (1)导包: (2)书写配置文件(要保证已经导入了约束): <?xml version="1.0" encoding="UTF-8" ...
- 每日一个知识点:Volatile 和 CAS 的弊端之总线风暴
每日一个知识点系列的目的是针对某一个知识点进行概括性总结,可在一分钟内完成知识点的阅读理解,此处不涉及详细的原理性解读. 一.什么是总线风暴 总线风暴,听着真是一个帅气的词语,但如果发生在你的系统上那 ...
- Spring Environment对象获取属性
String[] activeProfiles = env.getActiveProfiles();//获取当前是启用哪一个个配置文件 System.out.println(Arrays.toStri ...
- Flutter 1.22 正式发布
支持iOS 14和Android 11,新的i18n和l10n支持,可用于生产的Google Maps和WebView插件,新的App Size工具等等! 作者:Chris Sells 原文:http ...
- shell-逻辑操作符讲解与文件条件测试多范例多生产案例
1. 逻辑操作符 在书写测试表达式时,可以使用表1.1中的逻辑操作符实现复杂的条件测试 表1.1逻辑连接符 提示: ! 中文意思是反:与一个逻辑值相反的逻辑值 -a 中文意思是与(and & ...
- android的adb命令整理
adb.exe的路径在Android\Sdk\platform-tools 把这个路径加入到系统的path环境下. 先用usb连接设备,比如一台android手机 adb tcpip 5555 adb ...
- 多测师讲解selenium_alert弹框定位_高级讲师肖sir
from selenium import webdriverfrom time import sleepdrvier=webdriver.Chrome()url=r'F:\dcs\DCS课程安排\se ...
- 多测师讲解python练习题_100以内奇数,偶数的和_高级讲师肖sir
(1)通过while 循环来求出1-100之和'''(2)通过while 循环来求出1-100奇数之和'''(3)通过while 循环来求出1-100偶数之和''' 奇数和 sum1=0for i i ...