In-Memory:Hash Index
SQL Server 2016支持哈希查找,用户可以在内存优化表(Memory-Optimized Table)上创建哈希索引(Hash Index),使用Hash 查找算法,实现数据的极速查找。在使用上,Hash Index 和B-Tree索引的区别是:Hash Index 是无序查找,Index Key必须全部作为查找的条件,多个键值之间是逻辑与关系,并且只能执行等值查找,而B-Tree索引是有序查找,不需要Index Key都作为查找,只需要前序字段都存在,还可以进行大于、小于、等于等比较操作;在存储结构上,Hash Index使用Hash Table实现,存在Hash 冲突,而B-Tree索引的结构是B-Tree结构,存在页拆分和索引碎片等问题。
一,Hash 查找算法
在《数据结构》课程中,Hash查找的算法是:以关键字k为自变量,通过一个映射函数h,计算出对应的函数值y=h(k)(y称作哈希值,或哈希地址),根据函数值y,将关键字k存储在数组(bucket数组)所指向的链表中。在进行哈希查找时,根据关键字,使用相同的函数h计算哈希地址h(k),然后直接寻址相应的Hash bucket,直接到对应的链表中取出数据。因此,Hash 查找算法的数据结构由Hash Bucket数组,映射函数f和数据链表组成,通常将Bucket数组和数据链表称作Hash Table,如图,Hash Table由5个buckets和7个数据结点组成:

哈希查找的时间复杂度是O(n/m),n是指数据结点的数量,m是bucket的数量,在理想情况下,Hash Bucket足够多,Hash函数不产生重复的Hash Value,哈希查找的时间复杂度最优到达O(1),但是,在实际应用中,哈希函数有一定的几率出现重复的哈希地址,产生哈希冲突,时间复杂度会低于O(n/m);在最差的情况下,时间复杂度是O(n)。
二,Hash Index的结构
Hash Index使用Hash查找算法实现,SQL Server内置Hash函数,用于所有的Hash Index,因此,Hash Index就是Hash Table,由Hash Buckets数组和数据行链表组成。创建Hash Index时,通过Hash函数计算Index Key的Hash地址,Hash地址不同的数据行指向不同的Bucket,Hash地址相同的数据行指向相同的Bucket,如果多个数据行的Hash地址相同,都指向同一个Bucket,那么将这些数据行链接在一起,组成一个链表。
A hash index consists of an array of pointers, and each element of the array is called a hash bucket. The index key column in each row has a hash function applied to it, and the result of the function determines which bucket is used for that row. All key values that hash to the same value (have the same result from the hash function) are accessed from the same pointer in the hash index and are linked together in a chain. When a row is added to the table, the hash function is applied to the index key value in the row. If there is duplication of key values, the duplicates will always generate the same function result and thus will always be in the same chain.
举例说明,假定哈希函数是h(k)=Length(k),用于计算Index Key的字符个数,在内存优化表(Name,City)上创建Hash Index,Index ptr指向链表中的下一个数据行,如果没有下一个数据行,那么该指针为NULL:

1,以Name为Index Key创建Hash Index
第一个数据行的Name是“Jane”,HashValue是4,将该行数据映射到下标为4的Bucket中(Bucket数组的第五个元素),由于该数据行是第一个数据结点,Index ptr为NULL。
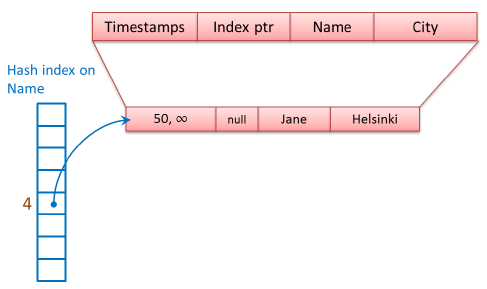
第二个数据行,Name值是“Greg”,HashValue是4,映射到下标为4的Bucket中,和第一个数据行链接在一起,组成一个链表(Chain),插入数据结点时,使用头部插入法,新的数据节点作为头结点,将头节点的Index ptr(next pointer)指针指向数据链表的第一个数据结点,如图,新的头结点“Greg”的Index ptr指向第一个数据行“Jane”。
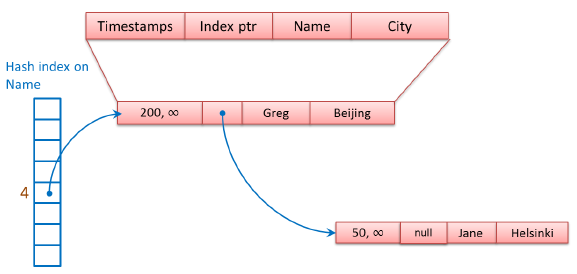
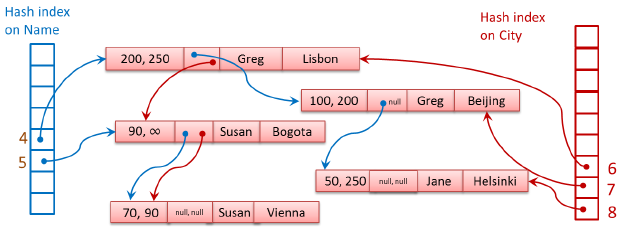
2,创建第二个Hash Index,以City为Index Key
当创建第二个Hash Index时,每个数据行结构中包含两个Index ptr指针,都用于指向下一个数据节点(Next Pointer):第一个Index ptr用于Index Key为Name的Hash Index,当出现相同的Hash Value时,该指针指向链表中下一个数据行,使数据行链接到一起组成链表;第二个Index ptr用于Index Key为City的Hash Index,指向链表中下一个数据行。
因此,当创建一个新的Hash Index时,在数据结构上,SQL Server需要创建Hash Buckets数组,并在每个数据行中增加一个Index ptr字段,根据Index Key为Index ptr赋值,组成一个新数据行链表,但是数据行的数量保持不变。
3,Hash 函数
在创建Hash Index时,不需要编写Hash 函数,SQL Server内置Hash函数:
- 内置的Hash函数产生的HashValue是随机和不可预测的,适用于所有的Hash Index;
- 内置的Hash函数是确定性的,相同的Index Key总是映射到相同的Bucket;
- 有一定的几率,多个Index Key会映射到相同的bucket中;
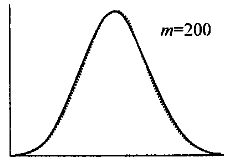
- 哈希函数是均衡的,产生的Hash Value服从泊松分布;
泊松分布不是均匀分布,Index Key不是均匀地分布在Hash bucket数组中。例如,有n个Hash Bucket,n个不同的Index Key,泊松分布产生的结果是:大约有1/3的Hash Bucket是空的,大约1/3的Hash bucket存储一个Index Key,剩下1/3的Hash Buckets存储2个Index Key。
4,Hash Index的链表长度
不同的Index Key,经过hash函数映射之后,可能生成相同的Hash Value,映射到相同的bucket中,产生 Hash 冲突。Hash算法,将映射到相同Bucket的多个Index Key组成一个链表,链表越长,Hash Index查找性能越差。
在DMV:sys.dm_db_xtp_hash_index_stats (Transact-SQL)中,表示Hash Index链长的字段有:avg_chain_length 和 max_chain_length ,链长应保持在2左右;链长过大,表明太多的数据行被映射到相同的Bucket中,这会显著影响Hash Index的查询性能,导致链长过大的原因是:
- 总的Bucket数量少,导致不同的Index Key映射到相同的Bucket上;
- 如果空的Bucket数量大,但链长过大,这说明,Hash Index存在大量重复的Index Key;相同的Index Key被映射到相同的bucket;
三,创建Hash Index
在内存优化表上创建Index,不能使用Create Index命令,SQL Server 2016支持两种方式创建索引:
1,在创建内存优化表时创建Hash Index
创建Hash Index的语法是:
INDEX index_name [ NONCLUSTERED ] HASH WITH (BUCKET_COUNT = bucket_count)
创建Hash Index的示例:
--create memory optimized table
create table [dbo].[products]
(
[ProductID] [bigint] not null,
[Name] [varchar](64) not null,
[Price] decimal(10,2) not null,
[Unit] varchar(16) not null,
[Description] [varchar](max) null,
constraint [PK__Products_ProductID] primary key nonclustered hash ([ProductID])with (bucket_count=2000000)
,index idx_Products_Price nonclustered([Price] desc)
,index idx_Products_Unit nonclustered hash(Unit) with(bucket_count=40000)
)
with(memory_optimized=on,durability= schema_and_data)
go
2,使用Alter Table命令创建Hash Index
alter table [dbo].[products]
add index hash_idx_Products_Name nonclustered hash(name)with(bucket_count=40000);
四,Hash Index的特点
总结Hash Index的特点:
- Hash Index使用Hash Table组织Index 结构,每一个数据节点都包含一个指针,指向数据行的内存地址;
- Hash Index是无序的,适合做单个数据行的Index Seek;
- 只有当Hash Index Key全部出现在Filter中,SQL Server才会使用Hash Index Seek操作查找相应的数据行,如果缺失任意一个Index Column,那么SQL Server都会执行Full Table Scan以获取符合条件的数据行。例如,创建Hash Index时指定N个column,那么SQL Server对这N个column计算Hash Value,映射到相应的bucket上,所以,只有当这N个Column都存在时,才能定位到对应的bucket,进而查找相应的数据结点;
参考文档:
Guidelines for Using Indexes on Memory-Optimized Tables
Troubleshooting Common Performance Problems with Memory-Optimized Hash Indexes
In-Memory:Hash Index的更多相关文章
- adaptive hash index
An optimization for InnoDB tables that can speed up lookups using = and IN operators, by constructin ...
- 【mysql】Innodb三大特性之adaptive hash index
1.Adaptive Hash Indexes 定义 If a table fits almost entirely in main memory, the fastest way to perfor ...
- only for equality comparisons Hash Index Characteristics
http://dev.mysql.com/doc/refman/5.7/en/index-btree-hash.html Hash Index Characteristics Hash indexes ...
- Redis学习笔记(五) 基本命令:Hash操作
原文链接:http://doc.redisfans.com/hash/index.html 学习前先明确一下概念,这里我们把Redis的key称作key(键),把数据结构hash中的key称为fiel ...
- insert buffer/change buffer double write buffer,双写 adaptive hash index(AHI) innodb的crash recovery innodb重要参数 innodb监控
https://yq.aliyun.com/articles/41000 http://blog.itpub.net/22664653/viewspace-1163838/ http://www.cn ...
- 自适应哈希索引(Adaptive Hash Index, AHI) 转
Adaptive Hash Index, AHI 场景 比如我们每次从辅助索引查询到对应记录的主键,然后还要用主键作为search key去搜索主键B+tree才能找到记录. 当这种搜索变多了,inn ...
- ArcEngine 异常 :The index passed was not within the valid range.
pRowBuffer.set_Value(pFds.FindField("W_Mean"), Re_mean[3]); 此句代码弹出异常:The index passed was ...
- 14.4.3 Adaptive Hash Index 自适应hash index
14.4.3 Adaptive Hash Index 自适应hash index 自适应hash index(AHI) 让InnoDB 执行更像内存数据库在系统使用合适的负载组合和足够的内存用于Buf ...
- Vue的路由实现:hash模式 和 history模式
hash模式:在浏览器中符号“#”,#以及#后面的字符称之为hash,用 window.location.hash 读取.特点:hash虽然在URL中,但不被包括在HTTP请求中:用来指导浏览器动作, ...
随机推荐
- 使用WITH AS 的ROW_NUMBER分页
WITH tempTable AS( --复杂查询语句) SELECT * FROM (select ROW_NUMBER() Over( order by xxx) as rowNum, ...
- IllegalStateException
例1 public static void main(String[]sdf){ List<String> list = new ArrayList<String>(); li ...
- button 禁止
1.按钮的id为btnzhuce==> 控制按钮为禁用: $("#btnzhuce").attr({"disabled":"disabled& ...
- AFNetworking 与 NSURLSession
转载自:http://blog.sina.com.cn/s/blog_8157560c0101kt7h.html 1. 也就是说在IOS 7.1 之后你想用网络请求的话有两种途径,NSUrlSessi ...
- apt-get &dpkg
apt-get是ubuntu常用的软件安装工具.他可以很easy的从互联网上下载软件安装包,并实现安装. apt-get比较常用的命令如下: apt-get install packagename ...
- android 工具类之图片加工
/** * 图片加工厂 * * @author way * */ public class ImageUtil { /** * 通过路径获取输入流 * * @param path * 路径 * @re ...
- vtk点云数据的显示[转]
#include "vtkActor.h" #include "vtkRenderer.h" #include "vtkRenderWindow.h& ...
- ags js下载地址
https://developers.arcgis.com/en/downloads/ 备用
- OpenCV 图像处理学习笔记(一)
解读IplImage结构 typedef struct _IplImage { int nSize; /* IplImage大小 */ int ID; ...
- IPv6 相关的工作简介
这里说明下,仅仅是IPv6在开发板上的相关的工作简介,没有很详细,都是自己一边积累,一边实践的.能帮助其他人最好,也算是给自己做个备忘录. 一.首先说下DHCPv6相关的.这里我使用的是DHCP6s. ...