【论文阅读】Where Is My Mirror?
Where Is My Mirror?(ICCV2019收录)
作者:

论文链接: https://arxiv.org/pdf/1908.09101.pdf
1. 研究背景
目前存在的计算机视觉任务都没有考虑镜像的问题,而在实际中由于镜像反射内容的混淆,极易导致性能下降。如图1所示,通常会造成(b)图错误的深度估计。(c)图中Mask RCNN错误的分割镜像中的反射物体。
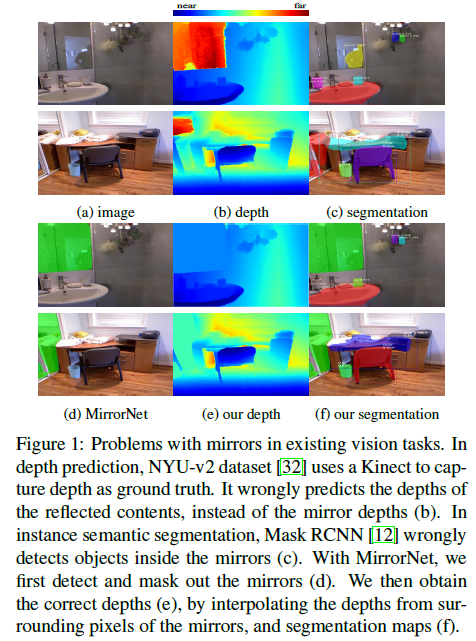
将镜像外部的真实内容与镜像内部的反射内容分离开来并不容易。关键的挑战在于,镜像通常会反射与其周围环境相似的内容,这使得区分两者非常困难。
2.贡献点
1.构建了第一个大规模的镜像数据集mirror segmentation dataset (MSD),其中包含取自不同的日常生活场景的4018张图片,包括镜像图片和对应的手工标注的镜像掩码。
2.提出了一种新的基于上下文对比特征提取模块的镜像分割网络,通过学习对镜像内外的上下文对比进行建模。
3.通过大量的实验,证明了所提出的网络优于许多从最先进的分割/检测方法得到的baseline。
3.方法细节
3.1 设计思想
研究人员观察到,人们识别镜像中的内容,通常会从边界入手,观察其不连续性。因此,这个问题的一个直接的解决方案,是应用低层次的特征,比如颜色和纹理变化,来检测镜像边界。但是如果一个镜像前面有物体遮挡,如图1中(c)图第二行所示,这个方法就无法检测出完整的边缘,从而实现精确的分割。因此,结合低层次的特征和高层次的语义信息进行分割是很有必要的。
3.2 数据集MSD
使用手机拍摄图像以及利用标注工具Labelme进行手工标注。数据集包含室内场景图像3677张和从室外场景图像341张,主要从日常生活场景例如卧室,客厅,办公室,花园,街道,停车场中获取镜像图像。因为本文研究重点在于室内图像,因此室内图像数量多于室外图像,室外图像主要是为了提供更多样的镜面形状和场景。最终将数据集分为训练集3063张,测试集955张。图2给出了该镜像分割数据集的一些示例。

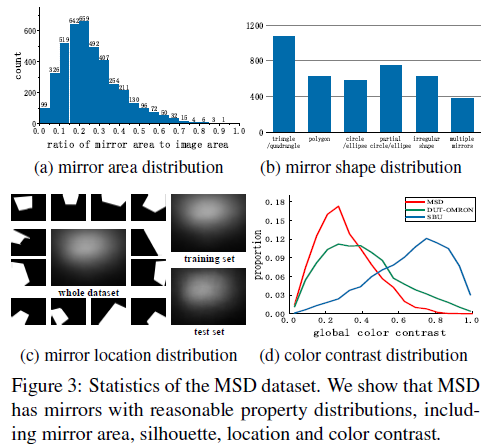
图3展示了对捕获的图像中镜像属性的统计分析(包括镜像区域、形状、在图像中的位置,以及镜像内外之间的全局颜色对比度)。图(a)是镜像区域的分布,将镜像区域与图片区域相比得到镜像区域的比例,统计数据显示大部分镜像比例在0到0.7之间。由于比例在0.95到1之间的镜像人类也无法较好的分辨,因此这部分数据集被舍弃。(b)图列出了镜像的多种形状。(c)图是镜像位置的分布,镜像大多会分布在图像的顶部区域,这与人类使用镜子的习惯一致。(d)图表明该镜像数据集的图像对比度相较于另外两个数据集更低,具有更大的分割挑战性。
3.3 实现细节
利用人类观察镜像的特性,即使用内容的不连续性,比如低层次的颜色/纹理变化以及高层次的语义信息。本文利用镜像和非镜像区域之间的对比特性来进行镜像分割。在文中作者提出了一种新的语境对比特征提取块(CCFE),用于提取镜像位置的多尺度上下文对比特征。
图4是本文分割镜像网络MirrorNet的结构图。它以单个图像为输入,通过预训练的特征提取网络(FEN)提取多层特征,这里FEN使用ResNeXt101。然后,将高层次的语义特征输入到CCFE模块中,通过检测出现对比的分界,学习上下文对比特征,从而用最粗的镜像映射定位镜像。该镜像映射作为注意映射,抑制非镜像区域的下一层FEN feature的特征噪声,使下一层能够集中学习候选镜像区域的特征。通过这种方式,MirrorNet逐步利用上下文对比信息,从粗到精地细化镜像区域。最后,对最粗的网络输出进行上采样,得到原始图像的分辨率作为输出。

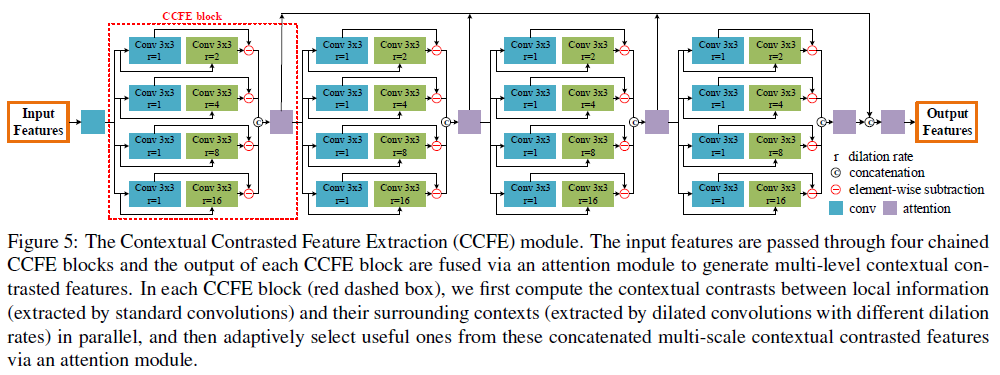
图5是上下文对比特征提取模块(CCFE)的结构图。在通过FEN提取特征之后,该模块的目的是生成多尺度的上下文对比特征来检测不同尺寸的反射镜像。在局部区域与它的周围区域设计了CCFE块进行上下文对比特征的学习,如公式1所示。其中F是输入特征,f_local是膨胀率为1的3×3的卷积,用来提取局部区域的特征;f_context是膨胀率为x的3×3的卷积,用来提取其周围区域的特征。在图5中可看到,蓝色的卷积块就是提取局部区域特征的卷积,而绿色卷积块则是提取其周围区域特征的卷积,实际设置膨胀率为2,4,8,16,将对应二者相减得到多尺度的上下文对比特征。经过attention模块再级联多个CCFE块得到最终的输出特征。这里的attention模块用的是ECCV2018论文《CBAM: Convolutional Block Attention Module》中的注意力模块。
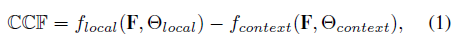
3.4 损失函数
损失函数是将s个最终上采样的mirror map和ground truth进行损失计算得到的。这里的Ls使用的是lovasz-hinge loss,来自CVPR2018的论文《The Lovasz-Softmax loss-A tractable surrogate for the optimization of the intersection-over-union measure in neural network》,该文证明该损失比传统的分割损失BCE更好。
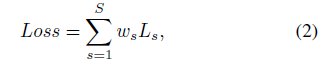
4. 实验结果
在自制的镜像分割数据集MSD上的对比实验结果如表1所示。在表1中,PSPNet、ICNet是语义分割算法,Mask RCNN是实例分割算法,DSS、PiCANet、RAS、R^3Net w/o C、R^3Net是显著性目标检测算法,DSC、BDRAR w/o C、BDRAR是阴影检测算法。评价标准中使用语义分割领域的IoU,Acc准则作为第一和第二标准。另外,还使用了显著性目标检测领域的F-meature和MAE指标以及阴影检测领域的BER指标。其中最好的结果加粗显示,次好的结果标红显示。结果显示使用了CRF后处理的MirrorNet获得了最好的分割效果。
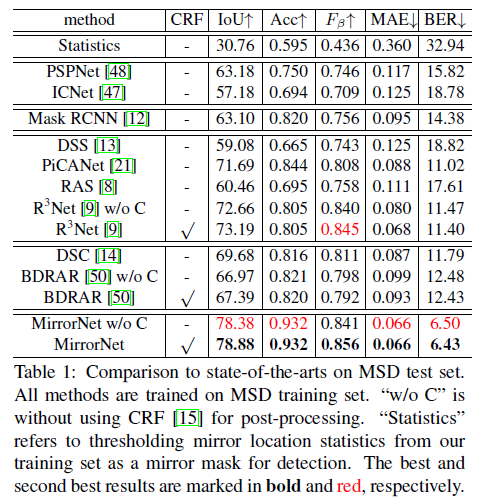
图6是对比结果的可视化。在第4,5,7行可以看到该方法有效的定位和分割出小物体;第1,3行将镜子区域检测为一个整体;第2行将镜子前的遮挡物正确分割开。

在额外的数据集ADE20K上验证了该方法的泛化性,一些分割结果的示例可以在图7中看到。同时,图8中也展示了一些对网上下载的具有很大挑战性图片的分割结果。这些图像不仅包含镜子,还包括其他类似镜子的物体,如绘画(第二,第三和六行),窗户(第五行),门(第四行)。然而我们可以从分割结果中看出,该方法有效的将这些物体与镜子分割开来。


消融实验的结果在表2中给出,验证了lovasz-hinge loss和提出的CCFE模块的有效性。图9是其可视化的对应结果。

由于本文方法依赖于对输入图像中呈现的上下文对比进行建模,所以在某些极端场景中,当镜子和周围环境之间的上下文对比不足时,它往往会失败,如图10所示。

【论文阅读】Where Is My Mirror?的更多相关文章
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline
论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline 如上图所示,本文旨在解决一个问题:给定一张图像, ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
随机推荐
- <编译原理 - 函数绘图语言解释器(1)词法分析器 - python>
<编译原理 - 函数绘图语言解释器(1)词法分析器 - python> 背景 编译原理上机实现一个对函数绘图语言的解释器 - 用除C外的不同种语言实现 解释器分为三个实现块: 词法分析器: ...
- 史上最详细的IDEA优雅整合Maven+SSM框架(详细思路+附带源码)
目录 前言: 1. 搭建整合环境 2.Spring框架代码的编写 3.SpringMVC框架代码的编写 4. Spring整合SpringMVC的框架 5.MyBatis框架代码的编写 6. Spri ...
- VuforiaAR 教程
Vuforia AR不仅可以识别图片也可以识别三维物体 直接上步骤: 1)开发环境 unity2017直接集成了Vuforia AR开发环境,不过在安装时要选择此项,也可以后续去unity官网下载相 ...
- Day 3,学习的知识点
年龄 如何判断是否未成年人 age = input('请输入你的年龄:')#input=输入age = int(age)#int=转化为整型if age < 18: print('小妹妹你 ...
- R.Swift优雅加载资源文件
在新的项目中,接触到了一个很不错的框架R.swift,可以帮助更方便安全的使用资源文件,相信已经使用过的或者还没有接触过的,一旦使用过了解过它,会爱上这个框架工具! 一.R.swift特点 当项目bu ...
- 关于ReentrantLock 中的lockInterruptibly方法的简单探究
今天在看Lock,都知道相比于synchronized,多了公平锁,可中断等优秀性能. 但是说到可中断这个特点,看到很多博客是这么描述的: “与synchronized关键字不同,获取到锁的线程能够响 ...
- Web for pentester_writeup之XML attacks篇
Web for pentester_writeup之XML attacks篇 XML attacks(XML攻击) Example 1 - XML外部实体注入(XXE) Payload http:// ...
- 学习笔记60_python面向对象
**** //可以给函数参数设置默认值 def stu_register(name,age,course,country="CN"): 若你的函数在定义时不确定用户想传入多少个参数 ...
- Ubuntu18.04 安装MySQL(Linux)解决登陆权限问题及Navicat for mysql 中文乱码问题
一.MySQL(Linux)解决登陆权限问题 Ubuntu18.04 安装mysql或者mariadb之后,发现普通用户和远程都没有权限连接. ERROR 1045: Access denied fo ...
- python中生成器及迭代器
列表生成式 列表生成式是python内部用来创建list的一种方法,其格式形如: L = [x*8 for x in range(10)] print(L) 此时会得到结果:[0, 8, 16, 24 ...