python-函数相关
目录:
一.三元运算
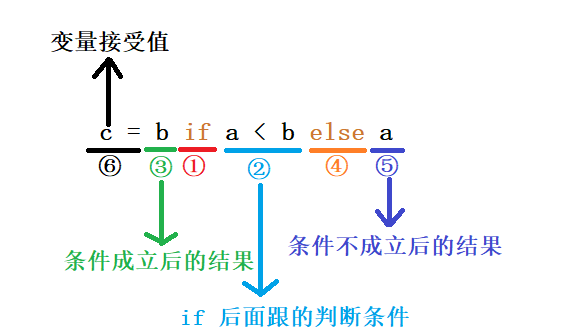
a = 1
b = 2
if a < b :
c = b
else:
c = a
这样写代码非常繁琐,所以在遇到if else非常简单的时候,可以用到三元运算
a = 1
b = 2
c = b if a < b else a
①---⑥表示写三元运算时候的流程
二.函数:
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。
但你也可以自己创建函数,这被叫做用户自定义函数。
定义函数规则:
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
函数内容以冒号起始,并且缩进。
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None
函数定义示例:
def 函数名(参数1,参数2):
'''
这是一个解决什么问题的函数
:param 参数1: 参数1代表输入什么
:param 参数2: 参数2代表输入什么
:return: 返回什么东西
'''
函数体
返回值
return 返回值
例如定义计算字符串长度的函数:
def my_len(my_str): #定义函数
'''
用于计算可变类型长度的函数
:param my_str: 用户输入的参数内容
:return:返回参数的长度
'''
count = 0
for val in my_str:
count += 1
return count
a = my_len("hightgood")
print(a) #输出值9
定义一个函数后,尽量不要用print,尽量return结果
自己是可以知道函数代码内部打印的是啥,自己可以随时修改,但是别人不知道
函数中的return:
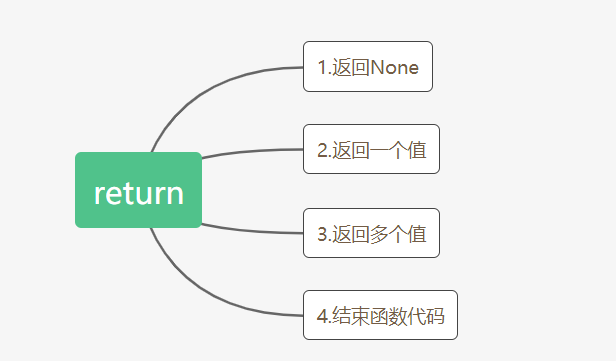
1.返回None
有三种情况:
(1)无return的情况
(2)本来就return None
(3)return #return空白
#无return
def my_print(parameter):
print("Welcome",parameter)
#return None
def my_print(parameter):
return None
#return
def my_print(parameter):
return #一般用于结束函数体
2.返回一个值
1 def my_len(my_str): #定义函数
2 #计算可变类型值的长度
3 my_str = "goodnight"
4 count = 0
5 for val in my_str:
6 count += 1
7 return count #count就是那个返回值
3.返回多个值
def my_print():
return 11,22,33,[1,2,3]
a = my_print()
print(a)
#打印结果:(11, 22, 33, [1, 2, 3])
return后面的值用逗号隔开,然后以元组的形式返回
4.结束函数代码
def my_print():
print('one')
return #遇到return不继续函数下面的代码
print('two')
my_print() #结果:one
5.补充:接收多个值
def my_print():
return 1,2,3
a,b,c=my_print()
print(a,b,c) #相当于用a接收1,b接收2,c接收3
def my_print():
return [4,5,6]
a,b,c=my_print()
print(a,b,c) #一个列表里有三个值,分别用abc去接收,相当于解包
函数的参数:
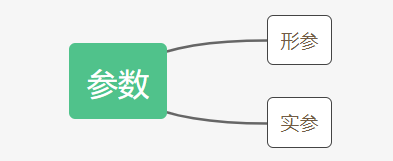
def my_len(my_str): #这里的my_str就是形参,形式参数,输入对象不确定,形参可以有多个,用逗号隔开
my_str = "goodnight"
count = 0
for val in my_str:
count += 1
return count
a = my_len("hightgood") #这里的hightgood就是实参,实际参数,输入对象确定
print(a)
函数参数详解:

1.位置参数:
def demo_1(a,b): #位置参数 用户必须传入的参数,不传会报错
print(a,b)
demo_1(1,2) #输出结果:1 2 按照位置传参
demo_1(b=1,a=2) #输出结果:2 1 按照关键字传参
demo_1(1,b=2) #输出结果:1 2 混用,但必须注意先按照位置传参,再按照关键字传参,不然会报错
2.默认参数:
def welcome(name,sex='man'): #sex为默认参数
print('welcome %s,sex %s'%(name,sex))
welcome('zrh') #输出结果:welcome zrh,sex man
welcome('lml','women') #输出结果:welcome lml,sex women
#默认参数如果不传参数,就用默认值,如果默认参数传入参数,就用传入值
默认参数的陷阱:
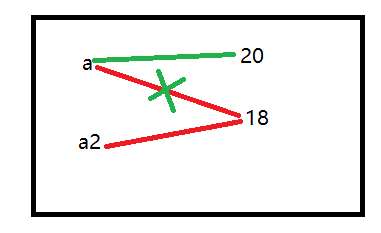
(1)
a = 18
def age(a1,a2=a):
print(a1,a2)
a = 20
age(10) #输出结果:10 18
内部原理:
(2)
专门针对可变数据类型
def demo(a = []):
a.append(1)
print(a)
demo() #输出结果:[1]
demo() #输出结果:[1] [1]
demo() #输出结果:[1] [1] [1]
def demo_1(a = []):
a.append(1)
print(a)
demo_1([]) #输出结果:[1]
demo_1([]) #输出结果:[1]
demo_1([]) #输出结果:[1]
因为可变类型改变不是在内存中开辟一个新空间,而是在原来的基础上做修改,而10--12行是开辟了三块新内存
3.动态参数:
定义动态参数
def demo(*agrs): #按位置输入的动态参数,组成一个元组
pass
def demo_1(**kwargs): #按关键字传入的参数,组成一个字典
pass
站在函数定义的角度:*做聚合作用,将一个一个的参数组合成一个元组(**则是字典)
站在函数调用的角度:*做打散用,将一个列表或元组打散成多个参数(**则是关键字形式)
#函数定义角度:
def demo(*agrs): #按位置输入的动态参数
print(agrs)
demo(1,2,3,4,5) #输出结果(1, 2, 3, 4, 5)
def demo_1(**kwargs): #按关键字传入的参数,组成一个字典
print(kwargs)
demo_1(a=1,b=2,c=3) #输出结果{'a': 1, 'b': 2, 'c': 3}
#函数调用角度:
val = [1,2,3,4]
val2 = {'a':1,'b':2}
demo(*val) #将val打散成 1 2 3 4,然后传入函数
demo_1(**val2) #将val2打散成 a=1 b=2,然后传入函数
解释一下为什么在混用的传参中有必须先按位置传参,再按关键数传参:
def demo(*agrs,**kwargs): #*agrs和**kwargs的位置是python固定死的
#所以必须先是按照位置传参的*agrs,再是按照关键字传参的**keagrs
print(agrs)
print(kwargs)
demo(1,2,3,4,a = 1,b = 2)
# 输出结果:
# (1, 2, 3, 4)
# {'a': 1, 'b': 2}
第3行对应第7行的输出结果
第4行对应第8行的输出结果
定义多个不同类型参数时的顺序:
def demo(位置参数1,位置参数2,*args,默认参数=x,**kwargs):
pass
#以后职业生涯用到多种参数时必须这么写
格式及原理:
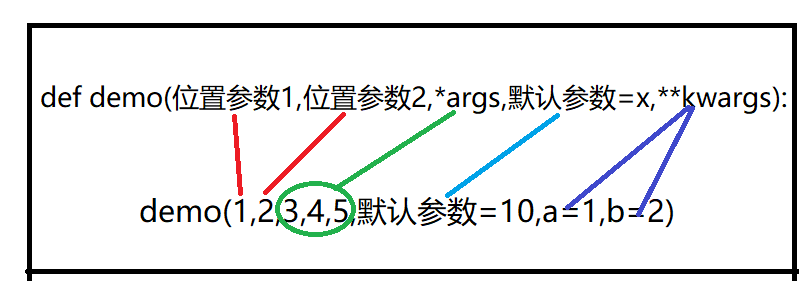
情况总结:
def demo(*args,**kwargs): #接收参数个数不确定的时候用动态传参,用到的时候再用
pass
def demo_1(a,b,c): #位置参数,几个参数必须都要传入几个值,最常用
pass
def demo_2(a,b=10): #默认参数,当参数信息大量形同时用到
pass
函数案例:
需求:写函数,用户输入操作文件名字,将要修改的内容,修改后的内容,然后进行批量操作

def dict_change(filename,old_content,new_content):
'''
函数用于文件内容批量修改操作
:param filename: 操作对象的名字
:param old_content: 将要修改的值
:param new_content: 修改后的值
:return:无返回值
'''
import os
with open(filename,encoding='utf-8') as file_old,open('new_file','w',encoding='utf-8') as file_new :
for val_old in file_old:
val_new = val_old.replace(old_content,new_content)
file_new.write(val_new)
os.remove(filename)
os.rename('new_file',filename)
dict_change('file','.','=')
修改后的文件:

函数的嵌套:
#函数的嵌套调用
def demo_1():
print(123)
def demo_2():
demo_1()
print(456)
demo_2()
# 输出结果:
#
# #函数嵌套定义
def demo_1():
print(123)
def demo_2():
print(456)
demo_2()
demo_1()
# 输出结果:
#
#
注意:内存读函数的时候先读定义函数名(不读里面的函数体),后面遇到调用此函数的时候,再返回读函数的函数体。
在函数外调整内部嵌套函数内容的方法:
def case(x,y,z):
def new_case(a,b,c):
print('content',a,b,c)
new_case(x,y,z)
case(1,2,3)
#输出结果 content 1 2 3
进阶:
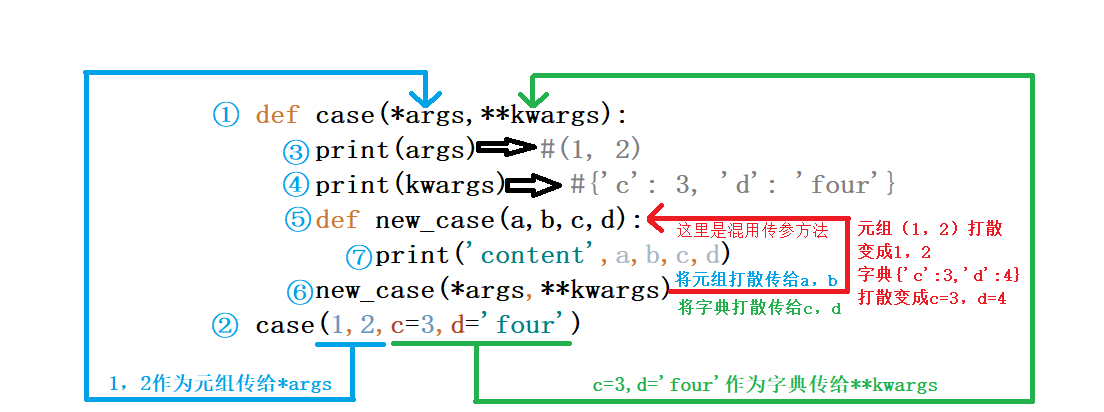
①到⑦表示代码运行顺序
*args 和 **kwargs 只是函数定义参数的方式,和混合传参不是一回事哦
函数的命名空间:
在函数外部定义的变量为全局变量,函数内部定义的变量为局部变量
在函数内定义的局部变量只在该函数内可见,当函数运行结束后,在其内部定义的所有局部变量将自动删除而不访问
1.
a = 1
b = 2
def num_max(a,b):
c = b if a<b else a
print(c)
def num_min(a,b):
c = a if a<b else b
print(c)
num_max(10,8)
num_min(5,6)

局部命名空间之间信息不互通,不共享
2.
1 a = 1
2 b = 2
3 def num_max():
4 c = b if a<b else a
5 print(c)
6 num_max() #输出结果:2
函数局部命名空间(儿子)可以用全局命名空间(爸爸)的内容,但是全局命名空间(爸爸)不可以使用函数局部命名空间(儿子)的内容
就是 儿子可以用爸爸的,爸爸不能用儿子的
3.
a = 1
b = 2
def num_max():
def num():
a = 3
print(a)
num()
num_max() #输出结果:3
对于局部命名空间来说,自己有的话就用自己的,自己没有再用全局命名空间的
4.
a = 1
b = 2
def num_max():
c = 3
def num():
d = 4
print(a)
num()
num_max() #输出结果:1

儿子没有的先用爸爸的,爸爸也没有的话,再用爷爷的
爷爷不能用爸爸,更不能用儿子
爸爸也不能用儿子的
命名空间的加载顺序:
1.启动python
2.内置的命名空间(在哪里都可以用,比如print()等)
3.加载全局命名空间中的名字 —— 从上到下顺序加载
4.加载局部命名空间中的名字 —— 调用该函数的时候,在函数里从上到下去加载
函数的作用域:
内置的命名空间,在任意地方都可以用
全局的命名空间,在我们写的代码里任意地方(相当于爷爷,爸爸儿子都可以用爷爷的)
局部的命名空间,只能在自己的函数内使用
global:在函数内部修改全局变量的值
a = 1
def demo_1():
a =2
print(a)
def demo_2():
a = 3
print(a)
demo_2()
demo_1()
print(a)
打印结果:

需求,在函数里修改全局变量a = 10,这个时候就用的global:
a = 1
def demo_1():
global a
a =10
print(a)
def demo_2():
a = 3
print(a)
demo_2()
demo_1()
print(a)
打印结果:

nonlocal:在函数内部修改函数上一级的变量值,儿子修改爸爸的值,但不影响爷爷的值,只改一层
nonlocal 只修改局部命名空间里的 从内部往外部找到第一个对应的变量名
a = 1
def demo_1():
a =2
print(a)
def demo_2():
a = 3
print(a)
demo_2()
demo_1()
print(a)
打印结果:
需求:修改demo_1()里a的值为10
a = 1
def demo_1():
a = 2
print(a)
def demo_2():
nonlocal a
a = 10
print(a)
demo_2()
demo_1()
print(a)
输出结果:

函数名的灵活应用:
def func(): pass
func就是函数名,加个括号func()才是调用函数
函数的名字首先是一个函数的内存地址,可以当作变量使用 ,函数名是第一类对象的概念
函数的名字可以赋值,可以作为其他列表等容器类型的元素
函数的名字可以作为函数的参数,返回值
def func():
print(123)
print(func)
#输出结果:<function func at 0x0000023DB22EF1F8>
# 是个函数 名为func 内存地址
就表示func是一个存着一个函数地址的变量而已
所以下面这些都可以使用:
def func():
print(123)
a = func
print(func)
print(a)
#输出结果:一模一样
# <function func at 0x000002435074F1F8>
# <function func at 0x000002435074F1F8>
def func():
print(123)
a = func
a() #输出结果:123
def func():
print(123)
list_1 = [func]
print(list_1) #输出结果 [<function func at 0x000001BC83DCF1F8>]
#这个时候 list_1[0] == func
list_1[0]() #输出结果:123 list_1[0]()也可以调用函数func()
def func():
print(123)
def exal(q):
q() #相当于func(),用到了前面说的嵌套函数的调用
print(q,type(q))
exal(func)
print(type(func))
#输出结果:
#
# <function func at 0x0000027B24E5F288> <class 'function'>
#<class 'function'>
高阶函数:
高阶函数定义:
1.函数接收的参数是一个函数名
2.函数的返回值是一个函数名
满足上述条件任意一个,都可称之为高阶函数
def foo():
print('from foo')
def test(func_name):
return func_name
print(test(foo)) #<function foo at 0x0000018F2211F288> 拿到的是foo函数名的内存地址
此时test()就是一个高阶函数
闭包:
内部函数(下面的demo_2)引用了外部函数(dem_1)的 变量,内部的函数就叫做闭包
def demo_1():
name = 'zrh'
age = ''
def demo_2():
print(name,age)
print(demo_2.__closure__)
#(<cell at 0x0000018B6DE9A108: str object at 0x0000018B6DE6DDF0>,
<cell at 0x0000018B6DE9A1F8: str object at 0x0000018B6DE6DDB0>)
#打印出来有东西说明用到了外部函数的变量,就形成了闭包
demo_1()
闭包的作用:
在变量不容易被别人改变的情况下,还不会随着你多次去调用而反复取创建
def demo_1():
name = 'zrh'
print(name)
demo_1()
demo_1()
demo_1()
demo_1()
demo_1()
demo_1()
#......
如果我执行demo_1函数一万次。那么内存就会开辟一万次空间储存 name = ‘zrh’,然后再耗费时间关闭那一万次的空间
def demo_1():
name = 'zrh'
def demo_2():
print(name)
return demo_2
i = demo_1()
i()
i()
i()
i()
如果用闭包的方式,即使调用函数一万次,内存也会在第6行代码执行时创建一次空间来储存name = ‘zrh’,大大节省空间利用效率
闭包的应用:
from urllib.request import urlopen #模块
def get_url():
url = 'http://www.cnblogs.com/'
def inner():
ret = urlopen(url).read()
return ret
return inner
get_web = get_url()
res = get_web()
print(res)
同样url = 'http://www.cnblogs.com/'只创建了一次,后面调用千百万次,内存空间只有一次

python-函数相关的更多相关文章
- Python函数相关
Python中的函数也是一种对象,而且函数还是一等公民.函数能作为参数,也能作为返回值,这使得Python中的函数变得很灵活.想想前面两篇中介绍的通过内嵌函数实现的装饰器和闭包. 下面就介绍一下Pyt ...
- python 函数相关定义
1.为什么要使用函数? 减少代码的冗余 2.函数先定义后使用(相当于变量一样先定义后使用) 3.函数的分类: 内置函数:python解释器自带的,直接拿来用就行了 自定义函数:根据自己的需求自己定义的 ...
- Python开发【第四篇】函数
函数的作用 函数可以让编程逻辑结构化以及模块化 无论是C.C++,Java还是Python,函数是必不可少的知识点,也是很重要的知识点,函数是完成一个功能的代码块,使用函数可以使逻辑结构变得更加清晰以 ...
- python拓展1 week1-week5复习回顾
知识内容: 1.python基础概念及基础语法 2.python基础数据类型 3.python模块相关 4.python函数相关 5.python面向对象相关 6.python文件处理相关 注:本节内 ...
- 有道笔记链接地址 -----关于python
一.python相关 python列表的操作[list[]]: http://note.youdao.com/noteshare?id=93922f3174b1d8fac04514064656 ...
- 『Python题库 - 填空题』151道Python笔试填空题
『Python题库 - 填空题』Python笔试填空题 part 1. Python语言概述和Python开发环境配置 part 2. Python语言基本语法元素(变量,基本数据类型, 基础运算) ...
- python函数(一)
今天记一下学到的python函数相关知识. 目录: 1.函数简介 2.函数定义 3.函数参数 第一部分:函数简介 我们在编程过程中往往会碰到这样的事情-----很多地方都用到了相同的一段代码.虽 ...
- Python函数参数和注解是什么
四种参数 Python函数func定义如下: def func(first, *args, second="Hello World", **kwargs): print(first ...
- python之路(六)-函数相关
在没有学习函数之前我们的程序是面向过程的,不停的判断,不停的循环,同样的代码重复出现在我们的代码里.函数可以更好的提高我们的 代码质量,避免同样的代码重复出现,而只需要在用的时候调用函数即可执行.此为 ...
- python(2)-函数相关
可变参数 def enroll(name, gender, age=6, city='Beijing'): print 'name:', name print 'gender:', gender pr ...
随机推荐
- ACM团队周赛题解(1)
这次周赛题目拉了CF315和CF349两套题. 因为我代码模板较长,便只放出关键代码部分 #define ll long long #define MMT(s,a) memset(s, a, size ...
- HBase导入数据同时与Phoenix实现同步映射
1.HDFS上数据准备 2019-03-24 09:21:57.347,869454021315519,8,1 2019-03-24 22:07:15.513,867789020387791,8,1 ...
- C. Anadi and Domino
题目链接:http://codeforces.com/contest/1230/problem/C C. Anadi and Domino time limit per test: 2 seconds ...
- 遗传编程(GA,genetic programming)算法初探,以及用遗传编程自动生成符合题解的正则表达式的实践
1. 遗传编程简介 0x1:什么是遗传编程算法,和传统机器学习算法有什么区别 传统上,我们接触的机器学习算法,都是被设计为解决某一个某一类问题的确定性算法.对于这些机器学习算法来说,唯一的灵活性体现在 ...
- python正则表达式字符记录
代码 功能 . 匹配任意1个字符(除了\n) [] 匹配[]中列举的字符 \d 匹配数字,即0-9 \D 匹配非数字, 即不是数字 \s 匹配空白,即空格,tab键 \S 匹配非空白 \w ...
- 【面试】我是如何在面试别人Redis相关知识时“软怼”他的
事出有因 Redis是一个分布式NoSQL数据库,因其数据都存储在内存中,所以访问速度极快,因此几乎所有公司都拿它做缓存使用,所以Redis常被称为分布式缓存. 一次我的一个同事让我帮他看Redis相 ...
- java架构之路-(分布式)初识zookeeper安装与参数详解
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提供的功 ...
- CF #579 (Div. 3) A.Circle of Students
A. Circle of Students time limit per test2 seconds memory limit per test256 megabytes inputstandard ...
- springboot系列之04-提高开发效率必备工具lombok
未经允许,不得转载 原作者:字母哥博客 本文完整系列出自:springboot深入浅出系列 一.前置说明 本节大纲 使用lombok插件的好处 如何安装lombok插件 使用lombok提高开发效率 ...
- 【SQL server基础】初步学习存储过程(好学易懂)
-------------------------------------------------------------------------- ------------------------- ...