并发编程之Fork/Join
并发与并行
并发:多个进程交替执行。
并行:多个进程同时进行,不存在线程的上下文切换。
并发与并行的目的都是使CPU的利用率达到最大。Fork/Join就是为了尽可能提高硬件的使用率而应运而生的。
计算密集型与IO密集型
计算密集型:也称之为CPU密集型,此时系统的硬盘,内存性能相对于CPU要很多。系统在运作的时候CPU是处于100% loading的状态,在系统完成磁盘的读写(I/O)以后,程序就会进行计算,在进行计算的时候CPU占用率是很高的。计算密集型任务最大的特点就是进行大量的计算,消耗CPU资源,比如说高清解码,计算圆周率啥的,都是靠CPU的运算能力。这种类型的任务虽然也支持多任务,但是花费在任务切换的时间越多,执行效率就越低,要最高效的利用cpu,建议任务数小于核心线程数。代码运行效率也很关键,一般使用C语言来写。线程数的设置:CPU核数+1(现代CPU支持超线程)。
IO密集型:CPU性能要比硬盘,内存性能好很多。这时候,大部分的情况是CPU在等I/O的读写操作,此时CPU loading并不是很高。I/O bound的程序一般在达到极限的时候,CPU利用率仍然比较低。对于IO密集型的任务主要涉及到网络,磁盘IO.特点是CPU消耗很少,任务的大部分时间都是在等待IO操作完成(磁盘IO的速度远远低于cpu与内存的速度)。对于这种任务,任务越多,CPU的效率越高。对于这种任务适合使用开发效率最高的脚本语言,C语言基本上没啥用。线程数的设置:(线程等待时间+线程CPU时间)/线程CPU时间)*CPU数目。
如何利用多核CPU,计算很大数组中所有整数进行排序?
当数据量小的时候使用快速排序快,快速排序显著的特征是用递归的方法去排序的。当数据量大的时候归递排序。递归排序的思想就是在数组中取一个中间值,将一个数组分为2个,一个比中间值大,一个比中间值小,如此反复拆分排序,直到最后无法再进行拆分,然后将结果合并。因此递归方法除了空间复杂度增加了,还可能会产生栈溢出。(程序计数器是唯一不会发生栈溢出的),虚拟机栈默认最大空间是1M.
分治思想:就是将一个规模大的问题划分为规模较小的子问题,然后逐步解决小问题,最后合并子问题的解就得到了原问题的解。即分割原问题--求解子问题--合并子问题的解。
子问题一般都是相互独立的,因此,通常通过递归调用算法来求解子问题。
Fork/Join框架
Fork/Join 是一个用于并行执行任务的框架,是一个把大任务拆分成小任务,执行小任务,最后汇总小任务的结果得到大任务的结果的框架。整体框架如下:
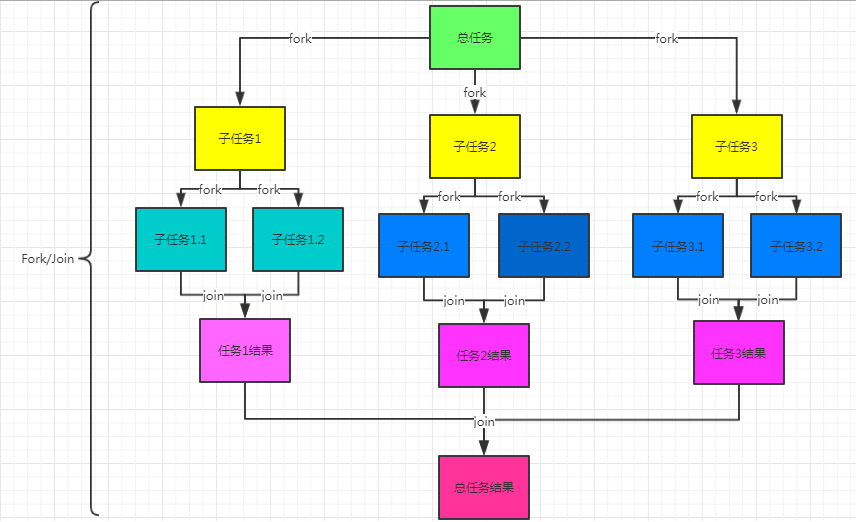
Fork/Join 特征:
1、ForkJoinPool是ExecutorService的补充 ,适用于一些特定的场景,适合于计算密集型场景。如果存在I/O,线程间同步,sleep()等会造成线程长时间阻塞的情况,此时可以配合ManagedBlocker使用。
2、ForkJoinPool主要是实现分治法,分治之后递归调用函数。
ForkJoinPool 框架主要类
ForkJoinPool 实现ForkJoin的线程池 - ThreadPool
ForkJoinWorkerThread 实现ForkJoin的线程
ForkJoinTask<V> 一个描述ForkJoin的抽象类 Runnable/Callable
RecursiveAction 无返回结果的ForkJoinTask实现Runnable
RecursiveTask<V> 有返回结果的ForkJoinTask实现Callable
CountedCompleter<T> 在任务完成执行后会触发执行一个自定义的钩子函数
提交任务:

fork()类似于Thread.start(),但是它并不立即执行任务,而是将任务放入工作队列中, 跟Thread.join()不同,ForkJoinTask的join()方法并不简单的阻塞线程 利用工作线程运行其他任务, 当一个工作线程中中调用join(),它将处理其他任务,直到注意到目标子任务已经完成。
ForkJoinPool中的所有工作线程都有一个自己的工作队列WorkQueue,是一个双端队列Deque,从队头取任务,先进后出,线程私有,不共享。
如下图所示:
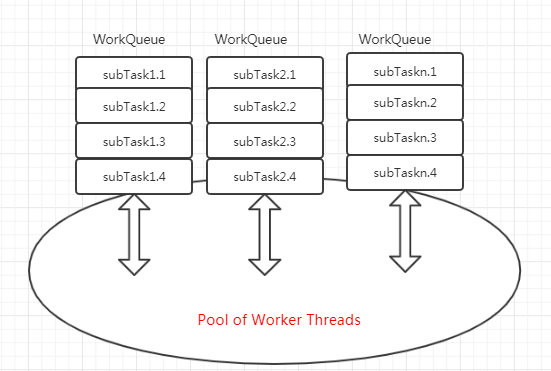
线程窃取
工作窃取就是指某个线程从其他队列里窃取任务来执行。在ForkJoinPool中就是将一个大任务分成n个互不依赖的子任务,为了减少线程之间的竞争,于是把这些子任务放到不同的队列当中去,并为每一个对列创建一个线程来执行队列中的任务,A队列的任务由A线程来执行。但是有的线程执行得比较快,很快就把自己队列当中的任务执行完成了,但是A队列里还有待执行的任务,这时候这个线程(假设是B线程)就会去窃取他的队列当中的任务来执行。为了减少窃取任务线程与被窃取任务线程之间的竞争,采用双端队列,窃取任务是从队尾窃取,被窃取任务线程从队头获取任务来执行。
为了尽可能的提高CPU的利用率,空闲的线程将从其他线程的队列中窃取任务来执行,从workQueue的队尾窃取任务,从而减少竞争,任务的窃取是遵从FIFO顺序进行的,因为先放入的任务往往表示更大的工作量,窃取来的任务支持进一步的递归分解。
WorkQueue双端队列最小化任务“窃取”的竞争, push()/pop()仅在其所有者工作线程中调用 ,这些操作都是通过CAS来实现的,是Wait-free的 。
poll() 则由其他工作线程来调用“窃取”任务 可能不是wait-free。任务窃取的好处就是充分利用了资源,但是也有缺点,当队列当中只有一个任务的时候,就会出现竞争,并且系统会耗费更多的资源,比如创建多个线程和多个双端队列。

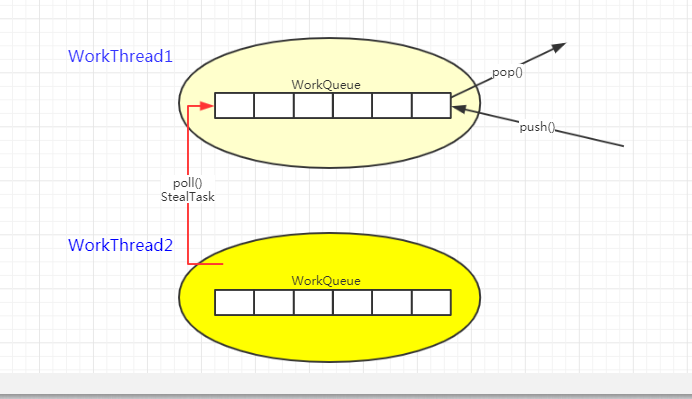
总结一下就是:
代码如下:
public final ForkJoinTask<V> fork() {
((ForkJoinWorkerThread) Thread.currentThread())
.pushTask(this);
return this;
}
final void pushTask(ForkJoinTask<?> t) {
ForkJoinTask<?>[] q; int s, m;
if ((q = queue) != null) { // ignore if queue removed
long u = (((s = queueTop) & (m = q.length - 1)) << ASHIFT) + ABASE;
UNSAFE.putOrderedObject(q, u, t);
queueTop = s + 1; // or use putOrderedInt
if ((s -= queueBase) <= 2)
pool.signalWork();
else if (s == m)
growQueue();
}
}
为了测试ForkJoinPool的好处,我们来看以下两段代码,来对比一下结果:
首先我们来看一下,就用自己写的分任务执行,来计算
package com.test.executor.arrsum; import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future; import com.test.executor.arrsum.utils.Utils; public class SumRecursiveMT {
public static class RecursiveSumTask implements Callable<Long> {
public static final int SEQUENTIAL_CUTOFF = 1;
int lo;
int hi;
int[] arr; // arguments
ExecutorService executorService; RecursiveSumTask( ExecutorService executorService, int[] a, int l, int h) {
this.executorService = executorService;
this.arr = a;
this.lo = l;
this.hi = h;
} public Long call() throws Exception { // override
System.out.format("%s range [%d-%d] begin to compute %n",
Thread.currentThread().getName(), lo, hi);
long result = 0;
if (hi - lo <= SEQUENTIAL_CUTOFF) {
for (int i = lo; i < hi; i++)
result += arr[i]; System.out.format("%s range [%d-%d] begin to finished %n",
Thread.currentThread().getName(), lo, hi);
}
else {
RecursiveSumTask left = new RecursiveSumTask(executorService, arr, lo, (hi + lo) / 2);
RecursiveSumTask right = new RecursiveSumTask(executorService, arr, (hi + lo) / 2, hi);
Future<Long> lr = executorService.submit(left);
Future<Long> rr = executorService.submit(right); result = lr.get() + rr.get();
System.out.format("%s range [%d-%d] finished to compute %n",
Thread.currentThread().getName(), lo, hi);
} return result;
}
} public static long sum(int[] arr) throws Exception {
int nofProcessors = Runtime.getRuntime().availableProcessors();
ExecutorService executorService = Executors.newFixedThreadPool(4);
//ExecutorService executorService = Executors.newCachedThreadPool(); RecursiveSumTask task = new RecursiveSumTask(executorService, arr, 0, arr.length);
long result = executorService.submit(task).get();
return result;
}
//执行该方法,看看测试结果
public static void main(String[] args) throws Exception {
int[] arr = Utils.buildRandomIntArray(20);
System.out.printf("The array length is: %d\n", arr.length); long result = sum(arr); System.out.printf("The result is: %d\n", result); }
} package com.test.executor.arrsum.utils; import java.util.Random; public class Utils { public static int[] buildRandomIntArray(int size) {
int[] array = new int[size];
for (int i = 0; i < size; i++) {
array[i] = new Random().nextInt(100);
}
return array;
} public static int[] buildRandomIntArray() {
int size = new Random().nextInt(100);
int[] array = new int[size];
for (int i = 0; i < size; i++) {
array[i] = new Random().nextInt(100);
}
return array;
} public static void main(String[] args) {
int[] ints = Utils.buildRandomIntArray(20); for (int i = 0; i < ints.length; i++) {
System.out.println(ints[i]);
}
}
}
package com.test.executor.arrsum; import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future; import com.test.executor.arrsum.utils.Utils; public class SumRecursiveMT {
public static class RecursiveSumTask implements Callable<Long> {
public static final int SEQUENTIAL_CUTOFF = 1;
int lo;
int hi;
int[] arr; // arguments
ExecutorService executorService; RecursiveSumTask( ExecutorService executorService, int[] a, int l, int h) {
this.executorService = executorService;
this.arr = a;
this.lo = l;
this.hi = h;
} public Long call() throws Exception { // override
System.out.format("%s range [%d-%d] begin to compute %n",
Thread.currentThread().getName(), lo, hi);
long result = 0;
if (hi - lo <= SEQUENTIAL_CUTOFF) {
for (int i = lo; i < hi; i++)
result += arr[i]; System.out.format("%s range [%d-%d] begin to finished %n",
Thread.currentThread().getName(), lo, hi);
}
else {
RecursiveSumTask left = new RecursiveSumTask(executorService, arr, lo, (hi + lo) / 2);
RecursiveSumTask right = new RecursiveSumTask(executorService, arr, (hi + lo) / 2, hi);
Future<Long> lr = executorService.submit(left);
Future<Long> rr = executorService.submit(right); result = lr.get() + rr.get();
System.out.format("%s range [%d-%d] finished to compute %n",
Thread.currentThread().getName(), lo, hi);
} return result;
}
} public static long sum(int[] arr) throws Exception {
int nofProcessors = Runtime.getRuntime().availableProcessors();
ExecutorService executorService = Executors.newFixedThreadPool(4);
//ExecutorService executorService = Executors.newCachedThreadPool(); RecursiveSumTask task = new RecursiveSumTask(executorService, arr, 0, arr.length);
long result = executorService.submit(task).get();
return result;
} public static void main(String[] args) throws Exception {
int[] arr = Utils.buildRandomIntArray(20);
System.out.printf("The array length is: %d\n", arr.length); long result = sum(arr); System.out.printf("The result is: %d\n", result); }
}
运行该代码的结果如下:
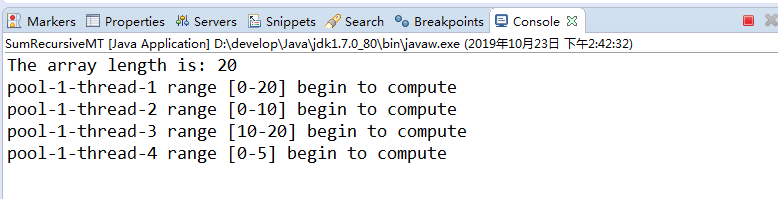
结果一直没有出来,就说明一直在计算。因为线程在递归计算,开的线程太多,然后计算时间比较长。
ForkJoin的使用
ForkJoinTask:我们要使用ForkJoin框架,就要创建一个ForkJoin 任务,创建ForkJoin任务的话,不需要直接继承ForkJoinTask类,而是继承他的子类.ForkJoin框架有两个子类RecursiveAction和RecursiveTask<V>。
1、RecursiveAction:用于返回没有结果的任务。(比如写数据到磁盘以后就退出。一个RecursiveAction可以把工作分割成若干小块,由独立的线程或者CPU执行,通过继承实现RecursiveAction)
2、RecursiveTask<V> :用于执行有返回结果的任务。(将一个任务分割成若干的子任务,每个子任务返回的值合并到一个集体结果,可以水平的分割和合并。)
ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行。任务分割出来的子任务会添加到当前工作线程的双端队列当中,进入队列的头部。当一个工作线程的队列中没有任务的时候它会从其他队列的尾部获取任务来执行。
接下来来看看用ForkJoinPool来计算的代码:
package com.test.executor.arrsum; import java.util.concurrent.RecursiveTask; /**
* RecursiveTask 并行计算,同步有返回值
* ForkJoin框架处理的任务基本都能使用递归处理,比如求斐波那契数列等,但递归算法的缺陷是:
* 一只会只用单线程处理,
* 二是递归次数过多时会导致堆栈溢出;
* ForkJoin解决了这两个问题,使用多线程并发处理,充分利用计算资源来提高效率,同时避免堆栈溢出发生。
* 当然像求斐波那契数列这种小问题直接使用线性算法搞定可能更简单,实际应用中完全没必要使用ForkJoin框架,
* 所以ForkJoin是核弹,是用来对付大家伙的,比如超大数组排序。
* 最佳应用场景:多核、多内存、可以分割计算再合并的计算密集型任务
*/
class LongSum extends RecursiveTask<Long> { static final int SEQUENTIAL_THRESHOLD = 1000;
static final long NPS = (1000L * 1000 * 1000);
static final boolean extraWork = true; // change to add more than just a sum int low;
int high;
int[] array; LongSum(int[] arr, int lo, int hi) {
array = arr;
low = lo;
high = hi;
} /**
* fork()方法:将任务放入队列并安排异步执行,一个任务应该只调用一次fork()函数,除非已经执行完毕并重新初始化。
* tryUnfork()方法:尝试把任务从队列中拿出单独处理,但不一定成功。
* join()方法:等待计算完成并返回计算结果。
* isCompletedAbnormally()方法:用于判断任务计算是否发生异常。
*/
protected Long compute() { if (high - low <= SEQUENTIAL_THRESHOLD) {
long sum = 0;
for (int i = low; i < high; ++i) {
sum += array[i];
}
return sum; } else {
int mid = low + (high - low) / 2;
LongSum left = new LongSum(array, low, mid);
LongSum right = new LongSum(array, mid, high);
left.fork();
right.fork();
long rightAns = right.join();
long leftAns = left.join();
return leftAns + rightAns;
}
}
} package com.test.executor.arrsum; import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask; import com.test.executor.arrsum.utils.Utils; public class LongSumMain { //获取逻辑处理器数量
static final int NCPU = Runtime.getRuntime().availableProcessors();
/** for time conversion */
static final long NPS = (1000L * 1000 * 1000); static long calcSum; static final boolean reportSteals = true; public static void main(String[] args) throws Exception {
int[] array = Utils.buildRandomIntArray(20000000);
System.out.println("cpu-num:"+NCPU);
//单线程下计算数组数据总和
calcSum = seqSum(array);
System.out.println("seq sum=" + calcSum); //采用fork/join方式将数组求和任务进行拆分执行,最后合并结果
LongSum ls = new LongSum(array, 0, array.length);
ForkJoinPool fjp = new ForkJoinPool(NCPU); //使用的线程数
ForkJoinTask<Long> task = fjp.submit(ls);
System.out.println("forkjoin sum=" + task.get()); if(task.isCompletedAbnormally()){
System.out.println(task.getException());
} fjp.shutdown(); } static long seqSum(int[] array) {
long sum = 0;
for (int i = 0; i < array.length; ++i)
sum += array[i];
return sum;
} }
以上的运行结果就很快:
cpu-num:4
seq sum=989877234
forkjoin sum=989877234
Fork/Join框架原理
异常处理
ForkJoinTask在执行任务的时候可能会抛异常,此时我们没有办法从主线程里面获取异常,所以我们使用以下几种方法来判断以及获取异常:
1、isCompletedAbnormally()方法来判断任务有没有抛出异常或者被取消。
2、getException()可以获取到异常。
3、isCompletedNormally()这个方法是看任务是否正常执行完成且没有任何异常。
示例:
if(task.isCompletedAbnormally())
System.out.print(task.getException());
ForkJoinPool构造方法
public ForkJoinPool() {
this(Runtime.getRuntime().availableProcessors(),
defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
Thread.UncaughtExceptionHandler handler,
boolean asyncMode) {
checkPermission();
if (factory == null)
throw new NullPointerException();
if (parallelism <= 0 || parallelism > MAX_ID)
throw new IllegalArgumentException();
this.parallelism = parallelism;
this.factory = factory;
this.ueh = handler;
this.locallyFifo = asyncMode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
this.submissionQueue = new ForkJoinTask<?>[INITIAL_QUEUE_CAPACITY];
// initialize workers array with room for 2*parallelism if possible
int n = parallelism << 1;
if (n >= MAX_ID)
n = MAX_ID;
else { // See Hackers Delight, sec 3.2, where n < (1 << 16)
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8;
}
workers = new ForkJoinWorkerThread[n + 1];
this.submissionLock = new ReentrantLock();
this.termination = submissionLock.newCondition();
StringBuilder sb = new StringBuilder("ForkJoinPool-");
sb.append(poolNumberGenerator.incrementAndGet());
sb.append("-worker-");
this.workerNamePrefix = sb.toString();
}
重要参数说明:
1、parallelism:并行数。一般跟CPU个数保持一致。通过Runtime.getRuntime().availableProcessors()可以获取到当前机器的CPU个数。
2、ForkJoinWorkerThreadFactory factory:创建线程的工厂
3、Handler :线程异常处理器,Thread.UncaughtExceptionHandler ,该处理器在线程执行任务时由于某些无法预料到的错误而导致任务线程中断时进行一些处理,默认情况为null。
4、boolean asyncMode: 表示工作线程内的任务队列是采用何种方式进行调度,可以是先进先出FIFO,也可以是先进后出FILO.如果为true,则表示线程池中的线程使用先进先出的方式进行调度,默认为false.
ForkJoinTask fork()/join()方法
1、fork():这个方法的作用就是将任务放到当前线程的工作队列当中去;
public final ForkJoinTask<V> fork() {
((ForkJoinWorkerThread) Thread.currentThread())
.pushTask(this);
return this;
}
2、join()的方法我们先看一下代码:
private int doJoin() {
Thread t; ForkJoinWorkerThread w; int s; boolean completed;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) {
if ((s = status) < 0)
return s;
if ((w = (ForkJoinWorkerThread)t).unpushTask(this)) {
try {
completed = exec();
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
return setCompletion(NORMAL);
}
return w.joinTask(this);
}
else
return externalAwaitDone();
}
*/
private V reportResult() {
int s; Throwable ex;
if ((s = status) == CANCELLED)
throw new CancellationException();
if (s == EXCEPTIONAL && (ex = getThrowableException()) != null)
UNSAFE.throwException(ex);
return getRawResult();
}
public final V join() {
if (doJoin() != NORMAL)
return reportResult();
else
return getRawResult();
}
1、检查调用Join()方法的线程是否是ForkJoinWorkerThread,如果不是的话就阻塞当前线程,等待任务完成,如果是则不阻塞;
2、判断任务的状态,是否已经完成,如果已经完成,则返回结果;
3、任务没有完成,判断任务是否处于自己的队列当中,如果是,就取出执行完任务;
4、任务没有在自己队列当中,则说明任务被偷走,找到偷走任务的小偷,窃取小偷工作队列中的任务,并执行,帮助小偷快点完成待join的任务;
5、若小偷偷走的任务已经完成,则找到小偷的小偷,帮助他完成任务;
6、递归执行5;
总体归纳起来的流程如下:
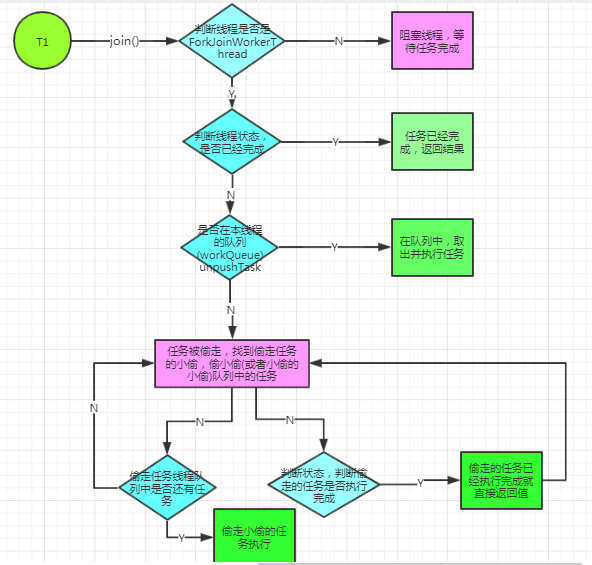
ForkJoinPool 之submit()方法
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) {
if (task == null)
throw new NullPointerException();
forkOrSubmit(task);
return task;
}
private <T> void forkOrSubmit(ForkJoinTask<T> task) {
ForkJoinWorkerThread w;
Thread t = Thread.currentThread();
if (shutdown)
throw new RejectedExecutionException();
if ((t instanceof ForkJoinWorkerThread) &&
(w = (ForkJoinWorkerThread)t).pool == this)
w.pushTask(task);
else
addSubmission(task);
}
ForkJoinPool有自己的工作队列,这些工作对列是用来接收由外部线程(非ForkJoinThread)提交过来的任务,这个对列称为submittingQueue。submit()和fork()没有本质的区别,只是提交对象是submittingQueue.submittingQueue也是工作线程窃取对象,当其中的任务被工作线程窃取成功的时候,代表提交任务正式进入执行阶段。
Fork/Join框架执行流程
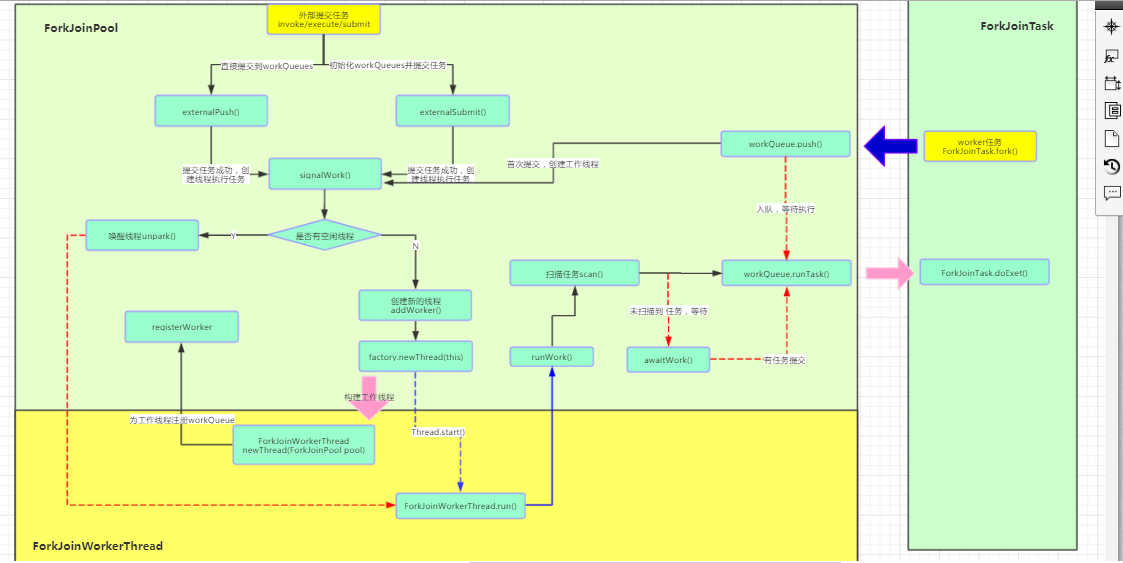
并发编程之Fork/Join的更多相关文章
- 并发编程之fork/join(分而治之)
1.什么是分而治之 分而治之就是将一个大任务层层拆分成一个个的小任务,直到不可拆分,拆分依据定义的阈值划分任务规模. fork/join通过fork将大任务拆分成小任务,在将小任务的结果join汇总 ...
- java-并发编程之fork/join框架
Fork/Join框架是Java 7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架.Fork/Join框架要完成两件事情: 1.任务分 ...
- c++并发编程之thread::join()和thread::detach()
thread::join(): 阻塞当前线程,直至 *this 所标识的线程完成其执行.*this 所标识的线程的完成同步于从 join() 的成功返回. 该方法简单暴力,主线程等待子进程期间什么都不 ...
- python并发编程之multiprocessing进程(二)
python的multiprocessing模块是用来创建多进程的,下面对multiprocessing总结一下使用记录. 系列文章 python并发编程之threading线程(一) python并 ...
- python并发编程之Queue线程、进程、协程通信(五)
单线程.多线程之间.进程之间.协程之间很多时候需要协同完成工作,这个时候它们需要进行通讯.或者说为了解耦,普遍采用Queue,生产消费模式. 系列文章 python并发编程之threading线程(一 ...
- python并发编程之gevent协程(四)
协程的含义就不再提,在py2和py3的早期版本中,python协程的主流实现方法是使用gevent模块.由于协程对于操作系统是无感知的,所以其切换需要程序员自己去完成. 系列文章 python并发编程 ...
- python并发编程之asyncio协程(三)
协程实现了在单线程下的并发,每个协程共享线程的几乎所有的资源,除了协程自己私有的上下文栈:协程的切换属于程序级别的切换,对于操作系统来说是无感知的,因此切换速度更快.开销更小.效率更高,在有多IO操作 ...
- python并发编程之threading线程(一)
进程是系统进行资源分配最小单元,线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.进程在执行过程中拥有独立的内存单元,而多个线程共享内存等资源. 系列文章 py ...
- 并发编程之:JMM
并发编程之:JMM 大家好,我是小黑,一个在互联网苟且偷生的农民工. 上一期给大家分享了关于Java中线程相关的一些基础知识.在关于线程终止的例子中,第一个方法讲到要想终止一个线程,可以使用标志位的方 ...
随机推荐
- 表达式树练习实践:C# 循环与循环控制
目录 表达式树练习实践:C# 循环 LabelTarget for / while 循环 无限循环 最简单的循环 多次循环 break 和 continue 一起 表达式树练习实践:C# 循环 C# ...
- Nginx缓存原理及机制
文章原创于公众号:程序猿周先森.本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号. 上篇文章介绍了Nginx一个较为重要的知识点:Nginx实现接口限流.本篇文章将介绍Nginx另一个重要知识点 ...
- filebeat使用multiline丢失数据问题
最近部署filebeat采集日志. 发现配置multiline后,日志偶尔会丢失数据,而且采集到的数据长度都不相同,所以和日志长度没有关系. 查阅filebeat官网后,找到了问题.filebeat有 ...
- Hadoop点滴-Hadoop分布式文件系统
Hadoop自带HDFS,即 Hadoop Distributed FileSystem(不是HaDoop FileSystem 的简称) 适用范围 超大文件:最新的容量达到PB级 流式数据访问:H ...
- Python简单的抓取静态网页内容
import requests from bs4 import BeautifulSoup res = requests.get('http://news.sina.com.cn/china/')#获 ...
- ES 32 - Elasticsearch 数据建模的探索与实践
目录 1 什么是数据建模? 2 如何对 ES 中的数据进行建模 2.1 字段类型的建模方案 2.2 检索.聚合及排序的建模方案 2.3 额外存储的建模方案 3 ES 数据建模实例演示 3.1 动态创建 ...
- 虚拟现实中自由步行(free-space walking)
之前我们讲到了虚拟现实中漫游方式的分类.虚拟现实中的漫游(travel/navigate)方式,即是应用提供给用户的,在虚拟环境中移动的方式.虚拟现实的漫游方式中,有一种被称为“完全动作线索”1,即用 ...
- java架构之路-(SpringMVC篇)SpringMVC主要流程源码解析(下)注解配置,统一错误处理和拦截器
我们上次大致说完了执行流程,也只是说了大致的过程,还有中间会出错的情况我们来处理一下. 统一异常处理 比如我们的运行时异常的500错误.我们来自定义一个类 package com.springmvcb ...
- jquery 全选,反选
<?php foreach ($contents as $item) { ?> <tr> <td><input name="qx" val ...
- zui框架配置日期控件只显示年月
zui框架配置日期控件datetimepicker只显示年月 <!DOCTYPE html> <head> <script src="~/Scripts/jqu ...