Mysql死锁如何排查:insert on duplicate死锁一次排查分析过程
前言
遇到Mysql死锁问题,我们应该怎么排查分析呢?之前线上出现一个insert on duplicate死锁问题,本文将基于这个死锁问题,分享排查分析过程,希望对大家有帮助。
死锁案发还原
表结构:
CREATE TABLE `song_rank` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`songId` int(11) NOT NULL,
`weight` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `songId_idx` (`songId`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
隔离级别:
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)
数据库版本:
+------------+
| @@version |
+------------+
| 5.7.21-log |
+------------+
1 row in set (0.00 sec)
关闭自动提交:
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 1 |
+--------------+
1 row in set (0.00 sec)
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 0 |
+--------------+
1 row in set (0.00 sec)
表中的数据:
mysql> select * from song_rank;
+----+--------+--------+
| id | songId | weight |
+----+--------+--------+
| 1 | 10 | 30 |
| 2 | 20 | 30 |
+----+--------+--------+
2 rows in set (0.01 sec)
死锁案发原因:
并发环境下,执行insert into … on duplicate key update…导致死锁
死锁模拟复现:
事务一执行:
mysql> begin; //第一步
Query OK, 0 rows affected (0.00 sec)
mysql> insert into song_rank(songId,weight) values(15,100) on duplicate key update weight=weight+1; //第二步
Query OK, 1 row affected (0.00 sec)
mysql> rollback; //第七步
Query OK, 0 rows affected (0.00 sec)
事务二执行:
mysql> begin; //第三步
Query OK, 0 rows affected (0.00 sec)
mysql> insert into song_rank(songId,weight) values(16,100) on duplicate key update weight=weight+1; // 第四步
Query OK, 1 row affected (40.83 sec)
事务三执行:
mysql> begin; //第五步
Query OK, 0 rows affected (0.00 sec)
mysql> insert into song_rank(songId,weight) values(18,100) on duplicate key update weight=weight+1; //第六步
事务一,事务二,事务三执行:
| 步骤 | 事务一 | 事务二 | 事务三 |
|---|---|---|---|
| 第一步 | begin; | ||
| 第二步 | insert into song_rank(songId,weight) values(15,100) on duplicate key update weight=weight+1; (Query OK, 1 row affected (0.00 sec) ) | ||
| 第三步 | begin; | ||
| 第四步 | insert into song_rank(songId,weight) values(16,100) on duplicate key update weight=weight+1; //被阻塞 | ||
| 第五步 | begin; | ||
| 第六步 | insert into song_rank(songId,weight) values(18,100) on duplicate key update weight=weight+1; //被阻塞 | ||
| 第七步 | rollback; | ||
| 结果 | Query OK, 1 row affected (40.83 sec) | ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
死锁浮出水面:
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
死锁破案排查分析
遇到死锁问题时,我们应该怎么处理呢?分一下几个步骤
1.查看死锁日志
当数据库发生死锁时,可以通过以下命令获取死锁日志:
show engine innodb status;
上面例子insert on duplicate死锁问题的日志如下:
*** (1) TRANSACTION:
TRANSACTION 27540, ACTIVE 19 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 23, OS thread handle 14896, query id 582 localhost ::1 root update
insert into song_rank(songId,weight) values(18,100) on duplicate key update weight=weight+1
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 116 page no 4 n bits 72 index songId_idx of table `test2`.`song_rank` trx id 27540 lock_mode X
locks gap before rec insert intention waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 80000014; asc ;;
1: len 4; hex 80000002; asc ;;
*** (2) TRANSACTION:
TRANSACTION 27539, ACTIVE 41 sec inserting, thread declared inside InnoDB 1
mysql tables in use 1, locked 1
4 lock struct(s), heap size 1136, 3 row lock(s), undo log entries 1
MySQL thread id 22, OS thread handle 6976, query id 580 localhost ::1 root update
insert into song_rank(songId,weight) values(16,100) on duplicate key update weight=weight+1
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 116 page no 4 n bits 72 index songId_idx of table `test2`.`song_rank` trx id 27539 lock_mode X
locks gap before rec
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 80000014; asc ;;
1: len 4; hex 80000002; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 116 page no 4 n bits 72 index songId_idx of table `test2`.`song_rank` trx id 27539 lock_mode X
locks gap before rec insert intention waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 80000014; asc ;;
1: len 4; hex 80000002; asc ;;
2.分析死锁日志
如何分析死锁日志呢? 分享一下我的思路
- 死锁日志分事务1,事务2拆分
- 找出发生死锁的SQL
- 找出事务持有什么锁,都在等待什么锁
- SQL加锁分析
事务1日志分析
从日志我们可以看到事务1正在执行的SQL为:
insert into song_rank(songId,weight) values(18,100) on duplicate key update weight=weight+1
该条语句正在等待索引songId_idx的插入意向排他锁:
lock_mode X locks gap before rec insert intention waiting
事务2日志分析
从日志我们可以看到事务2正在执行的SQL为:
insert into song_rank(songId,weight) values(16,100) on duplicate key update weight=weight+1
该语句持有一个索引songId_idx的间隙锁:
lock_mode X locks gap before rec
该条语句正在等待索引songId_idx的插入意向排他锁:
lock_mode X locks gap before rec insert intention waiting
锁相关概念补充(附):
考虑到有些读者可能对上面insert intention锁等不太熟悉,所以这里这里补一小节锁相关概念。
官方文档
InnoDB 锁类型思维导图:
我们主要介绍一下兼容性以及锁模式类型的锁
1.共享锁与排他锁:
InnoDB 实现了标准的行级锁,包括两种:共享锁(简称 s 锁)、排它锁(简称 x 锁)。
- 共享锁(S锁):允许持锁事务读取一行。
- 排他锁(X锁):允许持锁事务更新或者删除一行。
如果事务 T1 持有行 r 的 s 锁,那么另一个事务 T2 请求 r 的锁时,会做如下处理:
- T2 请求 s 锁立即被允许,结果 T1 T2 都持有 r 行的 s 锁
- T2 请求 x 锁不能被立即允许
如果 T1 持有 r 的 x 锁,那么 T2 请求 r 的 x、s 锁都不能被立即允许,T2 必须等待T1释放 x 锁才可以,因为X锁与任何的锁都不兼容。
2.意向锁
- 意向共享锁( IS 锁):事务想要获得一张表中某几行的共享锁
- 意向排他锁( IX 锁): 事务想要获得一张表中某几行的排他锁
比如:事务1在表1上加了S锁后,事务2想要更改某行记录,需要添加IX锁,由于不兼容,所以需要等待S锁释放;如果事务1在表1上加了IS锁,事务2添加的IX锁与IS锁兼容,就可以操作,这就实现了更细粒度的加锁。
InnoDB存储引擎中锁的兼容性如下表:
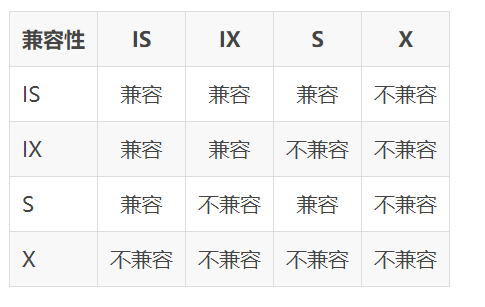
3.记录锁(Record Locks)
- 记录锁是最简单的行锁,仅仅锁住一行。如:
SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE - 记录锁永远都是加在索引上的,即使一个表没有索引,InnoDB也会隐式的创建一个索引,并使用这个索引实施记录锁。
- 会阻塞其他事务对其插入、更新、删除
记录锁的事务数据(关键词:lock_mode X locks rec but not gap),记录如下:
RECORD LOCKS space id 58 page no 3 n bits 72 index `PRIMARY` of table `test`.`t`
trx id 10078 lock_mode X locks rec but not gap
Record lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 6; hex 00000000274f; asc 'O;;
2: len 7; hex b60000019d0110; asc ;;
4.间隙锁(Gap Locks)
- 间隙锁是一种加在两个索引之间的锁,或者加在第一个索引之前,或最后一个索引之后的间隙。
- 使用间隙锁锁住的是一个区间,而不仅仅是这个区间中的每一条数据。
- 间隙锁只阻止其他事务插入到间隙中,他们不阻止其他事务在同一个间隙上获得间隙锁,所以 gap x lock 和 gap s lock 有相同的作用。
5.Next-Key Locks
- Next-key锁是记录锁和间隙锁的组合,它指的是加在某条记录以及这条记录前面间隙上的锁。
6.插入意向锁(Insert Intention)
- 插入意向锁是在插入一行记录操作之前设置的一种间隙锁,这个锁释放了一种插入方式的信号,亦即多个事务在相同的索引间隙插入时如果不是插入间隙中相同的位置就不需要互相等待。
- 假设有索引值4、7,几个不同的事务准备插入5、6,每个锁都在获得插入行的独占锁之前用插入意向锁各自锁住了4、7之间的间隙,但是不阻塞对方因为插入行不冲突。
事务数据类似于下面:
RECORD LOCKS space id 31 page no 3 n bits 72 index `PRIMARY` of table `test`.`child`
trx id 8731 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 80000066; asc f;;
1: len 6; hex 000000002215; asc " ;;
2: len 7; hex 9000000172011c; asc r ;;...
SQL加锁分析:
通过分析死锁日志,我们可以找到发生死锁的SQL,以及相关等待的锁,我们再对对应的SQL进行加锁分析,其实问题就迎刃而解了。
OK,我们回到对应的SQL,insert into song_rank(songId,weight) values(16,100) on duplicate key update weight=weight+1 执行过程到底加了什么锁呢?加锁机制官方文档
insert加锁策略:
insert语句会对插入的这条记录加排他记录锁,在加记录锁之前还会加一种 GAP 锁,叫做插入意向(insert intention)锁,如果出现唯一键冲突,还会加一个共享记录(S)锁。
(SQL加锁分析非常重要,在这里给大家推荐一篇文章,讲的非常好,解决死锁之路 - 常见 SQL 语句的加锁分析)
insert on duplicate key加锁验证
为了验证一下insert on duplicate key加锁情况,我们拿上面demo的事务1和2在走一下流程。
事务1:
mysql> begin; //第一步
Query OK, 0 rows affected (0.00 sec)
mysql> insert into song_rank(songId,weight) values(15,100) on duplicate key
update weight=weight+1; //第二步
Query OK, 1 row affected (0.00 sec)
事务2(另开窗口):
mysql> begin; //第三步
Query OK, 0 rows affected (0.00 sec)
mysql> insert into song_rank(songId,weight) values(16,100) on duplicate key
update weight=weight+1; // 第四步
使用show engine innodb status查看当前锁请求信息,如图:
有图可得:
事务2持有:IX锁(表锁),gap x锁,insert intention lock(在等待事务1的gap锁)
所以,insert on duplicate 执行过程会上这三把锁。
死锁原因分析
回归到本文开头介绍的死锁案发模拟现场(事务1,2,3)以及死锁日志现场,
案发后事务1的锁:
案发后事务2的锁:
案发复原路线:
1.首先,执行事务1执行:
begin;
insert into song_rank(songId,weight) values(15,100) on duplicate key update weight=weight+1;
会获得 gap锁(10,20),insert intention lock(插入意向锁)
2.接着,事务2执行:
begin;
insert into song_rank(songId,weight) values(16,100) on duplicate key update weight=weight+1;
会获得 gap锁(10,20),同时等待事务1的insert intention lock(插入意向锁)。
3.再然后,事务3执行:
begin;
insert into song_rank(songId,weight) values(18,100) on duplicate key update weight=weight+1;
会获得 gap锁(10,20),同时等待事务1的insert intention lock(插入意向锁)。
4.最后,事务1回滚(rollback),释放插入意向锁,导致事务2,3同时持有gap锁,等待insert intention锁,死锁形成!
锁模式兼容矩阵(横向是已持有锁,纵向是正在请求的锁):
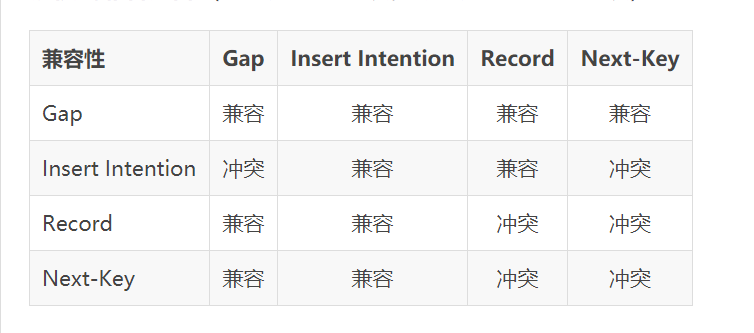
如何避免该insert on duplicate死锁问题
1.把insert on duplicate改为insert
try{
insert();
}catch(DuplicateKeyException e){
update();
}
因为insert不会加gap锁,所以可以避免该问题。
2.更改MySql版本
既然这是MySql5.7的一个bug,那么可以考虑更改Mysql版本。
3.尽量减少使用unique index。
gap锁跟索引有关,并且unique key 和foreign key会引起额外的index检查,需要更大的开销,所以我们尽量减少使用不必要的索引。
本文总结(重要)
本文介绍了MySql5.7死锁的一个bug。我们应该怎样去排查死锁问题呢?
- 1.show engine innodb status;查看死锁日志
- 2.找出死锁SQL
- 3.SQL加锁分析
- 4.分析死锁日志(持有什么锁,等待什么锁)
- 5.熟悉锁模式兼容矩阵,InnoDB存储引擎中锁的兼容性矩阵。
参考与感谢
- 一条Insert on duplicate引发的血案
- 读 MySQL 源码再看 INSERT 加锁流程
- 解决死锁之路 - 了解常见的锁类型
- MySQL InnoDB 锁——官方文档
- MySQL的锁机制 - 记录锁、间隙锁、临键锁
- 解决死锁之路 - 常见 SQL 语句的加锁分析
- 《MySQL技术内幕》
个人公众号
- 如果你是个爱学习的好孩子,可以关注我公众号,一起学习讨论。
- 如果你觉得本文有哪些不正确的地方,可以评论,也可以关注我公众号,私聊我,大家一起学习进步哈。
Mysql死锁如何排查:insert on duplicate死锁一次排查分析过程的更多相关文章
- 死锁问题------------------------INSERT ... ON DUPLICATE KEY UPDATE*(转)
前言 我们在实际业务场景中,经常会有一个这样的需求,插入某条记录,如果已经存在了则更新它如果更新日期或者某些列上的累加操作等,我们肯定会想到使用INSERT ... ON DUPLICATE K ...
- INSERT ... ON DUPLICATE KEY UPDATE产生death lock死锁原理
前言 编辑 我们在实际业务场景中,经常会有一个这样的需求,插入某条记录,如果已经存在了则更新它如果更新日期或者某些列上的累加操作等,我们肯定会想到使用INSERT ... ON DUPLICATE K ...
- MySQL优化--INSERT ON DUPLICATE UPDATE死锁
INSERT ON DUPLICATE UPDATE与死锁 在MySQL中提供两种插入更新的方式:REPLACE INTO和INSERT ON DUPLICATE UPDATE,简化了“存在则更新,不 ...
- mysql 行级锁的使用以及死锁的预防
一.前言 mysql的InnoDB,支持事务和行级锁,可以使用行锁来处理用户提现等业务.使用mysql锁的时候有时候会出现死锁,要做好死锁的预防. 二.MySQL行级锁 行级锁又分共享锁和排他锁. 共 ...
- mysql 插入重复值 INSERT ... ON DUPLICATE KEY UPDATE
向数据库插入记录时,有时会有这种需求,当符合某种条件的数据存在时,去修改它,不存在时,则新增,也就是saveOrUpdate操作.这种控制可以放在业务层,也可以放在数据库层,大多数数据库都支持这种需求 ...
- Mysql中INSERT ... ON DUPLICATE KEY UPDATE的实践
转: Mysql中INSERT ... ON DUPLICATE KEY UPDATE的实践 阿里加多 0.1 2018.03.23 17:19* 字数 492 阅读 2613评论 2喜欢 1 一.前 ...
- mysql INSERT ... ON DUPLICATE KEY UPDATE语句
网上关于INSERT ... ON DUPLICATE KEY UPDATE大多数文章都是同一篇文章转来转去,首先这个语法的目的是为了解决重复性,当数据库中存在某个记录时,执行这条语句会更新它,而不存 ...
- mysql中删除同一行会经常出现死锁?太可怕了
之前有一个同事问到我,为什么多个线程同时去做删除同一行数据的操作,老是报死锁,在线上已经出现好多次了,我问了他几个问题: 1. 是不是在一个事务中做了好几件事情? 答:不是,只做一个删除 ...
- MySQL的INSERT ··· ON DUPLICATE KEY UPDATE使用的几种情况
在MySQL数据库中,如果在insert语句后面带上ON DUPLICATE KEY UPDATE 子句,而要插入的行与表中现有记录的惟一索引或主键中产生重复值,那么就会发生旧行的更新:如果插入的行数 ...
随机推荐
- 【Maven】Mac 使用 zsh 后 mvn 命令就无效
RT -- 解决方法: 打开 .zshrc 文件,将 Maven 环境变量配置加入其中,或者 将 source ~/.bash_profile 添加到 .zshrc 中. PS: 之前搞不懂,每次使用 ...
- 物联网网关MQTT应用与配置测试介绍
1.MQTT介绍: MQTT(Message Queuing Telemetry Transport,消息队列遥测传输协议),作为除Modbus外最常用的协议之一,因其基于发布/订阅的模式,具有资源消 ...
- 一道看似简单的go程序的深入分析
先上代码: func main() { var a [10]int for i := 0; i < 10; i++ { go func(i int) { for { a[i]++ } }(i) ...
- CountDownLatch实现多线程并发请求
package com.test; import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Dat ...
- spark shuffle的写操作之准备工作
前言 在前三篇文章中,spark 源码分析之十九 -- DAG的生成和Stage的划分 剖析了DAG的构建和Stage的划分,spark 源码分析之二十 -- Stage的提交 剖析了TaskSet任 ...
- Resource 使用详解
极力推荐文章:欢迎收藏 Android 干货分享 阅读五分钟,每日十点,和您一起终身学习,这里是程序员Android 本篇文章主要介绍 Android 开发中的部分知识点,通过阅读本篇文章,您将收获以 ...
- Unity经典游戏教程之:是男人就下100层
版权声明: 本文原创发布于博客园"优梦创客"的博客空间(网址:http://www.cnblogs.com/raymondking123/)以及微信公众号"优梦创客&qu ...
- 记一次织梦cms渗透测试
记一次织梦cms渗透测试 0x01 前言 本次测试的整个流程:枚举用户名-针对性暴破-登录后台-后台编辑php文件getshell. 0x02 过程 1.登录功能模块存在用户名枚举缺陷,利用此权限先枚 ...
- spark shuffle读操作
提出问题 1. shuffle过程的数据是如何传输过来的,是按文件来传输,还是只传输该reduce对应在文件中的那部分数据? 2. shuffle读过程是否有溢出操作?是如何处理的? 3. shuff ...
- 记一次IDEA 打包环境JDK版本和生产环境JDK版本不一致引发的血案
问题描述: 本地开发环境idea中能正常运行项目,而idea打war包到Linux服务器的Tomcat下却不能正常运行,报如下错误: 09-Aug-2019 08:56:06.878 SEVERE [ ...