Python爬虫实战:爬取腾讯视频的评论
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 易某某
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
一、前提条件
安装了Fiddler了(用于抓包分析)
谷歌或火狐浏览器
如果是谷歌浏览器,还需要给谷歌浏览器安装一个SwitchyOmega插件,用于代理服务器
有Python的编译环境,一般选择Python3.0及以上
声明:本次爬取腾讯视频里 《最美公里》纪录片的评论。本次爬取使用的浏览器是谷歌浏览器
二、分析思路
1、分析评论页面
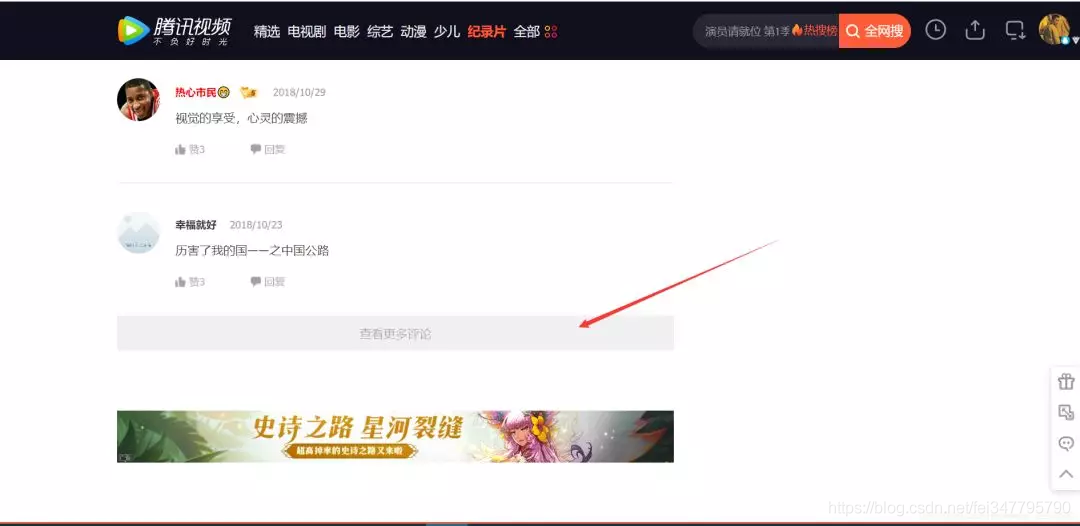
根据上图,我们可以知道:评论使用了Ajax异步刷新技术。这样就不能使用以前分析当前页面找出规律的手段了。因为展示的页面只有部分评论,还有大量的评论没有被刷新出来。
这时,我们应该想到使用抓包来分析评论页面刷新的规律。以后大部分爬虫,都会先使用抓包技术,分析出规律!
2、使用Fiddler进行抓包分析——得出评论网址规律
fiddler如何抓包,这个知识点,需要读者自行去学习,不在本博客讨论范围。
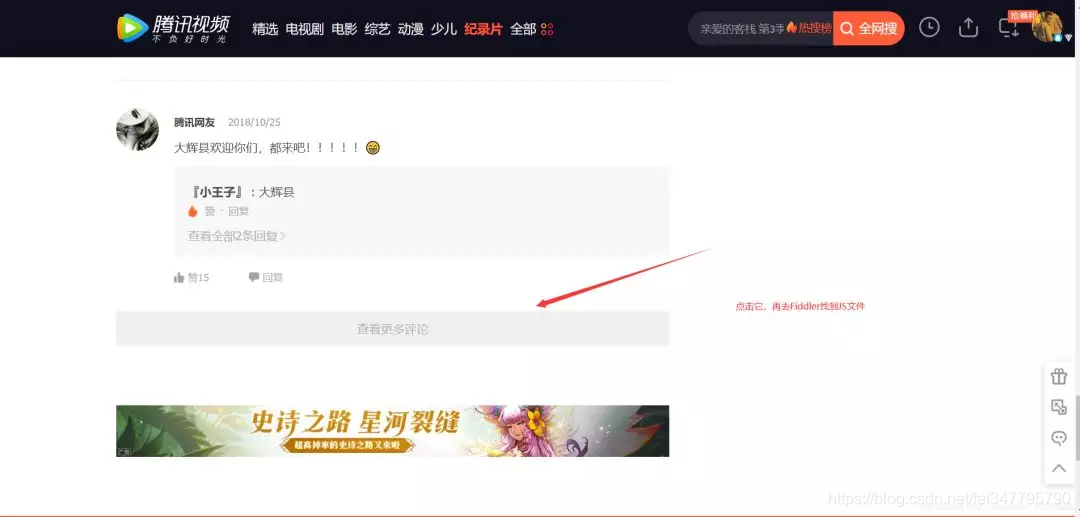
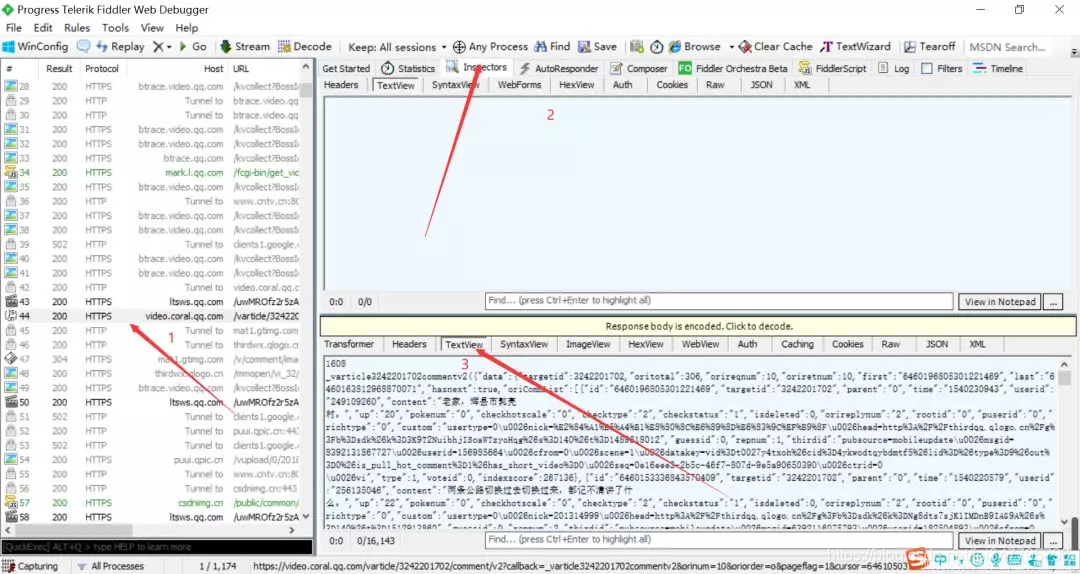
把上面两张图里面的内容对比一下,可以知道这个JS就是评论存放页面。(这需要大家一个一个找,一般Ajax都是在JS里面,所以这也找JS进行对比即可)
我们复制这个JS的url:右击 > copy > Just Url
大家可以重复操作几次,多找几个JS的url,从url得出规律。下图是我刷新了4次得到的JS的url:
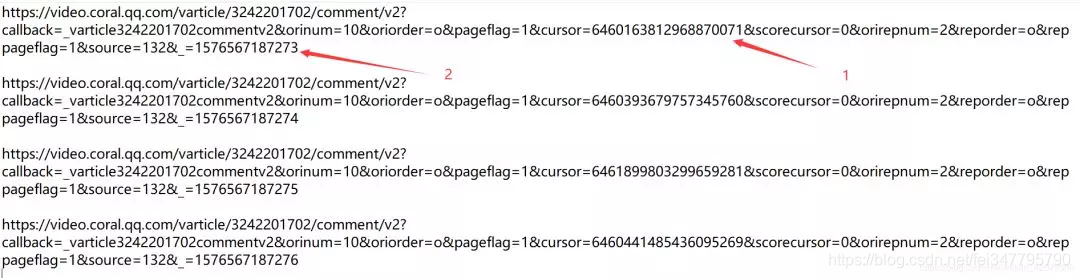
根据上图,我们发现url不同的地方有两处:一是cursor=?;二是_=?。
我们很快就能发现 _=?的规律,它是从1576567187273加1。而cursor=?的规律看不出来。这个时候如何去找到它的规律呢?
百度一下,看前人有没有爬取过这种类型的网站,根据他们的规律和方法,去找出规律;
羊毛出在羊身上。我们需要有的大胆想法——会不会这个cursor=?可以根据上一个JS页面得到呢?这只是很多大胆想法中的一个,我们就一个想法一个想法的试试。
我们就采用第二种方法,去js里面找。复制其中一个url为:
url = https://video.coral.qq.com/varticle/3242201702/comment/v2?callback=_varticle3242201702commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6460163812968870071&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1576567187273
去浏览器里面打开,在里面搜索一下此url的下一个url的cursor=?的值。我们发现一个惊喜!
如下:
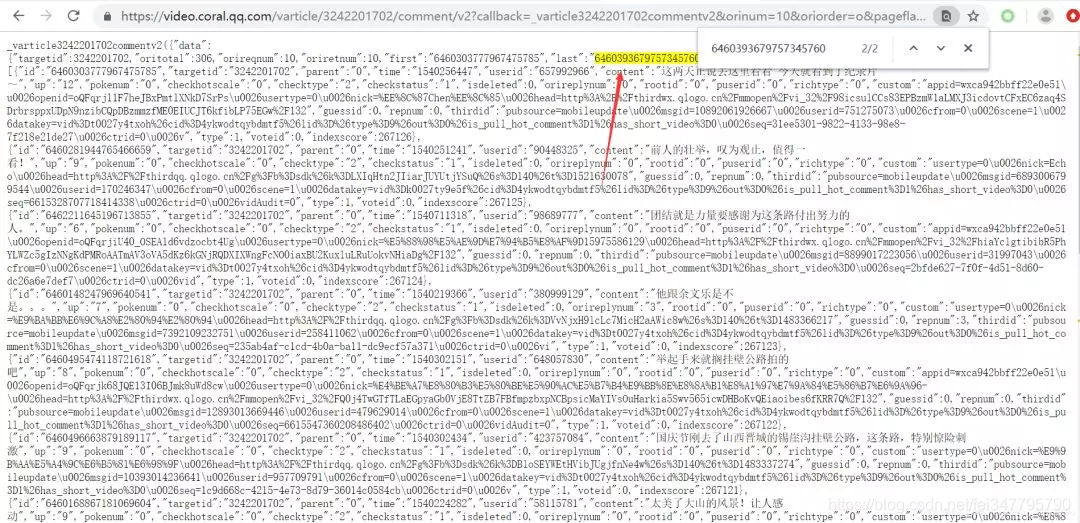
一般情况下,我们还要多试几次,确定我们的想法是正确的。
至此,我们发现了评论的url之间的规律:
_=?从1576567187273加1
cursor=?的值存在上面一个JS中。
三、代码编写
import re
import random
import urllib.request
#构建用户代理
uapools=["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0",
]
#从用户代理池随机选取一个用户代理
def ua(uapools):
thisua=random.choice(uapools)
#print(thisua)
headers=("User-Agent",thisua)
opener=urllib.request.build_opener()
opener.addheaders=[headers]
#设置为全局变量
urllib.request.install_opener(opener)
#获取源码
def get_content(page,lastId):
url="https://video.coral.qq.com/varticle/3242201702/comment/v2?callback=_varticle3242201702commentv2&orinum=10&oriorder=o&pageflag=1&cursor="+lastId+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_="+str(page)
html=urllib.request.urlopen(url).read().decode("utf-8","ignore")
return html
#从源码中获取评论的数据
def get_comment(html):
pat='"content":"(.*?)"'
rst = re.compile(pat,re.S).findall(html)
return rst
#从源码中获取下一轮刷新页的ID
def get_lastId(html):
pat='"last":"(.*?)"'
lastId = re.compile(pat,re.S).findall(html)[0]
return lastId
def main():
ua(uapools)
#初始页面
page=1576567187274
#初始待刷新页面ID
lastId=""
for i in range(1,6):
html = get_content(page,lastId)
#获取评论数据
commentlist=get_comment(html)
print("------第"+str(i)+"轮页面评论------")
for j in range(1,len(commentlist)):
print("第"+str(j)+"条评论:" +str(commentlist[j]))
#获取下一轮刷新页ID
lastId=get_lastId(html)
page += 1
main()
四、结果展示
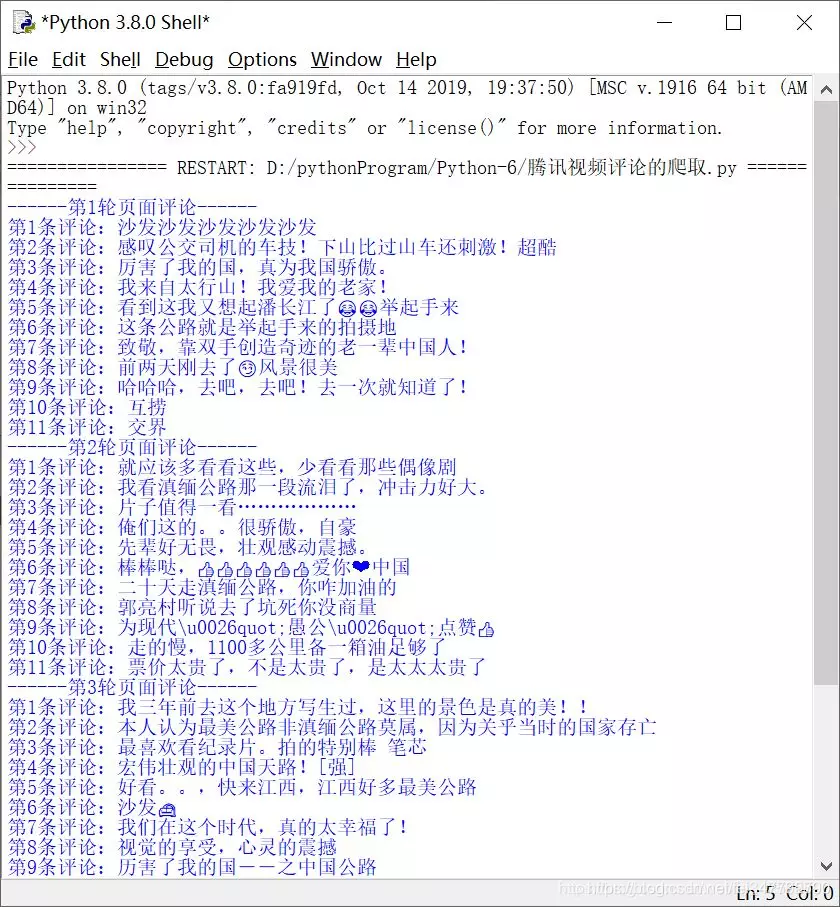 .
.
Python爬虫实战:爬取腾讯视频的评论的更多相关文章
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫实现抓取腾讯视频所有电影【实战必学】
2019-06-27 23:51:51 阅读数 407 收藏 更多 分类专栏: python爬虫 前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问 ...
- Python爬虫,爬取腾讯漫画实战
先上个爬取的结果图 最后的结果为每部漫画按章节保存 运行环境 IDE VS2019 Python3.7 先上代码,代码非常简短,包含空行也才50行,多亏了python强大的库 import os im ...
- python 爬取腾讯视频的全部评论
一.网址分析 查阅了网上的大部分资料,大概都是通过抓包获取.但是抓包有点麻烦,尝试了F12,也可以获取到评论.以电视剧<在一起>为例子.评论最底端有个查看更多评论猜测过去应该是 Ajax ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 用python实现的抓取腾讯视频所有电影的爬虫
1. [代码]用python实现的抓取腾讯视频所有电影的爬虫 # -*- coding: utf-8 -*-# by awakenjoys. my site: www.dianying.atim ...
- 如何手动写一个Python脚本自动爬取Bilibili小视频
如何手动写一个Python脚本自动爬取Bilibili小视频 国庆结束之余,某个不务正业的码农不好好干活,在B站瞎逛着,毕竟国庆嘛,还让不让人休息了诶-- 我身边的很多小伙伴们在朋友圈里面晒着出去游玩 ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
随机推荐
- Spring与Shiro整合 登陆操作
Spring与Shiro整合 登陆操作 作者 : Stanley 罗昊 [转载请注明出处和署名,谢谢!] 编写登陆Controller方法 讲解: 首先,如果你登陆失败的时候,它会把你的异常信息丢到 ...
- 利用堆来处理Top K问题
目录 一.什么是Top K问题 二.Top K的实际应用场景 三.Top K问题的代码实现及其效率对比 1.用堆来实现Top K 2.用快排来实现Top K 3.用堆或用快排来实现 TopK 的效率对 ...
- pyspark报错Exception: Java gateway process exited before sending its port number解决方法
1.问题 搭建spark的python环境好后简单使用,源代码如下: 然后就给我丢了一堆错误: 2.解决办法 这里指定一下Java的环境就可以了,添加代码: import os os.environ[ ...
- day20191120笔记
1.spring的优势 U盘拷.总结.微信公众号:.2.笔试,课前默写,默完之后要回答问题.3.微服务,带着,知识点,卷子.ssm整个东西讲一下.面试是综合能力.背面试题. 通过基础很重要.学精烂熟于 ...
- python排序算法之一:冒泡排序(及其优化)
相信冒泡排序已经被大家所熟知,今天看了一篇文章,大致是说在面试时end在了冒泡排序上,主要原因是不能给出冒泡排序的优化. 所以,今天就写一下python的冒泡排序算法,以及给出一个相应的优化.OK,前 ...
- 剑指Offer-34.数组中的逆序对(C++/Java)
题目: 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对.输入一个数组,求出这个数组中的逆序对的总数P.并将P对1000000007取模的结果输出. 即输出P%10000 ...
- 【Android - 控件】之MD - CardView的使用
CardView是Android 5.0新特性——Material Design中的一个布局控件,可以通过属性设置显示一个圆角的类似卡片的视图. 1.CardView的属性: app:cardCorn ...
- TypeScript躬行记(1)——数据类型
TypeScript不仅支持JavaScript所包含的数据类型,还额外扩展了许多实用的数据类型,例如枚举.空值.任意值等. 一.JavaScript的数据类型 JavaScript的数据类型包括6种 ...
- SpringBoot使用注解(@value)读取properties(yml)文件中 配置信息
为了简化读取properties文件中的配置值,spring支持@value注解的方式来获取,这种方式大大简化了项目配置,提高业务中的灵活性. 1. 两种使用方法1)@Value("#{co ...
- 源码分析 RocketMQ DLedger 多副本存储实现
目录 1.DLedger 存储相关类图 1.1 DLedgerStore 1.2 DLedgerMemoryStore 1.3 DLedgerMmapFileStore 2.DLedger 存储 对标 ...