深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10811587.html
目录
1.达到的目的
2.思路
2.1.强化学习(RL Reinforcement Learing)
2.2.深度学习(卷积神经网络CNN)
3.踩过的坑
4.代码实现(python3.5)
5.运行结果与分析
1.达到的目的
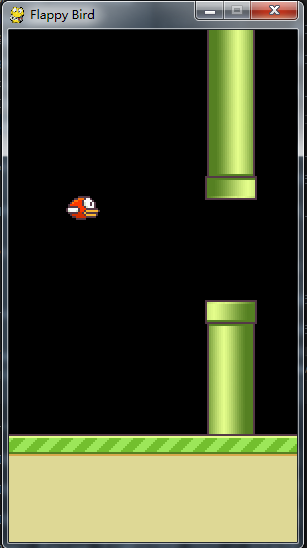
游戏场景:障碍物以一定速度往左前行,小鸟拍打翅膀向上或向下飞翔来避开障碍物,如果碰到障碍物,游戏就GAME OVER!
目的:小鸟通过训练,能够自动识别障碍物,做出正确的动作(向上或向下飞翔)。
2.思路
小鸟飞翔的难点是如何准确判断下一步的动作(向上或向下)?而这正是强化学习想要解决的问题。因为上一节案例网格的所有状态(state)数目是比较小的(16),所以可以通过遍历所有状态,计算所有状态的回报,生成 Q-Table(记录所有状态的价值)。但是本节的应用场景有所不同,它的状态是图片中的像素,如果图片大小是 84 * 84,batch = 4,每个像素大小在[0,255]范围内,有 256 种可能(256 个状态),那么最终 Q-Table 大小是
 数据计算量是非常庞大的。这里我们采用强化学习 + 深度学习(卷积神经网络),也就是 DQN(Deep Q Network)。
数据计算量是非常庞大的。这里我们采用强化学习 + 深度学习(卷积神经网络),也就是 DQN(Deep Q Network)。
卷积神经网络决策目的是预测当前状态所有行为的回报(Q-value)->目标预测值()以及参数的更新;
强化学习的目的是根据马尔科夫决策过程以及贝尔曼价值函数计算出当前状态所有行为的回报 ->目标真实值()
整张图片作为一个状态(因为小鸟不关心是像素还是图片,它只关心它下一步动作的方向),4张图片就是 4 个状态,且这 4 张图片在时间上是连续的。将所有状态(States:80*80*4)以及行为(Actions:1*2)作为卷积神经网络的输入值,卷积神经网络输出为当前状态的所有行为的价值(1*2),结构如下图

2.1 强化学习
贝尔曼最优方程如下(当前状态所有行为价值 = 当前即时奖励 + 下一状态所有行为的价值)
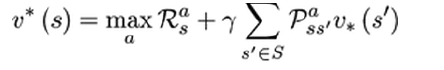
代码实现
readout_j1_batch = sess.run(readout, feed_dict = {s : s_j1_batch})
for i in range(0, len(minibatch)):
terminal = minibatch[i][4]
# if terminal, only equals reward
if terminal: # 碰到障碍物,终止
y_batch.append(r_batch[i])
else: # 即时奖励 + 下一阶段回报
y_batch.append(r_batch[i] + GAMMA * np.max(readout_j1_batch[i]))
minibatch保存了一个batch(32)下当前状态(s_j_batch)、当前行动(a_batch)、当前状态的即时奖励(r_batch)、当前状态下一时刻的状态(s_j1_batch)。
将当前状态下一时刻的状态(s_j1_batch)作为网络模型输入参数,就能得到下一状态(相对当前状态)所有行为的价值(readout_j1_batch),然后通过贝尔曼最优方程计算得到当前状态的Q-value。
大家可能会有这样的疑问:为什么当前状态价值要通过下一个状态价值得到,常规来说都是上一状态价值来得到?
贝尔曼最优方程充分体现了尝试这一核心思想,计算下一个状态价值是为了更新当前状态价值,从而找到最优状态行为。
2.2 深度学习
在输入数据进入神经网络结构之前,需要对图片数据进行预处理,从而减少运算量。
需要安装opencv库:pip install opencv-python,如果下载较慢,可以用国内镜像代替
pip install opencv-python -i http://pypi.douban.com/simple --trusted-host pypi.douban.com。
图片灰度处理:将彩色图片转变为灰度图片,图片大小设置成(80 * 80);
x_t = cv2.cvtColor(cv2.resize(x_t, (80, 80)), cv2.COLOR_BGR2GRAY)
二值化:设置图片像素阈值为 1,大于 1 的像素值更新为 255(白色),反之为 0(黑色)。
ret, x_t = cv2.threshold(x_t,1,255,cv2.THRESH_BINARY)
获取连续帧(4)图片:复制当前帧图片 -> 堆积成4帧图片 -> 将获取到得下一帧图片替换当前第4帧,如此循环就能保证当前的batch图片是连续的。
s_t = np.stack((x_t, x_t, x_t, x_t), axis=2)
s_t1 = np.append(x_t1, s_t[:, :, :3], axis=2)
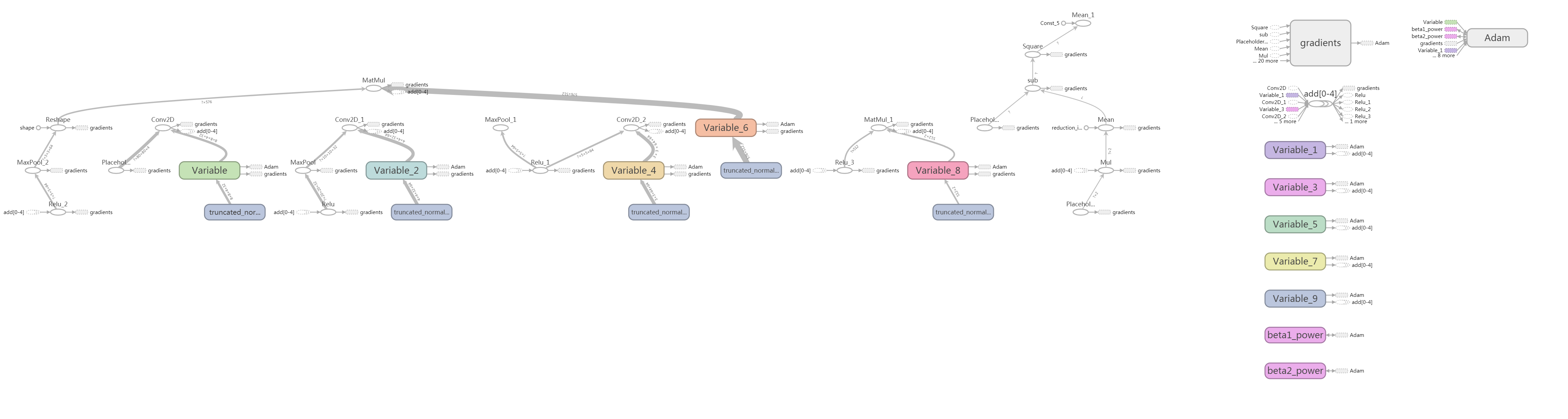
卷积神经网络模型
这里采用了3个卷积层(8*8*4*32, 4*4*32*64,3*3*64*64),3个池化层,4个Relu激活函数,2个全连接层,具体如下图
(建议对照图看代码,注意数据流的变化)

注意:要注意每个卷积层的Stride,因为padding = "SAME",与输入图片卷积后数据宽,高 = 输入图片宽,高/Stride。
比如,输入图片数据与第一个卷积层(8*8*4*32)卷积后,图片数据宽,高 = (80,80)/4 = (20,20),其他层卷积依次类推。
tensorboard可视流程图(具体生成操作步骤见 深度学习之卷积神经网络(CNN)详解与代码实现(二))
图片可能不是很清楚,在图片位置点击鼠标右键->在新标签页面打开图片,就可以放缩图片了。
3.踩过的坑
1.一定要弄明白深度强化学习的输入和输出。
强化学习的核心思想是尝试,深度学习的核心思想是训练。通过不断的将预测值和真实值的残差计算,不断的更新训练模型的参数,使残差值越来越小,最终收敛于一个稳定值,从而得到最佳的训练参数模型。
这里的预测值是通过深度学习得到,而真实值是通过强化学习得到,所以才有了深度强化学习的概念(DQN-Deep Q Network)。
卷积神经网络前向传播输入:4帧连续图片作为不同的状态States;
卷积神经网络前向传播输出:readout(2个不同的方向对应的价值);
卷积神经网络反向传播(通过损失函数获取损失,计算梯度,更新参数)输入:
i.y_batch(32, 2):通过强化学习得到的真实目标值[32 表示神经网络训练时每次批量处理数目,2表示Action不同方向对应的价值 ];
ii.a_batch(32, 2):每个行动的不同方向,在训练时更新步骤:初始化都为0 ->深度学习(卷积神经网络)输出readout_t(1, 2)-> 找到输出价值最大的索引 ->将a_batch中action相同索引置为1(表示最优价值的方向),达到更新得目的。
iii.s_j_batch(32, 80, 80, 4):下一个连续4帧,每一组是4帧,批量处理32组。
2.不要陷入常规的思维模式。
一般常规的思维模式是 A + B => C,这个 C 一般在计算或设计之前,在我们脑海中会计算出来,能够具体化。但是深度学习是打破这一常规思维模式的,它能够通过训练自发的学习,获取内在知识或规则。
以本节为例,在我们脑海中,总是想着下面几个问题
1. 为什么深度学习的结果就是行为的各个方向的价值,而不是其他?
解答:这是根据真实目标值决定的,卷积神经网络的要求是最后的输出值一定要跟真实目标值大小相同。损失函数计算损失,然后更新各个网络层的参数,不停的循环,使输出无限的逼近真实值,稳定后获取模型。
2. 在上一节强化学习时都是人为指定了方向的映射(0=up, 1=right, 2=down, 3=left),为什么深度强化学习不需要指定,它自己就能识别?
解答:当前一组帧和下一组帧之间在时间上是连续的,小鸟的每个动作在时间上也是连续的,通过深度学习后获取的模型其实已经学会了游戏的内在规则,知道在当前状态的下一步动作的方向,所以不需要我们人为指定,这正是深度学习的神奇之处。
4.代码实现(python3.5)
入口在代码最下端main,代码流程分为三个阶段:观察、探索、训练。由 OBSERVE 和 EXPLORE 设定
这也符合一般逻辑,先观察环境,然后再看看怎么飞。所以观察次数一般偏小,其实在探索时就已经在训练了,为什么要分开呢?
分开的目的是考虑更一般的情况,使模型更准确。比如某个状态向上和向下的价值一样,之前都是以向上的价值来计算整个价值,在探索时,我们就考虑向下的价值,然后来更新Q-Table。但是这种探索是随着模型的稳定,次数会越来越少。
工程结构图(整个工程代码可在百度网盘下载: https://pan.baidu.com/s/1faj-BHeYt14g3bNtrzsqXA 提取码: vxeb)
train.py
#!/usr/bin/env python
from __future__ import print_function import tensorflow as tf
import cv2
import sys
sys.path.append("game/")
try:
from . import wrapped_flappy_bird as game
except Exception:
import wrapped_flappy_bird as game
import random
import numpy as np
from collections import deque
'''
先观察一段时间(OBSERVE = 1000 不能过大),
获取state(连续的4帧) => 进入训练阶段(无上限)=> action '''
GAME = 'bird' # the name of the game being played for log files
ACTIONS = 2 # number of valid actions 往上 往下
GAMMA = 0.99 # decay rate of past observations
OBSERVE = 1000. # timesteps to observe before training
EXPLORE = 3000000. # frames over which to anneal epsilon
FINAL_EPSILON = 0.0001 # final value of epsilon 探索
INITIAL_EPSILON = 0.1 # starting value of epsilon
REPLAY_MEMORY = 50000 # number of previous transitions to remember
BATCH = 32 # size of minibatch
FRAME_PER_ACTION = 1 # GAME = 'bird' # the name of the game being played for log files
# ACTIONS = 2 # number of valid actions
# GAMMA = 0.99 # decay rate of past observations
# OBSERVE = 100000. # timesteps to observe before training
# EXPLORE = 2000000. # frames over which to anneal epsilon
# FINAL_EPSILON = 0.0001 # final value of epsilon
# INITIAL_EPSILON = 0.0001 # starting value of epsilon
# REPLAY_MEMORY = 50000 # number of previous transitions to remember
# BATCH = 32 # size of minibatch
# FRAME_PER_ACTION = 1 def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.01)
return tf.Variable(initial) def bias_variable(shape):
initial = tf.constant(0.01, shape = shape)
return tf.Variable(initial)
# padding = ‘SAME’=> new_height = new_width = W / S (结果向上取整)
# padding = ‘VALID’=> new_height = new_width = (W – F + 1) / S (结果向上取整)
def conv2d(x, W, stride):
return tf.nn.conv2d(x, W, strides = [1, stride, stride, 1], padding = "SAME") def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = "SAME")
"""
数据流:80 * 80 * 4
conv1(8 * 8 * 4 * 32, Stride = 4) + pool(Stride = 2)-> 10 * 10 * 32(height = width = 80/4 = 20/2 = 10)
conv2(4 * 4 * 32 * 64, Stride = 2) -> 5 * 5 * 64 + pool(Stride = 2)-> 3 * 3 * 64
conv3(3 * 3 * 64 * 64, Stride = 1) -> 3 * 3 * 64 = 576
576 在定义h_conv3_flat变量大小时需要用到,以便进行FC全连接操作
""" def createNetwork():
# network weights
W_conv1 = weight_variable([8, 8, 4, 32])
b_conv1 = bias_variable([32]) W_conv2 = weight_variable([4, 4, 32, 64])
b_conv2 = bias_variable([64]) W_conv3 = weight_variable([3, 3, 64, 64])
b_conv3 = bias_variable([64]) W_fc1 = weight_variable([576, 512])
b_fc1 = bias_variable([512])
# W_fc1 = weight_variable([1600, 512])
# b_fc1 = bias_variable([512]) W_fc2 = weight_variable([512, ACTIONS])
b_fc2 = bias_variable([ACTIONS]) # input layer
s = tf.placeholder("float", [None, 80, 80, 4]) # hidden layers
h_conv1 = tf.nn.relu(conv2d(s, W_conv1, 4) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2, 2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2) h_conv3 = tf.nn.relu(conv2d(h_conv2, W_conv3, 1) + b_conv3)
h_pool3 = max_pool_2x2(h_conv3) h_pool3_flat = tf.reshape(h_pool3, [-1, 576])
#h_conv3_flat = tf.reshape(h_conv3, [-1, 1600]) h_fc1 = tf.nn.relu(tf.matmul(h_pool3_flat, W_fc1) + b_fc1)
#h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat, W_fc1) + b_fc1) # readout layer
readout = tf.matmul(h_fc1, W_fc2) + b_fc2 return s, readout, h_fc1 def trainNetwork(s, readout, h_fc1, sess):
# define the cost function
a = tf.placeholder("float", [None, ACTIONS])
y = tf.placeholder("float", [None])
# reduction_indices = axis 0 : 列 1: 行
# 因 y 是数值,而readout: 网络模型预测某个行为的回报 大小[1, 2] 需要将readout 转为数值,
# 所以有tf.reduce_mean(tf.multiply(readout, a), axis=1) 数组乘法运算,再求均值。
# 其实,这里readout_action = tf.reduce_mean(readout, axis=1) 直接求均值也是可以的。
readout_action = tf.reduce_mean(tf.multiply(readout, a), axis=1)
cost = tf.reduce_mean(tf.square(y - readout_action))
train_step = tf.train.AdamOptimizer(1e-6).minimize(cost) # open up a game state to communicate with emulator
game_state = game.GameState()
# 创建队列保存参数
# store the previous observations in replay memory
D = deque() # printing
a_file = open("logs_" + GAME + "/readout.txt", 'w')
h_file = open("logs_" + GAME + "/hidden.txt", 'w') # get the first state by doing nothing and preprocess the image to 80x80x4
do_nothing = np.zeros(ACTIONS)
do_nothing[0] = 1
x_t, r_0, terminal = game_state.frame_step(do_nothing)
#cv2.imwrite('x_t.jpg',x_t)
x_t = cv2.cvtColor(cv2.resize(x_t, (80, 80)), cv2.COLOR_BGR2GRAY)
ret, x_t = cv2.threshold(x_t,1,255,cv2.THRESH_BINARY)
s_t = np.stack((x_t, x_t, x_t, x_t), axis=2) # saving and loading networks
tf.summary.FileWriter("tensorboard/", sess.graph)
saver = tf.train.Saver()
sess.run(tf.initialize_all_variables())
checkpoint = tf.train.get_checkpoint_state("saved_networks")
"""
if checkpoint and checkpoint.model_checkpoint_path:
saver.restore(sess, checkpoint.model_checkpoint_path)
print("Successfully loaded:", checkpoint.model_checkpoint_path)
else:
print("Could not find old network weights")
"""
# start training
epsilon = INITIAL_EPSILON
t = 0
while "flappy bird" != "angry bird":
# choose an action epsilon greedily
# 预测结果(当前状态不同行为action的回报,其实也就 往上,往下 两种行为)
readout_t = readout.eval(feed_dict={s : [s_t]})[0]
a_t = np.zeros([ACTIONS])
action_index = 0
if t % FRAME_PER_ACTION == 0:
# 加入一些探索,比如探索一些相同回报下其他行为,可以提高模型的泛化能力。
# 且epsilon是随着模型稳定趋势衰减的,也就是模型越稳定,探索次数越少。
if random.random() <= epsilon:
# 在ACTIONS范围内随机选取一个作为当前状态的即时行为
print("----------Random Action----------")
action_index = random.randrange(ACTIONS)
a_t[action_index] = 1
else:
# 输出 奖励最大就是下一步的方向
action_index = np.argmax(readout_t)
a_t[action_index] = 1
else:
a_t[0] = 1 # do nothing # scale down epsilon 模型稳定,减少探索次数。
if epsilon > FINAL_EPSILON and t > OBSERVE:
epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / EXPLORE # run the selected action and observe next state and reward
x_t1_colored, r_t, terminal = game_state.frame_step(a_t)
# 先将尺寸设置成 80 * 80,然后转换为灰度图
x_t1 = cv2.cvtColor(cv2.resize(x_t1_colored, (80, 80)), cv2.COLOR_BGR2GRAY)
# x_t1 新得到图像,二值化 阈值:1
ret, x_t1 = cv2.threshold(x_t1, 1, 255, cv2.THRESH_BINARY)
x_t1 = np.reshape(x_t1, (80, 80, 1))
#s_t1 = np.append(x_t1, s_t[:,:,1:], axis = 2)
# 取之前状态的前3帧图片 + 当前得到的1帧图片
# 每次输入都是4幅图像
s_t1 = np.append(x_t1, s_t[:, :, :3], axis=2) # store the transition in D
# s_t: 当前状态(80 * 80 * 4)
# a_t: 即将行为 (1 * 2)
# r_t: 即时奖励
# s_t1: 下一状态
# terminal: 当前行动的结果(是否碰到障碍物 True => 是 False =>否)
# 保存参数,队列方式,超出上限,抛出最左端的元素。
D.append((s_t, a_t, r_t, s_t1, terminal))
if len(D) > REPLAY_MEMORY:
D.popleft() # only train if done observing
if t > OBSERVE:
# 获取batch = 32个保存的参数集
minibatch = random.sample(D, BATCH)
# get the batch variables
# 获取j时刻batch(32)个状态state
s_j_batch = [d[0] for d in minibatch]
# 获取batch(32)个行动action
a_batch = [d[1] for d in minibatch]
# 获取保存的batch(32)个奖励reward
r_batch = [d[2] for d in minibatch]
# 获取保存的j + 1时刻的batch(32)个状态state
s_j1_batch = [d[3] for d in minibatch]
# readout_j1_batch =>(32, 2)
y_batch = []
readout_j1_batch = sess.run(readout, feed_dict = {s : s_j1_batch})
for i in range(0, len(minibatch)):
terminal = minibatch[i][4]
# if terminal, only equals reward
if terminal: # 碰到障碍物,终止
y_batch.append(r_batch[i])
else: # 即时奖励 + 下一阶段回报
y_batch.append(r_batch[i] + GAMMA * np.max(readout_j1_batch[i]))
# 根据cost -> 梯度 -> 反向传播 -> 更新参数
# perform gradient step
# 必须要3个参数,y, a, s 只是占位符,没有初始化
# 在 train_step过程中,需要这3个参数作为变量传入
train_step.run(feed_dict = {
y : y_batch,
a : a_batch,
s : s_j_batch}
) # update the old values
s_t = s_t1 # state 更新
t += 1 # save progress every 10000 iterations
if t % 10000 == 0:
saver.save(sess, 'saved_networks/' + GAME + '-dqn', global_step = t) # print info
state = ""
if t <= OBSERVE:
state = "observe"
elif t > OBSERVE and t <= OBSERVE + EXPLORE:
state = "explore"
else:
state = "train" print("terminal", terminal, \
"TIMESTEP", t, "/ STATE", state, \
"/ EPSILON", epsilon, "/ ACTION", action_index, "/ REWARD", r_t, \
"/ Q_MAX %e" % np.max(readout_t))
# write info to files
'''
if t % 10000 <= 100:
a_file.write(",".join([str(x) for x in readout_t]) + '\n')
h_file.write(",".join([str(x) for x in h_fc1.eval(feed_dict={s:[s_t]})[0]]) + '\n')
cv2.imwrite("logs_tetris/frame" + str(t) + ".png", x_t1)
''' def playGame():
sess = tf.InteractiveSession()
s, readout, h_fc1 = createNetwork()
trainNetwork(s, readout, h_fc1, sess) def main():
playGame() if __name__ == "__main__":
main()
5.运行结果与分析
因为不能上传视频,所以只能截取几张典型图片了。我训练了2920000次生成的模型,以这个模型预测,小鸟能够自动识别障碍物,不会发生碰撞。按如下配置训练和预测:
训练:OBSERVE = 1000,EXPLORE = 3000000
预测:OBSERVE = 100000,EXPLORE = 3000000 (预测是引用模型,所以不需要训练,OBSERVE要尽可能大)
预测时在train.py文件中将下面引用模型注释打开
"""
if checkpoint and checkpoint.model_checkpoint_path:
saver.restore(sess, checkpoint.model_checkpoint_path)
print("Successfully loaded:", checkpoint.model_checkpoint_path)
else:
print("Could not find old network weights")
"""
小鸟运行结果图片



在预测状态,运行代码,小鸟会自动飞翔,这时也会相应打印一些参数结果出来:

参数结果
terminal:是否碰撞到障碍物(True :是,False:否);
TIMESTEP:表示运行次数;
STATE:当前模型运行状态(observe:观察,explore:探索,train:训练);
EPSILON:表示进入探索阶段的阈值,是逐渐减小的;
ACTION:行动方向最大价值的索引;
REWARD:即时奖励;
Q_MAX:输出行动方向的最大价值;
不要让懒惰占据你的大脑,不要让妥协拖垮了你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐就掌握在你的脚下。
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird的更多相关文章
- 【转】【强化学习】Deep Q Network(DQN)算法详解
原文地址:https://blog.csdn.net/qq_30615903/article/details/80744083 DQN(Deep Q-Learning)是将深度学习deeplearni ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 深度强化学习:Deep Q-Learning
在前两篇文章强化学习基础:基本概念和动态规划和强化学习基础:蒙特卡罗和时序差分中介绍的强化学习的三种经典方法(动态规划.蒙特卡罗以及时序差分)适用于有限的状态集合$\mathcal{S}$,以时序差分 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 5G网络的深度强化学习:联合波束成形,功率控制和干扰协调
摘要:第五代无线通信(5G)支持大幅增加流量和数据速率,并提高语音呼叫的可靠性.在5G无线网络中共同优化波束成形,功率控制和干扰协调以增强最终用户的通信性能是一项重大挑战.在本文中,我们制定波束形成, ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
随机推荐
- PHP数组具有的特性有哪些
PHP 的数组是一种非常强大灵活的数据类型.以下是PHP数组具有的一些特性: 1.可以使用数字或字符串作为数组键值 1 $arr = [1 => 'ok', 'one' => 'hello ...
- Django--导出项目依赖库requirements.txt
虚拟环境下: 1.导出项目依赖库: pip freeze > requirements.txt 2.使用 pip 一次性安装项目的所有依赖项,方法是在命令行中输入: pip install - ...
- linux服务器cpu信息查看详解
在linux系统中,提供了/proc目录下文件,显示系统的软硬件信息.如果想了解系统中CPU的提供商和相关配置信息,则可以查/proc/cpuinfo.但是此文件输出项较多,不易理解.例如我们想获取, ...
- JS三座大山再学习(三、异步和单线程)
本文已发布在西瓜君的个人博客,原文传送门 前言 写这一篇的时候,西瓜君查阅了很多资料和文章,但是相当多的文章写的都很简单,甚至互相之间有矛盾,这让我很困扰:同时也让我坚定了要写出一篇好的关于JS异步. ...
- scrapy项目部署
什么是scrapyd Scrapyd是部署和运行Scrapy.spider的应用程序.它使您能够使用JSON API部署(上传)您的项目并控制其spider. 特点: 可以避免爬虫源码被看到. 有版本 ...
- 浏览器中的 Event Loop
当我们执行 JS 代码的时候其实就是往执行栈中放入函数,那么遇到异步代码的时候该怎么办?其实当遇到异步的代码时,会被挂起并在需要执行的时候加入到 Task(有多种 Task) 队列中.一旦执行栈为空, ...
- Hadoop streaming脚本中约束关系参数详解
1 -D mapred.output.key.comparator.class=org.apache.hadoop.mapred.lib.KeyFieldBasedComparator \ 2 -D ...
- U盘安装centos 7 提示 “Warning: /dev/root does not exist
背景介绍:公司需要使用台式机安装Centos 7.5 系统,来部署一个测试的数据库,在安装Centos 7.5 系统的时候,使用U启安装,但有问题. 提示信息如下 如图:安装centos 7时提示 & ...
- 阿里架构师花近十年时间整理出来的Java核心知识pdf(Java岗)
由于细节内容实在太多啦,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容! 整理了一份Java核心知识点.覆盖了JVM.锁.并发.Java反射.Spring原理.微服务.Zooke ...
- 【SSL1194】最优乘车
题面: 正文: 把每个边用链式前向星存起来,边权为\(1\),就可以愉♂快♂地最短路了