序列标注(BiLSTM-CRF/Lattice LSTM)
前言
在三大特征提取器中,我们已经接触了LSTM/CNN/Transormer三种特征提取器,这一节我们将介绍如何使用BiLSTM实现序列标注中的命名实体识别任务,以及Lattice-LSTM的模型原理。
本文提到的模型在我的Github中均有相应代码实现(Lattice LSTM之后更新)
BiLSTM
对于LSTM我就不再多做介绍了,想要了解的小伙伴可以看我之前的文章。BiLSTM就是双向LSTM,正向和反向提取句子信息,将正向和反向输出拼接在一起组成模型输出。
既然我们将BiLSTM看作特征提取器,意味着他的输出我们可以将其看作特征,作为另一个模型的输入来用。有了这种思想,我们将BiLSTM的输出输入一个简单的全连接神经网络就可以实现简单的分类了。
BiLSTM-CRF
如果仅仅将BiLSTM最后全连接神经网络进行分类,这就意味着,每一个标签输出,只由上下文决定,即:
\[P(y_t|X, Y) = P(y_t|X)\]
但实际上,我们上一节了解到的,序列标注任务中,不同字的隐藏状态之间通常是由相互联系的,如之前提到的IOBES标注,标签S(单个实体),则其前后必定是标签O(非实体字),标签I(实体中间字),则其前后必定只会是I、B(实体开头字)、E(实体结尾字)。显然,这些信息是不会包含在上述模型中的。
为了能够考虑到隐藏状态之间的相互关系,上文介绍的CRF模型就能提供作用了。我们记得之前的CRF模型参数化条件概率定义如下:
\[P(y|x)=\frac{1}{Z}exp(\sum_j\sum_{i=1}^{n-1}\lambda_it_j(y_{i+1}, y_i, x, i)+ \sum_k\sum_{i=1}^{n}\mu_ks_k(y_i, x, i))\]
其中:
\(t_j(y_{i-1}, y_i, x, i)\)为局部特征函数,该特征由当前节点和上一个节点决定,称其为状态转移特征,用以描述相邻节点以及观测变量对当前状态的影响;
\(s_k(y_i, x, i)\)为节点特征函数,该特征函数只和当前节点有关,称其为状态特征;
\(\lambda\)和\(\mu\)是对应特征函数的参数。
实际上,特征函数\(t(·)\)就包含了我们之前提到的隐藏状态之间的相互关系,\(s(·)\)包含了观察变量的特征表示对相应隐藏状态的关系。之前我们提到过,将上述两个特征函数看作可学习参数的一部分,然后将其整合到状态转移矩阵中去了。在代码实现中,我们仅仅需要学习一个状态转移矩阵,就能实现一个完整的CRF,实际上,这个状态转移矩阵中,就包含了两个特征函数信息。CRF对LSTM信息的再利用,显然比一个简单的分类模型要强。
Lattice LSTM
之前我们讨论的明明实体识别问题都是基于字的,主要是因为分词过程将引入很多误差来源,例如之前提到的OOV问题。但没有分词的过程使得基于字符的NER模型无法利用显性的词和词序信息来提取当前最有用的实体。如下图
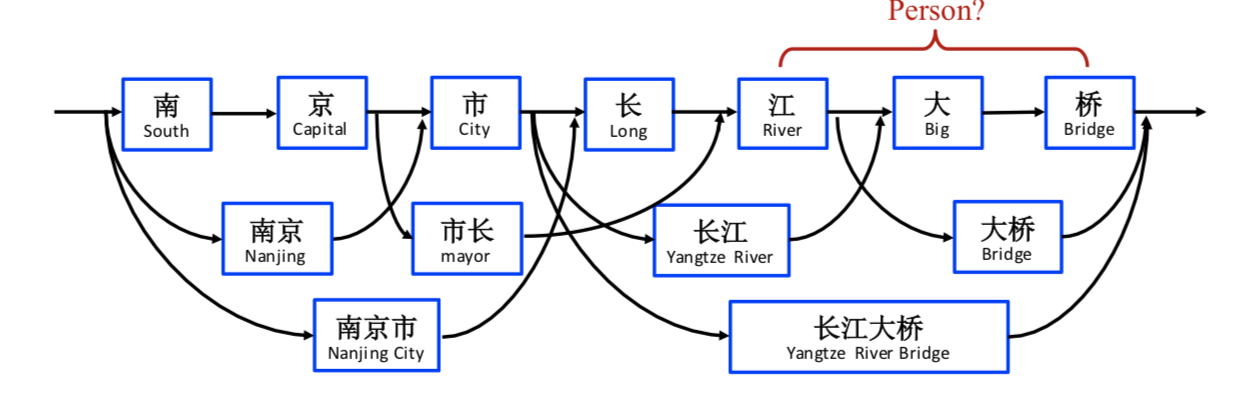
如果没有加入显性的词序信息,模型难以根据上下文判断该句应该识别出来地名“南京市/长江大桥”还是应该识别出人物“南京市长/江大桥”。Lattice LSTM的做法是构造一个潜在实体词典,当匹配到潜在实体出现的时候,将该潜在实体的信息输入到模型中辅助判断,从而实现潜在相关命名实体消歧。其大致模型结构如下图所示
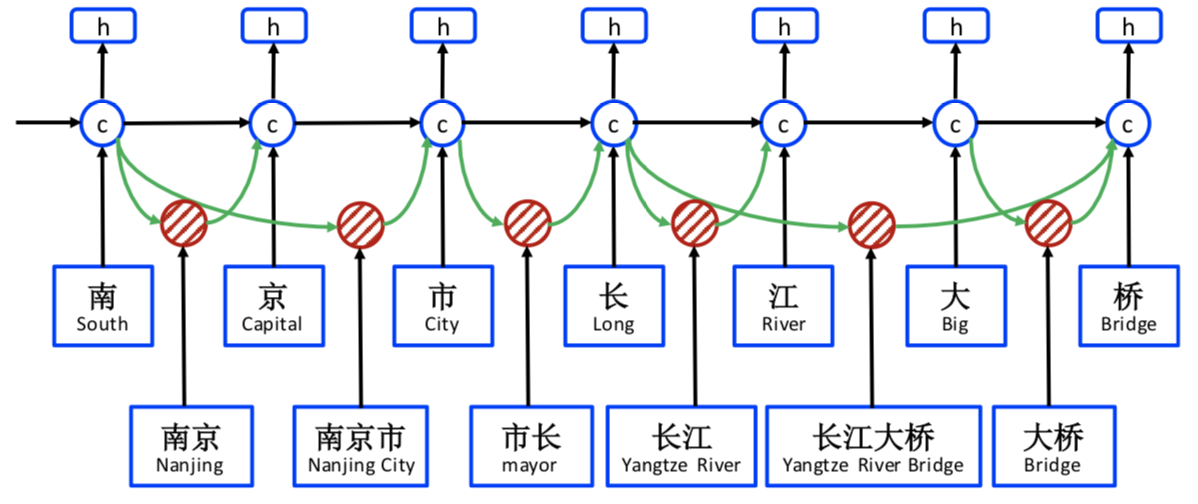
模型的细节可以参考官方给出的代码,之后我有时间再给出自己的实现。
参考链接
https://arxiv.org/pdf/1805.02023.pdf
https://www.jianshu.com/p/9c99796ff8d9
https://zhuanlan.zhihu.com/p/38941381
序列标注(BiLSTM-CRF/Lattice LSTM)的更多相关文章
- DL4NLP —— 序列标注:BiLSTM-CRF模型做基于字的中文命名实体识别
三个月之前 NLP 课程结课,我们做的是命名实体识别的实验.在MSRA的简体中文NER语料(我是从这里下载的,非官方出品,可能不是SIGHAN 2006 Bakeoff-3评测所使用的原版语料)上训练 ...
- TensorFlow (RNN)深度学习 双向LSTM(BiLSTM)+CRF 实现 sequence labeling 序列标注问题 源码下载
http://blog.csdn.net/scotfield_msn/article/details/60339415 在TensorFlow (RNN)深度学习下 双向LSTM(BiLSTM)+CR ...
- TensorFlow教程——Bi-LSTM+CRF进行序列标注(代码浅析)
https://blog.csdn.net/guolindonggld/article/details/79044574 Bi-LSTM 使用TensorFlow构建Bi-LSTM时经常是下面的代码: ...
- Bi-LSTM+CRF在文本序列标注中的应用
传统 CRF 中的输入 X 向量一般是 word 的 one-hot 形式,前面提到这种形式的输入损失了很多词语的语义信息.有了词嵌入方法之后,词向量形式的词表征一般效果比 one-hot 表示的特征 ...
- ALBERT+BiLSTM+CRF实现序列标注
一.模型框架图 二.分层介绍 1)ALBERT层 albert是以单个汉字作为输入的(本次配置最大为128个,短句做padding),两边分别加上开始标识CLS和结束标识SEP,输出的是每个输入wor ...
- LSTM+CRF进行序列标注
为什么使用LSTM+CRF进行序列标注 直接使用LSTM进行序列标注时只考虑了输入序列的信息,即单词信息,没有考虑输出信息,即标签信息,这样无法对标签信息进行建模,所以在LSTM的基础上引入一个标签转 ...
- NLP之CRF应用篇(序列标注任务)
1.CRF++的详细解析 完成的是学习和解码的过程:训练即为学习的过程,预测即为解码的过程. 模板的解析: 具体参考hanlp提供的: http://www.hankcs.com/nlp/the-cr ...
- BiLSTM:序列标注任务的标杆
Bidirectional LSTM-CRF Models for Sequence Tagging. Zhiheng Huang. 2015 在2015年,本文第一个提出使用BiLSTM-CRF来做 ...
- 转:TensorFlow入门(六) 双端 LSTM 实现序列标注(分词)
http://blog.csdn.net/Jerr__y/article/details/70471066 欢迎转载,但请务必注明原文出处及作者信息. @author: huangyongye @cr ...
随机推荐
- appium在windows系统下环境搭建
对于appium的介绍我就不说了,之前的文章介绍过.下面直入主题. 命令版本在安装过程中需要有python2环境,装完你可以装python3来写脚本. 环境要求: JDK >java语言安装包 ...
- centos7安装使用docker-tomcat-mysql
windows安装centos虚拟机 下载安装 virtualBox下载 https://mirrors.tuna.tsinghua.edu.cn/help/virtualbox/ centos7镜像 ...
- Python MySQL 数据库
python DB API python访问数据库的统一接口规范,完成不同数据库的访问 包含的内容: connection cursor exceptions 访问数据库流程: 1.创建connect ...
- effective java 3th item2:考虑 builder 模式,当构造器参数过多的时候
yiaz 读书笔记,翻译于 effective java 3th 英文版,可能有些地方有错误.欢迎指正. 静态工厂方法和构造器都有一个限制:当有许多参数的时候,它们不能很好的扩展. 比如试想下如下场景 ...
- CodeForces 677D. Vanya and Treasure 枚举行列
677D. Vanya and Treasure 题意: 给定一张n*m的图,图上每个点标有1~p的值,你初始在(1,1)点,你必须按照V:1,2,3...p的顺序走图上的点,问你如何走时间最少. 思 ...
- GRE Words Revenge AC自动机 二进制分组
GRE Words Revenge 题意和思路都和上一篇差不多. 有一个区别就是需要移动字符串.关于这个字符串,可以用3次reverse来转换, 前面部分翻转一下, 后面部分翻转一下, 最后整个串翻转 ...
- codeforces 459 D. Pashmak and Parmida's problem(思维+线段树)
题目链接:http://codeforces.com/contest/459/problem/D 题意:给出数组a,定义f(l,r,x)为a[]的下标l到r之间,等于x的元素数.i和j符合f(1,i, ...
- Webstorm 的设置
背景色
- 自定义Hive UDAF 实现相邻去重
内置的两个聚合函数(UDAF) collect_list():多行字符串拼接为一行collect_set():多行字符串拼接为一行并去重多行字符串拼接为一行并相邻去重UDAF:Concat() con ...
- 搭建Nuget服务器(Nuget私服)
一.前言 对公司或者对个人来说,经过一段时间的沉淀之后,都会有一些框架或者模块,为了对这些框架或者模块进行更好的管理和维护,也为了方便后面的开发或者其他同事,我们可以在我们本地或者内网搭建一个Nuge ...