隐马尔科夫模型HMM介绍
马尔科夫链是描述状态转换的随机过程,该过程具备“无记忆”的性质:即当前时刻$t$的状态$s_t$的概率分布只由前一时刻$t-1$的状态$s_{t-1}$决定,与时间序列中$t-1$时刻之前的状态无关。定义马尔科夫链的转移矩阵为$A$,有$$A_{ij}=p\left(s_{t}=j | s_{t-1}=i\right),\text{ }s_{t} | s_{t-1} \sim \operatorname{Discrete}\left(A_{s_{t-1}, :}\right)$$容易看出矩阵$A$的每行之和为1,给定一个起始状态$s_1$(也可通过某个分布产生),可通过从上述分布中抽样生成序列$\left(s_{1}, s_2, \dots, s_{t}\right)$。
模型定义
隐马尔科夫模型HMM假设观测是从一个隐藏的马尔科夫状态序列生成的,如下图所示:

- 不失一般性,假设共有$S$个离散状态,即$s \in \{1,2,\dots,S\}$
- 不失一般性,假设共有$X$种观测,即$x \in \{1,2,\dots,X\}$
- 定义初始的状态分布为$\vec{\pi}=(\pi_1,\pi_2,\dots,\pi_S)$,即$s_{1} \sim \operatorname{Discrete}(\vec{\pi})$
- 定义状态$s$的转移矩阵为$\mathcal{A}$,则$\mathcal{A}$为$S$行$S$列的矩阵,即$s_{i} |\left\{s_{i-1}=k^{\prime}\right\} \sim \operatorname{Discrete}\left(\mathcal{A}_{k^{\prime}, :}\right)$
- 定义观测$x$的生成概率为$\mathcal{B}$,则$\mathcal{B}$为$S$行$X$列的矩阵,即$x_{i} |\left\{s_{i}=k^{\prime}\right\} \sim \operatorname{Discrete}\left(\mathcal{B}_{k^{\prime}, :}\right)$
则HMM的求解可归纳为以下两个问题:
- 训练:已知观测序列$\vec{o}=(x_1,x_2,\dots,x_T)$,使用最大似然估计计算参数$\vec{\pi},\mathcal{A},\mathcal{B}$,即$$\vec{\pi}_{\mathrm{ML}}, \mathcal{A}_{\mathrm{ML}}, \mathcal{B}_{\mathrm{ML}}=\arg \max _{\vec{\pi},\mathcal{A},\mathcal{B}} p\left(\vec{o} | \vec{\pi},\mathcal{A},\mathcal{B}\right)$$
- 预测:已知观测序列$\vec{o}$以及参数$\vec{\pi},\mathcal{A},\mathcal{B}$,估计生成观测序列$\vec{o}$的最可能的隐藏状态序列$\vec{s}=(s_{1}, \ldots, s_{T})$,即$$s_{1}, \ldots, s_{T}=\arg \max _{\vec{s}} p\left(\vec{s} | \vec{o}, \vec{\pi},\mathcal{A},\mathcal{B}\right)$$
参数估计
要解决问题1,首先看一下如何估计$p\left(\vec{o} | \vec{\pi},\mathcal{A},\mathcal{B}\right)$,根据概率公式,有$$\begin{aligned} p(\vec{o} | \vec{\pi}, \mathcal{A}, \mathcal{B}) &=\sum_{s_{1}=1}^{S} \cdots \sum_{s_{T}=1}^{S} p\left(\vec{o}, s_{1}, \ldots, s_{T} | \vec{\pi}, \mathcal{A},\mathcal{B}\right) \\ &=\sum_{s_{1}=1}^{S} \cdots \sum_{s_{T}=1}^{S} \pi_{s_1}\mathcal{B}_{s_1,x_1}\prod_{i=2}^{T}\mathcal{A}_{s_{i-1},s_i}\mathcal{B}_{s_i,x_i} \end{aligned}$$如果按上述公式直接进行计算,复杂度为$\mathcal{O}(TS^T)$,效率太低,考虑使用动态规划的思想,将算法复杂度降为$\mathcal{O}(TS^2)$,可以使用两种方式:
1. Forward Algorithm
- 定义$\alpha_{t}(j)=p\left(x_{1}, x_{2} \ldots x_{t}, s_{t}=j | \vec{\pi}, \mathcal{A},\mathcal{B}\right),\text{ }t\in\{1,2,\cdots,T\},\text{ }j\in\{1,2,\cdots,S\}$,则算法可以写为:
- Initialization: $\alpha_{1}(j)=\pi_j\mathcal{B}_{j,x_1}; \quad 1 \leq j \leq S$
- Recursion: $\alpha_{t}(j)=\sum_{i=1}^{S} \alpha_{t-1}(i) \mathcal{A}_{i j} \mathcal{B}_{j,x_t} ; \quad 1 \leq j \leq S, 1<t \leq T$
- Termination: $p\left(\vec{o} | \vec{\pi},\mathcal{A},\mathcal{B}\right)=\sum_{i=1}^{S} \alpha_{T}(i)$
2. Backward Algorithm
- 定义$\beta_{t}(i)=p\left(x_{t+1}, x_{t+2} \ldots x_{T} | s_{t}=i, \vec{\pi}, \mathcal{A},\mathcal{B}\right),\text{ }t\in\{1,2,\cdots,T\},\text{ }i\in\{1,2,\cdots,S\}$,则算法可以写为:
- Initialization: $\beta_{T}(i)=1; \quad 1 \leq i \leq S$
- Recursion: $\beta_{t}(i)=\sum_{j=1}^{S} \mathcal{A}_{i j} \mathcal{B}_{j,x_{t+1}} \beta_{t+1}(j) ; \quad 1 \leq i \leq S, 1 \leq t < T$
- Termination: $p\left(\vec{o} | \vec{\pi},\mathcal{A},\mathcal{B}\right)=\sum_{j=1}^{S} \pi_{j} \mathcal{B}_{j,x_1} \beta_{1}(j)$
使用EM算法求解$\vec{\pi}_{\mathrm{ML}}, \mathcal{A}_{\mathrm{ML}}, \mathcal{B}_{\mathrm{ML}}$,关于EM算法的具体介绍可参考文章EM算法和高斯混合模型GMM介绍。具体到该问题,又被称为Forward-Backward Algorithm(i.e., Baum-Welch Algorithm):
- 假设参数的当前估计值$\mathcal{\Lambda}^*=[\vec{\pi}^*,\mathcal{A}^*,\mathcal{B}^*]$,则有
- E-step: 定义$q(\vec{s})=p(\vec{s} | \vec{o}, \mathcal{\Lambda}^*)$,则$\mathcal{L}(\mathcal{\Lambda})=\mathbb{E}_{q}[\ln p(\vec{o}, \vec{s} | \mathcal{\Lambda})]$。容易看出$$\ln p(\vec{o}, \vec{s} | \mathcal{\Lambda})= \underbrace{\ln \pi_{s_1}}_{\text{ initial state }} +\sum_{t=2}^{T} \underbrace{\ln \mathcal{A}_{s_{t-1}, s_t}}_{\text { Markov chain }} + \sum_{t=1}^{T} \underbrace{\ln \mathcal{B}_{s_t, x_t}}_{\text { observations }}$$因此$\mathcal{L}$的形式可写为$$\mathcal{L}(\mathcal{\Lambda})=\sum_{k=1}^{S} \gamma_{1}(k) \ln \pi_{k}+\sum_{t=2}^{T} \sum_{j=1}^{S} \sum_{k=1}^{S} \xi_{t}(j, k) \ln \mathcal{A}_{j, k}+\sum_{t=1}^{T} \sum_{k=1}^{S} \gamma_{t}(k) \ln \mathcal{B}_{k, x_{t}}$$其中$\gamma_t(k)=p(s_t=k | \vec{o}, \mathcal{\Lambda}^*),\text{ }\xi_t(j,k)=p(s_{t-1}=j,s_t=k | \vec{o}, \mathcal{\Lambda}^*); \quad 1 \leq t \leq T$,由贝叶斯公式可知$$\begin{cases} \gamma_t(k)=\frac{p(\vec{o}, s_t=k | \mathcal{\Lambda}^*)}{p(\vec{o} | \mathcal{\Lambda}^*)}=\frac{\alpha_t(k)\beta_t(k)}{\sum_{m=1}^S\alpha_t(m)\beta_t(m)} \\ \xi_t(j,k)=\frac{p(\vec{o}, s_{t-1}=j, s_t=k | \mathcal{\Lambda}^*)}{p(\vec{o} | \mathcal{\Lambda}^*)}=\frac{\alpha_{t-1}(j)\mathcal{A}_{jk}^*\mathcal{B}_{k,x_t}^*\beta_t(k)}{\sum_{m=1}^S\alpha_t(m)\beta_t(m)} \end{cases}$$注意此时的$\alpha_t(.)$以及$\beta_t(.)$是从参数的当前估计值$\mathcal{\Lambda}^*$计算出来的
- M-step: 更新参数的估计值$\mathcal{\Lambda}^*=\arg\max_{\mathcal{\Lambda}}\mathcal{L}(\mathcal{\Lambda})$,有$$\pi_{k}^*=\frac{\gamma_{1}(k)}{\sum_{j=1}^S \gamma_{1}(j)}, \quad \mathcal{A}_{jk}^*=\frac{\sum_{t=2}^{T} \xi_{t}(j, k)}{\sum_{t=2}^{T} \sum_{l=1}^{S} \xi_{t}(j, l)}, \quad \mathcal{B}_{kv}^*=\frac{\sum_{t=1}^{T} \gamma_{t}(k) I\left(x_{t}=v\right)}{\sum_{t=1}^{T} \gamma_{t}(k)}$$在实际应用中使用的不仅仅是1个序列,假设有$N$个序列,每个序列的长度为$T_n,\text{ }n\in\{1,2,\cdots,N\}$,则每个序列可以计算出自己的$\gamma_t,\xi_t$,记为$\gamma_t^{(n)},\xi_t^{(n)}$,更新公式变为$$\pi_{k}^*=\frac{\sum_{n=1}^{N} \gamma_{1}^{(n)}(k)}{\sum_{n=1}^{N} \sum_{j=1}^S \gamma_{1}^{(n)}(j)}, \quad \mathcal{A}_{jk}^*=\frac{\sum_{n=1}^{N} \sum_{t=2}^{T_{n}} \xi_{t}^{(n)}(j, k)}{\sum_{n=1}^{N} \sum_{t=2}^{T_{n}} \sum_{l=1}^{S} \xi_{t}^{(n)}(j, l)}, \quad \mathcal{B}_{kv}^*=\frac{\sum_{n=1}^{N} \sum_{t=1}^{T_{n}} \gamma_{t}^{(n)}(k) I\left(x_{t}^{(n)}=v\right)}{\sum_{n=1}^{N} \sum_{t=1}^{T_{n}} \gamma_{t}^{(n)}(k)}$$

- 迭代上述步骤直到收敛为止
隐藏状态序列估计
为了解决问题2,仍使用动态规划的思想(Viterbi Algorithm),定义$v_{t}(j)=\max _{s_{1}, \ldots, s_{t-1}} p\left(s_{1}, \ldots s_{t-1}, x_{1}, x_{2}, \ldots x_{t}, s_{t}=j | \mathcal{\Lambda}\right)$,此外还要定义$b_t(j)$用来存储$v_{t}(j)$对应的$s_{t-1}$,则算法可以写为
- Initialization: $$v_1(j)=\pi_j\mathcal{B}_{j,x_1},\text{ }b_1(j)=0; \quad 1 \leq j \leq S$$
- Recursion: $$\begin{aligned} v_{t}(j) &=\max _{i\in\{1,2,\cdots,S\}} v_{t-1}(i) \mathcal{A}_{i j} \mathcal{B}_{j,x_t} ; \quad 1 \leq j \leq S, 1<t \leq T \\ b_{t}(j) &= \underset{i\in\{1,2,\cdots,S\}}{\arg \max } v_{t-1}(i) \mathcal{A}_{i j} \mathcal{B}_{j,x_t} ; \quad 1 \leq j \leq S, 1<t \leq T \end{aligned}$$
- Termination: $$\begin{aligned} & \text { The best score: } P^*=\max _{\vec{s}} p\left(\vec{s},\vec{o} | \mathcal{\Lambda} \right)=\max _{i\in\{1,2,\cdots,S\}} v_{T}(i) \\ & \text { The start of backtrace: } s_{T}^*=\underset{i\in\{1,2,\cdots,S\}}{\operatorname{argmax}} v_{T}(i) \end{aligned}$$
- Backtrace: $$s_{t}^*=b_{t+1}(s_{t+1}^*); \quad 1 \leq t<T$$则$s_1^*,s_2^*,\ldots,s_T^*$即为$\arg\max _{\vec{s}} p\left(\vec{s},\vec{o} | \mathcal{\Lambda} \right)$,容易看出$\arg\max _{\vec{s}} p\left(\vec{s},\vec{o} | \mathcal{\Lambda} \right)=\arg\max _{\vec{s}} p\left(\vec{s} | \vec{o}, \mathcal{\Lambda} \right)$
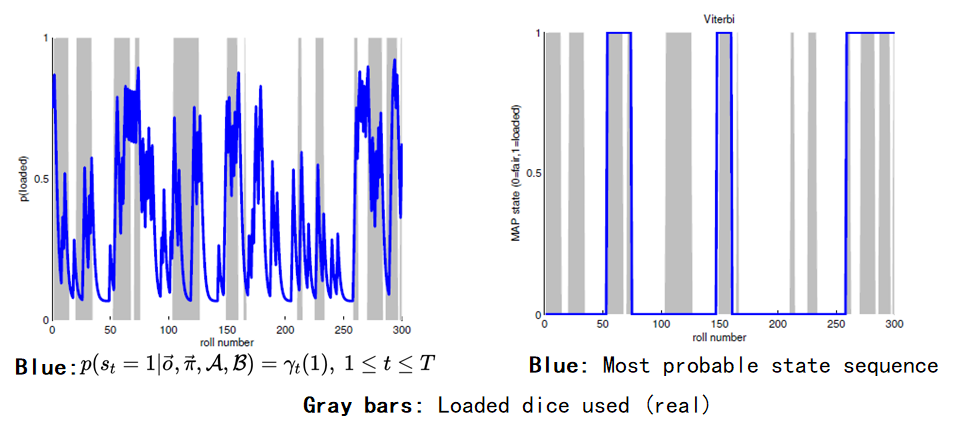
下面介绍一个使用HMM的简单例子:假设有两个骰子,一个未经处理(fair, 记为0),一个经过处理(loaded, 记为1)。每次投掷时使用前一次投掷的骰子,或者使用另一个骰子,观测序列是多次投掷所得到的骰子点数序列。假设真实的参数如下图所示,目标是通过观测序列估计真实的参数,进而估计出每次投掷使用的是哪个骰子。

最终的结果如下图所示,右图表示使用Viterbi算法得到的最可能的隐藏状态序列(即每次投掷使用了哪种骰子),注意左图进行简单地四舍五入后的结果不等于右图,因为左图并没有考虑状态之间的关联。
隐马尔科夫模型HMM介绍的更多相关文章
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- 用hmmlearn学习隐马尔科夫模型HMM
在之前的HMM系列中,我们对隐马尔科夫模型HMM的原理以及三个问题的求解方法做了总结.本文我们就从实践的角度用Python的hmmlearn库来学习HMM的使用.关于hmmlearn的更多资料在官方文 ...
- 隐马尔科夫模型HMM
崔晓源 翻译 我们通常都习惯寻找一个事物在一段时间里的变化规律.在很多领域我们都希望找到这个规律,比如计算机中的指令顺序,句子中的词顺序和语音中的词顺序等等.一个最适用的例子就是天气的预测. 首先,本 ...
- 隐马尔科夫模型 HMM(Hidden Markov Model)
本科阶段学了三四遍的HMM,机器学习课,自然语言处理课,中文信息处理课:如今学研究生的自然语言处理,又碰见了这个老熟人: 虽多次碰到,但总觉得一知半解,对其了解不够全面,借着这次的机会,我想要直接搞定 ...
- 猪猪的机器学习笔记(十七)隐马尔科夫模型HMM
隐马尔科夫模型HMM 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十七次课在线笔记.隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来 ...
- 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(一)HMM模型
隐马尔科夫模型HMM(一)HMM模型基础 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比 ...
- 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态 ...
随机推荐
- 【需要重新维护】Redis笔记20170811视频
很多内容都是抄的,个人记录 1.windows下初见 安装 进入目录 修改配置文件(暂时使用默认,未配置环境变量) 目录下:redis-server.exe启动服务 新建命令提示符,目录下,redis ...
- c# 自己实现可迭代的容器
在c#中我们经常使用到foreach语句来遍历容器,如数组,List,为什么使用foreach语句能够遍历一个这些容器呢,首先的一个前提是这些容器都实现了IEnumerable接口,通过IEnumer ...
- 牛客假日团队赛1 B
B.便便传送门(一) 题目链接:https://ac.nowcoder.com/acm/contest/918/B 题目 Farmer John最讨厌的农活是运输牛粪.为了精简这个过程,他制造了一个伟 ...
- WebGL 着色器偏导数dFdx和dFdy介绍
本文适合对webgl.计算机图形学.前端可视化感兴趣的读者. 偏导数函数(HLSL中的ddx和ddy,GLSL中的dFdx和dFdy)是片元着色器中的一个用于计算任何变量基于屏幕空间坐标的变化率的指令 ...
- AD域控制器安装使用
AD域控制器安装使用 一. 在服务器上安装域控制器 二. 将此服务器提升为域控制器 三. 将主机加入到我们创建的域中 在AD域控制器上查看加入的主机
- CentOs7.5安装FFmpeg
一.FFmpeg简介 FFmpeg是一个自由软件,可以运行音频和视频多种格式的录影.转换.流功能,包含了libavcodec ─这是一个用于多个项目中音频和视频的解码器库,以及libavformat— ...
- NumPy基础操作(3)——代数运算和随机数
NumPy基础操作(3)--代数运算和随机数 (注:记得在文件开头导入import numpy as np) 目录: NumPy在矩阵运算中的应用 常用矩阵运算函数介绍 编程实现 利用NumPy生成随 ...
- mysql 终端命令
1.打开数据库 /usr/local/MySQL/bin/mysql -u root -p 2.输入root密码 3.使用我的数据库 use mysql 4.查看表 desc table_name 5 ...
- django基础知识之定义模型:
定义模型 在模型中定义属性,会生成表中的字段 django根据属性的类型确定以下信息: 当前选择的数据库支持字段的类型 渲染管理表单时使用的默认html控件 在管理站点最低限度的验证 django会为 ...
- 事务的隔离级别,mysql默认的隔离级别是什么?
读未提交(Read uncommitted),一个事务可以读取另一个未提交事务的数据,最低级别,任何情况都无法保证. (1)所有事务都可以看到其他未提交事务的执行结果 (2)本隔离级别很少用于实际应用 ...