Hadoop HDFS 源码解析记录
版权说明: 本文章版权归本人及博客园共同所有,转载请标明原文出处( https://www.cnblogs.com/mikevictor07/p/12047502.html ),以下内容为个人理解,仅供参考。
文本参考书籍《Hadoop2.x HDFS源码剖析》编写。
一、HDFS体系结构
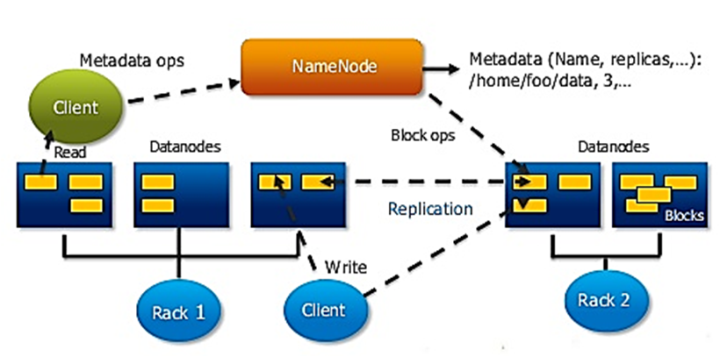
1、数据块Block
最小存储单元,默认128MB,适合大文件存储,减少寻址和内存开销。
2、Namenode
文件系统命名空间,含目录、文件的数据块索引,索引存储在内存中,文件越多占用内存越大。
同时存储命名空间镜像文件(FsImage)与编辑日志文件(EditLog),文件的变更先写入日志文件中。
2.X版本引入HA功能,通常通过Journal Nodes保持多主间EditLog同步。再加入ZKfailoverController进行主备切换操作(也可人工切换)。
3、Datanode
数据存储节点,执行数据块的创建、删除、复制等操作。
4、Secondary Namenode
由于Namenode 合并EditLog和FsImage非常耗时,特别在大型集群中。故增加一个secondary namenode负责定时从namenode获取(HTTP)EditLog并且合并到FsImage中,耗时的合并工作完成后将新的FsImage传回namenode。

二、HDFS主要流程
2.1 客户端的读取
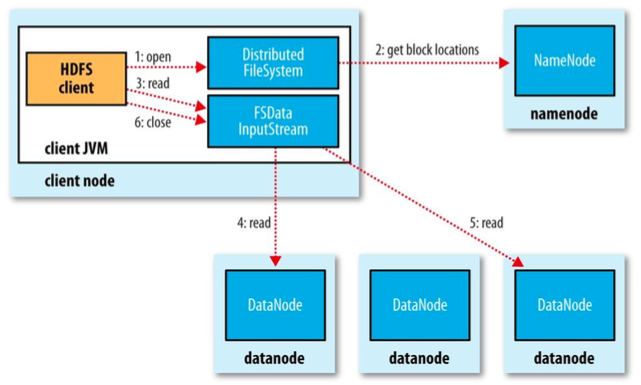
1、调用DistributedFileSystem.open打开文件(底层调用DFSClient.open)并创建HdfsDataInputStream。
2、通过调用DFSClient.getBlockLocations获取数据块所在的datanode节点列表,根据排序规则选择一个datanode建立连接获取数据块,当此数据块读取完毕后,再次向namenode获取下一个数据块。依次循环。
2.2 客户端写入流程
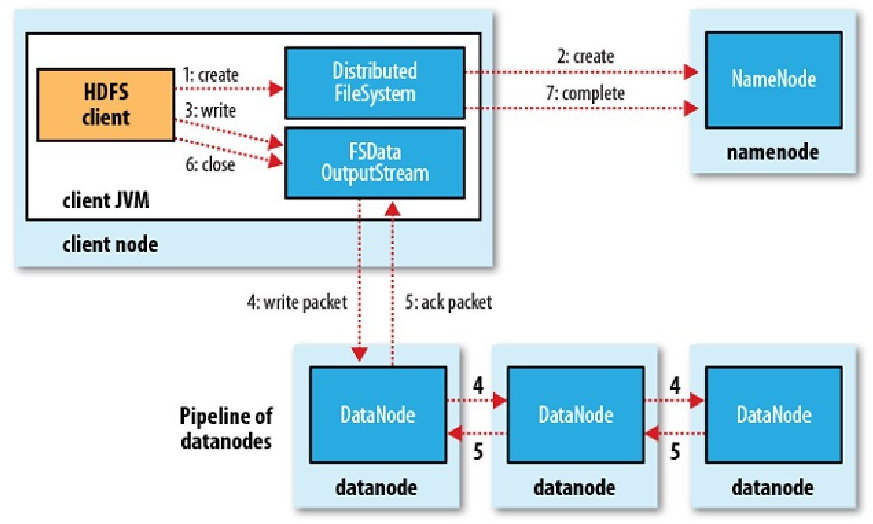
1、通过调用DistributedFileSystem.create在底层调用DFSClient.create发送通知namenode创建文件。
2、获取输出流后就可以调用DFSOutputStream写数据,空文件时就会调用Clientprotocol.addBlock向Namenode申请一个数据块并返回LocatedBlock,此对象包含该数据块的所有节点信息,后续即可往其中一节点write数据。
2.3 HA切换流程
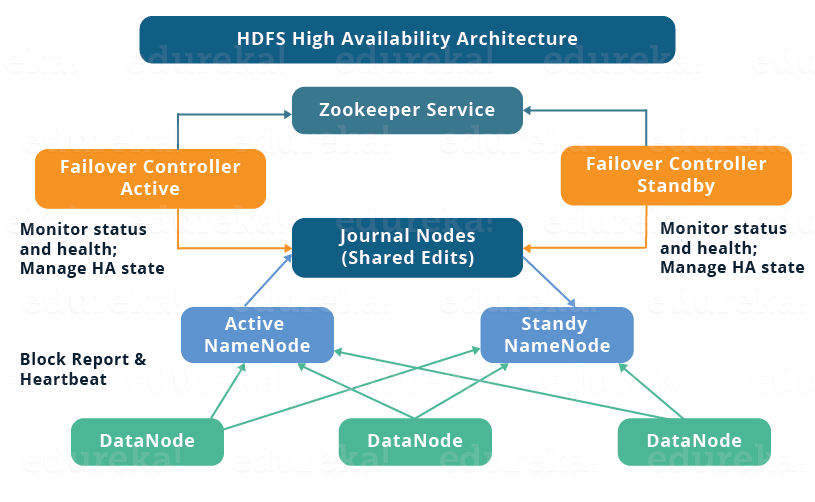
Hadoop 2.X之前版本NN存在单点故障,HA功能提供一个active NN与一个standby NN,命名空间实时同步。Active NN修改命名空间时同时通知多数的Quorum Journal Nodes(JNS),standby NN监听JNS中的editlog变化,并与自身的命名空间合并,当发生切换时,需要等待standby合并JNS上的所有editlog后才会进行切换。
ZKFailoverController会实时监控NN的状态,如果active NN处于不可用状态则进行自动主备切换,不需要人工干预,当然管理员也可用DFSHAAdmin命令进行手工切换。
三、NameNode
3.1 文件目录树
HDFS命名空间在内存中以树结构存储,目录与文件抽象为INode节点,目录为INodeDirectory,文件为INodeFile。目录有List<INode> children存储子目录或文件(内部使用二分法做检索),HDFS命名空间存储在本地系统FsImage文件中,启动时加载,与此同时NN会定期合并fsimage与editlog,editlog操作类为FSEditLog。
INodeFile主要成员变量:
private long header = 0L; # 文件头信息
private BlockInfoContiguous[] blocks; # 数据块与数据节点关系
3.2 数据块管理
1、NameNode启动时从fsimage加载文件与数据块之前的关系,数据块存储在哪些节点上具体是由datanode启动时向NN上报数据块信息时才能构建。
2、BlockMap在NN中存储数据块与节点的关系,该关系则由DN上报时更新。
3.3 数据节点管理
1、添加和撤销DN:HDFS提供的dfs.hosts可配置include和exclude,如果节点下线则配置exclude并执行dfsadmin -refreshNodes后NN开始进行撤销,下线的节点数据会复制到其他节点上,此时DN则处于正在被撤销状态,复制完毕后DN状态则变成已撤销。
2、DN启动需要向NN握手、注册于上报数据块,并定期发送心跳包。
3.4 NN的启动与停止
1、NN启动由NameNode类的main方法执行,并调用createNameNode方法进行初始化。调用FSNamesystem.loadFromDisk进行fsimage与editlog。
2、NN的停止则是通过启动时注册JVM的ShutdownHook,当JVM退出时调用,并输出一些退出日志。
四、数据节点DN
HDFS 2.X DN使用Federation架构,可配置多个命名空间,每个命名空间在DN中对应一个池。DN的启动由DataNode类的main方法执行,关闭也是注册了JVM的钩子。
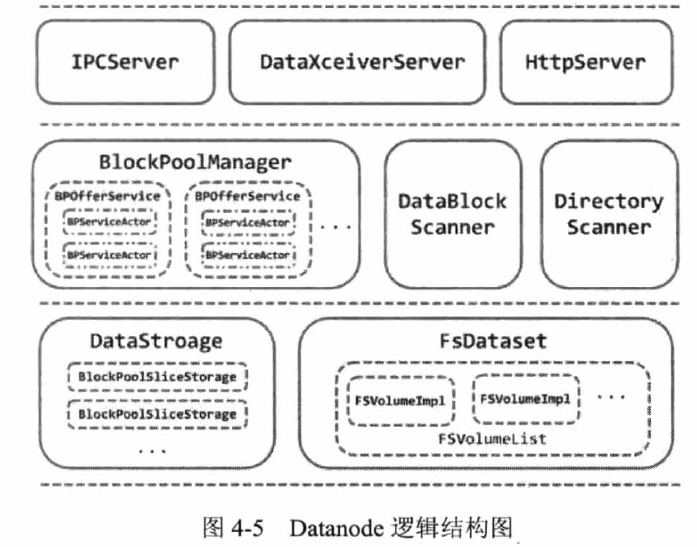
1、DataBlockScanner扫描数据块并检查校检和是否匹配。
2、DirectoryScanner定时扫描内存元数据与磁盘是否有差异,如有则更新内存。
3、IPCServer为RPC服务端,接收Client、NN、DN的RPC请求。
4、DataXceiverServer用于流式数据传输。
4.1 DN磁盘存储与读写
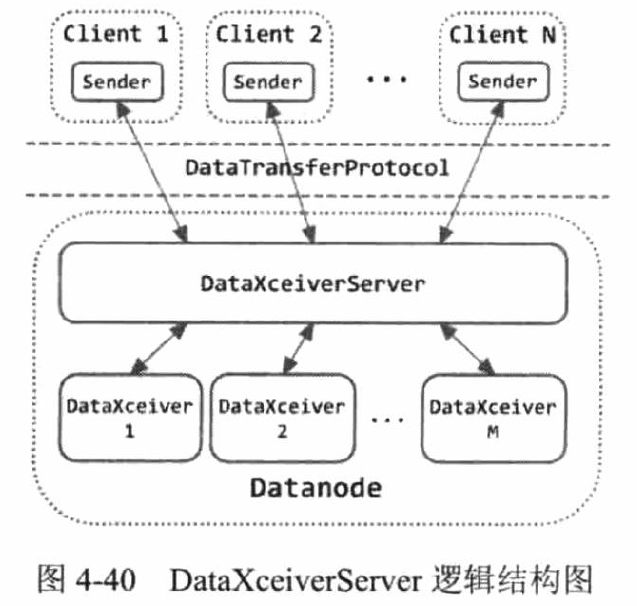
1、DFSStorage管理数据块,管理磁盘存储目录(dfs.data.dir),dfs.data.dir可定义多个存储目录,不同目录磁盘克异构。
2、DataTransferProtocol定义了基于TCP流的数据访问接口,包含Sender和Receiver,流程如下图:
五、HDFS常用工具
1、FsShell : bin/hadoop fs <args>
2、DFSAdmin: bin/hdfs dfsadmin <args>
Hadoop HDFS 源码解析记录的更多相关文章
- HDFS源码解析:教你用HDFS客户端写数据
摘要:终于开始了这个很感兴趣但是一直觉得困难重重的源码解析工作,也算是一个好的开端. 本文分享自华为云社区<hdfs源码解析之客户端写数据>,作者: dayu_dls. 在我们客户端写数据 ...
- HDFS源码解析系列一——HDFS通信协议
通信架构 首先,看下hdfs的交互图: 可以看到通信方面是有几个角色的:客户端(client).NameNode.SecondaryNamenode.DataNode;其中SecondaryNamen ...
- EventBus源码解析 源码阅读记录
EventBus源码阅读记录 repo地址: greenrobot/EventBus EventBus的构造 双重加锁的单例. static volatile EventBus defaultInst ...
- [源码解析]Oozie来龙去脉之内部执行
[源码解析]Oozie来龙去脉之内部执行 目录 [源码解析]Oozie来龙去脉之内部执行 0x00 摘要 0x01 Oozie阶段 1.1 ActionStartXCommand 1.2 HiveAc ...
- Parquet 源码解析
date: 2020-07-20 16:15:00 updated: 2020-07-27 13:40:00 Parquet 源码解析 Parquet文件是以二进制方式存储的,所以是不可以直接读取的, ...
- 2015.07.20MapReducer源码解析(笔记)
MapReducer源码解析(笔记) 第一步,读取数据源,将每一行内容解析成一个个键值对,每个键值对供map函数定义一次,数据源由FileInputFormat:指定的,程序就能从地址读取记录,读 ...
- MapReduce之提交job源码分析 FileInputFormat源码解析
MapReduce之提交job源码分析 job 提交流程源码详解 //runner 类中提交job waitForCompletion() submit(); // 1 建立连接 connect(); ...
- Flink 源码解析 —— 源码编译运行
更新一篇知识星球里面的源码分析文章,去年写的,周末自己录了个视频,大家看下效果好吗?如果好的话,后面补录发在知识星球里面的其他源码解析文章. 前言 之前自己本地 clone 了 Flink 的源码,编 ...
- Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
前言 如今,许多用于分析大型数据集的开源系统都是用 Java 或者是基于 JVM 的编程语言实现的.最着名的例子是 Apache Hadoop,还有较新的框架,如 Apache Spark.Apach ...
随机推荐
- PHP 面试官问:你说说Redis的几个过期策略?
在使用redis时,一般会设置一个过期时间,当然也有不设置过期时间的,也就是永久不过期.当设置了过期时间,redis是如何判断是否过期,以及根据什么策略来进行删除的. 设置过期时间 expire ke ...
- MathType转Word公式(OMML)
背景 由于之前个人喜欢在Word里做笔记,而有很多笔记里存在着大量的公式.在早期,由于对Word自身的公式的不理解,所以便使用了MathType这个工具来编写公式.但是现在本人已经转战到LatTeX了 ...
- 力扣(LeetCode)删除排序链表中的重复元素II 个人题解
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字. 思路和上一题类似(参考 力扣(LeetCode)删除排序链表中的重复元素 个人题解)) 只不过这里需要用到一个前 ...
- C语言1博客作业06
这个作业属于哪个课程 C语言程序设计II 这个作业的要求在哪里 https://www.cnblogs.com/sanying/p/11771502.html 我在这个课程的目标是 端正态度,认真对待 ...
- 用java实现“钉钉微应用,免登进入某H5系统首页“功能”
一.前言 哈哈,这是我的第一篇博客. 先说一下这个小功能的具体场景: 用户登录钉钉app,点击微应用,获取当前用户的信息,与H5系统的数据库的用户信息对比,如果存在该用户,则点击后直接进入H5系统的首 ...
- selenium滑块验证
使用selenium模拟登录解决滑块验证问题 本次主要是使用selenium模拟登录网页端的TX新闻,本来最开始是模拟请求的,但是某一天突然发现,部分账号需要经过滑块验证才能正常登录,如果还是模拟 ...
- ZeroC ICE的远程调用框架 ASM与defaultServant,ServantLocator
ASM与defaultServant,ServantLocator都是与调用调度(Dispatch)相关的. ASM是ServantManager中的一张二维表_servantMapMap,默认Ser ...
- 软件测试的原则,软件测试计划:5W1H
1.测试应该尽早介入. 2.所有的测试都应追溯到用户需求. 3.程序员应该避免检查自己的程序.除了单元测试.因为程序员对于自己的作品,思维具有局限性.无法保证测试质量.交给 ...
- python_08
一.作业 ''' 主页: 图标地址.下载次数.大小.详情页地址 详情页: 游戏名.好评率.评论数.小编点评.下载地址.简介.网友评论.1-5张截图链接地址. https://www.wandoujia ...
- 万恶之源-python内容的进化
1.整数: int--计算和比较 整数可以进行的操作: bit_length().计算整数在内存中占用的二进制码的长度 2.布尔值 bool 布尔值--用于条件使用 True 真 ...